Tensorflow进阶
第一章
图像领域,第\(i\)类图片提取到的特征:
其中,\(j\)表示一张图片的第\(j\)个像素,\(b_i\)是偏置值(bias),顾名思义就是这个数据本身的一些倾向,比如如果训练获得的参数\(w\)大部分数字是0,那么0特征对应的bias就会很大。
对于多分类问题,通常使用交叉熵作为损失函数(loss function),通常可以用它来判断模型对真实概率分布估计的准确程度,
其中,\(y'\)是真实概率分布,\(y\)是预测的概率分布
y_=tf.placeholder(tf.float32,[None,10]) # 真实label
cross_entropy=tf.reduce_sum(-tf.reduce_sum(y_*tf.log(y),reduction_indices=[1]))
定义优化器
train_step=tf.train.GradientDecentOptimizer(learning_rate=0.1).minimize(cross_entropy)
初始化:
tf.global_variable_initializer().run()
使用一部分样本进行训练,这被称作随机梯度下降,与每次都使用全部样本惊醒训练的传统梯度下降相对应,如果每次都使用全部样本,计算量太大,且有可能跳不出局部最优。
for i in range(1000):
batch_xs,batch_ys=mnist.train.next_batch(64)
train_step.run(feed_dict={x:batch_xs,y:batch_ys})
计算准确性:
correct_prediction=tf.equal(tf.argmax(y,axis=-1),tf.argmax(y_,axis=-1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print(accuracy.eval(feed_dict={x:mnist.test.images,y_:mnist:test.labels}))
第二章
-
神经网络的最大价值在于对特征的自动提取和抽象
深度学习在早期一度被认为是一种无监督的特征学习:a.无监督学习,自主提取频繁出现的特征;b.逐层抽象
自编码器(AutoEncoder):使用自身的高阶特征编码自己。自编码器其实也是一种神经网络,其输入输出是一致的,其借助稀疏编码器的思想,目标是使用稀疏的一些高阶特征重新组合来重构自己。
-
初始化方式
Xavier如果深度学习模型的权重初始化得太小,那信号在每层间传递时逐渐缩小而难以产生作用,但如果权重初始化得太大,那么信号将在每层间传递时逐渐放大,并最终导致发散和失效。
Xavier使权重满足0均值,方差为\(\frac{2}{n_{in}+n_{out}}\),参数初始值分布可以用均匀分布或高斯分布。 -
对数据进行预处理时,经常需要使用
sklearn等库进行数据的标准化,以使得量纲一致,注意:在标准化时,应该使用同一scalar,这样才能保证模型处理数据时的一致性:from sklearn.preprocessing import StandardScaler scaler=StandardScaler().fit(X_train) X_train=scaler.transform(X_train) X_test=scaler.transform(X_test) -
正则化是帮助惩罚特征权重的,特征权重也会成为模型损失函数的一部分,即为了使用某特征,模型需要付出loss的代价,除非这个特征确实有效,否则就会被loss惩罚而被舍弃掉。奥卡姆剃刀法则:越简单的东西越有效。
all_variables=tf.trainable_variables() reg_weight=1e-3 regularization_loss = reg_weight* tf.reduce_sum([ tf.nn.l2_loss(v) for v in all_variables ]) loss = original_loss + regularization_loss -
LRN模仿了生物神经网络的侧抑制机制,使得其中响应比较大的值变得相对更大,并抑制其它反馈较小的神经网络单元,增强了模型的泛化能力,LRN对ReLU这种没有上限边界的激活函数会比较有用,因为其会从附近的多个卷积核响应中挑选比较大的反馈,但不适应sigmoid这种有节并且能够抑制过大值得激活函数。tf.nn.lrn()
第三章
-
AlexNet:5conv + 3 FC,共8层
-
VGGNet从11层得网络一直到19层得网络都有详尽得性能测试。1×1卷积的主要意义在于线性变换。VGGNet拥有5段卷积,每一段有2~3个卷积层,同时尾部会连接一个最大池化层,其中经常出现多个完全一样的3×3的卷积层堆叠在一起。两个3×3卷积串联相当于一个5×5卷积层,即一个像素会跟周围5×5的像素发生关联,可以说感受野是5×5,但参数量小得多。堆叠卷积层,增大感受野。
VGGNet中的观点:
LRN层作用不大- 越深的网络效果越好
- 1×1卷积也是很有效的,但没有3×3卷积好,大一些卷积核可以学习更大的空间特征
一般来说,卷积层要提升表达能力,主要依靠增加输出通道数,但副作用是计算量增大以及过拟合,因为每一个输出通道对应一个滤波器(卷积核),同一个滤波器共享参数,只能提取一类特征,因此一个输出通道只能做一种特征处理。而NIN中的MLP conv则拥有更强大的能力,允许在输出通道之间组合信息。MLP conv基本等效于普通卷积层后再连接1×1卷积和ReLU激活函数,1×1卷积是一个非常优秀的结构,可以跨通道组织信息,提高网络表达能力,同时可以对输出通道进行升维和降维。
![]()
如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,构筑这个网络的最佳方法是逐层构筑网络,将上一层高度相关的节点进行聚类,并将聚类出来的每一个小簇连接在一起。
Batch Normalization是一个非常有效的正则化方法,可以让大型卷积网络训练加速数倍,同时使得收敛后的分类准确率显著提高。BN作用于神经网络上每层时,会对mini-batch数据内部进行标准化处理,使输出规范化到N(0,1)的正态分布,减少了内部协方差偏移(Internal covariance shift)。
-
Inception v3网络结构:首先是5个卷积层和2个池化层交替的普通结构,然后是3个Inception模块组,每个模块组内包含多个结构类似的Inception module。设计Inception Net的一个重要原则是:图片尺寸不断缩小,但输出通道不断增加;每一层卷积、池化或Inception模块组的目标都是将空间结构简化,同时将空间结构信息转化为高阶抽象的特征信息,即将空间维度转化为通道维度。
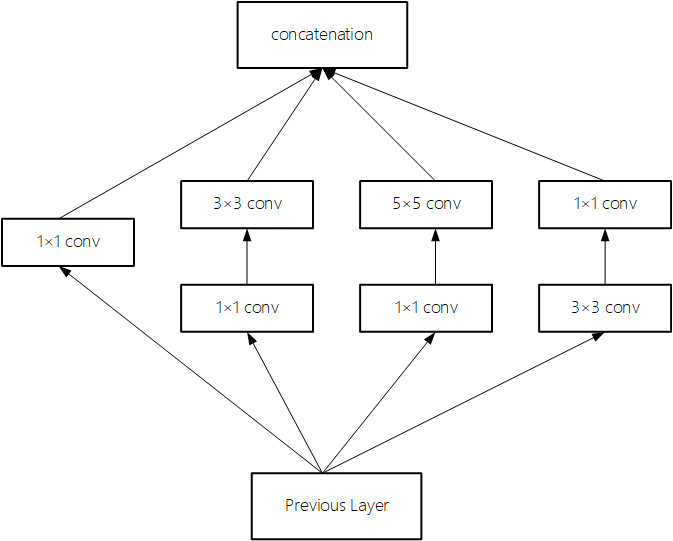
Inception Module规律:一般情况下有4个分支,第1个分支一般是1×1conv;第2个分支一般是1×1conv后再接分解后的n×1或1×n卷积;第3个分支和第2个分支类似,但一般更深一些;第4个分支一般具有最大池化或平均池化。因此,Inception Module是通过组合较简单的特征抽象(分支1),比较复杂的特征抽象(分支2和分支3)和一个简化结构的池化层(分支4),一共4种不同程度的特征抽象和变换有选择地保留不同层次的高阶特征,最大程度丰富网络的表达能力。
一般认为:神经网络的深度对性能十分重要,但网络越深,其训练难度也越大。
-
Highway Network相当于修改了每一层的激活函数,此前的激活函数只是对输入做一个非线性变换\(y=H(x,w_h)\),而Highway Network则允许保留一定比例的原始输入\(x\),即\(y=H(x,w_h)*T(x,w_T)+x*C(x,w_c)\),其中\(T\)为变换系数,\(C\)为保留系数,论文中令\(C=1-T\)。上一层的信息有一定比例可以不经过矩阵乘法和非线性变换,直接将信息送入下一层。
-
在不断加深神经网络深度时,会出现一个降级(Degradation)问题,即准确率先上升达到饱和,再持续加深深度时会导致准确率下降。这并不是过拟合问题,因为不但测试集上的误差会增大,训练集的误差也会增加。假设有一个较浅的网络达到了饱和的准确率,则在后面加入几个\(y=x\)的全等映射层,起码误差不会增大,即更深的网络不应带来训练集上的误差上升。
若某段神经网络的输入是\(x\),期望输出是\(H(x)\),如果直接把输入\(x\)传到输出作为初始结果,则此时需要学习的目标的是\(F(x)=H(x)-x\)。
ResNet学习的只是输出和输入的差别\(H(x)-x\),即残差。残差网络相当于:
![]() \[H(x)=F(x)+x\\ 目标=此层残差拟合+已有的拟合值 \]
\[H(x)=F(x)+x\\ 目标=此层残差拟合+已有的拟合值 \]之前的层相当于已经学习到一定的成果,对目标已经拟合到了一定程度,之后的层只不过是想要缩小这种拟合误差,因此至少不会让拟合越来越糟,至少能和之前的层相同。
普通直连的卷积神经网络和ResNet最大的区别在于,ResNet有很多旁路的支线,将输入直接到后面的层,使得后面的层可以直接学习残差,这种结构亦称作
shortcut或skip connections传统的卷积层或全连接层在传播信息时,或多或少存在信息丢失、损耗等问题,ResNet在某种程度上解决了这个问题,通过直接将输入信息绕道传入输出,保护信息的完整性,整个网络只需要学习输入和输出差别的那一部分,简化了学习的目标和难度。
在ResNet论文中,除了提出两层学习单元之外,还有三层学习单元,两层的残差学习单元中包含两个相同输出通道数(因为残差等于目标输出减去输入,即\(H(x)-x\),因此输入、输出维度必须保持一致)。3层残差网络使用了Network In Network和Inception Net中的1×1 conv,并且是在中间3×3的卷积,前后都使用1×1 conv,先降维再升维,另外,如果有输入和输出维度不同的情况,可以对\(x\)做一个线性映射变换维度,再连接后面的层。
![]()
两层残差单元,输入和输出维度保持一致。
![]()
前后1×1卷积,先降维再升维
第四章
Word2Vec将语言中的字词转化为计算机可以理解的稠密向量(Dense Vector).向量空间模型(Vector Space Models)可以将字词转化为连续值得向量表达。并且其中意思相近得词被映射到向量空间中相近的位置。向量空间模型在自然语言中主要依赖的假设是
Distributional Hypothesis:在相同语境下出现的词其语境也相近。向量空间模型可以大致分为两类:一类是计数模型,如
Latent Senantic Analysis,另一类是预测模型如Neural Probabilistic Language Model。计数模型统计在语料库中,相邻出现词的概率,再把这些计数统计结果转化为小而稠密的矩阵;而预测模型则根据一个词周围相邻词推测出这个词,以及它的空间向量。Word2Vec可以从原始语料中学习字词空间的预测模型,其主要分为CBOW(Continous Bag Of Words)和Skip-Gram两种模型。其中CBOW是从原始语句中推测目标字词,Skip-Gram则正好相反,是从目标字词中推测出原始词句。CBOW对小型数据较有效,Skip-Gram对大型数据较有效预测模型(Neural Probability Language Models)通常使用最大似然的方法,在给定的前面语句的情况下,最大化目标词汇\(w_t\)的概率。但其存在一个严重的问题是计算量非常大,需要计算词汇表中所有单词出现的概率。在
CBOW模型中不需要计算完整的概率模型,只需要训练一个二元的分类模型,仅需要区分真实的目标词汇和编造的词汇(噪声)两类,这种用少量噪音词汇来估计的方法,类似于蒙特卡罗模拟,当模型预测真实的目标词汇为高概率,同时预测其它噪音词汇为低概率时,训练的学习目标即被最优化。用编造的噪音词汇训练的方法被称作Negative Sampling(负采样)。用这种方法计算loss function的效率非常高,只需要计算随机选择的k个词汇而非词汇表中的全部词汇,因此训练速度非常快。实际中,使用Noise-Contrastive Estimation(NCE)loss。tf.nn.nce_loss()直接实现了该loss。Word2Vec训练样本的构造:以the quick brown fox jumped over the lazy dog为例,要构造一个语境与目标词汇的映射关系。其中语境包括一个单词左边和右侧的词汇,假设滑窗尺寸为1,可以制造映射关系包括[the,brown]->quick,[quick,fox]->brown,[brown,jumped]->fox等,因为Skip-Gram模型是从目标词汇预测语境,因此训练样本不再是[the,brown]->quick,而是quick->the,quick->brown。因此数据集变为了(quick,the)、(quick,brown)、(brown,quick)、(brown,fox)等。因此在训练时,希望模型能够从目标词汇quick预测出语境the。同时也需要制造随机的词汇作为负样本(噪声),希望预测的概率分布在正样本the上尽可能大,而在随机产生的负样本上尽可能小。做法就是通过优化算法比如SGD来更新模型的word embedding的参数,让概率分布NCEloss尽可能小。这样每个单词的Embedding Vector会随着训练过程不断调整,直到处于一个最适合语料的空间位置。在开源库中(如gensim),
Word2Vec模型常见的参数:skip_window:指单词最远可联系的距离num_skips是对每个单词生成的样本数量,num_skips应小于等于2*skip_windowbatch_size应是num_skips的整数倍span是对某个单词创造相关样本时使用的单词数量,包括目标单词本身和其前后的单词,因此span=2*skip_window+1
卷积神经网络虽然可以对图像进行分类,但是无法对视频中每一帧图像发生的事情进行关联分析。循环神经网络最大的特点时神经元的某些输出可作为其输入再次传输到神经元中,因此可以利用之前的信息。
![]()
\(x_t\)是RNN的输入,A是RNN的一个节点,而\(b_t\)是输出。对RNN输入数据\(x_t\),然后通过网络计算并得到输出结果\(h_t\),再将某些信息(state,状态)传递到网络的输入。将输出与label进行比较可以得到误差,有了误差之后就可以使用
梯度下降(Gradient Descent)和Back-Propagation Through Time(BPTT)方法对网络进行训练。BPTT与训练前馈神经网络的传统BP方法类似,也是使用反向传播求解梯度并更新网络参数。另外还有一种方法叫Real-Time Recurrent Learning(RTRL),其可以正向求解梯度。另外还有介于
BPTT和RTRL两种方法之间的混合方法,可用于缓解因为时间序列间隔过长带来的梯度弥散问题。![]()
RNN展开成串联形成后,每一层级的神经网络其参数都是相同的,并不需要训练成百上千层神经网络的参数,只需要训练一层RNN的参数。这里共享参数的思想和卷积网络中权值共享的方式也很类似。
对某些复杂问题,需要较早的信息,甚至是时间序列开头的信息。但间隔太远的输入信息,RNN是难以记忆的,因此长程依赖是传统RNN的致命伤。
LSTM的状态state,会贯穿所有串联在一起的LSTM单元,从第一个LSTM单元一直流向最后一个LSTM单元,其中只有少量的线性干预和改变。状态state再这条隧道中传递时,LSTM单元可以对其添加或删除信息。这些对信息流的修改操作有LSTM中的门(Gates)控制,每个LSTM单元包括3个门(输入、输出和遗忘门)。
GRU相比LSTM结构更简单,比LSTM少一个门,只有更新门和重置门,但准确率持平,收敛更快。
tf.nn.rnn_cell.BasicLSTMCell():num_steps: LSTM展开步数,控制训练过程,会限制梯度在反向传播时可以展开的步数hidden_size: LSTM输出维度state_is_tuple: 为True表示返回的state是一个Tuple形式,state=(c,h)
RNN的
Dropout层:tf.nn.rnn_cell.DropoutWrapper()RNN的堆叠函数:
tf.nn.rnn_cell.MultiRNNCell()






 浙公网安备 33010602011771号
浙公网安备 33010602011771号