ELK之日志收集系统配置
目录
1.ELK 日志收集系统之Supervisord安装配置
2.ELK 日志收集系统之Supervisord启动elasticsearch-head
3.ELK 日志收集系统之Kafka配置
4.ELK 架构部署之 Logstash 配置
5.ELK 架构部署之supervisord方式启动Kibana
6.ELK 日志收集系统之Filebeat配置
1.EFK 日志收集系统之Supervisord安装配置
0x01 Supervisord 简单介绍
Supervisor是一个客户/服务器系统,它可以在类Unix系统中管理控制大量进程。Supervisor使用python开发,有多年历史,目前很多生产环境下的服务器都在使用Supervisor。
Supervisor的服务器端称为supervisord,主要负责在启动自身时启动管理的子进程,响应客户端的命令,重启崩溃或退出的子进程,记录子进程stdout和stderr输出,生成和处理子进程生命周期中的事件。可以在一个配置文件中配置相关参数,包括Supervisord自身的状态,其管理的各个子进程的相关属性。配置文件一般位于/etc/supervisord.conf。
Supervisor的客户端称为supervisorctl,它提供了一个类shell的接口(即命令行)来使用supervisord服务端提供的功能。通过supervisorctl,用户可以连接到supervisord服务器进程,获得服务器进程控制的子进程的状态,启动和停止子进程,获得正在运行的进程列表。客户端通过Unix域套接字或者TCP套接字与服务端进行通信,服务器端具有身份凭证认证机制,可以有效提升安全性。当客户端和服务器位于同一台机器上时,客户端与服务器共用同一个配置文件/etc/supervisord.conf,通过不同标签来区分两者的配置。
0x02 Supervisord 安装及主要目录介绍
安装方式这里不多做介绍,可参考官网:Supervisor
我这里为了方便,直接 yum 仓库安装
# yum -y install supervisor
使用 yum 安装的 supervisor,主要关注三个文件:
/etc/supervisord.conf:supervisord 的主配置文件;/etc/supervisord.d:用于存放管理进程的配置;/var/log/supervisor:supervisord 的日志存放目录,存放关于supervisord的所有日志文件。
0x03 Supervisord 的配置
开启 Supervisord 的 Web 管理界面,在主配置文件(/etc/supervisord.conf)下找到如下配置,取消注释,配置配置访问IP、端口号(默认端口:9001)、登入账号、密码。虽然内网,密码建议复杂。
[inet_http_server] ; inet (TCP) server disabled by default
port=192.168.7.3:9001 ; (ip_address:port specifier, *:port for all iface)
username=admin ; (default is no username (open server))
password=admin ; (default is no password (open server))
重启supervisord
systemctl restart supervisord
浏览器访问:http://192.168.7.3:9001

supervisord 配置暂时到此结束,后面会用到supervisord管理如下进程。
| 进程名 | 介绍 |
|---|---|
| EFK-elasticsearch-head | elasticsearch 插件 |
| EFK-kafka-broker0 | Kafka实例 |
| EFK-kafka-broker1 | Kafka实例 |
| EFK-kafka-broker2 | Kafka实例 |
| EFK-kafka-consumer-mysql-1 | kafka消费者消费MySQL队列信息 |
| EFK-kafka-consumer-mysql-2 | kafka消费者消费MySQL队列信息 |
| EFK-kafka-consumer-nginx-1 | kafka消费者消费nginx队列信息 |
| EFK-kafka-consumer-nginx-2 | kafka消费者消费nginx队列信息 |
| EFK-kafka-consumer-php-1 | kafka消费者消费php队列信息 |
| EFK-kafka-consumer-php-2 | kafka消费者消费php队列信息 |
| EFK-kafka-consumer-php-1 | kafka消费者消费php队列信息 |
| EFK-kafka-consumer-php-2 | kafka消费者消费php队列信息 |
| EFK-kafka-consumer-system-1 | kafka消费者消费system队列信息 |
| EFK-kafka-consumer-system-2 | kafka消费者消费system队列信息 |
| EFK-kafka-manager | kafka的Web工具 |
| EFK-kafka-zookeeper | kafka必须连接zookeeper |
| EFK-kibana | kibana 进程 |
| EFK-logstash-indexer-mysql | logstash转发mysql消息 |
| EFK-logstash-indexer-system | logstash转发system消息 |
| EFK-logstash-indexer-php | logstash转发php消息 |
| EFK-logstash-indexer-nginx | logstash转发nginx消息 |
后期完成结果如下:

2.EFK 日志收集系统之Supervisord启动elasticsearch-head
由于在前文中0x04 安装 Elasticsearch,我们是在前台使用直接运行 npm run start 命令启动的 elasticsearch-head,这样有一点不好,开启此前台应用程序的中端不能关闭。比如可以用 nohup或& 让程序在后台运行。但我们还是更偏爱于使用Web界面管理的后台程序,更加直观明了。因此我们使用 supervisord 管理后台程序,话不多说,直接切入主题。
如果要使用 supervisord 管理后台进程,需要在 /etc/supervisord.d 目录下,配置进程的相关信息,创建配置文件elasticsearch-head.ini ,我这边的配置如下:
# 配置进程的名字
[program:EFK-elasticsearch-head]
# 命令运行的目录
directory=/usr/local/elasticsearch-head
# 进程执行的命令
command=/usr/local/node-v10.15.1-linux-x64/bin/npm run start
# 是否随supervisor启动
autostart=true
# 子进程启动多少秒之后,此时状态如果是running,则我们认为启动成功了。默认值为1
startsecs=1
# 标准错误日志目录
stderr_logfile=/var/log/supervisor/elasticsearch-head_stderr.log
# 标准输出日志目录
stdout_logfile=/var/log/supervisor/elasticsearch-head_stdout.log
# 进程启动的用户
user=elasticsearch
# 把 stderr 重定向到 stdout,默认 false,即把标准错误日志写入到标准输出日志中,说白了就是将两个日志文件合并到一个日志文件
redirect_stderr=true
# 标准输出 stdout 日志文件大小 20MB,默认为50MB
stdout_logfile_maxbytes=20MB
# 标准输出日志备份数量
stdout_logfile_backups=10
elasticsearch-head.ini 配置文件创建完毕后,可以在命令行中,运行命令:
# supervisorctl update
这条命令会加载 /etc/supervisord.d 目录下的进程文件:
- 如果有新的进程文件,则会直接启动该进程;
- 如果仅仅是旧的进程文件被更新了,则会停止该进程,再重新启动该进程。
# supervisorctl status
EFK-elasticsearch-head RUNNING pid 4107, uptime 8:23:41
supervisord 还有如下几条命令比较常用:
# 停止某一个进程
supervisorctl stop 进程名字
# 启动某一个进程
supervisorctl start 进程名字
# 去除某一个进程
supervisorctl remove 进程名字
对于一个新加入的进程,我们需要先执行 supervisorctl update 后,才能在 supervosprctl status 中看到进程的状态。
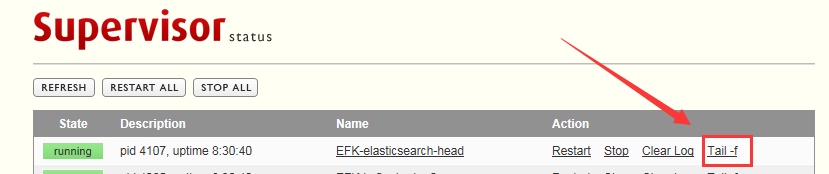
如果在命令终端观察到进程为RUNNING状态,则可以浏览器管理该进程了,浏览器输入: http://192.168.7.3:9001 ,如下图,选择 Tail -f,则可以看到/var/log/supervisor/elasticsearch-head_stdout.log日志中的内容,是不是很方便呢?
最后,我们要查看elasticsearch-head的端口是否起来:
# netstat -anlp | grep 9100
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 7112/grunt
# lsof -i :9100
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
grunt 7112 elasticsearch 18u IPv4 8031920 0t0 TCP *:jetdirect (LISTEN)
浏览器访问 :http://192.168.7.3:9100
3.EFK 日志收集系统之Kafka配置
0x01 Kafka简单介绍
关于Kafka的具体介绍,可参考中文文档:Kafka中文网站,以下摘抄于文档中一些比较重要的概念。
Kafka是一种高性能、低延迟、具备日志存储、备份和传播功能的分布式文件系统。有如下三种特性:
- 可以让你发布和订阅流式的记录
- 可以储存流式的记录,并且有较好的容错性。
- 可以在流式记录产生时就进行处理。
Kafka 可用于两大类别的应用:
- 构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当于message queue)
- 构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过kafka stream topic和topic之间内部进行变化)
Kafka 基本概念:
- Kafka作为一个集群,运行在一台或多台服务器上
- Kafka 通过
topic对存储的流数据进行分类 - 每条记录中包含一个
key、一个value和一个timestamp(时间戳) Topic就是数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka中的 Topic 总是多订阅者模式,一个 topic 可以区分拥有一个一个或者多个消费者来订阅它的数据- Kafka 集群保留所有发布的记录—无论他们是否已被消费—并通过一个可配置的参数——保留期限来控制。举个例子, 如果保留策略设置为2天,一条记录发布后两天内,可以随时被消费,两天过后这条记录会被抛弃并释放磁盘空间。
- 日志中的 partition(分区)有以下几个用途。第一,当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。第二,可以作为并行的单元集。
- 日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性。
- 每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
- 生产者可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。
- 消费者使用一个
消费组名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例。如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.。 - 通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消费者实例组成,便于扩展和容错。
根据EFK日志采集系统的特点,我个人对使用kafka的理解,即怎样解决日志在Kafka中做分类传输的问题:由于我们利用 Filebeat 采集到的日志会有很多不同的日志,比较常见的例如 Web服务器的Nginx的日志、php的日志,数据库服务器MySQL的日志、慢查询日志等,还有每一台服务器的系统日志。
所以,我们需要对不同的日志做分类传到Kafka的中。在Filebeat 中,我们利用 fields 添加一个自定义字段,这里我们会定义一个key为log_topic,值根据采集的日志来定,例如我们采集的是是nginx的错误日志和访问日志 /var/log/nginx/error.log、 /var/log/nginx/access.log ,则可以将 log_topic 的值定义为 nginx,然后在 filebeat中配置输出为 output.kafka,时,可以定义 topic 为 %{[fields.log_topic]},这样就可以实现,将不同的日志分类存储到 kafka 中。Kafka中比较重要的一个概念Topic,即数据主题。我们既然采集到了日志,并传递到Kafka中,在Kafka中也不能够随便存储。所以我们根据 filebeat 中自定义的log_topic字段,来定义Topic。为了做横向扩展,一个 topic 可以由多个 partition 组成,遇到瓶颈时,通过增加partition的数量来进行横向扩容。但是对于每一个partition,需要启用一个消费者,消费partition中的数据。即如下图所示:
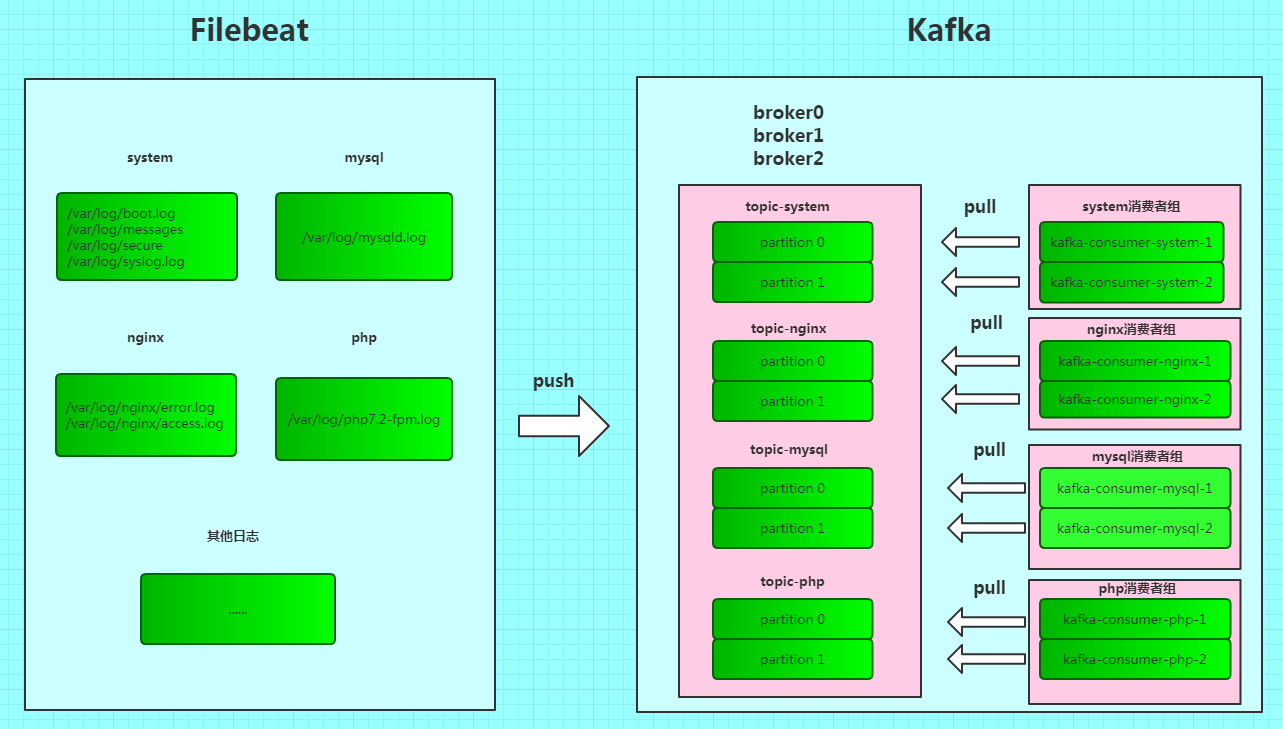
在上图中,我们采集了system、php、mysql、nginx日志,Filebeat 将日志推送到 Kafka中,并根据不同的日志存储在不同的 Topic 中。在Kafka中会启动3个broker实例,分别为 broker0、broker1和broker2。每个Topic分为两个partition,并且一个Topic对应一组消费者组,这组消费者组中每一个消费者对应消费一个partition中的消息队列。话不多说,开始实战!
0x01 Kafka 配置之启动 broker
在EFK之日志收集系统部署中,我们已将Kafka的安装包解压至 /usr/local 目录下,进入该目录下,查看有哪些文件内容:
# pwd
/usr/local/kafka_2.11-2.1.0
# ls
bin config libs LICENSE logs NOTICE site-docs
# ls bin/
connect-distributed.sh kafka-console-producer.sh kafka-log-dirs.sh kafka-run-class.sh kafka-streams-application-reset.sh zookeeper-security-migration.sh
connect-standalone.sh kafka-consumer-groups.sh kafka-mirror-maker.sh kafka-topics.sh zookeeper-server-start.sh
kafka-acls.sh kafka-consumer-perf-test.sh kafka-preferred-replica-election.sh kafka-verifiable-consumer.sh zookeeper-server-stop.sh
kafka-broker-api-versions.sh kafka-delegation-tokens.sh kafka-producer-perf-test.sh kafka-verifiable-producer.sh zookeeper-shell.sh
kafka-configs.sh kafka-delete-records.sh kafka-reassign-partitions.sh kafka-server-start.sh trogdor.sh
kafka-console-consumer.sh kafka-dump-log.sh kafka-replica-verification.sh kafka-server-stop.sh windows
如上,在 /usr/local/kafka_2.11-2.1.0/bin 目录下,可以看到有很多以.sh结尾的 Shell 脚本,重点关注以下几个脚本
zookeeper-server-start.sh # zookeeper服务启动脚本
kafka-topics.sh # topic管理脚本,可创建、删除、修改topic
kafka-console-consumer.sh # 消费者启动脚本
kafka-server-start.sh # broker 实例启动脚本
Kafka要运行,首先要启动 zookeeper。zookeeper是一个为分布式应用提供一致性服务的软件
1.启动 ZooKeeper 服务器
利用 /usr/local/kafka_2.11-2.1.0/bin下的zookeeper-server-start.sh脚本启动 ZooKeeper(当然我们肯定会有supervisord部署的)
# bin/zookeeper-server-start.sh config/zookeeper.properties
启动服务后,可以查看 zookeeper的 2181 端口是否启动
# netstat -tnlp | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 3850/java
# 查看连接数
# lsof -i:2181
- supervisord 方式部署
zookpeeper
在 /etc/supervisord.d 目录下,新建 kafka-zookeeper.ini 配置文件,填入如下内容:
[program:EFK-kafka-zookeeper]
directory=/usr/local/kafka_2.11-2.1.0/bin
command=/usr/local/kafka_2.11-2.1.0/bin/zookeeper-server-start.sh /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
autostart=true
startsecs=1
stderr_logfile=/var/log/supervisor/kafka-zookeeper_stderr.log
stdout_logfile=/var/log/supervisor/kafka-zookeeper_stdout.log
user=root
redirect_stderr=true
stdout_logfile_maxbytes=20MB
stdout_logfile_backups=10
然后执行在命令行中执行:
# supervisorctl update
# supervisorctl status
supervisord 方式部署完毕。
0x03 启动 broker 实例
脚本方式启动
# bin/kafka-server-start.sh config/server.properties
这里有一点要注意,我们在开启 broker 实例时,一般都不止一个broker,为了高可用,可定要多启动几个broker。而每个 broker 可能配置需求不一样,所有会多次用到server.properties配置文件,我们可以根据 broker的id来命令server.properties文件,在broker中,broker的ID必须是唯一的。在server.properties中配置。先讲讲server.properties配置文件:
# broker 的ID,必须为整数,且在集群中唯一
broker.id=0
# broker的机架位置。 这将在机架感知副本分配中用于容错。
broker.rack=efk
# broker监听的端口,如果在同一台服务器上启动多个broker,应启用不同的端口
listeners=PLAINTEXT://192.168.7.3:9092
# 服务器用于从接收网络请求并发送网络响应的线程数
num.network.threads=3
# 服务器用于处理请求的线程数,可能包括磁盘I/O
num.io.threads=8
# 服务端用来处理socket连接的SO_SNDBUF缓冲大小。
socket.send.buffer.bytes=102400
# 服务端用来处理socket连接的SO_RCVBUFF缓冲大小。
socket.receive.buffer.bytes=102400
# socket请求的最大大小,这是为了防止server跑光内存,不能大于Java堆的大小。
socket.request.max.bytes=104857600
# 保存日志数据的目录,如果未设置将使用log.dir的配置。可根据broker的id号配置
log.dirs=/tmp/kafka-logs-0
# 每个topic的默认日志分区数
num.partitions=1
# 每个数据目录,用于启动时日志恢复和关闭时刷新的线程数
num.recovery.threads.per.data.dir=1
# offset topic的副本数(设置的越大,可用性越高)。
offsets.topic.replication.factor=1
# 事务topic的副本数(设置的越大,可用性越高)。
transaction.state.log.replication.factor=1
# 覆盖事务topic的min.insync.replicas配置
transaction.state.log.min.isr=1
# 日志删除的时间阈值(小时为单位)
log.retention.hours=168
# 单个日志段文件最大大小
log.segment.bytes=1073741824
# 日志清理器检查是否有日志符合删除的频率(以毫秒为单位)
log.retention.check.interval.ms=300000
# 连接到 zookeeper 的IP和端口号
zookeeper.connect=192.168.7.3:2181
# 与ZK server建立连接的超时时间,
zookeeper.connection.timeout.ms=6000
# 在执行第一次重新平衡之前,group协调器将等待更多consumer加入group的时间。
group.initial.rebalance.delay.ms=0
在 server.properties 的配置文件中,最核心的三个配置为:
- broker.id
- log.dirs
- zookeeper.connect
请确保 broker.id 的唯一性;log.dirs的配置标准:kafka-logs-id号,例如:broker.id 为 0 ,则 log.dirs 可设置为 kafka-logs-0,依次类推。这里我们需要创建3个broker,依次配置 3 个 broker 的 supervisord 进程文件,参考 broker.id=0 的配置即可。
注意:broker的配置文件中还有一个特别重要的参数 max.message.bytes默认为 1000012,即 1M,生产者发送给broker消息的最大字节数。默认值是1000012,也就是1MB。生产者发送的消息超过该设置,会被broker拒绝接收,并且会收到broker的错误报告。
即在 Filebeat 中会收到如下报错信息:
2019-03-05T09:39:33.611+0800 ERROR kafka/client.go:131 Dropping event: no topic could be selected
2019-03-05T09:39:33.611+0800 ERROR kafka/client.go:131 Dropping event: no topic could be selected
2019-03-05T09:39:33.611+0800 ERROR kafka/client.go:131 Dropping event: no topic could be selected
所以解决这个问题有两种办法:
- 第一:日志标准化,每个日志文件的大小定义不超过
1M - 第二:增大``max.message.bytes`的数值
0x04 启动 comsumer 实例
Kafka中的消费者会主动到broker中拉取指定topic中指定patition中的消息。
如果用脚本启动消费者,如下:
# bin/kafka-console-consumer.sh --bootstrap-server 192.168..7.3:9092,192.168..7.3:9093,192.168..7.3:9094 --topic nginx --from-beginning
- bootstrap-server:为我们启动的broker实例,多个实例用
,隔开 - topic:消息主题
- from-beginning:从消息第一条消息开始消费
当然我们会更热衷于用 supervisord 启动消费者。此处只举一个例子,后续的消费者参考此配置即可。
在前面创建topic时,我们的配置文件中 server.properties 配置的参数 num.partitions=1,所以,每当我们自动创建一个topic的同时,也会为这个topic创建一个 partition。因此,对于每一个partition均要分配一个消费者。就拿一个消费system日志的消费者举例。
在 /etc/supervisord.d 中创建配置文件 kafka-consumer-system-1.ini,文件中写入如下配置:
[program:EFK-kafka-consumer-system-1]
directory=/usr/local/kafka_2.11-2.1.0/bin/
# bootstrap-server 指定broker实例
# topic 指定消费主题
# group 指定消费者归属于哪个消费者组,不用提前创建组名,直接指定组名,即创建消费者组
# partition 指定消费者消费 topic 中的哪个partition
# consumer.config 指定消费者的配置文件,每一个消费者一个单独的配置文件
command=/usr/local/kafka_2.11-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server 192.168.7.3:9092,192.168.7.3:9093,192.168.7.3:9094 --topic system --group system --partition 0 --consumer.config /usr/local/kafka_2.11-2.1.0/config/consumer-system-1.properties
autostart=true
startsecs=1
stderr_logfile=/var/log/supervisor/kafka-consumer-system-1_stderr.log
stdout_logfile=/var/log/supervisor/kafka-consumer-system-1_stdout.log
user=root
redirect_stderr=true
stdout_logfile_maxbytes=20MB
stdout_logfile_backups=10
接下来聊聊消费者的配置文件,默认放置于/usr/local/kafka_2.11-2.1.0/config目录下的consumer.properties,为了实现标准化,对每一个消费者的配置文件命名规范,做一个限制:consumer-topic名字-第几个消费者。
bootstrap.servers=192.168.7.3:9092,192.168.7.3:9093,192.168.7.3:9094
group.id=system
# 自动将偏移重置为最新偏移
auto.offset.reset=latest
# 会话超时时间
session.timeout.ms=15000
# 消费者在获取更多记录之前可以闲置的时间量
max.poll.interval.ms=60000
# 一次调用poll()时返回的最大记录数。
max.poll.records=400
# 发出请求时传递给服务器的id字符串
client.id=system1
# 心跳间隔时间
heartbeat.interval.ms=5000
启动消费者
# supervisorctl update
在 supervisord 的前端页面,点击 EFK-kafka-consumer-system-1中的 Tail -f,查看进程启动的日志,当然,我们还没有启动生产者(Filebeat),此时当然没有消息可以被消费啦!
4.EFK 架构部署之 Logstash 配置
0x01 Logstash 介绍
Logstash 由三个插件组成:
- INPUTS:输入端
- FILTERS:过滤端
- OUTPUTS:输出端
如下图,信息源通过 INPUT插件传入 Logstash,然后我们可以根据我们自己的需求,通过 Filter 插件将过滤出我们想要的日志,例如 message中包含 error的日志,则可以在这里配置。过滤完后,再输入到 OUTPUT插件中,选择输出的目的地。
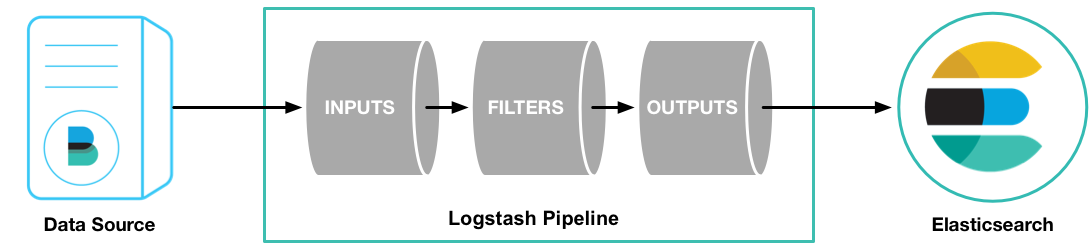
一个 Logstash的 pipeline至少需要 INPUT 和 OUTPUT。
0x02 配置 log4j2.properties
rmp包安装的Logstash主要的文件目录有两个:
/usr/share/logstash:logstash的安装目录/etc/logstash/:logstash的主配置文件目录
在 /usr/share/logstash 下,需要创建一个 config 目录:
# mkdir -p /usr/share/logstash/config
# cp /etc/logstash/log4j2.properties /usr/share/logstash/config
# chown -R logstash:logstash /usr/share/logstash
如果此步骤没有执行,在后面启动 logstash 时,会有提示/usr/share/logstash/config目录下,缺少log4j2.properties文件。
0x02 supervisord 方式部署
我们只需要配置INPUT和OUTPUT,FILTER根据实际需求,匹配过滤。
在 /etc/logstash/conf.d下创建 indexer-system.conf 文件,配置如下内容:
input {
kafka {
bootstrap_servers => "192.168.7.3:9092,192.168.7.3:9093,192.168.7.3:9094"
group_id => "system"
topics => "system"
auto_offset_reset => "latest"
decorate_events => true
codec => "json"
}
}
output {
elasticsearch {
hosts => ["192.168.7.3:9200"]
# 根据kafka 中 topic 的名字创建索引,并以天为单位
index => "%{[@metadata][kafka][topic]}-%{+YYYY.MM.dd}"
}
}
如果仔细的话,发现我们只接受了 kafka 中 topic 为 system 的日志,并在ES中给system类型的日志创建了索引;而且我们给文件取的名字 indexer-system.conf也包含一个 system 的名字。
因此,我们需要给每一个 topic 创建一个 indexer文件,并配置不同的 topic 和 group_id。
# pwd
/etc/logstash/conf.d
# ls
indexer-mysql.conf indexer-nginx.conf indexer-php.conf indexer-system.conf
如上,我给 topic 为mysql、nginx、php、system分别创建了一个 indexer 文件
然后,我们用 supervisord 启动 indexer-system.conf
在 /etc/supervisord.d 目录下,创建 logstash-indexer-system.ini的配置文件,输入一下内容
[program:EFK-logstash-indexer-system]
directory=/etc/logstash
# 启动logstash时,指定indexer-system.conf配置文件,指定数据存储目录indexer-system
command=/usr/bin/logstash -f /etc/logstash/conf.d/indexer-system.conf --path.data=/tmp/indexer-system
startsecs=1
stderr_logfile=/var/log/supervisor/logstash-indexer-system_stderr.log
stdout_logfile=/var/log/supervisor/logstash-indexer-system_stdout.log
user=logstash
redirect_stderr=true
stdout_logfile_maxbytes=20MB
stdout_logfile_backups=10
启动 logstash
# supervisorctl update
配置完毕!
注意:对于每一个logstash的indexer,我们都需要指定一个 indexer的配置文件;并配置一个数据存放的目录,不需要提前创建该目录,但是,不同的 indexer一定要存放在不同的目录。
5.EFK 架构部署之supervisord方式启动Kibana
由于kibana的启动方式直接运行/usr/local/kibana-6.6.0-linux-x86_64/bin下的 kibana即可,不过多解释,直接supervisord部署。
在 /etc/supervisord.d 目录下,创建 kibana.ini 配置文件:
[program:EFK-kibana]
directory=/usr/local/kibana-6.6.0-linux-x86_64
command=/usr/local/kibana-6.6.0-linux-x86_64/bin/kibana
startsecs=1
stderr_logfile=/var/log/supervisor/kibana_stderr.log
stdout_logfile=/var/log/supervisor/kibana_stdout.log
user=root
redirect_stderr=true
stdout_logfile_maxbytes=20MB
stdout_logfile_backups=10
启动 kibana
# supervisorctl update
浏览器访问:http://http😕/192.168.7.3:5601
6.EFK 日志收集系统之Filebeat配置
Filebeat 是我们的日志采集端,即每台机器上都需要安装 Filebeat,并配置不同的日志路径。
在 Filebeat 的主配置文件 /etc/filebeat/filebeat.yml 下配置如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/boot.log
- /var/log/messages
- /var/log/secure
fields:
log_topic: system
server_ip: "192.168.7.3"
- type: log
enabled: true
paths:
- /var/log/mysqld.log
fields:
log_topic: mysql
server_ip: "192.168.7.3"
output.kafka:
enabled: true
hosts: ["192.168.7.3:9092","192.168.7.3:9093","192.168.7.3:9094"]
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: false
codec.json:
pretty: false
escape_html: true
metadata:
retry.max: 3
refresh_frequency: 10m
worker: 1
max_retries: 3
bulk_max_size: 2048
timeout: 30s
broker_timeout: 10s
channel_buffer_size: 256
keep_alive: 0
required_acks: 1
compression: gzip
compression_level: 4
max_message_bytes: 1000000
client_id: beats
close_older: 30m
force_close_files: true
#没有新日志采集后多长时间关闭文件句柄,默认5分钟,设置成1分钟,加快文件句柄关闭;
close_inactive: 1m
#传输了3h后荏没有传输完成的话就强行关闭文件句柄,这个配置项是解决以上案例问题的key point;
close_timeout: 3h
##这个配置项也应该配置上,默认值是0表示不清理,不清理的意思是采集过的文件描述在registry文件里永不清理,在运行一段时间后,registry会变大,可能会带来问题。
clean_inactive: 72h
#设置了clean_inactive后就需要设置ignore_older,且要保证ignore_older < clean_inactive
ignore_older: 70h
# 限制 CPU和内存资源
max_procs: 1
queue.mem.events: 256
queue.mem.flush.min_events: 128
Filebeat默认是将采集的日志输入到ES中的,所以要注释掉/etc/filebeat/filebeat.yml中的 output.elasticsearch,在 Filebeat 中只允许有一个 output。
启动 Filebeat
# systemctl start filebeat
# systemctl enable filebeat
启动 Filebeat 后,我们可以通过如下命令查看 Filebeat 的日志:
# tail -f /var/log/filebeat/filebeat
配置完毕!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号