pandas核心
pandas描述性统计
数值型数据的描述性统计主要包括了计算数值型数据的完整情况、最小值、均值、中位 数、最大值、四分位数、极差、标准差、方差、协方差等。在NumPy库中一些常用的统计学函数也可用于对数据框进行描述性统计。
np.min 最小值
np.max 最大值
np.mean 均值
np.ptp 极差
np.median 中位数
np.std 标准差
np.var 方差
np.cov 协方差
实例:
import pandas as pd import numpy as np # 创建DF d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])} df = pd.DataFrame(d) print(df) """ Name Age Rating 0 Tom 25 4.23 1 James 26 3.24 2 Ricky 25 3.98 3 Vin 23 2.56 4 Steve 30 3.20 5 Minsu 29 4.60 6 Jack 23 3.80 7 Lee 34 3.78 8 David 40 2.98 9 Gasper 30 4.80 10 Betina 51 4.10 11 Andres 46 3.65 """ # 测试描述性统计函数 print(df.sum())#(每列)求和 """ Name TomJamesRickyVinSteveMinsuJackLeeDavidGasperBe... Age 382 Rating 44.92 dtype: object """ print(df.sum(1))#1是轴向 按行求和 """ 0 29.23 1 29.24 2 28.98 3 25.56 4 33.20 5 33.60 6 26.80 7 37.78 8 42.98 9 34.80 10 55.10 11 49.65 dtype: float64 """ print(df.mean())#按列求均值 """ Age 31.833333 Rating 3.743333 dtype: float64 """ print(df.mean(1))#年龄和评分的均值 """ 0 14.615 1 14.620 2 14.490 3 12.780 4 16.600 5 16.800 6 13.400 7 18.890 8 21.490 9 17.400 10 27.550 11 24.825 dtype: float64 """
pandas提供了统计相关函数:
count() | 非空观测数量 | |
|---|---|---|
| 2 | sum() |
所有值之和 |
| 3 | mean() |
所有值的平均值 |
| 4 | median() |
所有值的中位数 |
| 5 | std() |
值的标准偏差 |
| 6 | min() |
所有值中的最小值 |
| 7 | max() |
所有值中的最大值 |
| 8 | abs() |
绝对值 |
| 9 | prod() |
数组元素的乘积 |
| 10 | cumsum() |
累计总和 |
pandas还提供了一个方法叫作describe,能够一次性得出数据框所有数值型特征的非空值数目、均值、标准差等。
import pandas as pd #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])} #Create a DataFrame df = pd.DataFrame(d) print(df.describe()) """ Age Rating count 12.000000 12.000000 mean 31.833333 3.743333 std 9.232682 0.661628 min 23.000000 2.560000 25% 25.000000 3.230000 50% 29.500000 3.790000 75% 35.500000 4.132500 max 51.000000 4.800000 """ print(df.describe(include=['object'])) """ Name count 12 unique 12 top Gasper freq 1 """ print(df.describe(include=['number'])) """ Age Rating count 12.000000 12.000000 mean 31.833333 3.743333 std 9.232682 0.661628 min 23.000000 2.560000 25% 25.000000 3.230000 50% 29.500000 3.790000 75% 35.500000 4.132500 max 51.000000 4.800000 """
pandas排序
Pandas有两种排序方式,它们分别是按标签与按实际值排序。
import pandas as pd import numpy as np unsorted_df=pd.DataFrame(np.random.randn(10,2), #十行 两列 随机生成数 index=[1,4,6,2,3,5,9,8,0,7], columns=['col2','col1']) print(unsorted_df) """ col2 col1 1 2.415183 -1.132430 4 -0.572576 0.135119 6 1.503749 -0.666407 2 -1.292311 -0.959626 3 -0.689003 0.146044 5 0.139045 -1.221794 9 -0.944587 -0.643555 8 0.848157 0.446215 0 -0.332118 1.215189 7 0.061888 0.265198 """
按行标签排序
使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序。
import pandas as pd d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Minsu','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65])} unsorted_df = pd.DataFrame(d) # 按照行标进行排序 sorted_df=unsorted_df.sort_index() print (sorted_df) """ Name Age Rating 0 Tom 25 4.23 1 James 26 3.24 2 Ricky 25 3.98 3 Vin 23 2.56 4 Steve 30 3.20 5 Minsu 29 4.60 6 Jack 23 3.80 7 Lee 34 3.78 8 David 40 2.98 9 Gasper 30 4.80 10 Betina 51 4.10 11 Andres 46 3.65 """ # 按照行索引标签进行降序排列 sorted_df = unsorted_df.sort_index(ascending=False) print (sorted_df) """ Name Age Rating 11 Andres 46 3.65 10 Betina 51 4.10 9 Gasper 30 4.80 8 David 40 2.98 7 Lee 34 3.78 6 Jack 23 3.80 5 Minsu 29 4.60 4 Steve 30 3.20 3 Vin 23 2.56 2 Ricky 25 3.98 1 James 26 3.24 0 Tom 25 4.23 """ sorted_df = unsorted_df.sort_index(ascending=True,axis=3) print(sorted_df) """ Age Name Rating 0 25 Tom 4.23 1 26 James 3.24 2 25 Ricky 3.98 3 23 Vin 2.56 4 30 Steve 3.20 5 29 Minsu 4.60 6 23 Jack 3.80 7 34 Lee 3.78 8 40 David 2.98 9 30 Gasper 4.80 10 51 Betina 4.10 11 46 Andres 3.65 """
按某列值排序
像索引排序一样,sort_values()是按值排序的方法。它接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
import pandas as pd d = {'Name': pd.Series(['Tom', 'James', 'Ricky', 'Vin', 'Steve', 'Minsu', 'Jack', 'Lee', 'David', 'Gasper', 'Betina', 'Andres']), 'Age': pd.Series([25, 26, 25, 23, 30, 29, 23, 34, 40, 30, 51, 46]), 'Rating': pd.Series([4.23, 3.24, 3.98, 2.56, 3.20, 4.6, 3.8, 3.78, 2.98, 4.80, 4.10, 3.65])} unsorted_df = pd.DataFrame(d) print(unsorted_df) """ Name Age Rating 0 Tom 25 4.23 1 James 26 3.24 2 Ricky 25 3.98 3 Vin 23 2.56 4 Steve 30 3.20 5 Minsu 29 4.60 6 Jack 23 3.80 7 Lee 34 3.78 8 David 40 2.98 9 Gasper 30 4.80 10 Betina 51 4.10 11 Andres 46 3.65 """ # 按照列标签进行排序 sorted_df = unsorted_df.sort_index(axis=1) print(sorted_df) """ Age Name Rating 0 25 Tom 4.23 1 26 James 3.24 2 25 Ricky 3.98 3 23 Vin 2.56 4 30 Steve 3.20 5 29 Minsu 4.60 6 23 Jack 3.80 7 34 Lee 3.78 8 40 David 2.98 9 30 Gasper 4.80 10 51 Betina 4.10 11 46 Andres 3.65 """ # 按照年龄排序 print(sorted_df.sort_values('Age')) """ Age Name Rating 3 23 Vin 2.56 6 23 Jack 3.80 0 25 Tom 4.23 2 25 Ricky 3.98 1 26 James 3.24 5 29 Minsu 4.60 4 30 Steve 3.20 9 30 Gasper 4.80 7 34 Lee 3.78 8 40 David 2.98 11 46 Andres 3.65 10 51 Betina 4.10 """ # 联合间接排序 print(sorted_df.sort_values(['Age', 'Rating'])) """ Age Name Rating 3 23 Vin 2.56 6 23 Jack 3.80 2 25 Ricky 3.98 0 25 Tom 4.23 1 26 James 3.24 5 29 Minsu 4.60 4 30 Steve 3.20 9 30 Gasper 4.80 7 34 Lee 3.78 8 40 David 2.98 11 46 Andres 3.65 10 51 Betina 4.10 """ # 控制排序顺序 print(sorted_df.sort_values(['Age', 'Rating'], ascending=[True, False])) """ Age Name Rating 6 23 Jack 3.80 3 23 Vin 2.56 0 25 Tom 4.23 2 25 Ricky 3.98 1 26 James 3.24 5 29 Minsu 4.60 9 30 Gasper 4.80 4 30 Steve 3.20 7 34 Lee 3.78 8 40 David 2.98 11 46 Andres 3.65 10 51 Betina 4.10 """
pandas分组
在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数。在应用函数中,可以执行以下操作 :
-
聚合 - 计算汇总统计
-
转换 - 执行一些特定于组的操作
-
过滤 - 在某些情况下丢弃数据
import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) print(df)
# 按照年份Year字段分组 print (df.groupby('Year')) # 查看分组结果 print (df.groupby('Year').groups)
迭代遍历分组
groupby返回可迭代对象,可以使用for循环遍历:
print (df.groupby('Year').groups) # 遍历每个分组 for year,group in grouped: print (year) print (group)
grouped = df.groupby('Year') print (grouped.get_group(2014))
import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3, 4, 1, 1, 2, 4, 1, 2], 'Year': [2014, 2015, 2014, 2015, 2014, 2015, 2016, 2017, 2016, 2014, 2015, 2017], 'Points': [876, 789, 863, 673, 741, 812, 756, 788, 694, 701, 804, 690]} df = pd.DataFrame(ipl_data) print(df) """ Team Rank Year Points 0 Riders 1 2014 876 1 Riders 2 2015 789 2 Devils 2 2014 863 3 Devils 3 2015 673 4 Kings 3 2014 741 5 kings 4 2015 812 6 Kings 1 2016 756 7 Kings 1 2017 788 8 Riders 2 2016 694 9 Royals 4 2014 701 10 Royals 1 2015 804 11 Riders 2 2017 690 """ #按评分排序 print(df.sort_values('Points',ascending=False)) """ Team Rank Year Points 0 Riders 1 2014 876 2 Devils 2 2014 863 5 kings 4 2015 812 10 Royals 1 2015 804 1 Riders 2 2015 789 7 Kings 1 2017 788 6 Kings 1 2016 756 4 Kings 3 2014 741 9 Royals 4 2014 701 8 Riders 2 2016 694 11 Riders 2 2017 690 3 Devils 3 2015 673 """ # 按照年份Year字段分组,查看每个分组的信息 grouped = df.groupby('Year') print(grouped)#分组对象 # 查看分组结果 print(grouped.groups) """ {2014: Int64Index([0, 2, 4, 9], dtype='int64'), 2015: Int64Index([1, 3, 5, 10], dtype='int64'), 2016: Int64Index([6, 8], dtype='int64'), 2017: Int64Index([7, 11], dtype='int64')} """ #遍历查看每个分组的信息 for year, group in grouped: print(year) print(group) """ 2014 Team Rank Year Points 0 Riders 1 2014 876 2 Devils 2 2014 863 4 Kings 3 2014 741 9 Royals 4 2014 701 2015 Team Rank Year Points 1 Riders 2 2015 789 3 Devils 3 2015 673 5 kings 4 2015 812 10 Royals 1 2015 804 2016 Team Rank Year Points 6 Kings 1 2016 756 8 Riders 2 2016 694 2017 Team Rank Year Points 7 Kings 1 2017 788 11 Riders 2 2017 690 """ #若不希望获取所有分组,如下获取某个分组细节: group = grouped.get_group(2014) print(group) """ Team Rank Year Points 0 Riders 1 2014 876 2 Devils 2 2014 863 4 Kings 3 2014 741 9 Royals 4 2014 701 """
分组聚合
聚合函数为每个组返回聚合值。当创建了分组(group by)对象,就可以对每个分组数据执行求和、求标准差等操作。
# 聚合每一年的平均的分 grouped = df.groupby('Year') print (grouped['Points'].agg(np.mean)) # 聚合每一年的分数之和、平均分、标准差 grouped = df.groupby('Year') agg = grouped['Points'].agg([np.sum, np.mean, np.std]) print (agg)
import pandas as pd import numpy as np ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3, 4, 1, 1, 2, 4, 1, 2], 'Year': [2014, 2015, 2014, 2015, 2014, 2015, 2016, 2017, 2016, 2014, 2015, 2017], 'Points': [876, 789, 863, 673, 741, 812, 756, 788, 694, 701, 804, 690]} df = pd.DataFrame(ipl_data) # print(df) # 按照年份Year字段分组,查看每个分组的信息 grouped = df.groupby('Year') #分组后针对每一组执行聚合操作,(类似数据库中的组函数) r = grouped['Points'].agg(np.mean) print(r,type(r),r.values) """ Year 2014 795.25 2015 769.50 2016 725.00 2017 739.00 Name: Points, dtype: float64 <class 'pandas.core.series.Series'> [795.25 769.5 725. 739. ] """
平均值,和,标准差
r = grouped['Points'].agg([np.mean,np.sum,np.std]) print(r) """ mean sum std Year 2014 795.25 3181 87.439026 2015 769.50 3078 65.035888 2016 725.00 1450 43.840620 2017 739.00 1478 69.296465 """
pandas数据表关联操作
Pandas具有功能全面的高性能内存中连接操作,与SQL等关系数据库非常相似。 Pandas提供了一个单独的merge()函数,作为DataFrame对象之间所有标准数据库连接操作的入口。
合并两个DataFrame:
import pandas as pd left = pd.DataFrame({ 'student_id':[1,2,3,4,5,6,7,8,9,10], 'student_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung', 'Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'class_id':[1,1,1,2,2,2,3,3,3,4]}) right = pd.DataFrame( {'class_id':[1,2,3,5], 'class_name': ['ClassA', 'ClassB', 'ClassC', 'ClassE']}) print (left) print("========================================") print (right) print("========================================") # 合并两个DataFrame rs = pd.merge(left,right) print(rs) """ student_id student_name class_id class_name 0 1 Alex 1 ClassA 1 2 Amy 1 ClassA 2 3 Allen 1 ClassA 3 4 Alice 2 ClassB 4 5 Ayoung 2 ClassB 5 6 Billy 2 ClassB 6 7 Brian 3 ClassC 7 8 Bran 3 ClassC 8 9 Bryce 3 ClassC """ rs = pd.merge(left,right,how='outer')#内连接 print(rs) """ student_id student_name class_id class_name 0 1.0 Alex 1 ClassA 1 2.0 Amy 1 ClassA 2 3.0 Allen 1 ClassA 3 4.0 Alice 2 ClassB 4 5.0 Ayoung 2 ClassB 5 6.0 Billy 2 ClassB 6 7.0 Brian 3 ClassC 7 8.0 Bran 3 ClassC 8 9.0 Bryce 3 ClassC 9 10.0 Betty 4 NaN 10 NaN NaN 5 ClassE """ rs = pd.merge(left,right,how='left')#左外链接 print(rs) """ student_id student_name class_id class_name 0 1 Alex 1 ClassA 1 2 Amy 1 ClassA 2 3 Allen 1 ClassA 3 4 Alice 2 ClassB 4 5 Ayoung 2 ClassB 5 6 Billy 2 ClassB 6 7 Brian 3 ClassC 7 8 Bran 3 ClassC 8 9 Bryce 3 ClassC 9 10 Betty 4 NaN """ rs = pd.merge(left,right,how='right')#右外链接 print(rs) """ student_id student_name class_id class_name 0 1.0 Alex 1 ClassA 1 2.0 Amy 1 ClassA 2 3.0 Allen 1 ClassA 3 4.0 Alice 2 ClassB 4 5.0 Ayoung 2 ClassB 5 6.0 Billy 2 ClassB 6 7.0 Brian 3 ClassC 7 8.0 Bran 3 ClassC 8 9.0 Bryce 3 ClassC 9 NaN NaN 5 ClassE """
其他合并方法同数据库相同:
| SQL等效 | 描述 | |
|---|---|---|
left |
LEFT OUTER JOIN |
使用左侧对象的键 |
right |
RIGHT OUTER JOIN |
使用右侧对象的键 |
outer |
FULL OUTER JOIN |
使用键的联合 |
inner |
INNER JOIN |
使用键的交集 |
试验:
# 合并两个DataFrame (左连接) rs = pd.merge(left,right,on='subject_id', how='right') print(rs) # 合并两个DataFrame (左连接) rs = pd.merge(left,right,on='subject_id', how='outer') print(rs) # 合并两个DataFrame (左连接) rs = pd.merge(left,right,on='subject_id', how='inner') print(rs)
pandas透视表与交叉表
有如下数据:
"""表连接""" import pandas as pd left = pd.DataFrame({ 'student_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'student_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung', 'Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'class_id': [1, 1, 1, 2, 2, 2, 3, 3, 3, 4]}) right = pd.DataFrame( {'class_id': [1, 2, 3, 5], 'class_name': ['ClassA', 'ClassB', 'ClassC', 'ClassE']}) # 合并两个DataFrame data = pd.merge(left, right) print(data) """ student_id student_name class_id class_name 0 1 Alex 1 ClassA 1 2 Amy 1 ClassA 2 3 Allen 1 ClassA 3 4 Alice 2 ClassB 4 5 Ayoung 2 ClassB 5 6 Billy 2 ClassB 6 7 Brian 3 ClassC 7 8 Bran 3 ClassC 8 9 Bryce 3 ClassC """
透视表
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行分组聚合,并根据每个分组进行数据汇总。
"""透视表""" import pandas as pd left = pd.DataFrame({ 'student_id':[1,2,3,4,5,6,7,8,9,10], 'student_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung', 'Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'age':[11,11,11,21,21,21,31,31,31,41], 'gender':['M','F','M','M','M','F','F','M','F','F'], 'score':[16,19,14,23,27,2,39,79,56,99], 'class_id':[1,1,1,2,2,2,3,3,3,4]}) right = pd.DataFrame( {'class_id':[1,2,3,5], 'class_name': ['ClassA', 'ClassB', 'ClassC', 'ClassE']}) # 合并两个DataFrame data = pd.merge(left,right) # print(data) # 以class_id做分组汇总数据,默认聚合统计所有列 r = data.pivot_table(index=['class_id']) print(r)#统计每班的平均年龄 """ age score student_id class_id 1 11 16.333333 2 2 21 17.333333 5 3 31 58.000000 8 """ # 以class_id做分组汇总数据,默认聚合统计所有列 r = data.pivot_table(index=['class_id','gender']) print(r) """ age score student_id class_id gender 1 F 11 19.0 2.0 M 11 15.0 2.0 2 F 21 2.0 6.0 M 21 25.0 4.5 3 F 31 47.5 8.0 M 31 79.0 8.0 """ # 以class_id与gender做分组汇总数据,聚合统计score列 print(data.pivot_table(index=['class_id', 'gender'], values=['score'])) """ score class_id gender 1 F 19.0 M 15.0 2 F 2.0 M 25.0 3 F 47.5 M 79.0 """ # 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计 print(data.pivot_table(index=['class_id', 'gender'], values=['score'], columns=['age'])) """ score age 11 21 31 class_id gender 1 F 19.0 NaN NaN M 15.0 NaN NaN 2 F NaN 2.0 NaN M NaN 25.0 NaN 3 F NaN NaN 47.5 M NaN NaN 79.0 """ # 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计,添加行、列小计 # print(data.pivot_table(index=['class_id', 'gender'], # values=['score'], # columns=['age'], # margin=True)) # 以class_id与gender做分组汇总数据,聚合统计score列,针对age的每个值列级分组统计,添加行、列小计 # print(data.pivot_table(index=['class_id', 'gender'], # values=['score'], # columns=['age'], # margins=True, # aggfunc='max'))
交叉表(cross-tabulation, 简称crosstab)是一种用于计算分组频率的特殊透视表
# 按照class_id分组,针对不同的gender,统计数量 print(pd.crosstab(data.class_id, data.gender, margins=True))
pandas可视化
基本绘图:绘图
import pandas as pd import numpy as np import matplotlib.pyplot as mp df = pd.DataFrame(np.random.randn(10,4),index=pd.date_range('2018/12/18', periods=10), columns=list('ABCD')) df.plot() mp.show()
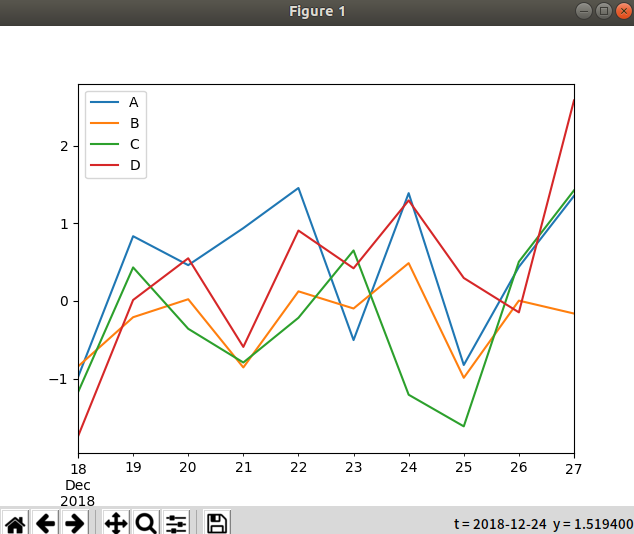
plot方法允许除默认线图之外的少数绘图样式。 这些方法可以作为plot()的kind关键字参数。这些包括 :
-
bar或barh为条形 -
hist为直方图 -
scatter为散点图
条形图
df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d']) df.plot.bar() # df.plot.bar(stacked=True) mp.show()

直方图
df = pd.DataFrame() df['a'] = pd.Series(np.random.normal(0, 1, 1000)-1) df['b'] = pd.Series(np.random.normal(0, 1, 1000)) df['c'] = pd.Series(np.random.normal(0, 1, 1000)+1) print(df) df.plot.hist(bins=20) mp.show()
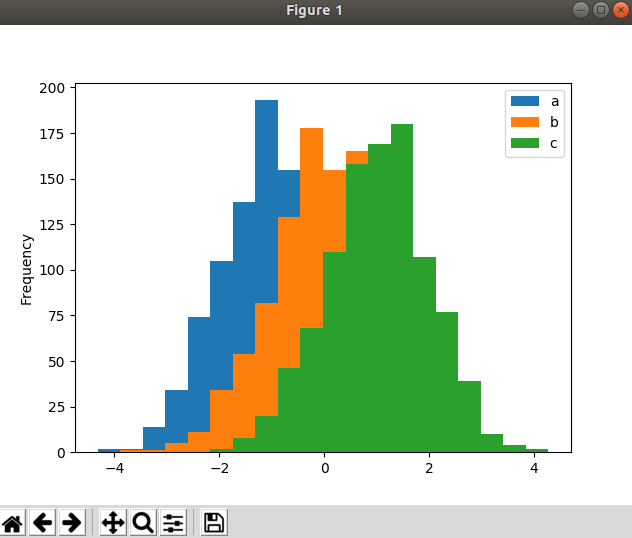
散点图
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd']) df.plot.scatter(x='a', y='b') mp.show()

饼状图
df = pd.DataFrame(3 * np.random.rand(4), index=['a', 'b', 'c', 'd'], columns=['x']) df.plot.pie(subplots=True) mp.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号