特征工程之降维算法
-
数据降维简介
数据降维即对原始数据特征进行变换,使得特征的维度减少。
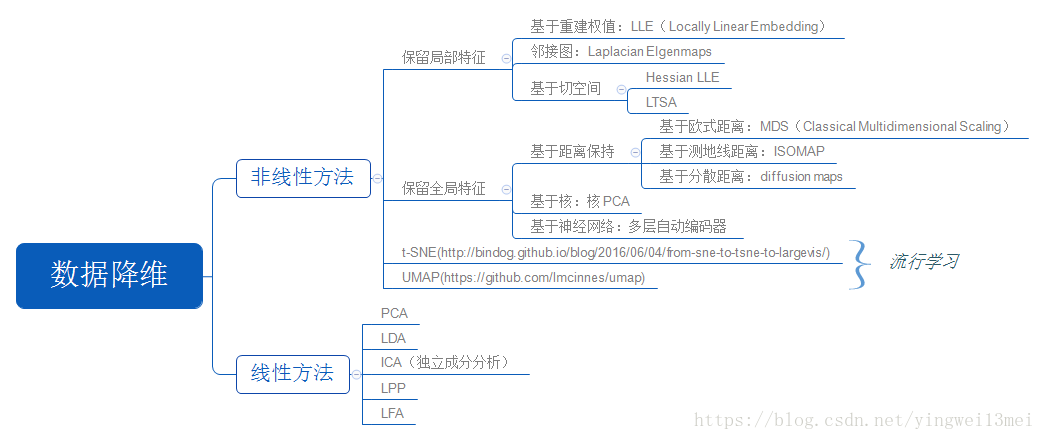
依据降维过程是否可以用一个线性变换表示,降维算法可以分为线性降维算法和非线性降维算法,下图展示了各种降维算法及其类别:
![yeG8oD.png]()
降维的必要性:
- 多重共线性和预测变量之间相互关联。多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯。
- 高维空间本身具有稀疏性。一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有2%。
- 过多的变量,对查找规律造成冗余麻烦。
- 仅在变量层面上分析可能会忽略变量之间的潜在联系。例如几个预测变量可能落入仅反映数据某一方面特征的一个组内。
降维的目的:
- 减少预测变量的个数。
- 确保这些变量是相互独立的。
- 提供一个框架来解释结果。相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示。
- 数据在低维下更容易处理、更容易使用。
- 去除数据噪声。
- 降低算法运算开销。
-
SVD
对于n阶实对称矩阵A,若非零向量x和数\(\lambda\)使得:
\[Ax=\lambda x \]则称x和\(\lambda\)为A的特征向量和对应的特征值。对于A的n个特征值\(\lambda_1\le\lambda_2...\le\lambda_n\)以及对应的特征向量\(w_1,w_2,...,w_n\),可以将A做如下分解:
\[A=W\Sigma W^T \]其中W为特征向量排列成的矩阵,\(\Sigma\)为特征值排列成的对角阵。一般我们会把W的这n个特征向量标准化,即满足\(w^Tw=1\),此时W的n个特征向量为标准正交基,满足\(W^TW=I\)。
上面的特征分解需要A为实对称矩阵,对于一般矩阵\(A\in\mathbb{R}^{n*m}\),SVD可以对其做类似分解:
\[A=U\Sigma V^T \]其中U是一个\(n*n\)的矩阵,\(\Sigma\)是一个\(n*m\)的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个\(m*m\)的矩阵。U和V都是单位正交阵,即满足\(U^TU=I,V^TV=I\)。U被称为左奇异矩阵,V被称为右奇异矩阵。
可以通过求\(AA^T\)的特征向量得到左奇异矩阵U,求\(A^TA\)的特征向量得到右奇异矩阵V,对二者的任意特征值开方可得到\(\Sigma\)。
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。因此,奇异值分解可以应用于图像压缩等领域。
-
PCA
一般认为方差越大的维度越有区分度,方差越小的维度区分度越小,越有可能是噪音。PCA的目标就是寻找一组新的正交基\(w_1,w_2,...,w_d\)(从m维下降到d维), 使得m维数据点在该正交基构成的平面上投影后,投影数据点间的距离最大, 即数据间的方差最大,且各个新维度间相关度最小,即协方差为0。
设原数据经过零均值化后为\(X\in\mathbb{R}^{n*m}\),则其协方差矩阵为\(C=X^TX\),设PCA的投影矩阵为\(P\in \mathbb{R}^{m*d}\),投影后新的数据为\(Y\in\mathbb{R}^{n*d}\),则有:
\[Y=XP \]新数据的协方差矩阵为:
\[\frac{1}{n}Y^TY=P^T(\frac{1}{n}X^TX)P=P^TCP \]根据矩阵P的各列为单位正交基的约束条件,以最大化方差为优化目标,由拉格朗日乘子法可以得到P即为矩阵C的前d个最大的特征值所对应的特征向量。
PCA的具体推导过程涉及带矩阵约束的最优化问题,可以参考https://datawhalechina.github.io/pumpkin-book/#/chapter10/chapter10,其中关于矩阵的迹的微分可以参考https://blog.csdn.net/hqh45/article/details/50920904。
以上是从最大方差角度理解,PCA也可以从最小化平方误差理解,可以参考https://www.cnblogs.com/xiaobingqianrui/p/10755867.html。
PCA的求解过程涉及协方差矩阵\(C=\frac{1}{n}X^TX\)的特征值分解,一般使用对X进行SVD来提高效率,因为存在某些SVD方法可以不进行特征值分解。
设X的SVD分解为:
\[X=U\Sigma V^T \]其中奇异值按照从大到小排列,V的前k列即对应C的前d个最大的特征值所对应的特征向量。
PCA的整体算法流程为:
输入:原始数据\(X\in\mathbb{R}^{n*m}\);低维空间维数d。
过程:
- 对X的各列进行零均值化,若各列数量级相差很大(量纲等原因导致),则还需要对数据进行标准化或归一化使其缩放到同样大小的区间;
- 求处理后的X的奇异值分解\(X=U\Sigma V^T\),其中奇异值按照从大到小排列;
- 取右奇异矩阵的钱d列构成变换矩阵P;
- 求降维后的数据\(Y=XP\)。
输出:
低维数据矩阵\(Y=XP\)。 -
LDA
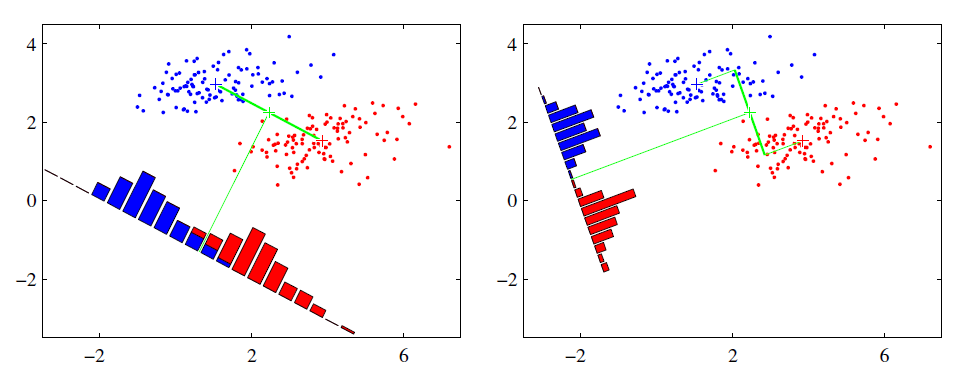
不同于PCA,LDA降维时需要类别信息,因此LDA是一种监督降维算法。PCA的思想可以用一句话概括,“内间均值差最大,类内方差最小”。以下图的二维数据为例:
![ynhLi8.png]()
我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。上图中提供了两种投影方式,从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。
当类别数为2时,设类标分别为0,1,两类数据的数目分别为\(N_0,N_1\),均值分别为:
\[m_j=\frac{1}{N_j}\sum_{x\in X_j}x,(j=0,1) \]LDA选择的降维直线的方向向量为\(w\),因为平移并不影响投影点的相对位置,所以可以设该直线过原点。则降维后的点的新坐标为:
\[y=w^Tx \]降维后的均值和方差分别为:
\[\mu_j=\frac{1}{N_j}\sum_{y\in Y_j}y=\frac{1}{N_j}\sum_{x\in X_j}w^Tx =w^Tm_j,(j=0,1) \\ s_j^2=\sum_{y\in Y_j}(y-\mu_j)^2=\sum_{x\in X_j}(w^Tx-w^Tm_j)(w^Tx-w^Tm_j)^T \\ =w^T(\sum_{x\in X_j}(x-m_j)(x-m_j)^T)w \]此处方差并未除以样本数目。LDA希望最大化类间均值,最小化类内方差,则可以令优化目标为:
\[\arg\max_w J=\frac{(\mu_1-\mu_2)^2}{s_1^2+s_2^2} \\ =\frac{w^T(m_0-m_1)(m_0-m_1)^Tw}{w^T(\sum_{x\in X_0}(x-m_0)(x-m_0)^T+\sum_{x\in X_1}(x-m_1)(x-m_1)^T)w} \]令:
\[S_b=(m_0-m_1)(m_0-m_1)^T \\ S_w=\sum_{x\in X_0}(x-m_0)(x-m_0)^T+\sum_{x\in X_1}(x-m_1)(x-m_1)^T \]称\(S_b\)为类间散度矩阵,\(S_w\)为类内散度矩阵,则:
\[\arg\max_w J=\frac{w^TS_bw}{w^TS_ww} \]上式是广义瑞利熵的形式,其最大值对应的w为\(S_w^{-1}S_b\)的最大特征值所对应的特征向量。
当类别数大于2时,\(W=(w_1,w_2,...,w_d)\),\(S_b\)稍有变化,设类别数目为N,则:
\[S_b=\sum_{j=1}^NN_j(m_j-m)(m_j-m)^T \\ m=\frac{1}{\sum_{j=1}^NN_j}\sum_{j=1}^NN_jm_j \]有一个问题是此时\(W^TS_bW\)和\(W^TS_wW\)均为矩阵,无法作为一个标量函数来优化,一般来说,我们可以用其他的一些替代优化目标来实现。常见的一个LDA多类优化目标函数定义为:
\[\arg\max_W J=\frac{tr(W^TS_bW)}{tr(W^TS_wW)}=\sum_{i=1}^d\frac{w_i^TS_bw_i}{w_i^TS_ww_i} \]上式右边即为d个广义瑞利熵之和,其最大值对应了\(S_w^{-1}S_b\)的前d个最大特征值所对应的特征向量。
由于:
\[S_b=\sum_{j=1}^NN_j(m_j-m)(m_j-m)^T \\ =[\sqrt{N_1}(m_1-m),...,\sqrt{N_N}(m_N-m)][\sqrt{N_1}(m_1-m),,...,\sqrt{N_N}(m_N-m)]^T \\ \sum_{i=1}^N\sqrt{N_i}\sqrt{N_i}(m_i-m)=0 \]因此\(rank(S_b)=N-1\),所以:
\[rank(S_w^{-1}S_b)=\min(rank(S_w^{-1}),rank(S_b))=rank(S_b)=N-1 \]因此\(S_w^{-1}S_b\)最多有N-1个特征向量,即LDA降维最多降到类别数N-1的维数,如果我们降维的维度大于N-1,则不能使用LDA。
LDA的整体算法流程为:
输入:原始数据\(D=\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\}\);低维空间维数d,\(d\le N-1\),N为类别数目。
过程:
- 计算类间散度矩阵\(S_b\),类内散度矩阵\(S_w\);
- 计算\(S_w^{-1}S_b\);
- 对\(S_w^{-1}S_b\)进行特征值分解,得到其最大的d个特征值对应的特征向量,将其拼接成矩阵\(W=(w_1,w_2,...,w_d)\);
- 对每一个样本\(x_i\),计算其降维后的坐标\(z_i=W^Tx_i\)
输出:
低维数据\(D'=\{(z_1,y_1),(z_2,y_2),...,(z_n,y_n)\}\)。实际上LDA除了可以用于降维以外,还可以用于分类。一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别带入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别。
-
PCA VS LDA
相同点:
-
两者均可以对数据进行降维。
-
两者在降维时均使用了矩阵特征分解的思想。
-
两者都假设数据符合高斯分布。
不同点:
-
LDA是有监督的降维方法,而PCA是无监督的降维方法
-
LDA降维最多降到类别数N-1的维数,而PCA没有这个限制。
-
LDA除了可以用于降维,还可以用于分类。
-
LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
-
-
MDS
MDS的核心思想是使得原始空间中的样本距离在低维空间中得以保持。
设原始空间的距离矩阵为\(D\in\mathbb{R}^{n*n}\),其中n为样本数量,D的第i行第j列的元素\(dist_{ij}\)表示样本\(x_i\)与样本\(x_j\)间的距离,MDS希望把数据降维成\(Z\in\mathbb{R}^{d*n},d<m\),其中m为数据的原始维度数目,d为新维度数目。并且MDS希望保持样本间的距离不变,即:
\[dist_{ij}=||z_i-z_j||_2 \]则:
\[dist_{ij}^2=||z_i-z_j||_2^2=||z_i||_2^2+||z_j||_2^2-2z_i^Tz_j \]令内积矩阵\(B=Z^TZ\),则:
\[b_{ij}=z_i^Tz_j \\ dist_{ij}^2=b_{ii}+b_{jj}-2b_{ij} \]由于在新维度对数据进行平移并不会改变样本间的距离,因此可以对Z进行零均值化,即令:
\[\sum_{i=1}^nz_i=0 \]则:
\[\sum_{j=1}^ndist_{ij}^2=nb_{ii}+\sum_{j=1}^nb_{jj}-2\sum_{j=1}^nb_{ij} \\ =nb_{ii}+tr(B)-2z_i^T\sum_{j=1}^nz_j=nb_{ii}+tr(B) \\ \sum_{i=1}^ndist_{ij}^2=nb_{jj}+\sum_{i=1}^nb_{ii}-2\sum_{i=1}^nb_{ij} \\ =nb_{jj}+tr(B)-2(\sum_{i=1}^nz_i^T)z_j=nb_{jj}+tr(B) \\ \sum_{i=1}^n\sum_{j=1}^ndist_{ij}^2=\sum_{i=1}^n(nb_{ii}+tr(B)) \\ =2ntr(B) \]令:
\[dist_{i.}^2=\frac{1}{n}\sum_{j=1}^ndist_{ij}^2=b_{ii}+\frac{1}{n}tr(B) \\ dist_{.j}^2=\frac{1}{n}\sum_{i=1}^ndist_{ij}^2=b_{jj}+\frac{1}{n}tr(B) \\ dist_{..}^2=\frac{1}{n^2}\sum_{i=1}^n\sum_{j=1}^ndist_{ij}^2=\frac{2}{n}tr(B) \]则易得到:
\[b_{ij}=-\frac{1}{2}(dist_{ij}^2-dist_{i.}^2-dist_{.j}^2+dist_{..}^2) \]即可以由原始距离矩阵Z求得内积矩阵B。对B进行特征值分解可以得到n个特征值\(\lambda_1\le\lambda_2...\le\lambda_n\)以及对应的特征向量\(w_1,w_2,...,w_n\),可以将B做如下分解:
\[B=W\Sigma W^T \]其中W为特征向量排列成的矩阵,\(\Sigma\)为特征值排列成的对角阵。选取B的前d大的特征值以及其特征向量构成\(\Sigma'\)和\(W'\),则B可以近似为:
\[B\approx W'\Sigma'W'^T \]Z可以表示为:
\[Z=\Sigma'^{\frac{1}{2}}W'^T \]MDS的整体算法流程为:
输入:距离矩阵\(D\in\mathbb{R}^{n*n}\),其元素\(dist_{ij}\)表示样本\(x_i\)与样本\(x_j\)间的距离;低维空间维数d。
过程:
- 计算\(dist_{ij}^2,dist_{i.}^2,dist_{.j}^2,dist_{..}^2\);
- 根据\(b_{ij}=-\frac{1}{2}(dist_{ij}^2-dist_{i.}^2-dist_{.j}^2+dist_{..}^2)\)计算矩阵B;
- 对矩阵B作特征值分解;
- 取B的d个最大特征值以及对应特征向量构成\(\Sigma'\)和\(W'\)。
输出:
低维数据矩阵\(Z=\Sigma'^{\frac{1}{2}}W'^T\),每列是一个样本的低维坐标。 -
Isomap
流形学习假设所处理的数据点分布在嵌入于外维欧式空间的一个潜在的流形体上,或者说这些数据点可以构成这样一个潜在的流形体。Isomap正是基于这一假设。
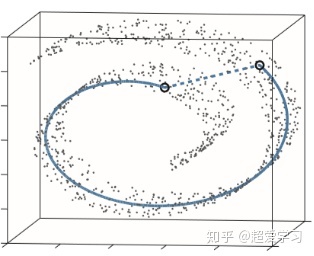
下图就是一个数据嵌入在流行体的例子,传统的例如PCA和MDS降维方法效果就不是十分理想。此流行体实际上是一个二维分布的平面,在三维空间中流行体上点与点之间的距离不能使用传统的欧式空间的距离来计算,而应该用测地线距离代表这两个点的实际距离。
![yu3Cxs.jpg]()
Isomap基于前面所讲的MDS算法,所不同之处在于Isomap使用最短路径来计算样本点在高维空间中的距离。
Isomap的整体算法流程为:
输入:样本集\(D=\{x_1,x_2,...,x_n\}\);近邻数k;低维空间维数d。
过程:
- 对于任意样本点i,找到其最近的k个邻居,计算点i与这k个点的距离,以此构建邻接图和邻接矩阵;
- 使用Floyd或Dijkstra算法计算任意两点之间的最短路径距离,从而构建距离矩阵;
- 将距离矩阵输入到MDS算法获取输出。
输出:
样本点在低维空间的投影\(\{z_1,z_2,...,z_n\}\)。 -
参考链接
https://www.cnblogs.com/pinard/p/6251584.html
https://blog.csdn.net/qq_38800089/article/details/109333248
https://www.cnblogs.com/pinard/p/6244265.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号