基本数据类型
一、字符串
1. 基本概念
计算机系统的每个内存单元都是唯一并且连续的物理地址,字符串在内存中一旦创建就被操作系统分配一块唯一并且连续的地址。计算机系统不允许我们修改字符串中的内容,一旦我想试图进行修改,系统马上报错。但如果我们想修改其中的内容,计算机系统会为我们开辟一块新的内存空间。例如:newstring是新生成的内存
oldstring = "周杰伦的烟花易冷" newstring = oldstring. replace("周杰伦", "林志炫")
python字符串的 “+” 是不太建议使用的,就下面这段代码来聊一聊这即将被取代的 “+”
1 string_1 = "abc" 2 string _2 = "def" 3 string = string _1 + string _2
根据基本定义,上面这段代码会产生三个内存,string是string_1 和 string_2的叠加版本,换句话说,如果string_1 和 string_2在接下来的程序中没有用到,那他们的内存基本就是浪费了,看看下面这张图:
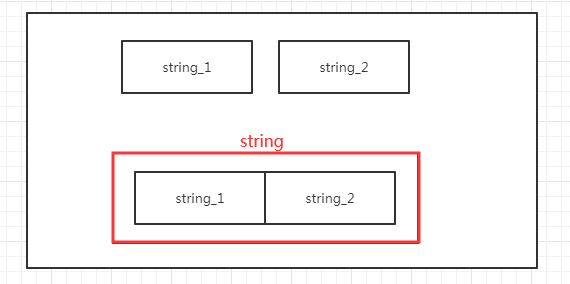
在python3.6以前,我们常用 “ += ” 来替代上面的加号,在python3.6之后,我们一般使用 “ f ' { name } ' ”(name是一个变量)
2. 两个典型的函数
maketrans函数 和 替换函数
maketrans(x, y=None, z=None, /) 、 translate(...) 和 replace()。maketrans函数用于建立键值对的映射,而替换函数translate函数和replace函数的使用各有千秋。下面将用一个例子来说明的他们的作用。
例如:使maketrans 与 translate的结合
string = "abcdefghijk" setKY = str.maketrans("abcd","----") #Set built-in print(string.translate(setKY)) #输出:----efghijk
例如:replace的使用
string = "abcdabcdabcdabcd" print(string.replace("ab",'--',2)) #参数2表示替换目标序列的前两个子序列 print(string.replace("ac",'--',2)) #替换无效,还是原样输出
expandtabs()函数
使用该函数将指定的n个字符为单位,当字符对象不足n个字符时,自动为对象字符填充剩余的空格。例如:
test = “username\temail\tpassword\nLynnLee\t nLynnLee.@qq.com\t123\n nLynnLee\t nLynnLee.@qq.com\t123\n” v = test.expandtabs(20) print(v) 结果为: username email password LynnLee nLynnLee.@qq.com 123 nLynnLee nLynnLee.@qq.com 123
3. 常用字符串函数
大小写转化
lower(self) #转化为小写 upper(self) #转化为大写 swapcase(self) #大小写互换 title(self) #将self转成标题,每一个单词的首字母变为大写 capitalize(self) #self首字母大写 casefold(self) #将self中的字母变为小写
字符位置处理
center(self, width, fillchar=None) #指定self的总宽度并居中 rjust(self, width, fillchar=None) #指定self的总宽度并右对齐 ljust(self, width, fillchar=None) #在指定宽度单位的self中向左对齐 join(self, iterable) #将iterable通过self连接,self作为分隔符 split(self, sep=None, maxsplit=-1) #将参数作为分隔符,可指定分隔的次数,但参数无法出现才结果集中 rsplit(self, sep=None, maxsplit=-1) #与split功能相同,但rsplit从右开始 splitlines(self, keepends=None) #只根据换行符进行分隔,参数为True是保留换行符,反之不保留 strip(self, chars=None) #默认情况下移除self两边的空格 lstrip(self, chars=None) #默认情况下移除self左边的空格 rstrip(self, chars=None) #默认情况下移除self右边的空格 expandtabs(self, tabsize=8) #默认为self指定8个单位,不足时以空格补充
字符查找
count(self, sub, start=None, end=None) #统计self中指定的sub(子串)的个数 find(self, sub, start=None, end=None) #查找self中指定的sub(子串)的索引位置,找不到则返回-1或 rfind(self, sub, start=None, end=None) #与find不同的是查找的是self中最右的sub(子串)的索引位置 index(self, sub, start=None, end=None) #查找self中指定的sub(子串)的索引位置,找不到则抛出ValueError rindex(self, sub, start=None, end=None) #与index不同的是查找的是self中最右的sub(子串)的索引位置
字符检查
isalnum(self) #判断self中是否包含数字、字母或者两者,其余情况为False isalpha(self) #判断self中是否仅包含字母或者中文 isdecimal(self) #判断self中是否仅包含十进制数 isdigit(self) #判断self中是否仅包含数字 isnumeric(self) #判断self中是否仅包含数字(能识别中文数字) isidentifier(self) #判断self中是否符合系统变量的命名规则 isprintable(self) #判断self中是否可打印,如果存在打印不可见的字符(如“\t或\n… …”)则为False isspace(self) #判断self中是否全为空格 istitle(self) #判断self是否为标题(首字母大写) isupper(self) #判断self是否全为大写字母 endswith(self, suffix, start=None, end=None) #判断self是否以suffix结尾 startswith(self, prefix, start=None, end=None) #判断self是否以prefix开头
字符转化
#将字典的字符转化为Unicode或设置键值对形成Unicode字典 maketrans(self, *args, **kwargs) #指定table的Unicode字典将替换self中的字符,与maketrans连用 translate(self, table) #将self指定的old替换为new,count为替换的次数,默认替换所有 replace(self, old, new, count=None) #返回一个元组,该元组的内容包含(head, sep, tail) rpartition(self, sep) encode(self, encoding='utf-8', errors='strict') #编码 decode(self, encoding='utf-8', errors='strict') #解码
二、列表
1. 基本概念
列表 List,本质是一个链表,从链表的实现角度来讲,链表的每一个结点都存放着值和指向下一个节点的指针。因此链表在内存的存储可以是不连续的,它是一种高效的数据结构。因此列表与字符串的区别是列表可以进行任意的修改。并且,列表的元素是任意的数据类型。当然,它支持循环、切片等多种操作。如果我们对列表进行切片,那结果仍是一个列表。
列表在对某个序列进行转换的时候,内部是通过循环进行的,而数字不能作为循环的对象因此数字不能转化为列表;而当列表转化为字符串的时候,字符串函数将整个列表作为字符串,这种做法让字符串变得丑陋,如果想变得美观可以自己写循环解决。
# 将字符 => 列表 string = "abcdefg" print(list(string)) # ['a', 'b', 'c', 'd', 'e', 'f', 'g'] # 列表 => 字符串 string = "" for i in [1,2,3,4, 'cnblog']: string += str(i) print(string) # 1234cnblog # 或 print("".join(['a', 'b', 'c', 'd', 'cnblog'])) # abcdcnblog
2. 列表的用途
用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。
li = ["1","2","3","4","5"] li.append("6") print(li) # 输出:['1', '2', '3', '4', '5', '6'] del_li = li.pop() # 不加参数的pop print(del_li) # 获取删除的值:6 print(li) # 显示删除结果:['1', '2', '3', '4', '5']
我们也可以把列表当做队列使用,队列作为特定的数据结构,最先进入的元素最先释放(先进先出)。不过,列表这样用效率不高。相对来说从列表末尾添加和弹出很快;在头部插入和弹出很慢(因为,为了一个元素,要移动整个列表中的所有元素)。要实现队列,使用 collections.deque,它为在首尾两端快速插入和删除而设计。例如:
from collections import deque # 导入 collections模块的deque函数 li = ["Lily","Lynn Lee","John"] queue = deque(li) # 使用deque函数 queue.append("Alger") # 往队列插入数据 queue.popleft() # 删除头部 print(queue) # 打印结果:deque(['Lynn Lee', 'John', 'Alger'])
3. 列表推导式
列表推导式由包含一个表达式的括号组成,表达式后面跟随一个 for 子句,之后可以有零或多个 for 或 if 子句。结果是一个列表,由表达式依据其后面的 for 和 if 子句上下文计算而来的结果构成。它的表达式的一般形式为:[ 表达式 for [ if 子 句 ] ] 。 下面将以简单的例子说明列表推导式的作用。
# 应用一: 生成列表中x的2次幂 # 不使用列表推导式 li = list(map(lambda x: x**2, range(10))) print(li) #打印结果为:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81] # 使用列表推导式 li = [x**2 for x in range(10)] print(li) #打印结果为:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81] # 应用二: 按两个列表元素不同的条件生成坐标 # 不使用列表推导式 li = [] for x in [1,2,3]: for y in [3,4,5]: if x != y: li.append((x, y)) print(li) #输出:[(1, 3), (1, 4), (1, 5), (2, 3), (2, 4), (2, 5), (3, 4), (3, 5)] # 使用列表推导式 li = [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y] print(li) #输出:[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
列表推导式的一般形式为:[ 表达式 for [if子句] ],在这里表达式如果不是简单的一条语句应该使用括号括起来。
# 不用括号括起来:报错(语法错误) [x, x**2 for x in range(6)] #报错 # 用括号括起来:正常执行 from math import pi li = [str(round(pi, i)) for i in range(1, 4)] print(li) #输出:['3.1', '3.14', '3.142']
应用举例:交换矩阵的行列
mylist = [ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], ] #第一个推导式获取原矩阵的三行数据,然后对于每一行一次打印 li = [ [row[i] for row in mylist] for i in range(4) ] print(li) #输出[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
三、字典
1. 基本概念
字典dict,存储的元素是一种无序的键值对(K-V),字典的K值为任意不可变数据类型(如:字符串、数字、元组),V值为任意数据类型。在计算机内部保存数据的时候是用哈希表表示的,列表不支持转化为哈希表的原因是K是变化的(列表可以增、删、改),而元组却可以用哈希表表示。由于它的无序性,使得它不能像列表那样使用切片。但是我们能对字典的中的K—Y值进行更改。使用for循环时(不能使用while),默认之只输出K值,不输出V值。当然,在字典中也提供了相应的内置函数弥补这个缺陷。
还有一点需要注意,当字典中有两个相同的K值时,前一个V值会被后一个V值覆盖。这里介绍一个典型的例子。比如当K值为bool类型的时,计算机认为True为1,False为0,若它前面的K值有0或者1,则将会被覆盖掉。在输出时True被替换为1,False被替换为0。By the way,bool类型的非零值在计算机内部都会被表示为1。使得bool类型为False的值有0, 空(None ),空字符串( " " ), 空元组( ( ) ),空列表( [ ] ),空字典( { } ),空集合( set( ) )。
info = { 1:1, True:123, #覆盖前一个的V值 False:456, "k7":["a","b","c","d"], "k7":("e","f","g","h",), #覆盖前一个的V值 } print(info) #输出:{1: 123, 'k7': ('e', 'f', 'g', 'h')}
2. 字典常用的内置函数
# fromkeys(*args, **kwargs)函数:是静态方法 #根据序列创建字典,由**kwargs指定统一的值 v = dict.fromkeys(["k1","k2","k3"],"see") print(v) #输出:{'k1': 'see', 'k2': 'see', 'k3': 'see'} # setdefault()函数: 设置默认值,若设置的值已存在,则返回已存在的value dic_ky = {"k1":"001","k2":"002"} v1 = dic_ky.setdefault('k3','003') #k3不存在,插入字典后返回一个值 v2 = dic_ky.setdefault('k1','111') #设置失败,返回看字典K1的原值001 print(v1) #输出:003 print(v2) #输出:001 # update()函数: 更新字典 #第一种方法 dic_ky = {"k1":"001","k2":"002"} dic_ky.update({'k1':'111','k2':222}) print(dic_ky) #输出:{'k1': '111', 'k2': 222} #第二种方法 dic_ky.update(k1='a',k2='b',k3='c',k4='d') print(dic_ky) #输出:{'k1': 'a', 'k2': 'b', 'k3': 'c', 'k4': 'd'} # keys函数、values()函数、 items()函数 for i in info.keys(): # keys函数: 取K值 print(i) for i in info.values(): # values()函数: 取V值 print(i) for k,v in info.items(): # 取K-V值,循环时需要使用两个迭代变量k,v print(k,v) # get(d=None)函数: 安全的取值函数,当取的K不存在时不会报错 v = info.get('k',"ERROR") #ERROR是不存在时返回的值,若该参数忽略,则返回None print(v) #输出:ERROR # pop()函数: 将指定K值的V删除,返回值可以接收被删除的V值 v = info.pop('k',"ERROR") #ERROR是不存在时返回的值,若该参数忽略,则返回None print(v) #输出:ERROR # popitem()函数: 返回被随机删除的键值对 k,v = info.popitem() #返回被随机删除的键值对 print(k,v) #输出:k8 ('e', 'f', 'g', 'h') # clear()函数 和 copy()函数不再列出。。。
四、元组
元组tuple,作为列表的升级版,是一种非常安全的数据结构。它的一级元素只能查,不能增、删、改。除此之外,列表支持的操作,元组都能支持。元组还可以实现封装和拆封。当我们要创建的数据不希望被修改时,请放心大胆地使用元组。如果我们真的需要对元组进行修改,我们可以间接进行(可转化为列表或字符串)。
元组在输出时总是有括号的,以便于正确表达嵌套结构。在输入时可以有或没有括号,不过带括号是一种更好的规范。为区别于函数,最好的习惯是在元组的最后加上逗号。虽然元组和列表很类似,它们经常被用来在不同的情况和不同的用途。元组有很多用途。例如 (x, y) 坐标对,数据库中的员工记录等等。元组的内置函数仅仅只提供了两个,分别是:count(value) 和 index(value, strat=None, stop=None)。
# 1. 元组可作为可迭代对象 li = [1,2,3,4,5] li.extend((6,7,8,9,)) #将元组向列表中追加 print(li) #输出:[1, 2, 3, 4, 5, 6, 7, 8, 9] # 2. 元组一级元素不可修改 tu = ("me","you",[(1,2,)],["abcd"],True,False,4,44,) value = tu[2][0][0] #取值 print(value) #输出: 1 tu[2][0] = 1122 #可修改,因为不是元组一级的元素 print(tu) #输出:('me', 'you', [1122], ['abcd'], True, False, 4, 44) tu[2][0][0] = 1111 #报错TypeError:只要是某个元组一级元素就不能被修改 # 3. 元组的封装和拆封 tu = (1, 2, 3, 'hello!') #封装过程 x, y, z, m = tu #拆封过程 print(x,y,z,m) #输出:1 2 3 hello!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号