
Python爬虫之XML
一、请求参数形式为xml
举例说明。
现在有这样一个网址:https://www.runff.com/html/live/s1484.html;想要查询图片列表,打开F12,观察到请求如下:
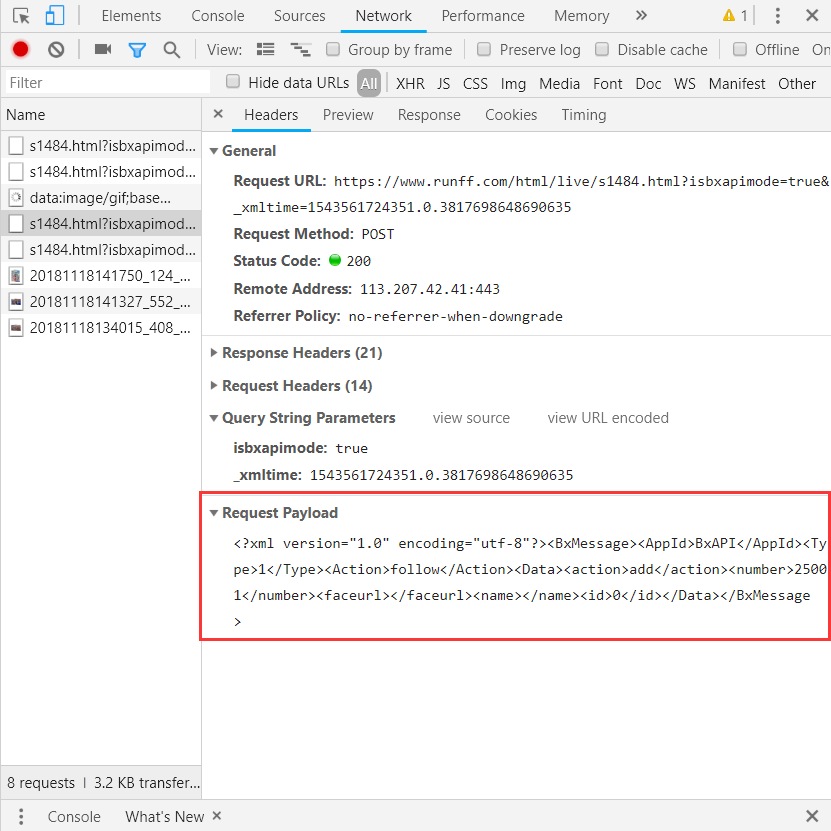
这里的请求参数形式为xml,使用python模仿请求的代码这样写
import requests fid = 3748813 bib = 25001 url = "https://www.runff.com/html/live/s1484.html" params = { "isbxapimode": "true", "_xmltime": "1543561724351.0.3817698648690635" } headers = { "cookie": "ASP.NET_SessionId=hb30jkbmqnfwyhjo0iqrrkdi", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36", } payload = '<?xml version="1.0" encoding="utf-8"?><BxMessage><AppId>BxAPI</AppId><Type>1</Type>' \ '<Action>getPhotoList</Action><Data><fid>{}</fid>' \ '<number>{}</number><minpid>0</minpid>' \ '<time>Wed Nov 21 2018 14:21:42 GMT+0800 (中国标准时间)</time><sign>false</sign>' \ '<pagesize>100</pagesize></Data></BxMessage>'.format(fid, bib) payload = payload.encode('utf-8') r = requests.post(url, headers=headers, params=params, data=payload, timeout=3) print(r.content.decode('utf-8'))
这里主要使用了post方法,将xml的参数直接以字符串的形式传给post的‘data’参数。
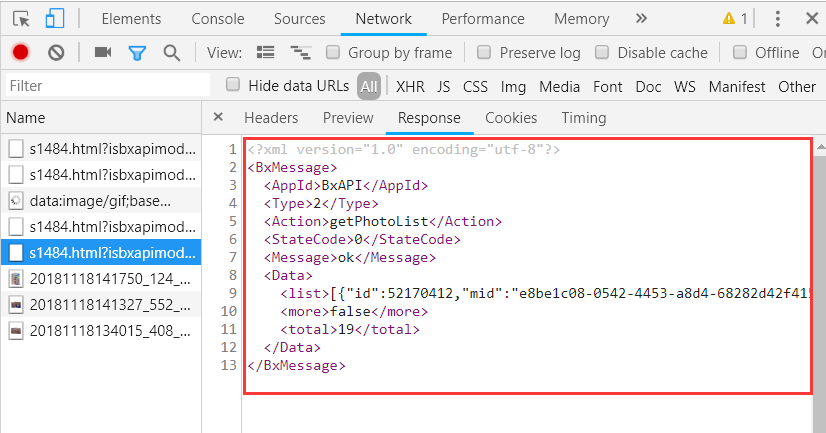
可以看到我们返回内容也是xml。这个时候就需要解析xml。
二、xml解析
xml原文(与上文的请求返回结果无关):
<?xml version="1.0" encoding="utf-8"?> <BxMessage> <AppId>BxAPI</AppId> <Type>2</Type> <Action>getPhotoList</Action> <StateCode>2</StateCode> <Message index="0">请先登录</Message> <Message index="1">ok</Message> <Data></Data> </BxMessage>
1.直接转成json处理
使用 xmltodict 库
代码:
from xmltodict import parse xml = '<?xml version="1.0" encoding="utf-8"?><BxMessage><AppId>BxAPI</AppId><Type>2</Type>' \ '<Action>getPhotoList</Action><StateCode>2</StateCode><Message index="0">请先登录</Message>' \ '<Message index="1">ok</Message><Data></Data></BxMessage>' data = parse(xml) # 解析xml为有序字典 print(data) box = data.get('BxMessage', {}) # 获取最外层的标签 app_id = box.get('AppId') # 获取次外层的标签 print(app_id) msg = box.get('Message', []) # 多个标签名相同时,获取到的是标签列表 for m in msg: print(m.get('@index')) # 获取属性,使用'@'前缀 print(m.get('#text')) # 获取标签文本,使用'#text'
输出:
OrderedDict([('BxMessage', OrderedDict([('AppId', 'BxAPI'), ('Type', '2'), ('Action', 'getPhotoList'), ('StateCode', '2'), ('Message', [OrderedDict([('@index', '0'), ('#text', '请先登录')]), OrderedDict([('@index', '1'), ('#text', 'ok')])]), ('Data', None)]))]) BxAPI 0 请先登录 1 ok
输出的是有序字典,取值可以和字典一样使用“get”。
假设有多个相同标签,转换成字典时,会将相同关键字的值组成一个列表。
2.直接解析xml
使用上文中的xml
简要解析代码:
from xml.etree import ElementTree xml = '<?xml version="1.0" encoding="utf-8"?><BxMessage><AppId>BxAPI</AppId><Type>2</Type>' \ '<Action>getPhotoList</Action><StateCode>2</StateCode><Message index="0">请先登录</Message>' \ '<Message index="1">ok</Message><Data></Data></BxMessage>' tree = ElementTree.fromstring(xml) # 从字符串解析得到xml结构 print(tree) # tree是一个xml 元素, BxMessage box = tree.find('Message') # 找tree下一级的标签 print(box) # box是一个xml 元素, BxMessage print(box.text) # 输出标签的内容 print(box.get('index')) # 获取标签属性 boxes = tree.findall('Message') # 找到所有该名字的标签, print(boxes) # 返回一个列表
输出:
<Element 'BxMessage' at 0x00000217E207D368> <Element 'Message' at 0x00000217E9CB0958> 请先登录 0 [<Element 'Message' at 0x00000217E9CB0958>, <Element 'Message' at 0x00000217E9CB98B8>]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号