
hadoop学习之spark应用
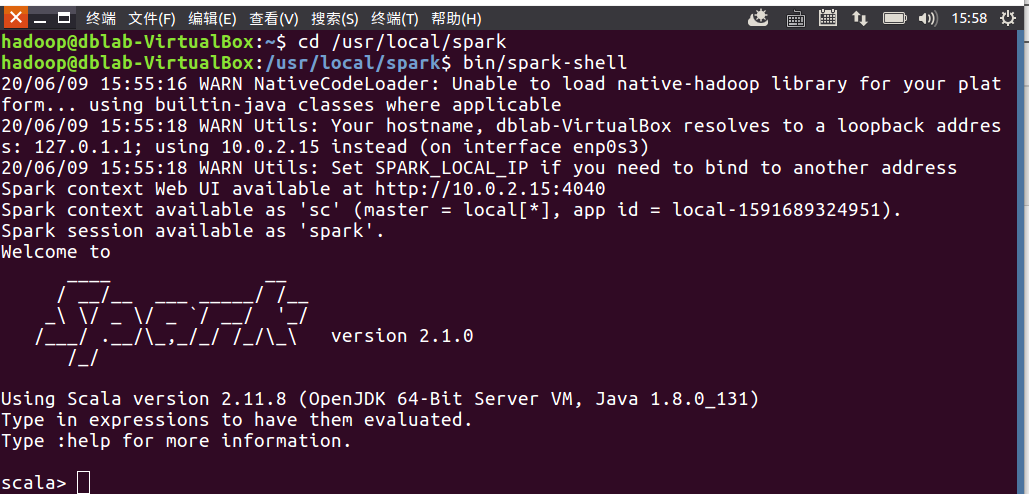
启动spark(前提是在Hadoop集群中已经安装配置好spark)
命令:cd /usr/local/spark
bin/spark-shell
RDD的创建方法:
(1)在程序内部创建 将某个编程语言的有序集合作为参数传入“SparkContex.parallelize(Seq)”方法可以生成一个RDD
(2)从程序外读取 通过如“SparkContex.textFile(path)”等方法从外部文件读数据并生成RDD
(3)RDD转换操作 通过对一个RDD执行转换操作,得到一个新的RDD
//用Spark自带的本地文件README.md文件生成RDD
val textFile = sc.textFile("file:///usr/local/spark/README.md")

//抽取含有“Spark”的行,生成一个新的RDD
val lineWithSpark = textFile.filter(line => line.contains("Spark"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号