

图书信息库完整解决方案(三)解析图书分类
经过综合对比分析(此处省略几千字),最终选定了HtmlUnit作为网页解析的工具。
通过maven来引入HtmlUnit资源包:
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.28</version>
</dependency>
下面是解析图书分类的核心逻辑,大量的精力是要放在分析网页源码上,从中找出一级级的节点规律,然后再解析出自己需要的数据。
public List<BookCategory> categoryFromDangdang() { List<BookCategory> lsCategory = new LinkedList<BookCategory>(); String categoryUrl = "http://category.dangdang.com/?ref=www-0-C"; try { HtmlPage page = webClientGetPage(categoryUrl,false, false, null); List<DomElement> ll = page.getElementsByTagName("div"); DomElement bookElement = null; for(int i=0;i<ll.size();i++) { DomElement e = ll.get(i); String s = e.getAttribute("class"); if(s.equalsIgnoreCase("classify_con")) { System.out.println("find book. class="+s); //在整个html中找到图书的一级节点 bookElement = e; break; } } if(bookElement != null) { DomElement eClassify_books = bookElement.getFirstElementChild().getFirstElementChild(); String s = eClassify_books.getAttribute("class"); //找到图书分类的解析区域 if(s.equalsIgnoreCase("classify_books")) { System.out.println("find classify_books. class="+s); String rootCategory = ""; Iterable<DomElement> elementIterable = eClassify_books.getChildElements(); for (java.util.Iterator<DomElement> i = elementIterable.iterator(); i.hasNext(); ) { DomElement e = (DomElement) i.next(); s = e.getAttribute("class"); //图书分类的描述 if(s.equalsIgnoreCase("classify_books_detail")) { DomElement eRoot = e.getElementsByTagName("h3").get(0).getFirstElementChild(); String url = eRoot.getAttribute("href"); String name = eRoot.getTextContent(); rootCategory = urlToCategory(url); System.out.println("find book rootCategory." + " name=" + name + " category=" + rootCategory); } //图书具体分类 else if(s.indexOf("classify_kind") != -1) { DomElement eCategory = e.getFirstElementChild().getFirstElementChild(); String url = eCategory.getAttribute("href"); String name = eCategory.getTextContent(); String category = urlToCategory(url); if(category.equalsIgnoreCase("cp01.59.00.00.00.00"))//繁体字显示有问题 name = "港台图书"; System.out.println("find book category. " + " name=" + name + " category=" + category); BookCategory bookCategory = new BookCategory(); bookCategory.setTitle(name); bookCategory.setCategory(category); bookCategory.setCategory_parent(rootCategory); bookCategory.setCache(0); lsCategory.add(bookCategory); //二级分类 DomElement ul = e.getElementsByTagName("ul").get(0); DomNodeList<HtmlElement> ulList = ul.getElementsByTagName("li"); for(int j=0;j<ulList.size();j++) { HtmlElement he = ulList.get(j); if(he.getAttribute("name").equalsIgnoreCase("cat_3")) { DomElement eSubCategory = he.getFirstElementChild(); url = eSubCategory.getAttribute("href"); name = eSubCategory.getTextContent(); String subCategory = urlToCategory(url); System.out.println("===========find book sub category. " + " name=" + name + " category=" + subCategory); BookCategory bookSubCategory = new BookCategory(); bookSubCategory.setTitle(name); bookSubCategory.setCategory(subCategory); bookSubCategory.setCategory_parent(category); bookSubCategory.setCache(1); lsCategory.add(bookSubCategory); } } } } } } //stringToFile(result,"E:\\category.html"); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); System.out.println("Exception="+e); } System.out.println("find book category finish. "); return lsCategory; }
解析出来的分类如下图所示:
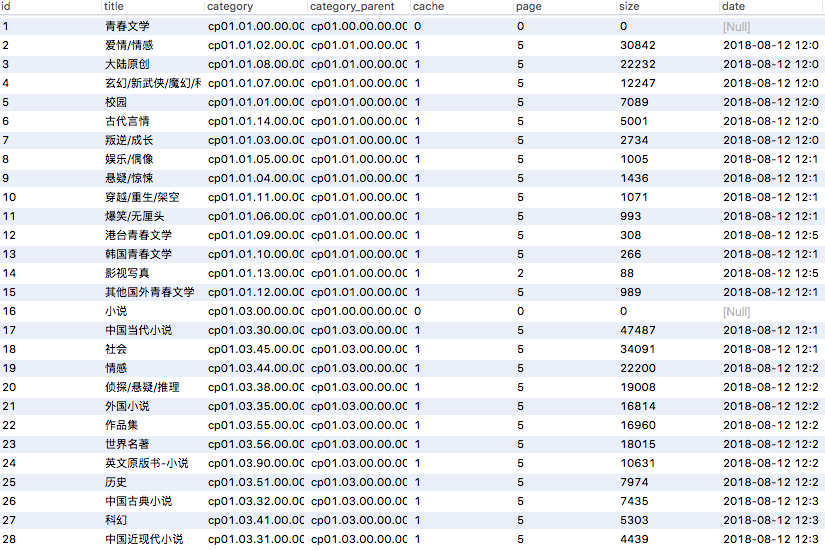
这样就获取到了当当的所有图书分类,因为分类数据只有一个页面,所以相对比较简单一些。
另外还可以解析分类下的第一个页面,从而可以获取到关联分类下的网页页数和图书数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号