

1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
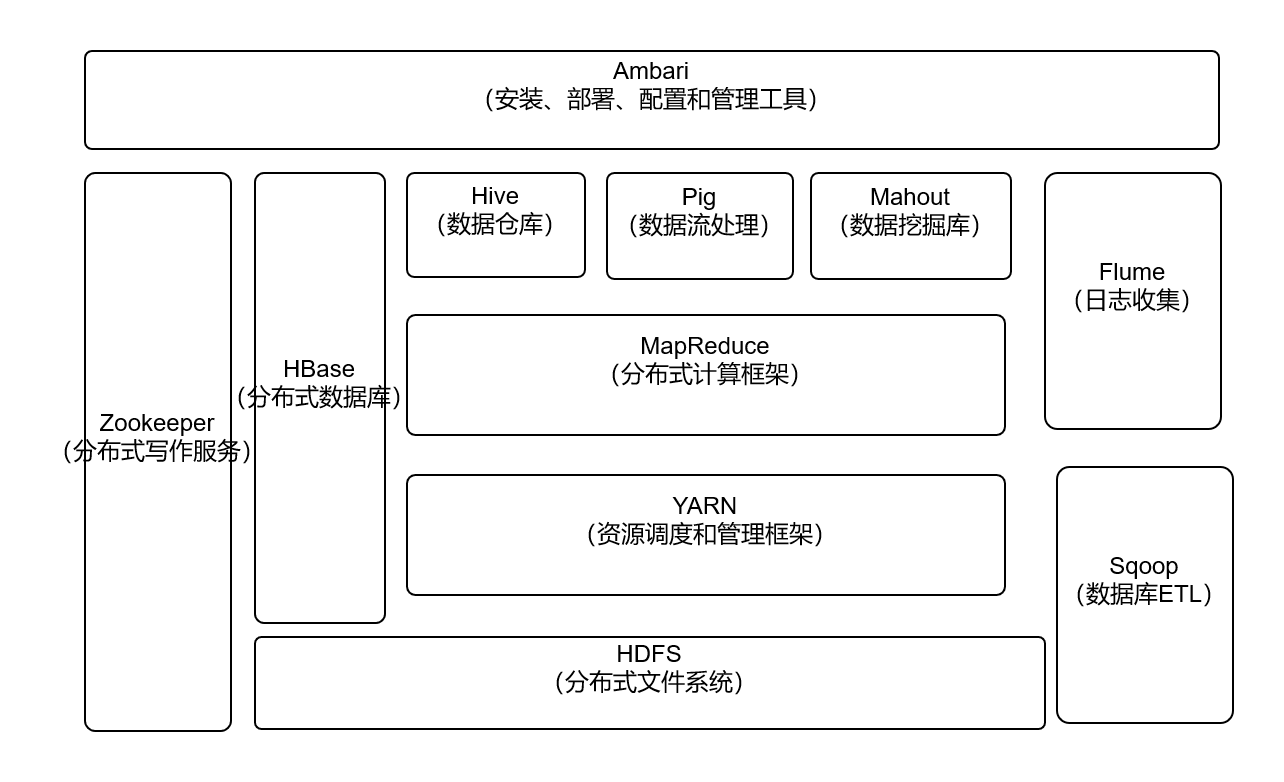
(1)HDFS分布式文件系统
HDFS可以兼容廉价的硬件设备,利用较低成本的及其实现大流量和大数据量的读写。
(2)MapReduce
MapReduce是分布式并行编程模型,用户大规模数据集的并行计算,让不会分布式并行编程的技术人员,也可以将程序运行在分布式系统上,实现海量数据集的计算。
(3)YARN
YARN是集群资源调度管理的组件,在YARN之上部署其他计算框架,由YARN统一进行资源分配。
(4)HBase
HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行元素和数百万列元素组成的数据表
(5)Hive
对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
(6)Flume
Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方的能力。
(7)Sqoop
用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
2.对比Hadoop与Spark的优缺点。
(1)性能
Spark在内存中处理数据相比于Hadoop使用磁盘io进行操作速度更快
(2)易用性
Spark支持Scala、Java、Python、Spark SQL等语言等,Spark可以使用交互模式操作获得实时反馈。
MapReduce没有交互模式。
(3)成本
Spark在数据多大PB的情况下依然有非常高的处理速度。被用于在数量只有十分之一的机器上,对100TB数据进行排序的速度比Hadoop MapReduce快3倍。
(4)兼容性
MapReduce和Spark相互兼容;MapReduce通过JDBC和ODC兼容诸多数据源、文件格式和商业智能工具,Spark具有与MapReduce同样的兼容性。
3.如何实现Hadoop与Spark的统一部署?
不同的计算框架统一运行在YARn之上,由YARN进行资源调度和管理,计算资源按需伸缩,不需要负载应用混搭,提高集群利用率,共享底层存储,避免数据跨集群迁移。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号