(pandas)合并重复列实例
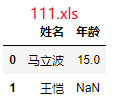
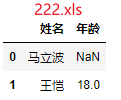
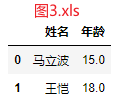
问题:合并111.xls、222.xls,最终效果如图3
import pandas as pd
df=pd.read_excel(r"111.xls")
df1=pd.read_excel(r"222.xls")
方法1:merge合并
思路:
1.以姓名为关键词,以并集的方法合并
2.以0替换缺失值Nan
3.新建"年龄"列,值为"年龄_x"列+"年龄_y"列
4.删除"年龄_x"列、"年龄_y"列
df2=pd.merge(df,df1,on="姓名",how="outer")
df2=df2.fillna(0)
df2["年龄"]=df2["年龄_x"]+df2["年龄_y"]
df2=df2.drop(["年龄_x","年龄_y"], axis=1)
方法2:concat合并
思路:
1.默认合并
2.筛选"年龄”列大于0的数据
df3=pd.concat([df,df1])
df3=df3[df3.年龄>0]
