


好好说说c++内存序--以单例模式为例子
1.首先写一个单例模式,面试中很容易遇见的,一听到单例,小猿忍不住投去鄙夷的目光,不过他还是挺谨慎的,并没有立即下笔,思索一番后,决定把自己曾经在公司某久经考验的框架里看过的一段代码搬运过来:
template<typename T>
class XX_Singleton {
public:
typedef T instance_type;
typedef volatile T volatile_type;
static T* getInstance() {
// 加锁, 双check机制, 保证正确和效率
if(!_pInstance) {
std::lock_guard<mutex> lock(_tl);
if(!_pInstance) {
_pInstance = new T;
}
}
return (T*)_pInstance;
}
virtual ~XX_Singleton() {
};
protected:
static mutex _tl;
static volatile T* _pInstance;
protected:
XX_Singleton() {
}
XX_Singleton (const TC_Singleton &);
XX_Singleton& operator=(const TC_Singleton &);
};
// 静态成员变量的定义
template <typename T>
volatile T* XX_Singleton<T>::_pInstance = nullptr;
大部分砖工应该见过类似上面这段代码实现的singleton,它采用 DCLP (Double-Checked Locking Pattern),期望做到多线程安全的同时又兼顾性能。然而,著名 c++ 专家 Scott Meyers 早在2004年就写过一篇论文 C++ and the Perils of Double-Checked Locking 专门讨论过上面这段代码,文中第 3 节和第 4 节主要从内存顺序(memory order)角度指出了这种实现存在问题,所以这实际上是一种错误的实现。然而糟糕的是,作者指出 c++ 标准(2004年c++11还没出现)在语言层面并没有一个可用的机制来获得这里需要的 memory order,正确的实现需要依赖系统相关的库,例如linux系统下的pthread库。在c++11出现后,这个问题得到了解决,c++11从语言层面提供了编写跨平台多线程程序所需的基础组件,例如多线程内存模型、原子变量、thread等,本文主要讨论原子变量(atomic)以及memory order相关的内容,在讨论过程中相关的地方会分析这个singleton实现的问题以及正确的做法。
(1) atomic类型和std::memory_order
c++11标准在头文件<atomic>里定义了 模板类型atomic<T> ,它封装了原子操作以及memory order相关的特性,并对各种整型(char、short、int、long等)、指针等类型提供了特化版本。需要注意的是,atomic<T>类型既不可copy也不可move,特化版本在atomic<T>的成员函数之外,一般会提供额外的成员函数,例如atomic<int>有额外的成员函数fetch_add、fetch_sub、fetch_and、fetch_or 等。
// 头文件<atomic> template<class T> struct atomic; // 头文件<memory> template<class T> struct atomic<T*>;
多线程同时访问(修改或读取)同一个原子变量,其行为是well-defined(相应的,多线程同时读写非原子变量,其行为是undefinde behavior)。除此之外,对原子变量的访问,还能建立线程间的同步关系,并对非原子变量类型的内存访问提供一定的顺序保证。
原子变量有两个最基本的成员函数,load 读取原子变量的值,store 写入某个值到原子变量,读取和写入都是原子的:

这些操作都有一个std::memory_order类型的参数,它是一个enum类型,定义了c++11标准里不同的memory order:
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;
这些枚举值在多线程的内存访问顺序上提供了不同程度的约束,其中memory_order_relaxed是最弱的,最强的是memory_order_seq_cst(它也是所有原子操作的默认参数)。关于这些memory_order值的含义以及它们对内存访问顺序的约束,后面会逐步来讨论。
c++11对原子变量的访问可以分为如下几类:
relaxed operation:
以memory_order_relaxed为参数的load、store、read-modify-write(例如fetch_add)操作称为relaxed operation,它只保证操作的原子性,不带来任何memory order的约束。
以memory_order_release(或更强的memory order,例如memory_order_seq_cst)为参数的store操作称为release operation(Mutex类型对象的lock()操作也是release operation,这里 Mutex 泛指符合互斥变量要求的类型,例如std::mutex,std::timed_mutex都符合)
以memory_order_acquire(或更强的memory_order,例如memory_order_seq_cst)为参数的load操作称为acquire operation(Mutex类型对象的unlock()操作也是release operation,这里 Mutex 泛指符合互斥变量要求的类型,例如std::mutex,std::timed_mutex都符合)
以memory_order_consume(或更强的memory_order,例如memory_order_seq_cst)为参数的load操作称为consume operation。
(2) memory location
对c++程序来说,内存就是一串连续的字节序列。我们说内存访问,到底是访问什么,是某个字,某个字节,某个bit,还是某块buffer ?
对于这个问题,c++11定义了memory location的概念,一个memory location指的是某个scalar type的对象(包括算术类型、指针类型、枚举类型和std::nullptr_t类型),或者最长的 相邻 非0长度bit域序列,下面这个例子来自cppreference,很好的解释了什么是memory location,注意变量 b 和 c 是同一个memory location, 变量 c 和 d 之间有一个长度为0的bit域隔开,因此变量 d 构成一个单独的memory location。
struct S {
char a; // memory location #1
int b : 5; // memory location #2
int c : 11, // memory location #2 (continued)
: 0,
d : 8; // memory location #3
struct {
int ee : 8; // memory location #4
} e;
} obj; // The object 'obj' consists of 4 separate memory locations
(3) data race
在多线程环境下,同一个 memory location 完全有可能同时被不同的线程访问到(c++ 允许不同的线程在没有任何同步的情况下同时访问同一个memory location),如果不加任何限制,很可能陷入可怕的data race。
所谓data race,容易理解的说法(不那么严密),是指两个线程同时访问同一个memory location,且至少有一个线程是修改操作。例如一个线程在写一个整型变量,另一个线程同时在读取这个整型变量,就会引起data race。需要注意,如果访问的是原子变量,或者两个线程对同一个memory location的访问遵循一定的先后顺序,则不认为发生了data race。
一旦程序发生了data race,便会产生未定义行为(undefined behavior)。啥叫"未定义行为", 在 C++ Concurrency IN ACTION 这本书里作者举了个例子(5.1.2节,p106), 那就是含有未定义行为的程序导致显示器着火了。
现在回头看小猿默写的那段代码,潜在的第一个问题就是可能存在如下图所示的data race,_pInstance 是一个普通的指针类型变量,因而是一个memory location,线程2是修改操作,如果线程1 和 线程2 同时访问该memory location,则完全符合data race的定义, 程序可能会产生未定义行为,幸好服务器不带显示器啊!
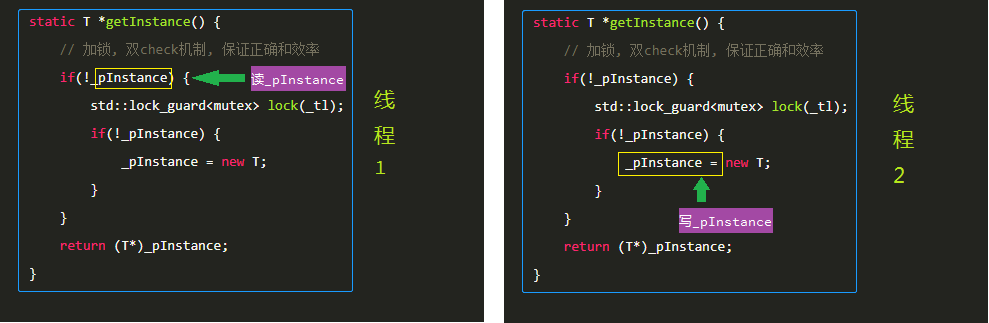
针对该单例实现代码的data race, 可以利用原子变量来修复(改动用黄色高亮显示),因为多线程同时访问同一个原子变量不构成data race:
template<typename T>
class XX_Singleton {
public:
static T* getInstance() {
// 加锁, 双check机制, 保证正确和效率
T* tmp = _pInstance.load(memory_order_relaxed);
if(tmp == nullptr) {
std::lock_guard<mutex> lock(_tl);
tmp = _pInstance.load(memory_order_relaxed);
if(tmp == nullptr) {
tmp = new T;
_pInstance.store(tmp, memory_order_relaxed);
}
}
return tmp;
}
protected:
static atomic<T*> _pInstance; // 用一个原子变量来存储单例对象的指针
};
// 静态成员变量的定义
template <typename T>
volatile T* XX_Singleton<T>::_pInstance = {nullptr};
(4) memory order
什么是memory order? 我们先通过一个简单的代码片段来了解:
// 全局变量
atomic<int> x; // 整型原子变量x, 初值为0
atomic<int> y; // 整型原子变量y, 初值为0
// 线程A
y.store(2, memory_order_relaxed); // 给y赋值2
x.store(1, memory_order_relaxed); // 给x赋值1
// 线程B
if (x.load(memory_order_relaxed) == 1) { // 如果读到x的值为1
assert(y.load(memory_order_relaxed) == 2)); // assert会失败吗?
}
这里对原子变量 x 和 y 的访问都使用 memory_order_relaxed,前面说过 memory_order_relaxed 可以确保操作的原子性,且多个线程同时访问同一个原子变量不会引起data race。现在的问题是, 线程2的assert有可能失败吗?
答案是会! 也就是说,线程B在读到 x 的值为1的前提下,仍然可能读到 y 的值为0(初值)。可能你感到有点困惑,线程A所执行的代码,是先给 y 赋值2,然后给 x 赋值1, 而线程B已经读到 x 的值为1了, 怎么可能读到的 y 值不是2呢?
原因可能有多种,其一,就是代码的书写顺序不一定和代码的执行顺序相同,这个顺序的不同,可能是因为编译器在生成指令的时候做了重排【Memory Ordering at Compile Time】,也可能是cpu在运行时进行了指令重排(instruction reorder),而编译器和cpu之所以这么做, 都是为了最大程度优化程序性能。其二,cpu一般是有多级缓存的,一个写入操作不一定立刻把新的值更新到内存,而一个读取操作也可能读取的是缓存值。
因此,虽然线程A所执行代码的书写顺序是先给 y 赋值后给 x 赋值, 但编译器生成的指令顺序可能是相反的(先给 x 赋值后给 y 赋值),也可能是线程B读到了 x 的最新值,但是读到的 y 值是运行B线程的cpu缓存的 y 值,结果就是线程B里面的assert判断有可能失败。
前面说到过,Scotter Meyes在论文 C++ and the Perils of Double-Checked Locking 中指出了小猿默写的单例实现代码里存在 memory order 的错误,现在我们可以来看看问题是什么了。
创建T类型的实例并保存其指针到_pInstance,实际上包括下面三个步骤:
(Ⅰ)分配内存 : tmp = operator new(sizeof(T));
(Ⅱ)调用T的构造函数 : new (tmp) T;
(Ⅲ)设置_pInstance的值 : _pInstance.store(tmp, memory_order_relaxed);
我们从形式上把代码写成上面这样的三步,然后分析如下两个线程同时调用getInstance()的情况:
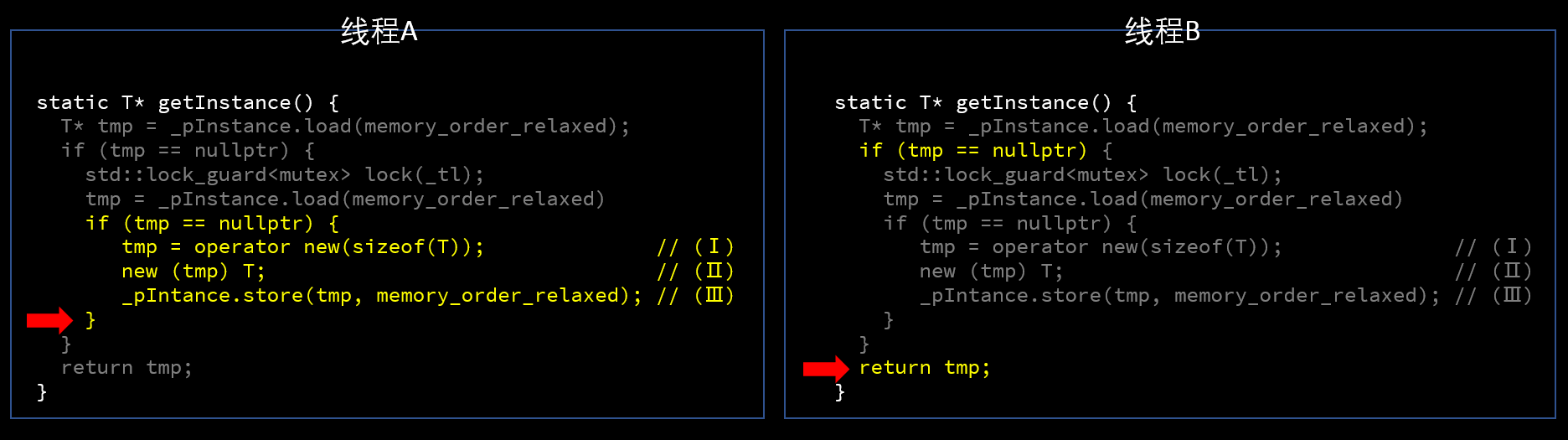
红色箭头表示两个线程正在执行的位置,线程A 完成实例的创建,并将指针存入原子变量_pInstance(memory_order参数为memory_order_relaxed,只保证操作的原子性),线程B读到_pInstance为非空指针,于是返回实例地址。问题来了,线程A和线程B各自返回的实例指针,有没有问题?(请先思考一下再往下看)
答案是,线程A返回的实例指针没有问题,它指向一个完整构造的T类型的对象,因为在单个线程内(线程A),前面的语句同后面的语句有 sequenced-before 关系,也就是说,线程A里最后的return语句执行的时候,它前面的语句一定执行完成了,因此T的实例一定是构造好的。
而线程B返回的实例指针,可能指向的是一个尚未完成构造的T类型对象!
首先,线程A内的代码书写顺序(Ⅰ) =》(Ⅱ)=》(Ⅲ)不一定就是其执行顺序。根据Scotter Meyes 的论文C++ and the Perils of Double-Checked Locking 所述,编译器倾向于产生(I)=》(Ⅲ)=》(Ⅱ)这样的执行代码顺序,也就是构造函数最后才执行:
(Ⅰ)分配内存 : tmp = operator new(sizeof(T));
(Ⅲ)设置_pInstance的值 : _pInstance.store(tmp, memory_order_relaxed);
(Ⅱ)调用T的构造函数 : new (tmp) T;
其次,即使线程A内代码就是按照(Ⅰ) =》(Ⅱ)=》(Ⅲ)的顺序执行,T的构造函数对成员变量的修改,也不一定对线程B全部可见。总之就是,memory_order_relaxed除了确保操作的原子性,并没有在两个线程之间提供任何同步。因此对于线程B来说,有可能返回的是一个指向未完成构造的实例。试想一下,如果T代表储户信息,你的的账户本来有1亿元, 结果线程B返回的实例,告诉你余额为996元,那是不是很梦幻。【注:即使编译器生成的执行代码顺序是(I)=》(Ⅲ)=》(Ⅱ),对线程A来说,最后的return语句返回的指针所指的实例依然是完成了构造的。】
你说,这不是我想要的结果啊。对于本节开始的那个简单例子,我就是希望线程B在读到 x 值为1的情况下,读到的 y 值一定是2,换句话说,希望对线程B来说的确就是 y.store 发生在 x.store 之前。这实际上是在要求线程A所产生的某些内存改变,先于线程B的某些操作发生,从而使得线程A的内存改变对线程B的某些操作具有可见性。在c++11里,通过给原子变量的读/写操作指定适当的memory_order参数是可以获得预期的顺序的,下面开始逐一介绍memory order相关的内容,先了解单线程情况下的操作间的顺序:
(4.1) sequenced-before
关于sequenced-before有几十条规则来描述什么情况下两个evaluation具有sequenced-before关系,这里不深究,详见 evaluation order 。
简单来说,sequenced-before 描述的是同一个线程里不同表达式求值的先后顺序【evaluation:姑且翻译为 "求值" 吧,一个evaluation可能是一个完整的语句,也可能是某个操作数或者参数的求值,具体定义见 Evaluation of Expressions】,如果evaluation A sequenced-before evaluation B, 那么 A 一定在 B 开始之前完成。简单的理解就是在同一个线程里,代码的书写顺序就是其执行顺序,写在前面的语句执行完了才会执行后续语句,这个很符合我们对代码执行顺序的预期,即我怎么写程序就怎么执行(按照书写的顺序执行)。【注:严格说 A 不一定发生在 B 之前,如果 A 和 B 访问完全独立的两个变量,仍然有可能对 A 和 B 做指令重排,但是对于单线程来说,在内存效果上,A 和 B 重排与否并无影响,参见 Happens-Before Does Not Imply Happening Before】
需要注意的是调用一个多参数的函数时,其各个参数的计算,是没有sequenced-before关系的,标准没有规定函数参数的求值是从左到右或者从右到左的顺序。在 Scott Meyers 的《Effective Modern C++》一书的 Item 21 里面有一个和 sequeced-before 相关的例子,下面这段代码里对函数processWidget()的调用可能会引起Widget对象的泄漏:
/* 说明: 因为函数参数的计算没有sequeced-before关系,也就是computePriority() 和shared_ptr<Widget>构造函数 的调用顺序不确定,所以可能有如下的调用顺序: (I) new Widget (II) computePriority() (III) shared_ptr<Widget>的构造函数 如果computePriority()函数调用过程中抛出异常,那么就会泄漏Widget对象 */ processWidget(shared_ptr<Widget>(new Widget), computePriority());
根据c++的规定,processWidget()函数的两个参数计算,并没有sequenced-before关系, computePriority()函数调用可能发生在new Widget和shared_ptr<Widget>构造函数调用之间,如果computePriority()发生异常,那就会泄漏Widget对象【注意,根据sequenced-before的规则,new Widget是 sequenced-before shared_ptr<Widget>构造函数的】。如果改成下面这样就不会有问题,原因见注释。
/* 说明: 语句(1) sequenced-before 语句(2), 因此pw一定在computePriority()调用之前就完成了构造, 即使computePriority()抛出异常,pw也能正确析构,不会有泄漏 */ shared_ptr<Widget> pw(new Widget); // (1) processWidget(pw, computePriority()); // (2)
(4.2) carries dependency
carries dependency 描述的是同一个线程里不同的表达式求值(evaluation)之间的依赖关系。在同一个线程里,如果evaluation A sequenced-before evaluation B, 并且 A 是 B 的操作数,或者 A 写入一个scaler类型的对象 M 而 B 读取 M 【scalar类型包括算术类型、指针类型、枚举类型和std::nullptr_t类型】,那么就说 A carries dependency into B。carries dependency 关系具有传递性,也就是说如果 A carries dependency into X,而 X carries dependency into B, 那么就有 A carries dependency into B。
/* *** 某个线程 *** */ // (1) carries dependency into (2) x = 1; // (1) y = 3 + x; // (2) // (3) carries dependency into (4) m = 3; // (3) n = m; // (4) // (5) carries dependency into (6), // (6) carries dependency into (7), // 所以 (5) carries dependency into (7) a = 1; // (5) b = a + 1; // (6) c = b - 2; // (7)
sequenced-before 和 carries dependency描述了单线程情形下求值(evaluation)的先后顺序,接下来介绍多线程情形下的操作顺序,首先是多线程对单个原子变量修改顺序的约束:
(4.3) modification order
modification order描述的是多线程程序里,对单个原子变量修改顺序的约束。c++11规定,在程序的一次运行期间,对同一个原子变量的修改操作具有一个全局顺序(total order),这个顺序对于所有线程来说是一样的。注意,只有原子变量符合这个规则,非原子变量没有这个约束。
下面通过一个简单例子来理解一下,线程 A 依次向原子变量 n 写入0,1两个值,线程 B 读取原子变量 n 的值5次。这里只有一个线程修改原子变量 n, 因此原子变量 n 的 modification order 就由线程A决定,即依次写入0, 1,根据 modification order 的规定,同一个原子变量的修改顺序对所有线程来说有一个total order, 因此线程B看到的也是 "n 被依次写入0, 1" 这个修改顺序(好像是废话啊,我同意你,但是确实得有这么个约束)。什么意思呢, 就是说对线程B来说,不可能先读到1, 然后再读到0,否则的话,对于B来说那 n 的修改顺序就成了'先写入1, 后写入0,这不符合modification order的约束。需要注意的是,线程B是可能多次读到0的,也就是可能读到序列 [0,0,0,1,1],但是不可能读到 [0,0,1,1,0] 这样的序列。
atomic<int> n; // 初值为0
// 线程 A
for (int i = 0; i < 2; ++i) {
n.store(i, memory_order_relaxed);
}
// 线程 B
int readed_values_B[5] = { 0 };
for (int i = 0; i < 5; ++i) {
readed_values_B[i] = n.load(memory_order_relaxed);
}
前面这些概念都比较容易理解,接下来介绍的内容相对来说要晦涩一些,请耐心阅读,如果有什么疑问欢迎一起讨论。
(4.4) synchronize-with
如果你是第一次接触这个概念,很可能会觉得每个单词都认识,放一起就一脸懵逼。(一看就懂的大神,请收下我膝盖Orz)
我们先看比较简单的2个线程的情况( C++ Concurrency IN ACTION ,5.3.3节,p132):
Synchronization is pairwise, between the thread that does the release and the thread that does the acquire. A release operation synchronizes-with an acquire operation that reads the value written.
理解一下就是,如果线程A以release operation(memory_order_release或更强的memory_order)修改了一个原子变量,而另一个线程B以acquire operation(memory_order_acquire或更强的memory_order)读到线程A修改的值,那就说线程A 的修改操作 synchonize-with 线程B 的读取操作,举个例子:
struct Point {
int x_;
int y_;
};
Point g_point;
std::atomic<int> g_guard(0);
// 线程A
void writePoint() {
g_point.x_ = 1;
g_point.y_ = 2;
// 以memory_order_release写入1到原子变量
g_guard.store(1, memory_order_release);
}
// 线程B
void readPoint() {
// 以memory_order_acquire读取原子变量,直到读到1 (线程A所写入的值)
while (g_guard.load(memory_order_acquire) != 1) {
this_thread::yield();
}
// while 循环结束时,一定是以memory_order_acquire读到线程A写入的值1
assert(g_point.x_ == 1 && g_point.y_ == 2); // 不会失败
}
线程A 的 g_guard.store(1, memory_order_release)同线程B里while循环的最后一次g_guard.load(memory_order_acquire)具有 synchronize-with 关系【注意是"while循环最后一次g_guard.load(memory_order_acquire)",因为只有这一次g_guard.load(memory_order_acquire)才读到线程A写入的值1】
这里synchronize-with 描述的是两个线程对同一个原子变量的修改和读取之间的关系,它在两个相关线程建提供了一个比较强的memory order约束: 线程A的store操作之前的所有内存修改(memory effects),对线程B的load之后的操作都可见,并且线程A的store操作之前的指令不允许reorder到store操作之后,线程B的load操作之后的指令不允许reorder到load之前。synchronize-with 关系像是在两个线程之间建立了一个内存屏障,这个屏障引入了一种较强的先后顺序,屏障前的内存修改对屏障后的所有操作都可见。
具体到上面这个例子,就是线程A对结构体g_point的修改,在线程B的“while循环最后一次g_guard.load(memory_order_acquire)”之后都是可见的,因此线程B的assert不会失败:

除了上面这种两个线程之间的synchronize-with关系, 还有一种情况涉及到多个线程对同一个原子变量的读写操作,理解这种情况需要引入 release sequence 的概念。
(4.5) release sequence
release sequence 在 cppreference 上的定义
翻译一下就是,对原子变量 M 的 release operation A ,以及同一个线程对该原子变量的修改,或者别的线程对该原子变量的read-modify-write操作(例如fetch_add、fetch_sub等成员函数),所构成的最长连续序列,就称为以A为首的 release sequence。
除了为首的操作A要求是 release operation(memory order参数为memory_order_release或更强的约束),该原子变量的release sequence里其余的操作的memory order参数可以随意(例如可以是memory_order_relaxed)。
A synchronize-with B 的另外一种情况,就是最后的 acquire operation B(以memory_order_acquire或更强的memory_order读)所读到的值,是以 release operation A为首的release sequence所写入的某个值。
下面是c++语言标准(29.3节 "order and consistency" 第2条)里对 synchronize-with 的定义:
An atomic operation A that performs a release operation on an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release sequence headed by A。
前面(4.4)节介绍的两个线程的synchronize-with关系,是其中一种简单的特殊情形。
现在我们知道,synchronize-with在两个线程之间提供了一种比较强的同步,不过有时候这种同步可能太强了,下面再看一个例子:
struct Payload {
int x_;
int y_;
};
atomic<Payload*> g_payload;
atomic<int> g_nothing;
// 线程A,创建Payload实例
void produce_data() {
g_nothing.store(996, memory_order_relaxed);
// 创建并初始化对象
Payload* p = new Payload;
p.x_ = 1;
p.y_ = 2;
// 以memory_order_release写入原子变量
g_payload.store(p, memory_order_release);
}
// 线程B,读取线程A创建的Payload数据
void consume_data() {
Payload* payload = nullptr;
// 以memory_order_acquire读取原子变量,直到读到非空 (线程A所写入的值)
while ((payload = g_payload.load(memory_order_acquire)) != nullptr) {
this_thread::yield();
}
assert(payload.x_ == 1 && payload.y_ == 2); // 不会失败
// 使用payload干一些事情。。。
assert(g_nothing.load(memory_order_relaxed) == 996); // 不会失败,但是线程B并不关心g_nothing的值
}
由于两个线程之间的synchronize-with关系,线程B(consume_data()函数)的两个assert语句都不会失败。但是线程B可能只关心 g_payload 的数据,对 g_nothing 不关心,可是synchronize-with顺带把线程A对 g_nothing 的修改也同步到线程B了,这自然会带来额外的开销
这个例子举得不咋的,不过它代表了一类使用场景,即通过一个原子类型的指针在两个线程间传递某个结构体数据。消费数据的线程一般只关心结构体的数据,其余的它不关心,所以只需要确保生产数据的线程对结构体所做的内存修改,对消费线程可见就行了,其余的数据不需要同步。c++11提供了一种比synchronize-with更弱的内存顺序比较适合这种场景,那就是 depency-ordered before 关系。
(4.6) dependency-ordered before
dependency-ordered before有两种情况:
(Ⅰ)一个线程以 release operation A(memory order为memory_order_release或者更强)修改原子变量,另一个线程以 consume operation(memory order为memory_order_consume或者更强)读该原子变量,读到的值是以A为首的release sequence中任意一个修改值;【同synchronize-with的定义非常类似,只是读取操作从acquire operation变成consume operation】
(Ⅱ)A dependency-ordered before X(跨线程),而 X carries dependency into B(同一个线程内)。
注意一下情况(Ⅱ),它结合了跨线程的dependency-ordered before和同一个线程内的carries dependency into关系,说明在读线程里,只有依赖于原子变量的操作才会和写线程产生同步关系。
现在再来看一下通过一个原子类型的指针在两个线程间传递数据结构的例子,我们把读取操作从memory_order_acquire改成memory_order_consume(黄色高亮代码):
struct Payload {
int x_;
int y_;
};
atomic<Payload*> g_payload;
atomic<int> g_nothing;
// 线程A,创建Payload实例
void produce_data() {
g_nothing.store(996, memory_order_relaxed);
// 创建并初始化对象
Payload* p = new Payload;
p.x_ = 1;
p.y_ = 2;
// 以memory_order_release写入原子变量
g_payload.store(p, memory_order_release);
}
// 线程B,读取线程A创建的Payload数据
void consume_data() {
Payload* payload = nullptr;
// 以memory_order_consume读取原子变量,直到读到非空 (线程A所写入的值)
while ((payload = g_payload.load(memory_order_consume)) != nullptr) {
this_thread::yield();
}
assert(payload.x_ == 1 && payload.y_ == 2); // 不会失败
// 使用payload干一些事情。。。
assert(g_nothing.load(memory_order_relaxed) == 996); // 这里可能失败
}
线程A的g_payload.store(p, memory_order_release)同线程B里while循环的最后一个payload = g_payload.load(memory_order_consume)具有dependency-ordered before关系,后者又carries dependency into线程B里的assert(payload.x_ == 1 && payload.y_ == 2)语句,因此符合(Ⅱ)所描述的denpendency-ordered before关系,也就是说线程A对payload数据的修改,对线程B的assert(payload.x_ == 1 && payload.y_ == 2)可见,因此这个assert语句不会失败。但是线程B的assert(g_nothing.load(memory_order_relaxed) == 996)语句,并不依赖于payload, 因此无法跟线程A的g_payload.store(p, memory_order_release)建立起denpendency-ordered before关系,没有机制保证线程A的g_nothing.store(996, memory_order_relaxed)操作对线程B可见,因此线程B的assert(g_nothing.load(memory_order_relaxed) == 996)语句可能会失败。
虽然dependency-ordered before比synchronize-with更高效,因为它只需要在有依赖关系的数据间建立同步,但实际上,大多数编译器并没有真正实现release-consume操作,而是直接用memory_order_acquire代替memory_order_consume(参见The Purpose of memory_order_consume in C++11这篇文章里Today's Compiler Support is Lacking小节)
(4.7) inter-thread happens before
Between threads, evaluation A inter-thread happens before evaluation B if any of the following is true
顾名思义,inter-thread happens before描述的是不同线程间操作的先后顺序,只有符合这5条规则之一的情况,才具备inter-thread happens before关系。这里需要注意下第3条,这里一定是 A synchronize-with X,如果是 A dependency-ordered before X,是不能得出 A inter-thread happens before B 的。
基于上面的各种概念,c++11还定义了更一般的happens-before关系,它既包括同一个线程里的操作顺序,也包括跨线程的操作间的顺序:
(4.8) happens-before
Regardless of threads, evaluation A happens-before evaluation B if any of the following is true:
(4.9) 常见和默认的memory ordering
c++11为memory_order定义了6个枚举值(参见本文第(1)节),在操作原子变量的时候,读和写所用的memory_order参数通常需要配对使用,不能随意组合,例如memory_order_acquire和memory_order_release可以配对使用,产生前面所介绍的synchronize-with关系。本节简单介绍一下常见的memory ordering:
(4.9.1) relaxed ordering
以memory_order_relaxed作为参数的原子操作,这个对于操作顺序没有任何约束,只保证操作的原子性。例如:
atomic<int> x = {0};
atomic<int> y = {0};
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
可能产生r1 == r2 == 42 的结果,尽管在线程1里 A sequenced-before B, 在线程2里 C sequenced-before D,但是因为memory_order_relaxed不提供任何顺序约束,对于线程1来说,可能是D发生在C的前面,整个执行顺序可能是D ==> A ==> B ==> C,从而导致r1 == r2 == 42 。
(4.9.2) release-acquire ordering
一个线程以memory_order_release对原子变量进行store操作,另一个线程以memory_order_acquire对同一个原子变量进行load操作,这个是(4.4)节synchronize-with关系的一种具体表现形式,这里就不再举例了。
(4.9.3) release-consume ordering
一个线程以memory_order_release对原子变量进行store操作,另一个线程以memory_order_consume对同一个原子变量进行load操作,这个是(4.6)节dependency-ordered before关系的一种具体表现形式,也不再举例。
(4.9.4) sequentially-consistent ordering(默认参数)
以 memory_order_seq_cst 为参数对原子变量进行load、store或者read-modify-write操作。c++11所有的原子操作都是采用memory_order_seq_cst作为默认参数,中文翻译为“顺序一致性”,这是所有memory_order类型里最强的一种【注:java只有这种memory order,通过java的关键字volatile来提供】。sequentially-consistent(顺序一致性)在原子变量操作顺序上有一个很强的约束:所有以memory_order_seq_cst为参数的原子操作(不限于同一个原子变量),对所有线程来说有一个全局顺序(total order),并且两个相邻memory_order_seq_cst原子操作之间的其它操作(包括非原子变量操作),不能reorder到这两个相邻操作之外。【注:同一个程序的不同运行,这个全局顺序是可以不一样的】。
我们通过下面的例子来理解一下顺序一致性:
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
// 线程A
void write_x() {
x.store(true, memory_order_seq_cst);
}
// 线程B
void write_y() {
y.store(true, memory_order_seq_cst);
}
// 线程C
void read_x_then_y() {
while (!x.load(memory_order_seq_cst))
;
if (y.load(memory_order_seq_cst)) {
++z;
}
}
// 线程D
void read_y_then_x() {
while (!y.load(memory_order_seq_cst))
;
if (x.load(memory_order_seq_cst)) {
++z;
}
}
int main() {
std::thread thread_a(write_x);
std::thread thread_b(write_y);
std::thread thread_c(read_x_then_y);
std::thread thread_d(read_y_then_x);
thread_a.join(); thread_b.join(); thread_c.join(); thread_d.join();
assert(z.load() != 0); // 一定不会失败
}
4个线程对两个原子变量x和y的操作都是memory_order_seq_cst,构成了顺序一致性(sequentially-consistent),因此对4个线程来说,对原子变量x和y的操作顺序是一致的,在这个全局一致的操作顺序里:
(Ⅰ)要么x.store(true, memory_order_seq_cst)发生在y.store(true, memory_order_seq_cst)之前,这时候线程D的x.load(memory_order_seq_cst)一定读到true,从而执行z++ ;
(Ⅱ)要么y.store(true, memory_order_seq_cst)发生在x.store(true, memory_order_seq_cst)之前,这时候线程C的y.load(memory_order_seq_cst)一定读到true,从而执行z++ ;
不论哪种情况,z值都会被修改,因此main()函数最后的assert语句一定不会失败。
在本文第(4)节"memory order"部分,我们分析了小猿所写单例代码所存在的memory order问题(线程B可能返回一个没有完成构造的实例)。现在有了c++11定义的memory order相关的概念,这个问题就可以很容易得到修复了。
(4.10) 利用c++11的memory order正确实现单例模式
首先利用 synchronize-with关系 可以修正这个错误.
template<typename T>
class XX_Singleton {
public:
static T* getInstance() {
T* tmp = _pInstance.load(memory_order_acquire);
if(tmp == nullptr) {
std::lock_guard<mutex> lock(_tl);
tmp = _pInstance.load(memory_order_relaxed);
if(tmp == nullptr) {
tmp = new T;
_pInstance.store(tmp, memory_order_release);
}
}
return tmp;
}
};
只有黄色高亮的两个地方做了修改,把load的memory_order参数从memory_order_relaxed 改成 memory_order_acquire,把store的memory_order参数从memory_order_relaxed 改成 memory_order_release。
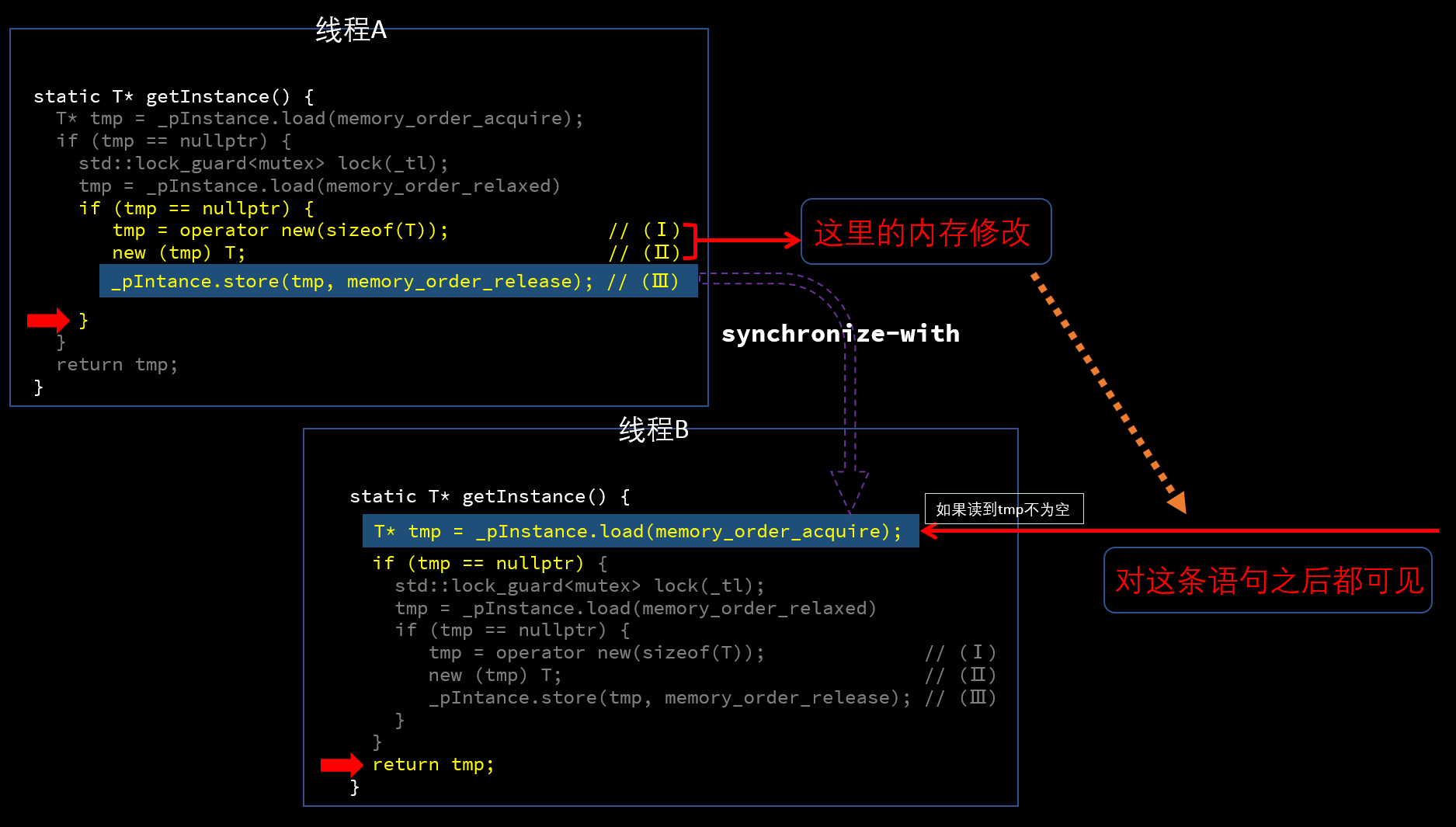
本文只关注线程B第一行读到tmp不为空直接返回的情况(其余的情况不涉及这里的memory_order,可以自己思考),如果读到的恰好是线程A的(Ⅲ)写入的值,那么会形成如上图所示的synchronize-with关系,它可以确保线程A的(Ⅰ)(Ⅱ)两步产生的内存变化,对线程B的 _pInstance.load(memory_order_acquire) 语句之后都可见,从而线程B返回的实例一定是完成了构造的。
因为顺序一致性(sequentially-consistent)在多线程的原子变量操作顺序上提供了比 synchronize-with 更强的约束,因此用默认的原子操作,可以达到一样的目的,但是性能比synchronize-with略低:
template<typename T>
class XX_Singleton {
public:
static T* getInstance() {
T* tmp = _pInstance.load(); // 等价于_pInstance.load(memory_order_seq_cst)
if(tmp == nullptr) {
std::lock_guard<mutex> lock(_tl);
tmp = _pInstance.load(memory_order_relaxed);
if(tmp == nullptr) {
tmp = new T;
_pInstance.store(tmp); // 等价于_pInstance.store(tmp, memory_order_seq_cst)
}
}
return tmp;
}
};
最后,利用dependency-ordered before关系也可以达成正确实现单例模式所需的memory ordering(正确性分析跟本节开头利用synchronize-with所做的实现类似,读者可以自行思考一下):
template<typename T>
class XX_Singleton {
public:
static T* getInstance() {
T* tmp = _pInstance.load(memory_order_consume);
if(tmp == nullptr) {
std::lock_guard<mutex> lock(_tl);
tmp = _pInstance.load(memory_order_relaxed);
if(tmp == nullptr) {
tmp = new T;
_pInstance.store(tmp, memory_order_release);
}
}
return tmp;
}
};
说到单例,不得不说c++11另一个重要的细节改动,那就是多线程情况下,局部static变量的初始化是线程安全的,语言确保局部静态变量只会初始化一次(参见stackoverflow回答,回答里有给出相关的语言标准)。标准 6.7节第4段有如下说明:
If control enters the declaration concurrently while the variable is being initialized, the concurrent execution shall wait for
completion of the initialization.
基于此,从c++11开始,简单可靠的单例实现可以直接通过static局部变量实现:
template<typename T>
class XX_Singleton {
public:
static T* getInstance() {
static T _instance;
return &_instance;
};
编译器会确保这里的多线程安全(通常情况下, 编译器生成的代码也是采用DCLP来实现的)。
另外,c++11还提供了std::call_once函数,也可以用来实现多线程安全的单例对象初始化,这里就不再赘述了。
完整的单利模式
template<typename T>
class XX_Singleton {
public:
static T* getInstance() {
// 加锁, 双check机制, 保证正确和效率
T* tmp = _pInstance.load(memory_order_accquire);
if(tmp == nullptr) {
std::lock_guard<mutex> lock(_tl);
tmp = _pInstance.load(memory_order_relaxed);
if(tmp == nullptr) {
tmp = new T;
_pInstance.store(tmp, memory_order_release);
}
}
return tmp;
}
virtual ~XX_Singleton() {
};
protected:
XX_Singleton() {
}
XX_Singleton (const XX_Singleton &);
XX_Singleton& operator=(const XX_Singleton &);
protected:
static mutex _tl;
static atomic<T*> _pInstance; // 用一个原子变量来存储单例对象的指针
};
// 静态成员变量的定义
template <typename T>
volatile T* XX_Singleton<T>::_pInstance = {nullptr};

 浙公网安备 33010602011771号
浙公网安备 33010602011771号