面向对象课程第一次随笔
一、基于度量分析程序结构
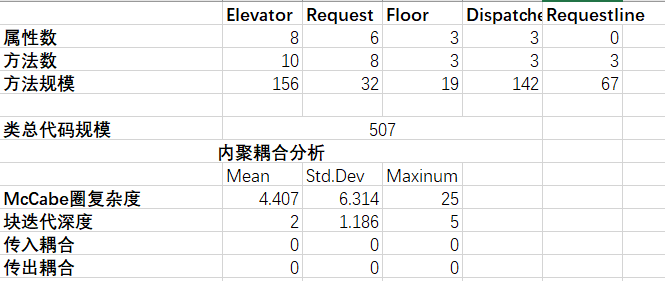
第一次作业

第二次作业
第三次作业
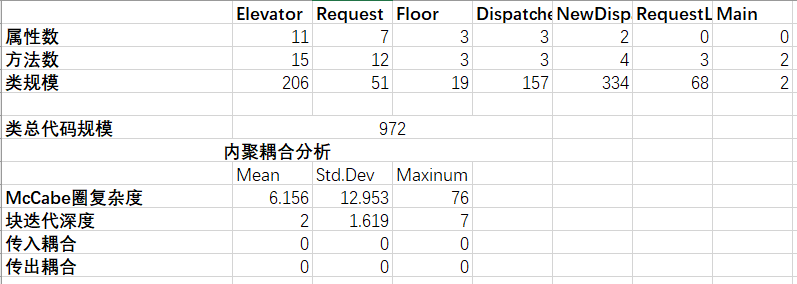
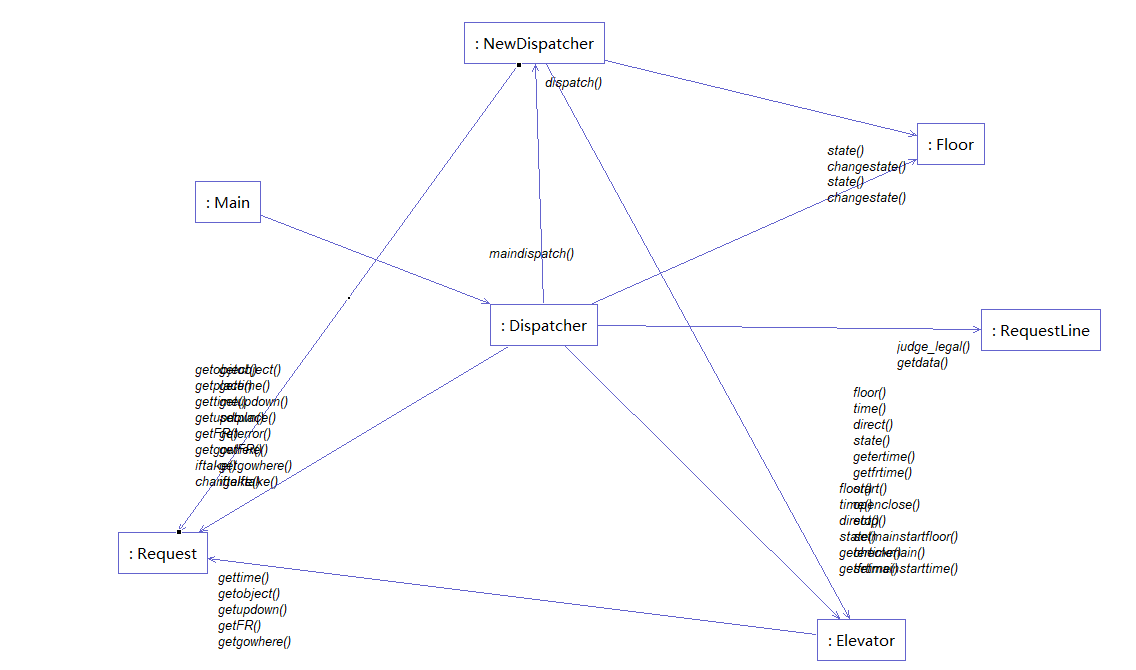
类图(以第三次作业为例)
这学期进行oo课程之前,我并没有接触过面向对象的编程方法,从以上第一次课程作业可以看出,我在对类的设计依然是过程式的思维,只是将传统的过程式变成划分为了多个类,而将每个类的方法简单的看作实现整个程序的函数。由于第一次作业较为简单,我并没有因此而产生许多bug,但自己这样设计是违反面向对象的编程思想的。
第二次作业和第三次作业都是电梯,区别在与调度策略不同。吸取了上次的经验教训,我的设计流程如下
(1)划分类,例如电梯类,楼层类,调度器类等。
(2)思考每个类要实现的功能
(3)确定每个类的方法和属性
(4)确定每个类之间的协作关系
这样设计,以对象作为设计单位,每个对象内的属性全部为private。代码的结构比较清晰,勉勉强强算一个面向对象程序吧。写代码过程中,我发现,这样写代码比较容易维护和查找bug,实现对代码的分块管理。
在第三次作业中,引入了继承和接口的面向对象基本概念,我虽然按照课程设计的要求进行了使用,但是由于第三次作业基于第二次作业的基础上修改,我的设计出现了很大的问题。
该次作业在第二次作业的基础上对调度器类进行继承Dispatcher->NewDispatcher(Schedule),并利用接口的来归纳电梯的运动状态。我在继承调度器类的时候,并没有想好怎么设计新的调度规则。我重载了自己的dispatch方法,也就是调度方法,在第二次作业中,该方法就略显复杂,这一次直接导致该方法复杂度爆炸,并且出现了许多bug,险些导致笔者的这次作业failed。
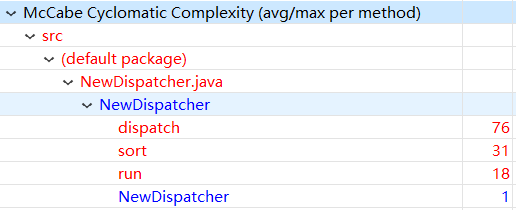
注:可以看出该方法的圈复杂度高到恐怖
总体来说,对第三次作业来说,我的作业由于没有很好地规划新的调度逻辑,导致了某些方法和类承担了过多本不该自己承担的任务。
二、Bug分析
第一次作业
无bug被查出,自己最开始写的时候不会正则倒是出了不少bug
第二次作业
(1)错误分支:忽略不同时的同质请求
在进行程序设计时,我在楼层类内有一个数组,记录在有楼层请求时,该数组记录电梯到达该楼层的时间。但是在考虑同质请求时,会用到该数组记录的时间。但是,楼层的同质请求是区分上行键和下行键的。单纯通过这个时间来判断实际上忽略了上行和下行,导致了bug。
bug位置:Floor类
第三次作业
(1)错误分支 :WFS状态,不捎带
错误是由于我在进行时间计算时,在输出为still状态时将开关门算了两次,非常不细心导致的bug,在课下的测试中意外的没有被发现。
bug位置:电梯类,run方法
(2)错误分支:主请求选取顺序
错误是由于我在进行选取下一个主请求的方法中有一个循环,我在写这个循环时失误将循环的初始值作为了循环变量,非常蠢。
bug位置:NewDispatcher类,dispatch方法
(3)错误分支:请求完成时间
导致错误原因有二,一是因为错误分支(1)中的原因,二是因为我在判断捎带和同质时,是先判断捎带,再判断同质。这样判断,在大部分的情况下,同质指令依然会被正确检测,但是当两条指令同质而前一条作为主指令,后一条不会被捎带时,会导致同质请求判断错误。
bug位置:NewDispatcher类,dispatch方法
从问题很多的第三次作业来看,包括我在课下测试调试中发现的问题,大部分问题发生在dispatch方法中和该方法与电梯类协调时,可见讲一个类的功能特别复杂,就容易导致管理麻烦,而且出现bug。合理划分功能给各个类与方法可以一定程度上避免这些问题。(笔者已经准备将第三次代码重构了)
三、测试中的策略
(1)查看错误分支树
错误分支树基本涵盖了我们可能出现的bug,我首先根据错误分支树,对每个分支构造较小的数据。
(2)利用C代码去 构造较大的数据去测试
大一些的数据可能会覆盖到小数据覆盖不到的各种情况。
(3)阅读测试程序代码并分析结构
这一点我做的不好,在测试时去检查一份和个人思路不同的代码是十分困难的,个人读完一遍除非是明显的漏洞,能力所限,很难读出bug。所以经常根据以上两条来进行测试。
在这次写博客分析代码结构的过程中,我发现通过metrics等工具分析代码结构也是不错的选择。我自身的bug往往出现在迭代次数多,代码长度长,圈复杂度高的区域,利用这点来寻找代码的脆弱部分应该也是可行的。
四、心得体会
(1)这门课之前,我没有写过任何面向对象的程序。接触了面向对象后,相当于多了一种看待程序设计的方式。同样是从想要的结果出发,曾经我写的过程式程序,考虑最多的是有什么函数,实现什么功能,通过怎样的的流程来完成一个程序。而面向对象的程序设计方法,是从程序要实现的功能入手,将程序由流程变为各个对象之间的交互(个人理解)
(2)多考虑一些情况,永远也不要让你的程序crash。作为写程序的人,我们需要对自己的程序负责,采取措施防止它破坏。
(3)程序不是从头写到尾,先构思好设计好,才能减少修改次数,少出bug。这一点在去年的计组课上我就深有体会,然而面向对象课的不同在于,没有人会指导你如何设计,你需要自己构思自己的代码架构,这对我来说并不容易。
(4)曾经我以为,我会花很多心思在找别人的bug上,现在我发现,大部分时间都在敲自己的代码,测试自己的程序。帮助他人测试的过程,对我来说,更像是学习大佬的设计。一些同学的程序让我从中学习到了不少东西(正则怎么写,怎么设计方法)。
PS:一点补充,关于圈复杂度与bug的产生
“圈复杂度(Cyclomatic Complexity)是一种代码复杂度的衡量标准。它可以用来衡量一个模块判定结构的复杂程度,数量上表现为独立现行路径条数,也可理解为覆盖所有的可能情况最少使用的测试用例数。圈复杂度大说明程序代码的判断逻辑复杂,可能质量低且难于测试和维护。程序的可能错误和高的圈复杂度有着很大关系。”
简单来讲,圈复杂度越大代表你的程序要测试的可能性越多,代码越难以维护。
圈复杂度计算公式 V(G) = e - n + 2。e代表程序流程图中的边数,n代表节点数。
举例计算在网上可以自行查看,在这里不多赘述。
基本上来说,如果你使用非常多的if.....else语句,那么圈复杂度会比较高。
拿第三次作业中我的一段出现bug的代码为例
if((requesttake[k].getFR()<=aim_floor && direct == 0)||(requesttake[k].getFR()>=aim_floor && direct == 1)) { taking = true; if(((requesttake[k].getFR()==aim_floor && direct == 0)||(requesttake[k].getFR()==aim_floor && direct == 1))&& requesttake[k].gettime()>=requestlist[main].gettime()){ if(requesttake[k].gettime()==requestlist[main].gettime()) { if(requesttake[k].getplace()>requestlist[main].getplace()) { break; } } else { break; } } if(run(requesttake,k)==1) { requestlist[requesttake[k].getplace()].changeiftake(true); k++; if(origin_floor != elevator.floor()) { i++; } origin_floor = elevator.floor(); } }
显然这段代码非常不好,非常多的if..else就像这样
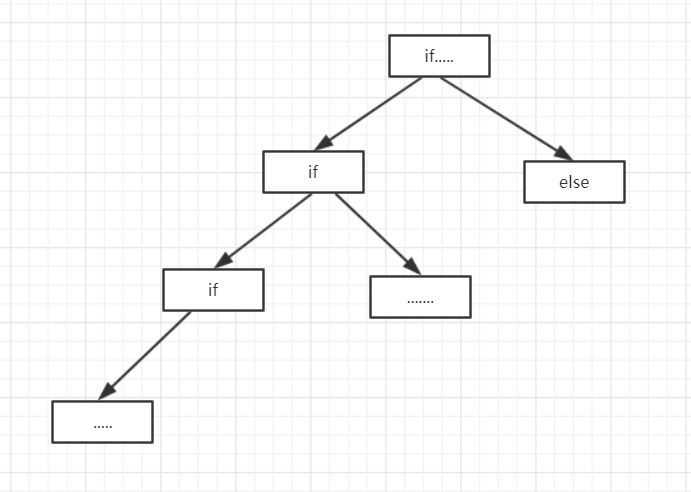
很难覆盖化测试而且非常容易出现bug。
此外,我的一个不好的习惯也是导致这段代码变成这个样子的原因。第三次作业中出现的bug,往往是来源于有些情况没有考虑或者现有机制处理错误。我经常在此基础上加入简单的条件语句来使bug变为一种特殊情况,修正bug。这样带来的后果就是本来代码脆弱的部分就越来越臃肿,越来越难以维护,圈复杂度提升,整体的方差也上升很快。
望引以为戒。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号