ICASSP 2020中的语音合成
ICASSP2020中与语音合成相关一共有5个Session,分别是:
-
Machine Learning for Speech Synthesis I
-
Machine Learning for Speech Synthesis II
-
Machine Learning for Speech Synthesis III
-
Speech Synthesis and Voice Conversion I
-
Speech Synthesis and Voice Conversion II
共计43篇论文。可以看到这些论文的分布:
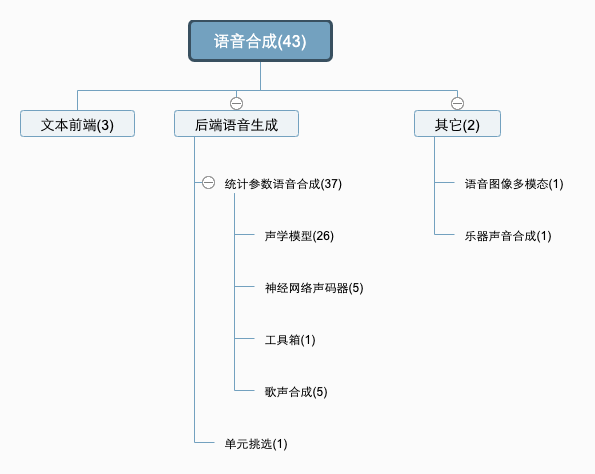
ICASSP2020语音合成部分的主要发展趋势:
-
Seq2Seq神经网络声学模型成为绝对主流,26篇声学模型(Acoustic Model, AM)相关论文,15篇使用Tacotron/Tacotron2。声学模型关注的主要问题包括:
-
稳定性
-
韵律和表现力
-
个性化
-
多语种
-
-
出现了一些新的声学模型,比如FlowTTS、AlignTTS和GraphTTS等。
文本前端
Zhang等, 《A Hybrid Text Normalization System Using Multi-Head Self-Attention For Mandarin》.
规则系统和神经网络混合的文本前端。主要探讨的是文本正则化(Text Normalization, TN),将非标准词(Non-Standard Words, NSW)转化为话语词(Spoken-Form Words, SFW)。比如将“打911”转化为“打九幺幺”,“开始于10:30”转化为“开始于十点半”或者“开始于十点三十”。文中使用正则表达式匹配,正则匹配不了了就送到神经文本正则模型(Neural TN Model),然后将原来文本、规则系统输出和神经文本正则模型的输出拼接起来,作为最终的输出。神经文本模型是一个多头自注意力机制的模型。
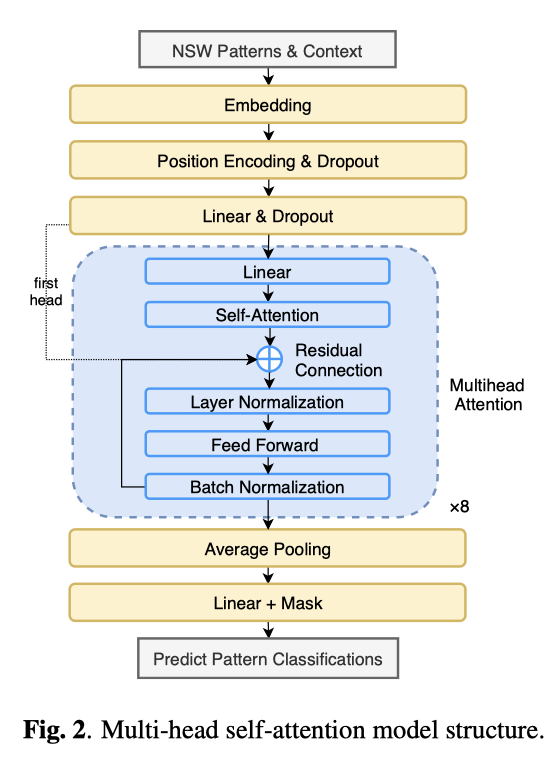
做词嵌入时,使用预训练的w2v(Wikipeida语料训练,更优)和BERT产生向量。论文中将使用神经文本正则模型的输出模式分为36种,神经模型的输出模式再传入模式读取器转化为SFW,文中还探讨了训练数据集中输出模式的种类不平衡的问题,上采样(在文本窗口内,用padding替换若干个字符,随机改变文本中数字,移动上下文窗口)和损失函数改造。整个混合系统的结构图:
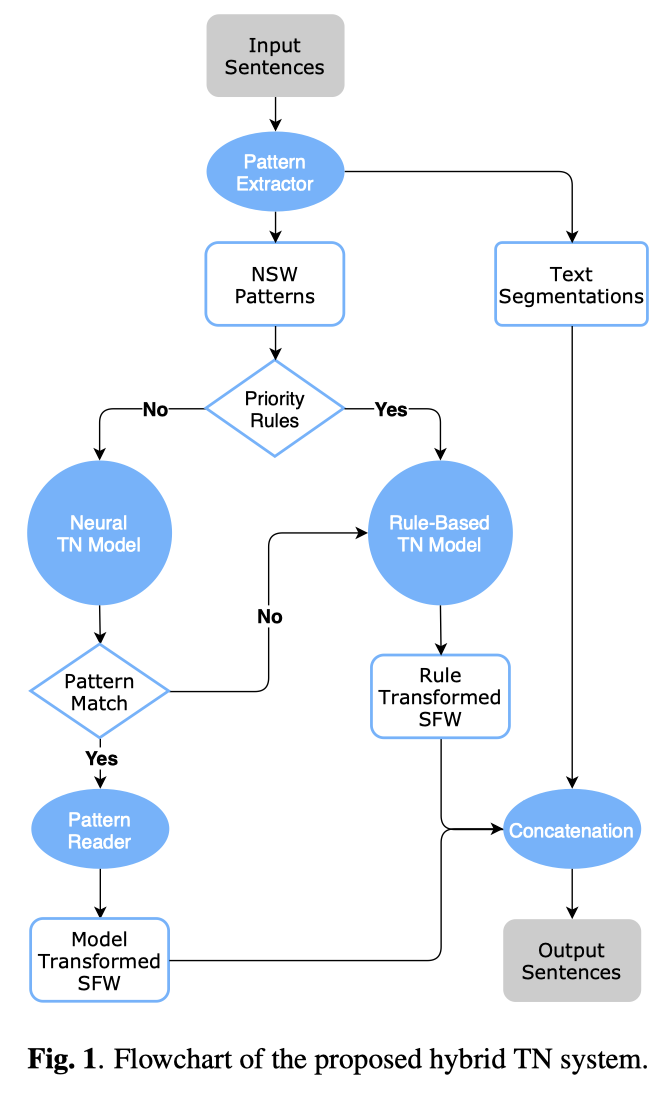
Pan等, 《A Unified Sequence-to-Sequence Front-End Model for Mandarin Text-to-Speech Synthesis》.
统一的seq2seq中文文本前端。这篇的文本正则化部分是使用本文上一篇Hybrid TN With Multi-Head Self-Attention中的方法。中文文本前端主要包括文本正则化(Text Normalization, TN),中文分词(Chinese Word Segment, CWS),词性标注(POS[part of speech] tagging),文本转音素(Grapheme-to-Phoneme, G2P)和韵律预测。韵律预测部分,ByteDance将韵律层级分为3个层级,韵律词(Prosody Word, PW),韵律短语(Prosody Phrase, PP)和语调短语(Intonation Phrase, IP)。这篇论文提出的统一序列到序列的文本前端,输入文本,输出音素、音调和韵律,整体结构类似于Tacotron2。
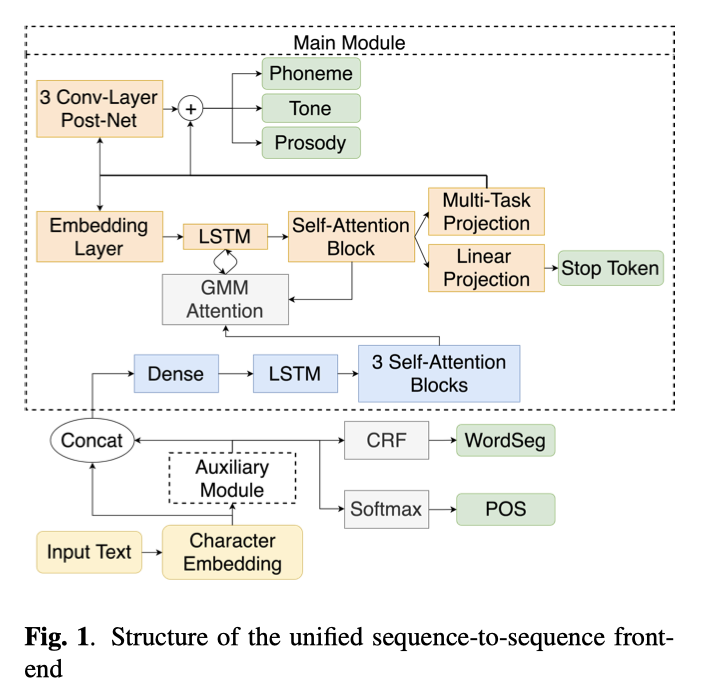
只不过在Character Embedding之后加入了分词和POS,这两个是通过辅助模块(Auxiliary Module)完成的,这个模块主题是带洞CNN(dilated-CNN, DCNN)或者transformer编码器(Transformer Encoder, TE)组成。分词和POS通过人民日报语料训练,韵律边界和拼音标签是使用内部数据集训练。DCNN由3个带洞卷积层组成,卷积核大小5,卷积核数量128,扩张率分别为1、2和4。TE包含一个256单元LSTM和一个8头自注意力模块,TE中同样包含位置嵌入(Position Embedding)。
文本首先通过词嵌入(Character Embedding)模块转化为300维词嵌入向量,这个词嵌入是通过1GB维基百科预训练的Word2Vec模型实现。词嵌入向量传入辅助模块,辅助模块的输出是分词和词性标注的one-hot向量,其中分词有4个标签,词性标注有99个标签。然后在CRF/Softmax层之前的dense表示和原来的嵌入向量拼接,作为后续主体模块的输入。主体模块的输出是音素、音调和韵律序列,以及停止符(Stop Token),作为后续声学模型的语言学输入。
Conkie和Finch, 《Scalable Multilingual Frontend for TTS》.
多语种文本前端。这个文本前端兼具规范化和Grapheme-to-Phoneme(G2P)的功能,直接将文本normalization和G2P任务作为机器翻译来做,实际上就是照办了Transformaer那一套,提出的框架还是Transformer。论文中尝试了两种做法,分别是将normalization和G2P分开做(Dual Model)以及两个模块联合用一个模型做(Combine),效果前者好一些,毕竟分开做,每个模型负担小一些。论文中还针对长文本,进行了类似于分帧(Splicing)的操作,窗长25个单词,重叠10个单词。同时,利用了字节编码对(Byte Encoding Pair, BEP)技术提升NLP模型的表现。
声学模型
多语种
Zhou等, 《End-to-End Code-Switching TTS with Cross-Lingual Language Model》.
CS(Code-Switching)TTS,编码转换语音合成/跨语种语音合成。从预训练的VecMap[1]中产生跨语种词嵌入(Cross-Lingual Word Embedding, CLWE),CLWE能够将不同语种的文本映射到同样的嵌入空间,分享彼此的上下文信息。产生音素嵌入之后,然后经过残差编码器,这个CLWE是和Speaker Embedding一起拼接到残差编码器输出之后的(见论文Fig3)。
实验数据集:THCHS-30和LibriTTS训练平均声学模型。字符级别的语言标示(Character-Level Language Identity,LID)one-hot之后拼接到音素嵌入向量。跨语种语言模型(Cross-Lingual Language Model, CLLM)是一个2LSTM(650units, dropout0.3),speaker embedding使用factor analysis获取。
[1] Mikel Artetxe, Gorka Labaka, and Eneko Agirre, “A robust selflearning method for fully unsupervised cross-lingual mappings of word embeddings,” arXiv:1805.06297, 2018.
Cao等, 《Code-Switched Speech Synthesis Using Bilingual Phonetic Posteriorgram with Only Monolingual Corpora》.
CS TTS,跨语种语音合成。就是在合成文本中存在不同语言的文本混合的语音合成。使用语音后验图(Phonetic PosteriorGrams, PPGs)建模语种说、话人无关的声学特征,PPG是一个时间-类别矩阵,表示某一特定帧音素类别的后验概率。解码器用线性映射输出PPG、LF0(log F0)、VUV(Voice/Unvoice)和停止符。之后,speaker embedding、双语PPG、LF0和VUV拼接送入2FC和4BLSTM组成的变换模型,speaker embedding和变换模型联合训练。
稳定性
Battenberg等, 《Location-Relative Attention Mechanisms for Robust Long-Form Speech Synthesis》.
提升TTS生成长句稳定性。谷歌的论文,提出了两种注意力机制,基于GMM的注意力和动态卷积注意力(Dynamic Convolution Attention,DCA)。后者主要是防止动态滤波器后向移动。
Liu等, 《Teacher-Student Training for Robust Tacotron-Based TTS》.
提升端到端TTS模型稳定性问题。这里主要解决的是自回归序列生成模型普遍存在的曝光偏差问题(exposure bias problem)。所谓曝光偏差,就是在使用教师强制的训练方式时,在训练和推断阶段,生成分布和真实数据分布不严格一致,因此条件概率在训练和推断阶段存在协变量偏移的问题,之前的预测结果发生错误,会导致错误传播,后续生成的序列也会偏离真实分布。解决这个问题的常规方案之一就是计划采样(Scheduled Sampling),在一个时间步上以一定概率使用真实数据,一定概率使用前一个时间步的预测值。这篇文章用蒸馏学习的方法解决曝光偏差,就是先训练一个老师模型,老师模型使用用真实数据引导训练,学生模型始终使用预测值作为上一个时间步的结果,引导下一个时间步的预测。知识蒸馏时候,引入了一个损失函数用于度量学生和老师的距离,就是解码器隐状态以及梅尔频谱的MSE。
Focusing on Attention- Prosody Transfer and Adaptative Optimization Strategy for Multi-Speaker End-to-End Speech Synthesis.
提升TTS稳定性,控制发音时长,自适用优化策略。1.提出一种带自反馈的时长控制器;2.提出一种自适用优化机制应对<文本,音频>不一致导致的不稳定问题。由于不发音音素和特殊发音等原因,对齐路径并不一定是一直单调向前的。时长控制器是一个DNN,输入文本部分(c_t,q_t)嵌入部分(词嵌入,韵律嵌入和说话人嵌入)和时长反馈部分(当前时间步、之前时间步。。。)。输出alignment向前、向后和不动的概率。
Yasuda, Wang和Yamagishi, 《Effect of Choice of Probability Distribution, Randomness, and Search Methods for Alignment Modeling in Sequence-to-Sequence Text-to-Speech Synthesis Using Hard Alignment》.
探讨语音合成模型稳定性问题。探讨如何选择良好的概率密度函数(Probability Distribution Fucntion, PDF)和对齐转移的采样方式。这篇文章对端到端TTS的“对齐方式”(注意力机制,alignment)有比较深入的理解和探讨。
韵律和表现力
-
Sun等, 《Generating Diverse and Natural Text-to-Speech Samples Using a Quantized Fine-Grained VAE and Auto-Regressive Prosody Prior》.
-
Sun等, 《Fully-Hierarchical Fine-Grained Prosody Modeling for Interpretable Speech Synthesis》.
-
Valle等, 《Mellotron: Multispeaker expressive voice synthesis by conditioning on rhythm, pitch and global style tokens》.
-
Um等, 《Emotional Speech Synthesis with Rich and Granularized Control》.
-
Xiao等, 《Improving Prosody with Linguistic and Bert Derived Features in Multi-Speaker Based Mandarin Chinese Neural TTS》.
-
Sun等, 《GraphTTS: graph-to-sequence modelling in neural text-to-speech》.
-
Szekely等, 《Breathing and Speech Planning in Spontaneous Speech Synthesis》.
这篇有点意思。为TTS增加气息等因素,使得合成语音更贴近人声。
-
Moss等, 《BOFFIN TTS: Few-Shot Speaker Adaptation by Bayesian Optimization》.
多说话人TTS,高斯优化,说话人适用,少于10分钟达到基模型的效果。
-
Aggarwal等, 《Using VAEs and Normalizing Flows for One-Shot Text-To-Speech Synthesis of Expressive Speech》.
-
Cooper等, 《Zero-Shot Multi-Speaker Text-To-Speech with State-of-the-Art Neural Speaker Embeddings》.
个性化
在目标说话人语料受限的情况下,合成具有目标说话人特点的语音。
-
Inoue等, 《Semi-Supervised Speaker Adaptation for End-to-End Speech Synthesis with Pretrained Models》.
-
Himawan等, 《Speaker Adaptation of a Multilingual Acoustic Model for Cross-Language Synthesis》.
-
Maiti, Marchi和Conkie, 《Generating Multilingual Voices Using Speaker Space Translation Based on Bilingual Speaker Data》.
工具箱
Hayashi等, 《Espnet-TTS: Unified, Reproducible, and Integratable Open Source End-to-End Text-to-Speech Toolkit》.
ICASSP2020中,ESPNet-TTS的论文也发表了。这是一种开源的语音合成合集,囊括了目前主流的语音合成,特别是端到端的语音合成方法,可以作为很好的学习、上线、论文基线。
GitHub地址:https://github.com/espnet/espnet
神经网络声码器
在合成质量和模型复杂度之间取得较好的平衡。
-
对LPCNet声码器的改进,特点是连续输出、多点生成。
-
Popov, Kudinov和Sadekova, 《Gaussian Lpcnet for Multisample Speech Synthesis》.
-
Hwang等, 《Improving LPCNET-Based Text-to-Speech with Linear Prediction-Structured Mixture Density Network》.
-
-
对WaveNet的改造,优化结构,多点生成。
- Tobing等, 《Efficient Shallow Wavenet Vocoder Using Multiple Samples Output Based on Laplacian Distribution and Linear Prediction》.
-
非自回归的声码器
-
Yamamoto, Song和Kim, 《Parallel Wavegan: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram》.
-
Wu和Ling, 《WaveFFJORD: FFJORD-Based Vocoder for Statistical Parametric Speech Synthesis》.
-
歌声合成
侧重于在声学模型中考虑乐谱中时长、音调等约束:改进网络结构、基频参数化。
-
Blaauw和Bonada, 《Sequence-to-Sequence Singing Synthesis Using the Feed-Forward Transformer》.
-
Choi等, 《Korean Singing Voice Synthesis Based on Auto-Regressive Boundary Equilibrium Gan》.
-
Nakamura等, 《Fast and High-Quality Singing Voice Synthesis System Based on Convolutional Neural Networks》.
-
Bonada和Blaauw, 《Hybrid Neural-Parametric F0 Model for Singing Synthesis》.
-
Lee等, 《Disentangling Timbre and Singing Style with Multi-Singer Singing Synthesis System》.
分离音色和歌唱风格。
其它论文
-
单元挑选
Zhou等, 《Extracting Unit Embeddings Using Sequence-To-Sequence Acoustic Models for Unit Selection Speech Synthesis》.
-
生成音频片段对应的说话人图像缺失部分(Talking Face)
Koumparoulis等, 《Audio-Assisted Image Inpainting for Talking Faces》.
-
将WaveNet/WaveGlow/NSF用于乐器声音合成
Zhao等, 《Transferring neural speech waveform synthesizers to musical instrument sounds generation》.
总结
-
深度学习在语音合成领域应用越来越广泛,文本前端、声学模型、声码器都有应用,现在传统方法比如单元挑选的语音合成方法研究较少。
-
讨论的领域多样,但有侧重点。目前有文语转换(TTS),也有歌声合成、乐曲合成,甚至音频&图像多模态等诸多研究方向,但是声学模型占据巨大的注意力。
-
声学模型主要关注多语种、稳定性、个性化、韵律表现力等方面,值得注意的是,之前一直是规则系统的文本前端,现在也有将神经网络应用到其中的尝试。
-
神经网络声码器的研究偏少,主要是希望平衡音质和模型复杂度,提升实际应用中采样点的生成速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号