技术的极限(5): 识别计算与技术背后的心智
上一篇:技术的极限(4): 解决不可靠的网络的挑战
下一篇:技术的极限(6): 密码朋克精神(Cypherpunk Spirit)
目录:
** 0x01 One Size Fits all
** 0x02 认知偏差
** 0x03 Linux背后的心智模型 | Linus Torvalds
** 0x04 Three rules of thumb
** 0x05 霍金:哥德尔和物理学的终结
** 0x06 二维的权限系统
** 0x07 计算机表示浮点数
** 0x08 计算机的本质
** 0x09 App Store的上App获得盈利的模式演化
** 0x0A 技术问答:数学和思辨的区别
** 0x0B 技术问答:万能指针void*
0x01 One Size Fits all
"One size fits all" is a description for a product that would fit in all instances. The term has been extended to mean one style or procedure would fit in all related applications. It is an alternative for "Not everyone fits the mold ". It has been in use for over 5 decades. There are both positive and negative uses of the phrase.
众口难调,一个尺寸不能满足所有需求。但是我们做工具,软件,产品,解决方案,常常想要做出同时适配“又快、又好、又省”这个不可能三角。在fastgood.cheap这个页面上,你可以通过滑动FAST,GOOD,CHEAP选项来体验不可能三角。你没办法同时让三个选项都打开,当你打开A,打开B,再想打开C的适合,A就会被自动关闭。

与One Size Fits all对应的是: “One Ring to rule them all“,来自指环王One Ring:
Three Rings for the Elven-kings under the sky,
Seven for the Dwarf-lords in their halls of stone,
Nine for Mortal Men doomed to die,
One for the Dark Lord on his dark throne
In the Land of Mordor where the Shadows lie.
One Ring to rule them all, One Ring to find them,
One Ring to bring them all and in the darkness bind them
In the Land of Mordor where the Shadows lie.
0x02 认知偏差
原文:wiki:Choice-supportive_bias
If a person chooses option A instead of option B, they are likely to ignore or downplay the faults of option A while amplifying those of option B. Conversely, they are also likely to notice and amplify the advantages of option A and not notice or de-emphasize those of option B.
如果一个人接收观点A,而不是观点B。那么这个人就会选择性的忽略A观点的缺陷,而放大观点B的缺陷。相对地,会放大观点A的优点而不提及观点B的优点。
经验里产生里正反馈的策略,会作为未来策略的选项。反之,经验里产生了负反馈的策略会作为未来排除的策略选项。这些对策略的偏好,进入了记忆,构成了偏见的基础。我们做出决策依据的是主观看法、先验知识、信念、动机和目标。
这是维基百科上列出的认知偏差法典(Cognitive bias codex):
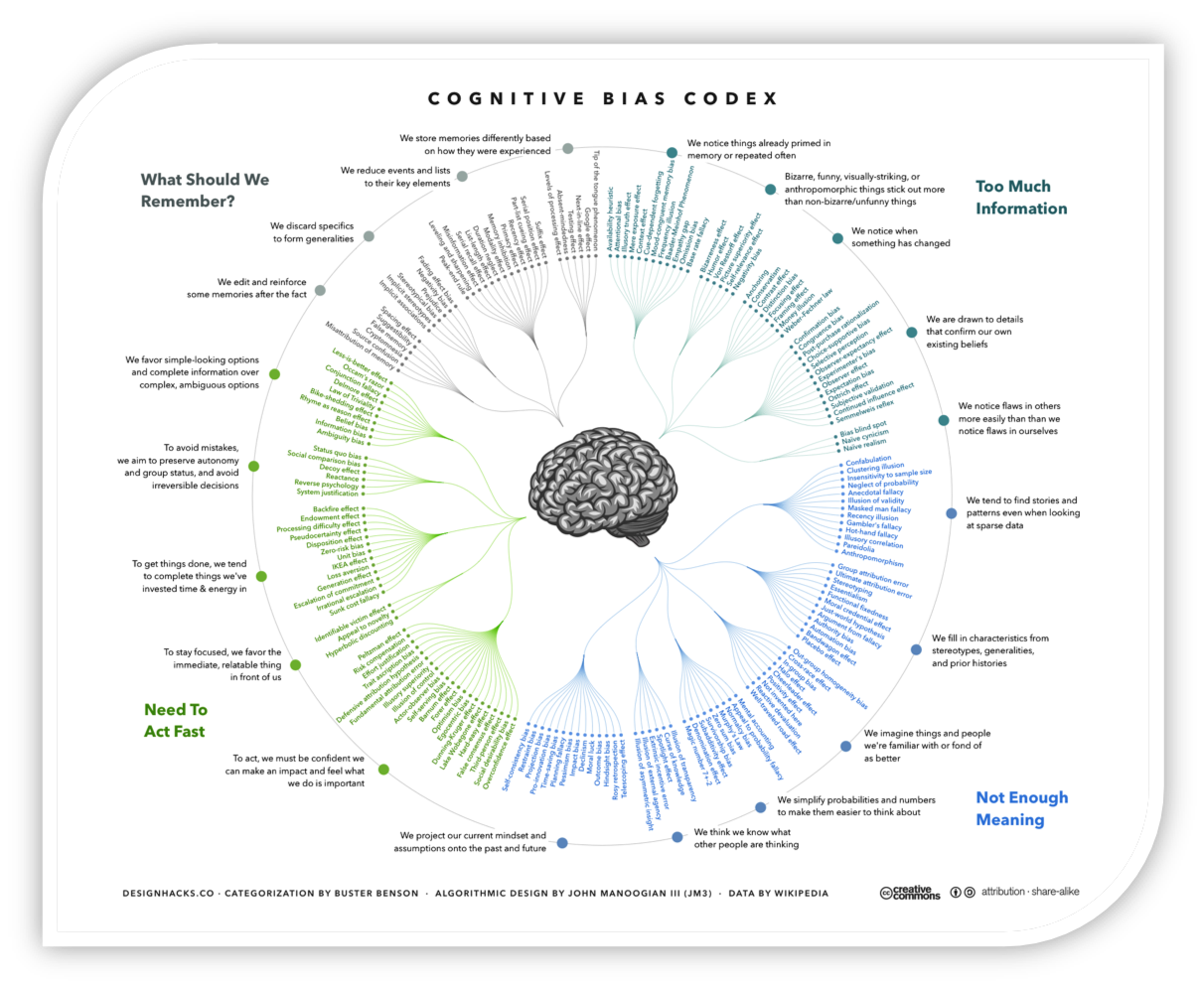
点击其中每一个分支,链接到对应到认知偏差所在的维基页面,可谓琳琅满目。根据人的大脑面对生存中的不同问题所采用的不同应对策略,它们被分为四个象限,分别是:
- What Should We Remember:
- We edit and reinforce some memories after the fact
- We discard specifics to form generalities
- We reduce events and lists to their key elements
- We store memories differently based on how they were experienced
- Too Much Information:
- We notice things already primed in memory or repeated often
- Bizarre, funny, visually striking, or anthropomorphic things stick out more than non-bizarre/unfunny things
- We notice when something has changed
- We are drawn to details that confirm our own existing beliefs
- We notice flaws in others more easily than we notice flaws in ourselves
- Not Enough Meaning
- We tend to find stories and patterns even when looking at sparse data
- We fill in characteristics from stereotypes, generalities, and prior histories
- We imagine things and people we're familiar with or fond of as better
- We simplify probabilities and numbers to make them easier to think about
- We think we know what other people are thinking
- We project our current mindset and assumptions onto the past and future
- Need To Act Fast
- We favor simple–looking options and complete information over complex, ambiguous options
- To avoid mistakes, we aim to preserve autonomy and group status, and avoid irreversible decisions
- To get things done, we tend to complete things we've invested time and energy in
- To stay focused, we favor the immediate, relatable thing in front of us
- To act, we must be confident we can make an impact and feel what we do is important
这还只是把大脑当作黑盒子一样研究得出来条目,有一种盲人摸象的结果。虽然人为把条目分为了四大类,但是实际上每个条目都是被独立的观察得到,看上去有一种离散的感觉。分类条目采用的是枚举法。
0x03 Linux背后的心智模型 | Linus Torvalds
原文:youtube:The mind behind Linux | Linus Torvalds
- Linus并不是为了开源而开源,最开始是因为写了Linux,就:“写了这么大的一个东西,想拿出来给大家看看:‘看,我写了这个!’”,然后他的朋友告诉他可以使用的开源协议,他也担心被商业公司盗去使用,所以就选择了开源协议开源。
- Linus在硅谷一家公司一工作就干了7年,他描述硅谷这个地方的人都是跳来跳去的,而他很稳定,就是个宅男。
- Linus实现Git的目的是为了维护Linux,再次说明他Linux和Git只是他满足自己需求而做的项目中的两个,他实现这些主要是为了解决自己的需求。
- Linus在Linux有10-100个开发者加入的时候就觉的这是一个巨大的突破,而100到10000则没那个感觉,10到100对技术而言是重要的,100到10000则是商业上是重要的。
- Linus认为品味很重要,举的一个例子是链表的一个小代码,很好的说明了是否能看清全貌,用通用的方法解决了啰嗦的分支处理,他喜欢和这样有品味的人一起工作。
- Linus只喜欢写命令行,他说如果被关在一个岛上,必须写GUI才能离开,他估计就挂在那了。
- Linus觉的开源让互相不喜欢的人能在一起工作,这很棒。
- Linus说他并不合群,因此他常常说出冒犯别人的话而自己并没有感觉到,他说,别人可以合群点,但他不是。
- Linus评价爱迪生和特斯拉,说特斯拉不断创造新的噱头,但是爱迪生不断的解决路上的坑,他认为自己是爱迪生这一派的,顺便吐槽了“有的公司就以特斯拉命名”
- Linus认为技术这个领域是“非黑即白”的,因此开源能起作用,但是像社会、政治等很难说清的地方他不确定这能否起作用,这些领域存在“黑、白、灰”等,再举例是:科学最早就是开源的,但是如今科学文章都被锁在封闭的期刊里(例如爱思唯尔),但如今在回归了,例如( https://arxiv.org , http://sci-hub.cc),另外一个例子就是维基百科)。
不过Linus后面为自己经常的冒犯做出了改变,据说还做了一个邮件过滤系统来解决这个问题,重新回归社区后决定不再骂人了:linus-torvalds-is-back
但这是发生在管理Linux将近30年之后。上一次Linus对版本管理的不满,导致了他开发了分布式版本管理工具git。而基于git的github源代码托管站点已经是全世界代码托管的大本营,各大公司也几乎把自己的开源项目都放在github上。更早之前的google code,微软的codeplex也都早早下架了,原因很简单:开发者们不在上面玩。如今,github已经被微软收购。
设计并制造一个最小内核的工具解决问题,往往比靠人和流程来解决的更好,并且最终会改变一整个领域的现状。
0x04 Three rules of thumb
- Duff’s rule: Pi seconds is a nanocentury.
3.14*billion second=3.14*10亿秒=3.14*10^9秒,大概有1个世纪- 1秒=10^9纳秒
- 因此,3.14秒约等于1个"纳世纪"
- 从而,如果一个任务需要1秒完成,完成10亿次需要多久?
- 大概30年,可见一个任务1秒完成并不快。
- Hopper’s rule: Light travels one foot in a nanosecond.
- 光速是299,792,458米每秒
- 光穿过0.983英尺每纳秒
- 这是计算机芯片制造的上限,信号在一个时钟周期内在芯片之间传播的速度被限制了,因此芯片技术只能在多核上走,但这又触碰了如何自动并行计算的问题。
- Rule of 72: An investment at n% interest will double in 72/n years.
- 投资1000块钱,利润率是6%的话,大概需要72/6=12年翻倍,变成2000块
掌握必要的经验法则,可快速估算相关问题。
0x05 霍金:哥德尔和物理学的终结
原文:zh-cn: 哥德尔和物理学的终结
原文: en: Gödel and the end of physics
哥德尔定理和我们是否能以有限数量的原理构建宇宙终极理论有什么关系呢?一个联系是明显的。根据实证论科学哲学,一个物理理论乃是一数学模型。因此如果有数学命题不能证明的话,那就有物理问题不能预测。
0x06 二维的权限系统
原文:How to Set File Permissions in Mac OS X
权限系统就是一个二维关系,下面的图,非常直观的展示了这点,Excel里也可以非常直接的通过行/列表示出来,但是把这些数字用位的方式加在一起,就不那么直观了。
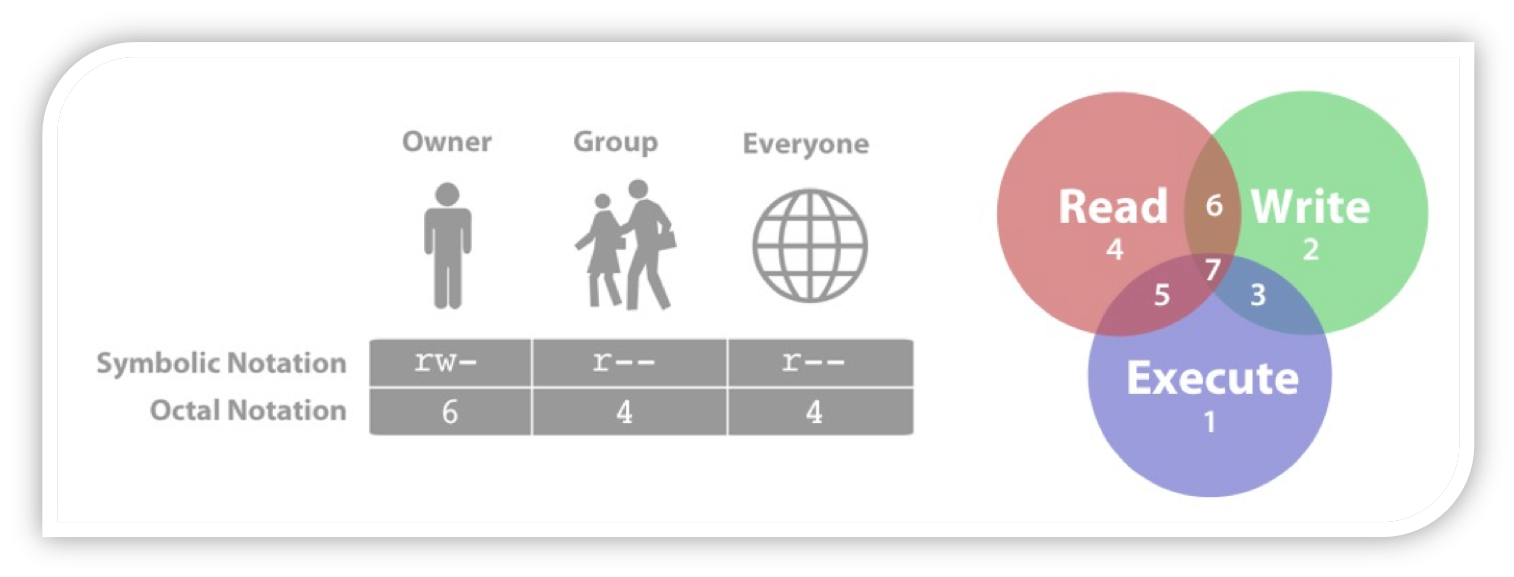
系统中的权限系统,一般叫做ACL(Acccess Control List),角色之间加上继承关系的话,就会产生树形结构,如下图:

0x07 计算机表示浮点数
[1] wiki:IEEE_754
[2] wiki:IEEE_754
[3] wiki:Single precision floating point format
[4] wiki:单精度浮点数
[5] wiki:Errors and residuals
[6] wiki:误差
数值计算在计算机里,结果都是指在精度范围内就够,精确值和计算值之间的差叫做误差,误差有两种,一种是绝对误差,另一种是相对误差,数值计算中有专门分析误差的知识。
误差会传播,在实际的开发中,如果是精度敏感的,需要选择合理的精度表示;在金额相关的计算中,一般需要BigNumber类型,计算的结果中都不做四舍五入,直到界面显示的时候才会按精度显示给用户。
[7] floating point visually explained
这篇的解释最佳,浮点数在计算机中被编码为3部分:
- 1个bit表示符号,例如3.14是正的,这个bit是0
- 8个bit表示在数轴上位于[0.5,1],[1,2],[2,4],[4,8],....[2127,2128]之间的哪个窗口(window)内,窗口公式是 [2^{E-127}, 2^{E-127+1}]。例如3.14在[2,4]这个区间,E=128.
- 23个bit表示把那个窗口拆成223份后,位于哪个部分。例如把[2,4]拆成223份,则3.14在 (3.14-2)/(4-2) * 2^23 = 4781507这个位置。
如图所示:



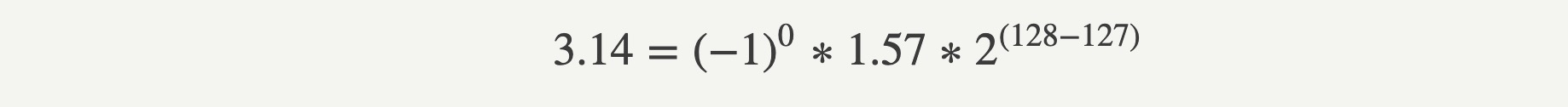
0x08 计算机的本质
原文:PDF:Five Deep Questions in Computing
- P = NP?
- What is computable?
- What is intelligence?
- What is information?
- **(How) can we build complex systems simply? **
计算机是一个独立的学科,核心是计算,说计算机不是一个独立学科的说法我在学校里也听说过,但其实是站不住脚的,每个学科真的不一样,我以前还觉得计算机学科和软件工程没区别,可实际上它们的核心关注点不同。
怎样算独立的学科?有核心解决的问题和理论体系,比如计算机的核心问题就是可计算,理论体系就是编程语言理论,这显然不是数学、不是物理、也不是管理。
你说语言算是数学么?以及使用语言来写故事算是数学么?一个人擅长数学推理和证明,没学过概率论,他学概率论的时候是不会有多大不舒适的,一样的符号体系,一样的推理和证明,但是他学编程不会这样。此外编程解决的问题中有大量不是数学问题,例如分析数学重度依赖的函数是单射的,在编程中根本不关心,例如程序里有协程这种跳转点,数学里没有明显的对应模型。我们可以举出大量它们之间关注的核心问题根本不同。
计算机和所有自然科学一样会大量使用数学,这是逻辑的需要,但它和数学还是不同的,核心问题不同。再举例,数学重度依赖于公式,计算机就不是,计算机就是重度依赖数据结构与算法。
虽然,图像处理、计算机视觉、计算机图形学、机器学习、模式识别、深度学习都依赖数学,甚至你还可以完全从函数逼近论的角度去学习深度学习,把深度学习完全放在函数逼近的学科内去研究。但是,那是这个研究对象的数学角度,而从计算机的角度,核心关注的则是实际把计算的程序搭建出来,输入数据,计算,输出可用的结果。追求结果的可用性,会导致并不追求中间计算过程的“存粹性”,例如限制只用一种数学方法就不是重要的。
回头说复杂性,软件开发中复杂性来自于想要满足所有用户的需求。假设一个产品原来有N个功能,理论上新加1个功能,最多可以导出1xN次对原功能的扰动,这个时候就很考验原来的设计的适应性,原来的设计是否彻底贯彻了开闭原则,把变动可能小的固化并封装起来,把变动可能性大的做成可拔插的,或者做成基于规则的引擎等,都会影响。
0x09 App Store的上App获得盈利的模式演化
原文:The Evolution of the App Store and the App Business
这家公司的App经历了App Store的不同阶段,post了一篇文章分析了App Store 不同阶段创造App,获得用户,获得盈利的不同模式。从买盒装软件,到免费软件+广告,到应用内付费。不同阶段获得用户的方式也不尽相同,从一开始只要做到分类软件的Top,到供大于求后通过刷榜来获得马太效应,到酒香不怕巷子深,软件的分发、获得用户、以及盈利模式一直在改变。
更多的软件早已是卖服务不卖软件,其中一种常见的模式是按时间收费,例如Office提供固定版本一次性购买、Office365的年费模式、自动续年费模式;还有一种是按规模收费,非会员可以使用绝大部分常用功能,而会员可以多人协同使用,高级会员可以使用企业级功能。
还有一种是按次数收费,很希望很多传统软件能从盒装软件的卖法改为这种按次数收费的模式,不但能减少盗版还能收到钱。比如Adobe Acrobat,编辑PDF的功能最正宗好使,但是它就只提供试用而已,但是实际上这个功能对很多人来说使用的频次很少,需要的时候就非常急需。卖太贵的单价,大部人会不愿意购买,可是如果做成扫码用一次,我想愿意付费使用的群体一定不小。例如Youku这样的视频网站,就会提供“单集电影”、”1个月会员“、”3个月会员“、”半年会员“,”自动按月续费“,“年费”等。你会想,为什么按年付费明明单价更便宜,还是会有许多人只买一个月,甚至只买一集?这就是不同使用频次导致的不同需求。
0x0A 技术问答:数学和思辨的区别
“一个无理数在数学上是确定么?例如自然对数e?”
这句话里面,什么是“确定”是一个未定义的概念。
比如我想证明e是不是“确定”的,我没有一个可以证明的对象?e满足什么性质后,它可以被看成是“确定”的?或者证明e不满足这个性质,从而证明e是“不确定”的。
但是你要证明一个函数是不是在一个区间上“连续”的,就可以。因为一个函数在区间上是不是连续,是有定义的。只要证明这个函数在区间上是不是满足这个性质就可以。
这是感性思辨和数学思维之间的区别。
0x0B 技术问答:万能指针void*
为什么很多回调函数
int callback(void* userData);用void*做参数?
因为不用void*,没办法传入任意指针,类型不对。传入之后用在C语言环境下直接转,在C++环境下可以用reinterpret_cast转换类型,顾名思义:重新解释=re interpret,reinterpret_cast不会改变数据内容。
C语言之所以是弱类型语言,而不是强类型语言,就是因为void*的存在,void*是C语言灵活的精髓,这是信任程序员,程序员需要自己知道自己在干什么,程序员自己知道传入回调函数的指针具体是什么类型,转换的时候也就知道对应的应该转换成什么类型。这就是C语言的多态。
--end--

 浙公网安备 33010602011771号
浙公网安备 33010602011771号