数据库相关
数据库创建注意事项
1:没有关联表的先建,有关联的表后建,多关联的表最后建
2:最好直接用sql语句建表要不会出错
3:要建外建约束必须建立索引
4:表之间建立索引的名字不能重复,索引名字一般与外建一致
MySQL数据库
数据库操作(select * from employee where 1=1等于自身)
创建数据库:
create database 数据库名
修改数据库:
alter database 数据库名 default character set utf8;
删除数据库:
drop database 数据库名;
查看数据库
show databases;
show create database 数据库名;
表操作
创建:
create table 表名(字段名 字段数据类型,字段名 字段数据类型..);
修改:
alter table 表名
添加字段: add column
修改字段类型: modify column
修改字段名称: change column
删除字段: drop column
修改表名: rename to
删除:
drop table 表名;
查看:
show tables;
desc 表名;
数据操作
添加:
insert into 表名(字段1,字段2...) values(值1,值2...);
修改:
update 表名 set 字段1=值1,字段2=值2...... where ..
删除
delete from 表名;
查看表
1)查询所有字段: select * from 表
2)查找指定字段: select 字段1,字段2 from 表;
3) 查询时指定别名 : select 字段1 as 别名1,字段2 as 别名2 from 表;
4) 查找时合并列: select 字段1+字段2 from 表
5) 查询时添加常量列: select 常量 as 别名 from 表
6)查询去除重复数据: select distinct 字段 from 表
7)条件查询 where
7.1 逻辑 : and or
7.2 比较: > >= < <= = <> between and
7.3 判空:
null: is null / is not null
空字符: ='' / <>''
7.4 模糊:
like
%: 任意个字符
_: 一个字符
8)分页查询
limit 起始行,查询行数
9)聚合查询(统计查询)
max() min() sum() avg() count()
10) 排序
order by 字段
asc: 升序
desc: 倒序
11)分组:
group by
12)分组后筛选
having 条件
sql分类:
1)DDL语句: 数据定义语句
create/alter/drop
2) DML语句: 数据操作语句
insert/update/delete
3) DQL语句: 数据查询语句
select/show
mysql约束
-- 非空: not null
CREATE TABLE student(
id INT,
NAME VARCHAR(20) NOT NULL,
gender CHAR(1)
);
-- 唯一:unique
CREATE TABLE student(
id INT UNIQUE,
NAME VARCHAR(20),
gender CHAR(1)
)
-- 主键(唯一+非空): primary key
CREATE TABLE student(
id INT PRIMARY KEY,
NAME VARCHAR(20),
gender CHAR(1)
);
--自增长: auto_increment
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
gender CHAR(1)
);
delete from 删除数据,不能重置自增长约束;truncate table 删除数据,也可以重置自增长约束。
外键与外键约束
语法:
-- 部门表(主表)
CREATE TABLE dept(
id INT PRIMARY KEY AUTO_INCREMENT, //主键自增长
deptName VARCHAR(20)
);
-- 员工表(副表)//里面的外键要参考外面的主键
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT,
empName VARCHAR(20), -- 姓名
deptId INT, -- 部门id //外键
-- 外键名 外键字段 主键字段
CONSTRAINT employee_dept_fk FOREIGN KEY(deptId) REFERENCES dept(id) //外键约束语
);
当有了外键后,数据操作顺序应该是:
1)插入数据,先插入主表数据,再插入副表数据
2)修改数据,先修改副表数据,再修改主表数据
3)删除数据,先删除副表数据,再删除主表数据
在外键的基础上,可以给外键再添加级联操作:
添加了级联操作之后,数据操作顺序可以变成:
1)修改数据,直接修改主表数据,同时修改副表数据
2)删除数据,直接删除主表数据,同时删除副表数据
修改级联:ON UPDATE CASCADE //加在外键约束语后面
删除级联:ON DELETE CASCADE //加在外键约束语后面
数据库设计(三大范式)
2.1 第一范式:要求表的每个字段都必须是独立的不可分割的单元
2.2 第二范式:在第一范式的基础上,要求表的除主键字段外的其他字段都和主键字段有关系的(不相关的数据分开)
2.3 第三范式:在第二范式的基础上,要求表的除主键外的其他字段都和主键是决定关系
(在第二范式的基础上,把重复的数据在分成一个表,减少数据冗余)
表与表的关系
4.2 内连接查询(最常见)
inner join
效果;只有满足了连接条件的数据才会被显示出来
4.3 左外连接查询
left outer join
左表数据全部显示,右表数据如果满足连接条件就显示,不满足就显示null
4.4 右外连接查询
right outer join
右表数据全部显示,左表数据如果满足连接条件就显示,不满足就显示null
SELECT s.NAME,p.NAME,w.wtime
FROM staff s,project p,worktime w
WHERE s.id=w.s_id AND p.id=w.p_id AND s.NAME='伍岳林';
Oracle数据库
连接数据库
命令格式 : sqlplus 用户名/密码@数据库ip:数据库端口/数据库实例 [ AS sysdba ]
普通连接
sqlplus scott/tiger@192.168.56.101:1521/orcl
管理连接
sqlplus sys/sys@192.168.56.101:1521/orcl as sysdba;
切换用户
conn 用户名/密码@数据库ip:数据库端口/数据库实例 [ AS sysdba ]
eg:
conn sys/sys@192.168.56.101:1521/orcl as sysdba;
数据库基本操作
修改
ed 修改 :执行修改好的内容
/ 修改 : 错误例子select * form emp改成c /form /from
清屏
host cls
显示表结构
desc emp
设置行宽
set linesize 150
设置列宽
Col colum for 填写需要的数值
Select查询
where 执行顺序(sql优化问题)
Where 执行顺序: 右 ---> 左
where condition1 and condition2
where condition2 and condition1
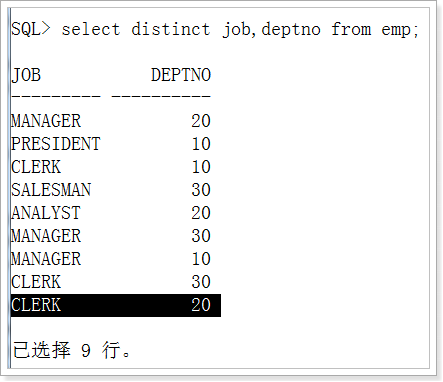
去掉重复记录
Select distinct job,depton from emp;
字符串并列
Sql -----------“ ||” 后面会取反双引号 相当于+号
Select ename || ‘的薪水是’ || sal from emp;

Oracle默认的日期格式
字符和日期要包含在单引号中
默认格式为:DD-MON-RR
修改日期格式
Alter session set NLS_DATE_FORMAT=’yyyy-dd-mm’;

比较运算符
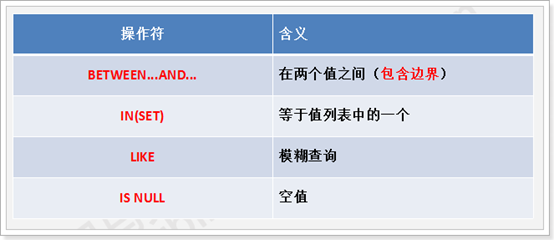
Beween…and…在两个之间
总结: between ... and ... 1包括边界 2 小值在前大值在后
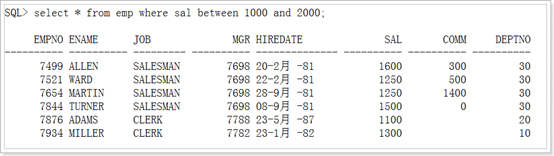
Select *from emp where sal between 1000 and 2000;
in表示在集合中 相当于or
注意:in()中有null不会报错但是无效
Select *from emp where depton in(10,20);

Like模糊查询(转义字符)
‘_’代表省略前一个字符和mysql一样
Select *from emp where ename like ‘_A%’;

注意: like 转义用法 escape 转义字符

Order by排序

注意:
1:Ordre by默认:升序asc
2:order by作用域: 作用所有字段,字段在先,先排,在后,后排.(谁在前面优先排谁)
降序只对前一个数据有效

Order by支持字段顺序排序

Order by后面可以跟算数表达式
Select *from emp order by sal*12;

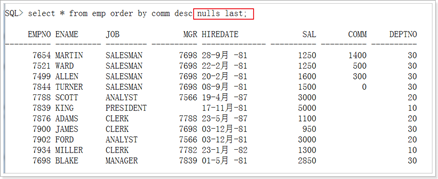
附加:nulls last表示无论升降null值排在最后
Select *from emp order by comm desc nulls last;
单行函数(dual相当于新表)

字符串函数
Select lower(‘hello WORLD’) 转小写, upper(‘hello WORLD’) 转大写, initcap(‘hello WORLD’) 首字大写 from dual;

查询当前时间
select sysdate from dual;
Concat 相当于’||’
Substr(a,b,c)
substr(a,b,c) --从a中,b位开始,取c个

Length(字符串)和lengthb(字节数)

Lpad和rpad替换

Instr索引值(从1开始),trim替换首字,replace取代


数字函数
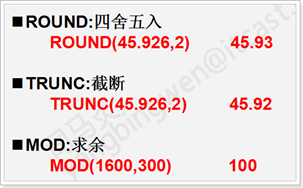
round 四舍五入
trunk 截断(时间可以取trunk((需要截取的时间字段),’year’(想要从哪里截取)))
mod 求余
日期函数
注意:可以对日期进行加减乘除

对时间进行四舍五入month月份,year年

trunk 截断(时间可以取trunk((需要截取的时间字段),’year’(想要从哪里截取)))
trunk(hiredate,’year’) 在hiredate中从年开始日期截断
滤空函数
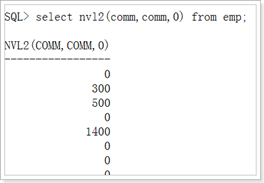
nvl(a,b,c) 如果a为null,输出c, 否则,输b
条件表达式(if-when-sele)
SELECT last_name,job_id, case job_id when 'AD_PRES' then 'A'
when 'ST_MAN' then 'B'
when 'IT_PROG' then 'C'
when 'SA_REP' then 'D'
when 'ST_CLERK' then 'E'
else 'F'
end FROM employees;

省略写法
SELECT last_name,job_id,decode(job_id,'AD_PRES','A','ST_MAN','B','IT_PROG','C','SA_REP','D','ST_CLERK','E','Others','F') GRADE FROM employees;
Group by分组
注意:组函数:有没有自动滤空功能? --有
怎么来屏闭自动滤空功能?
嵌套滤空函数来屏闭.
Group by只允许跟表字段列
分组函数

组函数使用:
在SELECT列表中所有未包含在组函数的列都应该包含在GROUP BY子句中。相反,包含在GROUP BY子句中的列不必包含在SELECT列表中。

having 相当where

Group by增强
select deptno,job,sum(sal) from emp group by rollup(deptno,job);

多表查询
连接类型

等值连接
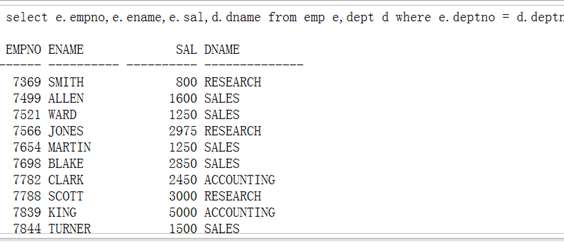
等值连接显示左边表的内容(左连接)
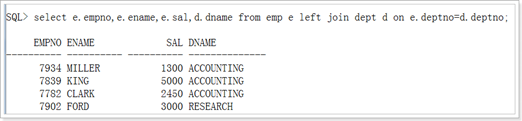
省略laft join

不等值连接

Between….and
外连接(左外连接和右外连接)

自连接
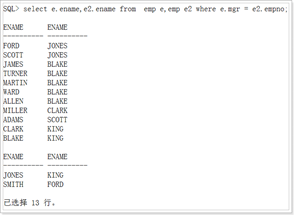
不推荐会产生笛卡尔积
子查询
子查询需要解决的问题:
不能一步到位进行查询,我们就使用子查询.
子查询需要注意的问题:
1.括号
2.主查询的where,select , from ,having后面都可以放置子查询
3.在group by 后面不能使用子查询
4.强调from后面子查询
5.主查询和子查询可以不同一张表,只要子查询返回的结果,主查询可以访问就可以了.
6.一般不在子查询中使用order by ,但TOP-N 分析问题,必须使用order by .
7.一般先执行子查询再执行主查询,但相关子查询例外.
8.单行子查询只能使用单行操作符,多行子查询只能使用多行操作符.
9.重点注意:子查询中的null
常规子查询
select 子查询
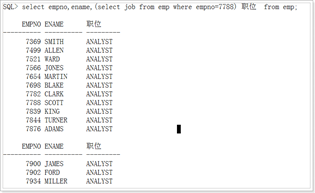
From子查询

Having子查询

子查询与主查询不在同一张表
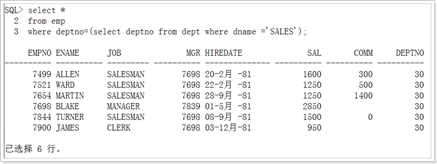
子查询中使用组函数
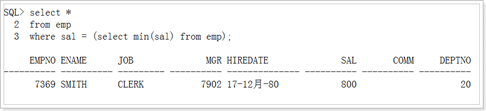
多行子查询
In在集合中

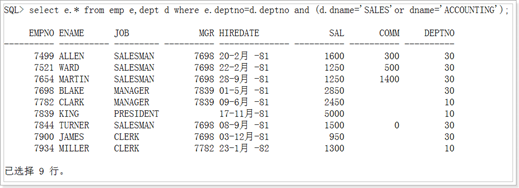
Any:和子查询返回的任意一个值比较
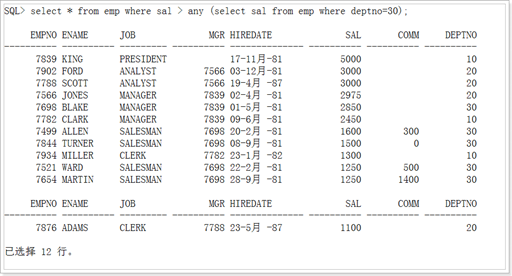
All:和子查询返回的所有值比较
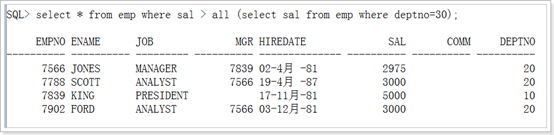
多行子查询空值
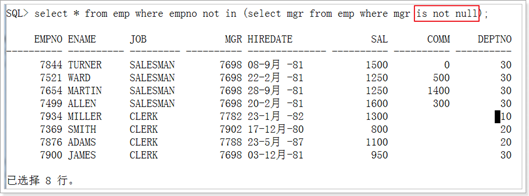
Using使用
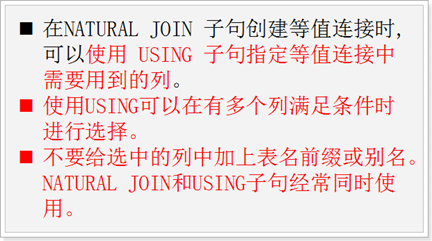
UNION / UNION ALL 并集
INTERSECT 交集
MINUS 差集
UNION运算符返回两个集合去掉重复元素后的所有记录
UNION ALL返回两个集合的所有记录包括重复的
INTERSECT运算符返回同时属于两个集合的记录
MINUS 返回属于第一个集合,但不属于第二个集合的记录
select * from emp where deptno=10;
+
select * from emp where deptno=20;
=
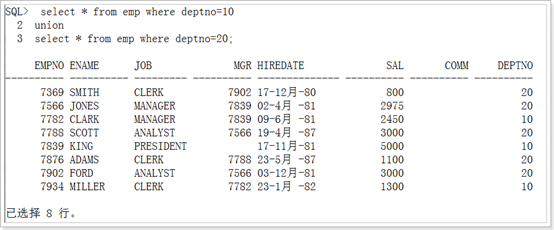
Group by增强(了解)
集合运算注意的问题:(尽量不使用集合运算)
1. 参加集合运算的列数相同,并且 类型一致.
2. 采用第一集合表作为表头
3. 如果要排序必须在最后一个集合中使用order by
4. 可以使用括号改变执行顺序
select deptno,job,sum(sal) from emp group by deptno,job;
+
select deptno,sum(sal) from emp group by deptno;
+
select sum(sal) from emp;

分页及rownum

注意:
关于rownum:
1.rownum 按照默认的顺序生成.

2.rownum只能使用 < 或者 <=,绝对不能使用 > 或者 >=

分页1:

分页2:

增删改
1:在建表时可以插入另一张表的数据
Create table emp2 as select * from emp;
可以向另一张表插入一些数据
Insert into emp2 select * from emp where ename like ‘ab%’;(注意:两张表列名对应)
更新和mysql一致
删除有delete和trancate

总结

注意:
Oracle 支持的 2 种事务隔离级别:READ COMMITED, SERIALIZABLE.
Oracle 默认的事务隔离级别为: READ COMMITED (读已提交)
Mysql 支持 4 中事务隔离级别. Mysql 默认的事务隔离级别为: REPEATABLE READ (可重复读)
Oracle默认开启事务
Oracle其他使用
常见数据库对象
表:table
视图:
序列:
索引:index
同义词:synonym
数据类型

建表操作
创建表
普通建表
Create table 表名( 字段1 数据类型[默认值,约束条件],
字段2 数据类型[默认值,约束条件],
...
)
例如:

子查询建表
Create table (表名) as (插入的sql的语句)
例如:

Alter修改表
Alter table (表名) add (字段 字段属性); //添加字段
Alter table (表名) modify (字段 字段属性); //修改字段
Alter table (表名) drop column (字段 字段属性); //删除字段
Alter table (表名) rename column (原字段名) to (修改后的字段名); //更改字段名
例如:alter table dept3 add (loc3 varchar(30));

删除表

Drop table 表名;
例如:

改变对象名称
Rename …to…
清空表
Truncate table (表名);

约束条件

不为空:Not null
唯一:unique
主键唯一:primary key 主键约束(自带唯一)
外键约束:Foreign key
检查:Check
视图对象

开启视图权限
在虚拟机中 grant create view to soctt;
Create view (创建的视图名) as (sql插入的表);
注意delete 、update 、 insert 视图操作中不能使用:
组函数
Group by 字句
Distinct 关键字
Rownum 伪列
删除视图:drop view (视图表名);
序列对象

例如:
Create sequence (表名)
increment by 10 (自增长)
start with 120 (初始值)
maxvalue 999 (最大)
nocache (缓冲)
nocycle; (多久循环)
删除序列

索引对象
Create index (索引名字) on (表名)(字段名,可以多个);

同义词对象
Create synonym (同义词简写) for (需要的同义词对象可以是表名);

Pl/sql设计
Plsql结构和组成

常量定义
变量:Char 、varchar2、date、number、boolean、long
引用型变量:字段名后%type;
例如:

记录型变量:字段名后%rowtype;
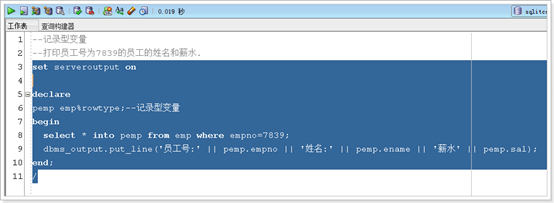
条件语句
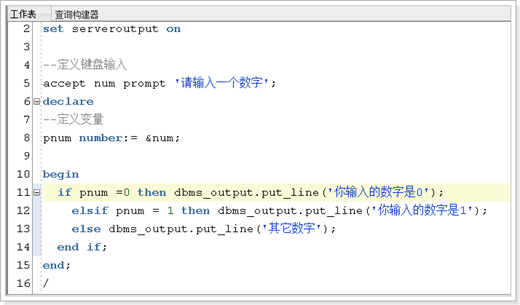
If语句
If…elsif…then…else..end if;(相当于if..else判断)
例如:
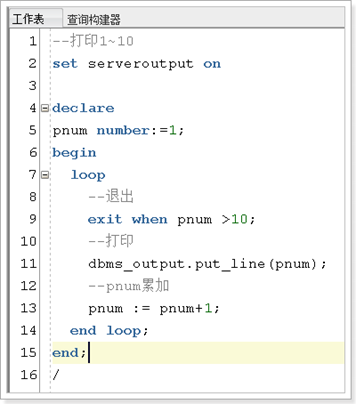
循环语句
loop (声明相当于for)
exit when (退出条件);
业务条件
end loop;(声明结束)
例如:
游标
需要开启和关闭 open (光标对象) close (光标对象)
注意:返回多个值无法用单个接收,就要定义游标,没走一次游标,返回一个值
Cursor 光标名 is (sql需要创建的光标对象);
例如:使用游标查询员工的姓名和工资,并打印

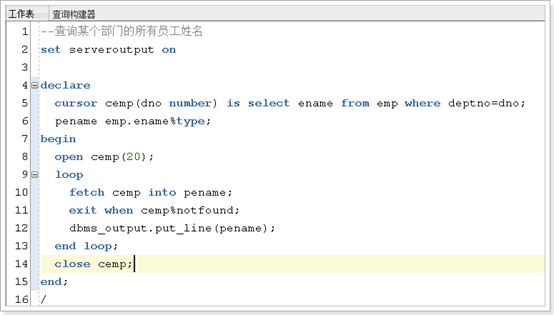
带参数光标
例如:查询某个部门的所有员工姓名
定义游标集合

自定义异常
--用户定义例外
--查询50号部门的员工姓名
set serveroutput on
declare
cursor cemp is select ename from emp where deptno=10;
pename emp.ename%type;
--自定义例外
no_emp_found exception;
begin
open cemp;
loop
--取出一条记录
fetch cemp into pename;
if cemp%notfound then
--抛出例外
raise no_emp_found;
end if;
end loop;
close cemp;
exception
when no_emp_found then dbms_output.put_line('没有找到员工');
when others then dbms_output.put_line('其它例外');
end;
/
Oracle数据字典

可以查询以下对象看结构:
DICTIONARY
USER_OBJECTS
USER_TABLES
USER_TAB_COLUMNS
USER_CONSTRAINTS
USER_CONS_COLUMNS
USER_VIEWS
USER_SEQUENCES
USER_TAB_SYNONYMS
触发器

实例:
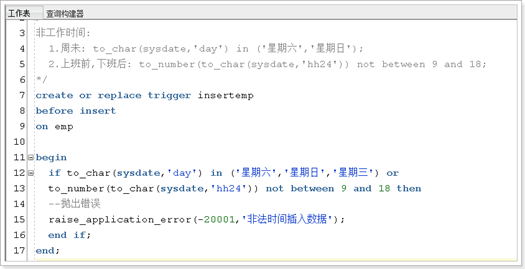
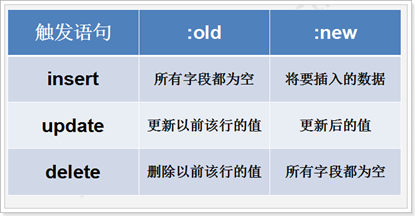
触发语句与伪记录变量的值
实例2:

闪回
1.错误删除数据并提交数据,并且commit
2.错误删除表(drop table)
3.如何获取表上的历史记录
4.如何撤消一个已经提交的事务
闪回表需要权限 grant flashback any table to scott; 授权
执行闪回表必须开启行移动alter table flashback_table enable row movement;
闪回类型:
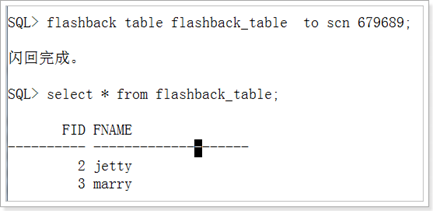
1.闪回表:将表回退到某一个时间上.
2.闪回删除: 将oracle回收站的内容恢复.
3.闪回版本查询: 获取表中的历史记录
4.闪回事务查询: 查询获取表中的user_sql
5.闪回数据库:将数据库回退到某一个时间上.
6.闪回归档日志: 将数据库操作回退到日志的某一个时间上.
查询scn

闪回表

修改闪回时间参数
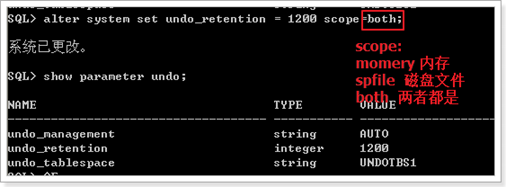
系统改变scn

语法:

闪回就是放入回收站
查看回收站

清空回收站

永久删除不闪回
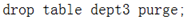

两张一样表闪回需要重命名

Oracle中导入导出
真正数据备份,不是用exp和imp
真正数据备份RMAN 全称:Recovery Manager
Imp数据导入
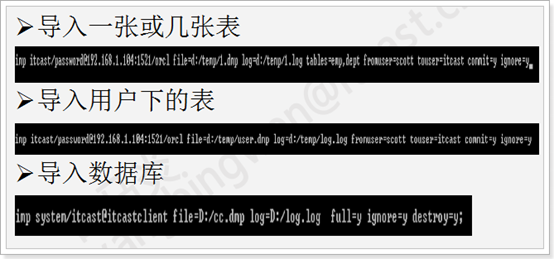
Emp和imp的提示模式
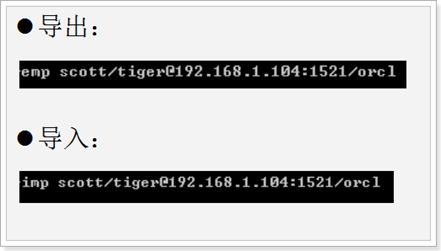
管理方案:
192.168.56.101:1158/em
创建新用户

要登入授权

授予用户建表权限并且具有对表的授权功能

给用户分配默认表空间

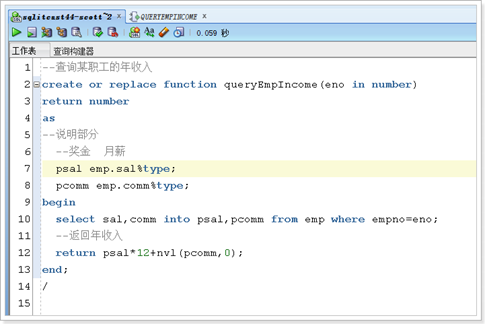
存储过程和存储函数
如果有返回值,使用存储函数,否则,使用存储过程
存储过程实例
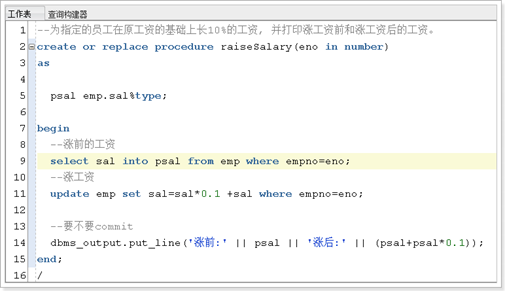
存储过程的调用

存储函数
在方法后面+(输入是in,输出是out)
In和out


 浙公网安备 33010602011771号
浙公网安备 33010602011771号