
RocketMQ
RocketMQ
一、MQ意义和选型
1、优势
1)削峰填谷(如:秒杀)
2)系统解耦(如:下一个订单,可能涉及积分、库存等)
3)提升性能
4)蓄流压测(线上有些链路不好压测,可以通过堆积一定量消息再放开来压测)
2、RocketMq特性
1)支持事务型消息(rabbitMQ,kafka不支持)
2)支持18个级别的延迟消息(rabbitMQ,kafka不支持)
3)支持指定次数和时间间隔的失败消息重发(rabbitMQ需要手动确认,kafka不支持)
4)支持consumer端tag过滤,减少不必要的网络传输。(rabbitMQ,kafka不支持)
5)支持重复消费(rabbitMQ 不支持,kafka支持)
二、RocketMQ集群概述
1、集群部署结构
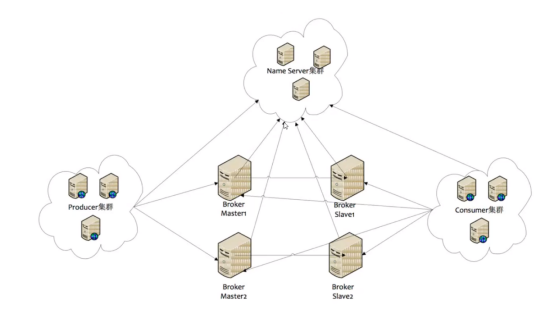
1)name Server
是一个无状态的节点,它的作用是负载均衡的作用,监控broker的状态,product 和consumer 通过Name Server获取broker链接。
2)Broker
核心,存储消息的具体数据。为了保证broker的高可用性,一般多部署几台,分主从,一主多从和多主多从,broker id 等于0时为主,其它为从。
每个Broker 与Name Server集群中所有的节点建立长连接,定时(每隔30s)注册Topic信息到所有的Name Server。Name Server定时(每隔10s)扫描所有存活broker的连接,如果Name Server超过2分钟没有收 到心跳,则Name Server断开与Broker的连接。
问题:如果Broker有一个主节点挂掉,product还能生产消息吗?Consumer还能消费吗?
生产者发送消息,consumer继续消费消息,这是高可用的设计,因为存在消息延迟,因为不是双写,是通过同步的方式同步主从。
3)Product
product每隔30s,从name Server获取所有topic队列的最新情况。
Producer每隔30s(由ClientConfifig中heartbeatBrokerInterval决定)向所有关联的broker发送心跳, Broker每隔10s中扫描所有存活的连接,如果Broker在2分钟内没有收到心跳数据,则关闭与Producer的连接。
4)Consumer
心跳检测和product一样
当consumer得到master宕机的通知后,可以继续消费从节点的消息。
一、关键特性及实现原理
1、顺序消费
生产者-MQServer-消费者 是一一对应关系时,可以保证顺序消费。但是这样的设计也会存在问题。比如:
1)吞吐量不够
2)一个出现问题,会导致整个处理流程阻塞。
RocketMQ解决顺序消费,通过轮询所有队列的方式来确定消息被发送到哪一个队列(负载均衡策略)。
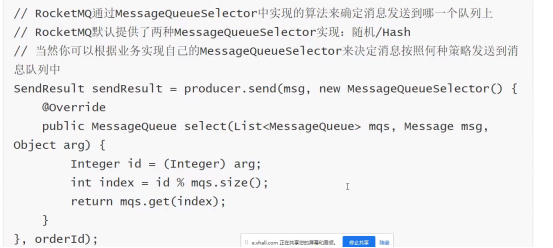
根据路由规则,选择选择合适的broker发送消息,基于下面的模型解决问题;
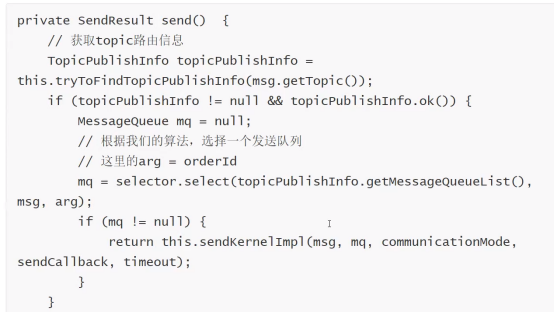
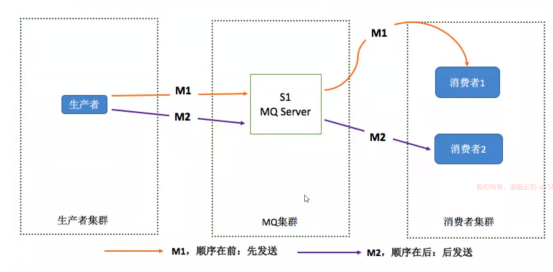
总结:上游发送者可以定制路由规则发送消息,消费者也可以定制这个消费规则。把消息需要顺序消费的写到同一个队列里面,这个队列布置是RocketMQ 的commitlog 也可以是kafaka的partion,这样保证百分之百顺序消费
1、消息重复
原因:网络不可达。
如何处理:1)消息端处理消息的业务逻辑要保持幂等性,不管处理多少次,最后处理的结果都一样;2)保证每一条数据都有唯一的编码,利用日志表存储消息处理的ID,如果新的消息ID在日志表中已经存在,那就不做处理;
LevelDb 和RocksDB 持久化数据
2、事务性消息
同样的一个转账业务,在集群环境下,耗时会成倍的增加,这显然是不能接受的。如何来规避这个问题?
大事务 = 小事务 + 异步
RocketMQ 支持事务消息,实现如下:
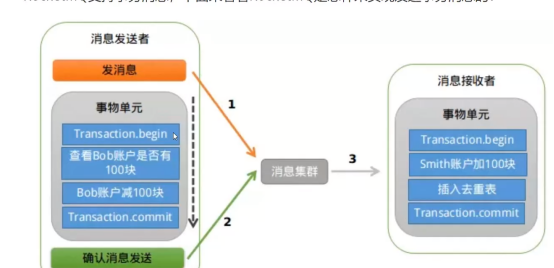
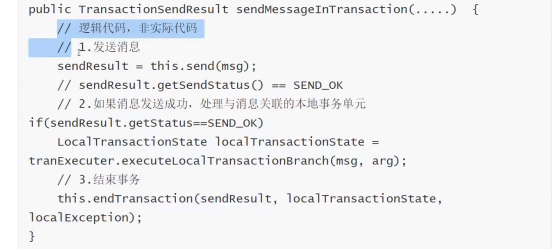
事务消息的发送过程:
1、消息存储
RocketMQ 的消息存储是有consumer queue 和commitLog 配合完成的。
consumer queue是消息的逻辑队列,相当于字典目录,用来指定消息在物理文件commitLog上的位置。
commitLog
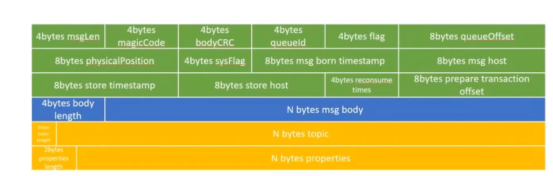
所有topic的消息都存在一个称为commitLog的文件中,改文件默认1GB,以顺序IO的方式写入磁盘,充分利用了磁盘的顺序写,减少IO竞争。
commitLog 中的存储格式如下:
ConsumQueue
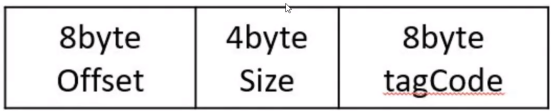
一个ConsumQueue表示一个topic的一个queue,类似kafka的一个partition,但是rocketmq在消 息存储上与kafka有着非常大的不同,RocketMQ的ConsumeQueue中不存储具体的消息,具体的消息 由CommitLog存储,ConsumeQueue中只存储路由到该queue中的消息在CommitLog中的offffset,消 息的大小以及消息所属的tag的hash(tagCode),一共只占20个字节,整个数据包如下:
在消息存储方面kafka和RocketMQ区别:
RocketMQ的消息存储在在同一个CommitLog中,而Kafka将每个partition的消息分开存储。RocketMQ 单个broker能支持更多的topic和 partition
1、消息订阅
RocketMq 消息订阅有两种模式:
一种叫push模式,即MQServer主动向消费端推送。
另一种是Pull模式,即消费端在需要时,主动向MQServer拉取
一、RocketMQ的其他特性
1)定时消息,只能发送7天内的定时消息
2)消息的刷盘策略(持久化)
3)主动同步策略:同步双写、异步复制
4)海量消息的堆积能力
5)高效通信
二、RocketMQ的最佳实践
1、Producer 最佳实践
1).一个应用尽可能用一个Topic,消息子类型用tags来标识,tags可以由应用自由设置。只有发送消息设置了tags,消费方在订阅消息时,才可以利用tags在broker做消息过滤。
2) 每个消息在业务层面的唯一标识码,要设置到keys字段,方便将来定位消息丢失问题。由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。
3)消息发送成功或者失败,要打印消息日志,务必打印sendResult和key字段
4)对于消息不可丢失应用,务必要有消息重发机制。例如:消息发送失败,存储到数据库,能有定时程序尝试重发或者人工触发重发。
2、Consumer 最佳实践
1)消费过程要做到幂等
2)尽量批量消费,提高吞吐量。
3、其它配置
autoCreateTopicEnable应设置为false,如果设为true会破会负载均衡。
4、RocketMQ设计相关
RocketMQ的设计假定:
1)每台PC机器都可能宕机的可能;
2)任意集群都可能处理能力不足
3)最坏的情况一定会发生
4)内网需要低延迟来提高最佳用户体验。
RocketMQ的关键:
1)分布式集群化;
2)数据安全
3)海量数据堆积
4)毫秒级投递延迟(推拉模式)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号