

第八周作业
-
-
LVS常用模型工作原理,及实现。
-
LVS的负载策略有哪些,各应用在什么场景,通过LVS DR任意实现1-2种场景。
-
web http协议通信过程,相关技术术语总结。
-
总结网络IO模型和nginx架构。
-
nginx总结核心配置和优化。
-
使用脚本完成一键编译安装nginx任意版本。
-
1、哨兵模式
在 redis3.0之前,redis使用的哨兵架构,它借助 sentinel 工具来监控 master 节点的状态;如果 master 节点异常,则会做主从切换,将一台 slave 作为 master。
哨兵模式的缺点:
(1)当master挂掉的时候,sentinel 会选举出来一个 master,选举的时候是没有办法去访问Redis的,会存在访问瞬断的情况;若是在电商网站大促的时候master给挂掉了,几秒钟损失好多订单数据;
(2)哨兵模式,对外只有master节点可以写,slave节点只能用于读。尽管Redis单节点最多支持10W的QPS,但是在电商大促的时候,写数据的压力全部在master上。
(3)Redis的单节点内存不能设置过大,若数据过大在主从同步将会很慢;在节点启动的时候,时间特别长;(从节点上有主节点的所有数据)
2、Redis集群
2.1、Redis集群的介绍
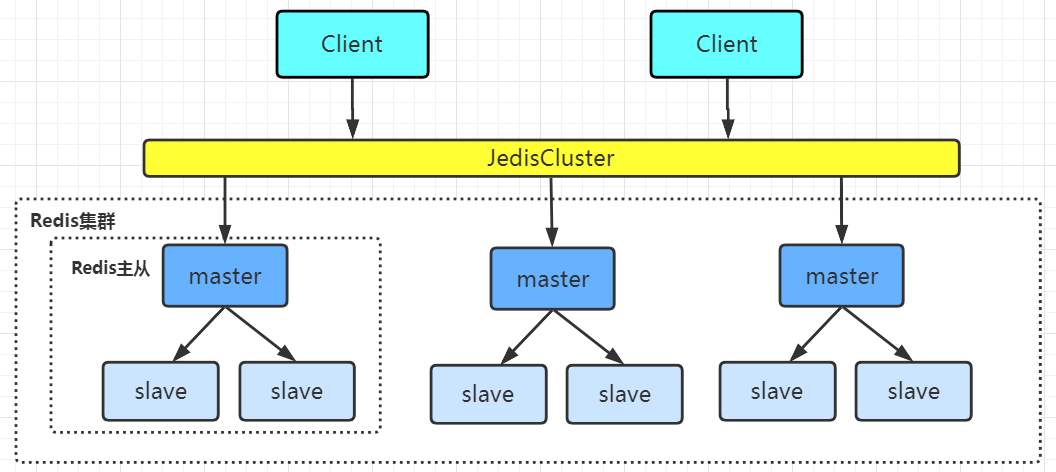
Redis集群是一个由多个主从节点群组成的分布式服务集群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。
2.2、Redis集群的优点:
(1)Redis集群有多个master,可以减小访问瞬断问题的影响;
若集群中有一个master挂了,正好需要向这个master写数据,这个操作需要等待一下;但是向其他master节点写数据是不受影响的。
(2)Redis集群有多个master,可以提供更高的并发量;
(3)Redis集群可以分片存储,这样就可以存储更多的数据;
2.3、Redis集群的搭建
Redis的集群搭建最少需要3个master节点,我们这里搭建3个master,每个下面挂一个slave节点,总共6个Redis节点;(3台机器,每台机器一主一从)
第1台机器: 192.168.1.1 8001端口 8002端口
第2台机器: 192.168.1.2 8001端口 8002端口
第3台机器: 192.168.1.3 8001端口 8002端口
第一步:创建文件夹
mkdir -p /usr1/redis/redis-cluster/8001 /usr1/redis/redis-cluster/8002
第二步:将redis安装目录下的 redis.conf 文件分别拷贝到8001目录下
cp /usr1/redis-5.0.3/redis.conf /usr1/redis/redis-cluster/8001
第三步:修改redis.conf文件以下内容

port 8001 daemonize yes pidfile "/var/run/redis_8001.pid" #指定数据文件存放位置,必须要指定不同的目录位置,不然会丢失数据 dir /usr1/redis/redis-cluster/8001/ #启动集群模式 cluster-enabled yes #集群节点信息文件,这里800x最好和port对应上 cluster-config-file nodes-8001.conf # 节点离线的超时时间 cluster-node-timeout 5000 #去掉bind绑定访问ip信息 #bind 127.0.0.1 #关闭保护模式 protected-mode no #启动AOF文件 appendonly yes #如果要设置密码需要增加如下配置: #设置redis访问密码 requirepass redis-pw #设置集群节点间访问密码,跟上面一致 masterauth redis-pw
第四步,把上面修改好的配置文件拷贝到8002文件夹下,并将8001修改为8002:
cp /usr1/redis/redis-cluster/8001/redis.conf /usr1/redis/redis-cluster/8002 cd /usr1/redis/redis-cluster/8002/ vim redis.conf #批量修改字符串 :%s/8001/8002/g
第五步,将本机(192.168.1.1)机器上的文件拷贝到另外两台机器上
scp /usr1/redis/redis-cluster/8001/redis.conf root@192.168.1.2:/usr1/redis/redis-cluster/8001/ scp /usr1/redis/redis-cluster/8002/redis.conf root@192.168.1.2:/usr1/redis/redis-cluster/8002/
scp /usr1/redis/redis-cluster/8001/redis.conf root@192.168.1.3:/usr1/redis/redis-cluster/8001/ scp /usr1/redis/redis-cluster/8002/redis.conf root@192.168.1.3:/usr1/redis/redis-cluster/8002/
第六步,分别启动这6个redis实例,然后检查是否启动成功
/usr1/redis/redis-5.0.3/src/redis-server /usr1/redis/redis-cluster/8001/redis.conf /usr1/redis/redis-5.0.3/src/redis-server /usr1/redis/redis-cluster/8002/redis.conf
ps -ef | grep redis

第七步,使用 redis-cli 创建整个 redis 集群(redis5.0版本之前使用的ruby脚本 redis-trib.rb)
运行以上命令,完成搭建
/usr1/redis/redis-5.0.3/src/redis-cli -a redis-pw --cluster create --cluster-replicas 1 192.168.1.1:8001 192.168.1.1:8002 192.168.1.2:8001 192.168.1.2:8002 192.168.1.3:8001 192.168.1.3:8002

说明:
-a :密码;
--cluster-replicas 1:表示1个master下挂1个slave; --cluster-replicas 2:表示1个master下挂2个slave。
扩展:
查看帮助命令: src/redis‐cli --cluster help
create:创建一个集群环境host1:port1 ... hostN:portN call:可以执行redis命令 add-node:将一个节点添加到集群里,第一个参数为新节点的ip:port,第二个参数为集群中任意一个已经存在的节点的ip:port del-node:移除一个节点 reshard:重新分片 check:检查集群状态
第八步,验证集群
(1)连接任意一个客户端
/usr1/redis/redis-5.0.3/src/redis-cli -a redis-pw -c -h 192.168.1.1 -p 8001
说明:‐a表示服务端密码;‐c表示集群模式;-h指定ip地址;-p表示端口号
(2)查看集群的信息: cluster info
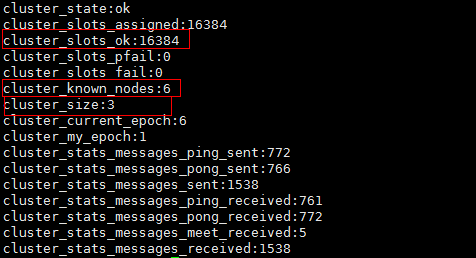
(3) 查看节点列表: cluster nodes slave 对应的 master 从上面也可以看到;
从上面可以看到 slave挂在哪个 master 下面;

在 /usr1/redis/redis-cluster/8001/nodes-8001.conf 文件中存储了节点信息;
(4)进行数据操作验证;
(5)关闭集群则需要逐个进行关闭,使用命令:
/usr/local/redis‐5.0.3/src/redis‐cli ‐a redis-pw ‐c ‐h 192.168.1.1 ‐p 8001 shutdown /usr/local/redis‐5.0.3/src/redis‐cli ‐a redis-pw ‐c ‐h 192.168.1.1 ‐p 8002 shutdown ......
注意:在创建集群的时候,需要把所有节点机器上的防火关闭,保证 Redis的服务端口和集群节点通信的 gossip 端口能通;
systemctl stop firewalld # 临时关闭防火墙
systemctl disable firewalld # 禁止开机启动
3、Redis集群原理分析
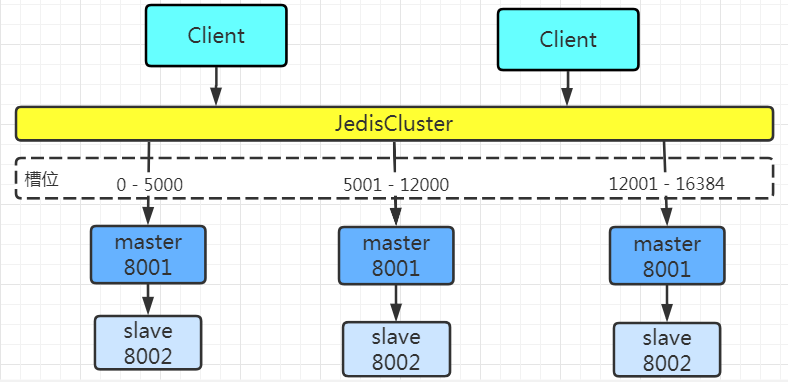
Redis Cluster 将所有数据划分为 16384 个 slots(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。只有master节点会被分配槽位,slave节点不会分配槽位。
当Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息,并将其缓存在客户端本地。这样当客户端要查找某个 key 时,可以直接定位到目标节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
槽位定位算法
Cluster 默认会对 key 值使用 crc16 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
HASH_SLOT = CRC16(key) % 16384
跳转重定位
当客户端向一个节点发出了指令,首先当前节点会计算指令的 key 得到槽位信息,判断计算的槽位是否归当前节点所管理;若槽位不归当前节点管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。客户端收到指令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有 key 将使用新的槽位映射表。

Redis集群节点之间的通信机制
维护集群的元数据有集中式和 gossip两种方式,Redis 的集群节点之间的通信采取 gossip 协议进行通信
(1)集中式:
优点:元数据的更新和读取,时效性非常好,一旦元数据出现变更立即就会更新到集中式的存储中,其他节点读取的时候立即就可以立即感知到;
缺点:所有的元数据的更新压力全部集中在一个地方,可能导致元数据的存储压力。zookeeper使用该方式
(2)gossip:
gossip协议包含多种消息,包括ping,pong,meet,fail等等。。
优点:元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力;
缺点:元数据更新有延时可能导致集群的一些操作会有一些滞后。
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如7001,那么用于节点间通信的就是17001端口。 每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几点接收到ping消息之后返回pong消息。
网络抖动
网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项 cluster-node-timeout ,表示当某个节点失联的时间超过了配置的 timeout时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
Redis集群选举原理
当 slave 发现自己的 master 变为 fail 状态时,便尝试进行 FailOver,以期成为新的 master。由于挂掉的 master 有多个 slave,所以这些 slave 要去竞争成为 master 节点,过程如下:
(1)slave1,slave2都 发现自己连接的 master 状态变为 Fail;
(2)它们将自己记录的集群 currentEpoch(选举周期) 加1,并使用 gossip 协议去广播 FailOver_auth_request 信息;
(3)其他节点接收到slave1、salve2的消息(只有master响应),判断请求的合法性,并给 slave1 或 slave2 发送 FailOver_auth_ack(对每个 epoch 只发一次ack); 在一个选举周期中,一个master只会响应第一个给它发消息的slave;
(4)slave1 收集返回的 FailOver_auth_ack,它收到超过半数的 master 的 ack 后变成新 master; (这也是集群为什么至少需要3个master的原因,如果只有两个master,其中一个挂了之后,只剩下一个主节点是不能选举成功的)
(5)新的master节点去广播 Pong 消息通知其他集群节点,不需要再去选举了。
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票。
延迟计算公式:DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
SLAVE_RANK:表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)
Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
集群是否完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
二、LVS常用模型工作原理,及实现。
一、负载均衡由来
在业务初期,我们一般会先使用单台服务器对外提供服务。随着业务流量越来越大,单台服务器无论如何优化,无论采用多好的硬件,总会有性能天花板,当单服务器的性能无法满足业务需求时,就需要把多台服务器组成集群系统提高整体的处理性能。不过我们要使用统一的入口方式对外提供服务,所以需要一个 流量调度器 通过均衡的算法,将用户大量的请求均衡地分发到后端集群不同的服务器上。这就是我们后边要说的 负载均衡。
使用负载均衡带来的好处:
-
提高了系统的整体性能
-
提高了系统的扩展性
-
提高了系统的可用性
二、负载均衡类型
广义上的负载均衡器大概可以分为 3 类,包括:DNS 方式实现负载均衡、硬件负载均衡、软件负载均衡。
2.1 DNS 实现负载均衡
DNS 实现负载均衡是最基础简单的方式。一个域名通过 DNS 解析到多个 IP,每个 IP 对应不同的服务器实例,这样就完成了流量的调度,虽然没有使用常规的负载均衡器,但也的确完成了简单负载均衡的功能。
通过 DNS 实现负载均衡的方式,最大的优点就是实现简单,成本低,无需自己开发或维护负载均衡设备,不过存在一些缺点:
-
服务器故障切换延迟大,服务器升级不方便。我们知道 DNS 与用户之间是层层的缓存,即便是在故障发生时及时通过 DNS 修改或摘除故障服务器,但中间由于经过运营商的 DNS 缓存,且缓存很有可能不遵循 TTL 规则,导致 DNS 生效时间变得非常缓慢,有时候一天后还会有些许的请求流量。
-
流量调度不均衡,粒度太粗。DNS 调度的均衡性,受地区运营商 LocalDNS 返回 IP 列表的策略有关系,有的运营商并不会轮询返回多个不同的 IP 地址。另外,某个运营商 LocalDNS 背后服务了多少用户,这也会构成流量调度不均的重要因素。
-
流量分配策略比较简单,支持的算法较少。DNS 一般只支持 RR 的轮询方式,流量分配策略比较简单,不支持权重、Hash 等调度算法。
-
DNS 支持的 IP 列表有限制。我们知道 DNS 使用 UDP 报文进行信息传递,每个 UDP 报文大小受链路的 MTU 限制,所以报文中存储的 IP 地址数量也是非常有限的,阿里 DNS 系统针对同一个域名支持配置 10 个不同的 IP 地址。
实际上生产环境中很少使用这种方式来实现负载均衡,毕竟缺点很明显。文中之所以描述 DNS 负载均衡方式,是为了能够更清楚地解释负载均衡的概念。一些大公司一般也会利用 DNS 来实现地理级别的负载均衡,实现就近访问,提高访问速度,这种方式一般是入口流量的基础负载均衡,下层会有更专业的负载均衡设备实现的负载架构。
2.2 硬件负载均衡
硬件负载均衡是通过专门的硬件设备来实现负载均衡功能,类似于交换机、路由器,是一个负载均衡专用的网络设备。目前业界典型的硬件负载均衡设备有两款:F5 和 A10。这类设备性能强劲、功能强大,但价格非常昂贵,一般只有 “土豪” 公司才会使用此类设备,普通业务量级的公司一般负担不起,二是业务量没那么大,用这些设备也是浪费。
硬件负载均衡的优点:
功能强大:全面支持各层级的负载均衡,支持全面的负载均衡算法。
性能强大:性能远超常见的软件负载均衡器。
稳定性高:商用硬件负载均衡,经过了良好的严格测试,经过大规模使用,稳定性高。
安全防护:除了具备负载均衡外,还具备防火墙、防 DDoS 攻击等安全功能,貌似还支持 SNAT 功能。
硬件负载均衡的缺点:
价格昂贵,就是贵。
扩展性差,无法进行扩展和定制。
调试和维护比较麻烦,需要专业人员。
注:至今没有用过硬件负载均衡,不过有幸曾经与 F5 有过一面之缘。
2.3 软件负载均衡
软件负载均衡,可以在普通的服务器上运行负载均衡软件,实现负载均衡功能。目前常见的有 Nginx、HAproxy、LVS。其中的区别:
Nginx :是 7 层负载均衡,支持 HTTP、E-mail 协议,貌似也支持 4 层负载均衡了。 HAproxy :是 7 层负载均衡软件,支持 7 层规则的设置,性能也很不错。OpenStack 默认使用的负载均衡软件就是 HAproxy。 LVS :是纯 4 层的负载均衡,运行在内核态,性能是软件负载均衡中最高的,因为是在四层,所以也更通用一些。
软件负载均衡的优点:
简单:无论是部署还是维护都比较简单。 便宜:买个 Linux 服务器,装上软件即可。 灵活:4 层和 7 层负载均衡可以根据业务进行选择;也可以根据业务特点,比较方便进行扩展和定制功能。
三、开源负载均衡器 LVS
软件负载均衡主要包括:Nginx、HAproxy 和 LVS。其实三款负载均衡软件都十分常用。四层负载均衡基本上都会使用 LVS,据了解如 BAT 等大厂都是 LVS 重度使用者,就是因为 LVS 非常出色的性能,能为公司节省很大成本。
了解到很多大公司使用的 LVS 都是定制版的,做过很多性能方面的优化,比开源版本性能会高出很多。目前只有淘宝开源过优化过的 alibaba/LVS,支持 FNAT 模式,但是也很久没有更新过了。另外爱奇艺去年开源出了 DPDK 版本的 LVS,名叫 DPVS,性能非常强悍。
目前较为熟悉的负载均衡软件是 LVS,且大部分中小型公司使用开源的 LVS 足够满足业务需求。
3.1 netfilter基本原理
LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡系统,所以要学习 LVS 之前必须要先简单了解 netfilter 基本工作原理。netfilter 其实很复杂也很重要,平时我们说的 Linux 防火墙就是 netfilter,不过我们平时操作的都是 iptables,iptables 只是用户空间编写和传递规则的工具而已,真正工作的是 netfilter。通过下图可以简单了解下 netfilter 的工作机制:
netfilter 是内核态的 Linux 防火墙机制,作为一个通用、抽象的框架,提供了一整套的 hook 函数管理机制,提供诸如数据包过滤、网络地址转换、基于协议类型的连接跟踪的功能。
通俗点讲,就是 netfilter 提供一种机制,可以在数据包流经过程中,根据规则设置若干个关卡(hook 函数)来执行相关的操作。netfilter 总共设置了 5 个点,包括:PREROUTING、INPUT、FORWARD、OUTPUT、POSTROUTING
PREROUTING :刚刚进入网络层,还未进行路由查找的包,通过此处;
INPUT :通过路由查找,确定发往本机的包,通过此处;
FORWARD :经路由查找后,要转发的包,在POST_ROUTING之前;
OUTPUT :从本机进程刚发出的包,通过此处;
POSTROUTING :进入网络层已经经过路由查找,确定转发,将要离开本设备的包,通过此处;
当一个数据包进入网卡,经过链路层之后进入网络层就会到达 PREROUTING,接着根据目标 IP 地址进行路由查找,如果目标 IP 是本机,数据包继续传递到 INPUT 上,经过协议栈后根据端口将数据送到相应的应用程序;应用程序处理请求后将响应数据包发送到 OUTPUT 上,最终通过 POSTROUTING 后发送出网卡。如果目标 IP 不是本机,而且服务器开启了 forward 参数,就会将数据包递送给 FORWARD 上,最后通过 POSTROUTING 后发送出网卡。
3.2 LVS基本原理
LVS 是基于 netfilter 框架,主要工作于 INPUT 链上,在 INPUT 上注册 ip_vs_in HOOK 函数,进行 IPVS 主流程,大概原理如图所示:
当用户访问 www.sina.com.cn 时,用户数据通过层层网络,最后通过交换机进入 LVS 服务器网卡,并进入内核网络层。 进入 PREROUTING 后经过路由查找,确定访问的目的 VIP 是本机 IP 地址,所以数据包进入到 INPUT 链上。 IPVS 是工作在 INPUT 链上,会根据访问的 vip+port 判断请求是否 IPVS 服务,如果是则调用注册的 IPVS HOOK 函数,进行 IPVS 相关主流程,强行修改数据包的相关数据,并将数据包发往 POSTROUTING 链上。 POSTROUTING 上收到数据包后,根据目标 IP 地址(后端服务器),通过路由选路,将数据包最终发往后端的服务器上。
开源 LVS 版本有 3 种工作模式,每种模式工作原理截然不同,说各种模式都有自己的优缺点,分别适合不同的应用场景,不过最终本质的功能都是能实现均衡的流量调度和良好的扩展性。主要包括以下三种模式:
DR 模式
NAT 模式
Tunnel 模式
另外必须要说的模式是 FullNAT,这个模式在开源版本中是模式没有的,代码 没有合并进入内核主线版本,后面会有专门章节详细介绍 FullNAT 模式。下边分别就 DR、NAT、Tunnel 模式分别详细介绍原理。
3.3 DR 模式实现原理
LVS 基本原理图(上图)中描述的比较简单,表述的是比较通用流程。下边会针对 DR 模式的具体实现原理,详细的阐述 DR 模式是如何工作的。
其实 DR 是最常用的工作模式,因为它的强大的性能。下边以一次请求和响应数据流的过程来描述 DR 模式的具体原理。
(一)实现原理过程
① 当客户端请求 www.sina.com.cn 主页,经过 DNS 解析到 IP 后,向新浪服务器发送请求数据,数据包经过层层网络到达新浪负载均衡 LVS 服务器,到达 LVS 网卡时的数据包:源 IP 是客户端 IP 地址 CIP,目的 IP 是新浪对外的服务器 IP 地址,也就是 VIP;此时源 MAC 地址是 CMAC,其实是 LVS 连接的路由器的 MAC 地址(为了容易理解记为 CMAC),目标 MAC 地址是 VIP 对应的 MAC,记为 VMAC。
② 数据包到达网卡后,经过链路层到达 PREROUTING 位置(刚进入网络层),查找路由发现目的 IP 是 LVS 的 VIP,就会递送到 INPUT 链上,此时数据包 MAC、IP、Port 都没有修改。
③ 数据包到达 INPUT 链,INPUT 是 LVS 主要工作的位置。此时 LVS 会根据目的 IP 和 Port 来确认是否是 LVS 定义的服务,如果是定义过的 VIP 服务,就会根据配置的 Service 信息,从 RealServer 中选择一个作为后端服务器 RS1,然后以 RS1 作为目标查找 Out 方向的路由,确定一下跳信息以及数据包要通过哪个网卡发出。最后将数据包通过 INET_HOOK 到 OUTPUT 链上(Out 方向刚从四层进入网络层)。
④ 数据包通过 POSTROUTING 链后,从网络层转到链路层,将目的 MAC 地址修改为 RealServer 服务器 MAC 地址,记为 RMAC;而源 MAC 地址修改为 LVS 与 RS 同网段的 selfIP 对应的 MAC 地址,记为 DMAC。此时,数据包通过交换机转发给了 RealServer 服务器(注:为了简单图中没有画交换机)。
⑤ 请求数据包到达 RealServer 服务器后,链路层检查目的 MAC 是自己网卡地址。到了网络层,查找路由,目的 IP 是 VIP(lo 上配置了 VIP),判定是本地主机的数据包,经过协议栈后拷贝至应用程序(比如这里是 nginx 服务器),nginx 响应请求后,产生响应数据包。以目的 VIP 为 dst 查找 Out 路由,确定吓一跳信息和发送网卡设备信息,发送数据包。此时数据包源、目的 IP 分别是 VIP、CIP,而源 MAC 地址是 RS1 的 RMAC,目的 MAC 是下一跳(路由器)的 MAC 地址,记为 CMAC(为了容易理解,记为 CMAC)。然后数据包通过 RS 相连的路由器转发给真正客户端。
从整个过程可以看出,DR 模式 LVS 逻辑非常简单,数据包通过路由方式直接转发给 RS,而且响应数据包是由 RS 服务器直接发送给客户端,不经过 LVS。我们知道一般请求数据包会比较小,响应报文较大,经过 LVS 的数据包基本上都是小包,上述几条因素是 LVS 的 DR 模式性能强大的主要原因。
(二)优缺点和使用场景
DR 模式的优点
a. 响应数据不经过 lvs,性能高
b. 对数据包修改小,信息保存完整(携带客户端源 IP)
DR 模式的缺点
a. lvs 与 rs 必须在同一个物理网络(不支持跨机房)
b. rs 上必须配置 lo 和其它内核参数
c. 不支持端口映射
DR 模式的使用场景
如果对性能要求非常高,可以首选 DR 模式,而且可以透传客户端源 IP 地址。
3.4 NAT 模式实现原理
lvs 的第 2 种工作模式是 NAT 模式,下图详细介绍了数据包从客户端进入 lvs 后转发到 rs,后经 rs 再次将响应数据转发给 lvs,由 lvs 将数据包回复给客户端的整个过程。
(一)实现原理与过程
① 用户请求数据包经过层层网络,到达 lvs 网卡,此时数据包源 IP 是 CIP,目的 IP 是 VIP。
② 经过网卡进入网络层 prerouting 位置,根据目的 IP 查找路由,确认是本机 IP,将数据包转发到 INPUT 上,此时源、目的 IP 都未发生变化。
③ 到达 lvs 后,通过目的 IP 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 RS 作为后端服务器,将数据包目的 IP 修改为 RIP,并以 RIP 为目的 IP 查找路由信息,确定下一跳和出口信息,将数据包转发至 output 上。
④ 修改后的数据包经过 postrouting 和链路层处理后,到达 RS 服务器,此时的数据包源 IP 是 CIP,目的 IP 是 RIP。
⑤ 到达 RS 服务器的数据包经过链路层和网络层检查后,被送往用户空间 nginx 程序。nginx 程序处理完毕,发送响应数据包,由于 RS 上默认网关配置为 lvs 设备 IP,所以 nginx 服务器会将数据包转发至下一跳,也就是 lvs 服务器。此时数据包源 IP 是 RIP,目的 IP 是 CIP。
⑥ lvs 服务器收到 RS 响应数据包后,根据路由查找,发现目的 IP 不是本机 IP,且 lvs 服务器开启了转发模式,所以将数据包转发给 forward 链,此时数据包未作修改。
⑦ lvs 收到响应数据包后,根据目的 IP 和目的 port 查找服务和连接表,将源 IP 改为 VIP,通过路由查找,确定下一跳和出口信息,将数据包发送至网关,经过复杂的网络到达用户客户端,最终完成了一次请求和响应的交互。
NAT 模式双向流量都经过 LVS,因此 NAT 模式性能会存在一定的瓶颈。不过与其它模式区别的是,NAT 支持端口映射,且支持 windows 操作系统。
(二)优点、缺点与使用场景
NAT 模式优点
a. 能够支持 windows 操作系统
b. 支持端口映射。如果 rs 端口与 vport 不一致,lvs 除了修改目的 IP,也会修改 dport 以支持端口映射。
NAT 模式缺点
a. 后端 RS 需要配置网关
b. 双向流量对 lvs 负载压力比较大
NAT 模式的使用场景
如果你是 windows 系统,使用 lvs 的话,则必须选择 NAT 模式了。
3.5 Tunnel 模式实现原理
Tunnel 模式在国内使用的比较少,不过据说腾讯使用了大量的 Tunnel 模式。它也是一种单臂的模式,只有请求数据会经过 lvs,响应数据直接从后端服务器发送给客户端,性能也很强大,同时支持跨机房。下边继续看图分析原理。
(一)实现原理与过程
① 用户请求数据包经过多层网络,到达 lvs 网卡,此时数据包源 IP 是 cip,目的 ip 是 vip。
② 经过网卡进入网络层 prerouting 位置,根据目的 ip 查找路由,确认是本机 ip,将数据包转发到 input 链上,到达 lvs,此时源、目的 ip 都未发生变化。
③ 到达 lvs 后,通过目的 ip 和目的 port 查找是否为 IPVS 服务。若是 IPVS 服务,则会选择一个 rs 作为后端服务器,以 rip 为目的 ip 查找路由信息,确定下一跳、dev 等信息,然后 IP 头部前边额外增加了一个 IP 头(以 dip 为源,rip 为目的 ip),将数据包转发至 output 上。
④ 数据包根据路由信息经最终经过 lvs 网卡,发送至路由器网关,通过网络到达后端服务器。
⑤ 后端服务器收到数据包后,ipip 模块将 Tunnel 头部卸载,正常看到的源 ip 是 cip,目的 ip 是 vip,由于在 tunl0 上配置 vip,路由查找后判定为本机 ip,送往应用程序。应用程序 nginx 正常响应数据后以 vip 为源 ip,cip 为目的 ip 数据包发送出网卡,最终到达客户端。
Tunnel 模式具备 DR 模式的高性能,又支持跨机房访问,听起来比较完美了。不过国内运营商有一定特色性,比如 RS 的响应数据包的源 IP 为 VIP,VIP 与后端服务器有可能存在跨运营商的情况,有可能被运营商的策略封掉。Tunnel 在生产环境确实没有使用过,在国内推行 Tunnel 可能会有一定的难度吧!
(二)优点、缺点与使用场景
Tunnel 模式的优点
a. 单臂模式,对 lvs 负载压力小
b. 对数据包修改较小,信息保存完整
c. 可跨机房(不过在国内实现有难度)
Tunnel 模式的缺点
a. 需要在后端服务器安装配置 ipip 模块
b. 需要在后端服务器 tunl0 配置 vip
c. 隧道头部的加入可能导致分片,影响服务器性能
d. 隧道头部 IP 地址固定,后端服务器网卡 hash 可能不均
e. 不支持端口映射
Tunnel 模式的使用场景
理论上,如果对转发性能要求较高,且有跨机房需求,Tunnel 可能是较好的选择。
3.6 涉及的概念术语
上述内容中涉及到很多术语或缩写,这里简单解释下具体的含义,便于理解。
CIP:Client IP,表示的是客户端 IP 地址。
VIP:Virtual IP,表示负载均衡对外提供访问的 IP 地址,一般负载均衡 IP 都会通过 Virtual IP 实现高可用。
RIP:RealServer IP,表示负载均衡后端的真实服务器 IP 地址。
DIP:Director IP,表示负载均衡与后端服务器通信的 IP 地址。
CMAC:客户端的 MAC 地址,准确的应该是 LVS 连接的路由器的 MAC 地址。
VMAC:负载均衡 LVS 的 VIP 对应的 MAC 地址。
DMAC:负载均衡 LVS 的 DIP 对应的 MAC 地址。
RMAC:后端真实服务器的 RIP 地址对应的 MAC 地址。
三、LVS的负载策略有哪些,各应用在什么场景,通过LVS DR任意实现1-2种场景。
LVS负载均衡之DR模式配置
DR 模式架构图:

操作步骤
实验环境准备:(centos7平台)

所有服务器上配置
# systemctl stop firewalld //关闭防火墙 # sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/sysconfig/selinux //关闭selinux,重启生效 # setenforce 0 //关闭selinux,临时生效 # ntpdate 0.centos.pool.ntp.org //时间同步 注意:realserver的网关需要指向DIP
步骤一:配置 router
1)打开 ip_forward
[root@router ~]# vim /etc/sysctl.conf net.ipv4.ip_forward = 1 [root@router ~]# sysctl -p
2)添加防火墙规则,指定客户端进来的规则,(此处使用 iptables 做的,也可以换成 firewalld来做)
[root@router ~]# iptables -F [root@router ~]# yum install iptables-services iptables [root@router ~]# iptables -t nat -A PREROUTING -p tcp --dport 80 -i ens33 -j DNAT --to-destination 10.10.10.110 //这条表示从 ens33(也就是192.168.1.31的)网卡进来访问80的包,DNAT到 10.10.10.110(也就是 LVS 调度器的 IP) [root@router ~]# [root@router ~]# iptables -t nat -A POSTROUTING -p tcp --dport 80 -o ens37 -j SNAT --to-source 10.10.10.120 //这条表示(为了客户端 192.168.1.35 访问 192.168.1.31 变成 10.10.10.120 访问10.10.10.110),这样可以实现 LVS 调度器能回客户端 如果不加这条的话,也可以在LVS 调度器上添加路由(route add default gw 10.10.10.120 指一个网关回去,因为 DNAT 的目标机器需要一个网关才能回给 client) [root@router ~]# iptables-save > /etc/sysconfig/iptables [root@router ~]# systemctl start iptables.service [root@router ~]# systemctl enable iptables.service
步骤二:配置 LVS 调度器
1)安装ipvsadm
[root@lvs-director ~]# yum install ipvsadm -y
2)配置调度规则
[root@lvs-director ~]# ipvsadm -A -t 10.10.10.110:80 -s rr [root@lvs-director ~]# ipvsadm -a -t 10.10.10.110:80 -r 10.10.10.11:80 -g //这里的 -g 就是表示使用直接路由模式,LVS 调度器就会把数据包调给 10.10.10.11 或 10.10.10.12 时,就只修改 MAC 地址,不修改目标 IP 直接路由过去 [root@lvs-director ~]# ipvsadm -a -t 10.10.10.110:80 -r 10.10.10.12:80 -g [root@lvs-director ~]# ipvsadm -ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 10.10.10.110:80 rr -> 10.10.10.11:80 Route 1 0 0 -> 10.10.10.12:80 Route 1 0 0
3)保存在文件中,设置为开机启动
[root@lvs-director ~]# [root@lvs-director ~]# ipvsadm -Sn > /etc/sysconfig/ipvsadm [root@lvs-director ~]# systemctl start ipvsadm [root@lvs-director ~]# systemctl enable ipvsadm
4) 由于下面会在 web服务器上面添加一个子接口 lo:0 10.10.10.110网卡,这样就会到导致 lvs 调度器过去的包可以成果过去,但是不会回来,因为回来时它会直接查找自己的 lo:0的10.10.10.110。所以需要加一个子接口 掩码给到 255.255.255.128。
[root@lvs-director ~]# ifconfig ens33:0 10.10.10.111 netmask 255.255.255.128
注意:如果用掩码 255.255.255.0 还是会出现ping 不通的情况,因为ping的时候 10.10.10.110和10.10.10.111掩码相同,优先级一样。而用225.225.225.128路由选择会优先使用10.10.10.111去ping
步骤三:配置realserver
在 realserver(web01和web02)上安装 nginx,并在不同的 web 服务器上建立不同的主页内容(方便测试),并启动。
1) 在 web01 服务器配置
[root@web01 ~]# yum install nginx -y [root@web01 ~]# echo "`hostname` `ifconfig ens33 |sed -n 's#.*inet \(.*\)netmask.*#\1#p'`" > /usr/share/nginx/html/index.html [root@web01 ~]# systemctl start nginx [root@web01 ~]# systemctl enable nginx
2) 在 web02 服务器配置
[root@web02 ~]# yum install nginx -y [root@web02 ~]# echo "`hostname` `ifconfig ens33 |sed -n 's#.*inet \(.*\)netmask.*#\1#p'`" > /usr/share/nginx/html/index.html [root@web02 ~]# systemctl start nginx [root@web02 ~]# systemctl enable nginx
3) 添加vip (不论后端有几个web服务器,都需要做)
# ifconfig lo:0 10.10.10.110 netmask 255.255.255.255 //注意掩码为4个255,想永久生效,可以写一个 ifcfg-lo:0 的网卡配置文件即可。
最好不要写成 ifconfig lo:0 10.10.10.110/32 的形式,用ifconfig 查掩码会出现四个0。
这一步是非常重要的,因为路由方式扔过来的包,目标 IP 不变,也就是说还是 10.10.10.120,只是通过找 10.10.10.11 或 10.10.10.12 的 MAC 地址扔过来的。
所以 web 服务器上也需要有一个 10.10.10.120 这个 IP 来解析;用 lo 网卡来虚拟就是为了尽量不要与 lvs 网卡造成 ARP 广播问题。
这里 netmask 为什么是4个 255,而不是 255.255.255.0?
如果为 255.255.255.0,那么 10.10.10.0/24 整个网络都无法和web服务器通讯。
4) 真实服务器把默认路由指向 router 同物理网段的 IP,可以临时加也可以直接写在配置文件里面,这里上面的环境准备已经写在了配置文件。 (web1 和 web2 都需要做) 临时加示例:
# route add default gw 10.10.10.120
5) 抑制 web 服务器上 IP 冲突问题 (web1 和 web2 都需要做)
# vim /etc/sysctl.conf net.ipv4.conf.lo.arp_ignore = 1 net.ipv4.conf.lo.arp_announce = 2 net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.all.arp_announce = 2 # sysctl -p
步骤四:在客户机上测试
[root@client ~]# curl 192.168.1.31 web01 10.10.10.11 [root@client ~]# curl 192.168.1.31 web02 10.10.10.12 [root@client ~]# curl 192.168.1.31 web01 10.10.10.11 [root@client ~]# curl 192.168.1.31 web02 10.10.10.12
从测试结果可以看出,轮循调度给后端web服务器了。至此dr模式就完成了。
四、web http协议通信过程,相关技术术语总结。
协议简介 HTTP 是在网络上传输HTML的协议,用于浏览器和服务器的通信 HTTP 协议构建于 TCP/IP 协议之上,是一个应用层协议,默认端口号是 80 HTTP 协议是以 ASCII 码传输,是无连接无状态的 请求报文 HTTP 请求分为三个部分:状态行、请求头、消息主体。类似于下面这样: 1 <method> <request-URL> <version> 2 <headers> 3 4 <entity-body> HTTP 定义了与服务器交互的不同方法,最基本的方法有4种,分别是GET,POST,PUT,DELETE。URL全称是资源描述符,我们可以这样认为:一个URL地址,它用于描述一个网络上的资源,而 HTTP 中的GET,POST,PUT,DELETE就对应着对这个资源的查,增,改,删4个操作 响应报文 HTTP响应也由3个部分构成,分别是:状态行、响应头(Response Header)、响应正文 常见的状态码有如下几种: 200 OK 客户端请求成功 301 Moved Permanently 请求永久重定向 302 Moved Temporarily 请求临时重定向 304 Not Modified 文件未修改,可以直接使用缓存的文件 400 Bad Request 由于客户端请求有语法错误,不能被服务器所理解 401 Unauthorized 请求未经授权。这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden 服务器收到请求,但是拒绝提供服务。服务器通常会在响应正文中给出不提供服务的原因 404 Not Found 请求的资源不存在,例如,输入了错误的URL 500 Internal Server Error 服务器发生不可预期的错误,导致无法完成客户端的请求 503 Service Unavailable 服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常 条件 GET 客户端重复访问站点域名,为了优化带宽,服务器根据请求中的 If-Modified-Since 字段判断响应文件是否有更新,如果没有更新,服务器返回 304 Not Modified 响应,告诉浏览器使用缓存文件,具体如下: Status Code: 304 Not Modified 持久连接 我们知道 HTTP 协议采用“请求-应答”模式,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接,Keep-Alive 功能使客户端到服务器端的连接持续有效,避免重复创建 HTTP 1.0 版本中,如果客户端浏览器支持 Keep-Alive ,那么就在HTTP请求头中添加一个字段 Connection: Keep-Alive 在 HTTP 1.1 版本中,默认情况下所有连接都被保持,如果加入 “Connection: close” 才关闭 Keep-Alive 简单说就是保持当前的TCP连接,避免了重新建立连接 长连接不可能一直保持,例如 Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开 HTTP 是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive 没能改变这个结果 使用长连接之后,客户端、服务端怎么知道本次传输结束呢?两部分:1. 判断传输数据是否达到了Content-Length 指示的大小;2. 动态生成的文件没有 Content-Length ,它是分块传输(chunked),这时候就要根据 chunked 编码来判断,chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束 Transfer-Encoding 标示 HTTP 报文传输格式的头部值,当前的 HTTP 规范定义了一种传输取值——chunked。标示消息体由数量未定的块组成,并以最后一个大小为0的块为结束 chunked 的优势:服务器端可以边生成内容边发送,无需事先生成全部的内容 HTTP/2 不支持 Transfer-Encoding: chunked,HTTP/2 有自己的 streaming 传输方式(Source:MDN - Transfer-Encoding) HTTP Pipelining 默认情况下 HTTP 协议中每个传输层连接只能承载一个 HTTP 请求和响应,浏览器会在收到上一个请求的响应之后,再发送下一个请求。 HTTP Pipelining(管线化)是将多个 HTTP 请求整批提交的技术,在传送过程中不需等待服务端的回应。 管线化机制通过持久连接(persistent connection)完成,仅 HTTP/1.1 支持此技术(HTTP/1.0不支持) 只有 GET 和 HEAD 请求可以进行管线化,而 POST 则有所限制 初次创建连接时不应启动管线机制,因为对方(服务器)不一定支持 HTTP/1.1 版本的协议 管线化不会影响响应到来的顺序 HTTP /1.1 要求服务器端支持管线化,但并不要求服务器端也对响应进行管线化处理,只是要求对于管线化的请求不失败即可 由于上面提到的服务器端问题,开启管线化很可能并不会带来大幅度的性能提升,而且很多服务器端和代理程序对管线化的支持并不好,因此现代浏览器如 Chrome 和 Firefox 默认并未开启管线化支持
五、总结网络IO模型和nginx架构。
白话Nginx的IO模型
主要介绍linux的5种IO模型,已经nginx和apache的IO模型区别。我会尽量用口语化的语言来解释。
纯属个人理解,如果有不对的地方欢迎指正。
针对结论党 首先先说三个名字: select、poll、epoll 效率: select < poll < epoll 栗子: 学生做题,老师检查 方案1:老师一个个问 — select 方案2:多个老师 — poll 方案3:学生做完了主动回答。— epoll 显然,方案3效率更高。
Linux的5种IO模型
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
也就是进程需要等数据。
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
阻塞 I/O(blocking IO)
非阻塞 I/O(nonblocking IO)
I/O 多路复用( IO multiplexing)
信号驱动 I/O( signal driven IO)
异步 I/O(asynchronous IO)
栗子场景,等快递。
阻塞IO
简单的说,就是死等。
我就站在前台等快递小哥,他不来我不走。
优点:
我能最快收到包裹。
最简单有效。
缺点:
很浪费时间。
非阻塞 I/O
每隔一段时间问一次。中间就低头玩手机或者到处走走。
优点:
我有时间干其他事情了。
’缺点:
快递小哥到了要等我,而往往他才是最忙的人。
I/O 多路复用
如果加入一个前台,专门收快递,会不会好很多?
这个前台就是复用,一个人干了N个人的事情。
前台也有几种工作模式:
select:快递来了,我一个个人问,是谁的快递。
poll:来一个快递,我加一个前台去问。
epoll:快递上写上电话(回调),快递来了我直接打电话让你来拿。
如果连接数少,前两者的速度可能更快。
但是连接数多了,系统会扛不住,或者说难以分配这么多前台,epoll的优势会瞬间暴增。
这也是nginx牛逼的根本。
异步 I/O
放在前台,你想什么时候拿都可以。
信号驱动式IO
每个人都先来登记,然后写下电话号码,快递到了我根据名字找号码,通知你。
总结
最开始学nginx的时候,肯定会被这几个模型弄懵,对于这些底层知识,我更在乎原理,然后可以复用到以后的编程中。我认为编程思想更重要,而不是上来一大堆专业术语。
六、nginx总结核心配置和优化。
Nginx的配置是以模块为单位来组织的,每一个模块包含一个或多个指令,指令是配置文件中的最小配置单元,一切配置项皆为指令。如http核心模块中的include、default_type、sendfile指令,都属于http模块。nginx所有模块中的指令见官方文档说明:http://nginx.org/en/docs/dirindex.html
1、服务器级别核心配置
| 指令 | 配置模块 | 语法 | 默认值 | 功能描述 |
| user | main | user nobody nobyd; | nobody | 以哪个用户权限运行工作线程 |
| daemon | main | daemon yes; | yes | nginx是否以守护进程运行 |
| worker_processes | main | worker_processes number; | 1 |
配置工作进程数。传统的web服务器(如apache)都是同步阻塞模型,一请求一进(线)程模式,当进(线) 程数增达到一定程度后,更多CPU时间浪费在线程和进程切换当中,性能急剧下降,所以负载率不高。Nginx 是基于事件的非阻塞多路复用(epoll或kquene)模型,一个进程在短时间内就可以响应大量的请求。建议将该值 设置<=cpu核心数量,一般高于cpu核心数量不会带来好处,反而可能会有进程切换开销的负面影响。 |
| worker_connections | events | worker_connections number; | 1024 |
并发响应能力的关键配置值,表示每个进程允许的最大同时连接数。maxConnection = work_connections * worker_processes;一般一个浏览器会同时开两条连接,如果是反向代理,nginx到后服务器的连接数量 也要占用2条连接数,所以,做静态服务器,一般maxConnection = work_connections * worker_processes / 2; 做反代理服务器时maxConnection = work_connections * worker_processes / 4; |
| use | events | use epoll; |
根据不同的平台,选择最高效的连 接处理方法 |
指定处理连接请求的方法。linux内核2.6以上默认使用epoll方法,其它平台请参考:http://nginx.org/en/docs/events.html 备注:要达到超高负载下最好的网络响应能力,还有必要优化与网络相关的linux内核参数 |
| worker_cpu_affinity | main | worker_cpu_affinity cpumask …; | 无 |
将工作进程绑定到特定的CPU上,减少CPU在进程之间切换的开销。用二进制bit位表示进程绑定在哪个CPU内核。 如8内核4进程时的设置方法:worker_cpu_affinity 00000001 00000010 00000100 10000000 |
| worker_rlimit_nofile | main | worker_rlimit_core size; | 受linux内核文件描述符数量限制 |
设置nginx最大能打开的文件描述符数量。因为Linux对每个进程所能打开的文件描述数量是有限制的,默认一般是1024个, 可通过ulimit -n FILECNT或/etc/securit/limits.conf配置修改linux默认能打开的文件句柄数限制。建议值为:系统最大数 量/进程数。但进程间工作量并不是平均分配的,所以可以设置在大一些。推荐值为:655350 |
| error_log | main, http, mail, stream, server, location | error_log 日志文件路径 日志级别; | error_log logs/error.log error; |
配置错误日志文件的路径和日志级别。日志级别有debug, info, notice, warn, error, crit, alert和emerg几种。nginx的日志使用 syslog输出,所以输出的日志格式是有规律的,系统运维人员可以根据日志规则进行查错或统计分析。更多说明请参考官方文档: http://nginx.org/en/docs/ngx_core_module.html#error_log |
| pid | main | pid 守护进程socket文件路径; | pid logs/nginx.pid | 配置nginx守护进程ID存储文件路径(不是工作进程) |
以上是nginx的顶层配置,管理服务器级别的行为。更多配置请参考官方文档:http://nginx.org/en/docs/ngx_core_module.html#working_directory
2、HTTP模块核心配置
| 指令 | 配置模块 | 语法 | 功能描述 |
| types | http, server, location | types { mime类型 文件后缀;}; | 配置能处理的文件类型。如:text/html html htm shtml; |
| include | any | include 文件路径; |
将外部文件的内容做为配置拷贝到nginx.conf文件中。如:include mime.type; 将当前目录下的mime.type配置文件拷贝到 nginx配置文件中。文件路径可以是相对路径或绝对路径。文件名可以用*来表示通配符 |
| default_type | http, server, location | default_type mime类型; |
文件名到后缀的映射关系。配置默认的mime类型,当在types指令中找不到请求的文件类型时,就使用default_type指定 的类型。默认为text/plain类型。 |
| access_log | http, server, location, if in location, limit_except |
access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]];access_log off; |
关闭或开启访问日志。默认配置为:access_log logs/access.log combined; 表示根据combined定义的日志格式,写入 logs/access.log文件中,combined是http模块默认格式。如果定义了buffer和gzip其中一个参数,日志默认会先写入缓存 中,当缓存满了之后,通过gzip压缩缓存中的日志并写入文件,启用了gzip压缩必须保证nginx安装的时候添加了gzip模 块。缓存大小默认为64K。可以配置gzip的1~9的压缩级别,级别越高压缩效率越大,日志文件占用的空间越小,但要求 系统性能也越高。默认值是1。http://nginx.org/en/docs/http/ngx_http_log_module.html#access_log |
| log_format | http | log_format 格式名称 日志格式; |
定义http访问日志的格式,在日志格式中可以访问http模块的内嵌变量,如果变存在的话,会做为日志输出。如: remoteaddr,remoteaddr,request等,更多变量请参考:http://nginx.org/en/docs/http/ngx_http_core_module.html#variables |
| sendfile | http, server, location, if in location | sendfile on | off; |
启用内核复制模式。作为静态服务器可以提高最大的IO访问速度。传统的文件读写采用read和write方式,流程为:硬盘 >> kernel buffer >> user buffer>> kernel socket buffer >>协议栈,采用sendfile文件读写的流程为:硬盘 >> kernel buffer (快速拷贝到kernelsocket buffer) >>协议栈,很明显sendfile这个系统调用减少了内核到用户模式之间的 切换和数据拷贝次数,直接从内核缓存的数据拷贝到协议栈,提高了很大的效率。这篇文章介绍比较详细:http://xiaorui.cc/?p=1673 |
| tcp_nodelay | http, server, location | off|on; | |
| tcp_nopush | http, server, location | off|on; |
tcp_nodelay和tcp_nopush这两个参数是配合使用的,启动这两项配置,会在数据包达到一定大小后再发送数据。 这样会减少网络通信次数,降低阻塞概率,但也会影响响应及时性。比较适合于文件下载这类的大数据通信场景。 |
| keepalive_timeout | http, server, location | keepalive_time 65; |
客户端到服务器建立连接的超时时长,超过指定的时间服务器就会断开连接。默认为75秒。降低每个连接的alive 时间可在一定程度上提高可响应连接数量,所以一般可适当降低此值 |
| gzip | http, server, location, if in location | gzip on | off; | 开启内容压缩,可以有效降低客户端的访问流量和网络带宽 |
| gzip_min_length | http, server, location | gzip_min_length length; |
单位为k,默认为20k。内容超过最少长度后才开启压缩,因为太短的内容压缩效果不佳,且压缩过程还会浪费系统 资源。这个压缩长度会作为http响应头Content-Length字段返回给客户端。 建议值:1000 |
| gzip_comp_level | http, server, location | gzip_comp_level 1~9; | 压缩级别,默认值为1。范围为1~9级,压缩级别越高压缩率越高,但对系统性能要求越高。建议值:4 |
| gzip_types | http, server, location | gzip_types mime-type …; |
压缩内容类型,默认为text/html;。只压缩html文本,一般我们都会压缩js、css、json之类的,可以把这些常见的文本 数据都配上。如:text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript; |
| open_file_cache | http, server, location | open_file_cache off; open_file_cache max=N [inactive=time]; | 默认值为off; 设置最大缓存数量,及缓存文件未使用的存活期。建议值:max=655350(和worker_rlimit_nofile参数一致) inactive=20s; |
| open_file_ cache_min_uses |
http, server, location | open_file_cache_min_uses number; | 默认为1,有效期内文件最少使有的次数。建议值:2 |
| open_file _cache_valid |
http, server, location | open_file_cache_valid time; |
默认为60s,验证缓存有效期时间间隔。 表示每隔60s检查一下缓存的文件当中,有哪些文件在20s以内没有使用超过2次的,就从缓存 中删除。采用lru算法。 |
| server | server { … } | http | HTTP服务器的核心配置,用于配置HTTP服务器的虚拟主机,可以配置多个 |
| listen | listen ip[:端口] | server |
配置虚拟主机监听的IP地址和端口,默认监听本机IP地址和80或8000端口。如果只设置了IP没设端口,默认使用80端口。如果只设置 了端口,没设置IP默认使用本机IP。详细配置请参考:http://nginx.org/en/docs/http/ngx_http_core_module.html#listen |
| server_name | server_name domain_name …; | server | 配置虚拟主机的域名,可以指定多个,用空格分隔。默认为空 |
| charset | http, server, location, if in location | charset charset | off; | 设置请求编码,和url参数乱码问题有关。 |
| location | server, location | location [ = | ~ | ~* | ^~ ] uri { … } location @name { … } |
http请求中的一个重要配置项,用于配置客户端请求服务器url地址的匹配规则。可以配置多个匹配规则 |
3、核心配置优化
# nginx不同于apache服务器,当进行了大量优化设置后会魔术般的明显性能提升效果 # nginx在安装完成后,大部分参数就已经是最优化了,我们需要管理的东西并不多 #user nobody; #阻塞和非阻塞网络模型: #同步阻塞模型,一请求一进(线)程,当进(线)程增加到一定程度后 #更多CPU时间浪费到切换一,性能急剧下降,所以负载率不高 #Nginx基于事件的非阻塞多路复用(epoll或kquene)模型 #一个进程在短时间内可以响应大量的请求 #建议值 <= cpu核心数量,一般高于cpu数量不会带好处,也许还有进程切换开销的负面影响 worker_processes 4; #将work process绑定到特定cpu上,避免进程在cpu间切换的开销 worker_cpu_affinity 0001 0010 0100 1000 #8内核4进程时的设置方法 worker_cpu_affinity 00000001 00000010 00000100 10000000 # 每进程最大可打开文件描述符数量(linux上文件描述符比较广义,网络端口、设备、磁盘文件都是) # 文件描述符用完了,新的连接会被拒绝,产生502类错误 # linux最大可打开文件数可通过ulimit -n FILECNT或 /etc/security/limits.conf配置 # 理论值 系统最大数量 / 进程数。但进程间工作量并不是平均分配的,所以可以设置的大一些 worker_rlimit_nofile 65535; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { # 并发响应能力的关键配置值 # 每个进程允许的最大同时连接数,work_connectins * worker_processes = maxConnection; # 要注意maxConnections不等同于可响应的用户数量, # 因为一般一个浏览器会同时开两条连接,如果反向代理,nginx到后端服务器的连接也要占用连接数 # 所以,做静态服务器时,一般 maxClient = work_connectins * worker_processes / 2 # 做反向代理服务器时 maxClient = work_connectins * worker_processes / 4 # 这个值理论上越大越好,但最多可承受多少请求与配件和网络相关,也可最大可打开文件,最大可用sockets数量(约64K)有关 worker_connections 65535; # 指明使用epoll 或 kquene (*BSD) use epoll; # 备注:要达到超高负载下最好的网络响应能力,还有必要优化与网络相关的linux内核参数 } http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; # 关闭此项可减少IO开销,但也无法记录访问信息,不利用业务分析,一般运维情况不建议使用 access_log off # 只记录更为严重的错误日志,可减少IO压力 error_log logs/error.log crit; #access_log logs/access.log main; # 启用内核复制模式,应该保持开启达到最快IO效率 sendfile on; # 简单说,启动如下两项配置,会在数据包达到一定大小后再发送数据 # 这样会减少网络通信次数,降低阻塞概率,但也会影响响应及时性 # 比较适合于文件下载这类的大数据包通信场景 #tcp_nopush on; 在 #tcp_nodelay on|off on禁用Nagle算法 #keepalive_timeout 0; # HTTP1.1支持持久连接alive # 降低每个连接的alive时间可在一定程度上提高可响应连接数量,所以一般可适当降低此值 keepalive_timeout 30s; # 启动内容压缩,有效降低网络流量 gzip on; # 过短的内容压缩效果不佳,压缩过程还会浪费系统资源 gzip_min_length 1000; # 可选值1~9,压缩级别越高压缩率越高,但对系统性能要求越高 gzip_comp_level 4; # 压缩的内容类别 gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript; # 静态文件缓存 # 最大缓存数量,文件未使用存活期 open_file_cache max=65535 inactive=20s; # 验证缓存有效期时间间隔 open_file_cache_valid 30s; # 有效期内文件最少使用次数 open_file_cache_min_uses 2; server { listen 80; server_name localhost; charset utf-8; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } ... } ... }
七、使用脚本完成一键编译安装nginx任意版本。
[root@localhost local]#vim nginx.sh
#!/bin/bash # #***************************************************************** #Author: mawr #QQ: 751458565 #Date: 2022-11-02 #FileName: nginx.sh #URL: #Description: 编译安装Nginx #Copyright (C) 2022All rights reserved #***************************************************************** clear echo "Preparations before installation..." ##variabled NGINX_VERSION="nginx-1.22.1" NGINX_INSTALL_DOC="/usr/local/nginx" NGINX_USER="nginx" NGINX_GROUP="nginx" NGINX_CONFIGURE="--prefix=${NGINX_INSTALL_DOC} --user=${NGINX_USER} --group=${NGINX_GROUP} --with-http_ssl_module --with-http_stub_status_module" ##function nginx_check(){ # 1、监测当前用户 要求为root if [ "$USER" != 'root' ];then echo "need to be root so that" exit 5 fi # 2、检查wget命令 WGET_CHECK=$(rpm -q wget) if [ $? -ne 0 ];then yum -y install wget &> /dev/null fi } nginx_install_pre(){ # 1、安装依赖 if ! (yum -y install make zlib zlib-devel gcc-c++ libtool openssl openssl-devel pcre-devel openssl openssl-devel elinks 1>/dev/null);then echo "ERROR:YUM install error" exit 5 fi # 2、下载nginx源码包 if (wget http://nginx.org/download/${NGINX_VERSION}.tar.gz &>/dev/null);then tar zxf ${NGINX_VERSION}.tar.gz if [ ! -d ${NGINX_VERSION} ];then echo "ERROR:not found ${NGINX_VERSION}";exit 5 fi else echo "ERROR:wget download file ${NGINX_VERSION}.tar.gz fail" fi } nginx_install_make(){ (groupadd ${NGINX_GROUP} ;useradd -s /sbin/nologin -r -M -g ${NGINX_GROUP} ${NGINX_USER}) &>/dev/null cd ${NGINX_VERSION} echo "nginx configure..." if ./configure ${NGINX_CONFIGURE} 1>/dev/null;then echo "nginx make ..." if make 1>/dev/null;then echo "nginx make install ..." if make install 1>/dev/null;then echo "nginx install success" else echo "ERROR: nginx install tail!";exit 5 fi else echo "ERROR: nginx make tail!";exit 5 fi else echo"ERROR: nginx configure tail!";exit 5 fi } # 配置nginx开机自启,使用systemctl 管理nginx服务 nginx_enable(){ cat > /usr/lib/systemd/system/nginx.service <<EOF [Unit] Description=nginx After=network.target [Service] Type=forking ExecStart=${NGINX_INSTALL_DOC}/sbin/nginx ExecReload=${NGINX_INSTALL_DOC}/sbin/nginx -s reload ExecStop=${NGINX_INSTALL_DOC}/sbin/nginx -s quit PrivateTmp=true [Install] WantedBy=multi-user.target EOF systemctl enable nginx.service 1>/dev/null } nginx_start(){ TEMP_NGINX=$(mktemp nginx.XXX) if systemctl start nginx.service;then echo "nginx start SUCCESS!" clear elinks http://localhost -dump >${TEMP_NGINX} head -n +11 ${TEMP_NGINX} rm -f ${TEMP_NGINX} echo -e "\e[1;36m Manager Nginx:\e[0m \e[0;32m systemctl start|stop|status|restart| nginx.service \e[0m" else echo "nginx stop FAIL" fi } nginx_check nginx_install_pre nginx_install_make nginx_enable nginx_start
第三方插件:nginx-module-vts-0.1.18 实现。
下载插件:
[05:17:39 root@mawr opt]#wget https://github.com/vozlt/nginx-module-vts/archive/refs/tags/v0.1.18.tar.gz
[05:19:34 root@mawr opt]#ls
nginx-1.20.1 nginx-1.20.1.tar.gz v0.1.18.tar.gz
[05:19:36 root@mawr opt]#tar -zvxf v0.1.18.tar.gz
[05:19:50 root@mawr opt]#ls
nginx-1.20.1 nginx-1.20.1.tar.gz nginx-module-vts-0.1.18 v0.1.18.tar.gz
[05:20:01 root@mawr opt]#nginx -V
nginx version: nginx/1.20.1
built by gcc 8.5.0 20210514 (Red Hat 8.5.0-10) (GCC)
built with OpenSSL 1.1.1k FIPS 25 Mar 2021
TLS SNI support enabled
configure arguments: --prefix=/apps/nginx --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module
重新编译:
[05:27:22 root@mawr nginx-1.20.1]#./configure --prefix=/apps/nginx --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module --add-module=/opt/nginx-module-vts-0.1.18
[05:28:01 root@mawr opt]#nginx -t
[05:28:15 root@mawr opt]#nginx reload
[05:29:01 root@mawr opt]#vim /opt/nginx/conf.d/pc.conf
vhost_traffic_status_zone;
server {
server_name www.mage.org
root /data/nginx/html/pc;
location /status {
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}
}
[05:35:01 root@mawr opt]#nginx -t
#注意编译完,必须重启nginx服务
[05:36:01 root@mawr opt]#systemctl restart nginx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号