
Flink-JAVA开发.02-简单介绍Flink中的有关对象
本文只能简单罗列一些Flink的基本概念,无法也没有一一指出每个概念的涵义。
更多内容参见Flink的官方文档:
https://nightlies.apache.org/flink/flink-docs-release-1.20/
一、Flink的起源和简介
Apache Flink 起源于 2009 年德国柏林工业大学的一个研究项目 Stratosphere,这是一个由德国研究基金会资助的分布式数据处理平台研究计划。2014 年,该项目正式捐赠给 Apache 基金会,并更名为 Flink,在德语中意为“敏捷、快速”。
-
2014 年 3 月:成为 Apache 孵化器项目
-
2014 年 12 月:晋升为 Apache 顶级项目
-
2015 年起:阿里巴巴大规模采用 Flink,并基于其开发了内部版本 Blink
-
2019 年:阿里将 Blink 开源并合并入 Flink 主干,极大增强了 Flink 的 SQL 能力和性能
截止202506,Flink已经发布了2.0版本,直接从1.20跳到2.0版本。
2.0虽然没有革命性的创新,但是有了性能的极大提升和稳定性提升,并且逐渐统一编程为数据流和TableApi&sql。
二、Flink的核心能力
- 流批一体
- 能处理SQL
- 适配多种语言
- 开源并适配多种操作系统
三、Flink概貌和执行环境
Flink可以笼统表述如下:
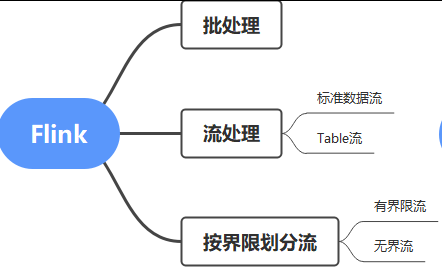
Flink由于能够处理流,也能处理RDBMS,所以除了计算,其实也非常适合作为ETL过程中的某个部件,例如抽取、轻度清洗、加载等。
如果愿意,也能够利用它的计算能力做一些数据库计算,虽然我不是很赞成那么做。
有界流和无界流
有界流-有停止时机的流,到了某个节点后就没有数据
无界流-没有明确停止时机的流,除非手动停止
例如如果你要计算今日花的钱,这是有界流;如果要计算某条河流的径流量,这大体算无界流。
执行环境
此外Flink非常体贴地提供了多个执行环境,以便开发和生产,这一点非常棒。
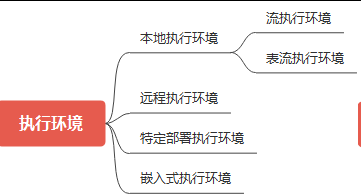
在学习和开发过程中,我们通常采用本地环境即可,这样简化和方便了学些和开发的负担,这一点很重要。
有了本地执行环境,一台笔记本电脑就能够完成相对简单的学习开发环境。
四、Flink数据流
数据流(DataStream)无疑是Flink的核心中的核心。
以流的方式处理数据,是一个很自然而然的想法,并不值得大书特书,但Flink的妙处在于采用了很多的细节,让流处理变得简单、灵活、高效。
例如要从树上采摘9999个珍贵的水果,不多也不少,为了提升效率,自然是一边摘一边计算,而不是摘完了再计算。道理就是这样,没有特别好说的。
数据流有关对象大体如下:
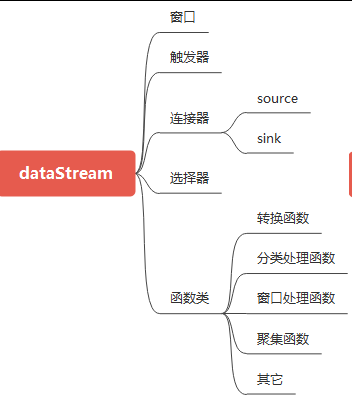
窗口分类
Flink处理数据的时候,需要用到一个窗口,窗口大体分两类:

窗口是一个逻辑的概念,并不是物理的。
FLink的数据流是基于时间窗口进行计算的。
4.1、时间分类
时间窗口和时间相关,而时间又可以划分为:
- 事件时间
- 处理时间
这个概念很重要,否则可能结果不如意。
1. 事件时间(Event Time)
- 定义:事件实际发生的时间,通常由数据本身携带(如日志中的时间戳、传感器记录的采集时间)。
- 特点:
- 与数据绑定:每个事件独立携带自己的时间戳,不受系统处理速度影响。
- 乱序容忍:支持处理延迟到达或乱序的数据(需配合水印机制)。
- 确定性结果:相同输入数据在不同运行环境下会产生相同的输出结果。
- 适用场景:
- 需要精确计算(如金融交易、用户行为分析)。
- 数据可能延迟或乱序到达(如物联网设备、分布式日志)。
2. 处理时间(Processing Time)
- 定义:事件被 Flink 处理时的系统时间(即当前时间戳)。
- 特点:
- 与系统绑定:依赖 Flink 任务所在机器的时钟。
- 实时性强:无需等待乱序数据,处理速度快。
- 非确定性结果:相同输入数据可能因系统负载、网络延迟等产生不同输出。
- 适用场景:
- 对实时性要求高且允许一定误差(如实时监控、告警)。
- 数据顺序严格有序(如实时仪表盘)。
3、关键区别对比
| 维度 | 事件时间(Event Time) | 处理时间(Processing Time) |
|---|---|---|
| 时间来源 | 数据自带的时间戳(如日志中的 timestamp 字段) |
Flink 处理时的系统时间(System.currentTimeMillis()) |
| 乱序处理 | 支持(通过水印机制) | 不支持(按到达顺序处理) |
| 延迟容忍 | 高(可等待延迟数据) | 低(立即处理,不等待) |
| 结果确定性 | 确定(相同输入必得相同输出) | 不确定(受系统状态影响) |
| 性能开销 | 较高(需维护水印、状态) | 低(直接处理) |
| 典型应用 | 财务审计、用户行为分析、延迟数据统计 | 实时监控、实时告警、近似计 |
4.2、水印和水印的用处
以下内容由ai整理,基本认同。
Flink 的水印(Watermark)是处理事件时间(Event Time)和乱序事件的核心机制,主要用于解决数据流中的延迟和乱序问题,确保计算结果的正确性和一致性。以下是水印的主要作用及其关键点:
1. 定义事件时间的进度
- 事件时间(Event Time):数据实际发生的时间(例如传感器记录的时间、用户点击时间)。
- 水印的作用:水印是一个时间戳,表示“所有事件时间小于等于该时间戳的数据都已到达”。例如,水印
T=10:00表示系统认为不会再有事件时间早于10:00的数据到来(或允许一定延迟)。
2. 触发窗口计算
- 窗口(Window):Flink 通常按时间或数据量划分窗口进行聚合计算(如每分钟统计一次点击量)。
- 水印如何触发窗口:
- 当水印的时间戳超过窗口的结束时间时,窗口会被触发计算。
- 例如,一个
[09:00, 10:00)的窗口,当水印到达10:00时,窗口会关闭并输出结果。
3. 处理乱序事件
- 乱序问题:由于网络延迟、分布式系统等原因,数据可能以乱序到达(例如
10:02的事件先到,10:01的事件后到)。 - 水印的容错机制:
- 水印允许一定的延迟容忍度(通过
allowedLateness参数设置)。 - 即使水印已触发窗口,后续到达的迟到数据(事件时间早于水印)仍会被处理(更新结果或侧输出到迟到数据流)。
- 水印允许一定的延迟容忍度(通过
4. 平衡延迟与结果准确性
- 水印生成策略:
- 周期性水印:定期生成水印(如每秒一次),适合实时性要求高的场景。
- 标点水印(Punctuated Watermark):由特定事件触发水印生成,适合有明确标记的数据流。
- 延迟控制:
- 水印生成越慢(等待更久),越能保证结果准确,但会引入更高延迟。
- 需根据业务需求调整水印策略(如设置最大延迟时间)。
5. 与处理时间(Processing Time)的对比
- 处理时间:按数据到达 Flink 的时间计算,无法处理乱序或延迟数据。
- 事件时间 + 水印:基于数据自带的时间戳,通过水印控制计算进度,更适合需要精确结果的场景(如财务统计、用户行为分析)。
示例场景
假设一个电商平台的点击流分析:
- 事件时间:用户点击商品的时间(如
10:00:01)。 - 水印设置:允许最多 5 秒的延迟(
allowedLateness=5s)。 - 窗口计算:每分钟统计一次点击量(
[10:00:00, 10:01:00))。- 当水印到达
10:01:05时,触发窗口计算。 - 如果
10:00:03的点击在10:01:10才到达,仍会被处理(更新结果或存入迟到数据流)。
- 当水印到达
总结
Flink 的水印是时间语义的核心组件,它通过事件时间进度标记和延迟容忍机制,解决了乱序和延迟数据的问题,使得流计算能够在保证低延迟的同时,输出准确的结果。合理配置水印策略是优化 Flink 作业的关键步骤。
4.3、窗口分配器分类
window Assigner,中文"窗口分配器",用于构建不同的逻辑窗口,大体划分为:
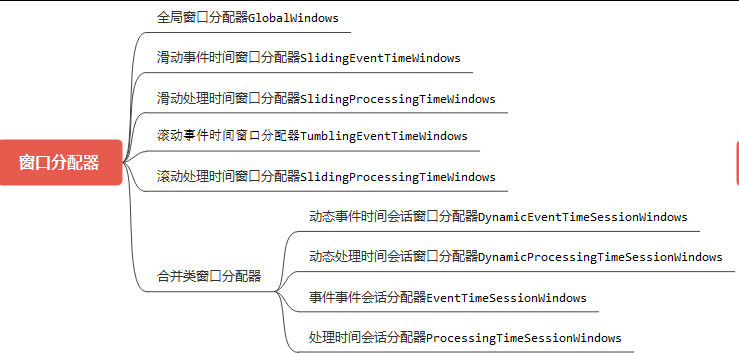
为了便于行文,窗口分配器也简称为窗口。
其中全局窗口(GlobalWindows)比较特殊,因为它比较灵活,但是又有一定的局限性,用处多,但是编程需要小心。
五、Flink TableApi&sql
Flink的 tableApi和sql相对比较简单。
总体上,Flink的sql有点类似iso的sql。
Flink的妙处在于可以在逻辑表上执行sql,除了基本的sql,还可以执行一些聚集函数和窗口函数.
另外,Flink的tableApi支持在tableStream环境中执行。
TableApi相对简单,没有什么特别好说的。
读者注意两点即可:执行环境和执行模式、SQL
SQL参考:https://nightlies.apache.org/flink/flink-docs-release-2.0/docs/dev/table/sql/overview/
SQL是一个好东西,容易学,和好用,值得花费一些时间学习!
本文来自博客园,作者:正在战斗中,转载请注明原文链接:https://www.cnblogs.com/lzfhope/p/18956037

 浙公网安备 33010602011771号
浙公网安备 33010602011771号