
for(int i=5;.......)
{
for(int j=1000;......)
{}
}
1.1如果小的循环在外层,对于数据库连接来说就只连接5次,进行5000次操作,如果1000在外,则需要进行1000次数据库连接,从而浪费资源,增加消耗。这就是为什么要小表驱动大表。
1.2驱动表(小表)的连接字段无论建立没建立索引都需要全表扫描的。被驱动表(大表)如果在连接字段建立了索引,则可以走索引。如果没有建立索引则也需要全表扫描。
1.3 两张表连接的情况
被驱动表的连接字段有索引:主键索引 对于驱动表中的每一条数据,到被驱动表的聚簇索引上寻找其对于的数据。 被驱动表的连接字段有索引:二级索引 对于驱动表上的每一条数据,到被驱动表的二次索引上寻找其对于的数据id,然后再根据数据id到聚簇索引上寻找对于的数据。 被驱动表的连接字段没有索引 对于驱动表上的每一条数据,都要到被驱动表上进行一次全表遍历,找到对应的数据。
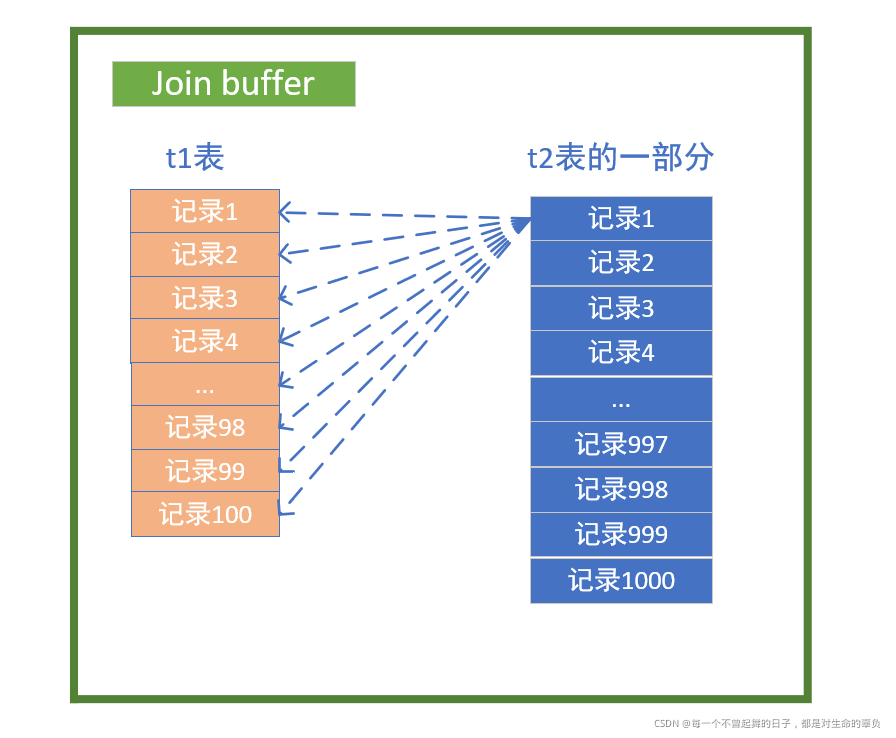
1.4 join buffer的作用
就是针对被驱动表的连接字段没有索引的情况下需要进行全表扫描,所以引入了join buffer内存缓冲区来对这个全表扫描过程进行优化。
在这个过程中,不再是每次从t1表中取1条记录。而是在开始时用内存缓冲区join buffer将t1表全部装入内存,每次取t2表的1000条记录调入内存。然后,让t1表与t2表在内存的这一部分(t2表在内存的这一部分作为外层循环,t1表作为内层循环)通过双重for循环进行匹配,然后循环这个过程,直到t2表的10000条数据都调入内存一次(即需要十次IO调入)。
2.判断驱动表与非驱动表
1 LEFT JOIN 左连接,左边为驱动表,右边为被驱动表.
2 RIGHT JOIN 右连接,右边为驱动表,左边为被驱动表.
3 INNER JOIN 内连接, mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表.
4 可通过EXPLANIN查看SQL语句的执行计划,EXPLANIN分析的第一行的表即是驱动表.
3.in和exists
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键)
in小 exists大
in后面跟的是小表,exists后面跟的是大表。
如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号