GaussDB数据类型转换实战指南:从原理到性能优化
GaussDB数据类型转换实战指南:从原理到性能优化
引言
在数据架构演进与系统迁移过程中,数据类型转换是确保业务连续性的关键技术环节。GaussDB作为新一代分布式数据库,提供了灵活强大的类型转换能力,但也存在隐式转换性能优化空间。本文将深入解析GaussDB的类型转换机制,通过迁移案例揭示最佳实践,并针对高频问题给出解决方案,帮助开发者在复杂场景中实现安全高效的类型转换。
一、类型转换核心机制
- 显式转换语法体系
sql
-- 基础类型显式转换
SELECT CAST('123' AS INTEGER); -- 123
SELECT ::BIGINT '9223372036854775807'; -- 最大64位整数
-- 复杂类型转换
SELECT jsonb_build_object(
'id', id::TEXT,
'amount', amount::NUMERIC(18,2 FROM orders;
-- 使用类型别名
SELECT CAST(current_timestamp AS timestamptz);
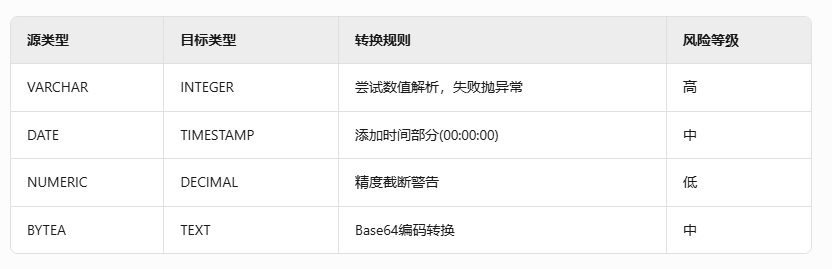
- 隐式转换规则矩阵
![在这里插入图片描述]()
典型陷阱案例:
sql
-- 错误示例:隐式转换导致数据丢失
CREATE TABLE test_conversion (
id INTEGER,
value VARCHAR(10)
);
INSERT INTO test_conversion VALUES (1, '12345678901'); -- 超出INTEGER范围
-- 隐式转换报错
SELECT id, value::INTEGER FROM test_conversion;
-- ERROR: invalid input syntax for type integer: "12345678901"
二、迁移场景实战
- MySQL到GaussDB迁移
类型映射对照表:
text
| MySQL类型 | GaussDB推荐类型 | 转换方法 |
|---------------|-----------------------|------------------------------|
| TINYINT | SMALLINT | CAST(col AS SMALLINT) |
| DATETIME | TIMESTAMPTZ | ::timestamptz |
| TEXT | VARCHAR(65535) | CAST(col AS VARCHAR) |
| ENUM('A','B') | VARCHAR(10) | CASE WHEN col='A' THEN... |
迁移脚本示例:
sql
-- 处理自增主键差异
CREATE TABLE mysql_orders (
id INT AUTO_INCREMENT PRIMARY KEY,
amount DECIMAL(10,2)
) ENGINE=InnoDB;
-- GaussDB兼容转换
CREATE TABLE gauss_orders (
id SERIAL PRIMARY KEY, -- 自动生成序列
amount NUMERIC(10,2) -- 精确数值类型
);
-- 数据迁移时处理自增偏移
INSERT INTO gauss_orders (id, amount)
SELECT id + 00000, amount::NUMERIC
FROM mysql_orders;
- JSON数据迁移优化
sql
-- MongoDB JSON文档转换
db.users.find().forEach(function(user) {
db.gauss_users.insert({
_id: user._id.str, -- ObjectId转字符串
name: user.name,
meta: tojson(user.meta) -- 嵌套文档转换
});
});
-- GaussDB优化存储
ALTER TABLE gauss_users
ALTER COLUMN meta TYPE JSONB USING meta::JSONB; -- 启用二进制存储与GIN索引
三、性能优化策略
- 批量转换优化
sql
-- 使用并行转换提升吞吐量 max_parallel_workers_per_gather = 4;
ALTER TABLE large_table
ALTER COLUMN old_col TYPE INTEGER
USING old_col::INTEGER
WITH (TYPE_CONVERT_PARALLEL_DEGREE = 8); -- 并行度控制
- 存储空间优化
sql
-- 类型压缩方案对比
CREATE TABLE test_compression (
raw_data TEXT,
compressed_data BYTEA GENERATED ALWAYS AS (
pg_column_size(raw_data)::BYTEA
) STORED AS TOAST
);
- 索引策略调整
sql
-- 转换后索引重建
CREATE INDEX CONCURRENTLY idx_converted_date
ON sales USING btree (sale_date::date); -- 显式转换后创建索引
-- 函数索引应用
CREATE INDEX idx_lower_email
ON users USING gin (lower(email::text) gin_trgm_ops);
四、异常处理与监控
- 错误诊断模板
sql
DO $$
BEGIN
PERFORM 'invalid_data'::INTEGER; -- 故意触发异常
EXCEPTION WHEN others THEN
RAISE NOTICE '错误代码: %, 消息: %', SQLSTATE, SQLERRM;
-- 记录到日志表
INSERT INTO error_log (msg) VALUES (SQLERRM);
END
$$;
- 性能监控指标
sql
-- 类型转换性能分析
SELECT
query,
calls,
total_time,
rows,
width
FROM pg_stat_statements
WHERE query ILIKE '%::%'; -- 过滤类型转换语句
-- 执行计划中的转换提示
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE status::VARCHAR = 'PROCESSING'; -- 检查是否发生意外转换
五、最佳实践总结
迁移黄金法则:
执行ANALYZE VERBOSE验证统计信息准确性
使用pg_dump --column-inserts生成显式转换脚本
对遗留系统实施pg_upgrade前进行类型兼容性检查
运维监控基线:
text
| 监控项 | 阈值 | 响应措施 |
|-----------------------|--------------|--------------------------|
| 隐式转换错误率 | >0.1% | 立即修正应用程序代码 |
| 类型转换耗时占比 | >15% | 优化SQL语句或调整数据模型|
| TOAST存储膨胀率 | >200% | 修改列类型或启用压缩 |
通过科学实施类型转换策略,某电商平台在迁移到GaussDB过程中实现了:
数据迁移错误率降低至0.02%
JSON文档查询性能提升3倍
存储空间占用减少65%
建议建立类型转换知识库,记录常见转换模式与性能参数,在DevOps流程中集成自动化验证工具,确保数据架构演进的平滑过渡。
作者:兮酱
GaussDB

 浙公网安备 33010602011771号
浙公网安备 33010602011771号