Redis缓存常见问题总结
Redis做缓存可以减轻数据库的压力, 其常见的三个缓存问题有:
- 缓存穿透
- 缓存击穿
- 缓存雪崩
一、缓存穿透(查询不到)
1、什么是缓存穿透?
正常的查询流程是: 先查询Redis缓存数据库中是否有对应的key, 有的话就取出对应的value; 如果缓存中没有就去数据库(DB)中查询, DB中有的话, 就将DB中的value取出来放到缓存中, DB中没有的话就不往缓存中加入。
假设查询某个user对象, 但缓存和DB中全都没有, 这个时候中间的Redis缓存就不起作用了(因为查不到)。但是客户端还是一直发起恶意查询,如果并发量小的话倒没事, 但查询量一旦较大就会使DB压力增大, 会有崩溃宕机的可能。这种情况就是缓存穿透。
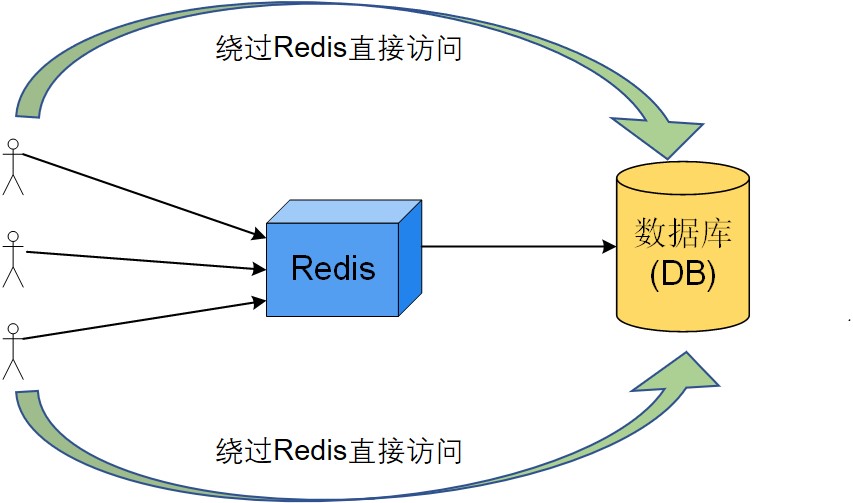
2、解决缓存穿透的措施
由缓存穿透的定义可知, 引起该问题的主要原因是要查询的对象在缓存和DB中全都没有, 并且客户端还一直在访问。那么针对该问有两种预防策略:
- 创建空的键值对。
- 在访问缓存之前进行必要的请求过滤, 直接过滤掉空的key。
(1) 增加空的key对象
不是查不到key对象吗?那我们就直接创造key, 设置个失效期, 只不过其value为空。这种方法可能保护了后端DB, 但这种方法存在的问题是储存了那么多的空值对象, 占了内存, 但意义并不大。
(2) 布隆过滤
布隆过滤(Bloom Filter)是一种较好的解决办法, 它是一种概率型的数据结构, 以牺牲正确率为代价, 换取查询速度的提升和内存消耗的降低。通过布隆过滤我们就可以过滤掉不符合条件的key。
布隆过滤算法的缺点源于它所使用的\(hash function\)定位key索引的位置。比如key1=file, key2=life, 使用一次\(hash function\)可能两者的hash code是一样的, 所以布隆过滤算法中一般要求多次散列, 但理论上还是不能保证不同的key一定对应不同的hash code(index)。所以使用布隆过滤器对一个key进行查询, 即使查到也不能说过滤器中一定就存在符合条件的key; 如果布隆过滤查不到指定的key, 那么该指定的key铁定不存在。
- 使用Google的guava包进行测试
<!-- guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
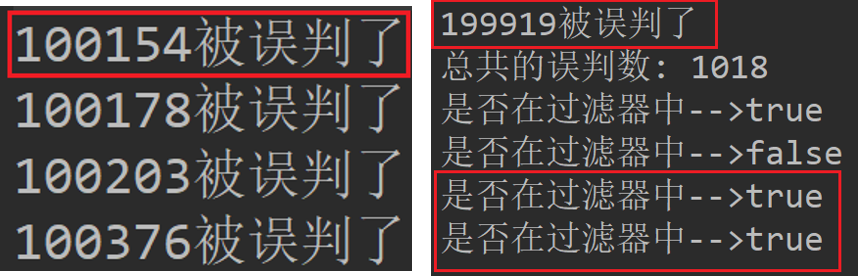
- 添加10万个数据, 然后测试10万个数据, 观察被测试的数据有多少被误判。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class test {
static int size = 100000;
static double fpp = 0.01;
public static void main(String[] args) {
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
int count = 0;
for (int i = size; i < size * 2; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "被误判了");
}
}
System.out.println("总共的误判数: " + count);
System.out.println("是否在过滤器中-->" + bloomFilter.mightContain(1000));
System.out.println("是否在过滤器中-->" +bloomFilter.mightContain(size + 1));
System.out.println("是否在过滤器中-->" +bloomFilter.mightContain(100154));
System.out.println("是否在过滤器中-->" +bloomFilter.mightContain(199919));
}
}
- 测试结果
二、缓存击穿(集中式访问热点key)
缓存击穿较上面的缓存穿透的区别是:缓存中也查不到, 但是DB中一定存在(值)。缓存击穿对应的场景一般是热点事件,如网上报道来了某地发生了某个热点事件, 该事件记为\(key\), 网友就会在一段时间内都对该事件进行大量的集中访问,缓存中该热点\(key\)到期失效后, 大的数据访问量依旧持续访问,此时缓存中查不到就会集中push到DB上, 发起对该热点key的访问,DB就有可能宕机。就像集中所有炮火猛烈轰击89师和暂7师的结合部, 非要撕开一个口子一样。

三、缓存雪崩(大批key集中失效)
缓存雪崩是因为缓存数据库中的大批key到期失效了, 在下一次生效之前这段时间段内, 大量的查询任务就会直接落在DB上, 引起DB压力增加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号