爬虫综合大作业
本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
一.把爬取的内容用数据库保存
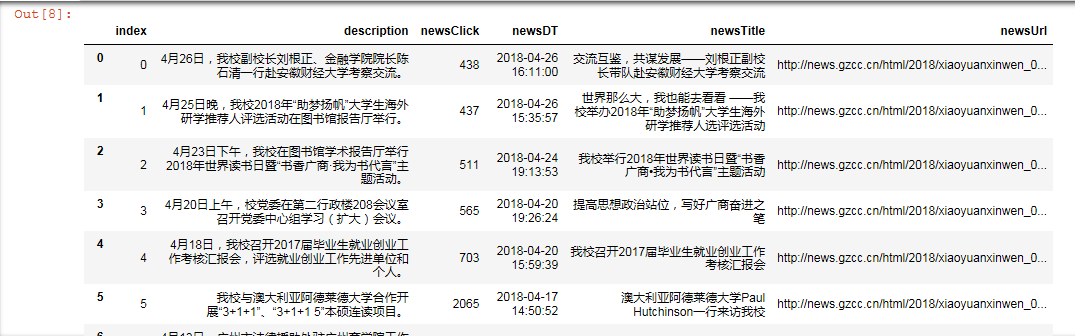
1.保存到sqlite3数据库
# 用pandas读出之前保存的数据: newsdf = pd.read_csv(r'D:\gzccnews.csv') # 创建保存newsdf到表gzccnews import sqlite3 with sqlite3.connect('gzccnewsdb.sqlite') as db: newsdf.to_sql('gzccnews',con=db) # 查询读出保存到sqlite3数据库的内容df2 with sqlite3.connect('gzccnewsdb.sqlite') as db: df2 = pd.read_sql_query('select * from gzccnews',con=db) df2
运行示例:
2.保存到MySQL数据库:
# 安装需要用到的类包 !pip install PyMySQL !pip install sqlalchemy # 导入类包连接MySQL数据库(gzcc_news) import pymysql from sqlalchemy import create_engine coninfo = "mysql+pymysql://root:@localhost:3306/gzcc_news?charset=utf8" engine = create_engine(coninfo,encoding="utf-8") # 把newsdf数据保存到gzcc_news数据库新建表news上 newsdf.to_sql(name='news',con=engine,if_exists='append',index= False,index_label='id')
运行示例:

二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
缘由
想了很久,不知道自己感兴趣的是什么,然后就爬了下社会热点话题和自己工作相关的东西。但最后限于技术不行,参考网上成功案例还是报错找不出哪里,ip也被封了几次。最后还是倒回来爬取影评。
《无问西东》这部电影对我触动很大,五一假期进行了三刷,其中有一幕记忆深刻:
吴岭澜“ 最好的学生都是学实科的。我只知道,这个年纪最重要的就是学习,何用管我学什么。每天把自己交给书本,心里就觉得踏实。”
梅贻琦答他:“ 你还忽略了一件事,真实。人把自己置身于忙碌当中,有一种麻木的踏实,但丧失了真实。”“ 真实就是,你看什么,做什么,和谁在一起,有一种从心灵深处满溢出来的不懊悔、也不羞耻的平和与喜悦。”
让我久久不能忘怀,有所共鸣又有所困惑。所以想着借此爬取广大网友的观点做一次分析,多看看别人看这部电影的想法感受,跳出自我,去寻找那么迷茫和拿不定主意什么才适合自己的方向。
爬取范围
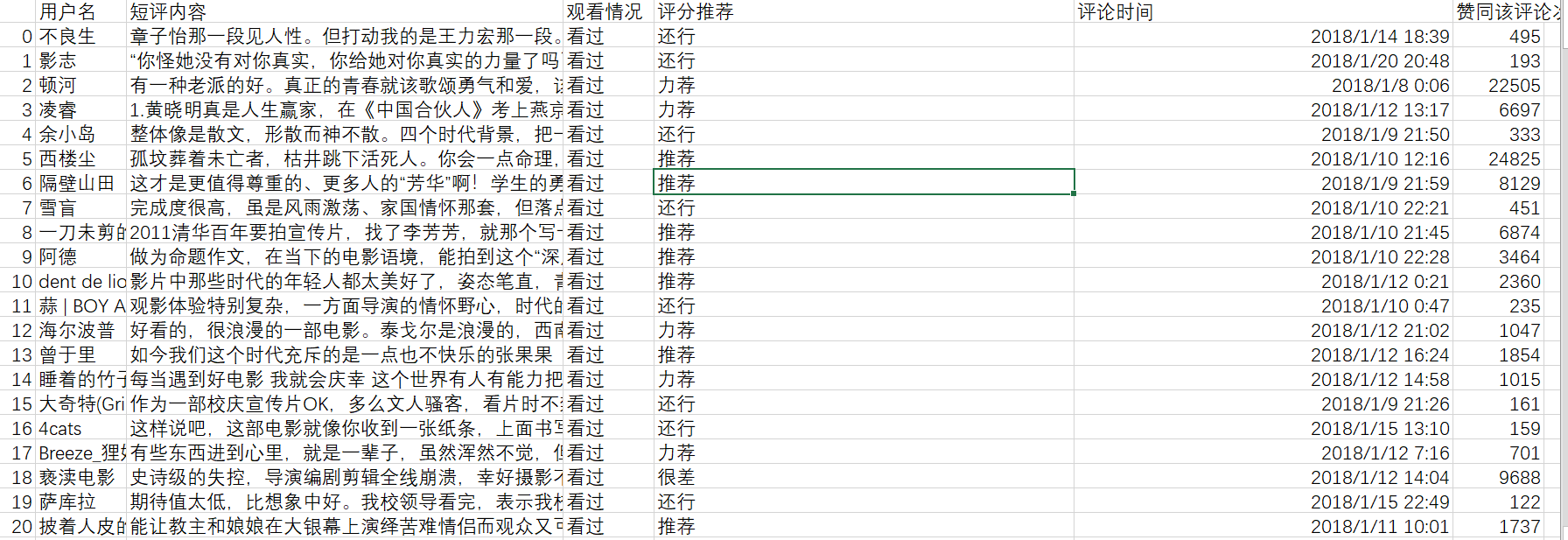
用python爬取用户名、短评内容、观看情况、评分推荐、评论时间、赞同该评论次数解读《无问西东》


# 导入需要用到的类包 import requests from bs4 import BeautifulSoup import time import random import pandas as pd uas = [ 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36', 'Mozilla / 5.0(Linux;Android 6.0; Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 73.0 .3683.103Mobile Safari / 537.36', 'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10' 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36' ] # 随机选取用户代理 def get_ua(): au = random.choice(uas) return au # 抓取解析网页 def get_soup(url): # 伪装浏览器发送请求 headers = { 'User-Agent': get_ua(), 'Host': 'movie.douban.com', 'Connection': 'keep-alive', 'Cookie': 'll="118281"; bid=PDfyRYzWZUA; __utmz=30149280.1557146179.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); ' 'gr_user_id=64e50650-eaac-439c-bf07-4845beda01f4; _vwo_uuid_v2=DCC7E0177B98EF36F009D20E376BAFAF0|af1541df8cba612ae9400c9868c99729; viewed="1291199";' ' __yadk_uid=NZF4B0V65mFYDKwVEtBIqD7IzCfqBuCo; trc_cookie_storage=taboola%2520global%253Auser-id%3D1b6006bb-7d65-4a3d-9ef8-0bd85ef174e3-tuct363a7b2;' ' __gads=ID=aa3da2d975e4bc28:T=1557291874:S=ALNI_Mb5dM0i_lKo5qiVEALC5SbsE4zAeg;' ' __utmz=223695111.1557291909.3.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/search; _' 'pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1557365604%2C%22https%3A%2F%2Fwww.douban.com%2Fsearch%3Fq%3D%25E6%2597%25A0%25E9%2597%25AE%25E8%25A5%25BF%25E4%25B8%259C%22%5D;' ' _pk_ses.100001.4cf6=*; __utma=30149280.574526707.1557146179.1557305660.1557365604.7; __utmc=30149280; __utma=223695111.1592700349.1557228376.1557305660.1557365604.6;' ' __utmc=223695111; ap_v=0,6.0; __utmb=30149280.4.9.1557368405684; dbcl2="196202536:5ThcQT2Qzr0";' ' ck=EL1Z; push_noty_num=0; push_doumail_num=0; ct=y; __utmt=1; _pk_id.100001.4cf6=627ae57bc2f4ade6.1557228376.6.1557369194.1557306413.; __utmb=223695111.19.10.1557365604' } res = requests.get(url, headers=headers) time.sleep(random.random()*5) #设置时间间隔,防止太快被封 res.encoding='utf-8' soup = BeautifulSoup(res.text,'html.parser') return soup # 获取一页用户的评论 def getText(soup): comment_list = [] for p in soup.select('.comment-item'): comment = {} username = p.select('.comment-info')[0]('a')[0].text watch = p.select('.comment-info')[0]('span')[0].text intro = p.select('.comment-info')[0]('span')[1]['title'] cTime = p.select('.comment-time ')[0]['title'] pNum = p.select('.votes')[0].text short = p.select('.short')[0].text text=short.replace('\n', ' ') comment['用户名']=username comment['观看情况']=watch comment['评分推荐']=intro comment['评论时间']=cTime comment['短评内容']=text comment['赞同该评论次数']=pNum comment_list.append(comment) return comment_list url = 'https://movie.douban.com/subject/6874741/comments?start={}&limit=20&sort=new_score&status=P' comments = [] for i in range(1,50): soup = get_soup(url.format(i * 20)) # 每一页20条评论需乘20来拼凑网页 comments.extend(getText(soup)) time.sleep(random.random() * 5) # # 测试爬出所有影评的概况 # for n in comments: # print(n) # 保存到本地csv文件 commentFile = pd.DataFrame(comments) commentFile.to_csv(r'D://comments1.csv', encoding='utf_8_sig')
爬取后的部分数据:
数据处理
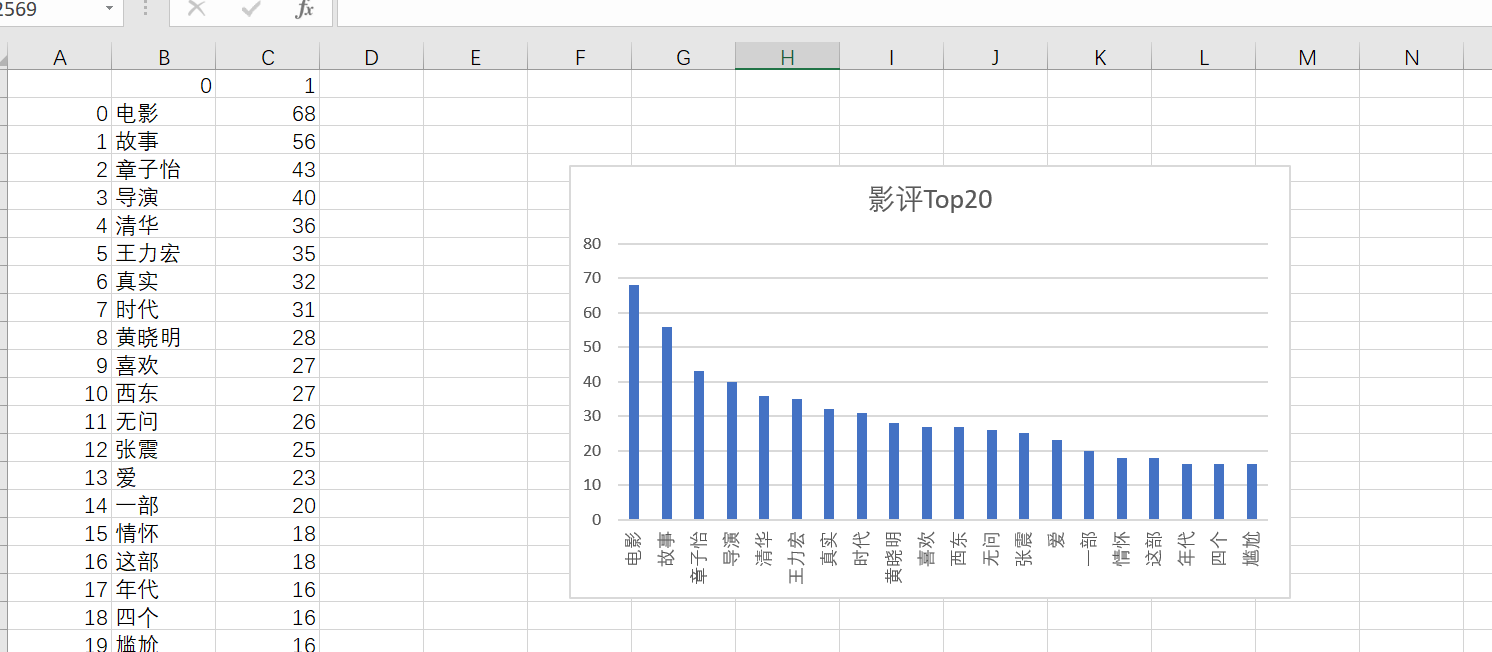
# 从文件读取待分析文本 with open(r'D:\\comments_analyse.txt', 'r', encoding='utf-8') as f: text = f.read() # 使用jieba进行中文分词 import jieba textCut = jieba.lcut(text) # 排除语法型词汇,代词、冠词、连词等停用词 with open(r'D:\\学习\\stops_chinese.txt', 'r', encoding='utf-8') as f: stops = f.read().split('\n') tokens = [token for token in textCut if token not in stops] # 将文本转化为集合 words_set = set(tokens) # 存入字典 words_dict = {} for w in words_set: words_dict[w] = tokens.count(w) # 字典转换成列表对词语进行词频排序 words_sort = list(words_dict.items()) words_sort.sort(key=lambda x: x[1], reverse=True) # print(words_sort) # for w in words_sort: # print(w) import pandas as pd pd.DataFrame(data=words_sort).to_csv(r'D:\\学习\\无问西东影评.csv',encoding='utf_8_sig')
词频统计:
词云:

# 插入空格把词语分开 wl_split=' '.join(tokens) # 调用generate()方法生成词云 from wordcloud import WordCloud mywc = WordCloud().generate(wl_split) # 显示词云 import matplotlib.pyplot as plt plt.imshow(mywc) plt.axis("off") plt.show()
总结
不知道哪里出了问题,只爬取到大概300条左右的一小部分数据,感觉没有分析跟豆瓣总结出的结论没有什么太大的差异,所以只能算做是一个小练习并没有太大的参考价值,以后还需更加努力学习。最后,总结下电影,嗯,想法各有不同,评论偏向中肯,戒骄戒躁,脚踏实地,才能仰望星空。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号