复合数据类型,英文词频统计
本次作业要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
1.列表,元组,字典,集合分别如何增删改查及遍历。
列表:通过[]来创建列表,可通过索引(index)来获取列表中的元素和修改元素;append() 方法向列表的最后添加一个元素,insert()向列表的指定位置插入一个元素,extend()使用新的序列来扩展当前序列,需要一个序列作为参数,它会将该序列中的元素添加到当前列表中;通过pop() 根据索引删除并返回被删除的元素;一般通过for循环来遍历列表,如for s in stus :print(s)形式。
元组:使用()来创建元组,它的操作的方式基本上和列表是一致的。但元组是不可变的序列,不能尝试为元组中的元素重新赋值
字典:使用 {} 来创建字典,每一个元素都是键值对,键不重复,值可以重复。可通过索引为其添加或修改元素dict['key']='value';一般通过del(del dict['key'])或pop()方法(dict.pop('key'))删除,其中pop(key[, default]),根据key删除字典中的key-value,会将被删除的value返回,如果删除不存在的key,会抛出异常。clear()用来清空字典;可以通过遍历keys()来获取所有的键, for k in d.keys() :print(k , d[k]),或通过items()方法遍历字典;如for k,v in d.items() :print(k , '=' , v)
集合:使用 {} 或set() 函数来创建集合,操作与字典类似,但只包含键,而没有对应的值,包含的数据不重复。可以通过set()来将序列和字典转换为集合。
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
列表用[]表示,有序,可变,可重复,元素以值的方式存储为值,可通过索引查找,如mylist[1]
元组用()表示,有序,不可变,可重复,元素以值的方式存储为值,可通过索引查找,如tuple[0]
字典用{}表示,无序,键不可重复,值可以重复,元素以键值对的方式存储为值,一般通过键查找,如dist['key']
集合用{}表示,无序,可变,不可重复,元素以值的方式存储为值,可以通过set()来将序列和字典转换为集合。
3.词频统计
# 读文本,获取单词函数
def get_text(file):
f = open(file, 'r', encoding='utf8')
text = f.read()
f.close()
# 将所有大写转换为小写
text = text.lower()
# re表示待替换的符号
re = '.?!:\"\',\n'
# 将所有其他做分隔符替换为空格
for i in re:
text = text.replace(i, ' ')
# 分隔出一个一个的单词
words_list = text.split()
return words_list
# 词频统计函数
def get_wordsort(words_list):
# 排除语法型词汇,代词、冠词、连词等无语义词
reps = {'it', 'if', 'the', 'at', 'for', 'on', 'and', 'in', 'to', 'of', 'a', 'was', 'be', 'were','in','about','from','with','without','an','one','another'
,'others','that','they','himself','itself','themselves','if','when','before','though','although','while','as','as long as','i','he','him','she',
'out','is','s','no','not','you','me','his','but'}
words_set = set(words_list) - reps
# 存入字典
words_dict = {}
for w in words_set:
words_dict[w] = words_list.count(w)
# 字典转换成列表对单词进行词频排序
words_sort = list(words_dict.items())
words_sort.sort(key=lambda x: x[1], reverse=True)
return words_sort
# 调用get_text函数获得一个个单词列表
words_list = get_text('D:\\学习\\oldManAndFish.txt')
# 调用词频统计函数get_wordsort获得从高到低的单词列表
words_sort = get_wordsort(words_list)
# 导入pandas包使用DataFrame方法对words_sort词频列表转换成csv文件保存
import pandas as pd
pd.DataFrame(data=words_sort).to_csv(r'D:\\学习\\story.csv',encoding='utf-8')
执行代码生成:
![]()
利用story.csv文件生成单词TOP(20):
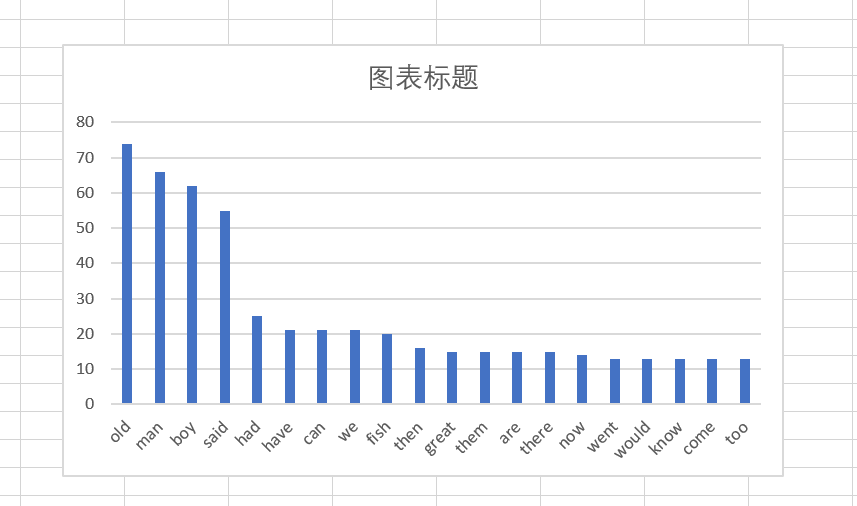
利用线上工具生成词云:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号