Fast R-CNN(RoI)
Fast R-CNN是一个基于区域的目标检测算法。Fast R-CNN建立在先前的工作之上,并有效地使用卷积网络分类目标建议框。与先前的工作相比,使用几点创新改善了训练和测试时间并增加了检测准确率。
2. Fast R-CNN结构和训练
图1展示了Fast R-CNN的结构。该网络输入一个完整的图像和一组目标建议框。首先用卷积和池化来产生一个特征图。然后,对每一个目标建议框使用RoI(Region of Interest)池化层从特征图提取一个固定长度的向量。每个特征向量送人两个兄弟般的全连接层,一个来输出类的概率,一个输出四个值。每组的四个值是边界框相关编码。
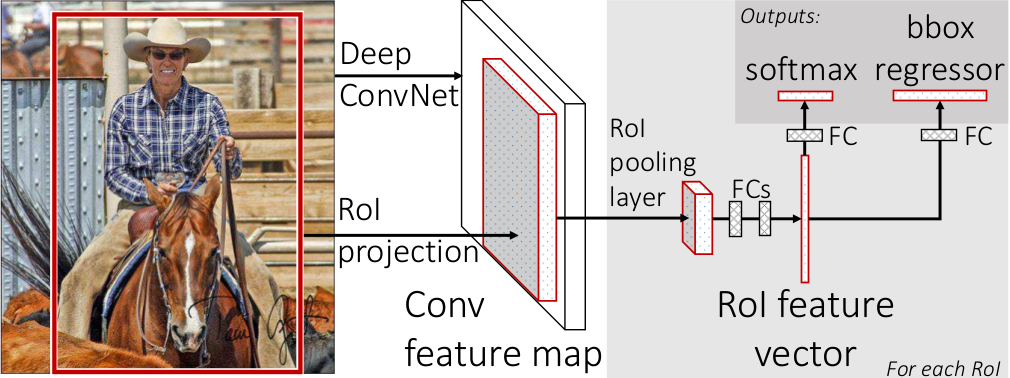
图1:Fast R-CNN结构。输入一张图像和多个RoI到全连接网络。每个RoI池化成固定尺寸的特征图,然后通过全连接层映射成一个特征向量。这个网络对于每个RoI有两个输出向量:softmax概率和每个类的边框回归偏移。这个结构使用一个多任务损失进行端到端的训练。
2.1 RoI池化层
RoI池化层用最大值池化将RoI内的特征转化成固定空间大小$H×W$(例如,7×7)的特征图。RoI是一个矩形框,用(r,c,h,w)表示,(r,c)表示左上角,(h,w)表示高度和宽度。
RoI最大池化将$h×w$的RoI分割成$H×W$的格点,每个格点的尺寸大约为$h/H×w/W$,将每个格点最大池化格点的输出。池化独立应用到每个特征图通道,好像标准最大池化一样。RoI层SPPnets中使用的空间金字塔池化中的简单的特殊情况。
2.2 从预训练网络初始化
尝试了3个预训练的ImageNet网络,每个都有5个最大池化层和5-13卷积层(4.1节有更多细节)。使用一个预训练的网路,有三个转换。
①最后一个最大池化层被RoI池化层取代,并且设置$H$和$W$与网络的第一个全连接层兼容。
②用两个兄弟般的层取代网络的最后全连接层和softmax。
③修改网络的输入:一组图像和这些图像的RoI
2.3 用于检测的微调
Multi-task loss. Fast R-CNN有两个输出层。第一个输出每个RoI在$K+1$个类上的离散概率分布。第二个输出是边框偏移。
每个训练RoI用真值类别$u$和真值边框回归目标$v$标签。在每一个标签的RoI上用多任务损失$L$联合训练分类和边框回归:
$L(p,u,t^u,v)=L_{cls}(p,u)+λ[u≥1]L_{loc}(t^u,v)$, (1)
这里$L_{cls}(p,u)=-\rm{log}p_{u}$是真实类别$u$的log损失。
第二个损失$L_{loc}$定义在真实边框回归目标的$(v_{x},v_{y},v_{w},v_{h})$和预测结果$t^u=(t^{u}_{x},t^{u}_{y},t^{u}_{w},t^{u}_{h})$上。当$u≥1$函数$[u≥1]$表示1,否则为0。按照惯例,将背景类标记为$u=0$。没有真值边框的背景RoI不参与损失计算。针对边框回归,使用下面损失:
$L_{loc}(t^{u},v)=\sum{i\in{\{x,y,w,h\}}}\rm{smooth}_{L_{1}}(t^{u}_{i}-v_{i})$, (2)
其中:
$\rm{smooth_{L_{1}}}(x) = \left\{
\begin{array}{lcl}
{0.5x^{2}} & if|x|<1 \\
{ |x|-0.5} & otherwise
\end{array}
\right.$ (3)
$L_{1}$损失比R-CNN和SPPnet中的$L_{2}$更鲁棒。当回归目标没有没有边界时,$L_{2}$损失训练需要仔细调整学习率来防止梯度爆炸。公式(3)消除了这种敏感。
公式(1)中的超参数λ控制了两个任务损失的平衡。将真值回归目标$v_{i}$归一化到0均值和单位方差。左右的实验使用λ=1。
Mini-batch sampling. 在微调过程中,SGD的批量数是$N=2$张图像,每张图像64RoI,共$R=128$个RoI。意思是每次训练只输入两张图像,64个RoI之间共享卷积特征。从与真值框重叠超过0.5的目标建议框中挑出25%的RoI,这些RoI只包含前景目标。其余RoI从目标建议与真值IoU在区间[0.1,0.5)的最大值中采样。除了数据镜像外,没有采用其它数据增强。
Back-propagation through RoI pooling layers. 为清楚起见,假设每个批量中只有一张图像($N=1$),这不影响结果。
设$x_{i}\in \mathbb{R}$是RoI池化层的第$i$激活输入,$y_{rj}$是第$r$个RoI层的第$j$个输出。RoI池化层计算$y_{rj}=x_{i*(r,j)}$,其中$i*(r,j)=argmax_{i'\in{R(r,j)}}x_{i'}$。$R(r,j)$是在输出单元$y_{rj}$子窗口上的一组输入索引,就是格点区域的所有索引。一个$x_{i}$可以被分配几个不同的输出$y_{rj}$。
RoI池化层的反向传播函数计算每个输入变量$x_{i}$损失函数的偏导数,如下所示:
$\frac{\partial L}{\partial x_{i}}=\sum_{r}\sum_{j}[i=i*(r,j)]\frac{\partial L}{\partial y_{rj}}$. (4)
总之,对于每个批量中的RoI的$r$和对于每个池化输出单元$y_{rj}$,如果$i$是$y_{rj}$最大池化的最大选择,则加上所有相关的偏导数$\partial L/ \partial y_{rj}$来求得$\frac{\partial L}{\partial x_{i}}$,也就是说,这些$y_{rj}$由相关$x_{i}$贡献得到,再反过来求$x_{i}$对于$L$的偏导数。
SGD hyper-parameters. 用于softmax分类和边框回归的全连接层使用零均值和分别为0.01和0.001的标准差初始化。偏置初始化为0。所有层使用一个全局学习率0.001,并且权值为1倍,偏置为2倍。
2.4 尺度不变性
探索了两种实现尺度不变性的方法:(1)通过暴力强迫学习(2)通过图像金字塔。暴力强迫法是在训练和测试时用一个预定义的像素尺寸。网络必须从训练数据学习尺度不变的目标检测。
相比而言,多尺度方法通过一个图像金字塔给网络提供尺度不变性。更多细节参考Spatial pyramid pooling in deep convolutional networks for visual recognition.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号