特征降维之PCA
目录
PCA思想
PCA主要用于数据降维,是一种无监督学习方法。主成分分析利用正交变换将可能存在相关性的原始属性转换成一组线性无关的新属性,并通过选择重要的新属性实现降维。由一系列特征组成的多维向量,其中某些元素本身没有区分性,比如某个元素在所有样本中都相等,或者彼此差距不大,那么那个元素对于区分的贡献度小。我们的目的即为找到那些方差大的维,去掉变化不大的维。
将 n 维特征映射到 k 维上(k<n),这 k 维是全新的正交特征,是互不相关的。这 k 维特征称为主元,是重新构造出来的 k 维特征,而不是简单地从 n 维特征中去除其余 n‐k 维特征。PCA可以对新求出的“主元”向量的重要性进行排序,而每个新变量是原有变量的线性组合,体现原有变量的综合效果,这些新变量又称为“主成分”,它们可以在很大程度上反映原来n个变量的影响。
主成分分析的解满足最大方差和最小均方误差两类约束条件,因而具有最大可分性和最近重构性。
问题形式化表述
从n维降到k维:找k个向量\(u^{(1)},u^{(2)},...,u^{(k)}\),将数据垂直映射到每个向量上,然后最小化映射误差(projection error,距离均方误差).
PCA之协方差矩阵
协方差定义
若等于0,则称X和Y不相关.
协方差的上界是\(|Conv(X,Y)|\le\sigma_1\sigma_2\),其中,\(Var(X)=\sigma_1^2,Var(Y)=\sigma_2^2\),当且仅当X和Y之间有线性关系时,等号成立.两边除以\(\sigma_1\sigma_2\)得到Pearson相关系数.
协方差矩阵常用来筛选特征(特征降维).
如对矩阵X进行降维,\(X\in \mathbb R^{m\times n}\),并且已去过均值:
目标是使得每个行向量的方差尽可能大,而行向量间的协方差为0(行与行之间的相关性尽可能小).(最大方差理论)
X对应的协方差矩阵为:
协方差矩阵是对称半正定,主对角线元为每个行向量的方差,次对角线元为行向量间的协方差.
协方差大于 0 表示 x 和 y 若有一个增,另一个也增;小于 0 表示一个增,一个减;协方差为 0 时,两者独立。协方差绝对值越大,两者对彼此的影响越大,反之越小。
矩阵-特征值
特征值(eigen value),特征向量(eigen vector)
\(A\mathbb x=\bbox[5px,border:1px solid red]\lambda\ \mathbb x\),则常数\(\lambda\)为矩阵A的特征值,\(\mathbb x\)为\(\lambda\)对应的特征向量.可以有多个.
PCA运算步骤
基础算法:
-
从数据中减去均值,每个样本除以各自的方差(方差归一化)(预处理的实质是将坐标原点移到样本点的中心点)
-
求特征协方差矩阵
-
求协方差矩阵的特征值和特征向量
-
将特征值按照从大到小的顺序排序,选择其中最大的 k 个,然后将其对应的 k个特征向量分别作为列向量组成特征向量矩阵。
-
将样本点投影到选取的特征向量上。假设样例数为 m,特征数为 n,减去均值后的样本矩阵为 DataAdjust(mXn),协方差矩阵是 nXn,选取的 k 个特征向量组成的矩阵为EigenVectors(nXk)。那么投影后的数据 FinalData 为
\[\text{FinalData}(m \times k) =\text{DataAdjust}(m \times n)\times \text{EigenVectors}(n \times k) \]
这样,就将原始样例的 n 维特征变成了 k 维,这 k 维就是原始特征在 k 维上的投影,代表了原始的n个特征。
PCA理论解释
有三个理论可以解释为什么协方差矩阵的特征向量作为k维理想特征:
- 最大方差理论
- 最小平方误差理论
- 坐标轴相关度理论
最大方差理论
在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。
理论,最好的 k 维特征是将 n 维样本点转换为 k 维后,每一维上的样本方差都
很大。降维的过程即高维向低维映射的过程(向一些轴投影).
投影的概念:向量\(\mathbb x^{(i)}=(x_1^{(i)},x_2^{(i)},\dots,x_n^{(i)})^T\)在单位向量\(u=(u_1,u_2,\dots,u_n)^T\)(代表某条直线的方向向量)上的投影的长度为:\(\langle x^{(i)},u \rangle ={x^{(i)}}^Tu=u^Tx^{(i)}\).
由于数据预处理后每一维度均值为0,投影后仍为0,因此方差为:
最后一个等号后边的二次项的中间部分即为样本特征的协方差矩阵.
用A来表示该协方差矩阵,用\(\lambda\)表示方差(目标函数),则上式写作:
由于 u 是单位向量,即\(u^Tu=1\),上式两边都左乘 u 得, \(u\lambda=\lambda u=uu^TAu=Au\),即\(Au=\lambda u\)
可以看出,\(\lambda\)就是A的特征值,u是特征向量.最佳的投影直线是特征值λ最大时对应的特征向量,其次是λ第二大对应的特征向量,依次类推。
因此,我们只需要对协方差矩阵进行特征值分解,得到的前 k 大特征值对应的特征向量就是最佳的 k 维新特征,而且这 k 维新特征是正交的。得到前 k 个 u 以后,样例 x 通过以下变换可以得到新的样本:
PCA 将 n 个特征降维到 k 个,可以用来进行数据压缩,如果 100 维的向量最后可以用10 维来表示,那么压缩率为 90%。同样图像处理领域的 KL 变换使用 PCA 做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
性质
- 保守方差是最大的
- 最终的重构误差(从变换后特征回到原始特征)是最小的。
由于PCA只是简单对输入数据进行变换,所以它既可以用于分类问题也可用于回归问题。
优点:不需要设定参数,结果仅与数据有关。可以方便的应用到各个场合。
参数k的选取
在主成分分析中,保留的主成分的数目是由用户来确定的。一个经验方法是保留所有大于1的特征值,以其对应的特征向量来做坐标变换。此外,也可以根据不同特征值在整体中的贡献,以一定的比例进行保留,即计算降维后的数据与原始数据之间的误差,令误差和原始数据能量的比值小于某个预先设定的阈值,选择使如下不等式成立的最小的k:
可以表述为原数据99%的方差被保留。分子是映射均方误差,分母是数据的总方差.降维之后损失的信息越多,方差越小.然而,上述公式不能直接计算,实际中用到奇异值分解:[U,S,V] = svd(X). svd得到的S是个对角矩阵,选择使如下不等式成立的最小的k:
数据重建
如何从压缩表示的数据中重建原本的数据?
压缩(降维)过程:\(z=U^T_{reduce}x\)
重建近似数据:\(X_{approx}=U_{reduce}z\)
主观理解
从主观的理解上,主成分分析到底是什么?它其实是对数据在高维空间下的一个投影转换,通过一定的投影规则将原来从一个角度看到的多个维度映射成较少的维度。到底什么是映射,下面的图就可以很好地解释这个问题——正常角度看是两个半椭圆形分布的数据集,但经过旋转(映射)之后是两条线性分布数据集。
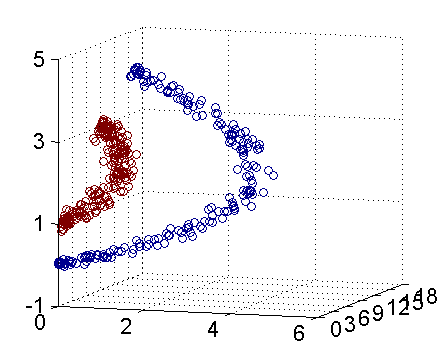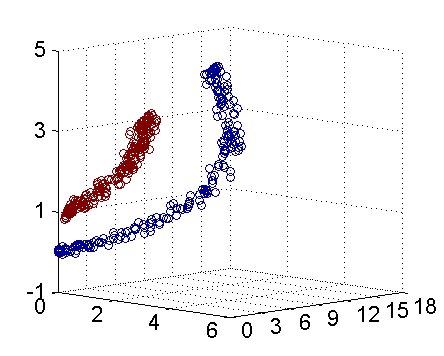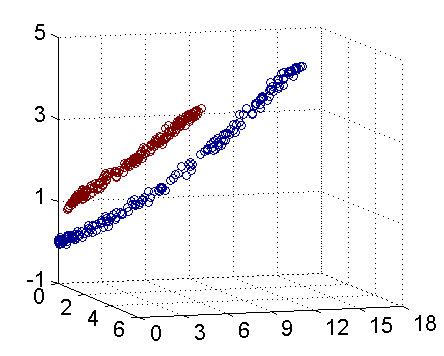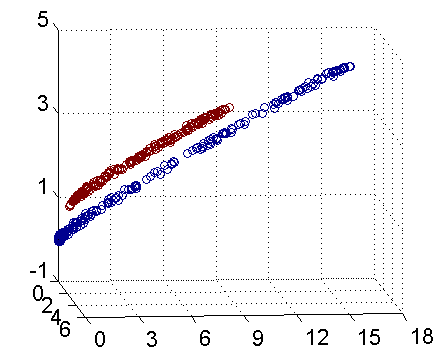
变换后的各分量,它们所包括的信息量不同,呈逐渐减少趋势。事实上,第一主分量集中了最大的信息量,常常占80%以上。第二、三主分量的信息量依次很快递减,到
了第N分量,信息几乎为零。选择较少的主成分来表示数据不但可以用作特征降维,还可以用来消除数据中的噪声。在信号处理中认为信号具有较大的方差,噪声有较小的方差。在很多情况下,在特征值谱中排列在后面的主成分(次成分)往往反映了数据中的随机噪声。因此,如果把特征值很小的成分置为0,再反变换回原空间,则实现了对原数据的降噪。
应用
从神经科学到计算机图形学都有它的用武之地。被誉为应用线形代数最有价值的结果之一。
- 压缩降维:
- 降低存储大小;
- 加快监督学习的过程
- 数据可视化(通常是2D,3D)
虽然可能能够降低模型过拟合,但不是防止过拟合的根本方法,应该考虑对参数加正则项.在设计机器学习系统之前不要急着想要使用PCA,应该先使用原始数据,效果不好或系统不能承受(计算,存储量大等)再使用PCA.
代码示例
# Transforming the data
n_components=2
pca = PCA(n_components)
X_reduced = pca.fit_transform(X)
# ('X Shape: ', (70000, 784)),X_reduced.shape=(70000, 2)
# Important thing - How much variance is explained by each dimension
print ('Ratio of variance explained: ', pca.explained_variance_ratio_)
# ('Ratio of variance explained: ', array([ 0.09746116, 0.07155445]))
principal_components = pca.components_ # (2, 784)
# Reconstructing data
pca_rec = PCA(n_components)
X_reduced_rec = pca_rec.fit_transform(X)
principal_components_rec = pca_rec.components_
rec = np.dot(X_reduced_rec, principal_components_rec)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
