mysql优化:定期删数据 + 批量insert + 字符串加索引为什么很傻
嗯,犯了一个很低级的错误,最近暴露出来了。
背景:
1. 内部平台,接口间断性无返回,查询日志注意到失败时,接口耗时达到4000+(正常状态:100+ms)
2. 增加日志打点,在关键步骤插入时间戳,发现单步insert 和 select操作耗时1000ms+
3. 查看数据库表数据,查询表数据量已积累到400w+,每天新增数据4W+,在字符串上建立了索引(之前埋下的很傻行为,无想法的加了索引,功能实现未考虑性能)
解决:
1. 考虑了数据的必要性,增加事件定期删除过期数据
1. 查看事件开关并开启 SHOW VARIABLES LIKE 'event_scheduler'; set global event_scheduler = on 2. 具体执行需要调用的存储过程,删除数据 DELIMITER // CREATE PROCEDURE delete_data_n_day_ago(IN n int) BEGIN delete from test_record where time < date_sub(curdate(), INTERVAL n day) ; END // DELIMITER ; 3. 写事件,调用存储过程 CREATE EVENT del_data ON SCHEDULE EVERY 1 DAY ON COMPLETION PRESERVE DO CALL delete_data_n_day_ago (3);
附:事件标准语法
CREATE [DEFINER = { user | CURRENT_USER }] EVENT [IF NOT EXISTS] event_name ON SCHEDULE schedule [ON COMPLETION [NOT] PRESERVE] [ENABLE | DISABLE | DISABLE ON SLAVE] [COMMENT 'string'] DO event_body; schedule: AT timestamp [+ INTERVAL interval] ... | EVERY interval [STARTS timestamp [+ INTERVAL interval] ...] [ENDS timestamp [+ INTERVAL interval] ...] interval: quantity {YEAR | QUARTER | MONTH | DAY | HOUR | MINUTE | WEEK | SECOND | YEAR_MONTH | DAY_HOUR | DAY_MINUTE | DAY_SECOND | HOUR_MINUTE | HOUR_SECOND | MINUTE_SECOND} 详见:mysql手册:https://dev.mysql.com/doc/refman/5.7/en/create-event.html
注释: event_name :创建的event名字(唯一确定的)。 ON SCHEDULE:计划任务。 schedule: 决定event的执行时间和频率(注意时间一定要是将来的时间,过去的时间会出错),有两种形式 AT和EVERY。 [ON COMPLETION [NOT] PRESERVE]: 可选项,默认是ON COMPLETION NOT PRESERVE 即计划任务执行完毕后自动drop该事件;ON COMPLETION PRESERVE则不会drop掉。 [COMMENT 'comment'] :可选项,comment 用来描述event;相当注释,最大长度64个字节。 [ENABLE | DISABLE] :设定event的状态,默认ENABLE:表示系统尝试执行这个事件, DISABLE:关闭该事情,可以用alter修改 DO event_body: 需要执行的sql语句(可以是复合语句)。CREATE EVENT在存储过程中使用时合法的。 --------------------- 作者:jesseyoung 来源:CSDN 原文:https://blog.csdn.net/JesseYoung/article/details/35257527 版权声明:本文为博主原创文章,转载请附上博文链接!
2. 循环调用 insert单条语句修改为批量
这一点也是网上很多文章提示的,修改为insert into table(keys) values (values1), (values2)...... ,但多是实验证明,没有原理,直至找到mysql手册
实际减少了下面提到的connecting + sending query to server + inserting indexes
3. 修改索引设置,增加自增字段作为主键
接下来就是做的很蠢的事情了,不知当初出于什么考虑,在URL字段增加了索引,压根没有考虑到性能问题,发现之后感觉太对不起老师。。。。
很多文章也提到最佳实践,不要在字符串建立索引,自己没有跑具体数据,借用网文数据说明,比如:https://foio.github.io/mysql-stridx/

问题一:在字符串上建索引为什么会慢呢?
1. 关于索引使用数据结构,不同引擎内部实现存在不一致,手册中涉及索引部分是说使用B- tree(虽然,网文很多是说B+ ) 更正下,B-树实际就是B树,B+树可以理解为一种特殊的B树

2. B+ 和B-的区别在于是否存数据非叶子节点不保存关键字记录的指针,数据均存在叶子节点
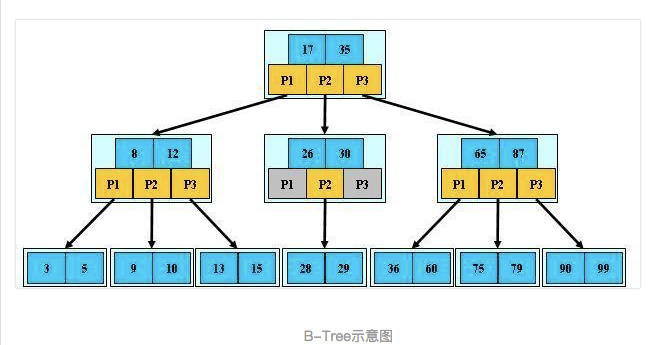
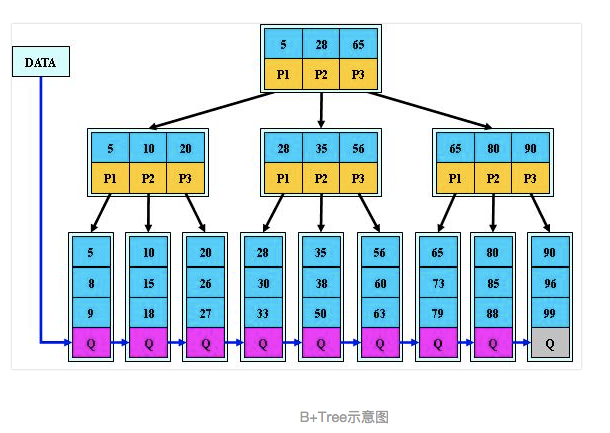
3. 数据库索引选择使用B树,而不是红黑树/二叉树之类
磁盘I/O操作耗时比内存久,计算机会预读磁盘,以页为单位读取,选取标准:磁盘I/O操作尽量少
每个节点作为一页,查询深度越小,磁盘读取操作越少,二叉树之类每个节点分为2路,相同数据深度更大,故不选取
4. 每个节点可分的路数越多,深度越小,读取的IO次数越少,索引字段选取int 和 长字符串大小差异,就导致了在字符串上建索引会慢
insert过程也伴随写索引,复杂度参考B树插入数据

4. 确认其他查询语句,新增索引
explain select * from tableName where columnName=2; id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------------------------+------+---------------+------+---------+------+--------+-------------+ | 1 | SIMPLE | tableName | ALL | NULL | NULL | NULL | NULL | 437081 | Using where |
ALTER table tableName ADD INDEX indexName(columnName)

后续:代码写之前,先确认SQL语句,explain确认步骤,尽量避免all类型 和 filesorting
参考:
https://dev.mysql.com/doc/refman/5.5/en/explain-output.html#explain_type

 浙公网安备 33010602011771号
浙公网安备 33010602011771号