
Python爬取豆瓣电影评论,并用词云显示
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/Freshman |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/Freshman/homework/11734 |
| 作业目标 | <学习库的用法及爬取影评的方法,并养成提交代码的习惯> |
| 作业源代码 | https://github.com/Subakuin/WinterVacationHomework |
| 学号 | <212011153> |
词云图
一、说明
以python作为代码语言,爬取豆瓣 《唐人街探案3》 的所有短评信息,用 jieba 进行分词并通过 stylecloud 生成词云。
二、具体流程:
1.分析网页
- 打开唐人街探案3的豆瓣影评
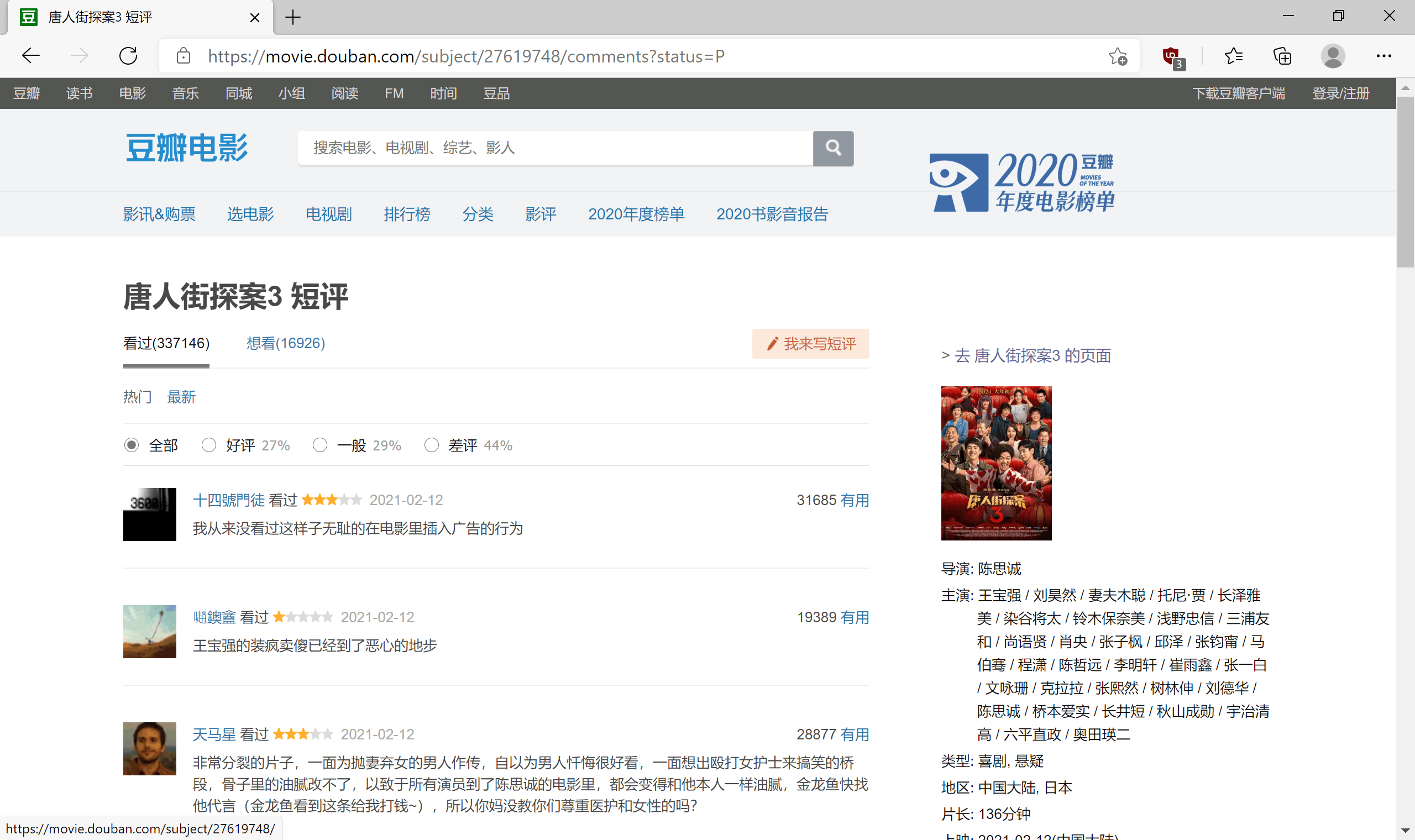
- 查看源代码
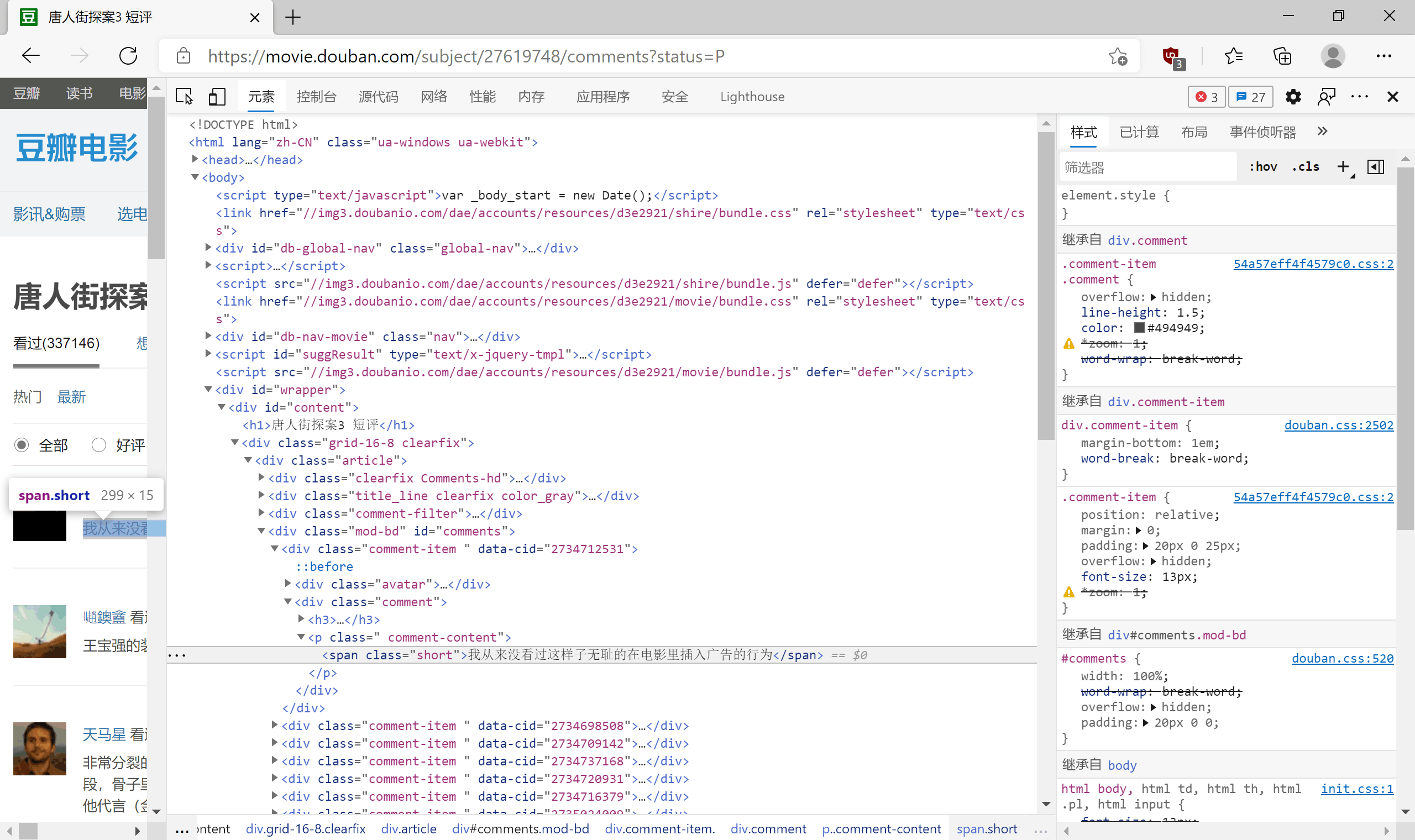
- 发现短评存放在
<span>标签中,所以需要爬取其里边的内容。
且通过翻页可以看到 url 仅改变 start ,每次翻页增加20,故可采用 for 循环语句控制页数


2.获取网页内容
- 通过
bs4以及requests模块进行获取
这里需要安装我们所要用到的库
requestsbs4stylecloudjieba(后面进行中文分词时需要用到)进入cmd命令行,输入
pip install ***进行第三方库的安装(***为库名称)
- 由于我在直接安装时速度很慢,且经常容易出现无法连接的情况,所以在这里推荐清华镜像源安装较快
pip install *** -i https://pypi.tuna.tsinghua.edu.cn/simple
同样 *** 为库名称,后面网址为清华镜像源,也可切换其他的镜像源
3.导入库并编写语言
这是最终修改完成之后的代码
# 分析豆瓣唐探3的影评,生成词云
import requests
from stylecloud import gen_stylecloud
import jieba
import re
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:64.0) Gecko/20100101 Firefox/64.0'
}
def jieba_cloud(file_name):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read(),cut_all=True)
result = " ".join(word_list)
# 制作中文词云
icon_name = " "
icon = "ciyun"
pic = icon + '.png'
gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
return pic
def spider_comment(movie_id, page):
comment_list = []
with open("douban.txt", "a+", encoding='utf-8') as f:
for i in range(1,page+1):
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P' \
% (movie_id, (i - 1) * 20)
req = requests.get(url, headers=headers)
req.encoding = 'utf-8'
comments = re.findall('<span class="short">(.*)</span>', req.text)
f.writelines('\n'.join(comments))
print(comments)
if __name__ == '__main__':
movie_id = '27619748' #引号中的数字即为电影短评网址中的那几个数字,可以通过修改它来爬取其他电影的短评
page = 10
spider_comment(movie_id, page)
jieba_cloud("douban.txt")
这是运行出来的词图

4.对代码进行创新优化
第一次commit
切换jieba分词全模式为精确模式
输出词云图片

第二次commit
添加词图显示的新形状,设计代码结构
def jieba_cloud(file_name, icon):
with open(file_name, 'r', encoding='utf8') as f:
word_list = jieba.cut(f.read())
result = " ".join(word_list)
icon_name = " "
if icon == "1":
icon_name = ''
elif icon == "2":
icon_name = "fas fa-dragon"
pic = str(icon) + '.png'
if icon_name is not None and len(icon_name) > 0:
gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc', output_name=pic)
else:
gen_stylecloud(text=result, font_path='simsun.ttc', output_name=pic)
return pic
# 主函数
if __name__ == '__main__':
movie_id = '27619748'
page = 10
spider_comment(movie_id, page)
jieba_cloud("douban.txt", "1")
jieba_cloud("douban.txt", "2")
输出词云图片

第三次commit
添加代码将词图以6种形式展现出来
输出词云图片



最终修改完的代码已放入github仓库 点此查看
- 远程仓库截图如下
| 代码行数 | 需求分析时间 | 编码时间 |
|---|---|---|
| 57 | 30min | n hours |
分解需求的思路
- 首先确定编程语言,再明确自己编写代码过程中所需要用到的库,配置好python的环境。接着进入学习、编写、修改并
简化代码的过程,划分代码结构层次,一层层进行编写并试运行,清楚自己期望的目的输出结果。在此过程中也要不断的提交
保留自己的历史代码,形成良好的习惯。这样可以保证在编写过程中不会分不清主次,更容易纠错修改,结构也会更加清晰明
了,后期便于进行代码的缩短优化,使其发挥出更好的性能。
在此次作业中遇到的问题
- 由于并未深入学习python语言,导致看到作业后的一脸茫然,之前也只是单单听说过python实现爬虫这个概念,却从未
实践过。于是完成此次作业花费的时间也就很多,并且遇到了不少的问题。不过我觉得最难受的就是网络问题,在配置python
库的时候速度很慢,会经常性的连接失败,自己英文学的也不是太好,报错有时候也不是太理解它所描述的原因,后来切换了
好几个镜像源,总算是完成了第一步的环境配置。然后便是编写代码、参考别人例子的过程,一次次代码的运行失败,一次次
的学习改正错误,麻烦确实麻烦,却也无法比拟成功后的喜悦。同时在提交代码到远程仓库时也一直失败,网页访问GitHub也
一直被墙,然后就想着用国内的gitee,不过为了尽量按作业要求来,于是又挂了代理访问github。虽然经历了不少的麻烦,
但却也学到了不少的东西。尤其是requests和jieba这两个库的使用,对python爬虫实战也有了更深入的了解和学习。不过整体
占比最重要的还是代码git的提交,开始自己也懒得去一遍遍的commit,却在代码报错修改和完善的过程中吃到了不少的苦头,
直到快完成时才想到了git,习惯之后才感受到了它的便捷。后面的两个作业我也会尽量尝试着去做,经历了开头的难点,我想
完成后面的作业应该不会太难。不过问题总是在实践中才出现,嘛,谁知道呢
参考链接资料及网站
总结
- 从来没有花费这么长的时间去学习并且实践,markdown的编写确实也很费时间,不过的确是自己不熟悉markdown的结果。
学习中经历的错误变成了自己独到的理解和经验,我也感受到了成功的喜悦。然而同时也让我深刻的感受到,自己所学的不过只
是沧海一粟,在我们的生活场景中用到的软件甚至系统底层又是多么庞大的工程啊,不知不觉便感慨人类社会的发展如此之快,
而仅仅用了两周时间便写出了git以及GitHub这样如此好用的系统级网站的那个人又是何等的怪物啊!我也想要成为那样的怪物,
然而这却是一个难以实现的目标,但却可以激励着我一点点的去学习和追赶。而目前最应该做的便是学好一门C语言到精通,多余
的话不说,少说多做是根本,希望开学后的我可以散发着别样的光芒!令人难以置信到不可理喻
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号