
生产者消费者模型
生产者消费者模型:https://blog.csdn.net/u011109589/article/details/80519863
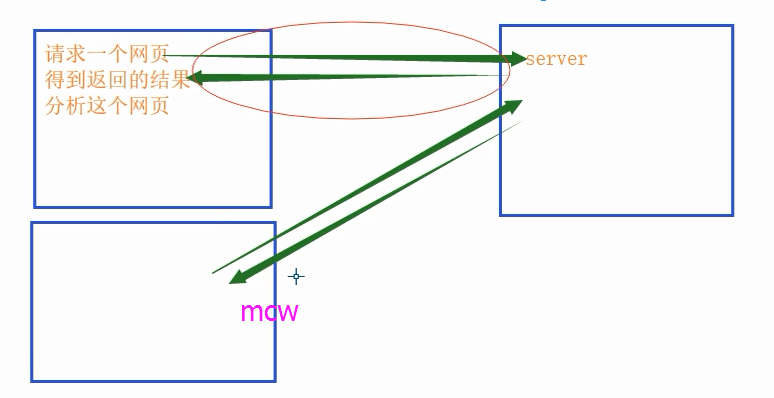
如上图:
1)客户端你要向服务端请求一个网页,
2)服务端返回一个结果给客户端,然后客户端分析这个网页
3)如果有一百个请求过来,那么就要起一百个连接,如果服务端响应一个连接就要启动一个进程,那么服务端需要开启一百个进程。而启动一百个进程的开销特别大
4)如果一百个请求过来服务端只开启一个进程,那么服务端只能一个一个的处理,这样效率会很慢,服务端响应一个请求的时候其它连接只能等待。这样明显是不合理的。
生产者消费者模型的原理(爬虫例子):

左边一个程序,中间一个容器,右边一个程序
左边那个程序只负责去请求网页,它在请求网页的过程当中,网页服务器响应请求需要一定的时间,左边这个程序获得的结果不是直接进行分析,而是放到中间的那个容器里面。左边这个程序负责发送网页请求,接收请求结果,并把结果发送到容器中。右边程序获取网页结果并分析网页数据。为什么要把它们分开呢?我左边请求网页的时间和右边网页处理所需要的时间不一致。左边网速比较慢,网页响应的时间也比较长,意味着我拿到网页的内容会很慢,假设需要5s钟,而右边程序分析网页结果是非常快的,假设需要0.5s时间。这种情况怎么做让它平衡呢?在左边起10个程序,让这10个程序同时去访问这10个网页。5s后10个结果回来后,把10个结果都扔到中间的容器里面。右边的那一个程序从容器中获取10个网页结果进行分析。
两个完全不同的过程,效率是不一样的。想让它的成果达到最高的速度。就需要把它完全的解耦开来,就做到最少的资源最少的程序获得最大的效率。因为两个过程的时间是10:1。那么这样的我就可以起11个进程,左边10个进程去请求网页,右边一个进程去处理网页,这样就达到平衡了。
如果5s中得到10个结果觉得慢,那么左边可以起20个进程请求网页,右边起2个进程处理网页。这样5s中就可以获得20个结果。
1)这样分开了以后,让你的程序执行效率达到最大化了。
2)我能节省很多个进程,否则你要想要获得20个结果,20个进程需要请求网页,处理网页。而如果使用生产者消费者模型的话,可以调节生产者和消费者的个数,让它们之间形成一个平衡的点。然后让他们分别去做这些事情。
所以,我们可以做一些程序专门获取处理的事情(左边这些进程),获取到的事情放到容器里面,在另一端做分析和解决这些事情(右边这些进程)。整个这个模型就是让生产者和消费者数量达到一个平衡。
我可以检测中间这个容器里事件的个数,分析是生产者还是消费者更快一些。假设这个队列里面经常是空的,说明生产者这边的速度慢,消费者这边的速度快。这个时候要添加生产者,调节平衡。如果这个队列总是满的,说明生产者快,消费者慢,那么需要添加消费者或者减少生产者
生产者:生产数据,右边要处理数据,左边获取到要处理的数据就是指生产数据
消费者:右边是处理数据的,我们称为消费者。
生产消费模型主要作用;就是做生产数据和消费数据的解耦问题的。解耦有什么好处,我们解耦之后可以分别对它们进行操作,指定它们之间的个数,让它们之间的操作达到平衡。
那么,消费者和生产者模型和进程有什么关系?
跟进程的关系:
# 一个进程就是一个生产者
# 一个进程就是一个消费者
跟队列的关系:
# 生产者和消费者之间的容器就是队列
这个模型中,队列还有一个作用。队列是有大小的,如果生产者过剩了,假设100个生产者进程1个消费者进程,消费者要是消费慢的话,队列里面不能无限的放数据,队列是有大小的。
生产者消费者模型的例子:
# 解耦 :修改 复用 可读性
# 把写在一起的大的功能分开成多个小的功能处理
# 登陆 注册
# 进程
# 一个进程就是一个生产者
# 一个进程就是一个消费者
# 队列
# 生产者和消费者之间的容器就是队列
----------------------------纯代码-----------------------
import time
import random
from multiprocessing import Process,Queue
def producer(q,name,food):
for i in range(5):
time.sleep(random.random())
fd = '%s%s'%(food,i)
q.put(fd)
print('%s生产了一个%s-%s'%(name,food,i))
def consumer(q,name):
while True:
food = q.get()
if not food:break
time.sleep(random.randint(1,3))
print('%s吃了%s'%(name,food))
def cp(c_count,p_count):
q = Queue(10)
for i in range(c_count):
Process(target=consumer, args=(q, '灰太狼')).start()
p_l = []
for i in range(p_count):
p1 = Process(target=producer, args=(q, '喜洋洋', '包子'))
p1.start()
p_l.append(p1)
for p in p_l:p.join()
for i in range(c_count):
q.put(None)
if __name__ == '__main__':
cp(2,3)
---------------------------纯代码------------------------
import time
import random
from multiprocessing import Process,Queue #1)从多进程导入进程队列两个类
def producer(q,name,food): #2)定义生产者,消费者函数,将创建的队列对象传进函数。
for i in range(5):
time.sleep(random.random()) #6)时间就time睡随几个数字范围内的秒数)
fd = '%s%s'%(food,i)
q.put(fd)
print('%s生产了一个%s-%s'%(name,food,i))
#5)生产者函数传进食物,对食物操作产生食物这个数据,将数据放入进程队列,q.put(数据)(因为是案例,模拟生产花费
def consumer(q,name): #2)定义生产者,消费者函数,将创建的队列对象传进函数。
while True:
food = q.get()
if not food:break
time.sleep(random.randint(1,3))
print('%s吃了%s'%(name,food))
#7)消费者函数传进名字。函数内从进程对类获取队列中数据q.get(),演示谁消费了什么食物,
8)生产者函数中一个人生产多个食物,用for 循环,一个人指定生产多少个。消费者函数中,由于不知道有谁消费,所以9)用while True来进行操作q.get()消费。让它直到消费完才停止
#定义一个生产者消费者的函数,传参消费者个数,生产者个数。将if __name__ == '__main__': 后面的东西放到函数里面。创建队列。根据传参for循环创建生产者消费者个数。对生产者进程阻塞,每个生产者进程结束之后才for循环消费者个数次往进程队列里面put None,保证每个消费者都能获得一个None实现退出消费者函数get的阻塞。
然后if __name__ == '__main__':后执行这个函数,传参进入cp(2,3)
def cp(c_count,p_count):
q = Queue(10) #3)创建队列对象,最大10个数据,
for i in range(c_count):
Process(target=consumer, args=(q, '灰太狼')).start() #4)创建生产者进程,传参队列
p_l = []
for i in range(p_count):
p1 = Process(target=producer, args=(q, '喜洋洋', '包子'))
p1.start()
p_l.append(p1)
for p in p_l:p.join()
for i in range(c_count):
q.put(None)
if __name__ == '__main__':
cp(2,3)
---------------------结果:
喜洋洋生产了一个包子-0
喜洋洋生产了一个包子-0
喜洋洋生产了一个包子-0
喜洋洋生产了一个包子-1
喜洋洋生产了一个包子-1
喜洋洋生产了一个包子-1
喜洋洋生产了一个包子-2
灰太狼吃了包子0
喜洋洋生产了一个包子-3
喜洋洋生产了一个包子-2
喜洋洋生产了一个包子-2
灰太狼吃了包子0
喜洋洋生产了一个包子-4
喜洋洋生产了一个包子-3
喜洋洋生产了一个包子-3
喜洋洋生产了一个包子-4
灰太狼吃了包子0
喜洋洋生产了一个包子-4
灰太狼吃了包子1
灰太狼吃了包子1
灰太狼吃了包子1
灰太狼吃了包子2
灰太狼吃了包子3
灰太狼吃了包子2
灰太狼吃了包子4
灰太狼吃了包子2
灰太狼吃了包子3
灰太狼吃了包子3
灰太狼吃了包子4
灰太狼吃了包子4
注解:
1)从多进程导入进程队列两个类
2)定义生产者,消费者函数,将创建的队列对象传进函数。
3)创建队列对象,最大10个数据,
4)创建生产者进程,传参队列
5)生产者函数传进食物,对食物操作产生食物这个数据,将数据放入进程队列,q.put(数据)(因为是案例,模拟生产花费6)时间就time睡随几个数字范围内的秒数)
7)消费者函数传进名字。函数内从进程对类获取队列中数据q.get(),演示谁消费了什么食物,
8)生产者函数中一个人生产多个食物,用for 循环,一个人指定生产多少个。消费者函数中,由于不知道有谁消费,所以9)用while True来进行操作q.get()消费。让它直到消费完才停止
10)一个生产者一个消费者,如果生产者快的时候,因为队列大小在创建进程队列的时候是指定大小的,当生产者过快的时候会因为不能插入队列等待消费者消费掉队列中的数据才插入。可以进行调整消费者和生产者的数量,即消费进程和生产进程的数量
11)如果队列取完了,消费者函数里面是死循环,get不到数据就会阻塞在那里,这样不合理。正常应该是让生产者生产完,放到队列我拿完了那么就退出死循环从队列里拿数据。- 如何解决:我在后面给生产者加个阻塞join,等所有的生产者生产完,再往队列里面添加None,当消费者函数中的get,get到None的时候(即if not get的数据:)就退出循环,这样在生产者生产完所有的数据之后,消费者就退出get等待了。如果只有一个消费者,get一个None之后就退出消费者函数中的get阻塞了,如果有两个消费者,那么需要get到两个None才可以让所有消费者(即消费者进程)退出消费者函数中的队列get阻塞。因此,有几个消费者就需要几个None,有几个消费者就需要在所有的生产者对象.join()(即阻塞一下,等待所有生产者进程结束)之后往进程队列里面put几个None。这样,没个消费者进程拿到一个None之后就会break退出死循环。
定义一个生产者消费者的函数,传参消费者个数,生产者个数。将if name 后面的东西放到函数里面。创建队列。根据传参for循环创建生产者消费者个数。对生产者进程阻塞,每个生产者进程结束之后才for循环消费者个数次往进程队列里面put None,保证每个消费者都能获得一个None实现退出消费者函数get的阻塞。
然后if name == 'main':后执行这个函数,传参进入cp(2,3)
消费者取完生产者生产的总数据之后退出从队列get数据
如果队列取完了,消费者函数里面是死循环,get不到数据就会阻塞在那里,这样不合理。正常应该是让生产者生产完,放到队列我拿完了那么就退出死循环从队列里拿数据。
- 如何解决:我在后面给生产者加个阻塞join,等所有的生产者生产完,再往队列里面添加None,当消费者函数中的get,get到None的时候(即if not get的数据:)就退出循环,这样在生产者生产完所有的数据之后,消费者就退出get等待了。如果只有一个消费者,get一个None之后就退出消费者函数中的get阻塞了,如果有两个消费者,那么需要get到两个None才可以让所有消费者(即消费者进程)退出消费者函数中的队列get阻塞。因此,有几个消费者就需要几个None,有几个消费者就需要在所有的生产者对象.join()(即阻塞一下,等待所有生产者进程结束)之后往进程队列里面put几个None。这样,没个消费者进程拿到一个None之后就会break退出死循环。
此处与上代码区别:
消费者添加 :if not food:break
p1.join() #所有生产者阻塞一下
q.put(None) #往队列里面放入None,供消费者函数取,取出这个不是真的就退出进程队列的get阻塞
q.put(None)
def consumer(q,name):
while True:
food = q.get()
if not food:break
time.sleep(random.randint(1,3))
print('%s吃了%s'%(name,food))
if __name__ == '__main__':
q = Queue(10)
p1 = Process(target=producer, args=(q, '喜洋洋', '包子'))
p1.start()
c1=Process(target=consumer, args=(q, '灰太狼'))
c2=Process(target=consumer, args=(q, '红太狼'))
c1.start()
c2.start()
p1.join()
q.put(None)
q.put(None)
-----------------结果:
喜洋洋生产了一个包子-0
灰太狼吃了包子0
喜洋洋生产了一个包子-1
喜洋洋生产了一个包子-2
灰太狼吃了包子2
红太狼吃了包子1
喜洋洋生产了一个包子-3
喜洋洋生产了一个包子-4
灰太狼吃了包子3
红太狼吃了包子4
Process finished with exit code 0
生产跟不上消费:
一个生产者两个消费者,生产者跟不上消费者的速度(time睡长一点,生产变慢),那么生产一个就被消费掉了。
------------------结果:
喜洋洋生产了一个包子-0
灰太狼吃了包子0
喜洋洋生产了一个包子-1
红太狼吃了包子1
喜洋洋生产了一个包子-2
灰太狼吃了包子2
喜洋洋生产了一个包子-3
红太狼吃了包子3
喜洋洋生产了一个包子-4
灰太狼吃了包子4
生产过剩现象(生产的快,消费的慢):
一个生产者一个消费者,如果生产者快的时候,因为队列大小在创建进程队列的时候是指定大小的,当生产者过快的时候会因为不能插入队列等待消费者消费掉队列中的数据才插入。可添加消费者,此处。
import time
import random
from multiprocessing import Process,Queue
def producer(q,name,food):
for i in range(5):
time.sleep(random.random())
fd = '%s%s'%(food,i)
q.put(fd)
print('%s生产了一个%s-%s'%(name,food,i))
def consumer(q,name):
while True:
food = q.get()
time.sleep(random.randint(1,3))
print('%s吃了%s'%(name,food))
if __name__ == '__main__':
q = Queue(10)
p1 = Process(target=producer, args=(q, '喜洋洋', '包子'))
p1.start()
c1=Process(target=consumer, args=(q, '灰太狼'))
c1.start()
------------------结果:
喜洋洋生产了一个包子-0
喜洋洋生产了一个包子-1
喜洋洋生产了一个包子-2
灰太狼吃了包子0
喜洋洋生产了一个包子-3
喜洋洋生产了一个包子-4
灰太狼吃了包子1
灰太狼吃了包子2
灰太狼吃了包子3
灰太狼吃了包子4
多进程爬虫
def consumer(q):
while True:
s = q.get()
if not s:break
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S)
ret = com.finditer(s)
for i in ret:
print({
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num")}
)
if __name__ == '__main__':
count = 0
q = Queue(3)
p_l = []
for i in range(10):
url = 'https://movie.douban.com/top250?start=%s&filter='%count
count+=25
p = Process(target=producer,args=(q,url,)).start()
p_l.append(p)
p = Process(target=consumer, args=(q,)).start()
for p in p_l:p.join()
q.put(None)
--------------------------------结果:
{'id': '176', 'title': '未麻的部屋', 'rating_num': '8.9', 'comment_num': '138201人'}
{'id': '177', 'title': '穿越时空的少女', 'rating_num': '8.6', 'comment_num': '238035人'}
{'id': '178', 'title': '模仿游戏', 'rating_num': '8.6', 'comment_num': '338718人'}
{'id': '179', 'title': '一个叫欧维的男人决定去死', 'rating_num': '8.8', 'comment_num': '182980人'}
{'id': '180', 'title': '魂断蓝桥', 'rating_num': '8.8', 'comment_num': '159135人'}
{'id': '181', 'title': '房间', 'rating_num': '8.8', 'comment_num': '217933人'}
{'id': '182', 'title': '猜火车', 'rating_num': '8.5', 'comment_num': '298472人'}
{'id': '183', 'title': '忠犬八公物语', 'rating_num': '9.1', 'comment_num': '89899人'}
{'id': '184', 'title': '魔女宅急便', 'rating_num': '8.6', 'comment_num': '265070人'}
{'id': '185', 'title': '恐怖游轮', 'rating_num': '8.4', 'comment_num': '437343人'}
{'id': '186', 'title': '罗生门', 'rating_num': '8.7', 'comment_num': '167548人'}
{'id': '187', 'title': '完美陌生人', 'rating_num': '8.5', 'comment_num': '317948人'}
{'id': '188', 'title': '阿飞正传', 'rating_num': '8.5', 'comment_num': '281842人'}
{'id': '189', 'title': '哪吒闹海', 'rating_num': '8.9', 'comment_num': '114924人'}
{'id': '190', 'title': '香水', 'rating_num': '8.5', 'comment_num': '349002人'}
{'id': '191', 'title': '黑客帝国3:矩阵革命', 'rating_num': '8.6', 'comment_num': '212734人'}
{'id': '192', 'title': '海街日记', 'rating_num': '8.7', 'comment_num': '199016人'}
{'id': '193', 'title': '朗读者', 'rating_num': '8.5', 'comment_num': '325734人'}
{'id': '194', 'title': '浪潮', 'rating_num': '8.7', 'comment_num': '167347人'}
{'id': '195', 'title': '可可西里', 'rating_num': '8.7', 'comment_num': '164466人'}
{'id': '196', 'title': '谍影重重2', 'rating_num': '8.6', 'comment_num': '209685人'}
{'id': '197', 'title': '谍影重重', 'rating_num': '8.5', 'comment_num': '249992人'}
{'id': '198', 'title': '牯岭街少年杀人事件', 'rating_num': '8.8', 'comment_num': '141814人'}
{'id': '199', 'title': '战争之王', 'rating_num': '8.6', 'comment_num': '216463人'}
{'id': '200', 'title': '地球上的星星', 'rating_num': '8.9', 'comment_num': '113949人'}
{'id': '126', 'title': '神偷奶爸', 'rating_num': '8.5', 'comment_num': '540924人'}
{'id': '127', 'title': '蝙蝠侠:黑暗骑士崛起', 'rating_num': '8.7', 'comment_num': '394574人'}
{'id': '128', 'title': '萤火之森', 'rating_num': '8.8', 'comment_num': '241203人'}
{'id': '129', 'title': '唐伯虎点秋香', 'rating_num': '8.5', 'comment_num': '508757人'}
{'id': '130', 'title': '超能陆战队', 'rating_num': '8.6', 'comment_num': '530945人'}
{'id': '131', 'title': '怪兽电力公司', 'rating_num': '8.6', 'comment_num': '343426人'}
{'id': '132', 'title': '岁月神偷', 'rating_num': '8.7', 'comment_num': '381393人'}
{'id': '133', 'title': '电锯惊魂', 'rating_num': '8.7', 'comment_num': '271110人'}
{'id': '134', 'title': '无人知晓', 'rating_num': '9.1', 'comment_num': '120276人'}
{'id': '135', 'title': '七武士', 'rating_num': '9.2', 'comment_num': '104252人'}
{'id': '136', 'title': '谍影重重3', 'rating_num': '8.8', 'comment_num': '243010人'}
{'id': '137', 'title': '真爱至上', 'rating_num': '8.6', 'comment_num': '415607人'}
{'id': '138', 'title': '疯狂原始人', 'rating_num': '8.7', 'comment_num': '494056人'}
{'id': '139', 'title': '喜宴', 'rating_num': '8.9', 'comment_num': '186550人'}
{'id': '140', 'title': '英雄本色', 'rating_num': '8.6', 'comment_num': '258624人'}
{'id': '141', 'title': '东邪西毒', 'rating_num': '8.6', 'comment_num': '345314人'}
{'id': '142', 'title': '萤火虫之墓', 'rating_num': '8.7', 'comment_num': '260349人'}
{'id': '143', 'title': '贫民窟的百万富翁', 'rating_num': '8.5', 'comment_num': '483044人'}
{'id': '144', 'title': '血战钢锯岭', 'rating_num': '8.7', 'comment_num': '447829人'}
{'id': '145', 'title': '黑天鹅', 'rating_num': '8.5', 'comment_num': '529828人'}
{'id': '146', 'title': '记忆碎片', 'rating_num': '8.6', 'comment_num': '359566人'}
{'id': '147', 'title': '傲慢与偏见', 'rating_num': '8.5', 'comment_num': '408012人'}
{'id': '148', 'title': '时空恋旅人', 'rating_num': '8.7', 'comment_num': '285877人'}
{'id': '149', 'title': '心迷宫', 'rating_num': '8.7', 'comment_num': '260540人'}
{'id': '150', 'title': '纵横四海', 'rating_num': '8.8', 'comment_num': '213239人'}
{'id': '26', 'title': '蝙蝠侠:黑暗骑士', 'rating_num': '9.1', 'comment_num': '523466人'}
{'id': '27', 'title': '乱世佳人', 'rating_num': '9.2', 'comment_num': '375291人'}
{'id': '28', 'title': '活着', 'rating_num': '9.2', 'comment_num': '417773人'}
{'id': '29', 'title': '少年派的奇幻漂流', 'rating_num': '9.0', 'comment_num': '814359人'}
{'id': '30', 'title': '控方证人', 'rating_num': '9.6', 'comment_num': '180582人'}
import time
import random
from multiprocessing import JoinableQueue,Process
def producer(q,name,food):
for i in range(5):
time.sleep(random.random())
fd = '%s%s'%(food,i)
q.put(fd)
print('%s生产了一个%s-%s'%(name,food,i))
q.join()
def consumer(q,name):
while True:
food = q.get()
time.sleep(random.random())
print('%s吃了%s'%(name,food))
q.task_done()
if __name__ == '__main__':
jq = JoinableQueue()
p =Process(target=producer,args=(jq,'喜洋洋','包子'))
p.start()
c = Process(target=consumer,args=(jq,'灰太狼'))
c.daemon = True
c.start()
p.join()
-----------------结果:
喜洋洋生产了一个包子-0
灰太狼吃了包子0
喜洋洋生产了一个包子-1
喜洋洋生产了一个包子-2
喜洋洋生产了一个包子-3
灰太狼吃了包子1
喜洋洋生产了一个包子-4
灰太狼吃了包子2
灰太狼吃了包子3
灰太狼吃了包子4
from multiprocessing import Manager,Process,Lock
def func(dic,lock):
with lock:
dic['count'] -= 1
if __name__ == '__main__':
# m = Manager()
with Manager() as m:
l = Lock()
dic = m.dict({'count':100})
print(dic)
p_l = []
for i in range(100):
p = Process(target=func,args=(dic,l))
p.start()
p_l.append(p)
for p in p_l:p.join()
print(dic)
----------------------结果:
{'count': 100}
{'count': 0}
# mulprocessing中有一个manager类
# 封装了所有和进程相关的 数据共享 数据传递
# 相关的数据类型
# 但是对于 字典 列表这一类的数据操作的时候会产生数据不安全
# 需要加锁解决问题,并且需要尽量少的使用这种方式
# 线程 开销小 数据共享 是进程的一部分
# 进程 开销大 数据隔离 是一个资源分配单位
# cpython解释器 不能实现多线程利用多核
# 锁 :GIL 全局解释器锁
# 保证了整个python程序中,只能有一个线程被CPU执行
# 原因:cpython解释器中特殊的垃圾回收机制
# GIL锁导致了线程不能并行,可以并发
# 所以使用所线程并不影响高io型的操作
# 只会对高计算型的程序由效率上的影响
# 遇到高计算 : 多进程 + 多线程
# 分布式
# cpython pypy jpython iron python
# 遇到IO操作的时候
# 5亿条cpu指令/s
# 5-6cpu指令 == 一句python代码
# 几千万条python代码
# web框架 几乎都是多线程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号