ElasticSearch入门实战
全文检索
根据搜索条件将相关内容结果进行检索。
- 查询: 根据明确的条件对数据进行过滤,例如年龄 > 20且工资 < 10000的人进行过略。
- 检索: 没有明确的条件,通过相关性将结果进行返回,例如根据查询条件的同义词、错别字等等进行查询。
通过常规的模糊查询只能查出包含xxx的内容,而没办法根据相关性进行查询。
例如我们想要查询java设计模式相关的文章,如果使用MySQL查询则是以下语句:
select * from artcle where title like "%JAVA设计模式%";
这样做有个弊端就是,如果我们存储的数据是以下文章的话则是查不出结果的。

所以需要某种数据结果来实现根据关键字对数据进行查询,这种数据结构就是倒排索引表。
倒排索引表
利用分词器将文章按关键字进行分词,分词之后记录每个关键字所对应出现再哪几篇文章中,例如下图所示

如果想要搜索Java设计模式的话,分词器会将Java设计模式进行分词,例如分出Java和设计模式,我们只要将符合Java关键字和设计模式关键字锁对应的文章检索出来即可。
ElasticSearch
开源全文检索引擎,适合处理高并发分布式场景的文章检索。
优点:
- 支持分布式: 可以轻易的支持水平扩展,将数据节点分片多台机子中,例如服务器空间不足,无法存储数据,一旦水平扩展之后,那么数据就存储再其他服务器中。
- 全文检索: 分词检索功能。
- 支持度高: 支持大多数编程语言,例如python、Java、Go等。
- 高性能: 使用倒排索引表来优化以及缓存技术来优化查询效率。
- 易用性: 采用Restul API构建系统api,可以很方便的对数据进行检索操作。
安装
官网: https://www.elastic.co/cn/downloads/elasticsearch

选择操作系统即可进行下载,下载完成之后进行解压并运行bin\elasticsearch.bat即可运行,前提是需要搭建Java JDK环境,如果没有JDK的话es内置了一个JDK供使用。
执行结果:
访问127.0.0.1:9200出现无法访问的问题,如下图所示:
原因是ElastSearch默认打开了ssl证书校验,将config\elasticSearch.yml文件中的以下两项配置改成false即可。
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
之后启动发现可以正常访问页面了。
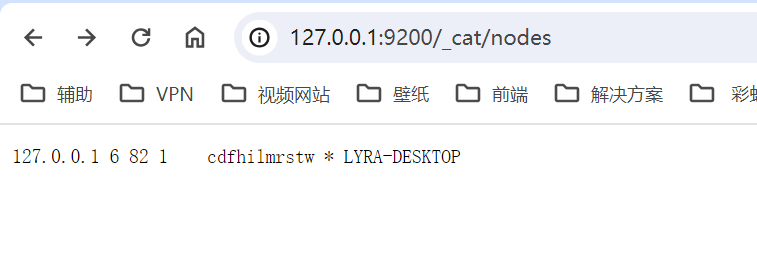
查看ElasticSearch节点信息,访问/_cat/nodes即可看见es集群信息,因为我只在本地搭建了一个ElasticSearch,所以下图就只有一个节点。
安装插件
查看已安装插件以及删除插件
elasticsearch-plugin list
elasticsearch-plugin remove


如果使用命令删除成功但是查询插件列表抛异常了,如下图所示:
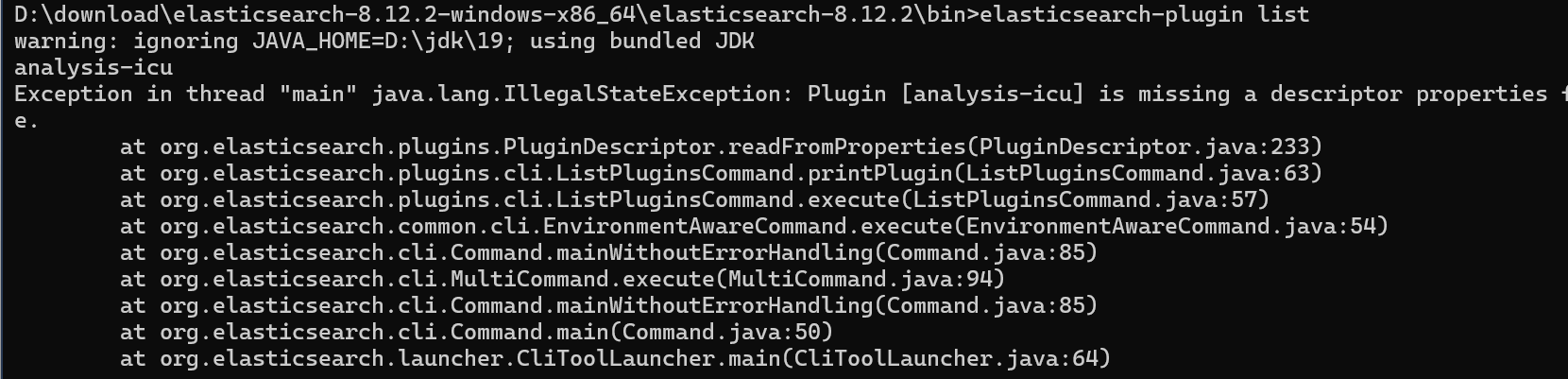
那么需要将elasticsearch/plugins下的指定插件的目录删除即可。
安装icu分词器
elasticsearch-plugin install analysis-icu


安装ik分词器
官网: https://github.com/infinilabs/analysis-ik
查找使用的ES版本与ik分词器相符的版本并进行下载,例如你的ES版本为8.12.2,那么再Relase中寻找8.12.2版本安装即可,如下图所示:
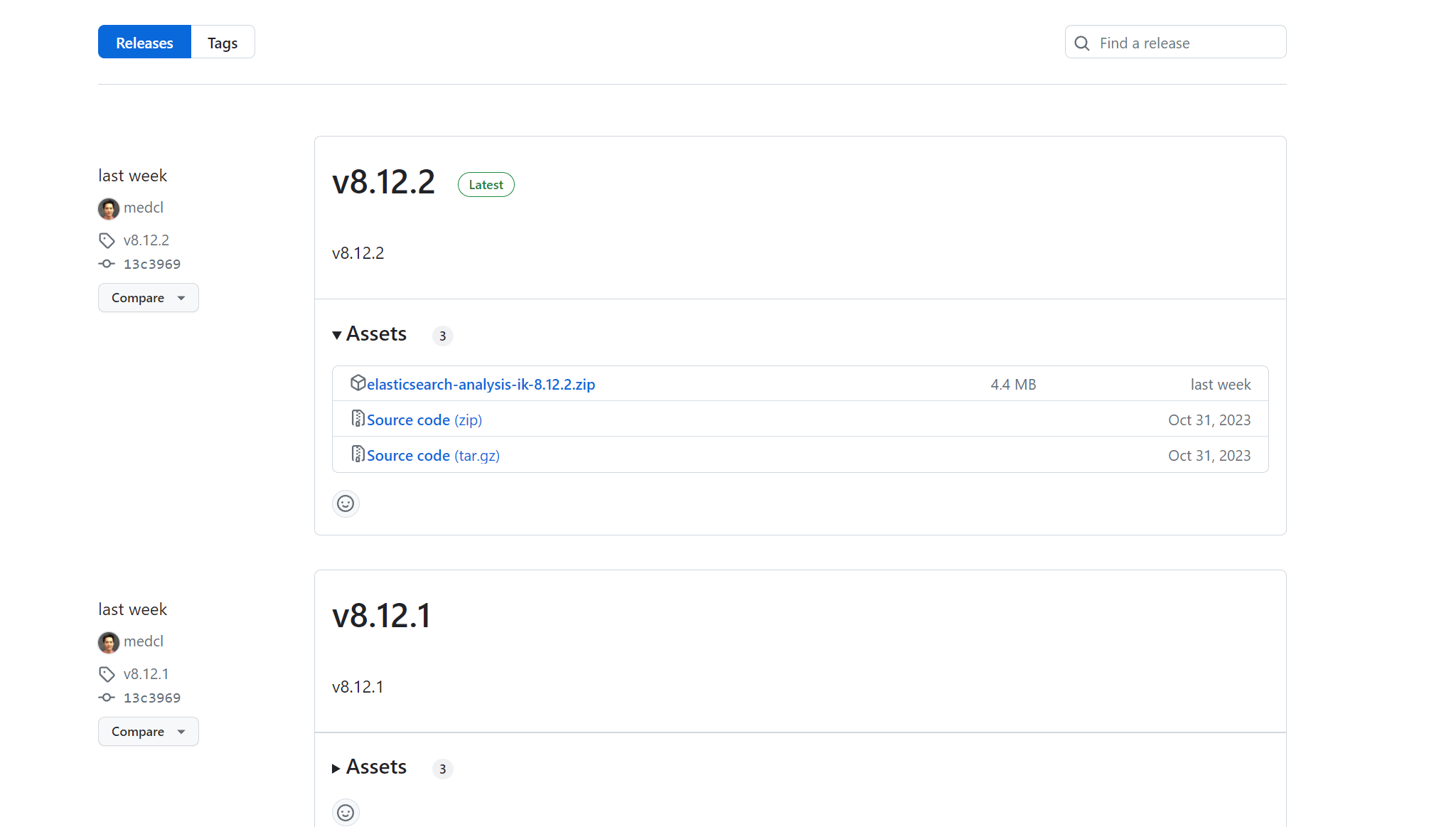
安装方式和icu分词器相似,首先需要复制Relase版本中的链接,如下图所示:
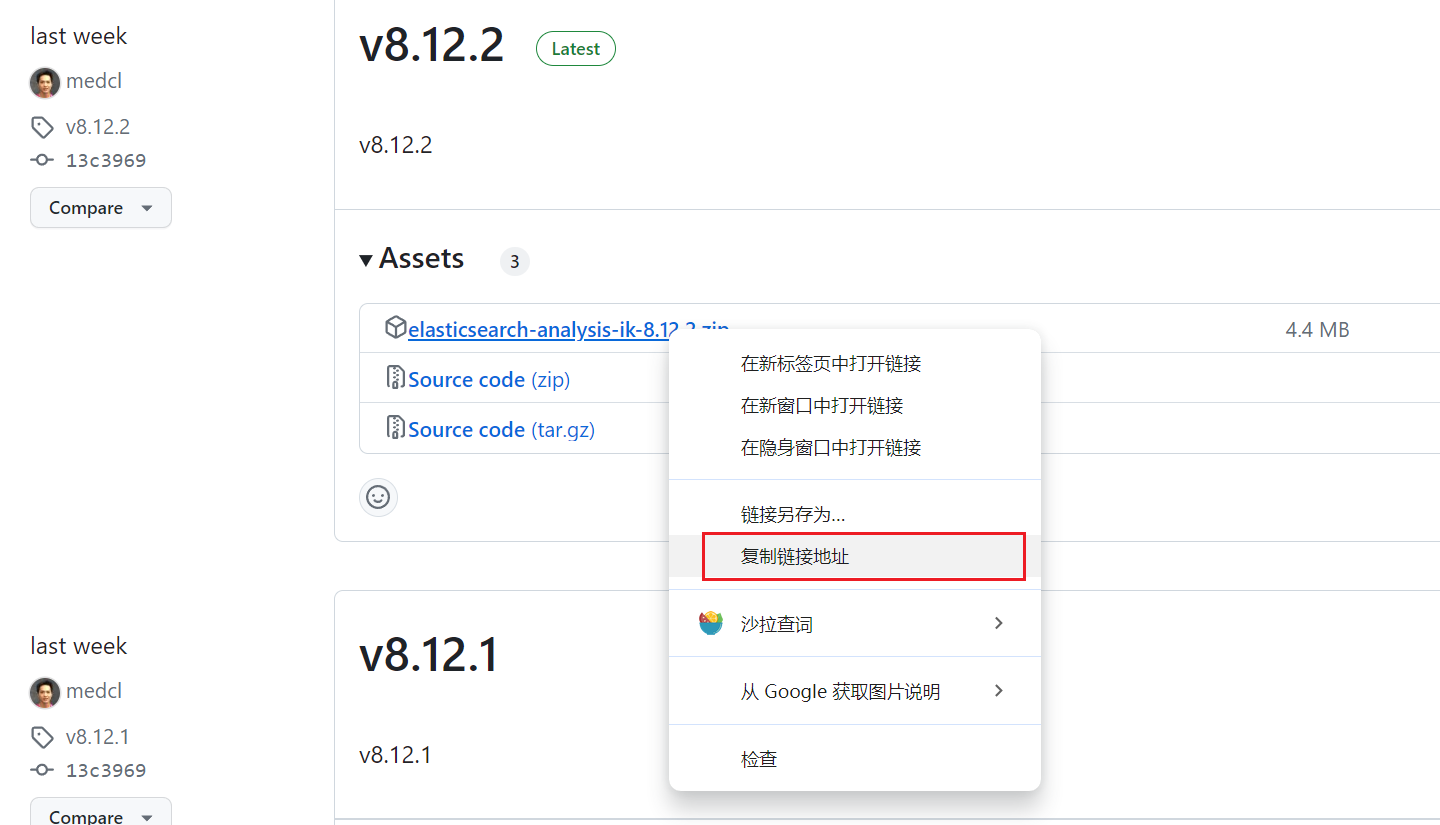
再使用elasticsearch-plugin安装即可
elasticsearch-plugin install https://github.com/infinilabs/analysis-ik/releases/download/v8.12.2/elasticsearch-analysis-ik-8.12.2.zip
ik分词器与icu分词器对比
icu分词器
查询
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "中华人民共和国"
}
分词结果
{
"tokens": [
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 2
}
]
}
icu分词器将词分成了中华、人民、共和国三种,但是这种方式有个弊端,如果查询中华人民这个词的话就查不到记过。
ik分词器
ik分词器就很好的优化了以上问题
查询
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
从结果可知,我们要查中华人民的话,就不会像icu分词器那样查不出来了。
{
"tokens": [
{
"token": "中华人民共和国",
"start_offset": 0,
"end_offset": 7,
"type": "CN_WORD",
"position": 0
},
{
"token": "中华人民",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "中华",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "华人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 3
},
{
"token": "人民共和国",
"start_offset": 2,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "人民",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 5
},
{
"token": "共和国",
"start_offset": 4,
"end_offset": 7,
"type": "CN_WORD",
"position": 6
},
{
"token": "共和",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 7
},
{
"token": "国",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 8
}
]
}
字段:
- start_offset: 开始偏移
- end_offset: 结束偏移
记录位置可以对指定关键字进行高亮显示,如下图京东搜索所示:
概念
- 节点: es的实例,一台机子可以装很多节点。
- 角色: 主机点,活跃节点,一般一个集群只会有一个主节点; 从节点,备用节点,一遍主节点挂了之后,由从节点选举形成一个主节点; 数据节点, 专门存数据的节点。
索引: 相当于关系型数据库中的表。倒排索引文件。表动作则是对数据库表中数据进行操作,例如往索引中添加一条数据。
组成部分:- alias: 别名,索引迁移的时候会用到。
- mappings: 索引映射,类似表结构,例如字段名称,数据类型等等。
- settings: 索引配置信息,例如number_of_shards分片数、number_of_replicas分片副本数。
- 文档: 相当于MySQL中的一行表数据。
文档的meta data是已下划线开头的,用于存储文档相关配置信息。其余字段存储的就是文档实际的数据信息了。
_index: 文档索引名称。
_type: 文档类型,高版本es已经废除文档类型了,所以这个字段一直为_doc。
_id: 文档唯一id。
_source: 文档数据json。
_version: 文档版本,每次修改都会 + 1,乐观锁场景可以用到。
_seq_no: 和_version医院,一旦数据发生改变,数据则会累计。保证后写入的_seq_no一定大于先写如的_seq_no。
操作
创建索引
PUT /index名称,例如我要创建一个index名称为test_index的话如下例所示
PUT /test_index
如果未指定分片信息的话默认会设置成1个分片,1个分片副本
创建的时候也可以指定索引配置信息。
PUT /test_index
{
"settings": {
"index": {
// 索引分片数 默认为1,只有再创建索引的时候才能进行设置
"number_of_shards": "2",
// 分片副本数,默认为1 运行设置为0
"number_of_replicas": "3"
// 自动刷新间隔,如果设置为-1则需要手动进行索引刷新,如果不刷新的话无法搜到指定结果
"refresh_interval": 1
// from + size 搜索索引最大值,默认为10000,分页参数,如果设置成10000则分页查询时最多返回10000条
"max_result_window": 200000
}
}
}
查看索引信息
GET /索引名称,如下所示,查看test_index索引
GET /test_index
输出
{
"test_index": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "test_index",
"creation_date": "1709639448800",
"number_of_replicas": "1",
"uuid": "LaDuNjmvRNSAKpDfMJyo2g",
"version": {
"created": "8500010"
}
}
}
}
}
修改索引配置信息
除了number_of_shards这个配置外,其他的索引配置都能进行修改,如下所示,
修改前:
{
"test_index": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "2",
"provided_name": "test_index",
"creation_date": "1709652311231",
"number_of_replicas": "3",
"uuid": "17CkXLc7TOOhsGMlNTgfLg",
"version": {
"created": "8500010"
}
}
}
}
}
put /index名称/_settings 可以对索引配置进行修改
PUT /test_index/_settings
{
"index": {
"number_of_replicas": "3",
"refresh_interval": "10s",
"max_result_window": 200000
}
}
执行以上语句之后再对索引信息查询之后结果如下
{
"test_index": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"refresh_interval": "10s",
"number_of_shards": "2",
"provided_name": "test_index",
"max_result_window": "200000",
"creation_date": "1709652311231",
"number_of_replicas": "3",
"uuid": "17CkXLc7TOOhsGMlNTgfLg",
"version": {
"created": "8500010"
}
}
}
}
}
mapping
如果未设置mapping的话,插入数据之后会自动创建mapping,如下所示,直接再索引中插入一条数据之后则会自动创建一个索引mapping出来
PUT /test_index/_doc/1
{
"name": "lyra",
"age": 12
}
索引信息:
{
"test_index": {
"aliases": {},
"mappings": {
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"refresh_interval": "10s",
"number_of_shards": "2",
"provided_name": "test_index",
"max_result_window": "200000",
"creation_date": "1709652311231",
"number_of_replicas": "3",
"uuid": "17CkXLc7TOOhsGMlNTgfLg",
"version": {
"created": "8500010"
}
}
}
}
}
系统会默认为字符串类型的设置一个默认的副类型keyword类型,如何使用keyworkd类型的字段就进行查询时可以不分词进行查询。例如用户姓名没有必要进行分词,那么设置索引mapping的时候直接设置类型为keyword类型。
手动创建索引可以在创建索引的时候直接指定,如下所示
PUT /test_index
{
"mappings": {
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "keyword"
}
}
}
}
索引映射如下所示:
{
"test_index": {
"aliases": {},
"mappings": {
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "keyword"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "test_index",
"creation_date": "1709654324885",
"number_of_replicas": "1",
"uuid": "5bVRn8bjR8isRZmRBfA2kQ",
"version": {
"created": "8500010"
}
}
}
}
}
创建文档
PUT /索引名称/_doc/文档id,如下所示
PUT /test_index/_doc/1
{
"name": "lyra",
"age": 12
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号