RNN
-
什么是RNN
RNN(循环神经网络)是一种用于处理时序数据的特殊结构的神经网络。所谓时序数据,是指句子、语音、股票这类具有时间顺序或者是逻辑顺序的序列数据。
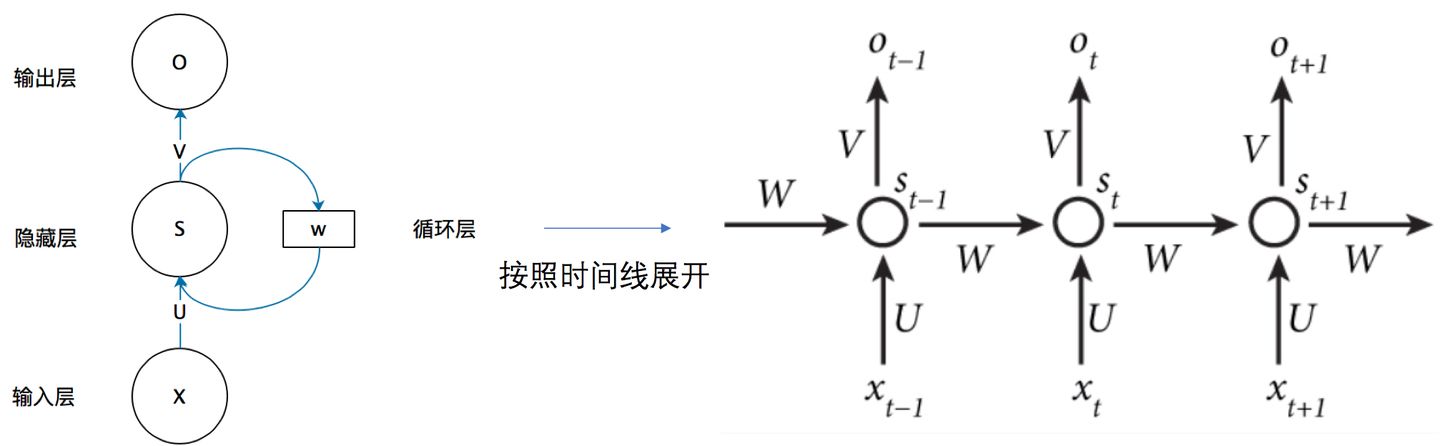
RNN的折叠图和展开图为:
![sc9eTx.jpg]()
RNN的参数为U、W和V三个矩阵,其中U为输出到隐藏层的参数矩阵,W为上一个时刻到当前时刻的参数矩阵,V为隐藏层到输出的参数矩阵。
RNN的整个过程用公式可以表示为:
\[s_t=f(Ux_t+Ws_{t-1}) \\ o_t=g(Vs_t) \]其中,f和g分别为隐藏层和输出层的激活函数。
RNN相比于传统的全连接神经网络的一个优点就是,隐藏层的神经元之间也是有连接的,这样的结构让RNN能够很自然的应用到语音识别、序列标注这类的任务当中。
-
RNN的求导过程
RNN的求导过程被称为BPTT(back-propagation through time),需要分别考虑对U、W和V三个参数的导数。
假设第t个时刻的损失为\(L_t\),则\(L_t\)对三个参数矩阵的导数分别为:
-
对U求导
由于\(s_t=f(Ux_t+Ws_{t-1})\),所以:
\[\frac{\partial s_t}{\partial U}=\frac{\partial s_t}{\partial U}+\frac{\partial s_t}{\partial s_{t-1}}\frac{\partial s_{t-1}}{\partial U} \\ =\frac{\partial s_t}{\partial U}+\frac{\partial s_t}{\partial s_{t-1}}(\frac{\partial s_{t-1}}{\partial U}+\frac{\partial s_{t-1}}{\partial s_{t-2}}\frac{\partial s_{t-2}}{\partial U}) \\ =... \\ =\sum_{i=1}^t\frac{\partial s_i}{\partial U}\prod_{j=i}^{t-1}\frac{\partial s_{j+1}}{\partial s_j} \]需要指出的是,上面式子中的偏导符号容易引起误解,若等式前后有相同偏导数符号,则等式前的需要考虑中间变量,等式后的不要考虑。
\[\frac{\partial L_t}{\partial U}=\frac{\partial L_t}{\partial o_t}\frac{\partial o_t}{\partial s_t}\frac{\partial s_t}{\partial U} \\ =\frac{\partial L_t}{\partial o_t}\frac{\partial o_t}{\partial s_t}(\sum_{i=1}^t\frac{\partial s_i}{\partial U}\prod_{j=i}^{t-1}\frac{\partial s_{j+1}}{\partial s_j}) \] -
对W求导
由于\(s_t=f(Ux_t+Ws_{t-1})\),所以:
\[\frac{\partial s_t}{\partial W}=\frac{\partial s_t}{\partial W}+\frac{\partial s_t}{\partial s_{t-1}}\frac{\partial s_{t-1}}{\partial W} \\ =\frac{\partial s_t}{\partial W}+\frac{\partial s_t}{\partial s_{t-1}}(\frac{\partial s_{t-1}}{\partial W}+\frac{\partial s_{t-1}}{\partial s_{t-2}}\frac{\partial s_{t-2}}{\partial W}) \\ =... \\ =\sum_{i=1}^t\frac{\partial s_i}{\partial W}\prod_{j=i}^{t-1}\frac{\partial s_{j+1}}{\partial s_j} \]\[\frac{\partial L_t}{\partial W}=\frac{\partial L_t}{\partial o_t}\frac{\partial o_t}{\partial s_t}\frac{\partial s_t}{\partial W} \\ =\frac{\partial L_t}{\partial o_t}\frac{\partial o_t}{\partial s_t}(\sum_{i=1}^t\frac{\partial s_i}{\partial W}\prod_{j=i}^{t-1}\frac{\partial s_{j+1}}{\partial s_j}) \] -
对V求导
\[\frac{\partial L_t}{\partial V}=\frac{\partial L_t}{\partial o_t}\frac{\partial o_t}{\partial V} \]
若使用RNN进行文本分类等只需要取最后一个时刻T的输出的任务,则总的梯度为:
\[\frac{\partial L}{\partial U}=\frac{\partial L_T}{\partial U} \\ \frac{\partial L}{\partial W}=\frac{\partial L_T}{\partial W} \\ \frac{\partial L}{\partial V}=\frac{\partial L_T}{\partial V} \]若使用RNN进行序列标注等需要取所有时刻的输出的任务,则总的梯度为:
\[\frac{\partial L}{\partial U}=\sum_{t=1}^T\frac{\partial L_t}{\partial U} \\ \frac{\partial L}{\partial W}=\sum_{t=1}^T\frac{\partial L_t}{\partial W} \\ \frac{\partial L}{\partial V}=\sum_{t=1}^T\frac{\partial L_t}{\partial V} \] -
-
RNN的梯度问题
以对W矩阵的导数为例:
\[\frac{\partial L_t}{\partial W}=\frac{\partial L_t}{\partial o_t}\frac{\partial o_t}{\partial s_t}(\sum_{i=1}^t\frac{\partial s_i}{\partial W}\prod_{j=i}^{t-1}\frac{\partial s_{j+1}}{\partial s_j}) \]注意到其中存在连乘项:
\[\prod_{j=i}^{t-1}\frac{\partial s_{j+1}}{\partial s_j} \]由于:
\[s_t=f(Ux_t+Ws_{t-1}) \]因此连乘项中的每一项都会携带一个激活函数的导数以及一个W矩阵。类似于在神经网络一节中所提及的那样,若激活函数选用Sigmoid或者是Tanh等具有正负饱和区的函数,则很容易出现梯度消失的现象;若参数矩阵W过大,则很容易出现梯度爆炸的现象。
解决方案有:
- 选用更好的激活函数;
- 将参数初始化得很小;
- 求导的时候对序列进行截断,只对一个较短的子序列进行求导;
- 改进RNN的结构,如LSTM、GRU,之后章节会介绍。
-
双向RNN
当使用RNN处理完形填空、命名实体识别等需要上下文的任务时,单向RNN所携带的前面时刻的信息是不够的。此时,考虑使用双向RNN来既考虑前面时刻的信息,也考虑后面时刻的信息。
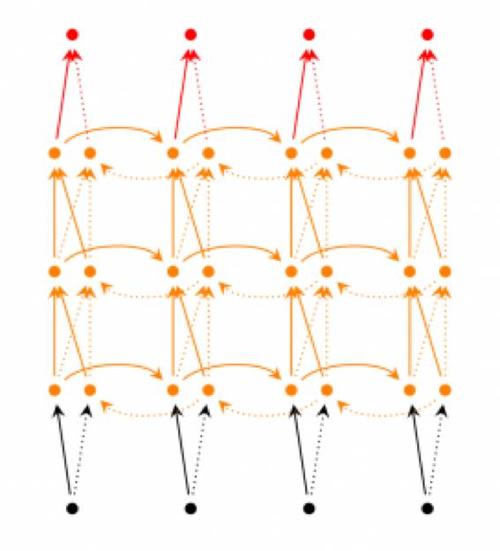
双向RNN的结构如下:
![scJULd.jpg]()
正向RNN对序列进行正向编码,反向RNN对序列进行反向编码,然后把每个时刻的正反状态拼接起来送到输出层,用公式可以表示为:
\[s_{f,t}=f(U_fx_t+W_fs_{t-1}) \\ s_{b,t}=f(U_bx_t+W_bs_{t-1}) \\ o_t=g(V[s_{f,t},s_{b,t}]) \]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号