Fairseq-快速可扩展的序列建模工具包
一种快速、可扩展的序列建模工具包,Pytorch的高级封装库,适用于机器翻译、语言模型和篇章总结等建模任务。
-
抽象
-
注册
-
实现上的特点
抽象
Dataset:数据加载
Fairseq中的Dataset基本都是按功能逐层封装,按需组合起来。所有数据加载的实现均位于fairseq/data下面。
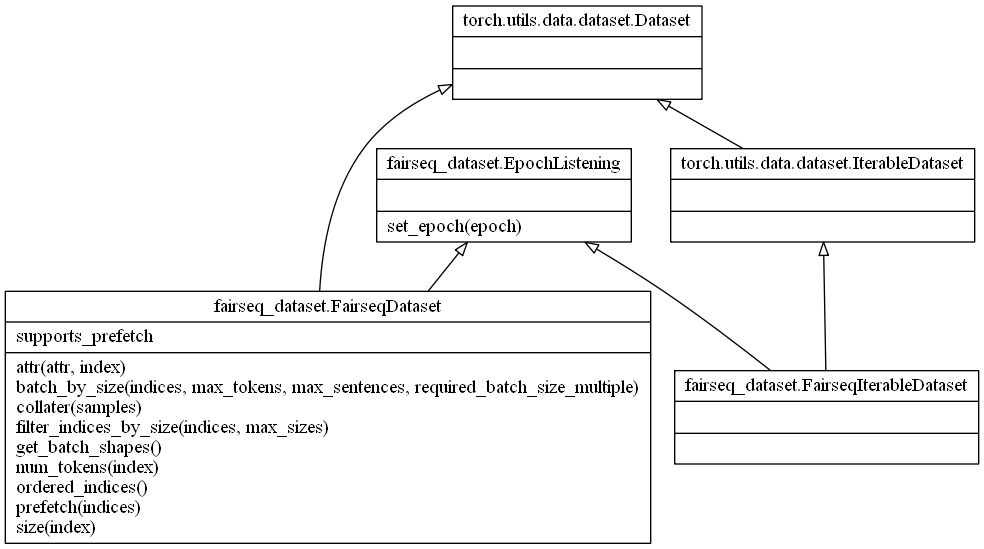
两个比较常用的数据处理类:
-
IndexedDataset直接处理/读取,bin/raw文件。 -
LanguagepairDataset包含src和tgt两个Dataset,用于处理成对的数据。比如在机器翻译的中翻英任务中,处理中文和英文文本。
Option:参数定义
Fairseq中的参数统一使用argsparser库实现,模型通用参数被定义在fairseq/option.py下。同时每个模型均有其特有参数,通过每个模型的add_args(parser)函数定义。
-
在
fairseq/option.py中定义了6类通用参数,对应的函数分别是get_preprocessing_parser(),get_training_parser(),get_generation_parser(),get_interactive_generation_parser(),get_eval_lm_parser()和get_validation_parser。这6类通用参数又通过add_***_args()组装起来。 -
在模型各自的实现中,通过继承接口中的
add_args()添加模型特有的参数,比如fairseq\models\lstm.py中通过add_args()添加了LSTM模型的encoder-embed-dim,encoder-layers,encoder-bidirectional等参数。
Model:网络模型的抽象
Fairseq中的Model负责模型的定义,包括各个模型的总体结构,每个模型提供argeparser供用户传入自定义参数。所有的模型定义均位于fairseq/models下。
所有的模型均继承自类BaseFairseqModel,而BaseFairseqModel又继承自torch.nn.Module,因此所有的Fairseq模型均可以作为其它Pytorch代码的模块。模型的具体结构,比如嵌入层的维度、隐藏层的个数由architectures定义。特别地,
-
LanguageModel和EncoderDecoderModel均直接继承自BaseFairseqModel,BaseFairseqModel主要提供add_args()、build_model()等统一的接口,以及模型加载等功能。 -
Encoder和Decoder均直接继承自torch.nn.Module,LanguageModel和EncoderDecoder包含Encoder和Decoder。 -
Decoder包含一个output_layer抽象接口,BERT这样的语言模型由于存在输出,因此继承的是Decoder。
FairseqTask
Fairseq主要以FairseqTask为核心,使用FairseqTask将各个部分衔接起来。一个Task可以是TranslationTask(比如使用Transformer做翻译),也可以是一个LanguageModelTask。所有的任务定义均位于fairseq/tasks下。一个FairseqTask实例需要实现以下功能:
-
字典存储/加载。
-
提供加载、分切数据的帮助类,获得装载数据的
Dataloader、iterator等。 -
创建模型。
-
创建
criterion。 -
循环训练、验证,直至收敛或达到指定训练轮数。
FairseqTask实现的功能基本上包含了模型运行的全部要素,可以看到主函数的调用流程:

Criterion
所有的准则(criterion)定义在fairseq/criterions内,准则对给定的模型和小批量数据计算损失(Loss)。也就是:
在Fairseq中,实现所谓的“混合专家”(mixture-of-experts)模型,准则(criterion)实现EM风格(EM-style)的训练,以节约算力。
Optimizer
所有的优化器(optimizer)定义在fairseq/optim中,优化器根据梯度,更新模型参数。
Scheduler
定义在fairseq/lr_scheduler中。在训练过程中,调整学习率。
注册
注册机制
Fairseq中许多组件都是公共的,模块之间尽量解耦,需要一种方式指定应该跑哪一个Model,数据装载使用哪一个Dataset。注册机制在Fairseq中大量使用。
以FairseqTask的注册机制为例,FairseqTask包含了多个子类,如TranslationTask、MaskedLMTask、LanguageModeling等。在fairseq/task/__init__.py中会通过for循环import该目录下的所有文件,最后在TASK_REGISTRY中可以得到key:cls形式的模块存储器。其中,key为字符串,cls为模块的cls对象。这种方式可以很方便的通过指定参数,导入想要的模块。在函数装饰器setup_task()和register_task()中,通过TASK_REGISTRY载入和注册task。
举个例子,通过装饰器进行注册,比如:
@register_task('language_modeling')
class LanguageModelingTask(FairseqTask):
...
在Model、Criterion部分都有该机制的身影。
在主函数train.py中,通过setup_task(),build_model(),build_criterion()中得到所需部分。
同样地,可以使用注册机制固化模型参数。一些模型仅仅有模型参数上的区别,本质并无区别,比如roberta_base,roberta_large。因此需要指定各个模型的具体默认参数,当然这些参数,用户可以通过fairseq的参数系统进行指定。这些模型的具体参数同样可以用注册的方式固定下来,在使用时可以更加方便。
- 对于模型,使用
@register_model装饰器注册。
@register_model('roberta')
class RobertaModel(FairLanguageModel):
...
- 对于具体的模型结构,使用
@register_model_architecture装饰器注册。
@register_model_architecture('robtera','roberta_large')
def roberta_large_architecture(args):
args.encoder_layers = getattr(args,'encoder_layers',24)
args.encoder_embed_dim = getattr(args,'encoder_embed_dim',1024)
...
base_architecture(args)
注册的函数对象会在ARCH_CONFIG_REGISTERY中存储,并在option.py中调用:
ARCH_CONFIG_REGISTRY[args.arch](args)
实现上的特点
Fairseq使用Pytorch实现,支持多机、多卡、混合精度训练。提升速度,降低显存占用。
分批次
Fairseq依据序列长度对源/目标序列进行分组,相似长度的序列作为一组,以减小对序列的补齐填充操作。每一个mini-batch内的样本在训练过程中不变,但每一轮训练时都会打乱mini-batch间的顺序。当在多卡、多机上运行时,每一个worker的mini-batches平均长度有所不同,以实现更有代表性(more representative)的迭代。
多GPU训练
-
使用NCCL2库和
torch.distributed作为GPU间的通信。 -
每个GPU上保留一个模型副本。
-
前向计算和反向传播异步。Fairseq中每一层的梯度计算完成后,都会把结果存放到缓存中,当缓存大小达到某一个阈值之后,在一个后台线程中同步梯度,反向传播照常进行。在每一个GPU上累加梯度,以减小worker上处理时间的方差,这样就不必等待计算比较慢的worker。
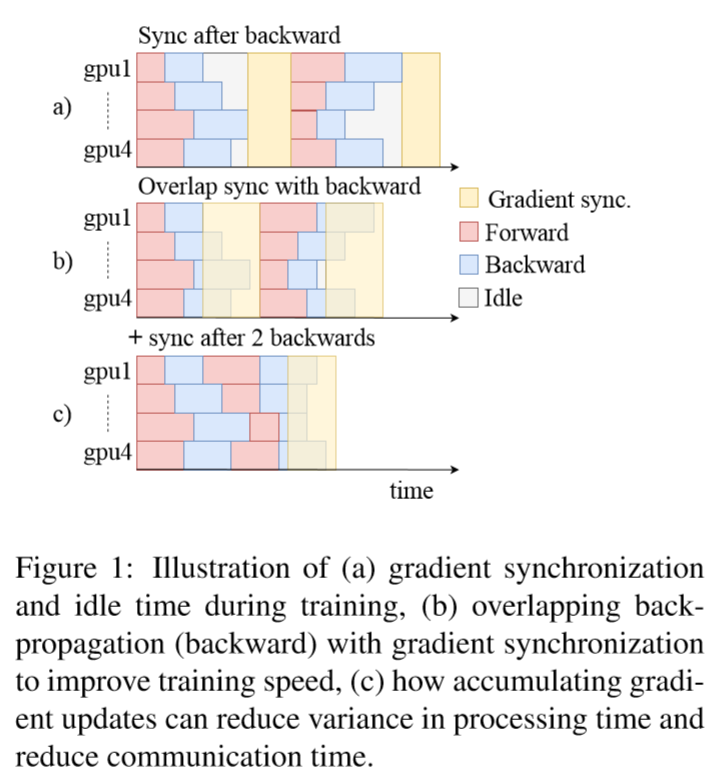
如图所示,图a在同步梯度时,等待最慢的worker,因此产生了大量的等待时间(白色所示,idle)。但Fairseq同时采用了图b和图c的技术,反向传播(back-propagation)和梯度同步(gradient synchronization)同时进行,并且累加梯度以减少worker上面处理时间的“抖动”,从而提升训练速度。
混合精度训练
Fairseq同时支持半精度浮点(half precision float point, FP16)和全精度浮点(full precision float point, FP32)的训练和推断。在前后向以及worker之间规约(all-reduce)时,使用FP16。但在参数更新时仍然采用FP32,以保证计算精度。由于FP16提供的精度有限,为了防止激活和梯度的下溢出,Fairseq实现了所谓的动态损失缩放(dynamic loss scaling)。当FP16的梯度在worker之间同步完成之后,将缩放到FP16的数字恢复为原来的FP32,并更新模型权重。
推断优化
Fairseq通过增量解码(incremental decoding)提供了更快的推理速度。所谓的增量解码,就是在解码时,将之前tokens处于激活beam状态下的模型状态(model states)缓存起来,以备后用,这样每一个新的token进来,只需要计算新的状态即可。也就是说,如果使用FairseqDecoder接口实现普通的解码器,对于每一个输出,都需要重新整个解码器隐状态,计算复杂度O(n^2)。而使用FairseqIncrementalDecoder接口实现增量解码,就可以实现O(n)的解码速度。
在训练和推理阶段,通过用户指定的最大tokens数量,构建动态样本数量的batch。并且Fairseq在保证准确率的前提下,支持FP16精度的推断。相比于FP32,FP16推断将解码速度提高54%。注意:在Fairseq中,用户通过指定max-tokens,Fairseq会自动构建不定数量的batch送入模型训练。当然,用户同样可以通过batch-size指定一个批次中的最大样本数。
Fairseq repo (Python): https://github.com/pytorch/fairseq
Paper: http://cn.arxiv.org/abs/1904.01038
Document: fairseq.readthedocs.io
https://zhuanlan.zhihu.com/p/100249351
https://zhuanlan.zhihu.com/p/100643955

 浙公网安备 33010602011771号
浙公网安备 33010602011771号