6.Spark安装
0.系统版本信息
OS:Debian-8.2 JDK:1.8.0_181 Hadoop-2.8.4 Zookeeper-3.4.10 Hbase:1.3.1 Spark:2.3.1
主机信息
192.168.74.131 master 192.168.74.133 slave1 192.168.74.134 slave2 192.168.74.135 slave3
1.前提条件
A:安装好jdk并配置好环境变量 B:安装好Hadoop并能够跑通example下的wordcout C:安装好zookeeper,并能够跑通
2.spark安装配置
A:下载安装
镜像:http://mirrors.hust.edu.cn/apache/spark/spark-2.3.1/
#spark 只需要在需要使用的机器上安装即可,在这里在master上安装 cd /home/hadoop/opt wget http://mirrors.hust.edu.cn/apache/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz tar zxvf spark-2.3.1-bin-hadoop2.7.tgz mv spark-2.3.1-bin-hadoop2.7 spark-2.3.1
备注:
下面的配置主要是为了查看spark的job历史,submit任务时可以不需要对spark进行任何配置,只需要在提交任务脚本中添加环境和配置参数即可
B:#spark-env.sh
cd /home/hadoop/opt/spark-2.3.1/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master:9000/user/spark/applicationHistory"
根据上面的配置需要在hdfs上创建相关目录
hdfs dfs -mkdir -p /user/spark/applicationHistory
C:spark-defaults.conf
cd /home/hadoop/opt/spark-2.3.1/conf cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://master:9000/user/spark/applicationHistory
D:开启历史的webUI服务
/home/hadoop/opt/spark-2.3.1/sbin/start-history-server.sh
上面的配置端口是18080:在哪台机器上开启的该服务,ip就是哪台机器的
#查看启动的服务,发现有HistoryServer表示启动成功 jps
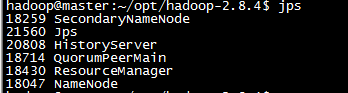
访问spark历史的webui:http://192.168.74.131:18080/
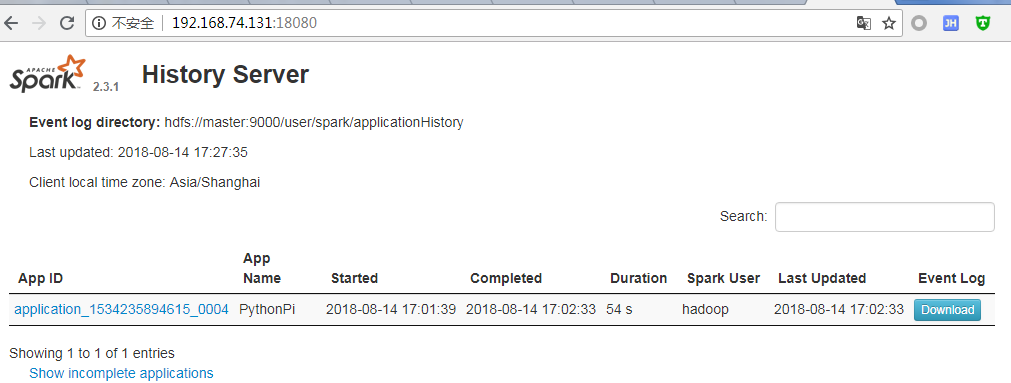
3.spark任务提交脚本
#!/bin/bash
source /etc/profile
cd `dirname $0`
curdir=`pwd`
echo ${JAVA_HOME}
echo ${HADOOP_HOME}
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
export SPARK_HOME=/home/hadoop/opt/spark-2.3.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_DRIVER_MEMORY=1G
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR="/home/hadoop/opt/hadoop-2.8.4/etc/hadoop"
SPARK_SUBMIT="/home/hadoop/opt/spark-2.3.1/bin/spark-submit"
${SPARK_SUBMIT} \
--master "yarn" \
--deploy-mode cluster \
--driver-memory 1G \
--executor-memory 1G \
--executor-cores 1 \
--conf "spark.eventLog.enabled=true" \
--conf "spark.eventLog.compress=true" \
--conf "spark.local.dir=/tmp" \
--conf "spark.eventLog.dir=hdfs://master:9000/user/spark/applicationHistory" \
/home/hadoop/opt/spark-2.3.1/examples/src/main/python/pi.py 10
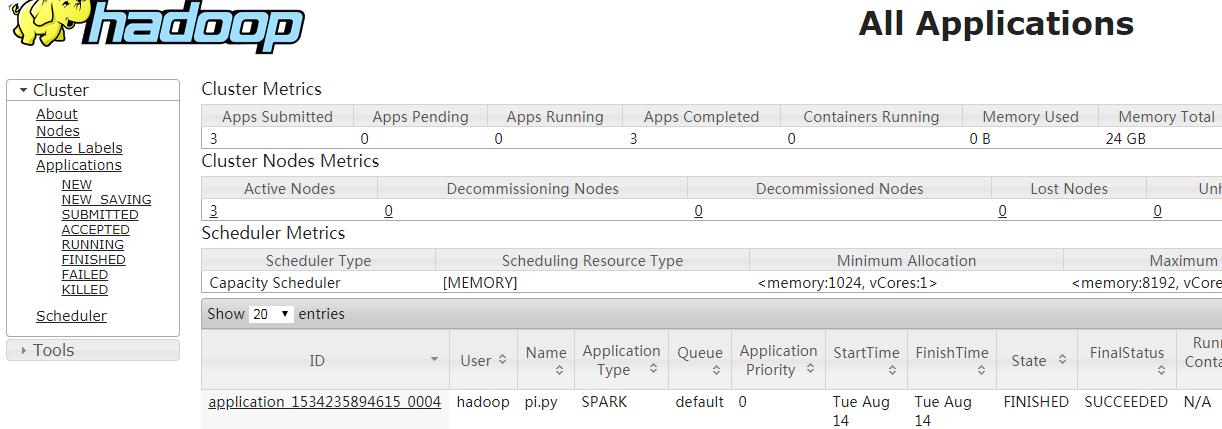
yarn资源查看http://192.168.74.131:8088/cluster,这里的端口是hadoop的yarn-site.xml中的端口配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8041</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
http://www.cnblogs.com/makexu/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号