数据游戏:预测3天后招商银行的股价
前阵子报名参加了一个数据比赛,题目是预测5月15号(星期三)招商银行的股价,截止时间是在5月12号(星期天)。在本次预测中,我用到的是岭回归。
一、岭回归
线性回归
先回顾一下普通线性回归。一般来说,线性回归方程:y=w1x1+w2x2...+wnxn。我们把这组变量 xn 定成一个矩阵 X,把回归系数存放在向量W中,则 y=X*W。

存在的问题
(1)、特征数大于样本数
当特征数大于样本数的时候,上面的式子就存在问题了。矩阵要求逆,就必须为满秩矩阵,当特征数大于样本数的时候,就不为满秩了。可以通俗地理解为由于样本数量太少,没有办法提供足够的有效的信息。
(2)、多重共线性
多重共线性指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。举个例子,对于一般人来说,体重和身高是有很强的关联的,但如果我们需要预测某样东西,以这两者作为自变量,即使可以很好的拟合,但这个模型的解释性还是不够。
由于上面两个问题的存在,岭回归就出现了。它解决回归中重大疑难问题:排除多重共线性,进行变量的选择,在存在共线性问题和病态数据偏多的研究中有较大的实用价值。按照度娘的解释:岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
岭回归在上面式子的基础上做了点儿改进: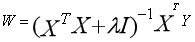 ,(其中
,(其中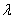 称为岭参数)很好地解决了上面的问题,假如
称为岭参数)很好地解决了上面的问题,假如 是一个奇异矩阵(不满秩),添加
是一个奇异矩阵(不满秩),添加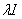 后可以保证其可逆。
后可以保证其可逆。
二、数据获取
本次数据是通过 Tushare 的 get_hist_data()获取的。Tushare是一个免费、开源的python财经数据接口包。python安装tushare直接通过
pip install tushare 即可安装。
import tushare as ts data = ts.get_hist_data('600848')
运行之后可以查看它的前后几行数据,按照tushare官方的说明,get_hist_data()只能获取近3年的日线数据,而他的返回值的说明是这样的:
〖date:日期;open:开盘价;high:最高价;close:收盘价;low:最低价;volume:成交量;price_change:价格变动;p_change:涨跌幅;ma5:5日均价;ma10:10日均价;ma20:20日均价;v_ma5:5日均量;v_ma10:10日均量;v_ma20:20日均量〗
均价的意思大概就是股票n天的成交价格或指数的平均值。均量则跟成交量有关。至于其他的返回值,应该是一下子就能明白的吧。在获得数据之后,我们查看一下描述性统计,通过 data.describe() 查看是否存在什么异常值或者缺失值。

这样看来似乎除了由于周末以及节假日不开盘导致的当天的数据缺失以外,并没有其他的缺失和异常。但是这里我们不考虑节假日的缺失值。
三、数据预处理
由于获取的数据是按日期降序排序,但本次预测跟时间序列有关,因此我们需要把顺序转一下,让它按照日期升序排序。
data1 = data[::-1]
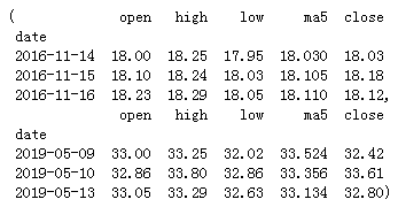
处理完顺序之后,我们要做一下特征值的选择。由于 volume 以及均量的值很大,如果不进行处理的话,很可能对整体的预测造成不良影响。由于时间有限,而且考虑到运算的复杂度,这里我没有对这些特征进行处理,而是直接将它们去掉了。至于均价,我是按照自己的理解,和10日均价、20日均价相比,5日均价的范围没那么大,对近期的预测会比另外两个要好,因此保留5日均价。接着,我用 sklearn.model_selection 的 cross_val_score,分别查看除〖'open', 'close', 'high', 'low', 'ma5'〗以外的其他剩余属性对预测值的影响。发现 ‘p_change’、'price_change' 这两个属性对预测结果的影响不大,为了节省内存,增加运算速度,提高预测的准确性,也直接把它们去掉了。完了之后,查看前后三行数据。
data1 = data1[['open','high','low','ma5','close']] data1.head(3), data1.tail(3)
四、建模预测
由于提交截止日期是周日,预测的是周三,因此需要先对周一周二的信息进行预测。在这里我突然想到一个问题,是用前一天的所有数据来训练模型以预测当天的 close 比较准确,还是用当天除了 close 以外的其他数据来训练模型以训练当天的 close 比较准呢?为了验证这个问题,我分别对这两种方法做了实验。
为了减少代码量,定义了一个函数用以评估模型的错误率。
def get_score(X_train, y_train): ridge_score = np.sqrt(-cross_val_score(ridge, X_train, y_train, cv=10, scoring='neg_mean_squared_error')) return np.mean(ridge_score)
(1)、用前一天的所有数据来当训练集
y_train = data1['close'].values[1:] X_train = data1.values[:-1] score = get_score(X_train, y_train)
输出结果大约为0.469,这个错误率就比较大了,不太合理,更何况还要预测其他特征值作为测试数据。
(2)、用当天除了 close 以外的其他数据来当训练集
data2 = data1[:] y_train = data2.pop('close').values X_train = data2.values score = get_score(X_train, y_train)
输出结果大约为0.183,跟第一个相比简直好多了。所以,就决定是你了!
接下来建模并把模型保存下来:
y_train = data1['close'] X_train = data1[['open', 'high', 'low', 'ma5']] close_model = ridge.fit(X_train, y_train) joblib.dump(ridge, 'close_model.m')
在预测之前呢,我们先拿训练集的后8组数据做一下测试,做个图看看:
scores = [] for x in X_train[-8:]: score = close_model.predict(np.array(x).reshape(1, -1)) scores.append(score) x = np.arange(8) fig, axes = plt.subplots(1, 1, figsize=(13, 6)) axes.plot(scores) axes.plot(y_train[-8:]) plt.xticks(x, data1.index[-8:].values, size=13, rotation=0)
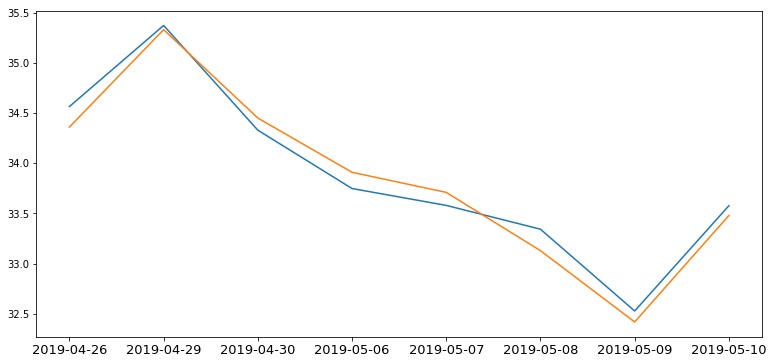
看到这样子我还是相对比较放心的,不过,这个模型的训练值除了“close”以外的属性都是已知的,要预测三天后的还得预测前两天的测试值。
def get_model(s): y_train = data1[s].values[1:] X_train = data1.values[:-1] model = ridge.fit(X_train, y_train) return model
def get_results(X_test): attrs = ['open', 'high', 'low', 'ma5'] results = [] for attr in attrs: result = get_model(attr).predict(X_test) results.append(result) return results
接下来预测三天的股价:
X_test = data1[-1:].values for i in range(3): results = get_results(X_test) close = close_model.predict(np.array(results).reshape(1, -1)) results.append(close) X_test = np.array(results).reshape(1, -1) print("5月15日招商银行关盘时的股价为:" + str(round(close[0], 2)))
5月15日招商银行关盘时的股价为:33.44
五、总结
虽然预测结果是这样子,但感觉这样预测似乎很菜啊。毕竟预测的每个值都会有偏差,多个偏差累加起来就很多了,这让我有点害怕。不知道存不存在不预测其他值直接预测close的方法,或者说直接预测5月15号的而不用先预测13、14号的方法。虽然我知道有种算法是时间序列算法,但不是很懂。希望哪位大神看了能给我一些建议,指点迷津。
对于一个自学数据分析的在校学生,苦于没有项目经验,正好赶上这次的【数据游戏】,能利用此次机会操作一波真的很不错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号