day111 爬虫第一天
一、模拟浏览器发请求.
import requests
r1 =requests.get(
url ="https://dig.chouti.com/",
headers ={
"user-agent":'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' # 模拟浏览器
}
)
print(r1.text)
二、拿到访问的cookie (cookie.get_dict)
import requests
r1 =requests.get(
url ="https://dig.chouti.com/",
headers ={
"user-agent":'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
)
r1_cookie_dict =r1.cookies.get_dict() #取cookie方式.
print(r1_cookie_dict)
三 、 通过拿到的Cookie自动登录
import requests
r1 =requests.get(
url ="https://dig.chouti.com/",
headers ={
"user-agent":'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
)
r1_cookie_dict =r1.cookies.get_dict()
print(r1_cookie_dict)
打印cookie 数据{'gpsd': '2b374387cb18e6231dad05778939ed9e', 'JSESSIONID': 'aaaq8zR3Ff_WQ8XSSeysw'}
import requests
r2 =requests.post(
url= 'https://dig.chouti.com/login',
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}, # headers 里的数据为请求头.
data={
"phone":"8618611998441",
"password":"xxx",
"oneMonth":1
}, #data 里的数据为请求体.
cookies =r1_cookie_dict #通过第一次访问拿到cookie
)
print(r2.text) #打印请求结果
打印结果:{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_53188065757"}}}
四、点赞请求
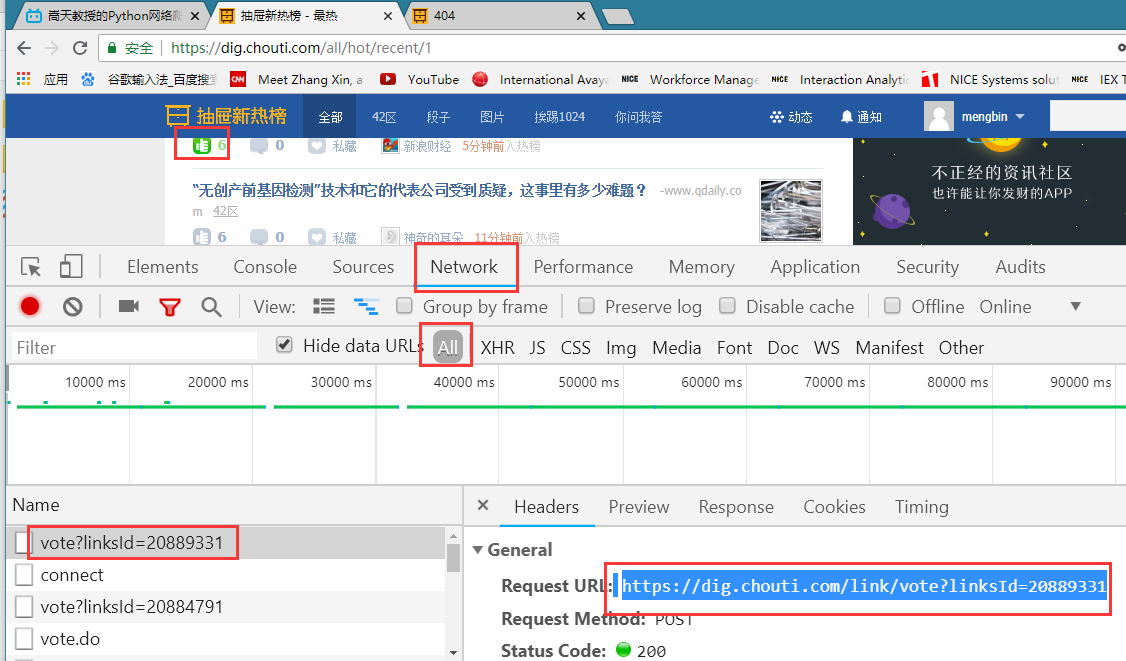
r3 =requests.post(
url="https://dig.chouti.com/link/vote?linksId=20889331",
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
},
cookies =r1_cookie_dict
)
print( "r3.text===>",r3.text)
打印结果:r3.text===> {"result":{"code":"30010", "message":"你已经推荐过了", "data":""}}
总结 (三步骤)
#第一步 拿到cookie
import requests r1 =requests.get( url ="https://dig.chouti.com/", headers ={ "user-agent":'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' } ) r1_cookie_dict =r1.cookies.get_dict() print("r1_cookie====>",r1_cookie_dict) #第二步登录
import requests r2 =requests.post( url= 'https://dig.chouti.com/login', headers={ 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' }, data={ "phone":"8618611998441", "password":"xxx", "oneMonth":1 }, cookies =r1_cookie_dict ) print("r2.text===>",r2.text) #第三步点赞
r3 =requests.post( url="https://dig.chouti.com/link/vote?linksId=20889331", headers={ 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36' }, cookies =r1_cookie_dict ) print( "r3.text===>",r3.text)
作业
作业:
1. 爬取抽屉新热榜的新闻:
标题
简介
地址
图片
2. 煎蛋网
- 爬取标题+简介
- 爬取图片
一 、 抽屉网站爬虫
import os
import requests
from bs4 import BeautifulSoup
#1. 伪造浏览器发送请求
r1 =requests.get(
url = "https://www.autohome.com.cn/news/"
)
r1.encoding="gbk"
print(r1.text)
#2.去响应 的响应体中解析我们想要的数据.
soup =BeautifulSoup(r1.text,"html.parser")
#3. 找名字按照响应的规则:div 标签且 id = auto -channel-lazyload-article找匹配成功的第一个
container =soup.find(name="div",attrs={"id":"auto-channel-lazyload-article"})
#4.去container中找所有的li标签
li_list =container.find_all(name ="li")
for tag in li_list:
title =tag.find(name ="h3")
if not title:
continue
summary =tag.find(name="p")
a =tag.find(name="a")
url ="https:"+a.attrs.get("href")
img= tag.find(name="img")
img_url= "https:"+img.get("src")
print(title.text)
print(summary.text)
print(url)
print((img_url))
#下载图片
r2 =requests.get(
url=img_url
)
file_name =img_url.rsplit("/",maxsplit=1)[1]
file_path=os.path.join("imgs",file_name)
with open(file_path,"wb")as f:
f.write(r2.content)
"""
作业:
1. 爬取抽屉新热榜的新闻:
标题
简介
地址
图片
2. 煎蛋网
- 爬取标题+简介
- 爬取图片
"""
import requests
from bs4 import BeautifulSoup
#1. 伪造浏览器发送请求
r1 =requests.get(
url="https://dig.chouti.com",
headers={
"user-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36"
}
)
#2.去响应的响应体重解析我们想要的数据
soup =BeautifulSoup(r1.text,"html.parser")
container = soup.find(name ="div",attrs={"id":"content-list"})
div_list = container.find_all(name ="div",attrs = {"class":"part1"})
# 1 拿到标题
# for item in div_list:
# title = item.find(name ="a")
# title =title.text
# title =title.strip()
# print(title)
#2 拿到简介
# div_list = container.find_all(name ="div",attrs = {"class":"area-summary"})
# for item in div_list:
# summary = item.find(name ="span",attrs ={"class":"summary"})
# print(summary,type(summary))
#3.拿到地址:
# for item in div_list:
# tag =item.find(name ="a",attrs = {"class":"show-content color-chag"})
# url=tag.attrs.get("href")
# print(url)
#4. 图片.
div_item =container.find_all(name ="div",attrs ={"class":"item"})
for item in div_item:
div_pic = item.find(name="div", attrs={"class": "news-pic"})
print(div_pic)
pic =div_pic.find("img")
img_url ="https://"+pic.get("original") #图片的url
print(img_url)
二 、煎蛋网爬虫
import requests
from bs4 import BeautifulSoup
r1 =requests.get(
url ="http://jandan.net"
)
soup =BeautifulSoup(r1.text,"html.parser")
container = soup.find(name ="div",attrs={"id":"content"})
div_list = container.find_all( name ="div",attrs={"class": "post f list-post"})
#1 打印出所有的标题.
# for item in div_list:
# div_index =item.find(name ="div",attrs ={"class":"indexs"})
# title = div_index.find(name ="h2")
# title =title.find(name="a")
# print(title.text)
#2 .打印出所有的简介.
for item in div_list:
div_index =item.find(name ="div",attrs ={"class":"indexs"})
# print(len(div_index.contents))
print(div_index.contents[6])#共计7个长度,标签之间空格也算一个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号