2024秋软工实践第10组团队展示与选题报告
| 作业所属课程 | 软件工程2024 |
|---|---|
| 作业要求 | 2024秋软工实践团队作业-第一次 |
| 作业目标 | 分析需求、确定所实现的功能、对整体任务进行规划 |
| 团队名称 | 不是草台班子 |
| 团队成员学号 | 姓名 |
|---|---|
| 102201427 | 侯丽珂 |
| 102201426 | 郑嘉祺 |
| 102201241 | 戴康怡 |
| 102201218 | 肖晗涵 |
| 112200328 | 谢李东 |
| 292300304 | 陈鹭 |
| 102201242 | 魏儀阳 |
| 082100170 | 朱胤帆 |
| 112200629 | 赵弈茗 |
| 102202132 | 郑冰智 |
团队展示
队名:当然不是草台班子
- 寓意:不是草台班子
团队项目的具体规划及描述
-
集中发表意见,确认选题
- 目标:通过团队讨论,确定项目的核心目标和方向,即开发一个接入大语言模型的Web翻译系统。
- 步骤:
- 团队成员各自提出项目设想和想法。
- 通过头脑风暴,整理出多个潜在的选题方向。
- 通过投票或讨论,确定最终的选题。
-
对所设想功能进行补充、完善架构
- 目标:明确系统的核心功能和架构设计,包括大语言模型的接入、翻译功能、润色功能等。
- 步骤:
- 列出初步的功能列表。
- 讨论每个功能的实现方式和技术可行性。
- 设计系统的整体架构图,包括前端、后端、数据库和API接口等。
-
明确各自分工、技术选型
- 目标:确定每个团队成员的具体任务,选择合适的技术栈。
- 步骤:
- 根据团队成员的技能和兴趣,分配前端、后端、数据库、API开发等任务。
- 讨论和选择合适的技术框架,如前端框架(React、Vue等)、后端框架(Node.js、Django等)、数据库(MySQL、MongoDB等)、大语言模型API(如OpenAI、GPT-4等)。
- 确定沟通工具和文档管理工具,如Slack、Trello、GitHub等。
-
完成原型
- 目标:开发一个初步的系统原型,展示核心功能和界面设计。
- 步骤:
- 设计原型的用户界面(UI)和用户体验(UX)。
- 实现核心功能的原型代码,包括基本的翻译功能和大语言模型的接入。
- 进行初步的测试,验证原型的可行性。
-
分组进行各项功能的实现
- 目标:根据原型,进一步完善和优化前端和后端的功能。
- 步骤:
- 前端团队专注于用户界面的美观和用户交互的优化,确保系统的易用性。
- 后端团队专注于系统性能的优化,确保翻译功能和大语言模型的流畅运行。
- 定期进行代码审查和集成测试,确保前后端的协同工作。
队员风采
队员详情
1. 侯丽珂
- 学号:102201427
- 性格:顶i
- 擅长方面:规划、整理
- 不擅长方面:写代码(这是计算机学子可以说的吗)
- 兴趣爱好:听歌(三无Marblue七年老狂粉)、写作(马甲当然是不能扒的)、看电影动漫(MyGo请看,赛马娘请看,转天请看)
- 软工角色:产品设计
- 期待与建议:希望自己能顺利把这个项目捋完,希望大家好好相处别打架(bushi)、按时完成各自任务,积极沟通。
2. 郑嘉祺
- 学号:102201426
- 性格:情绪稳定
- 擅长方面:不清楚
- 不擅长方面:不清楚
- 兴趣爱好:睡觉
- 软工角色:前端(主)、测试(协助)
- 期待与建议:希望能一起完成一个项目,在实践中成长。
3. 戴康怡
- 学号:102201241
- 性格:是个i人但是在别人眼里好像是e?
- 擅长方面:前端、产品设计
- 不擅长方面:后端
- 兴趣爱好:吃饭、睡觉
- 软工角色:前端(主)、产品设计(协助)
- 期待与建议:加油干!!
4. 肖晗涵
- 学号:102201218
- 性格:时而积极时而懒惰(超i)
- 擅长方面:临时抱佛脚(bushi)
- 不擅长方面:都不太擅长,但是可以学!
- 兴趣爱好:看小说、听歌
- 软工角色:前端
- 期待与建议:希望每个人都能在团队中充分展现自己的能力,齐心协力完成任务!
5. 谢李东
- 学号:112200328
- 性格:e人,无脑程序猿;
- 擅长方面:貌似没有什么很擅长的;
- 不擅长方面:对于程序界面设计还有比较多的问题;
- 兴趣爱好:骑车、羽毛球
- 软工角色:后端
- 期待与建议:希望明确给我的分工就好了!
6. 陈鹭
- 学号:292300304
- 性格:比较安静
- 擅长方面:目前还有很多还在学习,较为擅长的是Python
- 不擅长方面:其他语言的程序设计,已经一些技术软件和接口的使用(那些还没学[表情])
- 兴趣爱好:看书、听音乐
- 软工角色:前端
- 期待与建议:希望能在团队中学到更多的知识,为大家做一些贡献。
7. 魏儀阳
- 学号:102201242
- 性格:内向
- 擅长方面:无
- 不擅长方面:全都不擅长
- 软工角色:后端
- 期待与建议:期待好消息,做自己力所能及的事就好。
8. 朱胤帆
- 学号:082100170
- 性格:幽默?
- 擅长方面:后端、运维
- 不擅长方面:前端
- 兴趣爱好:玩游戏
- 软工角色:运维测试(主)、后端(协助)
- 期待与建议:能够学习一下前后端分工合作,上线一个完整产品的完整流程。
9. 赵弈茗
- 学号:112200629
- 性格:i人、友善
- 擅长方面:会一点qt、微信小程序开发、人工智能
- 不擅长方面:不擅长前后端接口对接
- 兴趣爱好:羽毛球、桌游
- 软工角色:后端
- 期待与建议:希望能完整地做完项目,提升能力。
10. 郑冰智
- 学号:102202132
- 性格:典型的I型人格
- 擅长方面:小程序前端设计、性能测试、安全测试
- 不擅长方面:后端架构设计,数据库优化
- 兴趣爱好:旅行、阅读、音乐
- 软工角色:测试(主)、前端(协助)
- 期待与建议:
- 期待:对web的前端开发没有太多了解,但体验过小程序的前端开发,期待能在此过程中提升自己的开发技能。也希望能够在测试环节中,发现并解决更多潜在问题,为产品质量保驾护航。
- 建议:建议团队在项目初期就明确分工,并进行有效的沟通,确保每个人都了解自己的职责和目标。
成员信息汇总表
| 学号 | 昵称/姓名 | 性格 | 擅长方面 | 不擅长方面 | 兴趣爱好 | 软工角色 | 熟练语言 | 熟练的LLM接口 | 对团队的期待与建议 |
|---|---|---|---|---|---|---|---|---|---|
| 102201427 | 侯丽珂 | 顶i | 规划整理 | 不擅长写代码 | 听歌、写作、看电影看动漫 | 产品设计 | Python, C | OpenAI GPT-3/4, 文心一言 | 希望顺利完成项目,团队和睦,按时完成任务 |
| 102201426 | 郑嘉祺 | 情绪稳定 | 不清楚 | 不清楚 | 睡觉 | 前端(主) 测试(协助) | C, C++, Python | 无 | 希望在实践中成长,完成项目 |
| 102201241 | 戴康怡 | i人但在别人眼里像e | 前端,产品设计 | 后端 | 吃饭,睡觉 | 前端(主) 产品设计(协助) | C | GPT | 加油干! |
| 102201218 | 肖晗涵 | 时而积极时而懒惰(超i) | 临时抱佛脚(bushi) | 不太擅长,但可以学 | 看小说、听歌 | 前端 | C, 前端三件套, JavaScript | 文心一言,kimi | 希望每个人都充分展现能力,齐心协力完成任务 |
| 112200328 | 谢李东 | e人,无脑程序猿 | 貌似没有什么很擅长的 | 对于程序界面设计还有比较多的问题 | 骑车,羽毛球 | 后端 | Python | 文心一言,ChatGPT | 明确分工即可 |
| 292300304 | 陈鹭 | 安静 | Python | 其他语言,技术软件和接口的使用 | 看书、听音乐 | 前端 | Python | 无 | 希望能为团队贡献力量,学到更多 |
| 102201242 | 魏儀阳 | 内向 | 无 | 全都不擅长 | 玩 | 后端 | 无 | 无 | 做自己力所能及的事 |
| 082100170 | 朱胤帆 | 幽默 | 后端,运维 | 前端 | 玩游戏 | 运维测试(主) 后端(协助) | Golang, Shell | GPT | 希望学习前后端合作,上线完整产品 |
| 112200629 | 赵弈茗 | i人,友善 | Qt,微信小程序开发,人工智能 | 前后端接口对接 | 羽毛球、桌游 | 后端 | Python, C++ | 无 | 希望提升能力,完整做完项目 |
| 102202132 | 郑冰智 | 典型的I型人格 | 小程序前端设计、性能测试、安全测试 | 后端架构设计,数据库优化 | 旅行、阅读、音乐 | 测试(主) 前端(协助) | Python | ChatGPT API | 希望提升开发技能,发现并解决潜在问题,团队分工明确,沟通有效 |
团队愿景
尺有所短寸有所长,每个人都有自己擅长的方面,希望在团队合作中能将每个人的优势都发挥出来。此外,团队合作中难免会有想法和意见上的摩擦,并且我们来自不同的专业,空闲时间也因课程而有所出入,积极且有效的沟通是解决这些矛盾的最优解,希望未来一段时间内合作愉快!而更远的未来,也能因这一次合作相连。
选题报告
1. 引言
1.1. 项目背景
- 随着自然语言处理(NLP)技术的飞速发展,基于 LLM 的应用逐渐成为主流。这些模型(如 OpenAI 的 GPT、Google 的 PaLM 等)已经展示出强大的语言生成和理解能力,能够处理多语言的翻译任务。传统的翻译软件如 Google Translate 或 DeepL 虽然非常成熟,但依然有一些局限性,尤其是在复杂上下文、多义词、文化语境和口语化语言方面。
- 目前,OCR 技术在识别印刷或手写的文字时非常有用,尤其在翻译文档、书籍、图片中的文字信息时尤为重要。然而,现有的 OCR 翻译工具在电脑端的用户体验并不理想:
- 操作复杂:许多 OCR 工具需要用户进行多步操作,如手动截图、复制粘贴文字等,过程繁琐。
- 收费问题:例如,网易有道等一些主流翻译工具虽然提供了 OCR 识图功能,但大多数高质量的 OCR 识别和翻译服务需要收费。对于需要频繁使用 OCR 翻译的用户来说,这带来了经济负担。
- 翻译质量参差不齐:部分 OCR 工具对复杂文本的识别准确度不高,尤其是在处理多语言或不同字体、格式时,常常会导致识别错误,进而影响翻译质量。
- 基于上述传统翻译软件所存在的相关问题,本项目组决定开发一个基于 LLM 的更高质量的翻译工具——“云译网”。

1.2. 项目目的
开箱即用的高质量翻译工具
1.2.1. 优化用户体验
- 一键翻译:在网页端支持用户通过上传图片、PDF 或输入文本直接获取翻译结果,简化操作流程。
- 简洁的 Web 界面:提供一个直观、易用的 Web 用户界面,让用户可以轻松选择语言、上传文件、查看和复制翻译结果。
1.2.2. OCR 识别集成
- 高效 OCR 识别:在网页端实现图片或 PDF 中的文字识别功能,并自动与翻译模块对接,用户无需额外操作提取文字。
- 文本预览与编辑:提供识别出的文本预览,允许用户在翻译前进行手动修改或确认。
1.2.3. 高质量翻译
- 上下文翻译:通过 LLM 的上下文理解能力,为用户提供准确、自然的翻译结果,尤其在长文本或段落翻译中体现其优势。
- 多语言支持:支持多种常用语言的互译,包括但不限于英语、中文、西班牙语、法语、德语等。
1.2.4. 简化成本结构
- 免费:为用户提供一定额度的免费 OCR 识别和翻译服务,吸引更多用户使用。
1.2.5. 扩展性和后续支持
- 后续功能扩展:为未来版本预留扩展接口,便于在后期增加语音识别、实时翻译等功能。
- 用户反馈机制:集成反馈功能,让用户可以提交翻译问题或提出改进建议,从而优化翻译质量。
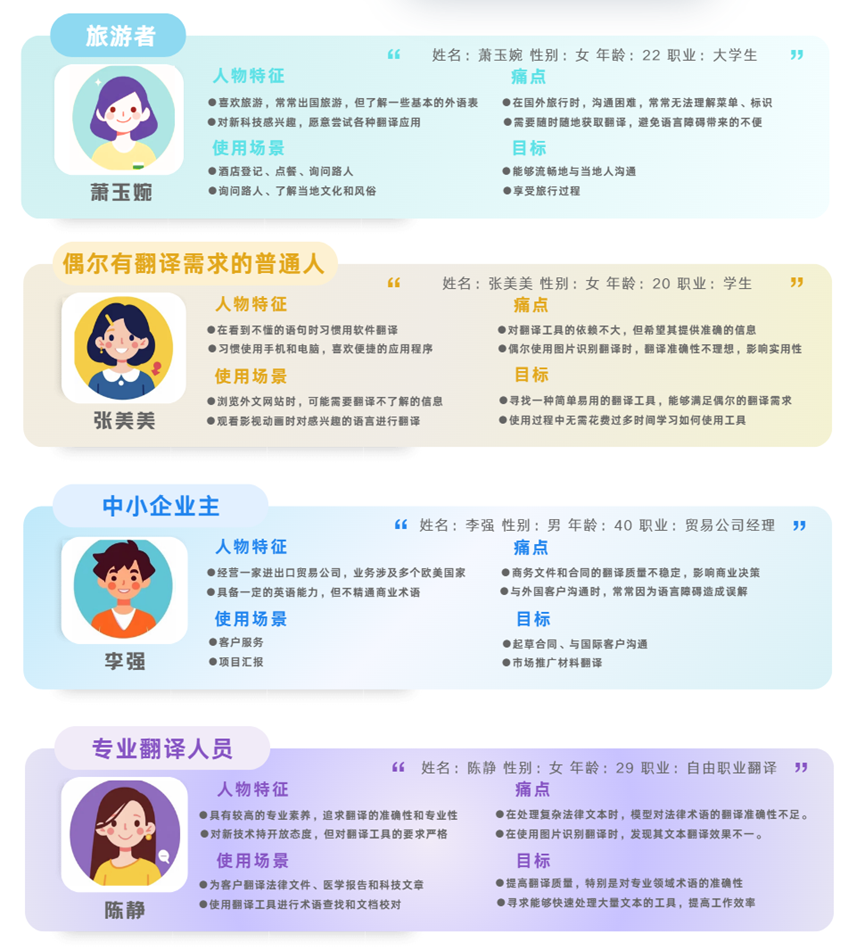
1.3. 用户画像
“云译网”所主要面向的用户主要是对翻译质量以及对翻译便捷度和速度要求较高的人群。主要提取了用户的四个方面的数据:人物特征、使用场景、痛点和目标。
2. 云译网需求分析
2.1. NABCD 模型
-
N (Need) - 需求
- 随着全球化的加速,准确、自然的语言翻译变得日益重要,尤其在商业、学术和个人交流中。
- 用户需要一种能够提供高质量、自然流畅的翻译工具,特别是在商业、学术、旅游和个人交流中。
-
A (Approach) - 方法
- 开发基于大语言模型(LLM)的智能翻译工具,利用深度学习和自然语言处理技术。
- 结合文本、语音和图片识别等多种输入方式,增强用户体验。
-
B (Benefits) - 好处
- 提供高质量、流畅自然的翻译服务,特别是在处理复杂句子和专业领域的术语时。
- 用户可以享受到个性化翻译服务,提高工作和学习效率。此外,实时翻译功能将极大地提升沟通的便捷性。
-
C (Competition) - 竞争
- 主要竞争对手包括 DeepL、Google Translate 等已建立的翻译工具。
- 需要通过创新的功能和更高的翻译质量来吸引用户。
-
D (Delivery) - 推广
- 制定有效的市场推广策略,吸引目标用户群体。
- 利用社交媒体、在线广告、合作伙伴关系等方式,提升品牌知名度和用户参与度。
- 提供试用或优惠活动,鼓励用户体验云译网的翻译服务,从而促进用户转化。
2.2. 功能描述
根据项目目标,云译网的功能可以分为以下几类:
2.2.1. 核心功能
- 高质量翻译服务:
- 利用 LLM 进行自然、流畅的翻译,避免逐字翻译导致的误解。
- 翻译内容拓展:
- 翻译内容即时传入LLM记录,翻译后即可对于相关内容,和大模型进行对话,可以极为方便的了解相关内容。
- 个性化翻译:
- 允许用户自定义翻译风格和专业术语翻译(如法律、医疗等)。
- 收集用户反馈,持续微调模型以提高翻译质量。
- 图片识别翻译:
- 支持图片文字翻译功能,以满足更广泛用户的多样化需求。
- 翻译质量检测:
- 提供对人工翻译的检测校验,便于翻译人员自测自己的学习成果。
2.2.2. 辅助功能
- 用户界面优化:
- 开发简洁直观的用户界面,方便用户快速输入和获取翻译。
- 提供文本、语音、图片文字识别等多种输入输出方式。
- 实时翻译与优化:
- 实现快速响应的实时翻译功能,使用缓存机制提高常见句子的响应速度。
- 优化后端系统以减少计算资源消耗。
- 未来功能拓展:
- 提供 API 服务,便于其他应用程序或平台集成翻译功能。
- 支持语音翻译,以满足更多用户需求。
- 团队协作翻译,支持团队在同一文档内同时翻译,利于需要团队协作的大型翻译项目。
2.3. 相关竞品分析
在翻译工具市场中,有多款成熟的产品,主要竞品分析如下:
| 竞品名称 | 优势 | 劣势 |
|---|---|---|
| DeepL | - 高质量的翻译,特别是在长句和复杂结构上表现优秀。 - 界面友好,用户体验良好。 |
- 图片翻译功能弱。 |
| Google Translate | - 提供多种输入方式,包括语音和图片识别。 | - 翻译质量在专业领域相对较低,常出现逐字翻译的现象。 |
| Microsoft Translator | - 提供实时翻译和多设备支持,适合商业使用。 - 强调与 Microsoft 其他产品的整合。 |
- 用户界面较为复杂,学习曲线较陡。 |
| iTranslate | - 提供离线翻译功能 - 支持语音翻译 |
- 付费功能较多,免费版本功能有限。 |
3. 云译网系统特性
- 集成现有网页端在线翻译的各种功能,无需调用多个翻译器,简洁易用。
3.1. 功能涵盖
- AI 会话:实现 AI 交流功能,文章润色。
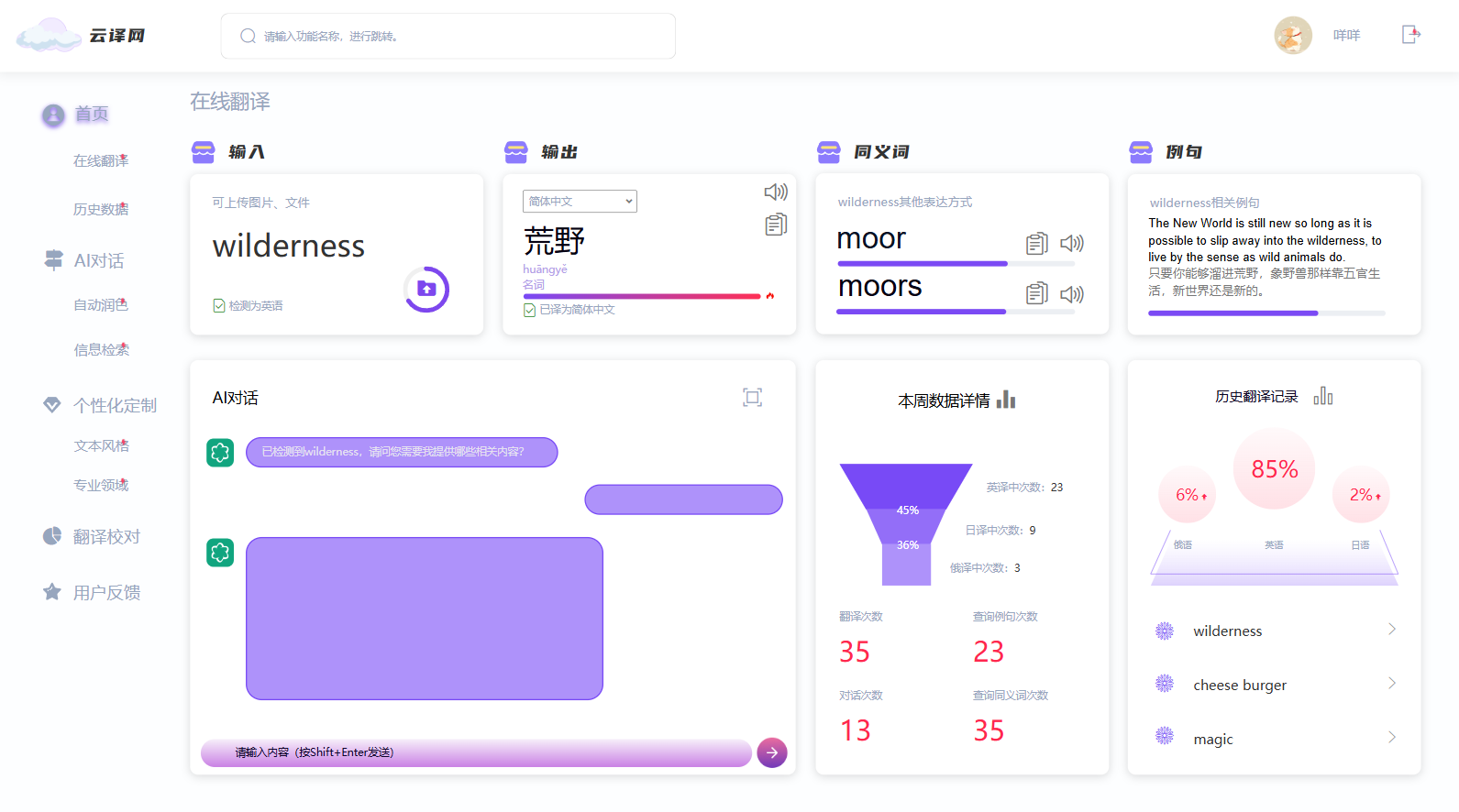
- 即时翻译:实现文本翻译的功能,注重简易和时效性。上方有源语言和目标语言的下拉框,以及左右的原文文本框和翻译文本框。
- 个性化翻译:下拉框中选择专业领域,比如学术论文、生物医药、信息技术等。
- 用户反馈和支持界面:可供质量、功能反馈及客服服务。
3.2. 页面详情
4. 非功能性需求
4.1. 功能完备性
“云译网”项目的功能较为完备,基本涵盖了翻译工具所需的各种功能,包括即时翻译、个性化翻译、文档翻译、OCR 翻译、翻译润色、相关内容检索、团队协作等功能。
4.2. 技术先进性
- 项目采用了最新的自然语言处理(NLP)技术和大语言模型(LLM),这些技术在处理复杂句子和专业领域的术语时表现出色。
- 项目结合了 OCR 识别技术,实现了图片和 PDF 文档的自动翻译,进一步提高了翻译的便捷性和准确性。此外,项目还注重技术的持续创新和改进,通过不断优化算法和模型,提升翻译质量和效率。
- 项目集成了现有翻译系统的各种功能,并使用LLM进行拓展,支持用户使用LLM的检索能力,通过会话了解翻译后的内容,无需上网单独查询。
- 项目提供了翻译质量检测等功能。
4.3. 用户体验方面
- 在用户体验方面,项目注重用户体验的优化,注重用户界面的简洁直观和操作流程的便捷性,通过一键翻译、简洁的 Web 界面等功能,降低了用户的使用门槛。
- 项目还提供了个性化翻译服务,允许用户自定义翻译风格和专业术语翻译,提高了翻译的准确性和个性化程度。
- 项目注重用户反馈和持续改进,通过收集用户反馈和不断优化模型,不断提升用户体验和满意度。通过这些措施以增强用户的忠诚度和黏性,提升产品的市场竞争力。
5. 项目结构
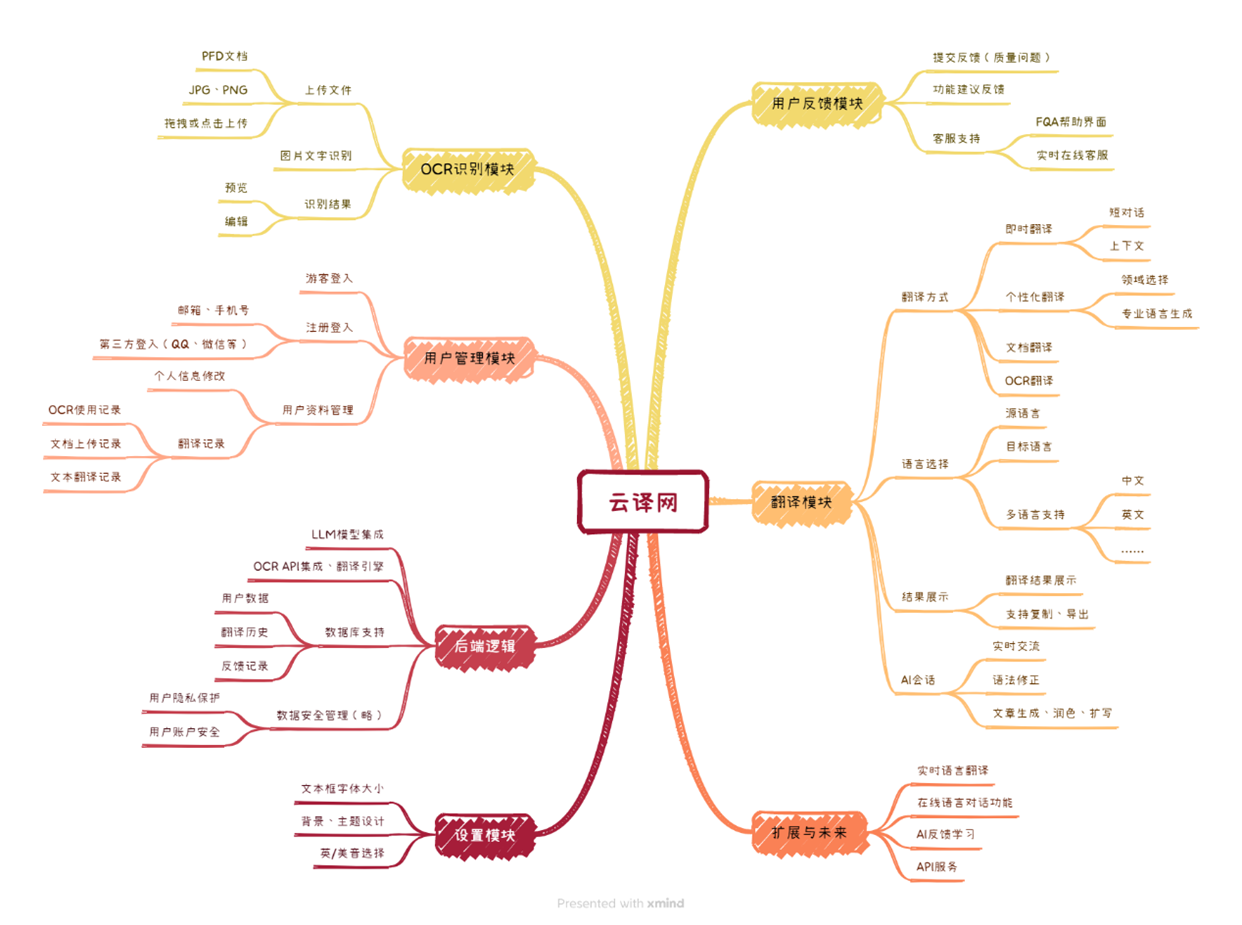
5.1. 项目的功能架构思维导图
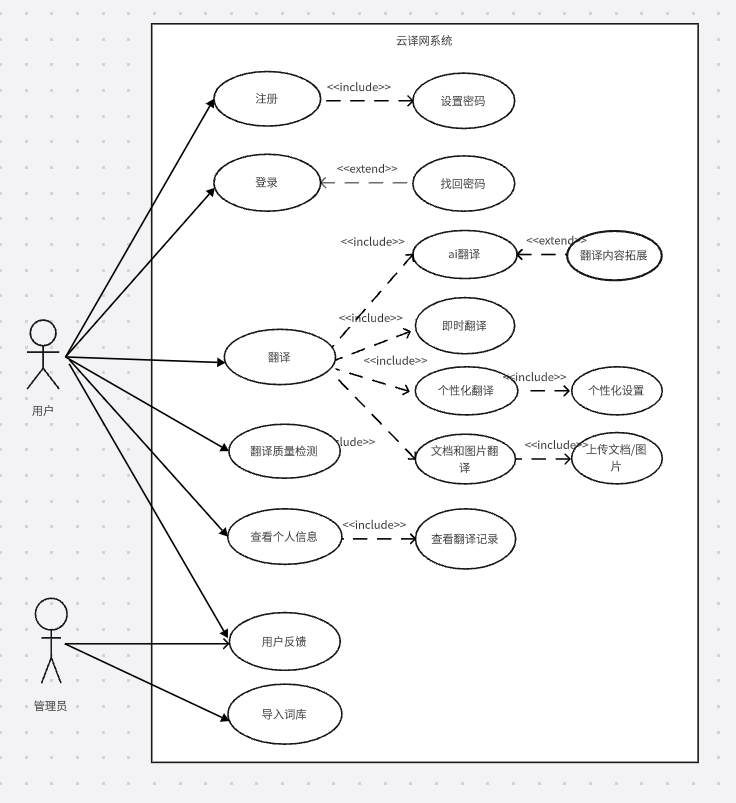
5.2. 项目用例图
5.3. 项目类图
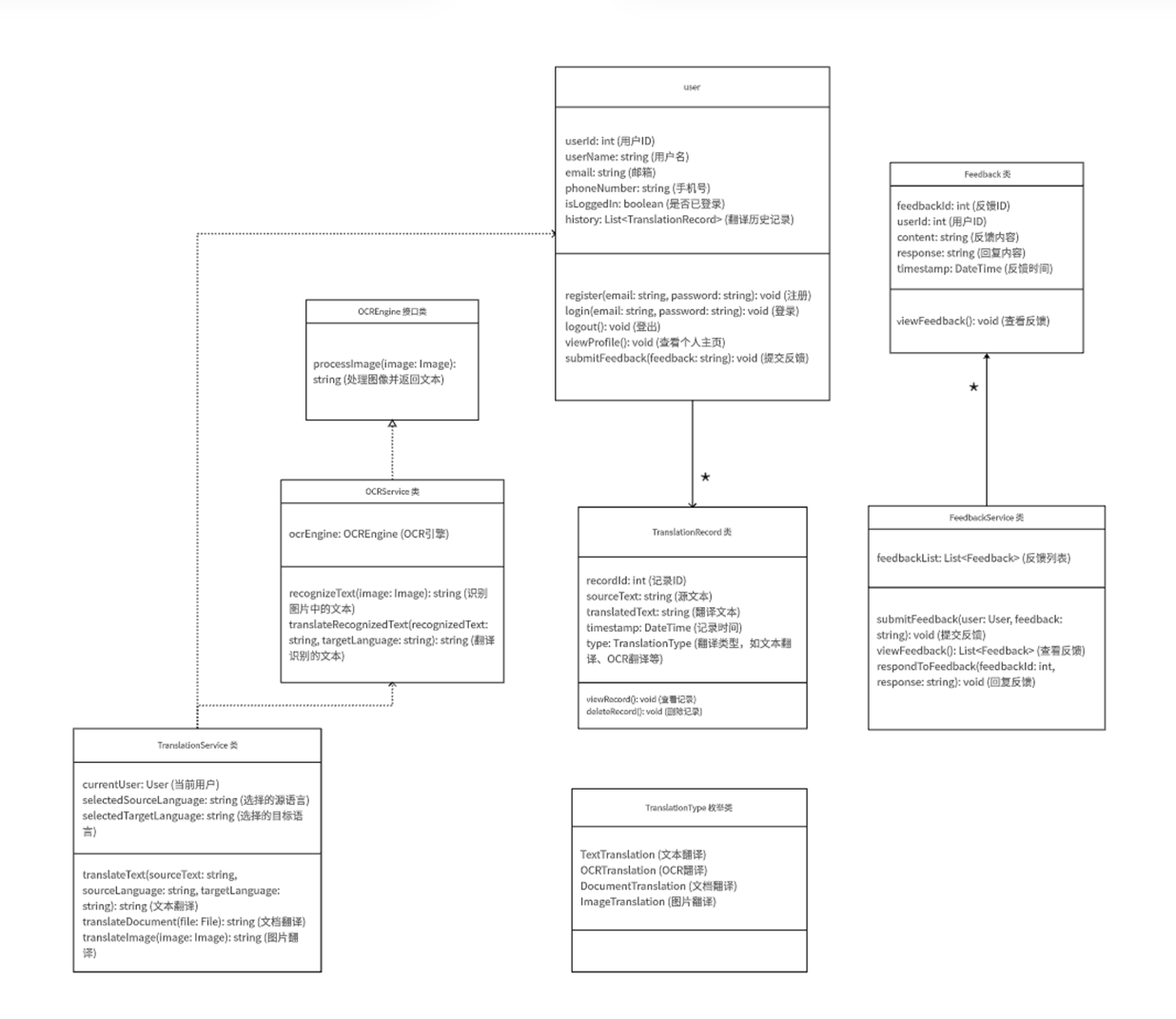
6. 前端和后端描述
6.1. 前端
- 负责开发用户界面和交互逻辑,包括首页、即时翻译、个性化翻译、用户反馈和支持等页面。
- 实现 OCR 识别功能的上传和预览功能。
- 优化用户体验,确保界面简洁直观、操作流程便捷。
6.2. 后端
- 负责实现翻译功能和 OCR 识别功能的后端逻辑。
- 优化后端系统,提高响应速度和资源利用率。
- 提供 API 接口,支持其他应用程序或平台集成翻译功能。
- 存储和管理用户信息和历史记录。
7. 迭代记录表格
| 迭代次数 | 日期 | 功能描述 | 负责人 | 状态 |
|---|---|---|---|---|
| 1 | 2024-10-30 | 初步完成核心功能:高质量翻译服务和个性化翻译功能 | 前端团队 | 进行中 |
| 2 | 2024-11-3 | 完成用户界面优化和实时翻译功能 | 前端团队 | 进行中 |
| 3 | 2024-11-8 | 集成 OCR 识别功能,实现图片和 PDF 文档的自动翻译 | 后端团队 | 计划中 |
| 4 | 2024-11-12 | 提供 API 服务,支持其他应用程序或平台集成翻译功能 | 后端团队 | 计划中 |
| 5 | 2024-11-18 | 优化后端系统,减少计算资源消耗,提高响应速度 | 后端团队 | 计划中 |
8. 验收标准
8.1. 功能验收
-
高质量翻译服务:
- 翻译结果准确、自然流畅,无明显误解。
- 测试用例:提供多种语言的文本,检查翻译结果是否符合原文意思,是否自然流畅。
-
个性化翻译:
- 用户能够自定义翻译风格和专业术语翻译,翻译结果符合用户要求。
- 测试用例:用户自定义法律、医疗等专业术语的翻译,检查翻译结果是否符合用户自定义的风格和术语。
-
用户界面优化:
- 界面简洁直观,操作流程便捷,用户能够轻松完成翻译任务。
- 测试用例:模拟用户操作,检查界面是否简洁直观,操作流程是否便捷。
-
实时翻译与优化:
- 实时翻译功能响应速度快,翻译结果准确。
- 测试用例:输入文本后立即检查翻译结果,确保响应速度快且翻译结果准确。
-
OCR 识别功能:
- 图片和 PDF 文档中的文字识别准确率高,翻译结果符合用户要求。
- 测试用例:上传不同类型的图片和 PDF 文档,检查文字识别的准确率和翻译结果。
-
API 服务:
- API 接口稳定可靠,能够支持其他应用程序或平台集成翻译功能。
- 测试用例:调用 API 接口进行翻译,检查接口的稳定性和可靠性。
-
AI 对话:
- 翻译后可立即就翻译的内容,和 AI 对话,检索相关信息。
- 测试用例:翻译完成后立即与 AI 对话,检查对话功能的准确性和响应速度。
-
翻译质量检测:
- 提供对人工翻译的检测校验,便于翻译人员自测自己的学习成果。
- 测试用例:上传人工翻译的文本,检查检测校验功能的准确性和实用性。
8.2. 用户体验验收
-
用户对界面设计和操作流程的满意度高:
- 测试用例:收集用户反馈,检查用户对界面设计和操作流程的满意度。
-
用户能够轻松上手并快速完成翻译任务:
- 测试用例:模拟新用户使用系统,检查用户是否能够轻松上手并快速完成翻译任务。
-
用户在使用过程中遇到的问题能够及时得到解决:
- 测试用例:模拟用户遇到问题,检查问题是否能够及时得到解决。
8.3. 性能验收
-
系统响应时间快,无明显卡顿现象:
- 测试用例:模拟高并发访问,检查系统响应时间是否快,是否存在卡顿现象。
-
后端系统资源消耗低,能够支持高并发访问:
- 测试用例:模拟高并发访问,检查后端系统资源消耗是否低,是否能够支持高并发访问。
-
OCR 识别功能和翻译功能的准确率高,识别速度快:
- 测试用例:上传不同类型的图片和 PDF 文档,检查 OCR 识别功能和翻译功能的准确率和识别速度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号