

复习
常用模块
pymysql(连接数据库)、pillow(生成图片)、selenium(爬虫)、sqlalchemy(orm对象关系映射) paramiko(连接服务器执行命令)
内置函数
map()映射 接收一个可迭代对象 将每一位元素交由一个函数处理 结果返回一个列表
max()min()最大最小
zip() 接收多个可迭代对象 组合成一个新的迭代器 类型为元组
isinstance() 判断数据类型
chr() 填数字 返回对应ascii码的数字或字母 65~90小写 97~122大写
ord() 填字符 返回对应ascii的数字
dir() 返回对象能够调用的名字
反射机制
用字符串的形式操作对象中的属性或方法 允许程序在运行时以字符串的形式动态的操作对象中的属性或方法 且无需提前知道对象的类型或名称
hasattr 判断对象中是否有对应属性或方法
setattr 给对象新增属性或方法
getattr 从对象中取对应的属性或方法 可以设默认值 否则报错
delattr 从对象中删除对应的属性或方法
魔法方法
__init__ 类实例化后给对象添加属性的时候自动触发
__new__ 类实例化对象前自动触发 返回一个新对象
__str__ 对象被执行打印操作的时候自动触发
__call__ 对象被加括号调用的时候自动触发
__getattr__ 对象点不存在名字的时候自动触发
__getattribute__ 对象点名字就会自动触发
__setattr__ 对象点名字添加或修改属性的时候自动触发
__enter__ 对象被with上下文管理开始的时候自动触发
__exit__ with语句上下文管理结束的时候自动触发
深浅拷贝
浅拷贝就是拷贝出一个新的对象 如果内部数据包含可变类型 那么只会拷贝第一层 其中的可变类型引用原来的
深拷贝就是拷贝出一个全新的对象 所有数据都是全新的
装饰器
装饰器通常是一个闭包函数 把被装饰的函数名当做参数传递进来 可以在不修改源代码的情况下给对象增加新的功能或做一些其他操作
还有一种特殊的装饰器 类装饰器 通过重写__init__和__call__方法实现
生成器
生成器是一个特殊的函数 内部含有yield关键字 该函数加括号并不会直接执行 而是返回一个生成器对象 需要通过next方法来执行内部函数 下次调用基于yield关键字继续向下执行 本质就是一个迭代器
迭代器
迭代器是由可迭代对象通过__iter__方法产生的 它提供了一种不依赖于索引取值的方式
猴子补丁
猴子补丁是指在程序运行过程中动态的替换对象中的属性或方法 以实现额外的功能或修复一些缺陷
并发编程
同步异步
同步异步是一个任务的提交方式
同步指的是任务按照预定的顺序依次执行 提交该任务后必须等待该任务执行完毕了再执行下一个任务
异步指的是任务不按照固定的顺序执行 一个任务提交后不管他是否执行完毕 会继续执行下一个任务
阻塞非阻塞
用来表达任务的执行状态
阻塞就是如当遇到io那么会阻塞在原地当io结束接着执行
非阻塞就是如当遇到io那么不会原地阻塞 继续往下执行 定时检查io是否完成
程序运行三大态 就绪态 阻塞态 运行态
进程间数据相互隔离
进程间通信技术IPC 不同进程间可以进行数据的交换和通信
1.消息队列
2.共享内存
3.socket套接字
守护进程
守护进程会随着被守护进程的结束而立刻结束
僵尸进程
子进程执行完毕后并不会立刻销毁所有的数据 会有一些信息短暂的保留下来 等待父进程回收 这些进程就叫做僵尸进程
孤儿进程
子进程正常运行 父进程结束或突然死亡的就叫做孤儿进程 操作系统会有一个进程来成为这些孤儿进程的父进程 以便进行资源回收和管理
进程 线程和协程
进程是资源分配的最小单位 一个应用程序运行至少会开启一个进程
线程是CPU调度的最小单位 也就是CPU执行的最小单位
协程就是单线程下实现并发 在代码层面遇到io控制切换
一个应用程序运行至少有一个进程 一个进程下至少有一个线程
并行和并发
并行指的是同一时间内执行多个任务 目的是为了提高系统的执行效率 通常需要多个cpu或多核cpu参与
并发指的是一段时间内处理多个任务的能力 看起来像是在同时执行 目的是为了提高系统的响应性能
通常计算密集型用多进程 io密集型用多线程
网络编程
OSI七层协议
应用层
为应用程序提供服务 如http dns ftp等
表示层
表示处理数据的方式 如加密 压缩 转换数据格式等
会话层
负责建立管理和终止会话等 如管理会话标识符
传输层
负责数据的传输 如tcp udp port等协议都在这层
网络层
负责数据的路由和转发 如ip协议在这层
数据链路层
负责定义数据的格式和传输规则 并进行差错检测和纠正等 如以太网协议 mac地址等在这层
物理连接层
实际传输数据的硬件设备和物理介质 如电缆 光纤等
tcp和udp
tcp是一种面向连接的可靠协议 也叫流式协议 发送数据前需要先建立连接 并且有反馈机制
tcp协议需要三次握手建立连接和四次挥手断开连接
会产生黏包问题
解决方法有 1.消息定长 2.包尾加特殊标识符 3.包头加长度
udp是一种无连接的不可靠协议 数据传输不可靠并且没有确认机制 优点是速度快
http和https
http协议也叫超文本传输协议 包含请求首行 请求头 请求体 默认端口80
http的特点
基于请求响应
基于TCP协议作用于应用层之上
无连接
无状态
请求首行包含请求方式 请求地址和请求的http协议的版本号
请求头是以key value的组成方式 常见的请求头有
user-agent 标识客户端的类型及版本等
accept 指定客户端能够接收的内容类型
host 指定服务器的主机名和端口
referer 请求的来源url地址
cookie 传递保存在客户端中的cookie
x-forwarded-for 识别客户端真实的ip地址
content-type 指定请求体中数据的类型
请求体中包含要发送的数据
http常见的版本
0.9 最初的版本 功能简陋 只支持get请求
1.0 支持多种请求方式 每次tcp连接只能发送一个请求 默认是短连接的 可以声明keep-alive实现长连接
1.1 默认就是长连接 无需手动声明
2.0 出现了多路复用等特性 多路复用就是虽然1.x中有长连接 但是请求的发送也是串行的 多路复用可以并行的发送多个请求 提高对带宽的利用率
3.0 弃用了tcp协议 改为使用基于udp协议的quic协议来实现
https是安全的超文本传输协议 是基于http协议加上ssl或tls证书加密的 传输的数据是加密的 保证了传输的安全 默认端口443
git
git是一款代码版本管理软件 用来做版本管理 帮助开发者合并开发的代码 出现冲突会做提示
常用命令
git init 初始化本地仓库
git status 查看文件变化
git add . 提交到暂存区
git commit -m"" 将暂存区的文件提交为一个版本
git log 查看版本库版本信息
git reset --hard 回退到指定的版本
git config --global user.name 全局设置提交版本时的用户名 局部去掉--global即可
git config --global user.email 全局设置提交版本时的邮箱
分支合并命令
git branch 查看分支或创建分支 加-d是删除分支
git checkout 切换分支
git merge 合并分支
连接远程仓库命令
git remote add 添加远程仓库
git remote remove 删除远程仓库
git push 提交版本到远程仓库
git pull 拉取远程仓库的代码
克隆
git clone 克隆远程仓库的代码
查看指定文件在什么时候被动过
git blame
restful规范
1.保障数据的安全 使用https协议
2.接口带api标识
3.接口带版本信息
4.数据即资源 使用名词尽量不使用动词
5.资源操作方式由请求方式决定
6.请求地址中带过滤条件
7.响应中带状态码
8.返回信息中带连接
9.返回数据中带错误信息
10.不同请求返回的东西遵循规范
如get返回所有数据 post返回新增的数据 put返回修改的对象 del返回空
django相关
django是一款遵循MVC设计模式的web应用程序框架 但它其实也是MTV模式 是基于MVC模式的具体实现
执行原生sql 通过raw方法
django orm优化
批量创建时可以使用bulk_create 可以一次性插入多条数据
用values和value_list取自己需要的字段
用select_related和prefetch_related来查询可以一并查询出与之相关联的外键对象 从而减少数据库的查询次数 select_related是针对单个对象的关联查询 prefetch_related适用于多个对象的查询
drf相关
drf自动生成路由通过路由组件实现 视图类需要继承viewset及其子类才行 路由层中导入SimpleRouter来注册 这样就可以自动生成路由
action装饰器 在视图类的方法上添加该装饰器 可以自动生成路由(遵循上述规则)
jwt全称就是jsonwebtoken 通常用来在客户端和服务端之间传递身份信息或其他基本信息
由三部分组成
头部 声明加密算法等信息
荷载 实际传输的信息 如用户id 用户名等
签名 是由头部和荷载加上秘钥通过加密得到的
可以有效防止数据被篡改或伪造 后端会根据jwt的签名来验证 如果通过则请求合法 反之不合法
认证组件 假设有些接口需要登录才能够访问 那么就需要用到认证组件
1.写一个认证类 继承BaseAuthentication
2.重写authenticate方法 编写相关逻辑
3.认证通过返回当前用户和token
4.不通过抛出AuthenticationFailed异常
权限组件 假设有些接口需要有一定的权限才能够访问 就可以用到权限组件
1.自定义权限类 继承BasePermission
2.重写has_permission方法 实现权限的认证
3.有权限返回True 反之False
频率组件 通常用于控制接口访问的频率
1.自定义频率类 继承SimpleRateThrottle
2.重写get_cache_key方法 返回什么就以什么做限制
3.类中配置属性scope
4.配置文件中配置
过滤
可以使用内置的过滤类 指定字段做模糊匹配 url中只能用search做key值
使用第三方如django-filter 指定字段完整匹配
自定义过滤类
1.自定义一个过滤类 继承BaseFilterBackend
2.重写filter_queryset方法
3.携带条件返回对应结果 没携带返回所有数据
django实现数据库读写分离
配置中配置多个数据库
新建个py文件写一个类
定义两个方法 db_for_read和db_for_write
配置文件中增加配置DATABASE_ROUTERS指向自己写的类
实现了自动的读写分离
也可以手动指定 使用using方法
mysql相关
mysql中有哪些日志
MySQL数据库中有以下几种日志:
1. 二进制日志(Binary Log):二进制日志是MySQL中最重要的日志之一。它记录了对数据库的修改操作,包括插入、更新和删除等操作。二进制日志以二进制格式存储,可以用于数据恢复、主从复制以及数据库的备份和恢复。
2. 事务日志(Transaction Log):事务日志也称为回滚日志或重做日志(Redo Log)。它记录了事务的修改操作,在事务提交之前,将修改的数据记录到事务日志中,以确保在数据库崩溃或故障发生时能够恢复数据的一致性。
3. 错误日志(Error Log):错误日志记录了MySQL服务器在运行过程中产生的错误和警告信息,包括数据库启动、连接问题、查询错误等。错误日志对于排查和解决数据库问题非常有用。
4. 查询日志(Query Log):查询日志记录了MySQL服务器收到的所有查询语句,包括SELECT、INSERT、UPDATE、DELETE等操作。查询日志可以用于分析查询性能和跟踪查询执行情况。
5. 慢查询日志(Slow Query Log):慢查询日志记录了执行时间超过阈值的查询语句。它可以帮助开发人员和管理员找出执行效率低下的查询,以便进行性能优化。
6. 更新日志(Update Log):更新日志记录了数据表的修改操作,包括INSERT、UPDATE和DELETE等操作。更新日志主要用于MySQL复制和主从同步。
这些日志在MySQL中提供了丰富的信息,对于数据库的管理、维护、故障恢复和性能优化都起着重要的作用。可以根据具体需求和情况,开启或关闭不同的日志,并根据日志内容进行分析和处理。
mysql主从
步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
redis相关
五大数据类型
字符串
列表
集合
哈希
有序集合
持久化方案
rdb
在指定条件成立的情况下 会将成立时的所有数据做快照 生成一个rdb文件 数据容易丢失
aof
客户端每写入一条命令 就会记录一条日志 数据不容易丢失
aof重写 随着命令的逐步写入 aof文件会越来越大 所以可以通过aof重写来解决 在配置文件中配置即可 本质就是把过期的 无用的重复的命令做优化 减少磁盘占用量
混合持久化
rdb和aof可以同时开启 也是在配置文件中配置
redis开启事务
开启事务命令 multi
提交事务 exec
可以通过管道pipline实现 把命令放进管道中 然后通过调用execute方法依次执行所有的命令 原理就是要么一次性都执行要么都不执行
主从复制
是一种数据复制的架构
为了解决容量瓶颈 机器故障 qps瓶颈等
实现了读写分离 可以提高并发量 做数据备份 一主可以有多从 但是一从只能有一个主
redis通过slaveof命令来实现主从 发送该命令的是从
哨兵模式
哨兵是redis官方提供的高可用性的解决方案 监控主从复制的状态 当主节点出现故障的时候 哨兵会自动将一个从节点升级为主节点 并通知其他从节点切换主节点 当原先主节点恢复 会变成从节点
集群
将多个独立的计算机或服务组合在一起以提供高可用性 高性能和容错能力的方式 之间通过网络相互通信和协作
数据库多机数据分布方案
哈希分布 hash分区 节点取余
顺序分布 如总共有100个数据 将1~33的存到第一台 34~66的存到第二台 剩下的第三台
redis使用了虚拟槽 总共16384个槽(0~16383) 搭建集群后每个节点存储指定槽的数据
redis中过期数据如何删除
redis会自动将过期的数据删除 但redis默认是惰性删除 也就是需要再次访问过期数据才会删除 可以通过配置文件设置activedefrag为yes 来启用主动过期删除机制
当缓存数据过多时 如何解决(缓存淘汰策略)
1.LRU 即最近最少使用的优先被淘汰
2.LFU 即不经常使用的会被优先淘汰
3.FIFO 即先进先出 按照缓存进入的顺序进行淘汰
4.LRU-K 即基于最近使用和访问频率来淘汰
5.Random 即随机淘汰
6.TTL 即过期的数据会被淘汰
7.Size-based 即基于大小淘汰 占用大的优先淘汰
还有一种就是结合持久化机制使用 将热点数据但不常更新的数据持久化 这样就不会占用缓存数据库的内存了
缓存穿透
缓存穿透指的是缓存和数据库中都没有的数据 而用户不断发起请求 这时的用户可能就是攻击者 会导致数据库的压力过大
解决方案:
接口层做校验
将缓存和数据库都取不到的数据存入缓存 value为null有效时间设得短一些 可以防止用户反复对一个数据查取的攻击
布隆过滤器
缓存击穿
缓存击穿指的是一个存在于缓存中的数据在过期的同时又恰好被并发的发送大量的请求 导致请求直接绕过缓存访问数据库引起数据库压力骤增 甚至导致宕机
解决方案:
设置热点数据永不过期 或过期时间特别长
缓存中使用互斥锁 保证过期的同时只有一个请求
缓存雪崩
缓存雪崩指的是在缓存中有大量的数据具有相同的过期时间 过期的同时又大量的请求同时落到数据库上 造成数据库瞬时压力过大 甚至导致宕机等现象
解决方案:
将缓存过期时间随机
使用二级缓存 将数据分散到多个不同的缓存中
服务端限制并发请求数量
docker相关
docker和虚拟机VM的区别
1.资源消耗 docker更轻量级 虚拟机需要完整的模拟出一个虚拟硬件平台
2.启动速度 docker启动更快
3.隔离性不同
4.架构不同 docker是操作系统级别 虚拟机是硬件级别
是一种容器化管理平台 容器是一种轻量化的虚拟化技术 将应用程序及其依赖打包到一个独立的容器中 使它可以在不同的计算机上运行 无需担心环境差异或依赖问题
docker镜像就是装了操作系统又装了一些软件的一堆文件
docker容器 镜像运行起来就成为了容器
类比:类和对象 镜像就相当于类 容器就相当于对象 每个镜像都会有些基础软件和配置 创建出来的容器都会有 并且容器是由镜像运行产生 容器可以给自己添加独有的软件等 和类和对象的概念类似
docker常用命令
启动 systemctl start docker
停止 systemctl stop docker
开机自启 systemctl enabl docker
拉取镜像 docker pull
查看本地镜像 docker images 加-q只查看id
删除镜像 docker rmi id
查看运行的容器 docker ps -a查看所有 -l 查看最后一次运行的
运行容器 docker run
-id 不自动进入容器
-it 自动进入容器
--name 容器名
-v 目录映射 宿主机目录:容器目录
-p 端口映射 宿主机端口:容器端口
启动容器 docker start
进入容器 docker exec
文件拷贝
容器拷贝到宿主机 docker cp 容器id:容器目录 要拷贝的文件
宿主机拷贝到容器 docker cp 要拷贝的文件 容器id:容器目录
删除容器 docker rm 容器id
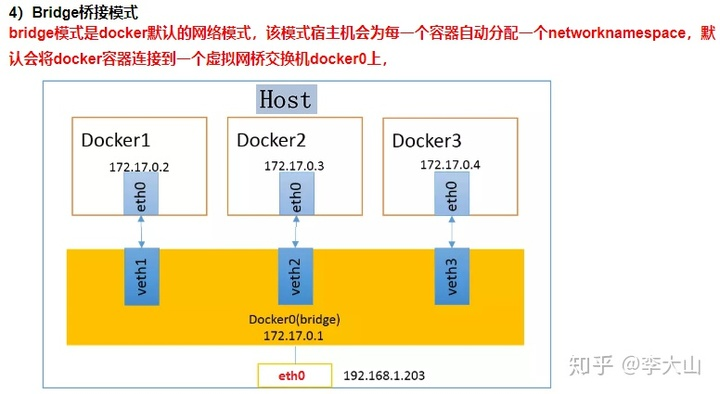
docker run创建Docker容器时,可以用 --net 选项指定容器的网络模式 :
host模式:使用 --net=host 指定。
none模式:使用 --net=none 指定。
bridge模式:使用 --net=bridge 指定,默认设置。
container模式:使用 --net=container:NAME_or_ID 指定

dockerfile
是用于构建docker镜像的文本文件
FROM 基础镜像
MAINTAINER 作者
ENV 环境变量
RUN 执行的命令
WORKDIR 容器的工作目录
CMD 启动容器执行的命令 只生效最后一条
ENTRYPOINT 和CMD一样 不过所有的都会执行
ADD 将本地的文件拷贝到镜像中
EXPOSE 对外暴露的端口
通过docker build -t="镜像名" 来构建镜像
一个docker镜像由多个层构成 通常由多个只读层和一个可读写层组成 镜像分层存储的设计可以使得多个镜像可以共享同一个基础层 从而节省存储空间 但是当dockerfile中执行run命令后会创建一个新的层 没执行一次都会创建一层 所有应当合并多条run命令为一条 避免导致过度使用run命令导致镜像变得臃肿和庞大 而CMD命令的执行并不会产生新的一层
docker compose
是一个能一次性定义和管理多个docker容器的工具 通过yml文件来配置
docker-compose up
celery相关
先导入celery库 实例化出一个对象 需要制定一个名称 一个消息代理和一个结果存储地址
再定义任务函数 使用@app.task装饰器装饰 函数需要返回结果
启动celery celery -A应用名 worker -l info
后续通过任务函数.delay方法执行该异步任务即可
Celery 的架构一般被认为是三层的,由以下组件构成:
客户端:客户端负责创建任务,并将任务发送到消息代理(Message Broker)中。Celery 提供了多种客户端,如 Python API、Django 应用程序、命令行工具等。
消息代理:消息代理负责接收客户端发送的任务,并将任务分发给工作者(Worker)。Celery 支持多种消息代理,如 RabbitMQ、Redis、Amazon SQS 等。
工作者:工作者负责处理任务,并将处理结果返回给消息代理。Celery 支持多种工作者类型,如本地进程、分布式进程、协程等。
起定时任务
编写任务函数
配置定时任务的调度规则 通过crontab方法配置多久执行一次
起worker进程
起beat进程
RabbitMQ相关
是一种开源的消息中间件 支持持久化 传输确认 发布确认等 支持集群 具有灵活的分发消息策略 并且自身提供了一个易用的用户界面
解决了应用解耦 提升了系统的可用性 实现了流量的削峰 消息分发和可以实现进程间通信
有六种模式
hello word模式
简单说就以一个存 一个取
工作队列 work queues
任务队列模式 一个消息队列允许多个消费者从中获取
发布订阅 publish
创建交换机的时候exchange_type为fanout 多个消息队列从交换机中获取数据
会将一个消息同时发送给多个订阅者
路由 routing
创建交换机的时候exchange_type为direct
指定routing_key完整匹配
可以指定将该条消息给哪个消息队列
主题 topics
创建交换机的时候exchange_type为topics
指定routing_key模糊匹配
模糊匹配将该条消息给匹配成功的消息队列
远程调用 rpc
持久化
创建队列的时候传入durable=True参数 就可以将该消息队列持久化
生产者传入消息的时候指定properties参数 也可以将该条消息持久化
闲置消费
如果有多个消费者 是按照顺序依次将消息给消费者 但如果有一个消费者处理消息很耗时 那么就可以设置闲置消费
消费者调用basic_qos方法
确保消息安全有ack确认机制 配置auto_ack=False 写一个回调函数 当取到消息后会触发 内部调用确认basic_ack取走消息方法
Pandas相关
Pandas Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数含义:
data:一组数据(ndarray 类型)。
index:数据索引标签,如果不指定,默认从 0 开始。
dtype:数据类型,默认会自己判断。
name:设置名称。
copy:拷贝数据,默认为 False
传入一个列表那么列表中的单个数据就为值
取值直接通过series的返回值跟列表一样按照索引取对应值
示例:
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar["y"])
传入一个字典 那么key就是索引 value为值
示例:
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
如果只需要字典中的一部分值 只需要执行index参数传入需要的索引即可
示例:
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)
Pandas DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
构造如下
pandas.DataFrame( data, index, columns, dtype, copy)
参数:
data:一组数据(ndarray、series, map, lists, dict 等类型)
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n)
dtype:数据类型。
copy:拷贝数据,默认为 False
使用列表套列表创建
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
使用ndarrays创建(numpy中的对象)
# 列标签就site和age 每行的数据按照列表中的顺序依次 每列的数据个数必须相等 否则报错
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
使用列表套字典创建
# 列标签就是每个小字典的key值 行数据就是value值 没有对应的部分数据为NaN
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
可以使用loc属性返回指定行的数据 根据行索引
# 使用默认行索引
print(df.loc[0])
# 使用自定的行索引
print(df.loc['x'])
# 返回多行数据
print(df.loc[[0, 1]])
Pandas CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用
读取CSV文件
df = pd.read_csv('nba.csv')
将读取的CSV文件返回为DataFrame类型数据 不使用该函数返回前五行和末五行 中间部分以...代替
df.to_string()
将DataFrame类型数据转为CSV文件
to_csv()
head(n) 方法用于读取前面的 n 行,如果不填参数n,默认返回5行。
tail(n) 方法用于读取尾部的 n 行,如果不填参数n,默认返回5行,空行各个字段的值返回NaN。
info() 方法返回表格的一些基本信息
Pandas JSON
read_json() 读取json文件 可以是文件也可以是url地址
如果有内嵌的json数据 不能直接读取
这时我们就需要使用到 json_normalize() 方法将内嵌的数据完整的解析出来
示例:
json_normalize(data, record_path=['内嵌的key值'], meta=['除内嵌数据外要展示的其他元素'])
详细查看: https://www.runoob.com/pandas/pandas-json.html
Pandas 数据清洗
1.清洗空值
dropna() 清洗空值 默认返回一个新DataFrame对象
isnull() 判断各个单元格是否为空
fillna() 替换一些空字段
mean() 计算列均值(所有值加起来的平均值)
median() 计算中位数值(排序后排在中间的数)
mode() 众数(出现频率最高的)
读取csv文件的时候 可以传na_values 指定空数据类型
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数:
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
thresh:设置需要多少非空值的数据才可以保留下来的。
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
2.清洗格式错误数据
pandas.to_datetime() 格式化日期
3.清洗错误数据
DataFrame对象.index可以获取行索引 可以通过for循环它 给每行数据做一些清洗
4.清洗重复数据
duplicated() 返回True或False 重复的为True
drop_duplicates() 直接删除重复的数据 默认不影响原来的 可以指定inplace参数
Pandas 常用函数
详细查看: https://www.runoob.com/pandas/pandas-functions.html
sqlalchemy相关
简单使用
导入
生成引擎对象
引擎对象点raw_connection方法获取连接
连接对象点cursor方法获取游标
游标对象点execute方法执行原生sql语句
创建和操作数据表
1.创建表
导入declarative_base生成一个基类
模型类继承基类
写字段用column函数起来 并传入字段类型
常用数据类型
Interger 整型
String 字符串
Float 浮点型
DECIMAL 定点型
Boolean 布尔型
Date 日期
Text 文本类型
Enum 枚举类型
__tablename__指定表名
__table_args__建立索引
通过基类并传入引擎对象来把表同步到数据库
Base.metadata.create_all(引擎对象)
2.插入数据
导入sessionmaker并绑定引擎对象生成session类并实例化得到一个session对象
使用模型类传入字段生成对象
session对象点add传入模型类对象
commit提交
close关闭
session对象是全局的 可能有线程安全问题 所以可以使用scoped_session对象来创建
想要生成线程是安全的,可以使用内部的local对象,取代当前线程的session,如果当前线程中有local那么就直接使用
基本的增删改查
1.查
filter中写表达式
filter_by直接写等式 也就是传参的形式
session对象.query(指定模型表)
.all() 取出所有 返回一个普通列表 如果不加all那么返回执行的sql语句
.first() 取出第一个
也可以执行查询指定字段 直接模型类.字段即可
可以使用text函数 使用字符串的形式查询 可以以:参数的形式占位等待传参
然后.params传入占位的参数
from_statement方法可以执行原生sql语句
2.增
add 增加单个对象
add_all 增加多个对象 列表形式
3.删
filter或filter_by查询的结果不点all或first直接点delete即可删除 会返回影响的行数
4.改
update 以字典的形式 传入字段名及新值
使用对象 直接将查询到的对象点字段等于新值再session.add即可
内部通过判断有没有主键来区分 如果有就是修改 没有就是新增
高级查询
1.查询条件中逗号隔开默认是and关系
2.范围查询
使用filter查询 模型类点字段后再点between即可查找指定范围内的数据
如 res = session.query(Book).filter(Book.id.between(1,9)).all()
3.in条件查询
同理 但in是python中的关键字 所以换成 in_
res = session.query(Good).filter(Good.id.in_([1,3,5])).all()
4.与或非查询
非直接在查询条件前加~
res = session.query(Good).filter(~Good.id.in_([1,3,5])).all()
与使用or_方法
res = session.query(Good).filter(or_(Good.id>1,Good.name=='phone')).all()
5.模糊查询
和条件点like搭配使用
%表示匹配任意长度的任意字符
_表示匹配任意单个字符
[]表示匹配指定字符集中的任意一个字符
[^]表示匹配除指定字符集外的任意一个字符
6.分页
# 一页放3条数据,查第7页
# 条 t 页 s
# [t*s:t*s+t]
res = session.query(Good)[3 * 7:3 * 7 + 3]
7.排序
点order_by方法
排序字段.desc() 降序
排序字段.asc() 升序
8.分组查询
group_by(分组的字段)
9.分组后过滤
having(过滤条件)
执行原生sql
方式一:
导入
生成引擎对象
引擎对象点raw_connection方法获取连接
连接对象点cursor方法获取游标
游标对象点execute方法执行原生sql语句
方式二:
导入
生成引擎对象
生成Session类 并绑定引擎
产生session对象
session.execute(text('原生sql'), params={'参数名':'值'})
一对多的表模型关系建立
relationship跟数据库无关,不会新增字段,只用于快速连表操作,backref用于反向查询
# 一对多关系
from sqlalchemy import create_engine
import datetime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
from sqlalchemy.orm import relationship
# 第二步:执行declarative_base,得到一个类
Base = declarative_base()
class Hobby(Base):
__tablename__ = 'hobby'
id = Column(Integer, primary_key=True)
caption = Column(String(50), default='篮球')
class Person(Base):
__tablename__ = 'person'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
# hobby指的是tablename而不是类名
# 关联字段写在多的一方,写在Person中,跟hobby表中id字段做外键关联
hobby_id = Column(Integer, ForeignKey("hobby.id"))
# 跟数据库无关,不会新增字段,只用于快速链表操作
# 基于对象的跨表查询:就要加这个字段,取对象 person.hobby pserson.hobby_id
# 类名,backref用于反向查询
hobby = relationship('Hobby', backref='pers') # 如果有hobby对象,拿到所有人 hobby.pers
def __repr__(self):
return self.name
engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/aaa", )
# 把表同步到数据库 (把被Base管理的所有表,都创建到数据库)
Base.metadata.create_all(engine)
# 把所有表删除
# Base.metadata.drop_all(engine)
多对多的表模型创建
relationship跟数据库无关,不会新增字段,只用于快速连表操作,backref用于反向查询
第三张表手动建立 secondary指定第三张关联表
# 多对多关系
from sqlalchemy import create_engine
import datetime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
from sqlalchemy.orm import relationship
# 第二步:执行declarative_base,得到一个类
Base = declarative_base()
# 中间表 手动创建
class Boy2Girl(Base):
__tablename__ = 'boy2girl'
id = Column(Integer, primary_key=True, autoincrement=True)
girl_id = Column(Integer, ForeignKey('girl.id'))
boy_id = Column(Integer, ForeignKey('boy.id'))
class Girl(Base):
__tablename__ = 'girl'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
def __str__(self):
return self.name
def __repr__(self):
return self.name
class Boy(Base):
__tablename__ = 'boy'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64), unique=True, nullable=False)
# 与生成表结构无关,仅用于查询方便,放在哪个单表中都可以
# 方便快速查询,写了这个字段,相当于django 的manytomany,快速使用基于对象的跨表查询
girls = relationship('Girl', secondary='boy2girl', backref='boys')
def __str__(self):
return self.name
def __repr__(self):
return self.name
engine = create_engine("mysql+pymysql://root@127.0.0.1:3306/aaa", )
# 把表同步到数据库 (把被Base管理的所有表,都创建到数据库)
Base.metadata.create_all(engine)
连表查询
使用join方法 默认是inner join 自动按照外键关联 可以指定isouter参数来表示左连接
session.query(模型类).join(模型类)
可以指定on条件 也就是连表条件
session.query(模型类).join(模型类, 连表条件)
或者也可以
session.query(模型类1, 模型类2).filter(模型类1连表的字段 == 模型类2连表的字段)
Flask相关
简单使用
from flask import Flask
app = Flask(__name__)
# 注册路由---->装饰器
@app.route('/index')
def index():
return 'hello web'
@app.route('/')
def home():
return 'hello home'
if __name__ == '__main__':
app.run()
基础知识
四件套
render_template 渲染模板 跟django有区别
redirect 重定向
return 字符串 返回字符串
jsonify 返回json格式
请求的request对象是全局的 直接导入使用即可 不同的视图函数不会混乱
request.method 请求方式
request.form 将post请求body体的内容转换成了字典
session对象也是全局的 需要指定秘钥
举例
app.secret_key = 'aiwnlnef'
放值 session['键'] = '值'
取值 session.get('键')
转换器
举例
@app.route('/index/<int:pk>')
常用的:
string(默认转换器):将参数转换为字符串。
int:将参数转换为整数
float:将参数转换为浮点数
path:将参数转换为字符串,包括路径中的斜杠
uuid:将参数转换为UUID(通用唯一标识符)对象
配置文件的几种方式
方式一:一般测试用
app.debug = True
app.secret_key = 'ieoanweofn'
只支持这两个
方式二:使用app.config设置
app.config['DEBUG'] = True
...
方式三:使用py文件
app.config.from_pyfile('py文件路径')
方式四:使用类的形式
app.config.from_object('类名')
方式五:通过环境变量配置
app.config.from_envvar('环境变量名')
方式六:json文件的形式
app.config.from_json('json文件名')
方式七:字典形式---》配置中心
app.config.from_mappint({'DEBUG': True})
路由
本质其实就是 app.add_url_rule('/', endpoint=None, view_func=视图函数, methods=[请求方式])
add_url_rule中的参数
rule URL规则
view_func 视图函数名称
defaults = None 默认值, 当URL中无参数,函数需要参数时 以字典形式
endpoint = None, 路径的别名,名称,用于反向解析URL,即: url_for('名称')
methods = None, 允许的请求方式,如:["GET", "POST"]
strict_slashes 对URL最后的 / 符号是否严格要求
redirect_to 重定向到指定的地址
视图类
继承MethodView 类中写跟请求方式同名的方法即可
然后手动注册路由
想要给视图类加装饰器
类属性decorators = [装饰器,]
内部原理和django类似 都是通过获取请求方式 从视图类中反射出对应的视图函数
1 as_view 执行流程跟djagno一样
2 路径如果不传别名,别名就是函数名(endpoint)
3 视图函数加多个装饰器(上下顺序和必须传endpoint)
4 视图类必须继承MethodView,否则需要重写dispatch_request
5 视图类加装饰器:类属性decorators = [auth,]
请求与响应
from flask import Flask, request, make_response,render_template
app = Flask(__name__)
app.debug = True
@app.route('/', methods=['GET', 'POST'])
def index():
#### 请求
# request.method 提交的方法
# request.args get请求提及的数据
# request.form post请求提交的数据
# request.values post和get提交的数据总和
# request.cookies 客户端所带的cookie
# request.headers 请求头
# request.path 不带域名,请求路径
# request.full_path 不带域名,带参数的请求路径
# request.script_root
# request.url 带域名带参数的请求路径
# request.base_url 带域名请求路径
# request.url_root 域名
# request.host_url 域名
# request.host 127.0.0.1:500
obj = request.files['file']
obj.save(obj.filename)
### 响应 四件套
# 1 响应中写入cookie
# response = 'hello'
# res = make_response(response) # flask.wrappers.Response
# print(type(res))
# res.set_cookie('xx','xx')
# return res
# 2 响应头中写数据(新手四件套,都用make_response包一下)
response = render_template('index.html')
res = make_response(response) # flask.wrappers.Response
print(type(res))
res.headers['yy']='yy'
return res
if __name__ == '__main__':
app.run()
session
原理是响应的时候,把session中的值加密 写入cookie中 返回到浏览器 下次请求来的时候携带这个cookie解密 然后重新赋值给session
闪现
作用:
跨请求来保存数据
当次请求 访问出错 被重定向到其他地址 重定向到这个地址后 可以拿到当时的错误
设置闪现
flash(值) 可以设置多次 放到列表中
flash(值, category='debug') 分类存
获取闪现
get_flashed_messages() 取完就删除
get_flashed_messages(category_filter=['debug']) 分类取
请求扩展
请求扩展中 在请求来了 或者请求走了 可以绑定一些函数 到这里就会执行对应函数 类似于django的中间件
before_request:请求来了会走,如果他返回了四件套,就结束了
after_request :请求走了会走,一定要返回response对象
before_first_request:第一次来了会走
teardown_request:无论是否出异常,会走
errorhandler:监听状态码,404 500
template_global:标签
template_filter:过滤器
蓝图
之前在一个py中写flask项目,后期需要划分项目 蓝图的作用就是组织和构建大型应用程序的方法 将项目分解为更小 更可管理的模块 每个模块都具有自己的路由视图等
使用
1.导入蓝图类 并实例化得到蓝图对象
shop_bp = Blueprint('shop', __name__)
2.app中注册蓝图
app.register_blueprint(shop_bp, url_prefix='路由前缀')
每个蓝图在注册的时候可以有前缀 但是必须以/开头
3.在不同的视图中 用对应的蓝图注册路由
g对象
在flask框架中 使用g对象 可以在整个请求的全局可以放值可以取值 相当于其他框架中的context上下文
可以在全局的位置任意导入使用 其实也可以用request但是它内置了很多变量 容易造成数据污染
g对象和session对象的区别 g对象只针对于当次请求 session对象针对的是多次请求
信号
信号是一种时间处理机制 可以让应用程序中不同的部分进行通信
## 使用内置信号
第1步:写一个函数,由于信号触发时,会自动传入一些参数,所以该函数的参数最好写成 *args, **kwargs
第2步:绑定内置信号
before_render_template.connect(函数)
第3步:等待被触发
## 自定义信号的步骤
第1步:自定义一个信号
导入
from flask.signals import _signals,
自定义信号
xxx=_signals.signal('xxxx')
第2步:写一个函数,由于是自定义的函数,所以要传入什么参数需要我们定义
第3步:将函数绑定给自定义的信号
自定义信号.connect(函数)
第4步:编写函数触发的位置
自定义信号.send(有参数传参数)
flask请求生命周期
1.客户端发送请求
2.请求到达 经过web网关 将http请求封装成request对象 并找到要调用的视图函数
3.请求上下文创建
4.预处理 如请求扩展中的before_request
5.到对应视图函数处理请求并返回响应
6.响应处理 如请求扩展中的after_request
7.发送返回响应给客户端
8.请求上下文销毁

 浙公网安备 33010602011771号
浙公网安备 33010602011771号