
Flink-JAVA开发.03-开发一个自定义的表连接器
特别申明:讨论的是表连接器,或者说是org.apache.flink.table.factories.Factory的实现类
一、前言
当我们使用表和不是使用流来处理数据的时候,常常面临一个问题:系统默认的连接器不够用。
在2.0版本中 ,文档提到系统提供了以下连接器:
https://nightlies.apache.org/flink/flink-docs-release-2.0/docs/connectors/table/overview/
| Name | Version | Source | Sink |
|---|---|---|---|
| Filesystem | Bounded and Unbounded Scan | Streaming Sink, Batch Sink | |
| Elasticsearch | 6.x & 7.x | Not supported | Streaming Sink, Batch Sink |
| Opensearch | 1.x & 2.x | Not supported | Streaming Sink, Batch Sink |
| Apache Kafka | 0.10+ | Unbounded Scan | Streaming Sink, Batch Sink |
| Amazon DynamoDB | Not supported | Streaming Sink, Batch Sink | |
| Amazon Kinesis Data Streams | Unbounded Scan | Streaming Sink | |
| Amazon Kinesis Data Firehose | Not supported | Streaming Sink | |
| JDBC | Bounded Scan, Lookup | Streaming Sink, Batch Sink | |
| Apache HBase | 1.4.x & 2.2.x | Bounded Scan, Lookup | Streaming Sink, Batch Sink |
| Apache Hive | Supported Versions | Unbounded Scan, Bounded Scan, Lookup | Streaming Sink, Batch Sink |
| MongoDB | 3.6.x & 4.x & 5.x & 6.0.x | Bounded Scan, Lookup | Streaming Sink, Batch Sink |
这些连接器能够满足大部分业务场景,涵盖文件系统,日志系统,流,jdbc,一些大数据。
除了亚马逊的两个,其它的都支持流式写入和批处理写入。
只不过有时候,个性化的需求还是存在的。
例如:
1.你可能想从excel,JSON文件中读取数据
2.你可能想在写入目标库之前先执行一些其它操作,例如删除数据,获取truncate目标表
3.你可能需要对接一些国产的数据库
二、指定一个完整的表连接器
2.1、简介
一个标准的连接器,需要实现两个接口,如下图:
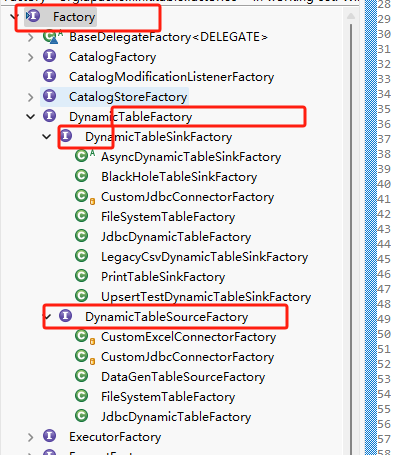
这两个接口分别是:
org.apache.flink.table.factories.DynamicTableSourceFactory
org.apache.flink.table.factories.DynamicTableSinkFactory
前者用于读取数据,后者用于输出数据
DynamicTableSourceFactory的核心方法
DynamicTableSource createDynamicTableSource(Context context);DynamicTableSinkFactory的核心方法
DynamicTableSink createDynamicTableSink(Context context);
然而创建一个自定义的连接器,并不容易,并不是简单实现两个接口即可,其实还需要实现一堆乱七八糟的附件!
2.2、实现一个简单的jdbc表连接器
如下图,这是一个简单的自定义jdbc表连接器所包含的类:
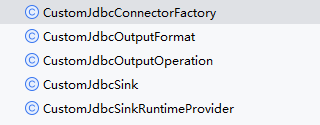
其中CustomJdbcConnectorFactory是入口主类。
| 类 | 主要功能 | 备注 |
| CustomJdbcConnectorFactory | 实现读取和写入的两个接口。分别实现DynamicTableSourceFactory DynamicTableSinkFactory,前者负责数据读取,后者负责数据的输出。 |
对DynamicTableSourceFactory的实现完全是赋值Flink已有的代码 |
| CustomJdbcSink | 实现数据的输出。实现接口DynamicTableSink, SupportsRowLevelDelete | 主要是关联CustomJdbcSinkRuntimeProvider |
| CustomJdbcSinkRuntimeProvider | 实现OutputFormatProvider接口,关联
CustomJdbcOutputFormat |
|
| CustomJdbcOutputFormat | 实现接口OutputFormat,并关联CustomJdbcOutputOperation | |
| CustomJdbcOutputOperation | 实现数据的输出和删除 |
2.2.1类关系图

2.2.2 部分实现说明
虽然是简单的实现,但是代码也不少 ,涉及到5个类文件,实现6个接口,这还是在简化了source实现的前提下。
这里关键说明两个:CustomJdbcConnectorFactory,CustomJdbcOutputOperation
CustomJdbcConnectorFactory
此工厂实现了数据读取和写入工厂两个接口,实现代码如下:
public class CustomJdbcConnectorFactory implements DynamicTableSinkFactory, DynamicTableSourceFactory {
private static final ConfigOption<String> DRIVER_CLASS = ConfigOptions.key("driver-class").stringType().noDefaultValue();
private static final ConfigOption<String> URL = ConfigOptions.key("url").stringType().noDefaultValue();
private static final ConfigOption<String> TABLE_NAME = ConfigOptions.key("table-name").stringType()
.noDefaultValue();
private static final ConfigOption<String> USERNAME = ConfigOptions.key("username").stringType().noDefaultValue();
private static final ConfigOption<String> PASSWORD = ConfigOptions.key("password").stringType().noDefaultValue();
//
private static final ConfigOption<String> IDCOLCODE = ConfigOptions.key("idColCode").stringType().noDefaultValue();
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
return this.createSink(context);
}
private DynamicTableSink createSink(Context context) {
DataType dataType=context.getPhysicalRowDataType();
final ReadableConfig options = FactoryUtil.createTableFactoryHelper(this, context).getOptions();
JdbcOptionRecord jdbcOptionRecord=new JdbcOptionRecord(
options.get(DRIVER_CLASS),
options.get(URL),
options.get(TABLE_NAME),
options.get(USERNAME),
options.get(PASSWORD),
options.get(IDCOLCODE),
dataType);
return new CustomJdbcSink(jdbcOptionRecord);
}
@Override
public String factoryIdentifier() {
return "cust-jdbc";
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
Set<ConfigOption<?>> options = new HashSet<>();
options.add(URL);
options.add(TABLE_NAME);
options.add(USERNAME);
options.add(PASSWORD);
options.add(IDCOLCODE);
options.add(DRIVER_CLASS);
return options;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
return Collections.emptySet();
}
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
final FactoryUtil.TableFactoryHelper helper =
FactoryUtil.createTableFactoryHelper(this, context);
final ReadableConfig config = helper.getOptions();
helper.validate();
validateConfigOptions(config, context.getClassLoader());
validateDataTypeWithJdbcDialect(
context.getPhysicalRowDataType(),
config.get(URL),
config.get(COMPATIBLE_MODE),
context.getClassLoader());
return new JdbcDynamicTableSource(
getJdbcOptions(helper.getOptions(), context.getClassLoader()),
getJdbcReadOptions(helper.getOptions()),
helper.getOptions().get(LookupOptions.MAX_RETRIES),
getLookupCache(config),
helper.getOptions().get(FILTER_HANDLING_POLICY),
context.getPhysicalRowDataType());
}
@Override
public Set<ConfigOption<?>> forwardOptions() {
return DynamicTableSinkFactory.super.forwardOptions();
}
@SuppressWarnings("deprecation")
private void validateConfigOptions(ReadableConfig config, ClassLoader classLoader) {
String jdbcUrl = config.get(URL);
JdbcFactoryLoader.loadDialect(jdbcUrl, classLoader, config.get(COMPATIBLE_MODE));
checkAllOrNone(config, new ConfigOption[] {USERNAME, PASSWORD});
checkAllOrNone(
config,
new ConfigOption[] {
SCAN_PARTITION_COLUMN,
SCAN_PARTITION_NUM,
SCAN_PARTITION_LOWER_BOUND,
SCAN_PARTITION_UPPER_BOUND
});
if (config.getOptional(SCAN_PARTITION_LOWER_BOUND).isPresent()
&& config.getOptional(SCAN_PARTITION_UPPER_BOUND).isPresent()) {
long lowerBound = config.get(SCAN_PARTITION_LOWER_BOUND);
long upperBound = config.get(SCAN_PARTITION_UPPER_BOUND);
if (lowerBound > upperBound) {
throw new IllegalArgumentException(
String.format(
"'%s'='%s' must not be larger than '%s'='%s'.",
SCAN_PARTITION_LOWER_BOUND.key(),
lowerBound,
SCAN_PARTITION_UPPER_BOUND.key(),
upperBound));
}
}
checkAllOrNone(config, new ConfigOption[] {LOOKUP_CACHE_MAX_ROWS, LOOKUP_CACHE_TTL});
if (config.get(LOOKUP_MAX_RETRIES) < 0) {
throw new IllegalArgumentException(
String.format(
"The value of '%s' option shouldn't be negative, but is %s.",
LOOKUP_MAX_RETRIES.key(), config.get(LOOKUP_MAX_RETRIES)));
}
if (config.get(SINK_MAX_RETRIES) < 0) {
throw new IllegalArgumentException(
String.format(
"The value of '%s' option shouldn't be negative, but is %s.",
SINK_MAX_RETRIES.key(), config.get(SINK_MAX_RETRIES)));
}
if (config.get(MAX_RETRY_TIMEOUT).getSeconds() <= 0) {
throw new IllegalArgumentException(
String.format(
"The value of '%s' option must be in second granularity and shouldn't be smaller than 1 second, but is %s.",
MAX_RETRY_TIMEOUT.key(),
config.get(
ConfigOptions.key(MAX_RETRY_TIMEOUT.key())
.stringType()
.noDefaultValue())));
}
}
@SuppressWarnings({ "rawtypes", "unchecked" })
private void checkAllOrNone(ReadableConfig config, ConfigOption<?>[] configOptions) {
int presentCount = 0;
for (ConfigOption configOption : configOptions) {
if (config.getOptional(configOption).isPresent()) {
presentCount++;
}
}
String[] propertyNames =
Arrays.stream(configOptions).map(ConfigOption::key).toArray(String[]::new);
Preconditions.checkArgument(
configOptions.length == presentCount || presentCount == 0,
"Either all or none of the following options should be provided:\n"
+ String.join("\n", propertyNames));
}
private static void validateDataTypeWithJdbcDialect(
DataType dataType, String url, String compatibleMode, ClassLoader classLoader) {
final JdbcDialect dialect = JdbcFactoryLoader.loadDialect(url, classLoader, compatibleMode);
dialect.validate((RowType) dataType.getLogicalType());
}
private InternalJdbcConnectionOptions getJdbcOptions(
ReadableConfig readableConfig, ClassLoader classLoader) {
final String url = readableConfig.get(URL);
final InternalJdbcConnectionOptions.Builder builder =
InternalJdbcConnectionOptions.builder()
.setClassLoader(classLoader)
.setDBUrl(url)
.setTableName(readableConfig.get(TABLE_NAME))
.setDialect(
JdbcFactoryLoader.loadDialect(
url, classLoader, readableConfig.get(COMPATIBLE_MODE)))
.setParallelism(readableConfig.getOptional(SINK_PARALLELISM).orElse(null))
.setConnectionCheckTimeoutSeconds(
(int) readableConfig.get(MAX_RETRY_TIMEOUT).getSeconds());
readableConfig.getOptional(DRIVER).ifPresent(builder::setDriverName);
readableConfig.getOptional(USERNAME).ifPresent(builder::setUsername);
readableConfig.getOptional(PASSWORD).ifPresent(builder::setPassword);
readableConfig.getOptional(COMPATIBLE_MODE).ifPresent(builder::setCompatibleMode);
getConnectionProperties(readableConfig)
.forEach((key, value) -> builder.setProperty(key.toString(), value.toString()));
return builder.build();
}
@SuppressWarnings("deprecation")
private LookupCache getLookupCache(ReadableConfig tableOptions) {
LookupCache cache = null;
// Legacy cache options
if (tableOptions.get(LOOKUP_CACHE_MAX_ROWS) > 0
&& tableOptions.get(LOOKUP_CACHE_TTL).compareTo(Duration.ZERO) > 0) {
cache =
DefaultLookupCache.newBuilder()
.maximumSize(tableOptions.get(LOOKUP_CACHE_MAX_ROWS))
.expireAfterWrite(tableOptions.get(LOOKUP_CACHE_TTL))
.cacheMissingKey(tableOptions.get(LOOKUP_CACHE_MISSING_KEY))
.build();
}
if (tableOptions
.get(LookupOptions.CACHE_TYPE)
.equals(LookupOptions.LookupCacheType.PARTIAL)) {
cache = DefaultLookupCache.fromConfig(tableOptions);
}
return cache;
}
private JdbcReadOptions getJdbcReadOptions(ReadableConfig readableConfig) {
final Optional<String> partitionColumnName =
readableConfig.getOptional(SCAN_PARTITION_COLUMN);
final JdbcReadOptions.Builder builder = JdbcReadOptions.builder();
if (partitionColumnName.isPresent()) {
builder.setPartitionColumnName(partitionColumnName.get());
builder.setPartitionLowerBound(readableConfig.get(SCAN_PARTITION_LOWER_BOUND));
builder.setPartitionUpperBound(readableConfig.get(SCAN_PARTITION_UPPER_BOUND));
builder.setNumPartitions(readableConfig.get(SCAN_PARTITION_NUM));
}
readableConfig.getOptional(SCAN_FETCH_SIZE).ifPresent(builder::setFetchSize);
builder.setAutoCommit(readableConfig.get(SCAN_AUTO_COMMIT));
return builder.build();
}
}
关键方法是:
createSink -- 创建输出实现
createDynamicTableSource -- 创建读取实现
requiredOptions -- 设置工厂的可定义参数
CustomJdbcOutputOperation
public class CustomJdbcOutputOperation implements Serializable {
private final Logger LOGGER = LoggerFactory.getLogger(getClass());
private static final long serialVersionUID = 1L;
private final JdbcOptionRecord jdbcOption;
public CustomJdbcOutputOperation(JdbcOptionRecord jdbcOption) {
this.jdbcOption = jdbcOption;
}
public void executeInsert(RowData row, DataType dataType) throws SQLException {
//注意:只适合少量数据处理
try (Connection conn = getConnection()) {
String sql = buildInsertSQL(row, dataType);
try (PreparedStatement stmt = conn.prepareStatement(sql)) {
bindParameters(stmt, row,dataType);
stmt.executeUpdate();
}
}
}
public void executeDelete(RowData row,DataType dataType) throws SQLException {
try (Connection conn = getConnection()) {
String sql = buildDeleteSQL(row);
Row newRow=this.toRow(row,dataType);
try (PreparedStatement stmt = conn.prepareStatement(sql)) {
// 绑定主键参数(假设第一个字段是主键)
if (row.isNullAt(0)) {
stmt.setObject(1, null);
} else {
Object fieldValue = this.getFieldValue(newRow, 0);
stmt.setObject(1, fieldValue);
}
LOGGER.info("删除表{}的旧数据",jdbcOption.tableName());
stmt.executeUpdate();
}
}
}
private String buildInsertSQL(RowData row, DataType dataType) {
StringBuilder sql = new StringBuilder("INSERT INTO ")
.append(this.jdbcOption.tableName())
.append(" (");
// 从dataType获取真实字段名
List<String> fieldNameList=DataType.getFieldNames(dataType);
int fieldCount = row.getArity();
for (int i = 0; i < fieldCount; i++) {
if (i > 0) {
sql.append(",");
}
String fieldName=fieldNameList.get(i);
sql.append(fieldName);
}
sql.append(") VALUES (");
for (int i = 0; i < fieldCount; i++) {
if (i > 0) {
sql.append(",");
}
sql.append("?");
}
sql.append(")");
return sql.toString();
}
private String buildDeleteSQL(RowData row) {
return "DELETE FROM " + this.jdbcOption.tableName()
+ " WHERE " +this.jdbcOption.idColCode()+" = ?";
}
private void bindParameters(PreparedStatement stmt, RowData row, DataType dataType) throws SQLException {
int fieldCount = row.getArity();
Row newRow=this.toRow(row,dataType);
for (int i = 0; i < fieldCount; i++) {
int pos = i + 1; // JDBC参数从1开始
if (row.isNullAt(i)) {
stmt.setObject(pos, null);
} else {
Object fieldValue =this.getFieldValue(newRow, i);
stmt.setObject(pos, fieldValue);
}
}
}
private Row toRow(RowData row, DataType dataType) {
RowRowConverter converter = RowRowConverter.create(dataType);
Row newRow=converter.toExternal(row);
return newRow;
}
private Object getFieldValue(Row row, int pos) {
return row.getField(pos);
}
private Connection getConnection() throws SQLException {
//注意:通常此处代码无意义,可以删除。因为JDBC驱动4之后,SPI是自动加载的,不需要手动注册。
//此处保留的原因是:因为已经写出来了
if (!StringUtils.isNotEmpty(this.jdbcOption.driverClass())) {
this.registerJdbcDriver(this.jdbcOption.driverClass());
}
return DriverManager.getConnection(
this.jdbcOption.url(),this.jdbcOption.userName(), this.jdbcOption.password());
}
private void registerJdbcDriver(String driverClass) {
try {
if (!isDriverLoaded(driverClass)) {
Class.forName(driverClass);
}
} catch (ClassNotFoundException e) {
LOGGER.error("Driver class not found: {}", driverClass);
}
}
private Boolean isDriverLoaded(String driverClass) {
Enumeration<Driver> drivers = DriverManager.getDrivers();
while (drivers.hasMoreElements()) {
Driver driver = drivers.nextElement();
if (driver.getClass().getName().equals(driverClass)) {
return true;
}
}
return false;
}
}
注意:这是一个比较低效的实现,可以应付一些简单的输出。
例如这里是一条记录就调用一次,这个效率之低下令人发指。
三、小结
在Flink的较高版本中,例如2.0之后,很多传统的简单实现都被标记为过时,这是一个很大的区别。
这意味着Flink2.x之后,很多的郎打式实现被抛弃了,而是让用户适当地使用实现类。
Flink那么做的原因,估计是郎打表达式并不利于调试和优化,毕竟java是java,不是javascript。
无论如何,Flink的确是一个不错的计算框架,尤其是要实时计算一些结果的时候。
本文来自博客园,作者:正在战斗中,转载请注明原文链接:https://www.cnblogs.com/lzfhope/p/19001219

 浙公网安备 33010602011771号
浙公网安备 33010602011771号