通道注意力模块——SENet(CVPR2018)
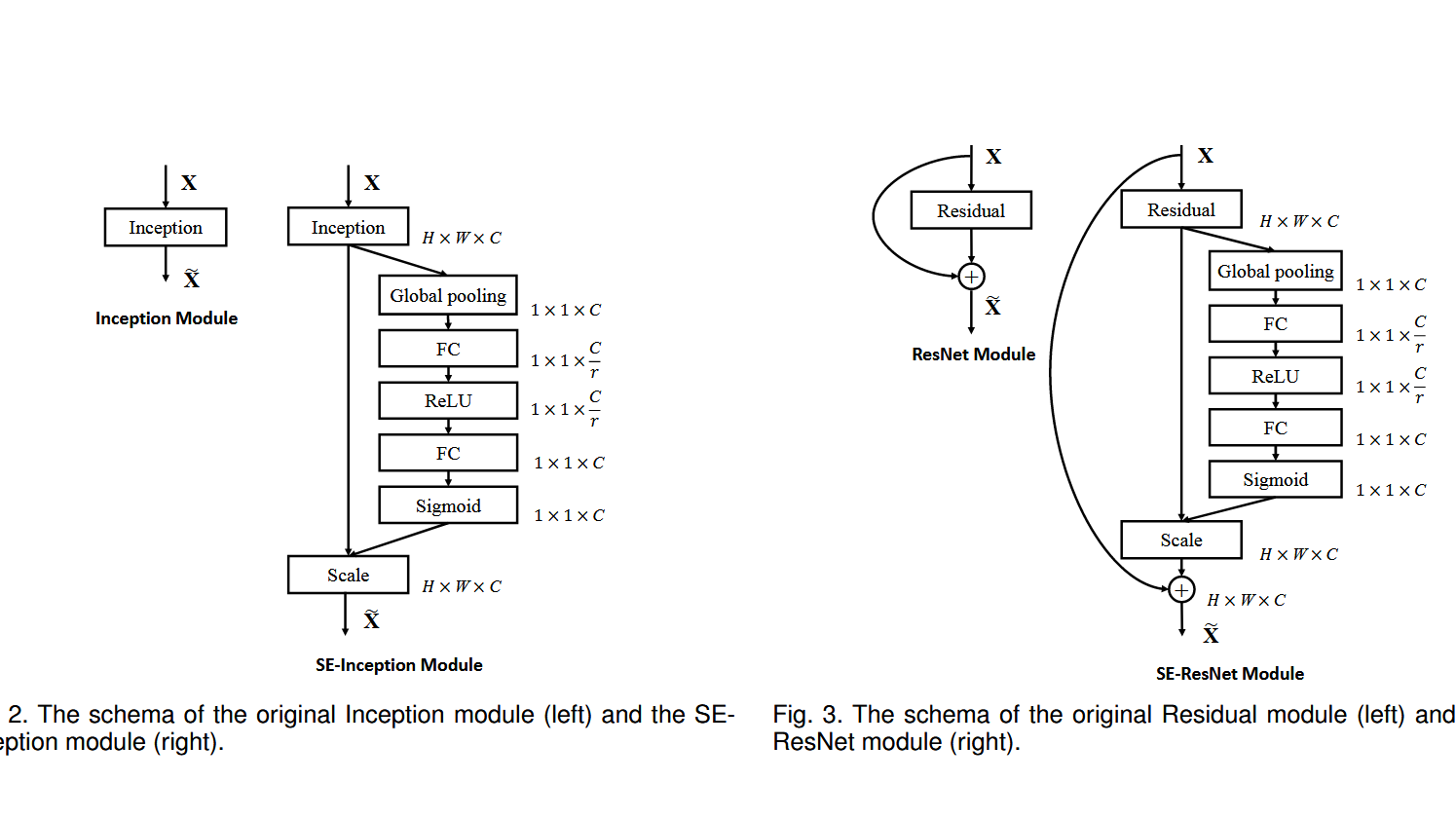 特征图中的不同通道(channel)代表不同的对象,通道注意力显式建模通道之间的相互依赖性,通过网络自适应学习每个通道的重要程度,并为每个通道赋予不同的权重系数,从而来强化重要的特征,抑制非重要的特征。
特征图中的不同通道(channel)代表不同的对象,通道注意力显式建模通道之间的相互依赖性,通过网络自适应学习每个通道的重要程度,并为每个通道赋予不同的权重系数,从而来强化重要的特征,抑制非重要的特征。
Squeeze-and-Excitation Networks:深度学习中的通道注意力范式
基本信息
-
标题:Squeeze-and-Excitation Networks (SENet)\(_{[1]}\)
-
作者与机构:
- 胡杰、吴恩华(中国科学院软件研究所,国家重点实验室;中国科学院大学;Momenta公司;澳门大学人工智能中心)
- 孙刚(中科院自动化所 LIAMA-NLPR;Momenta公司)
-
发表会议:CVPR 2019(arXiv 预印本发布于 2017年)
-
论文链接:arXiv:1709.01507
核心贡献与创新点
一句话核心思想:提出 Squeeze-and-Excitation (SE) 模块,通过自适应建模通道间依赖关系,动态重校准特征通道权重,显著提升卷积神经网络 (CNN) 表达能力。
主要创新点
- 通道注意力建模:区别于传统 CNN 仅关注空间特征融合,SE 模块首次引入通道间动态建模机制。
- 计算高效:极小的参数和计算开销(约 1% 额外 FLOPs)即可显著提升主流架构(如 ResNet\(_{[3]}\)、Inception \(_{[4]}\))性能。
- 广泛适用性:可灵活嵌入多种 CNN 架构,在分类、检测、分割等任务中广泛验证有效性。
SE 模块详解
SENet 设计了两个关键操作:Squeeze 和 Excitation,在特征图上进行动态加权:
1️⃣ Squeeze(特征压缩)
利用全局平均池化提取每个通道的全局信息,消除空间维度,捕获整体语义上下文:
- 输入:通道特征图 \(u_c \in \mathbb{R}^{H \times W}\)
- 输出:压缩向量 \(z \in \mathbb{R}^{C}\)
2️⃣ Excitation(特征激励)
通过瓶颈式全连接网络建模通道依赖性,生成每个通道的注意力权重:
- \(W_1 \in \mathbb{R}^{C/r \times C}\): 降维层(默认缩减比 \(r=16\))
- \(W_2 \in \mathbb{R}^{C \times C/r}\): 升维层
- \(\delta\): ReLU 激活函数
- \(\sigma\): Sigmoid 激活函数
3️⃣ 重标定(通道加权)
最终将学到的通道权重向量 \(s\) 应用于输入特征图:
通过逐通道缩放实现特征强化与抑制。
PyTorch 代码示例
import torch.nn as nn
class SEBlock(nn.Module):
def __init__(self, c, ratio = 16):
super(SEBlock, self).__init__()
# squeeze layer
# 全局平均池化(Global Average Pooling, GAP)可以通过 nn.AdaptiveAvgPool2d(1) 实现。这样可以将任意尺寸的特征图池化为每个通道1×1的输出。
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# excitation layer
self.fc = nn.Sequential(
nn.Linear(c, c // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c // ratio, c, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size() # batch size, channels, height, width
y = self.avg_pool(x).view(b, c) # squeeze operation
y = self.fc(y).view(b, c, 1, 1) # 将全连接层输出的通道权重调整为适合与原始特征逐通道相乘的形状
return x * y.expand_as(x)
# 测试
if __name__ == "__main__":
import torch
se_block = SEBlock(64)
x = torch.randn(1, 64, 32, 32) # batch size of 1, 64 channels, 32x32 feature map
print("输入形状:", x.shape)
output = se_block(x)
print("输出形状",output.shape) # should be the same shape as input: (1, 64, 32, 32)
输出结果为:

关键实验与消融分析
消融实验亮点
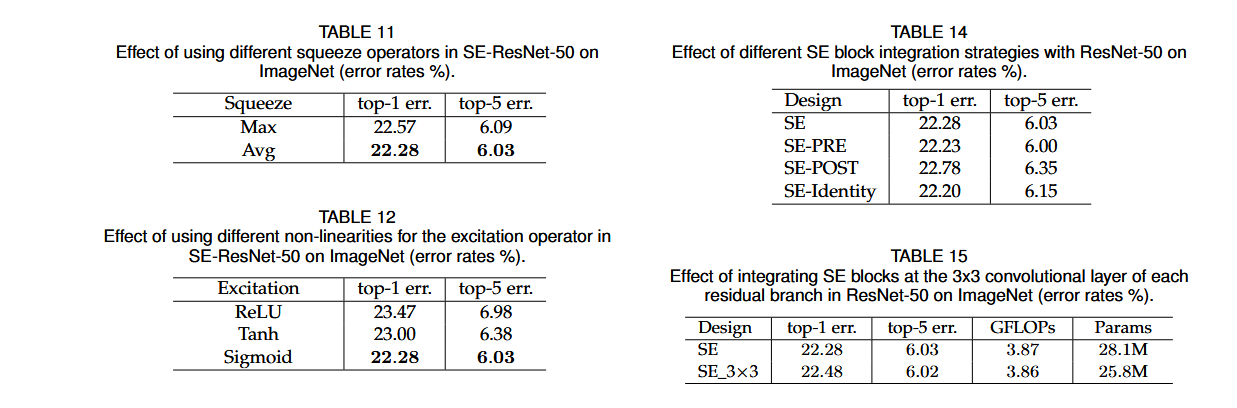
- 激活函数分析:
- 使用 ReLU 作为 Excitation 激活函数导致性能严重下降。
- 采用 Tanh 可缓解信息截断,但 Sigmoid 效果最佳。其原因在于:
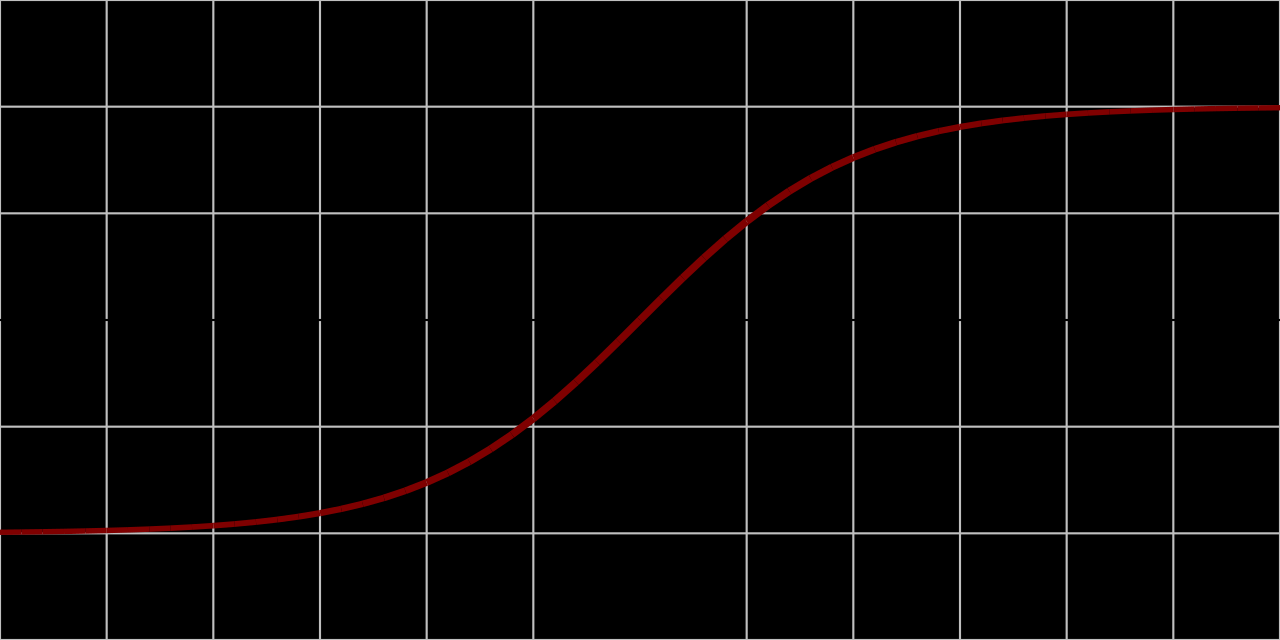
- ReLU 直接丢弃负值,破坏通道之间的细粒度相互依赖;
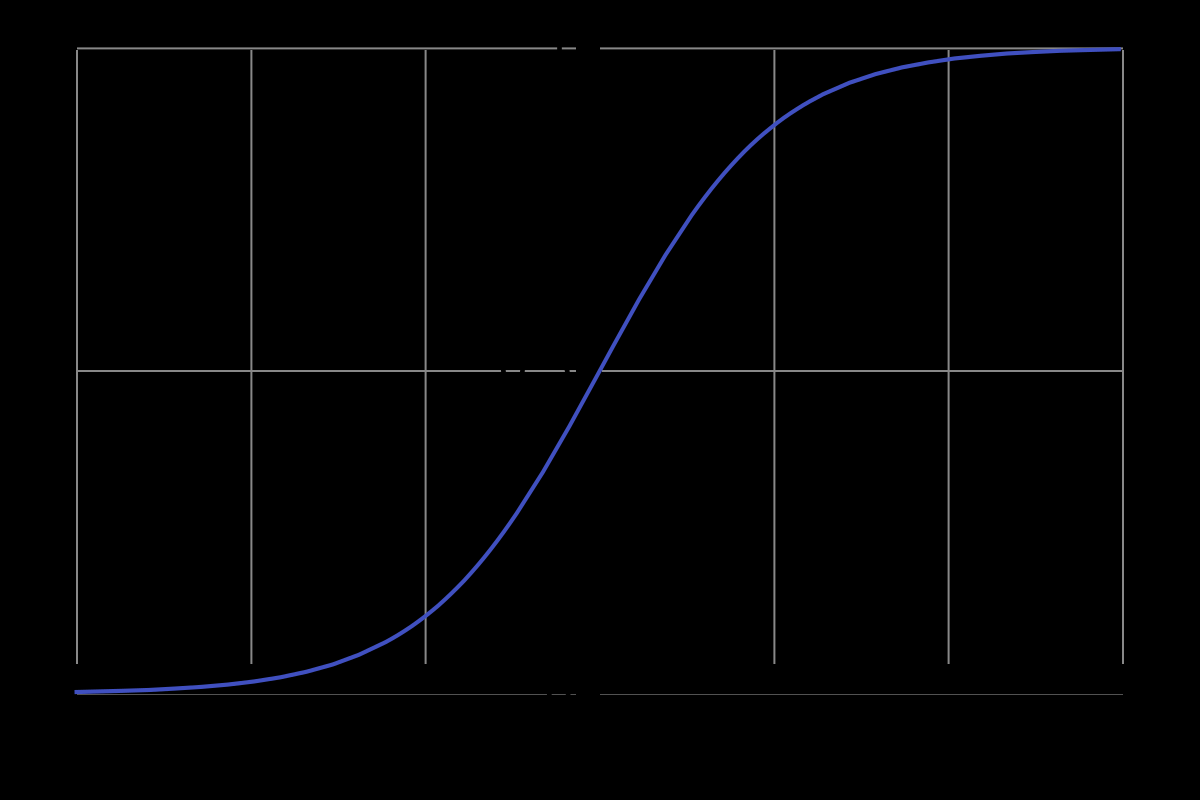
- Sigmoid 保持非互斥性与连续性,允许柔性调节通道重要性。
- ReLU 直接丢弃负值,破坏通道之间的细粒度相互依赖;
- 使用 ReLU 作为 Excitation 激活函数导致性能严重下降。
引申案例:MobileNetV3\(_{[2]}\) 中引入\(h-swish\) 激活函数,有效在轻量网络中保留更多负值信息,验证了非线性激活与注意力模块深度耦合的重要性。
计算复杂度建模
SENet 模块额外计算复杂度为:
其中:
- \(S\):阶段数(如 ResNet 中 4 个 stage)
- \(N_s\):第 s 阶段内 SE 模块数
- \(C_s\):第 s 阶段特征通道数
- \(r\):缩减比例(全局超参数)
相较标准卷积层的计算成本,SE 模块引入的开销极为有限。
性能表现
使用的数据集以及评价指标
| 数据集 | 任务 | 数据规模 | 评价指标 | 备注 |
|---|---|---|---|---|
| ImageNet (ILSVRC 2012) | 图像分类 | 1000类, 1.28M训练图像, 50K验证图像 | Top-1 Error (%) Top-5 Error (%) |
核心实验,几乎所有主结果均来自此数据集 |
| CIFAR-10 | 图像分类 | 10类, 50K训练图像, 10K测试图像 | Classification Error (%) | 轻量级验证SE模块泛化能力 |
| CIFAR-100 | 图像分类 | 100类, 50K训练图像, 10K测试图像 | Classification Error (%) | 验证SE模块在细粒度分类中的表现 |
| ImageNet 5K (扩展实验) | 图像分类 | 5000类,扩展版本 | Top-1 Error (%) Top-5 Error (%) |
检验SE模块可扩展性,非核心实验 |
| Places365 | 场景分类 | 365类, 1.8M训练图像 | Top-1 Error (%) Top-5 Error (%) |
迁移学习任务,评估泛化能力 |
| COCO Detection (MS COCO) | 目标检测 | 80类, 118K训练图像 | mAP (Mean Average Precision) | 在目标检测任务中集成SE模块的效果 |
| PASCAL VOC Detection | 目标检测 | 20类 | mAP | 补充验证检测任务泛化能力 |
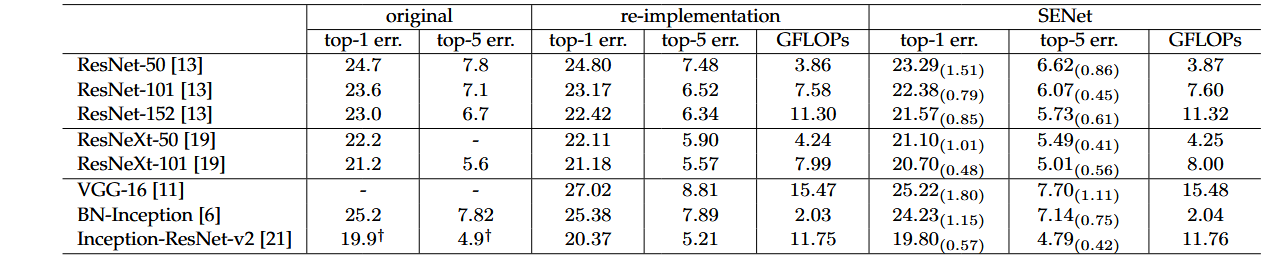
在 ImageNet ILSVRC 2012 上的主要表现
典型应用场景
- 图像分类、目标检测、语义分割
- 嵌入轻量级架构(如 MobileNetV3\(_{[2]}\))
- 资源受限场景下提升模型判别能力
延伸与未来方向
激活函数优化
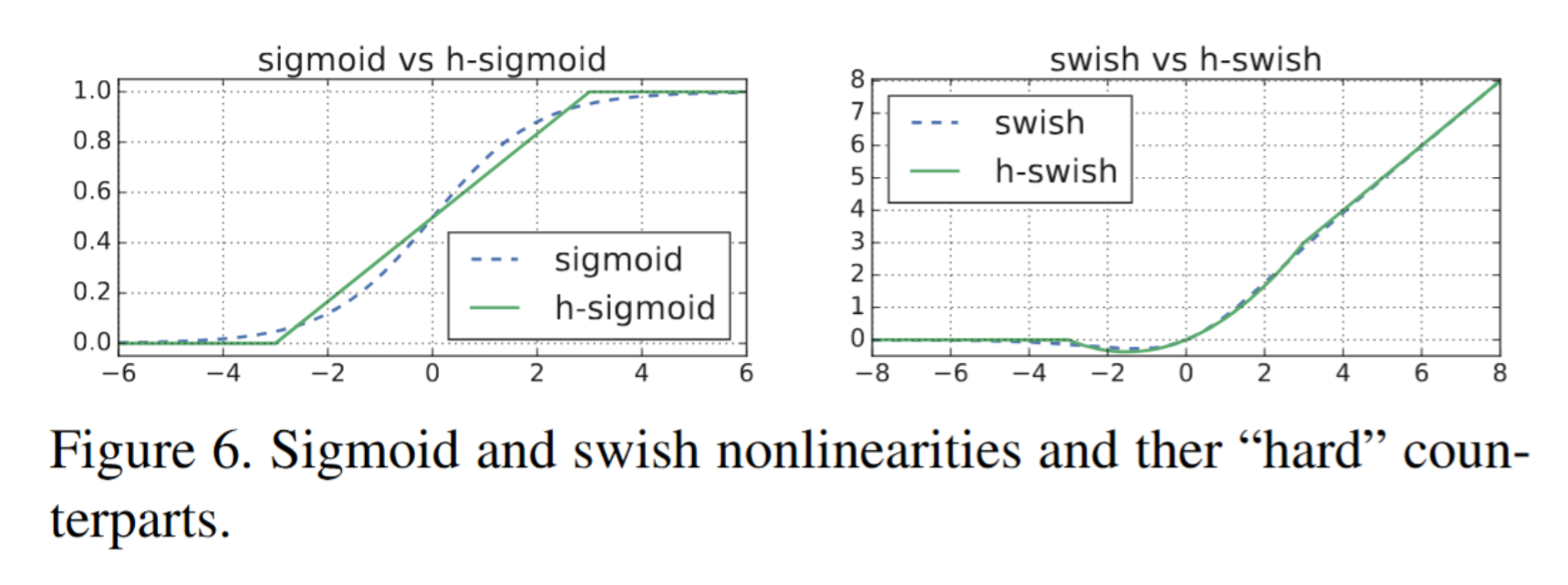
- h-swish(MobileNetV3\(_{[2]}\)):在轻量网络中缓解负值信息丢失问题;
- 探索平滑激活与自适应门控机制融合。
结构精简与动态扩展
- 动态缩减比例 \(r\):防止深层网络过度压缩;
- 多尺度通道建模(如 NSENet 分层注意力)。
跨任务迁移
- 与 Transformer 融合形成通道-空间双维度注意力(如 SANet);
- 强化小样本学习中的关键特征建模与噪声抑制。
理论与实践价值
- 奠定通道注意力范式基石,衍生出 CBAM\(_{[5]}\)、ECA\(_{[6]}\) 等高效注意力模块;
- NAS 搜索框架中自动学习 SE 模块嵌入位置,提升资源利用效率。
⭐改进方向:
- 文中采用了串行和并行接入的方式,在自己的模型中可以考虑串行、并行、交叉等方式接入。
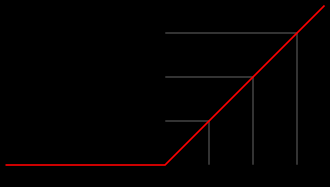
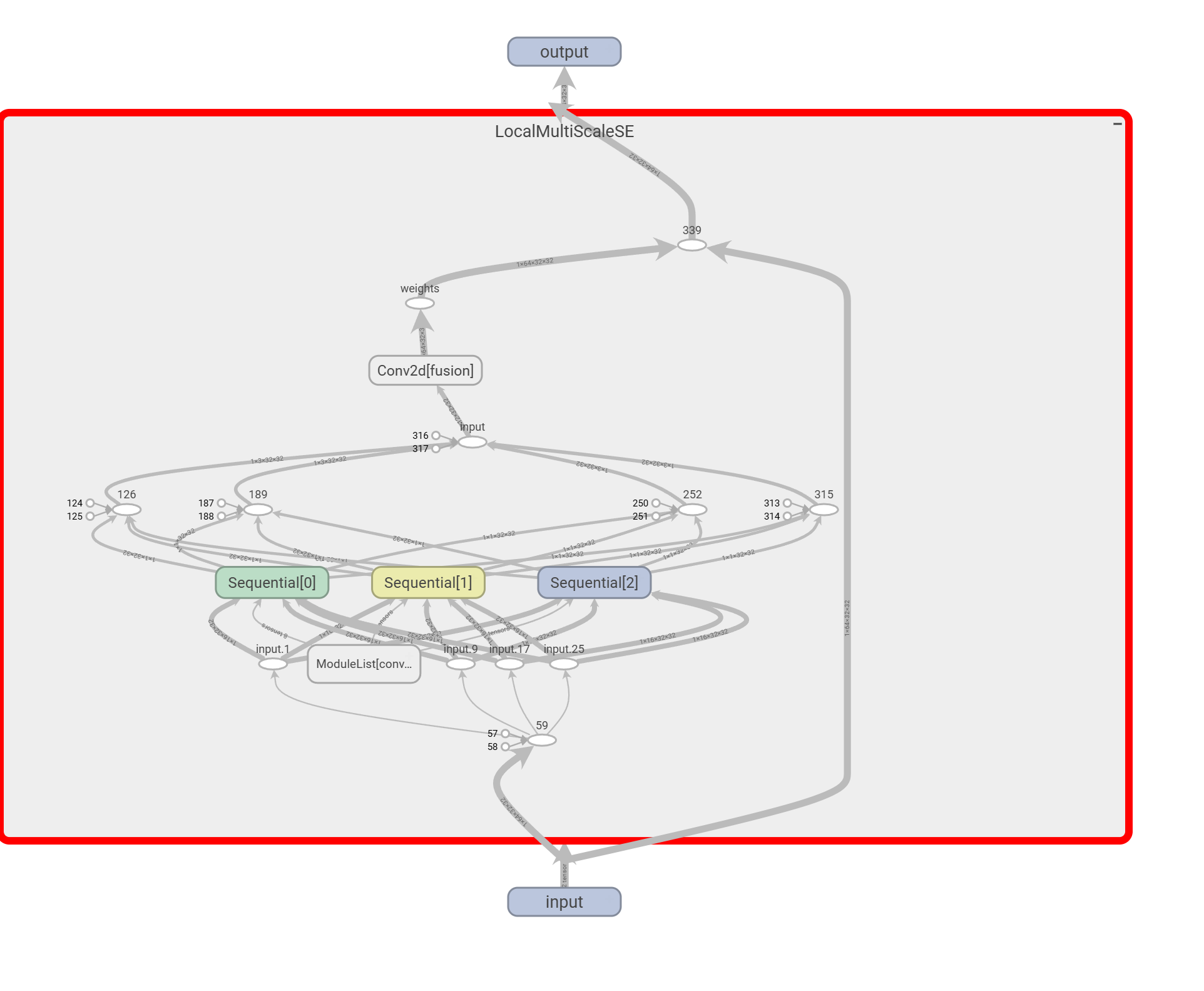
- 激励模块中的瓶颈结构通过两层MLP执行先降维后升维的操作,旨在学习通道间相关性。鉴于并非所有通道信息都具有同等重要性,尝试提出在通道层面采用多尺度特征提取机制,实现对关键通道的选择性增强。下面是一个例子:
总结
Squeeze-and-Excitation Networks 通过极简有效的通道加权机制,在神经网络架构设计中引入了动态特征重标定思想,深刻影响了后续注意力机制与轻量化网络的发展趋势。未来,SE 模块理念仍将在多模态融合、自监督预训练、小样本学习等领域发挥关键作用。
参考文献
[1] J. Hu, L. Shen, and G. Sun, “Squeeze-and-Excitation Networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7132–7141. DOI: 10.1109/CVPR.2018.00745.
[2] A. Howard et al., “Searching for MobileNetV3,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1314–1324. DOI: 10.1109/ICCV.2019.00140.
[3] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778. DOI: 10.1109/CVPR.2016.90.
[5] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “CBAM: Convolutional Block Attention Module,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 3–19. DOI: 10.1007/978-3-030-01234-2_1.
[6] Wang, Qilong, et al. "ECA-Net: Efficient channel attention for deep convolutional neural networks." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
附录(公式详细推导)
1. SE 模块核心思想回顾
目标:在 CNN 中动态建模通道之间的相关性,通过学习自适应的通道权重,对每个通道的重要性进行加权调整,从而提升网络的表达能力。
SE 模块包括三个步骤:
- Squeeze(特征压缩)
- Excitation(特征激励)
- Scale(通道重标定)
2. 公式推导与说明
2.1 Squeeze 阶段公式推导
公式:
背景说明:
-
输入:中间卷积层输出的特征图 \(\mathbf{U} \in \mathbb{R}^{C \times H \times W}\),其中:
- \(C\) 表示通道数
- \(H\)、\(W\) 分别是特征图的高和宽
-
目的:通过全局平均池化(Global Average Pooling, GAP)将每个通道的二维空间特征压缩成一个单一标量,捕获该通道的全局语义。
推导:
对于第 \(c\) 个通道的特征图 \(u_c \in \mathbb{R}^{H \times W}\),其全局平均池化结果为:
即,
- 该操作的结果是一个长度为 \(C\) 的向量 \(\mathbf{z} \in \mathbb{R}^{C}\),代表了每个通道的全局特征统计。
理解:
- GAP 作为信息瓶颈,有效地去除了空间维度,仅保留通道层次的全局上下文信息,为后续建模通道依赖关系奠定基础。
2.2 Excitation 阶段公式推导
公式:
背景说明:
- 目的:通过自适应门控机制学习通道间的非线性依赖关系,生成每个通道的重要性权重。
- 核心结构:两层全连接(Fully Connected, FC)神经网络构成的瓶颈结构。
推导分步:
(1) 降维(压缩信息冗余)
首先将输入向量 \(z\) 经过第一层全连接层 \(W_1 \in \mathbb{R}^{C/r \times C}\) 进行降维:
其中 \(r\) 是缩减比例(典型值为 16),防止过拟合与计算冗余,同时保留通道间关联性抽象信息。
(2) 非线性激活
随后经过 ReLU 非线性激活函数:
以增加模型对复杂通道间非线性关系的拟合能力。
(3) 升维(恢复原始维度)
经过第二层全连接层 \(W_2 \in \mathbb{R}^{C \times C/r}\) 将特征重新投影回原始通道空间:
(4) Sigmoid 激活(映射至权重区间)
最终通过 Sigmoid 函数限制权重在 \((0, 1)\) 区间内:
获得最终通道权重向量 \(s \in \mathbb{R}^{C}\)。
理解:
- 降维-升维的瓶颈结构能在低维空间建模冗余特征间的复杂交互;
- Sigmoid 保证了权重连续且可微,便于训练。
2.3 Scale 阶段公式推导(特征重标定)
公式:
背景说明:
- 目的:依据学习得到的通道权重 \(s_c\) 对每个通道的特征图逐通道地重新加权,强化有用特征,抑制无关信息。
推导:
对于每个通道 \(c\),直接对原始特征图逐元素乘上对应的标量权重:
也即逐通道乘法(channel-wise multiplication),实现通道重要性动态调节。
3. SE 模块整体数学模型
综合以上三步,可将整个 SE 模块表示为如下整体函数:
其中:
- \(F_{squeeze}\): 全局平均池化
- \(F_{excite}\): 瓶颈全连接子网络
- \(F_{scale}\): 通道加权操作
4. 计算复杂度分析公式推导
额外参数开销:
SE 模块的参数主要来自两个全连接层:
其中:
- 第一层降维 FC 层参数:\(C \times \frac{C}{r}\)
- 第二层升维 FC 层参数:\(\frac{C}{r} \times C\)
额外计算量:
考虑整个网络所有 stage,总开销为:
- \(S\):stage 数
- \(N_s\):第 \(s\) 个 stage 中的 SE 模块数量
- \(C_s\):第 \(s\) 个 stage 的通道数
结论:
由于 \(\frac{2}{r} \ll 1\),整体计算开销相较标准卷积非常小,但性能提升显著。
5. 重要延伸思考
为什么使用 Sigmoid 而非 ReLU?
- ReLU 会截断负值,导致部分通道权重恒为零;
- Sigmoid 保证了每个通道都有柔性调节空间(权重在 \((0,1)\) 之间),符合注意力机制连续调节的需求;
- h-swish 进一步在轻量模型中优化了激活信息流动性(MobileNetV3\(_{[2]}\) 的贡献之一)。
本文来自博客园,作者:迪杰Tesla,转载请注明原文链接:https://www.cnblogs.com/medcs/p/18926383

 浙公网安备 33010602011771号
浙公网安备 33010602011771号