Kaggle M5 沃尔玛销量时间序列预测 竞赛总结
简介
7月1日,Kaggle 举办的M5沃尔玛销量时间序列竞赛刚刚结果。6月一整月,我的精力主要都投入到了这个比赛中。Kaggle基于同一个数据集举办了两场竞赛,其中Accrucy是点估计,Uncertainty则是对分位数的估计。这两场比赛从3月3日开始,但我从6月才开始参加,相当于在最终一个月的时间完成了这场比赛。
这是我的Feature赛首战,很幸运两场比赛都进入了Top2%的银牌区:
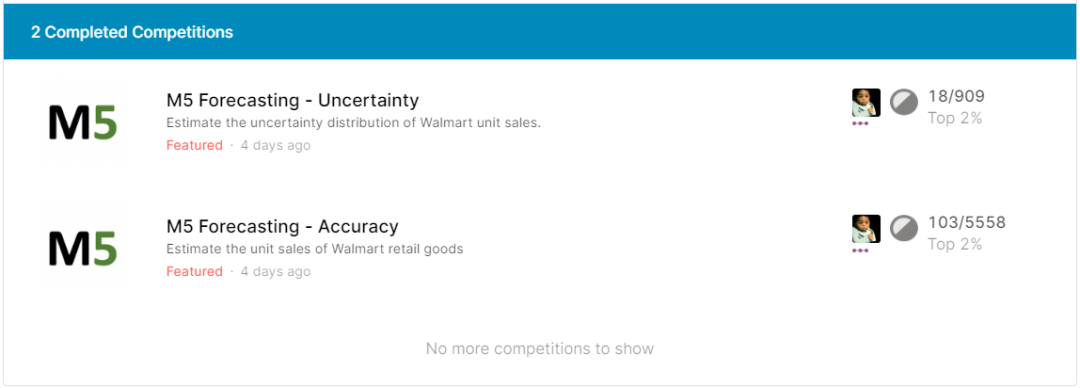
刚看到这个成绩时我不敢相信自己的眼睛。尤其是看到A/B榜排名变化的时候。事实上很多获胜者都经历了非常大的shake up。这和数据集的特性有关。下面进行一个简单的总结吧。
预备
这是我Feature赛的首战经历。在参加之前遇到了许多意想不到的困难。但是无论如何,这些困难都是可以被技巧克服的。但tricks不能代表一切。在参加比赛前最好确保一定的知识储备。
首先你需要具备机器学习的基础知识。此外之前我拿Titanic和House Price Prediction这两个比赛练过手。此外需要熟悉numpy和pandas操作数据的方法。Feature比赛几乎都是多个数据表,因此需要对多表联结(concat, merge, join)、数据重塑(melt, dcast)和分组(groupby)等知识进行反复练习。关于Boosting方法的原理一定要熟悉,主要是各个参数的涵义等等。后期调参的时候肯定会用得到。
遇到的问题
内存
内存容量是打Featured比赛都会遇到的问题,也是我打这个比赛的最大瓶颈。因为时序数据需要进行数据重塑,原本的数据容量被加大。所以很多算法和tricks其实无法在这个数据上施展拳脚。从内存的角度来说,微软的LightGBM几乎是最佳的算法,它的内存消耗和运行时间都经过极大优化。LightGBM还支持分批次训练,每次训练只需要用一部分数据,这些都在保证准确率的同时节省了内存和运行时间。
此外,Python中的垃圾回收与和改变字节数也能大大降低内存。比方将64位浮点数转为32位等等。普通的8G笔记本电脑肯定是不够的,尽管我在比赛期间加装了一块内存条,内存升级到了16G,但在一些时候还是无济于事。后期我的模型训练几乎全是在Kaggle云Notebook中完成的。不得不说Kaggle Notebook的免费配置还是挺给力的,它不仅能下载输出文件,还能将其他Notebook的输出文件直接作为新Notebook的输入文件来运行。
时间序列相关知识
在此之前我从未做过时序相关的数据项目,这导致我刚加入的时候看不懂Public Kernel的代码。但这也是我参加这个比赛的主要目的,就是向Kagglers学习。因为算法很大程度上是要满足“预测未来”的需求。按照Kaggle比赛的套路,在充分理解竞赛规则后,首先从Public Kernel中找一个代码风格好的,进行二次开发。
在辛苦地阅读每一个函数之后,我发现大部分参赛者在Feature Engineering部分大量使用了lag rolling mean/std的方法。其次创建了很多的时间变量,包括年份、星期几、季度。
在FE方面,我仅仅提取了是否为weekends这个变量。因为显然周末逛超市的人更多。后来输出的feature importance图中也证实了这个特征对预测有一定效果。
数据集的划分
一般的tabular data是通过随机划分的办法划分训练集、验证集和测试集。但对于时序数据来说。这样的做法会导致“时间穿越”问题,“时间穿越”本质上是一种data leakage,会导致严重的过拟合问题。因此必须根据时间顺序来划分训练/验证/测试集。
而M5比赛本身又为数据集的划分增添了一定的复杂性。训练集为2011-01-29 ~ 2011-04-24共1913天的数据 。而验证集是 2016-04-25 ~ 2016-05-22(共28天)的数据。A榜基于验证集计算评价指标,而B榜则基于延后28天,即2016-05-23 ~2016-06-19的预测数据。也就是说,A榜和B榜没有任何交集。三者的划分如下所示:

在比赛结束前的一个月,Kaggle会放出2016-04-25 ~ 2016-05-22日的数据完整结果,即A榜的答案。这也使得A榜的提交结果对于比赛的参考价值不大。此外Kaggle释出的full label data的id变量有所区别,而Public Kernel中给出的思路大多是拟合A榜,这使得很多高分Kernel都是过拟合A榜的结果。如果想对这些代码进行二次开发的话,必须通读并理解它们,而且改为对B榜的拟合。之前分享了 一个简单的 baseline 方案,可以作为一开始的框架来用。
在比赛中,我最初采取的是其他选手(@ragnar)分享的GroupKFold交叉验证,其中将“年-星期”作为分组。这样同组的样本就会尽量在同一折中出现,但我认为这个做法仍然无法避免“时间穿越”问题,但好在他使用了很多rolling的特征,尽可能地避免了这个问题。而且GroupKFold的好处是它使用了全部的训练数据,让模型学习到了更多的信息。而且这个方法在前期也确实取得了很高的分数。
但是,我在比赛后期改用了3折TimeSeriesSplit的交叉验证方案。这是因为GroupKFold运行耗费的时间太久了,每次运行至少3小时起步,比赛结束前几天我耗不起这个时间,所以采用了更为轻便的TimeSeriesSplit。
我认为对不同cv方法的比较和验证是非常重要的,这是比赛的核心工作。其实可用的cv方法还有很多,有时需要大量的实践积累才能得到有效的结论。其次,使用其他数据来验证也是必要的。
A/B 榜的问题
这场比赛A、B榜的排名发生了翻天覆地的变化,最终的优胜者几乎都是shake up好几百名的选手。很多选手在赛后也感叹这场比赛像“lottery”。这对于我们的启示是不要盲目相信A榜,要相信自己的local cv结果。但A榜也不是完全没有价值。即使绝对排名无法参考,也可以用来检验某种方法的好坏。而Uncertainty赛的A榜更有参考价值。因为对分位数的估计是没有label的,因此只能盲猜方法的好坏。
损失函数 Loss Function
其中\(Y_t\)是特定时间序列在t时刻的真实值。\({{{\hat Y}_t}}\)是预测值。n是训练样本的长度(历史观察数),h是预测范围。在本场比赛中,训练集来自2011-01-29到2016-05-22共1941天的销量历史数据。因此n=1941。要预测未来28天的销量,因此h=28.
对于这个数据量来说,网格搜索法用不了、Stacking用不了。调参只能手动调。在可用算法缺乏的情况下,损失函数(Loss Function)的选择就成了比赛获胜的关键。由于预测的目标是销量,可以将其看做正常的连续变量或计数变量。那么Poisson损失函数更符合后者,还有的参赛者使用了tweedie loss、以及自定义的损失函数,比如:
def custom_asymmetric_train(y_pred, y_true):
y_true = y_true.get_label()
residual = (y_true - y_pred).astype('float')
grad = np.where(residual < 0, -2 * residual, -2 * residual * 1.15)
hess = np.where(residual < 0, 2, 2 * 1.15)
return grad, hess
我对以上几种损失函数进行了时间序列交叉验证,同时进行手动调参,尽量提升单个模型的得分。
之后我对以上几种损失函数模型进行了融合,也就是非常简单的mean-based blending。这一步提升了模型的泛化能力,降低了过拟合。得到了融合后的预测。之后,我尝试了一些硬编码处理。通过观测标签,发现大量的0销量,因此我将极小的预测值编码为0。这时可以根据A榜的分数变化来观测效果。我另外又尝试了乘以一个系数,如0.98/1.01等等。发现效果比较好。这种技巧属于magic multiplier,在不熟悉原理的情况下应当谨慎使用。
总结
需要总结的东西太多了。我常常觉得打Kaggle竞赛最重要的是心态。重要的是从这个过程中学到新东西而不是名次。尽量要保持住“即使没有奖牌也要做下去”热情。
Kaggle比赛的时间线问题也很重要。一场Kaggle比赛动辄持续数个月,从头一直关注到尾很容易感到筋疲力尽。从比赛的后半段参加是一个比较偷懒的选择。但我的教训是不要像我一样将模型融合拖到提交的最后一天才做。
我在这场比赛中非常感谢的一位选手是@kyakovlev。他分享的Notebook对我产生了很大的启发。他分享的M5 - Witch Time(https://www.kaggle.com/kyakovlev/m5-witch-time)Notebook 可能是这场比赛最有趣的彩蛋。
他对一个base submission表做了一系列魔法骚操作,对表乘以了一系列系数(选取这些数字的理由非常神奇),最后在A榜上取得了超高分数。相当于以自己做了一个反面例子,展示过拟合的过程。同时也无情拆穿了很多的copy-paster。因为确实存在很多的无脑参与者直接下载Public Kernel的结果提交。甚至还有到处刷"Great Notebook!"这样的无营养评论的。@kyakovlev的这个文章是对他们的最佳讽刺。
无论如何,尽管有很多Kaggler的无私分享让你省去了前期数据清理、探索性数据分析的时间。但深入理解问题的核心是最重要的,不然也无法对现有的Kernel做出改动。一定要仔细测试那些高分Public Kernel是不是有价值的,并且基于自己的判断搭建Pipeline和Local CV。
至于Uncertainty比赛就可以把Accuracy赛的预测结果拿来直接用了。我的做法是将我的预测文件通过Public Kernel分享的方法直接转化为分位数的估计,再与另一个Public Kernel融合起来降低过拟合。如果做法正确的话两个比赛的结果应该是比较一致的。
要学习的还有很多,相比于无私分享Kernel的明星选手来说,我仅仅是基于别人的代码做了非常微小的工作。此外非常感谢国内的一些Kaggle爱好者的分享,如Kaggle竞赛宝典、Coggle数据科学等微信公众号。他们分享的以往时序竞赛的Baseline让我对基本概念有了准确并快速的了解。
Happy Kaggling!
Kaggle Profile:
https://www.kaggle.com/rikdifos/
我的解决方案已上传github:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号