Hadoop-总结
HDFS
hafs进程
namenode -> 元数据写到硬盘上 -> 两种文件:fsimage edit_log —> 为什么写出两文件
fsimage 恢复快,数据不全,edits_log 数据全,恢复慢,使用2个文件更好,
所有基于内存的解决方案都是这样(例如redis)
安全模式:防止你读到读不到元数据对应的块
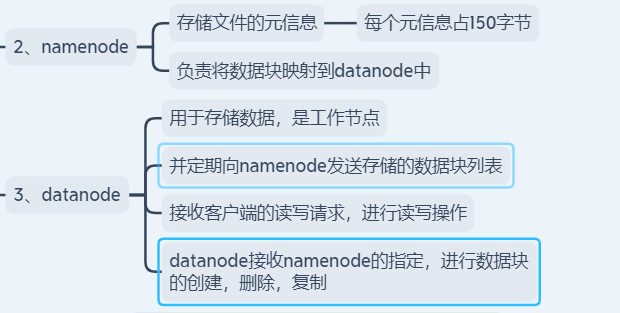
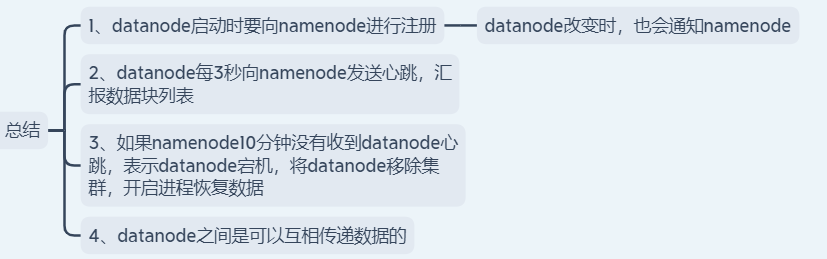
datanode -> 存储数据的,与namenode保持心跳机制,同时上报元数据
HA相关进程
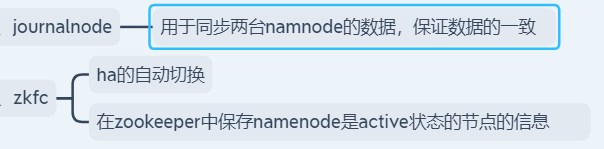
zkfc -> 切换namenode的active,stanby状态的,还负责监控namenode的是否存活的
journalnode -> 同步两个namenode之前的元数据信息的,同步edit_log
hadoop --config 指定加载配置,可以多个集群切换操作
hadoop distcp 大文件拷贝
yarn
resourceManager
nodeManager appMaster在此上面跑
proxyServer
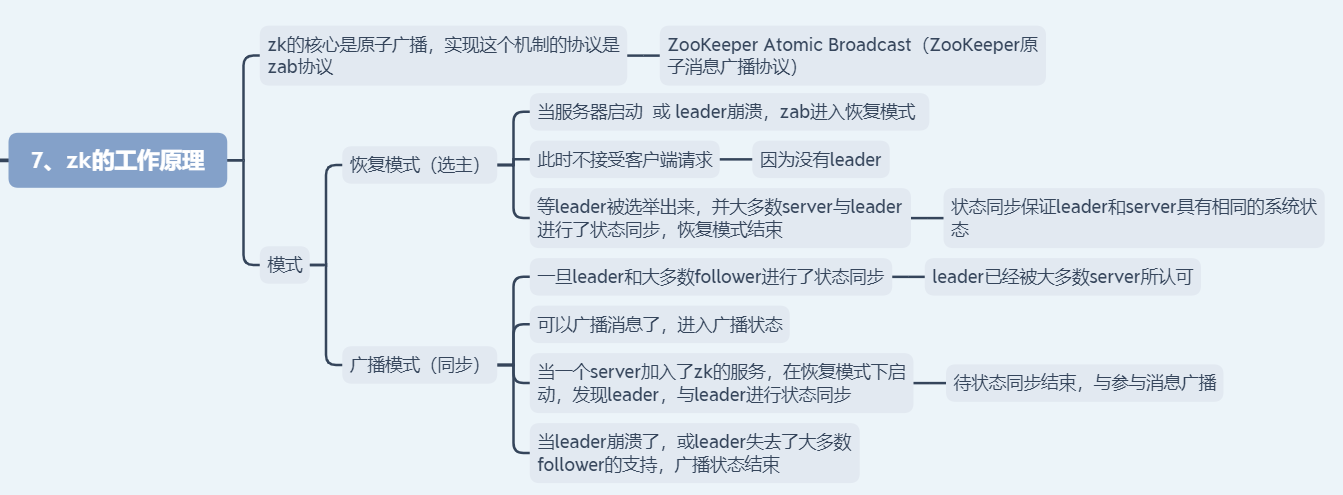
zookeeper


HDFS

优缺点:

yarn
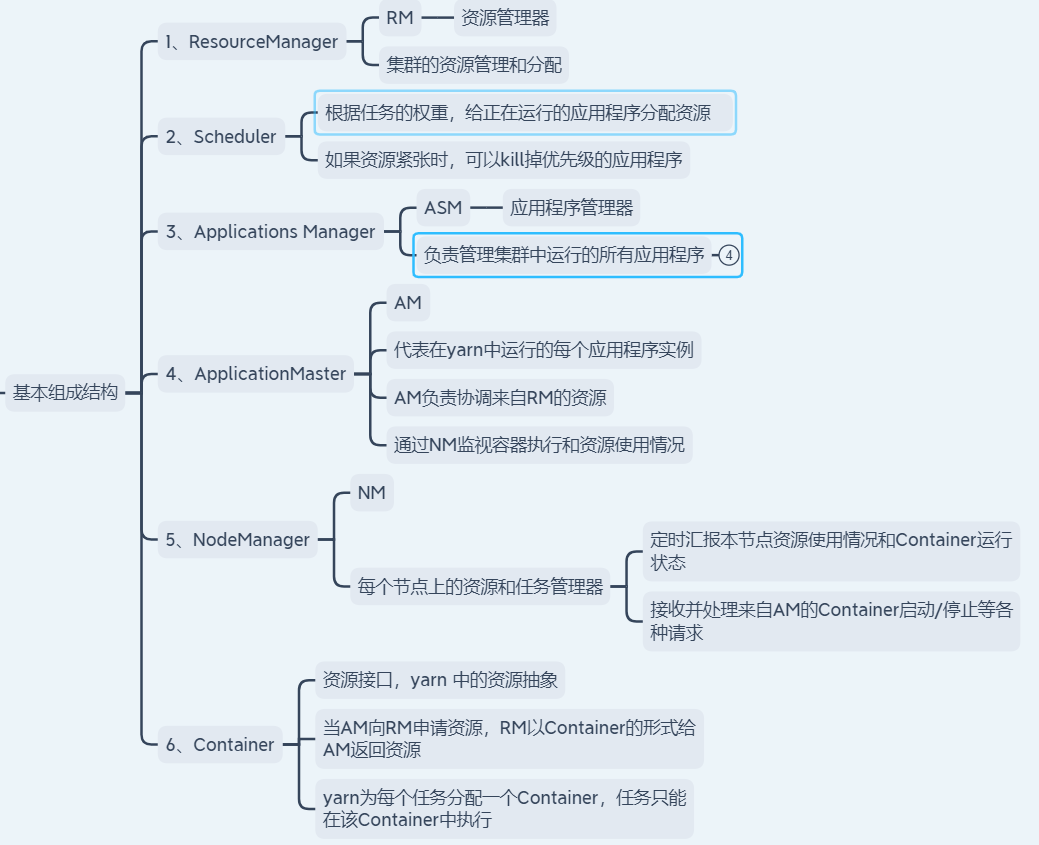
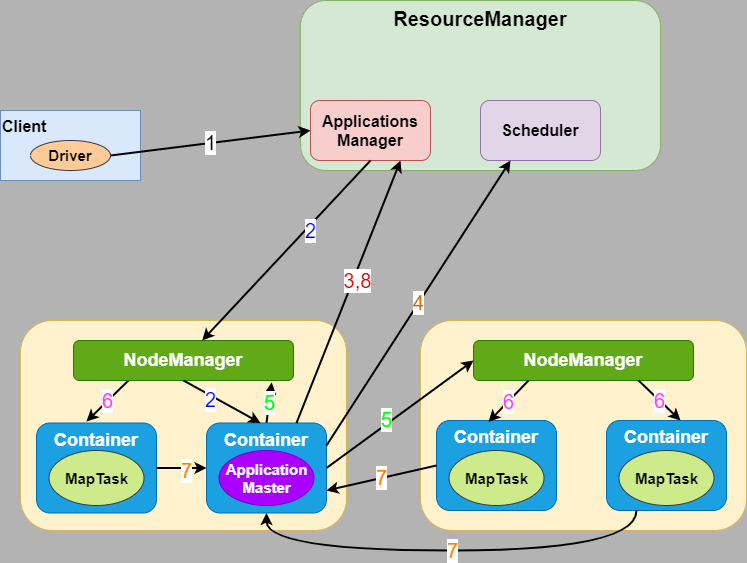
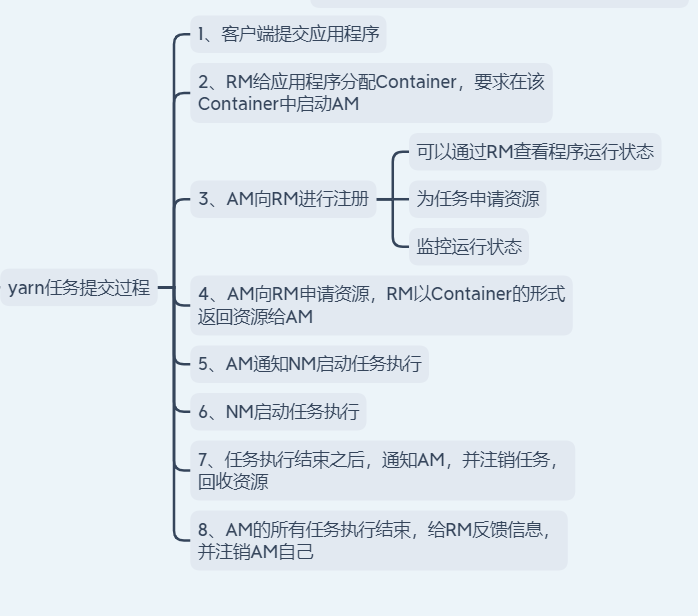
(1).用户向YARN中提交应用程序。
(2).ResourceManager为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster。
(3).ApplicationMaster首先向ResourceManager注册,目的是让用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束。
(4).ApplicationMaster向ResourceManager 的 scheduler申请和领取资源(通过RPC协议)。
(5).ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务(java进程)。
(6).NodeManager启动任务。
(7).各个任务向ApplicationMaster汇报自己的状态和进度(通过RPC协议),以便让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
(8).应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
工作的时候,得有项目上线
1.开发完成
2.打包
3.用JD-GUI看一下打的包是不是你最新写的代码
4.上传到服务的操作机上
5.跑起来
参考博客:YARN原理
Mapreduce
mapreduce的shuffle在面试的时候会问那几点?
1.map为什么输出到环型缓冲区,为什么叫环型缓冲区?
减少磁盘落地次数
还需要排序
2.为什么在缓冲区输出的时候进行排序?
速度快
3.combiner的作用,运行原理?
map端局部聚合
4.reduce拉取过来的数据为什么放在buffer?
减少网络拉取的次数、减少磁盘落地次数、还有排序
5.reduce中的排序是为什么?
放磁盘必须排序,不排序,速度太慢,顺序读取速度快,spark基于内存可以先不排序
6.为什么reducer输入的数据必须在硬盘上?直接放在内存里面不就不用排序了吗?
内存不够用,放内存可以不用排序
7.mr的map和reduce如果没有自己的实现类,那能运行吗?
可以,什么也不干
8.什么是shuffle?第一进行数据的网络拉取,第二进行key的洗排
9.shuffle怎么优化?
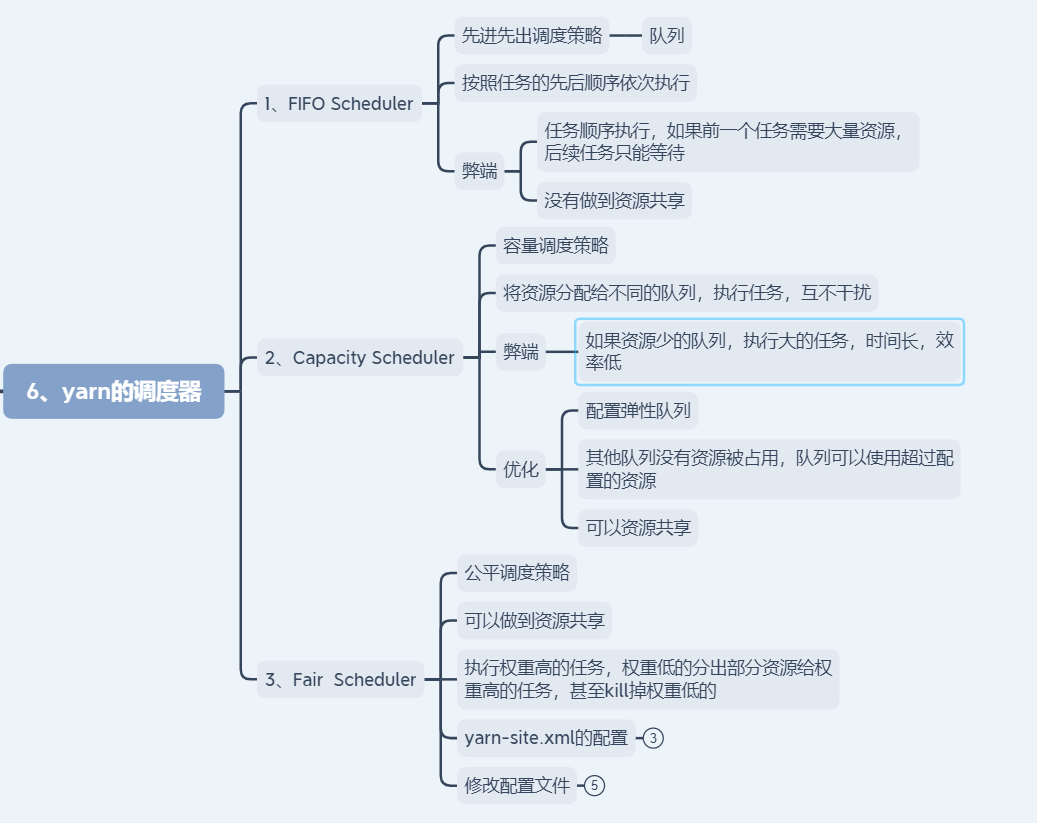
1).首先shuffle过程中可能产生数据的倾斜 -> 自己定义一个partitioner(默认是hashCode % numReduce)
2).使用combiner或压缩map任务输出的数据量,其实总的来说就是减少网络传输的数据量
3).调整参数,map端的sort的内存,reduce端的拉取的内存
4).使用mapjoin来进行数据的join,这样可以彻底的避免shuffle
程序在集群中运行需要几个条件:
1.程序的配置
2.你的代码
3.环境
java -Djava.libary.path=/usr/local/hadoop/etc/hadoop,/usr/local/hadoop/share/hadoop/common/*,/usr/local/hadoop/share/hadoop/common/lib/*,/usr/local/hadoop/share/hadoop/hdfs/*,/usr/local/hadoop/share/hadoop/hdfs/lib/*,/usr/local/hadoop/share/hadoop/mapreduce/*,/usr/local/hadoop/share/hadoop/mapreduce/lib/*,/usr/local/hadoop/share/hadoop/yarn/*,/usr/local/hadoop/share/hadoop/yarn/lib/*,/usr/local/hbase/lib/*,/usr/local/hadoop/lib/*
你程序的参数来源有几个位置啊?
1.默认配置文件(default)
2.配置文件(site)
3.命令行
4.代码里设置的
优先级从高到低排序:4 > 3 > 2 > 1
自定义序列代类可以实现两个接口
1.WritableComparable
2.Writable
counter为什么要限制?
这里可以做为工作经验去说:
涉及到两个类baseMR和jobRunnerUtil
baseMR:
1.原生的mr实现可以通过3种方法 1).通过toolRunner加上继承Configured实现Tool 2).通过main方法 3).通过任务工作链
然后会给团队开发带来麻烦,然后统一使用一种封装好的BaseMR,来写mr,这样团队的代码就统一。
2.兼容任务工作链开发,并且可以使用工作链中的每个任务都能拿到命令行传参的配置,另外还兼容每个任务有自己独立的配置
3.任务会有运行失败的时候,咱们都MR任务重新跑就会有原来输出目录存在了,运行失败了是不是应该重跑啊,然后又会因为输出目录已经存在导致任务的失败。怎么解决自动删除
4.规定了任务的名称里面,必须有任务的ID,并且这个任务的ID是唯一的。好处是什么?在yarn界面上方便你查找任务的日志。
5.固定了任务的输出目录,是为了HDFS满了的时候知道删除那部分数据,因为正式使用的数据都已经被移走了。
jobRunnerUtil:
1.封装了任务工作链的统一写法。
2.可以返回整个任务工作链的运行结果。
3.可以计算整个任务工作链的执行时长。
4.返回任务工作链中每个任务的计算器,以便任务工作链整体接触时候再结果工作链的运行结(成功/失败)进行相应的操作
baseMR和jobRunnerUtil合并使用还有一个好处就是可以把配置任务依赖关系和写mr的代码进行结耦,方便多人同时协作开发。
mr开发中需要注意两个坑:
坑1.注意本地变量与集群变量
坑2.注意reduce的values循环问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号