尚硅谷云原生实战学习笔记
 尚硅谷云原生实战学习笔记,学吧,学无止境。
尚硅谷云原生实战学习笔记,学吧,学无止境。
尚硅谷云原生实战学习笔记
我不会设置仅粉丝可见,不需要你关注我,仅仅希望我的踩坑经验能帮到你。如果有帮助,麻烦点个 👍 吧,这会让我创作动力+1 😁。我发现有的时候会自动要求会员才能看,可以留言告诉我,不是我干的!😠
写在前面
-
感想 | 摘抄 | 问题
- 层层恐惧:Pod、Deploy、Service、Ingress
- 什么是微服务
1. 引入
-
云平台核心
没有一种云计算类型适用于所有人。多种不同的云计算模型、类型和服务已得到发展,可以满足组织快速变化的技术需求。
部署云计算资源有三种不同的方法:公共云、私有云和混合云。采用的部署方法取决于业务需求。
-
为什么用云平台
- 环境统一
- 按需付费
- 即开即用
- 稳定性强
国内常见的云平台:阿里云、百度云、腾讯云、华为云、青云。。。
国外常见云平台:亚马逊AWS、微软Azure、。。。
-
公有云:购买云服务商提供的公共服务器
公有云优势:
- 成本更低
- 无需维护
- 近乎无限制的缩放性
- 高可靠性
-
私有云:自己搭建云平台,或者购买
-
-
云平台操作
-
安全组:防火墙相关的度端口设置,如果不开端口,也无法外网访问
-
入方向规则中需要手动添加目的端口,才能访问
-
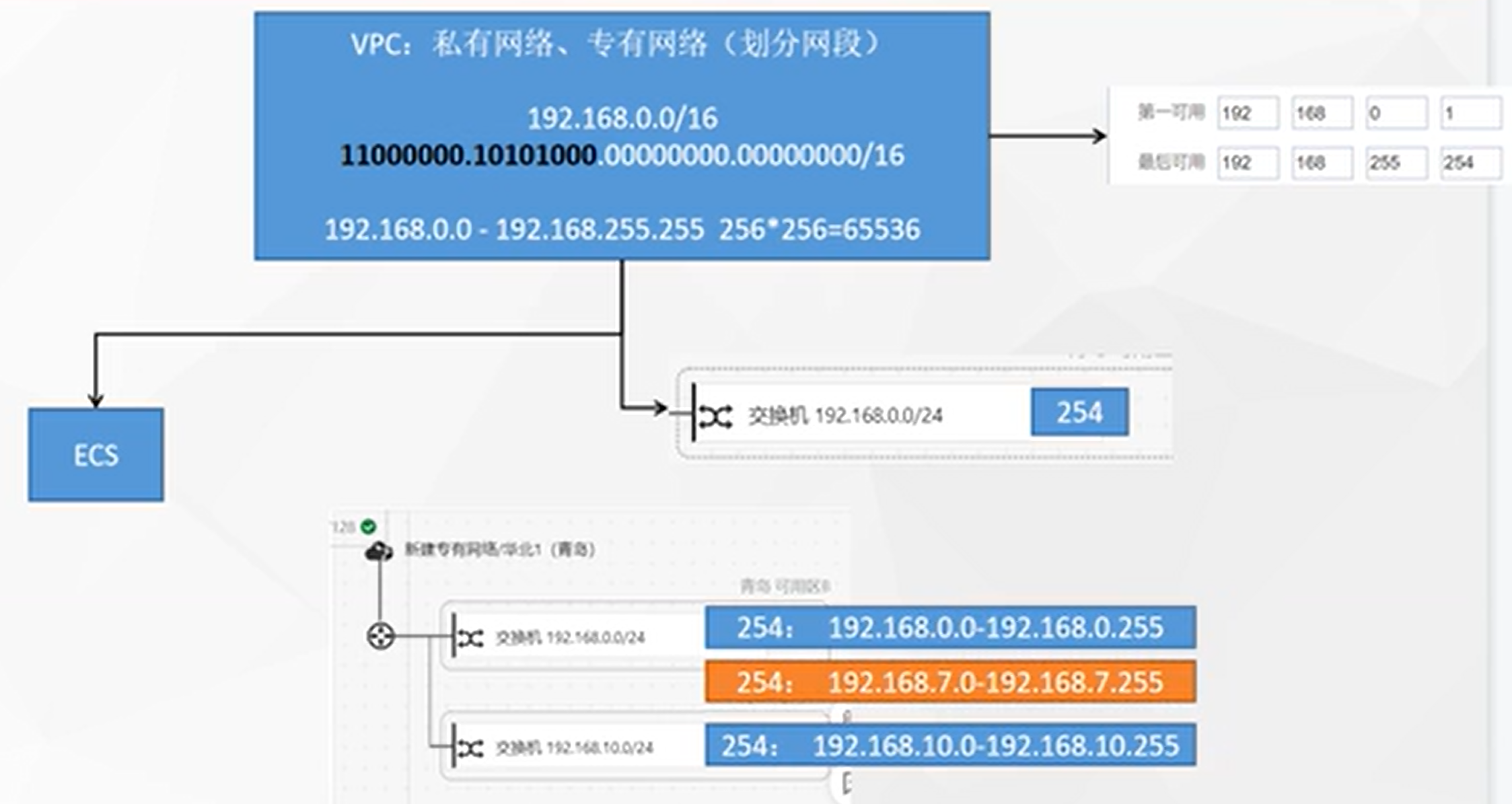
VPC:更多是进行隔离,比如开发和生产分别在不同的VPC网络下,不同的VPC之间是完全隔离的
![在这里插入图片描述]()
-
2. Docker基础
-
Docker基本概念
-
解决的问题
-
统一标准
- 应用构建
- java、C++、js
- 打成软件包
- .exe
- docker build...镜像
- 应用分享
- 所有软件的镜像放到一个指定地方 docker hub
- 安卓,应用市场
- 应用运行
- 统一标准的镜像
docker run
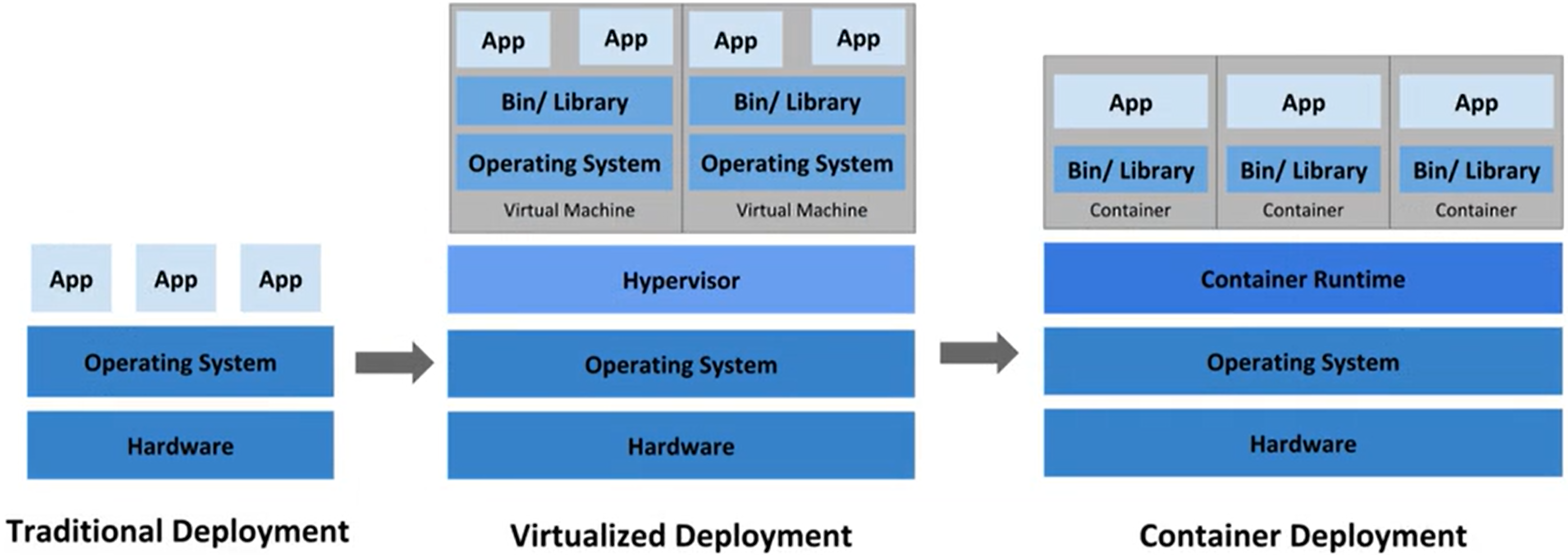
容器化时代
- 应用构建
-
虚拟化技术
- 基础镜像GB级别
- 创建使用稍微复杂
- 隔离性强
- 启动速度慢
- 移植与分享不方便
-
容器化技术
- 基础镜像MB级别
- 创建简单
- 隔离性强
- 启动速度秒级
- 移植与分享方便
-
-
资源隔离:
- cpu、memory资源隔离与限制
- 访问设备隔离与限制
- 网络隔离与限制
- 用户、用户组隔离限制
-
架构
![在这里插入图片描述]()
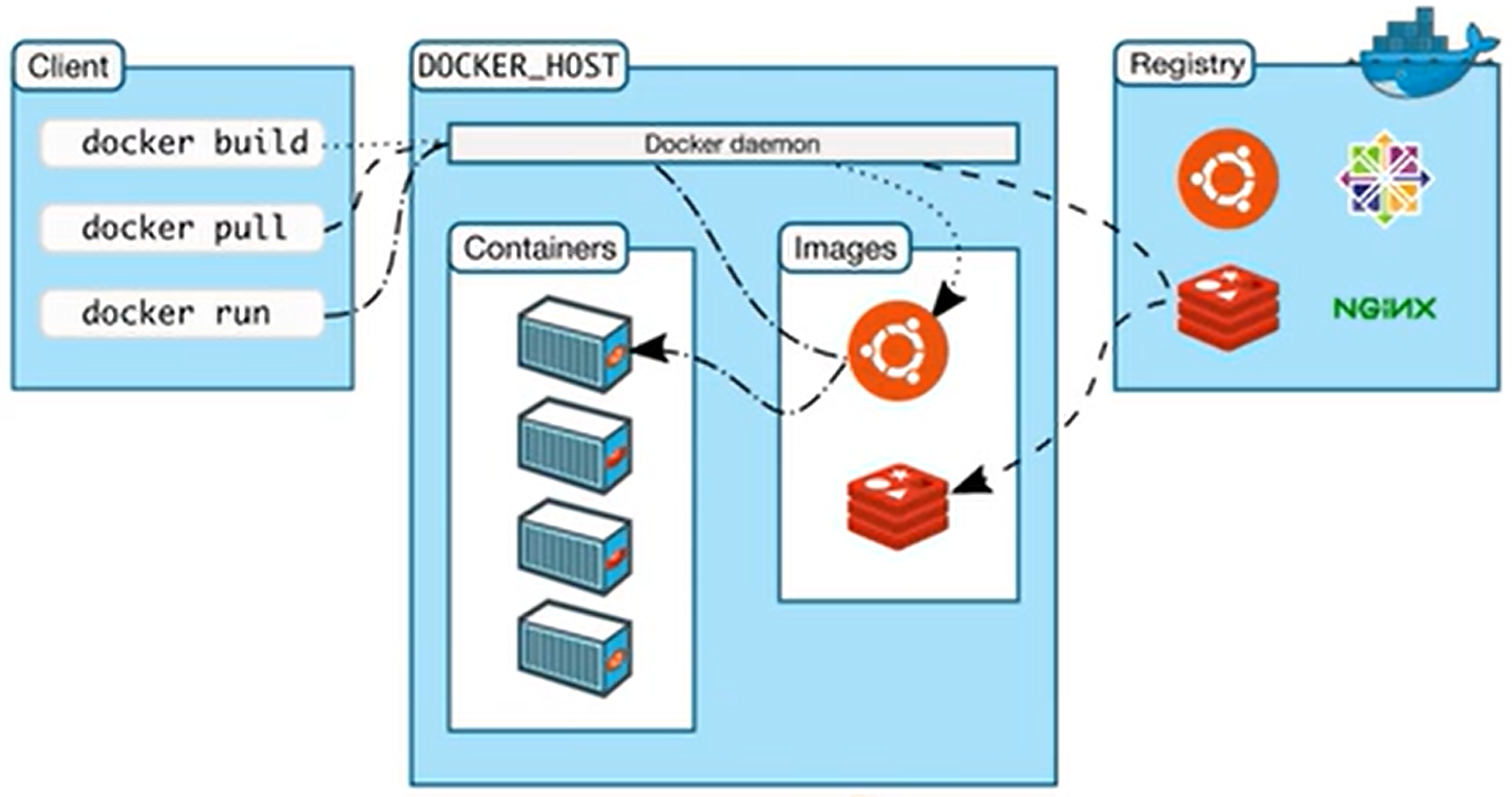
- Docker Host:安装Docker的主机
- Docker Daemon:运行在Docker主机上的Docker后台进程
- Client:操作Docker主机的客户端(命令行、UI等)
- Registry:镜像仓库、Docker Hub
- Images:镜像,带环境打包好的程序,可以直接启动运行
- Containers:容器,由镜像启动起来正在运行中的程序
交互逻辑:装好Docker,然后去 软件市场 寻找镜像,下载并运行,查看容器状态日志等排错。
-
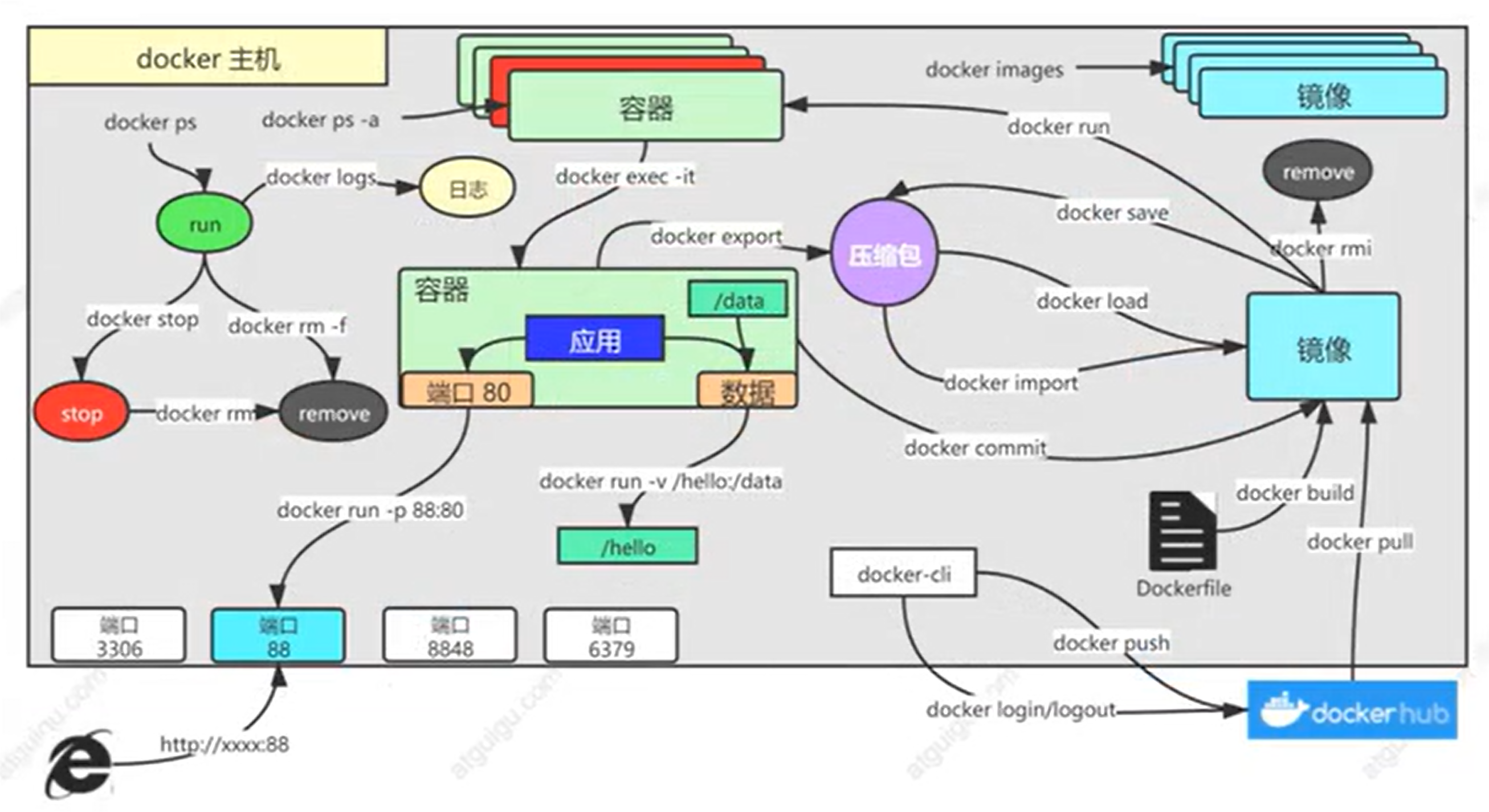
Docker常用命令
![在这里插入图片描述]()
-
容器运行
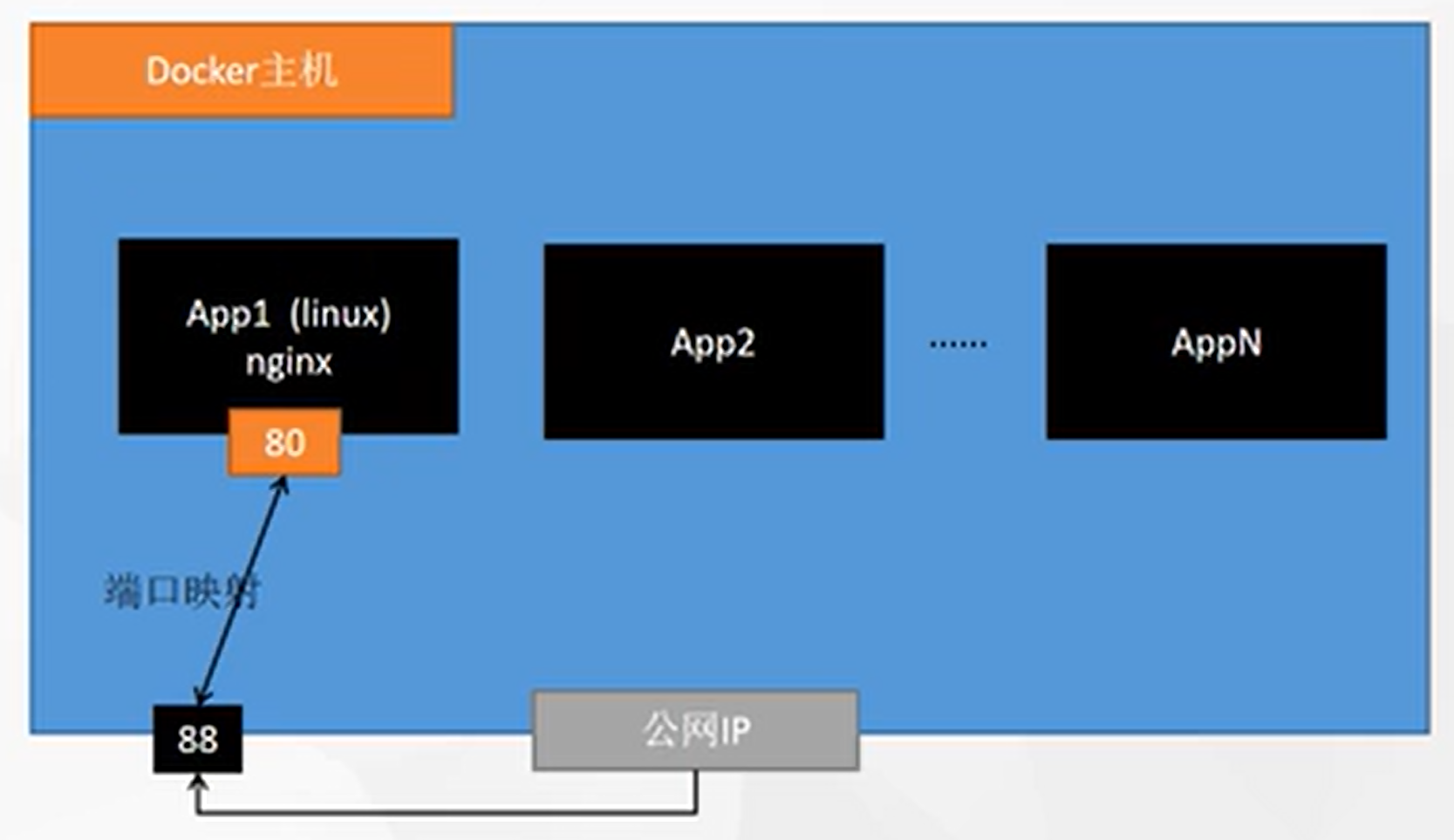
![在这里插入图片描述]()
docker run --name=mynginx -d --restart=always nginx-
--restart=always:容器随着docker开机自启 -
👿 如果创建容器的时候,没有指定参数,可以通过:
docker update 容器id --restart=always。但是update无法修改端口,如果要做端口映射,则要重启容器。
-
-
进入容器修改内容:
docker exec -it 容器id /bin/bash- 有的容器没有 bash,可以试试
/bin/sh
- 有的容器没有 bash,可以试试
-
提交改变:
docker commit -a "lihuowang" -m "提交内容备注" 容器ID 自己定义的镜像名:tag -
镜像保存:
docker save -o xxx.tar 镜像名:tag镜像加载:
docker load -i xxx.tar -
镜像推送:
docker tag 本地镜像:tag 新仓库:tag,docker push 新仓库:tag- 这里的 新仓库:远程新建的仓库,比如:
lihuowang/本地镜像把旧镜像的名字,改成仓库要求的新办名字 - 当然,需要登录:
docker login
- 这里的 新仓库:远程新建的仓库,比如:
-
挂载数据:
docker run --name=xxx -d --restart=always -p 88:80 -v /data/html:/usr/share/nginx/html:ro nginx- ro: readonly
- rw: read and write
- 修改页面只需要去主机修改即可同步到容器中
-
日志查看:
docker logs 容器名 -
进入容器:
docker exec -it 容器名 /bin/bash -
从容器中复制东西到宿主机:
docker cp 容器id:/etc/nginx/nginx.conf /data/conf/nginx.conf,反过来一样
-
-
-
实战和进阶
-
redis启动:
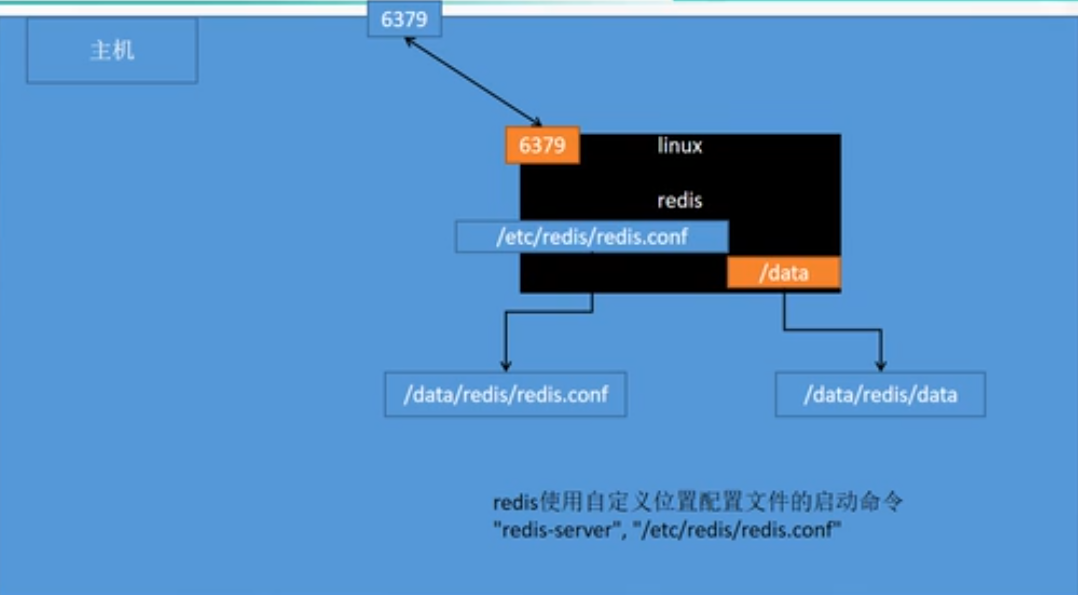
docker run --privileged=true -v E:\11-container\huazhi-redis\redis.conf:/etc/redis/redis.conf -v E:\11-container\huazhi-redis\data\:/data -d --name=huazhi-redis -p 6379:6379 redis:7.4 redis-server /etc/redis/redis.conf![在这里插入图片描述]()
-
把应用打包成镜像
-
以前,以java为例
- SpringBoot打包成可执行的jar
- 把jar上传给服务器
- 服务器运行
java -jar xx.jar
-
现在:所有机器都安装docker,任何应用都是镜像,所有机器都可以运行
-
Dockerfile
FROM openjdk:8-jdk-slim LABEL maintainer=huowang COPY xxx/target/*.jar /app.jar ENTRYPOINT ["java", "-jar", "/app.jar"] -
构建镜像:
docker build -t java-demo:v1.0 [-f Dockerfile] .,如果要指定Dockerfile可以加-f,注意最后要加.表示当前路径
-
-
-
启动容器:
docker run -d -p 8080:8080 --name myjava-app java-demo:v1.0 -
查看容器运行日志:
docker logs 容器ID,跟踪查看:docker logs -f 容器ID
-
-
开发完了怎么迁移到新的环境呢
docker logindocker tag xxx:v1.0 yyy/xxx:v1.0docker push yyy/xxx:v1.0docker pull yyy/xxx:v1.0docker run -d -p 8080:8080 --name zzz xxx:v1.0
3. Kubernetes实战入门
Kubernetes基础概念
-
是什么
我们急需一个大规模容器编排系统
![在这里插入图片描述]()
kubernetes具有以下特征:
- 服务发现和负载均衡:Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
- 存储编排:Kubernetes 允许你自动挂载你选择的存储系统,比如本地存储,类似Docker的数据卷。
- 自动部署和回滚:你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态更改为期望状态。Kubernetes 会自动帮你根据情况部署创建新容器,并删除现有容器给新容器提供资源。
- 自动完成装箱计算:Kubernetes 允许你设置每个容器的资源,比如CPU和内存。
- 自我修复:Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的容器,并运行状况检查的容器。
- 秘钥与配置管理:Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth令牌和ssh密钥。你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
kubernetes 为你提供了一个可弹性运行分布式系统的框架。kubernetes 会满足你的扩展要求、故障转移、部署模式等。例如,Kubernetes 可以轻松管理系统的 Canary 部署。
-
架构
-
工作方式:kubernetes Cluster = N master node + N worker node(N >= 1)
-
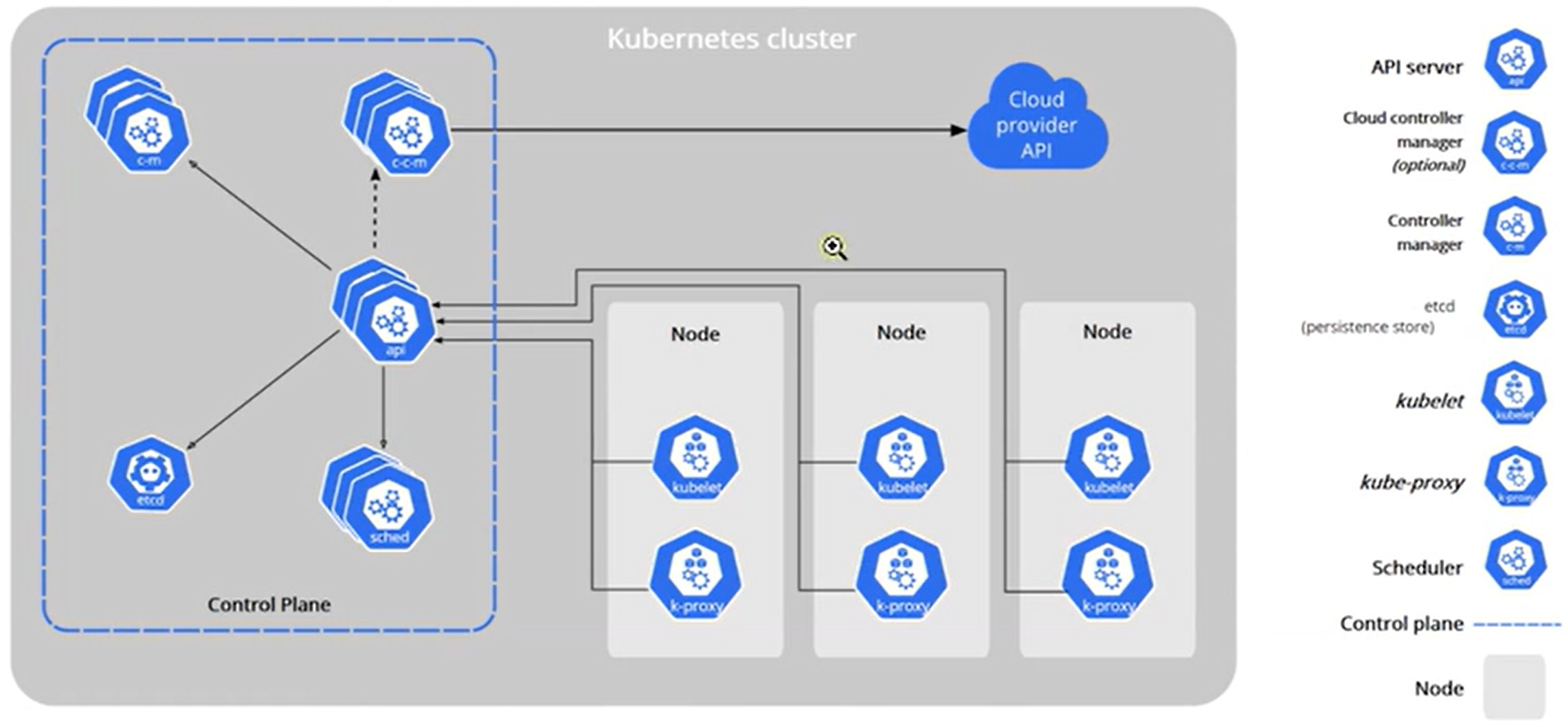
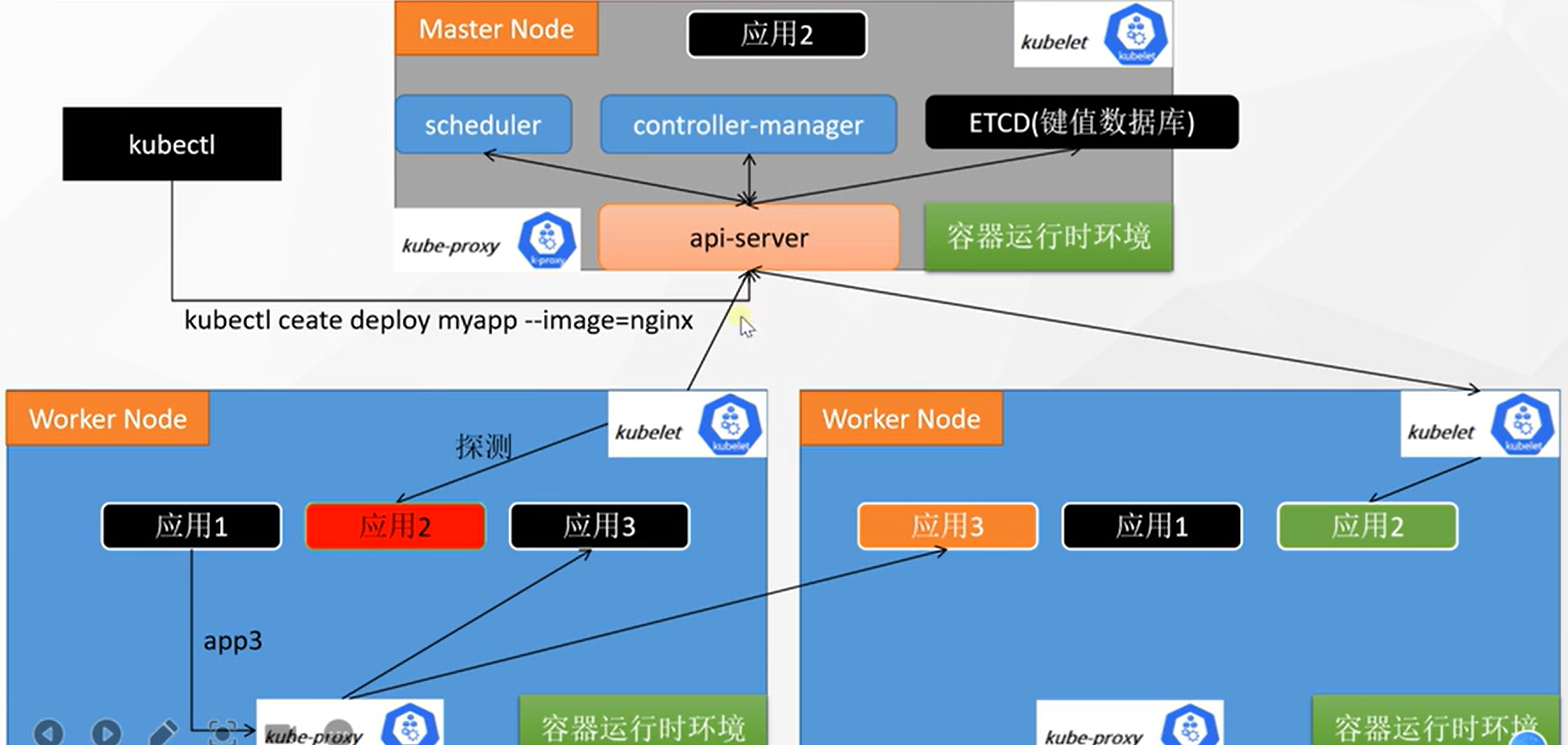
组件架构
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
- 集群中所有组件的交互都是通过 api-server 的 (秘书处)
- 集群中所有的网络访问都是通过 kube-proxy 的 (看门大爷)
- 集群中所有要运行的应用程序都要有一个容器运行时环境
- 每一个集群节点都要有一个 kubelet (监工,厂长),来监控节点的应用状态,并向 api-server 汇报
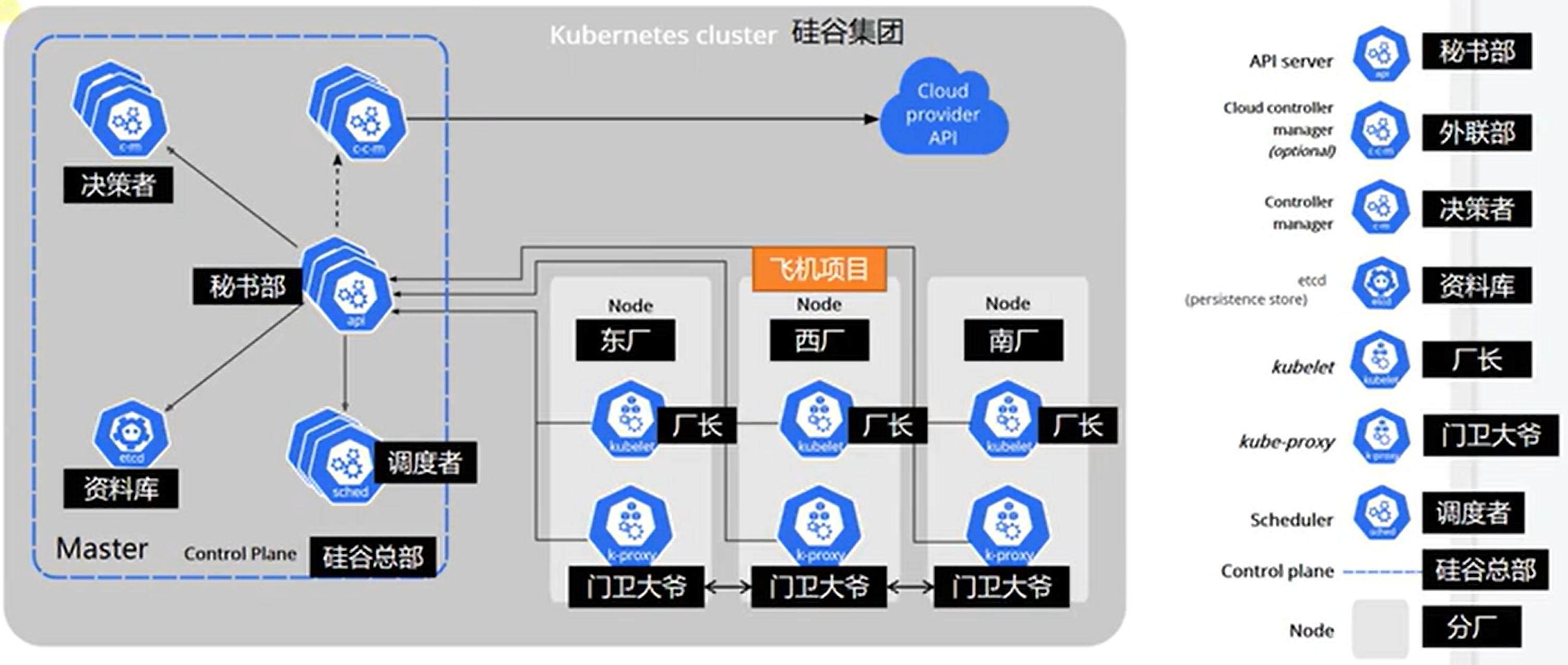
k8s架构
-
控制平面组件(Control Plane Components)
控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)。控制平面组件可以在集群中的任何节点上运行。然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。请参阅 使用 kubeadm 构建高可用性集群 中关于多 VM 控制平面设置的示例。
1.1 kube-apiserver 秘书处 api
API 服务器是 Kubernetes 控制面的组件,该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平伸缩,也就是说,它可通过部署多个实例进行伸缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
1.2 etcd 资料库 etcd
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。您的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。要了解 etcd 更深层次的信息,请参考 etcd 文档。
**1.3 kube-scheduler ** 调度者 sched
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
1.4 kube-controller-manager 决策者 c-m
在主节点上运行 控制器 的组件。
从逻辑上讲,每个控制器都是一个单独的进程,但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
1.5 cloud-controller-manager 外联部 c-c-m
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面 组件。 云控制器管理器允许您链接集群到云提供商的应用编程接口中, 并把和该云平台交互的组件与只和您的集群交互的组件分离开。
cloud-controller-manager仅运行特定于云平台的控制回路。如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境,所部署的环境中不需要云控制器管理器。与kube-controller-manager类似,cloud-controller-manager将若干逻辑上独立的控制回路组合到同一个可执行文件中,供你以同一进程的方式运行。你可以对其执行水平扩容(运行不止一个副本)以提升性能或者增强容错能力。下面的控制器都包含对云平台驱动的依赖:
- 节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
- 路由控制器(Route Controller): 用于在底层云基础架构中设置路由
- 服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
-
Node组件
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
2.1 kubelet 厂长 kubelet
一个在集群中每个节点(node)上运行的代理。它保证容器(containers)都运行在 Pod 中。kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。kubelet 不会管理不是由 Kubernetes 创建的容器。
2.2 kube-proxy 门卫大爷 k-proxy
kube-proxy 是集群中每个节点上运行的网络代理,实现 Kubernetes 服务(Service) 概念的一部分。kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则,kube-proxy 仅转发流量本身。
-
-
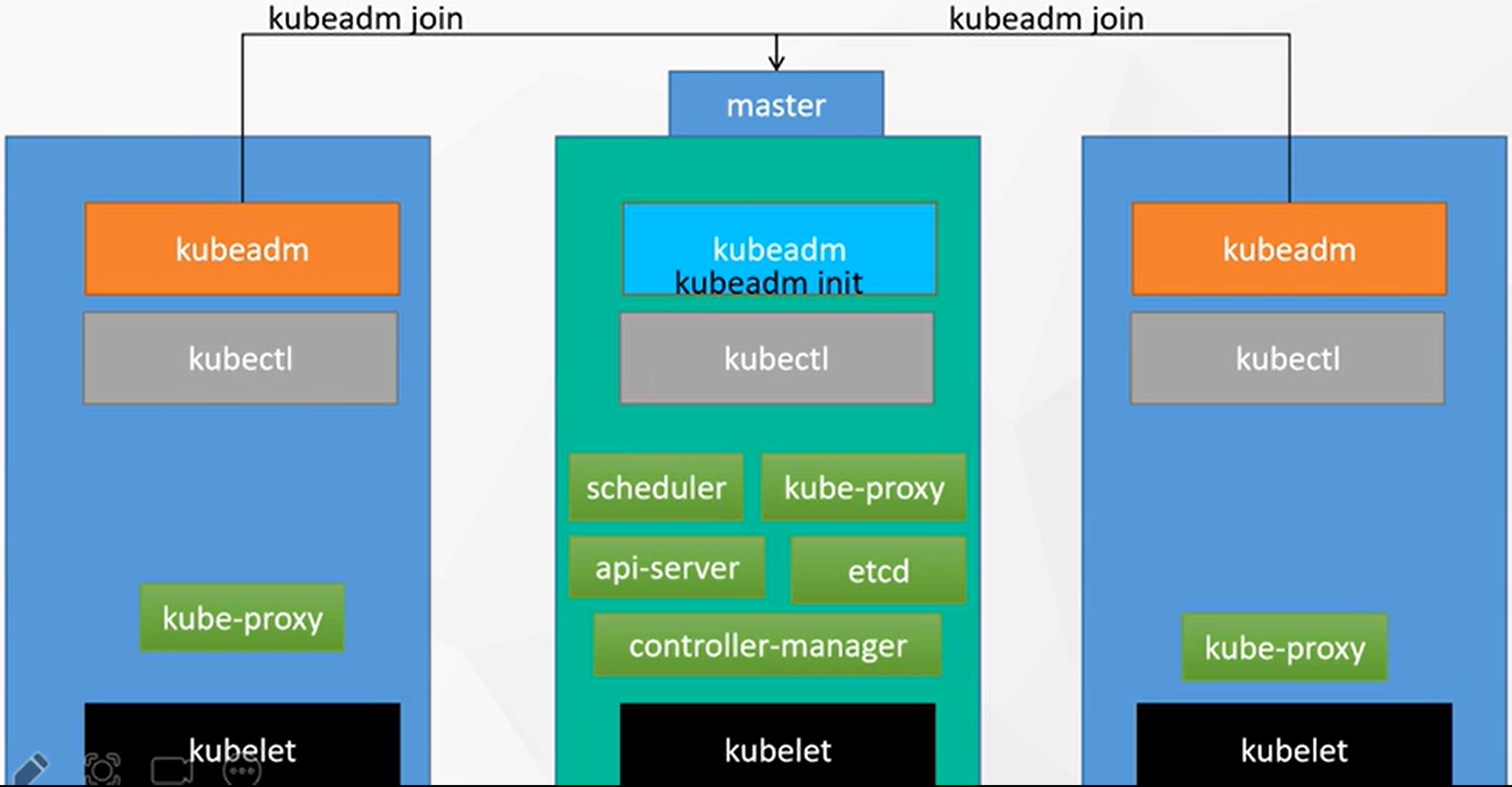
kubeadm创建集群
![在这里插入图片描述]()
- 设置主机名:
hostnamectl set-hostname xxx
-
安装kubeadm
-
一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
-
每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
-
2 CPU 核或更多
-
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 设置防火墙放行规则
-
节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
- 设置不同hostname
-
开启机器上的某些端口。请参见这里 了解更多详细信息。
- 内网互信
-
禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区。
- 永久关闭
-
-
所有机器执行以下操作:
#各个机器设置自己的域名 hostnamectl set-hostname xxxx # 将 SELinux 设置为 permissive 模式(相当于将其禁用) sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config #关闭swap swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab #允许 iptables 检查桥接流量 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sudo sysctl --system -
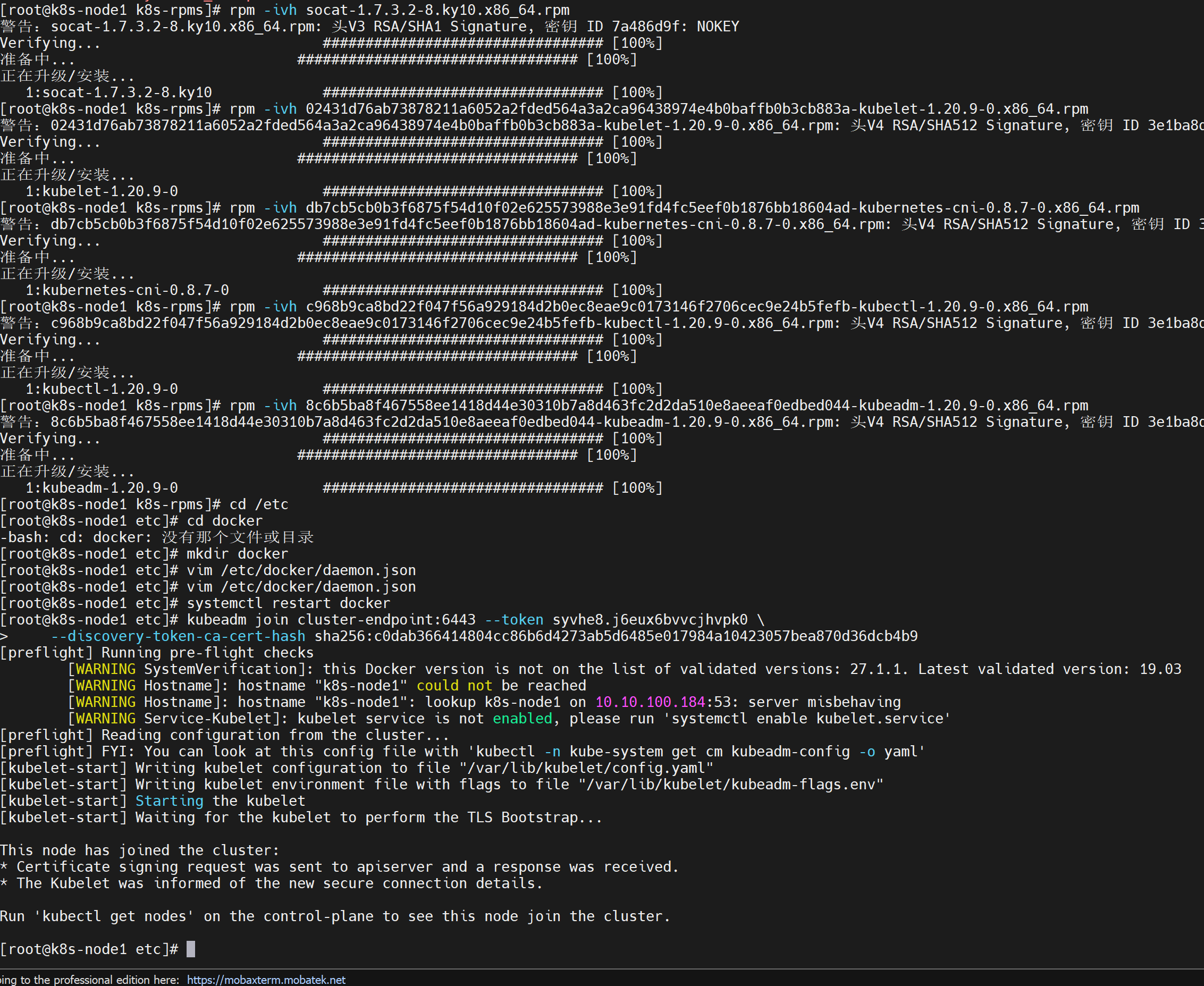
安装kubelet、kubeadm、kubectl
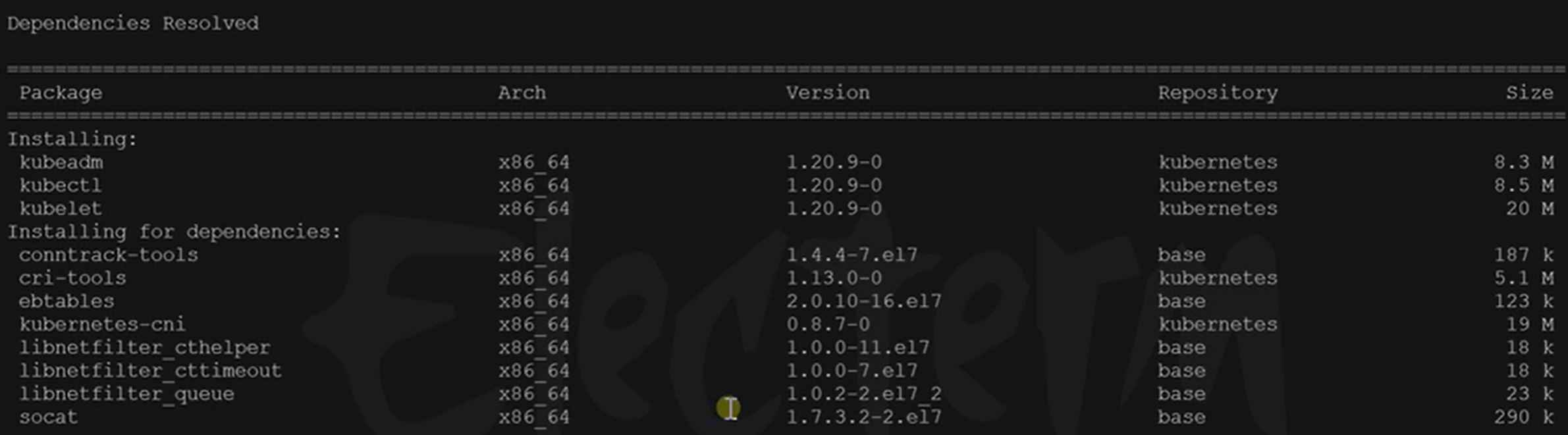
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg exclude=kubelet kubeadm kubectl EOF sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 --disableexcludes=kubernetes # 启动kubelet sudo systemctl enable --now kubelet![在这里插入图片描述]()
Installing:
Installing for dependencies
**我的离线安装:[1.20.9] **
下载正主及其依赖的rpm包:
-
https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/Packages/,在这里选择老师的,1.20.9,没错,我是试错回来了。。。 -
由于下面的内容已经经历过了,所以我直接开始安装:
-
kubectl:
rpm -ivh c968b9ca8bd22f047f56a929184d2b0ec8eae9c0173146f2706cec9e24b5fefb-kubectl-1.20.9-0.x86_64.rpm -
接下来本来是要安装kubelet的,但是报错依赖socat,好家伙原来旧版本依赖啊
socat:
rpm -ivh socat-1.7.3.2-8.ky10.x86_64.rpm -
kubelet:
rpm -ivh 02431d76ab73878211a6052a2fded564a3a2ca96438974e4b0baffb0b3cb883a-kubelet-1.20.9-0.x86_64.rpm -
kubeadm:
rpm -ivh 8c6b5ba8f467558ee1418d44e30310b7a8d463fc2d2da510e8aeeaf0edbed044-kubeadm-1.20.9-0.x86_64.rpm -
启动kubelet:
sudo systemctl enable --now kubelet
-
我的离线安装:[1.31.3]
下载正主及其依赖的rpm包:
https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/rpm/x86_64/,这里我选择了最新版的,即1.31。- 还有其他的依赖包,基本都可以在aliyun的centos、ubuntu或者其他什么系统的各种镜像里找到,你去os里面找就行。我因为用的是麒麟系统,所以在麒麟的源里找:
https://update.cs2c.com.cn/NS/V10
rpm -ivh xxx.rpm
- -i: 代表安装(install)。
- -v: 增强模式,显示更详细的安装信息,比如安装过程中的文件名。
- -h: 显示进度条(当与 -v 一起使用时)。
- cri-tools:
rpm -ivh cri-tools-1.31.1-150500.1.1.x86_64.rpm - kubeadm:
rpm -ivh kubeadm-1.31.3-150500.1.1.x86_64.rpm - kubectl:
rpm -ivh kubectl-1.31.3-150500.1.1.x86_64.rpm - libnetfilter_queue、libnetfilter_cttimeout、libnetfilter_cthelper:
rpm -ivh lib* - conntrack-tools:
rpm -ivh conntrack-tools-1.4.6-2.ky10.x86_64.rpm - kubernetes-cni:
rpm -ivh kubernetes-cni-1.5.1-150500.1.1.x86_64.rpm - kubelet:
rpm -ivh kubelet-1.31.3-150500.1.1.x86_64.rpm - 启动kubelet:
sudo systemctl enable --now kubelet
-
-
使用kubeadm引导集群
-
下载各个机器需要的镜像
sudo tee ./images.sh <<-'EOF' #!/bin/bash images=( kube-apiserver:v1.20.9 kube-proxy:v1.20.9 kube-controller-manager:v1.20.9 kube-scheduler:v1.20.9 coredns:1.7.0 etcd:3.4.13-0 pause:3.2 ) for imageName in ${images[@]} ; do docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/$imageName done EOF chmod +x ./images.sh && ./images.sh我的离线安装:
-
根据老师的视频截图,直接从老师的源下载镜像
![在这里插入图片描述]()
docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-proxy:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-scheduler:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-apiserver:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-controller-manager:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/etcd:3.4.13-0 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/coredns:1.7.0 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/pause:3.2 -
导出镜像:
docker save -o xxx.tar 镜像ID -
传入服务器并加载镜像:
docker load -i xxx.tar,这下镜像都到离线的服务器中啦 -
此外也可以用脚本批量导入
#!/bin/bash for image in ./images/*.tar; do echo "正在导入镜像:$image" docker load -i "$image" done-
chmod +x load_images.sh -
./load_images.sh
-
自建registry
-
为了解决镜像不要再传来传去的问题,我决定自建registry:
docker run -d -p 5000:5000 --name myregistry --restart=always -v /data/registry:/var/lib/registry registry:latest -
配置需要客户端docker
/etc/docker/daemon.json:{"insecure-registries": ["服务端IP:5000"]} -
重启docker:
-
如果是windows的docker desktop:直接右键重启
-
如果是linux的docker:
sudo systemctl daemon-reload sudo systemctl restart docker
-
-
给镜像打自己的tag:
docker tag 镜像ID 服务端IP:5000/kube-proxy:v1.20.9 -
push到服务端:
docker push 服务端IP:5000/kube-proxy:v1.20.9 -
从服务端pull:
docker pull 服务端IP:5000/kube-proxy:v1.20.9
问题
应该是我安装的k8s版本太高了,导致docker里面的镜像版本太低报错:
this version of kubeadm only supports deploying clusters with the control plane version >= 1.30.0. Current version: v1.20.9 To see the stack trace of this error execute with --v=5 or higher我发现最新的版本是
v1.31.3,整吧,整吧-
整完之后报错:没有
containerd啥的,就是找不到这个服务,研究了一下发现Containerd与Docker有什么区别:https://zhuanlan.zhihu.com/p/718335600
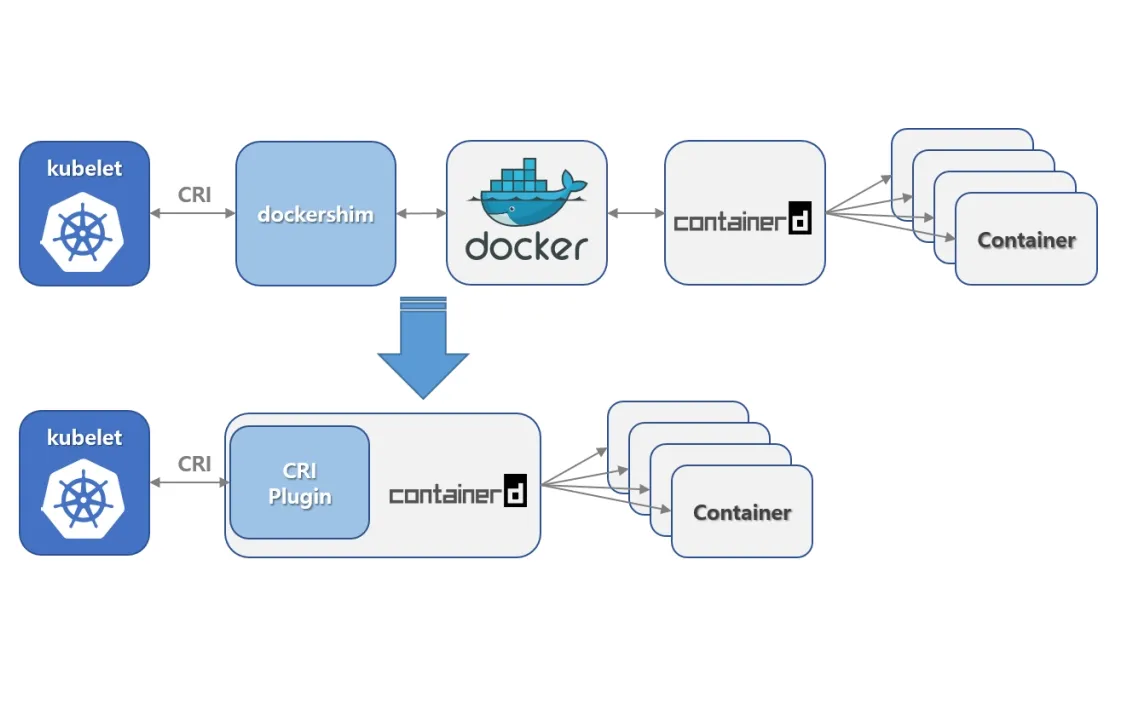
-
在1.20版本中将内置的dockershim进行分离,这个版本依旧还可以使用dockershim,但是在1.24中被删除。从1.24开始,大家需要使用其他受到支持的运
行时选项(例如containerd或CRI-O)![在这里插入图片描述]()
现在工作中k8s是使用containerd还是docker来管理容器:https://www.zhihu.com/question/3418508537/answer/31609642599
为什么这俩工具长得差不多?
-
咱先说个背景知识,这事儿的根子还在于,
Kubernetes这玩意儿,自己不生产容器,它就是个“调度员”,就是管你要什么容器,跑哪里,怎么跑,这些事儿。容器本身是由更底层的东西来管的。 -
Docker和containerd,就是两种帮你把容器跑起来的工具。最早Docker算是主流,后来containerd上位,成了 Kubernetes 里默认的容器管理方式。这两个工具呢,说白了,都能帮你把应用打包成容器,把代码、依赖、配置啥的都塞一块,想在哪儿跑都行。 -
只是,
Docker做了更多,它不仅仅管容器,还做镜像构建、注册、分发什么的。而containerd就精简得多,专注跑容器的核心功能。你可以理解为Docker是个大公司里的全能员工,啥都想干;而containerd就是个专注一件事的小专家,干活专心不出岔子。
Docker 落伍的根源在哪?
说白了,
Docker的锅有点儿多。一开始它啥都干,但Kubernetes真正搞起来后,发现有些事不需要它插手。比如容器的构建和分发,用不上
Kubernetes就能搞定;但是Docker自带的这些东西不仅多余,还拖慢系统。想想公司里的“全能”同事啥都管,有时候反倒不省心,是不是?- 性能负担:Docker 架构复杂、依赖多,在大规模场景下,额外的服务和功能就成了累赘,常常拖慢系统。就像你把一个公司所有职能都给一个人,这人反倒越干越慢,还常出小毛病。
- 兼容性不足:Docker 的架构不符合 Kubernetes CRI(Container Runtime Interface,容器运行时接口)的规范,需要一层转接,叫
dockershim。多一个环节就多一份不稳定的风险,出点问题谁都搞不清锅在哪儿。换个精简专注的containerd,直接上 CRI,少了中间商,省心多了。 - 复杂架构:Docker 的架构里带了很多没用的东西,举个例子,自己带了个 Docker Engine 和 Docker Daemon,就像一个人带个小助理,干活是方便了,但也有点拖沓。咱不如直接让 containerd 这个大力士上,直接扛活儿干。
- Kubernetes 直呼“去掉 dockershim”:2021 年 Kubernetes 就宣布正式抛弃 Docker 支持了,原因很简单,大家都嫌麻烦,尤其是多出来的 dockershim 维护成本高,风险大。既然有更好的选择,谁还拿着“扶不起的阿斗”?
那
containerd有啥独门绝技?好嘞,containerd 出场了。这个家伙清晰明了,就是个硬派选手。它干活就干“运行容器”这一件事,不掺和别的,省心省事儿。来看几个它独有的好处:
- 体积小,速度快:不多说了,containerd 不像 Docker 那么复杂,你也不用花额外心思去理解各种多余的东西。专注就是力量,咱玩 Kubernetes 就是要这个小、快、专注的工具,别整那些花里胡哨的。
- 架构简洁:containerd 和 Kubernetes 打交道的接口天然契合,没啥中间层,直接干活就完事儿。容器调度上,少一环,稳定性就上来。再说,简洁的东西维护起来也省心,不会今天冒泡明天掉线。
- 维护方便,社区活跃:虽然 containerd 看着小,但人家是 CNCF(云原生计算基金会)亲自罩的,不会没人管。Kubernetes 里一出啥问题,容器底层的社区老铁马上就给你支援,不怕没解决方案。咱们用它,也更省心。
现实工作中的利弊权衡
好了,咱说点实际工作中的情况吧。用 containerd 一开始可能不太习惯,尤其你要是以前 Docker 用得很熟。但公司里啥活不是从学不会到学会,containerd 这玩意儿上手成本其实也没那么高。
- 开发、测试的环境:Docker 环境用惯了,你本地开发、打包镜像还是得靠它。但是上了生产环境,部署到集群里,就用 containerd,两者配合着用,各司其职,这样效率最高。
- 从 Docker 转 containerd 的迁移成本:对,迁移成本有一些,但这就跟升级设备一样,忍一忍,等习惯了就好。这事儿吧,长痛不如短痛,公司总要向前走。切了 containerd,你会发现架构稳定性提升不止一点半点。
- 容器镜像管理:containerd 没有内置的镜像构建和分发功能,但这事儿也不难解决,反正公司内部用一些专门的镜像库(Registry),照样方便得很。大公司还会用 CI/CD 工具链串起来,哪里还用纠结这个。
总结
真要总结的话,就是这事儿早就没啥悬念了:
Docker好用在开发阶段,本地折腾项目谁都爱它;可真上生产,containerd必须安排。干活儿嘛,就要用对的工具,containerd精简稳定,省去 Docker 的各种麻烦和复杂性。咱就别纠结了,生产上用 Kubernetes 那就直接containerd,少走弯路。Containerd ctr、crictl、nerdctl 客户端命令介绍与实战操作
https://zhuanlan.zhihu.com/p/562014518Containerd 常见命令操作
更换 Containerd 后,以往我们常用的 docker 命令也不再使用,取而代之的分别是
crictl和ctr两个命令客户端。-
crictl是遵循 CRI 接口规范的一个命令行工具,通常用它来检查和管理kubelet节点上的容器运行时和镜像。 -
ctr是containerd的一个客户端工具。 -
ctr -v输出的是containerd的版本,crictl -v输出的是当前 k8s 的版本,从结果显而易见你可以认为crictl是用于k8s的。 -
一般来说你某个主机安装了 k8s 后,命令行才会有 crictl 命令。而 ctr 是跟 k8s 无关的,你主机安装了 containerd 服务后就可以操作 ctr 命令。
使用
crictl命令之前,需要先配置/etc/crictl.yaml如下:runtime-endpoint:unix:///run/containerd/containerd.sock image-endpoint:unix:///run/containerd/containerd.sock timeout:10 debug:false也可以通过命令进行设置:
crictl config runtime-endpointunix:///run/containerd/containerd.sock crictlconfigimage-endpointunix:///run/containerd/containerd.sock更多命令操作,可以直接在命令行输入命令查看帮助。
docker --help ctr --help crictl --help -
-
containerd安装教程:参考链接:
-
"validate service connection: validate CRI v1 runtime API for endpoint \" unix:///var/run/containerd/:https://blog.csdn.net/qq_33371766/article/details/140361531 -
【kubeadm】离线部署k8s(使用containerd):https://blog.csdn.net/Nefertari___/article/details/135932563
-
轻量级容器管理工具Containerd的两种安装方式:https://www.cnblogs.com/liuzhonghua1/p/18010847
-
从 github 上下就完了: https://github.com/containerd/containerd/releases ,我下的是
containerd-1.7.24-linux-amd64.tar.gz -
创建containerd目录并解压
mkdir /root/containerd tar -zxvf containerd-1.7.24-linux-amd64.tar.gz -C /root/containerd -
追加环境变量并立即生效:
export PATH=$PATH:/usr/local/bin:/usr/local/sbin && source ~/.bashrc -
使containerd生效
cd /root/containerd/bin cp * /usr/bin cp ctr /usr/local/bin -
检查containerd的管理命令
ctictl是否好用:ctictl --version -
生成containerd配置文件
mkdir -p /etc/containerd/ containerd config default > /etc/containerd/config.toml -
修改containerd默认配置文件
-
修改
sandbox_image为自己registry的 pause 镜像 -
修改 仓库镜像,我是把所有各种镜像都指向自己的registry了
[plugins] ... [plugins."io.containerd.grpc.v1.cri"] ... # sandbox_image = "registry.k8s.io/pause:3.8" sandbox_image = "10.4.32.48:5000/pause:3.10" ... [plugins."io.containerd.grpc.v1.cri".registry] [plugins."io.containerd.grpc.v1.cri".registry.mirrors] [plugins."io.containerd.grpc.v1.cri".registry.mirrors."registry.k8s.io"] endpoint = ["http://10.4.32.48:5000"] [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] endpoint = ["http://10.4.32.48:5000"] [plugins."io.containerd.grpc.v1.cri".registry.mirrors."10.4.32.48:5000"] endpoint = ["http://10.4.32.48:5000"] ...
-
-
启动containerd,且设置自启:
systemctl start containerd && systemctl enable containerd
-
-
查看当前版本 kubeadm 安装对镜像的需求:
kubeadm config images listfalling back to the local client version: v1.31.3 registry.k8s.io/kube-apiserver:v1.31.3 registry.k8s.io/kube-controller-manager:v1.31.3 registry.k8s.io/kube-scheduler:v1.31.3 registry.k8s.io/kube-proxy:v1.31.3 registry.k8s.io/coredns/coredns:v1.11.3 registry.k8s.io/pause:3.10 registry.k8s.io/etcd:3.5.15-0现在知道下什么了吧,反正通过你的方式搞到这些镜像,然后push到你的registry中,为后续做准备
-
-
初始化主节点,只在主节点运行
# 所有机器添加master域名映射,以下需要修改为自己的 # 每一个节点都要添加这句话,让每个节点都知道主节点是谁 # 执行后的效果:ping cluster-endpoint 可以ping通 echo "10.4.32.48 cluster-endpoint" >> /etc/hosts # 主节点初始化 # --apiserver-advertise-address 管理节点ip # --image-repository containerd配置文件中的镜像仓库 # --control-plane-endpoint 管理节点ip # --pod-network-cidr=192.168.0.0/16 这么写是因为后面calico网络安装的yaml文件中默认的是这个 kubeadm init \ --apiserver-advertise-address=10.4.32.48 \ --control-plane-endpoint=cluster-endpoint \ --image-repository 10.4.32.48:5000 \ --kubernetes-version v1.20.9 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=192.168.0.0/16 # 这里k8s的版本,我改回来 v1.20.9- 因为docker要用
172.xxxx,所以在选集群网络范围的时候要避开 - 【如果你非要改】所有网络范围不重叠,也不能跟机器ip范围不重叠
问题 [1.20.9]
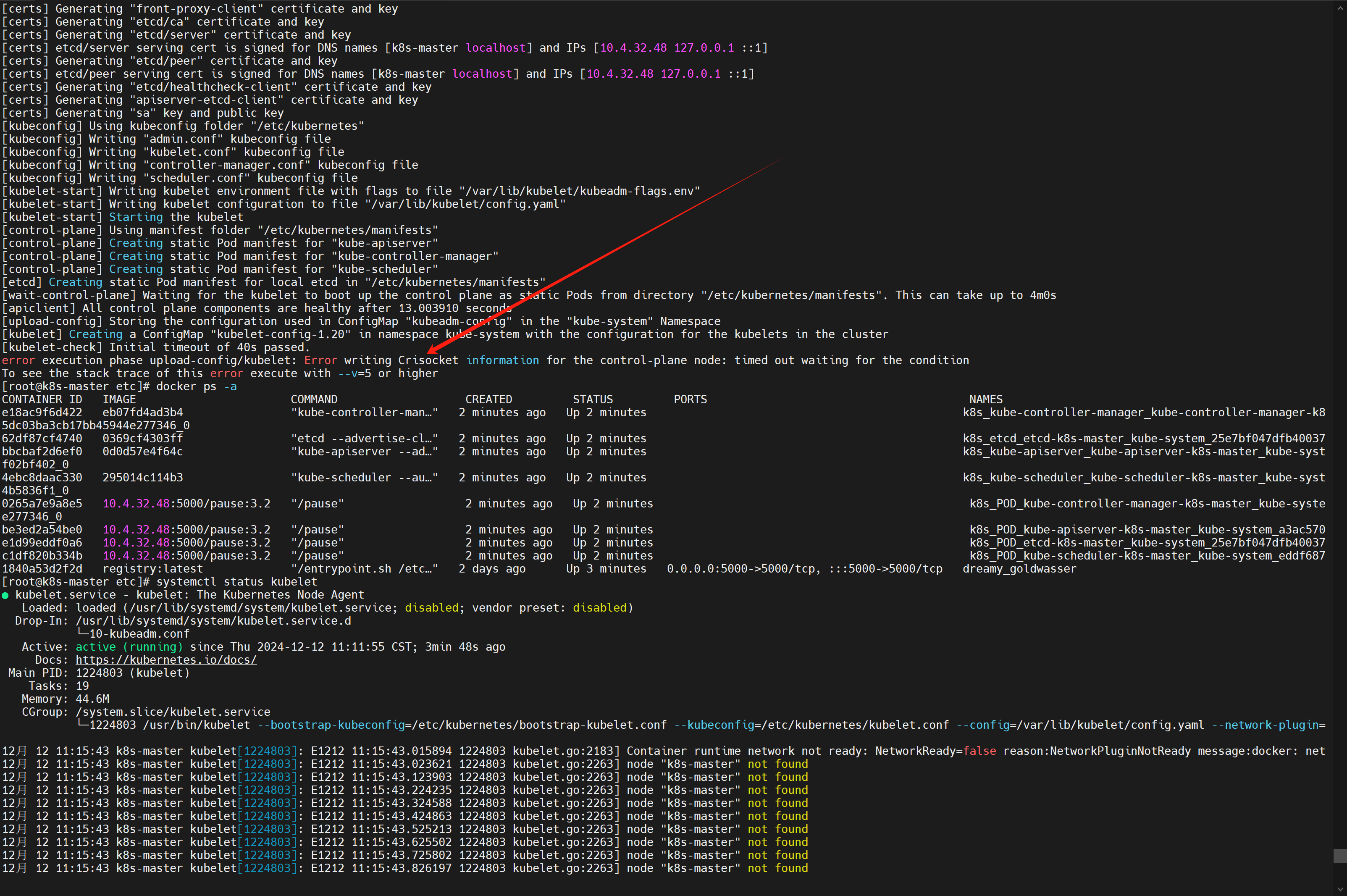
运行很顺利,但是突然报错了个蛇皮错误:
error execution phase upload-config/kubelet: Error writing Crisocket information for the control-plane node: timed out waiting for the condition![在这里插入图片描述]()
⚠️ 这个一搜就搜到了,都是同样的解决方案:
https://blog.51cto.com/u_16099200/10939353
https://blog.csdn.net/q_hsolucky/article/details/124273257
https://blog.csdn.net/weixin_41831919/article/details/118713869
swapoff -a kubeadm reset systemctl daemon-reload systemctl restart kubelet iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X其中:
-
swapoff -a:是一个用于禁用所有交换分区和交换文件的命令。在 Linux 系统中,交换空间(swap space)用于将不常用的内存页面从内存移出到磁盘上,以便释放更多的物理内存用于其他进程。使用 swapoff -a 可以将所有当前启用的交换空间禁用。在某些情况下,例如在配置 Kubernetes 集群时,可能需要禁用交换,因为 Kubernetes 对内存管理的要求不鼓励使用交换空间 -
iptables是一个用于配置 Linux 系统上的网络封包过滤规则的命令:-
iptables -F:清空所有默认表(filter表)中的规则链内的规则。也就是说,这将移除所有的输入(INPUT)、输出(OUTPUT)和转发(FORWARD)链中的规则。 -
iptables -t nat -F:清空nat表中的规则链,这将移除有关网络地址转换(NAT)的所有规则,如源地址伪装(MASQUERADE)和端口映射(DNAT, SNAT)等。 -
iptables -t mangle -F:清空mangle表中的规则链,它主要用于对数据包的服务类型(TOS)、TTL等进行修改。 -
iptables -X:删除用户自定义链。这个命令不会影响默认的规则链(如 INPUT、OUTPUT、FORWARD),但会删除所有用户自定义的链。
总结起来,这一系列命令的作用是清空
iptables中的所有规则和用户自定义的链,恢复到一个相对“干净”的状态。要注意的是,执行这些命令后,可能会导致你当前的防火墙策略失效,导致机器变得不安全,因此要慎重操作 -
⚠️ 其次是一个docker的问题,可能是我的docker版本太高了或者其他的原因:
detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”.参考:https://blog.csdn.net/zhyysj01/article/details/130965489
解决:在
/etc/docker/daemon.json中加一个配置,然后重启docker服务就行{ "exec-opts": ["native.cgroupdriver=systemd"] }然后查看一下:
docker info | grep Cgroup,现在是 systemd 了问题 [1.31.3]
-
报错了,
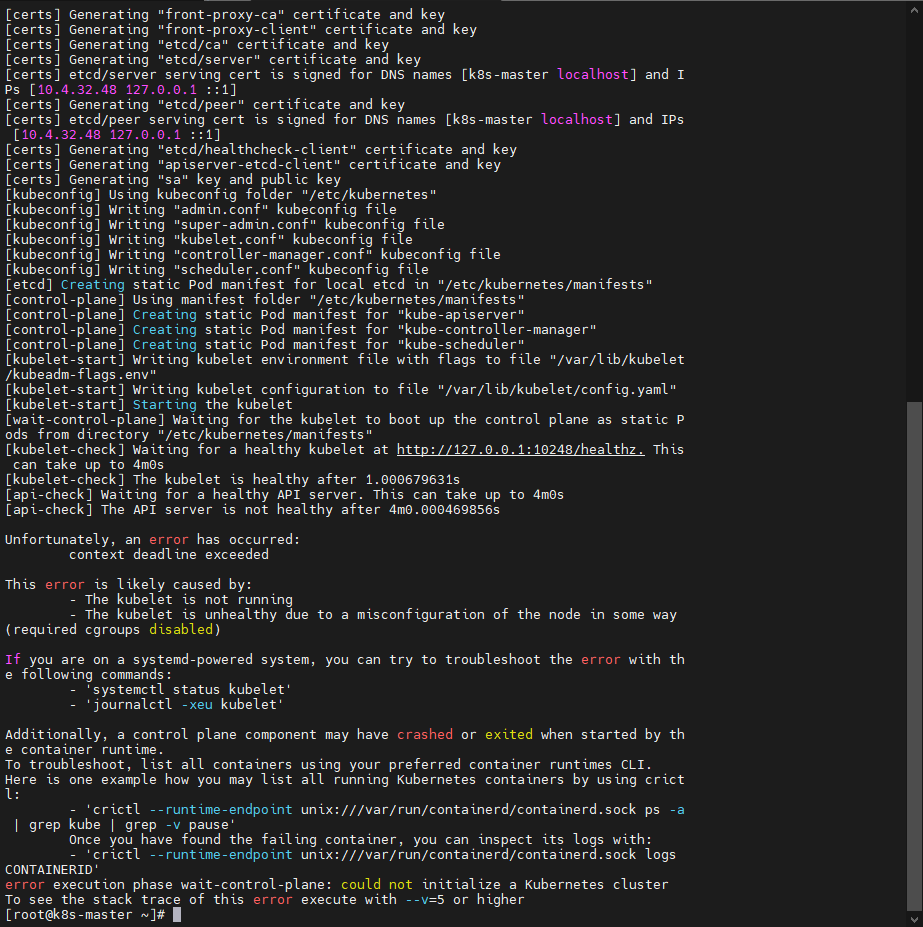
crictl ps -a发现etcd和apiserver都没起来![在这里插入图片描述]()
![在这里插入图片描述]()
-
crictl logs etcd的容器ID发现,很多路径都没有权限:open /etc/kubernetes/pki/etcd/peer.key: permission denied"我直接
chmod 666整上了:chmod 666 /etc/kubernetes/pki/etcd/peer.keychmod 666 /etc/kubernetes/pki/etcd/server.key- 然后把挂了的 etcd 和 apiserver 删掉,一会儿就自动起来了
注意:不要
kubeadm reset一下,重新来过,还是会没权限,因为每次都是重来。![在这里插入图片描述]()
-
当我们
crictl ps -a的时候发现警告WARN[0000] runtime connect using default endpoints: [unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead. WARN[0000] image connect using default endpoints: [unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.参考:https://www.cnblogs.com/zmh520/p/18393109
-
修改
crictl的配置文件:vim /etc/crictl.yamlruntime-endpoint: "unix:///run/containerd/containerd.sock" timeout: 0 debug: false -
重启
containerd:systemctl restart containerd
-
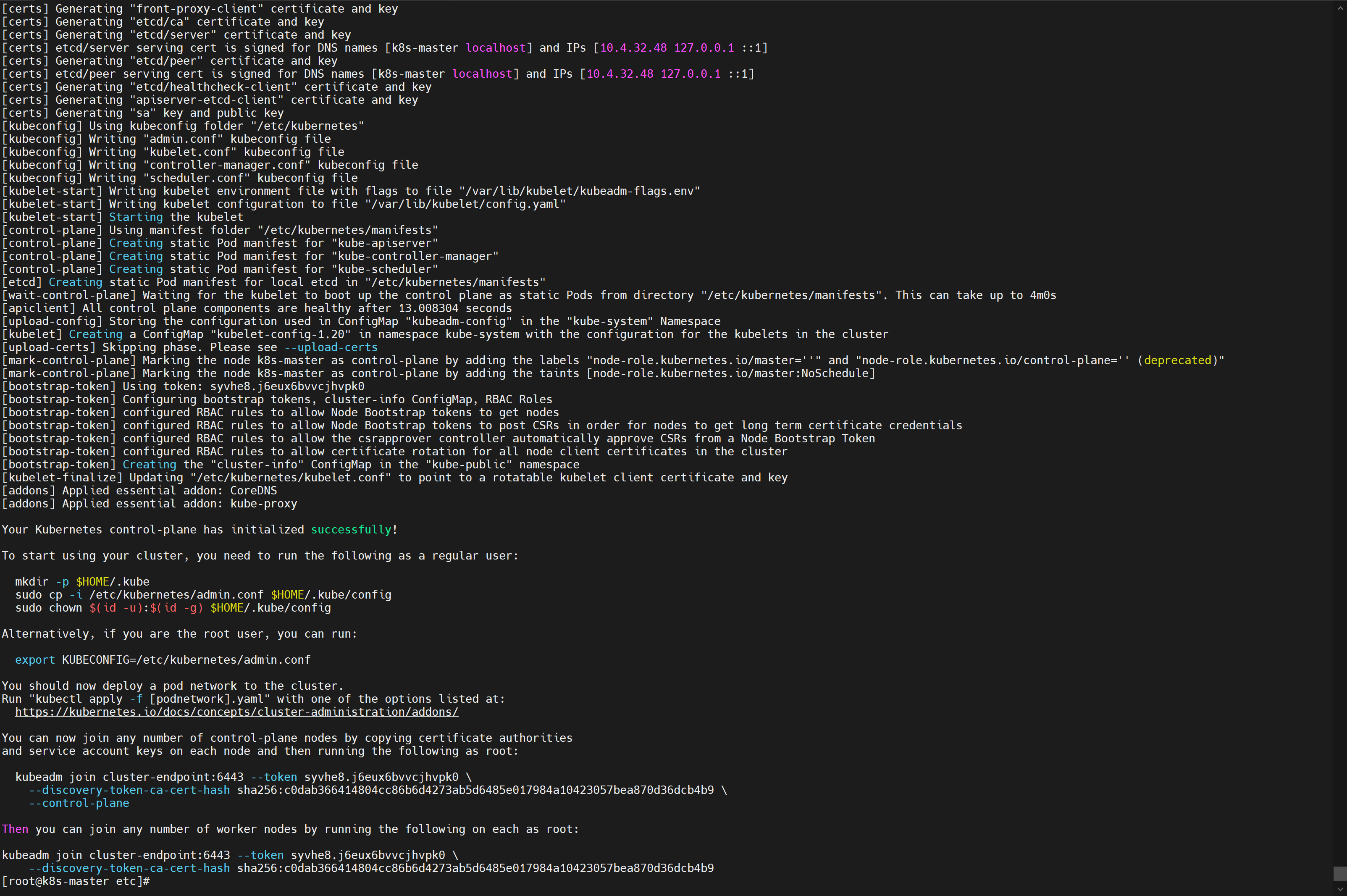
我只能说两个字:成功!🎉
![在这里插入图片描述]()
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join cluster-endpoint:6443 --token syvhe8.j6eux6bvvcjhvpk0 \ --discovery-token-ca-cert-hash sha256:c0dab366414804cc86b6d4273ab5d6485e017984a10423057bea870d36dcb4b9 \ --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join cluster-endpoint:6443 --token syvhe8.j6eux6bvvcjhvpk0 \ --discovery-token-ca-cert-hash sha256:c0dab366414804cc86b6d4273ab5d6485e017984a10423057bea870d36dcb4b9 - 因为docker要用
-
设置
.kube/config📍 主节点,使用!创建目录、复制配置文件、赋权~
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config成功啦!
[root@k8s-master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master NotReady control-plane,master 3h50m v1.20.9⚠️ 其实中间出了一个小插曲:
kubectl get nodes之后报错:Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")略微一搜:https://download.csdn.net/blog/column/11866583/126112342
好家伙,难不成是之前1.31.4的残留导致的,我直接:
rm -rf $HOME/.kube,再重复 📍 中的三行命令即可。真有我的,解决!:happy: -
安装网络组件
现在主节点是 NotReady 是吧,原因是没有 deploy a pod network to the cluster,即缺少一个网络插件,把k8s的机器用网络插件串起来打通。
k8s支持很多网络插件,我们选择 calico
-
下载 calico 的配置文件:
https://docs.projectcalico.org/manifests/calico.yaml,我访问之后直接跳转到了:https://calico-v3-25.netlify.app/archive/v3.25/manifests/calico.yaml -
安装:
kubectl apply -f calico.yaml问题:报错了:
error: unable to recognize "calico.yaml": no matches for kind "PodDisruptionBudget" in version "policy/v1"⚠️ 发现是当前k8s不支持calico的版本
https://blog.csdn.net/weixin_45379855/article/details/125175823
那是当然啊,我下的最新的calico,了解了一下,应该选v3.20
https://docs.projectcalico.org/v3.20/manifests/calico.yaml
再安装就成功啦 🎉
-
一些命令
-
kubectl get nodes:查看集群所有节点 -
kubectl apply -f xxx.yaml:根据配置文件,给集群创建资源,比如创建网络资源 calico -
查看集群部署了哪些应用?
-
docker ps = kubectl get pods -A [-w]:查询所有pod的状态[一直监听]watch -n 1 kubectl get pods -A:每一秒执行后面的命令,查看pod状态 -
运行中的应用在docker里面叫容器,在k8s里面叫Pod
-
-
查看pod信息:
kubectl describe pod 【pod名】 -n 【命名空间】 -
删除pod:
kubectl delete pod 【pod名】 -n 【命名空间】
-
-
通过
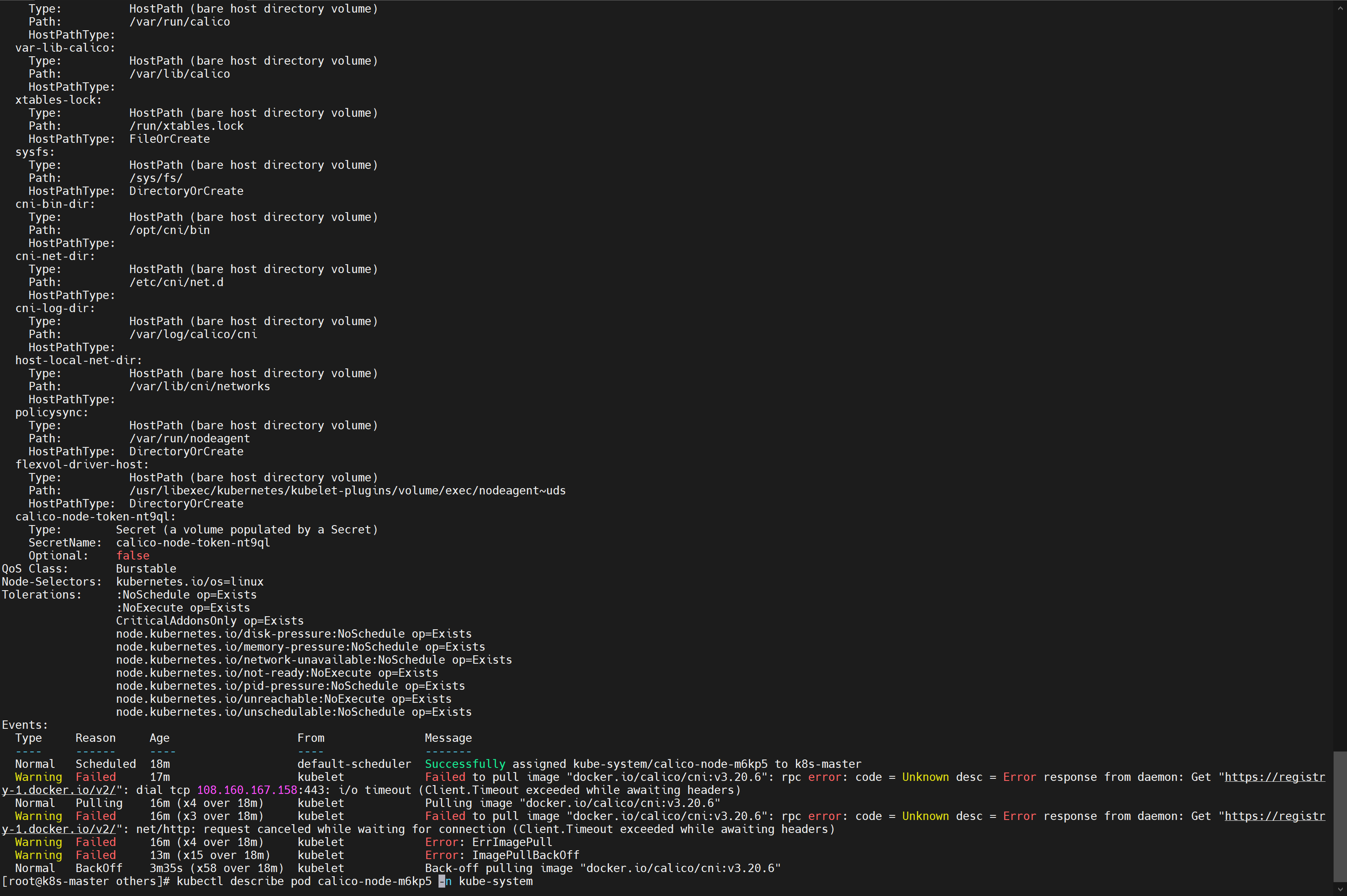
kubectl get nodes看到主节点 notready,然后用kubectl get pods -A看到 calico 的 status 是 Init:ImagePullBackOff,这说明拉镜像失败了,肯定失败啊,我们都没管 calico 的镜像-
通过
kubectl describe pod calico-node-m6kp5 -n kube-system,我们可以看到,问题在这儿呢:Failed to pull image "docker.io/calico/cni:v3.20.6"![在这里插入图片描述]()
-
总结还需要如下镜像:
docker.io/calico/cni:v3.20.6docker.io/calico/pod2daemon-flexvol:v3.20.6docker.io/calico/node:v3.20.6docker.io/calico/kube-controllers:v3.20.6
❓ 问了下GPT4o
要使用 Calico 作为 Kubernetes 集群的网络插件,你通常需要拉取和部署多个容器镜像。这些镜像各自负责不同的功能和组件。以下是一些常用的 Calico 组件及其所需的镜像:
-
calico/cni: CNI 插件,负责网络接口的设置和配置。
- 镜像名称示例:
calico/cni
- 镜像名称示例:
-
calico/node: 核心组件,负责路由、策略、安全组等。
- 镜像名称示例:
calico/node
- 镜像名称示例:
-
calico/kube-controllers: 负责网络策略和 IP 池的管理。
- 镜像名称示例:
calico/kube-controllers
- 镜像名称示例:
-
calico/pod2daemon-flexvol: 用于 Flexible Volumes 的插件,支持网络策略的强化。
- 镜像名称示例:
calico/pod2daemon-flexvol
- 镜像名称示例:
-
calico/typha: (可选) 用于大规模集群,以减少对 API 服务器的负载。
- 镜像名称示例:
calico/typha
- 镜像名称示例:
-
配置
/etc/docker/daemon.json,这样从docker.io也会到自建的registry中搞镜像"registry-mirrors": ["http://10.4.32.48:5000"]
🎉 在所有镜像push之后,自动就 Ready 啦!pods们都 running 啦!
![在这里插入图片描述]()
-
-
-
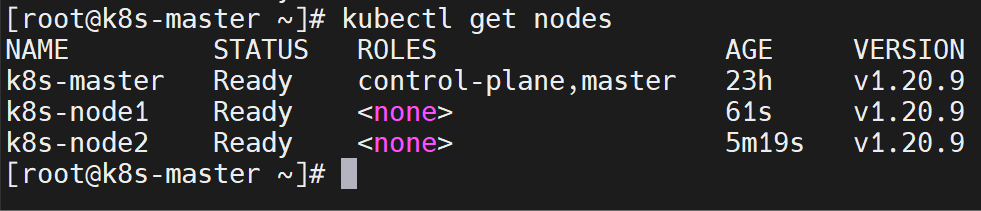
加入Work节点
还是之前
kubeadm init成功显示里面的命令,在Work节点的服务器中运行:kubeadm join cluster-endpoint:6443 --token syvhe8.j6eux6bvvcjhvpk0 \ --discovery-token-ca-cert-hash sha256:c0dab366414804cc86b6d4273ab5d6485e017984a10423057bea870d36dcb4b9但是这个令牌是24h有效的,如果过期了怎么办?
在master节点创建新令牌:
kubeadm token create --print-join-command⚠️ 当然问题还是会有的,还是老问题
detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd".解决:编辑
/etc/docker/daemon.json,记得重启docker哦systemctl restart docker{ "insecure-registries" : ["10.4.32.48:5000"], "registry-mirrors": ["http://10.4.32.48:5000"], "exec-opts": ["native.cgroupdriver=systemd"] }🎉 成功啦!
![在这里插入图片描述]()
👌 回去主节点上可以看到加入的工作节点们~
![在这里插入图片描述]()
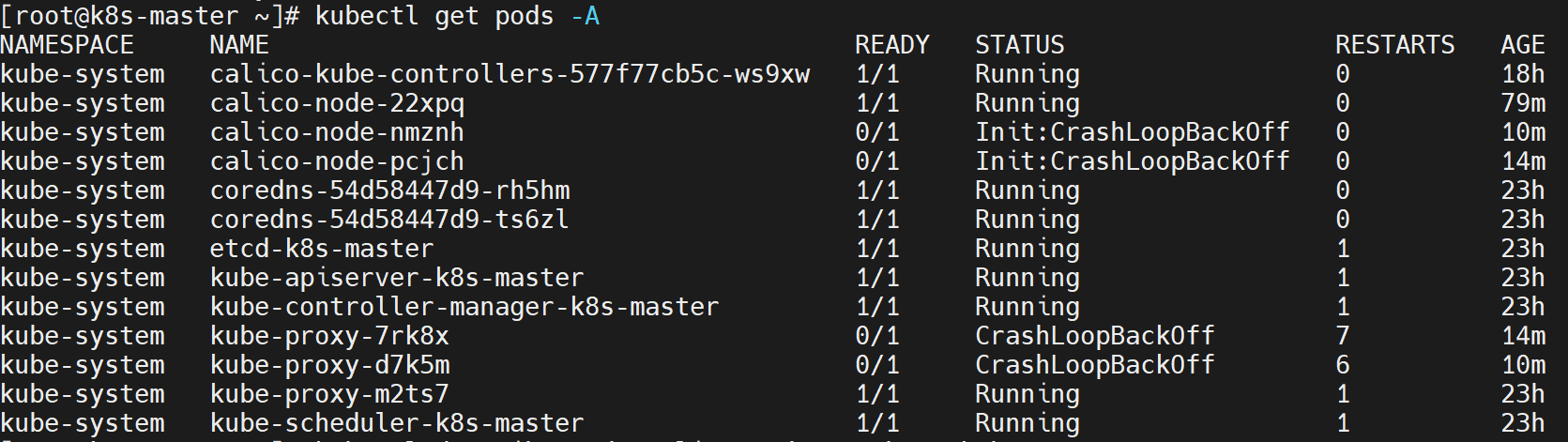
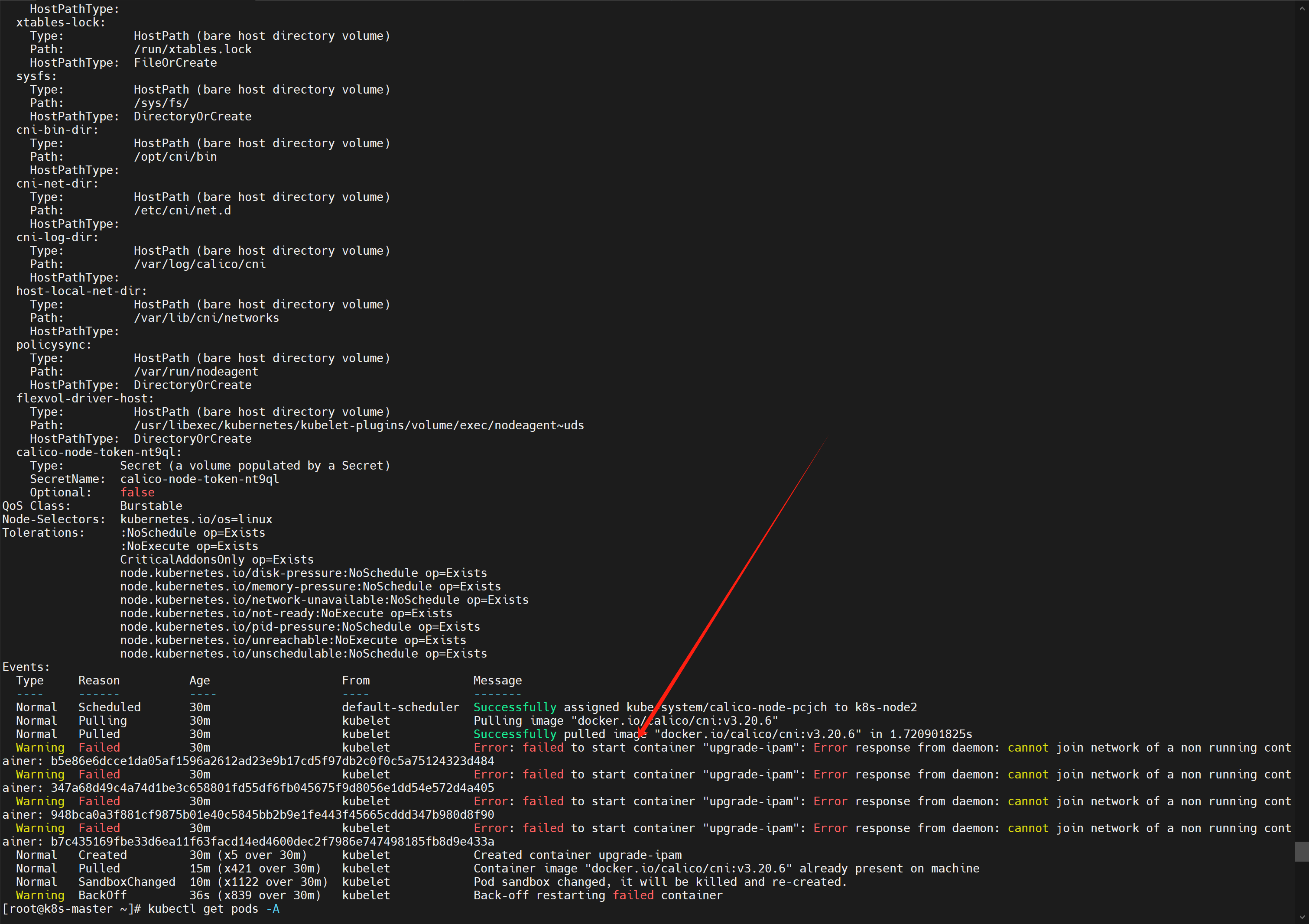
⚠️ 没错没错,问题又来了,从主节点上看到工作节点虽然都ready了,但是!
kubectl get pods -A会发现,有的pod没有启起来![在这里插入图片描述]()
-
用
kubectl describe pod 【pod名】 -n 【命名空间】看可以发现,是子节点容器启不起来的问题![在这里插入图片描述]()
-
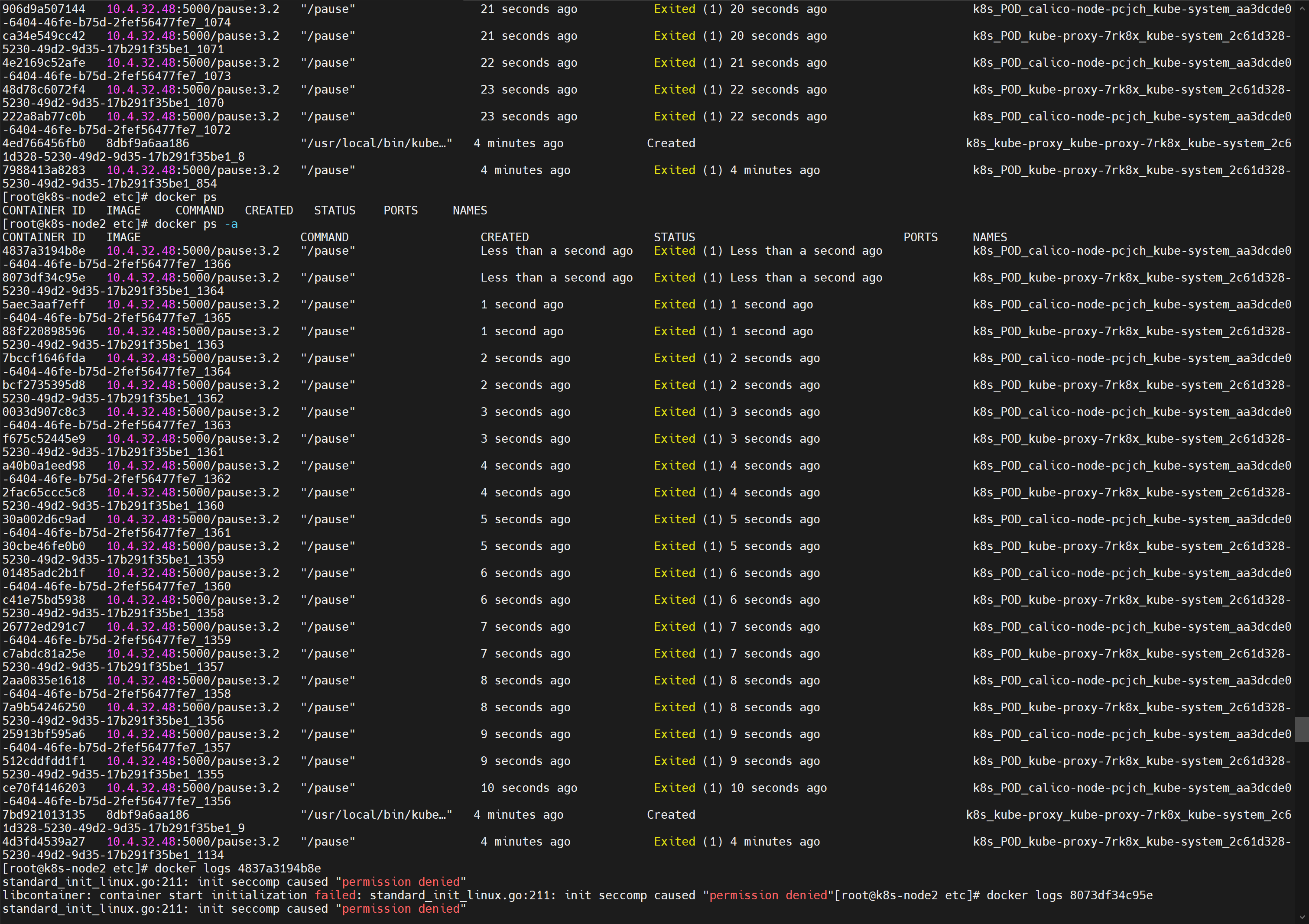
熟悉吗!我太熟悉了!我去work的节点一看
docker ps -a,好家伙一堆卡卡失败的啊,找一个失败的进去看看docker logs 【容器ID】,报错如下。我百度一查 seccomp,虽然看不懂啊,但我看到了一个关键词 podman,好家伙,这个我熟悉啊,银河麒麟docker的最大绊脚石!standard_init_linux.go:211: init seccomp caused "permission denied" libcontainer: container start initialization failed: standard_init_linux.go:211: init seccomp caused "permission denied"![在这里插入图片描述]()
解决:
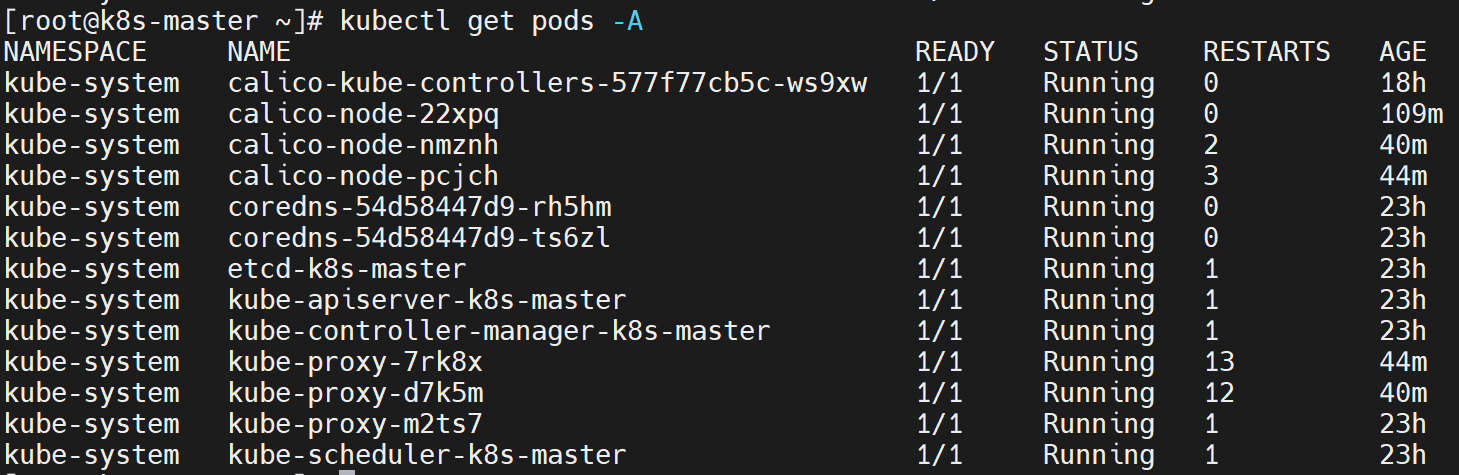
yum remove podman,好家伙,我踏马怎么能忘记这个!全部就自己running了,醉醉的。![在这里插入图片描述]()
-
-
集群自我修复能力测试
如果把三个服务器都reboot,重启成功后,可以看到节点都在自动恢复
-
- 设置主机名:
-
部署dashboard
-
kubernetes官方提供的可视化界面
- 官方地址:https://github.com/kubernetes/dashboard
- 下载 v2.3.1 的yaml文件:https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
- 安装:
kubectl apply -f recommended-v2.3.1.yaml
⚠️ 果然,不出问题是不可能的,必然是镜像的问题
- kubernetesui/metrics-scraper:v1.0.6
- kubernetesui/dashboard:v2.3.1
-
设置访问端口
-
修改配置文件中的
type: ClusterIP改为type: NodePortkubectl edit svc kubernetes-dashboard -n kubernetes-dashboard -
找到端口,在安全组放行:
kubectl get svc -A |grep kubernetes-dashboard[root@k8s-master others]# kubectl get svc -A |grep kubernetes-dashboard kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.51.184 <none> 8000/TCP 33m kubernetes-dashboard kubernetes-dashboard NodePort 10.96.223.53 <none> 443:31345/TCP 33m需要在安全组中把 31345,也就是上面的最后一行那个
443:31345这个端口放开 -
访问:
https://集群任意IP:端口(即31345),用 k8s-node1 为例:https://10.4.32.50:31345![在这里插入图片描述]()
⚠️ 输入了打不开,报错内容如下
10.4.32.50 通常会使用加密技术来保护您的信息。Chrome 此次尝试连接到 10.4.32.50 时,该网站发回了异常的错误凭据。这可能是因为有攻击者在试图冒充 10.4.32.50,或者 Wi-Fi 登录屏幕中断了此次连接。请放心,您的信息仍然是安全的,因为 Chrome 尚未进行任何数据交换便停止了连接。 您目前无法访问10.4.32.50,因为此网站发送了Chrome无法处理的杂乱凭据。网络错误和攻击通常是暂时的,因此,此网页稍后可能会恢复正常。解决:只能说很神奇,你只需要在当前页面输入
thisisunsafe,就完事儿了,我擦真的很神奇,你看不到你的输入,就是盲打,打完就跳转了。并且后面都是直接跳转了
-
-
创建访问账号
光看这个玩意儿,不知道登录的token是啥啊,需要自己弄,没错:
kubectl apply -f dash.yaml那么这个文件怎么写呢:
# 创建访问账号,准备一个yaml文件; vi dash.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard这样就创建了一个服务的账号:
admin-user -
令牌访问
-
获取访问令牌:
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"输出的还挺像jwt token的
eyJhbGciOiJSUzI1NiIsImtpZCI6IllLRDhuSGpndDhJOFRnUWtCNE5XQXZER1NfMDlwY25BR3VGMEl1dnN0Nm8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWN6ZHo3Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJkY2MyOThhZS1iMzBlLTRiMzUtODMyNy00MDg3ZTkzYzk1NzIiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.S16hXdYbCu64pmEHw6U7hW28jPzxKB7V-tm-n-m3lupzgPIdaudKvSoUjPTy-O55h2_4CgMI0GuQTSNCopjj0Rnf5CxOzarpfSkHvo6C9HuJp1nQhOJJpzKPTNT3m_rYjwJwSgGnZasvGFfmvCndut6qLLYSsZr_sFdUL1rJOBs5peoCnmR7yptrrrog-e9Vtxkhr-Q04RqwJCYXjxPkmKevGTLYlLfbpC_c_JPlLsafjut3DgFrZWb0hwQzwdYOk1JDBcJbV0Jv5CG98jNT02mFoSq3m0aZ_T_aIWtTzdNi7f4siblzoffViIYcN42_5D_FdR4JctVqddR4Nu_O-Q -
然后一粘贴就登录了
![在这里插入图片描述]()
-
-



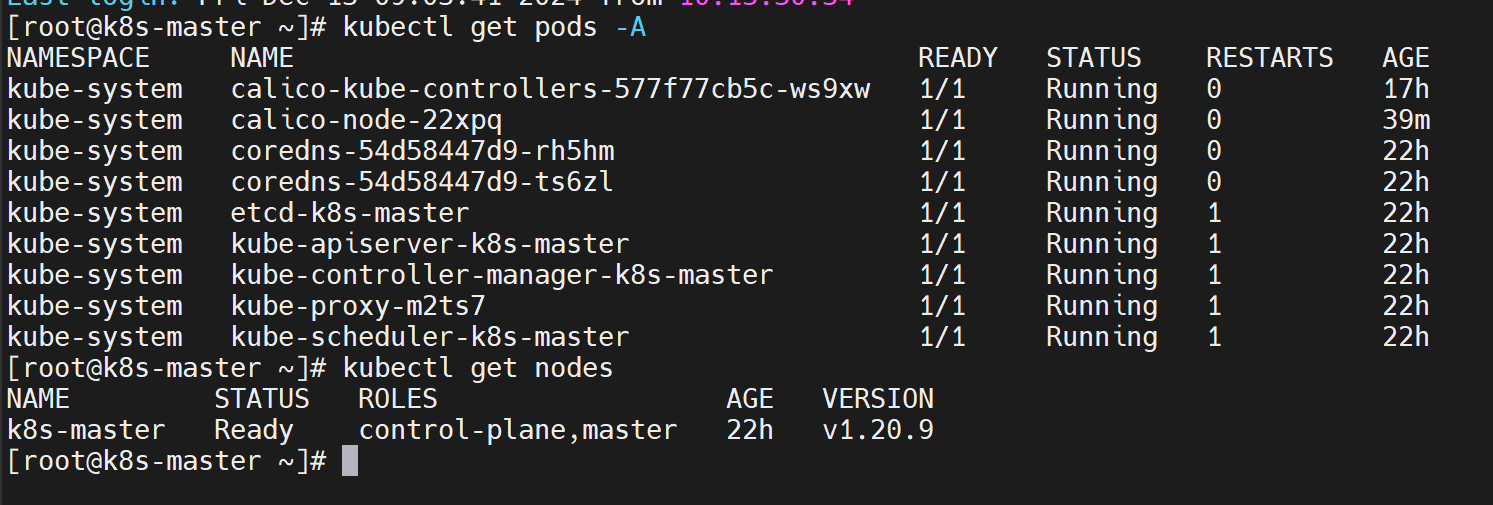
Kubernetes核心实战
-
资源创建方式
- 命令行
- YAML
-
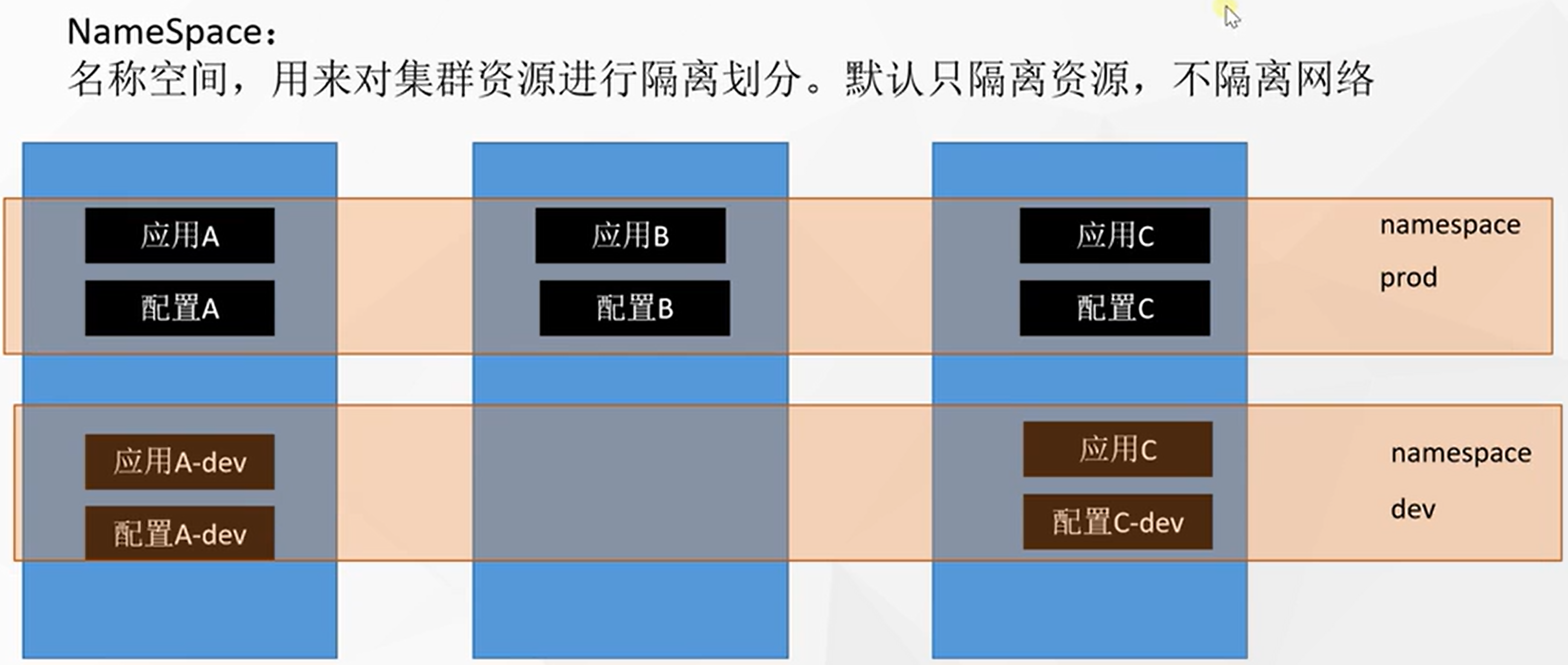
Namespace
名称空间是用来隔离资源的,对资源进行分组。默认隔离资源,不隔离网络。
![在这里插入图片描述]()
-
获取当前名称空间列表:
kubectl get ns -
查看名称空间中的应用列表:
kubectl get pods -n 【名称空间】 -
删除名称空间:
kubectl delete ns 【名称空间】,删除时,会把该空间下的所有应用资源全部删除,请谨慎! -
创建名称空间:
kubectl create ns 【名称空间】# 如果用yaml创建名称空间:kubectl apply -f xxx.yaml # 删除:kubectl delete -f xxx.yaml,这样删的比较干净 # 版本号 apiVersion: v1 # 资源类型 kind: Namespace metadata: name: hello
-
-
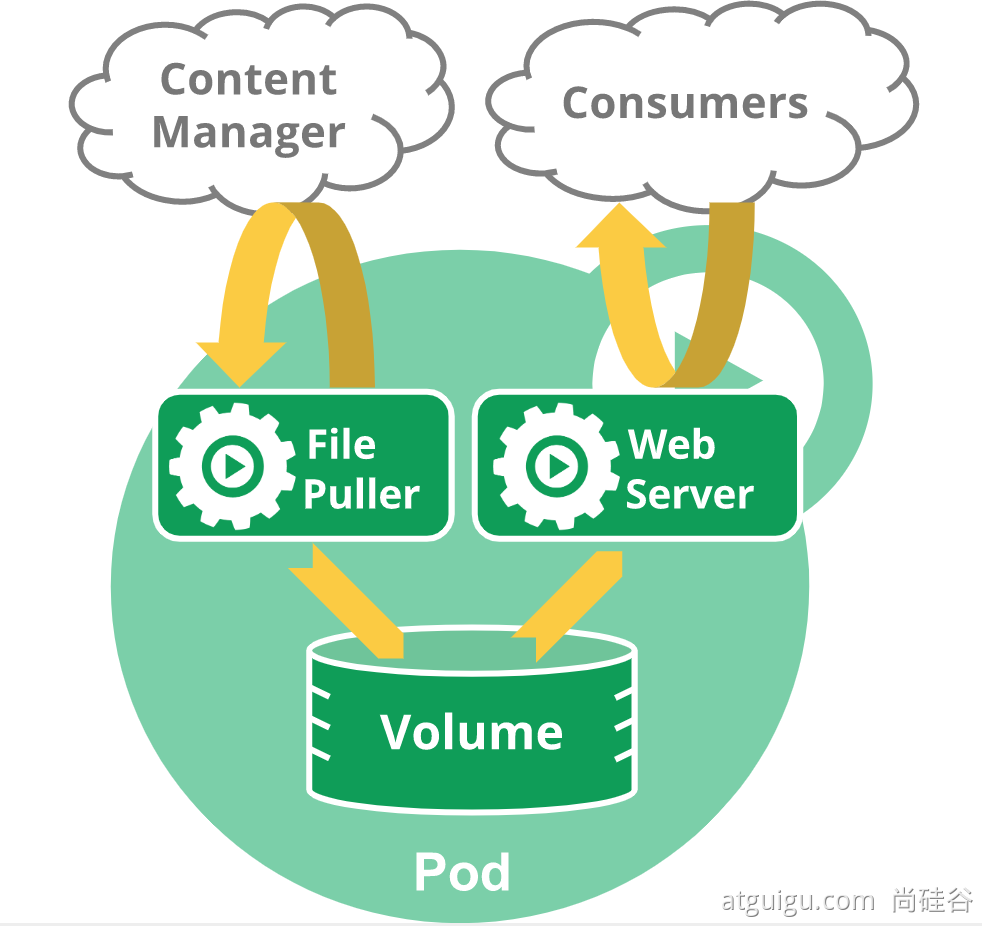
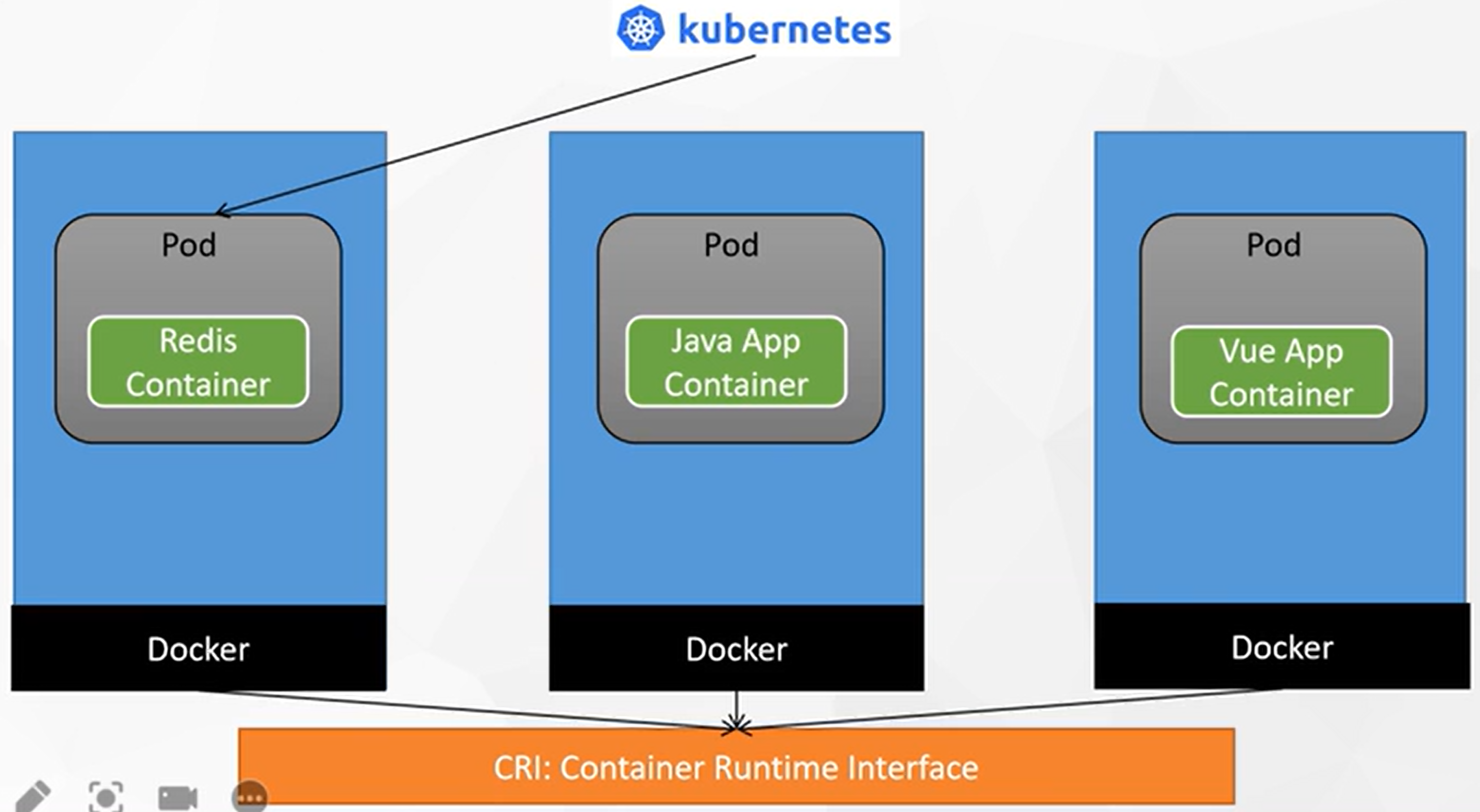
Pod
运行中的一组容器,Pod是kubernetes中应用的最小单位
![在这里插入图片描述]()
![在这里插入图片描述]()
-
创建pod:
-
命令行创建:
kubectl run mynginx --image=nginx,这样创建的pod在默认的命名空间中。⚠️ 如果要用本地的镜像 --image=10.4.32.48:5000/nginx
⚠️ 如果本地镜像是http,要设置docker或者containerd的配置文件
-
编辑 containerd 的配置文件,通常位于 /etc/containerd/config.toml。在 [plugins."io.containerd.grpc.v1.cri".registry] 的 mirrors 部分添加你的注册表:
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."10.4.32.50:5000"] endpoint = ["http://10.4.32.50:5000"] -
编辑 Docker 的配置文件 /etc/docker/daemon.json,添加或修改 insecure-registries 字段以包含你的注册表地址。确保配置如下:
{ "insecure-registries" : ["10.4.32.50:5000"] }
-
-
配置文件创建:
kubectl apply -f pod.yaml,删除:kubectl delete -f pod.yamlapiVersion: v1 kind: Pod metadata: labels: run: mynginx name: mynginx # namespace: default spec: containers: - image: 10.4.32.48:5000/nginx name: mynginx -
可视化操作,上述配置yaml粘贴到下图中
![在这里插入图片描述]()
![在这里插入图片描述]()
-
-
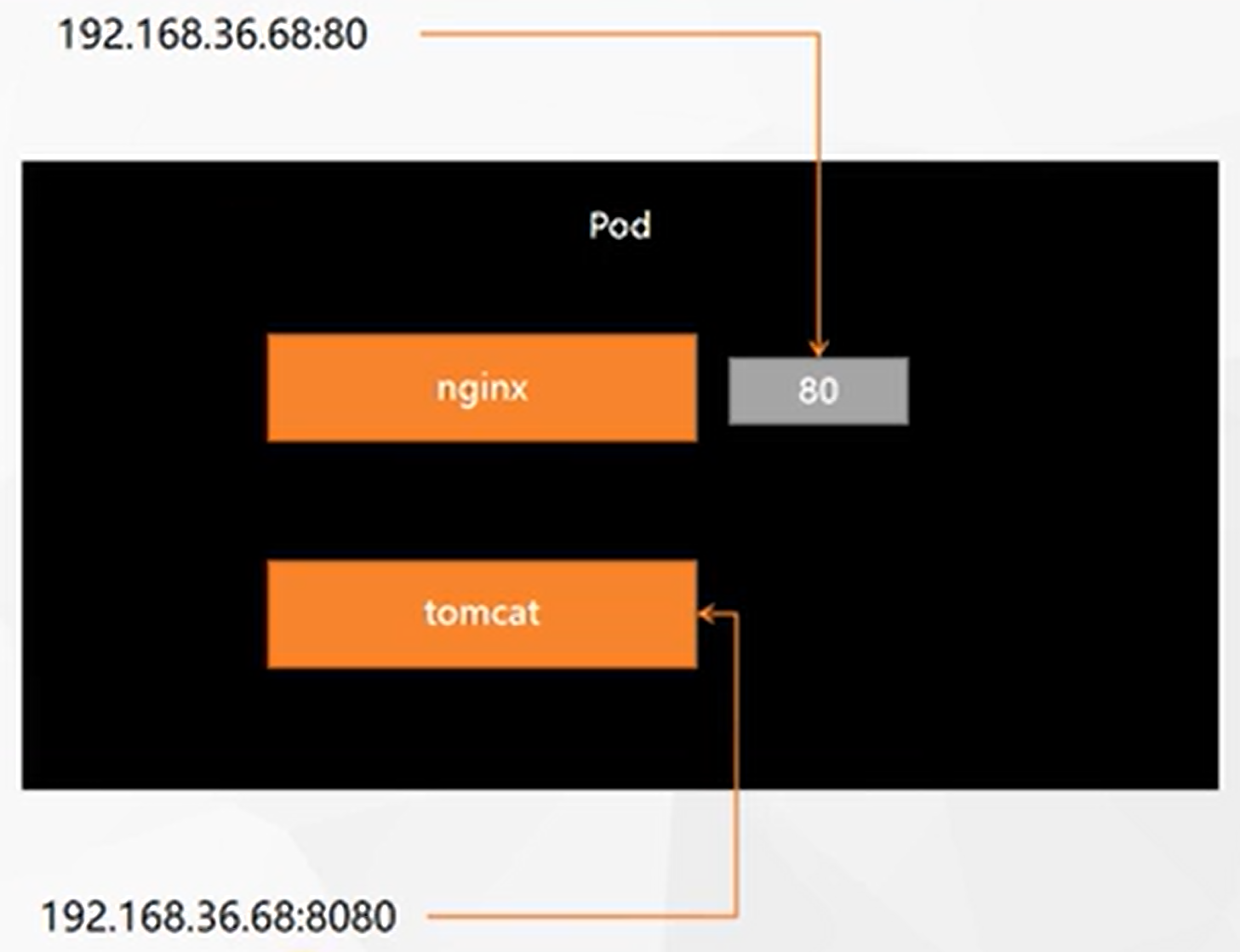
一个pod中有多个容器创建
apiVersion: v1 kind: Pod metadata: labels: run: myapp name: myapp spec: containers: - image: 10.4.32.48:5000/nginx name: nginx - image: 10.4.32.48:5000/tomcat:8.5.68 name: tomcat- 只有一个IP
- 默认访问到的是nginx,因为nginx是80端口
- 如果访问的是8080端口,则会访问到tomcat
- nginx访问tomcat,仅需
127.0.0.1:8080,同一个pod内共享网络空间和存储 - 如果一个pod中多个容器占用同样的端口,会导致启动失败
![在这里插入图片描述]()
-
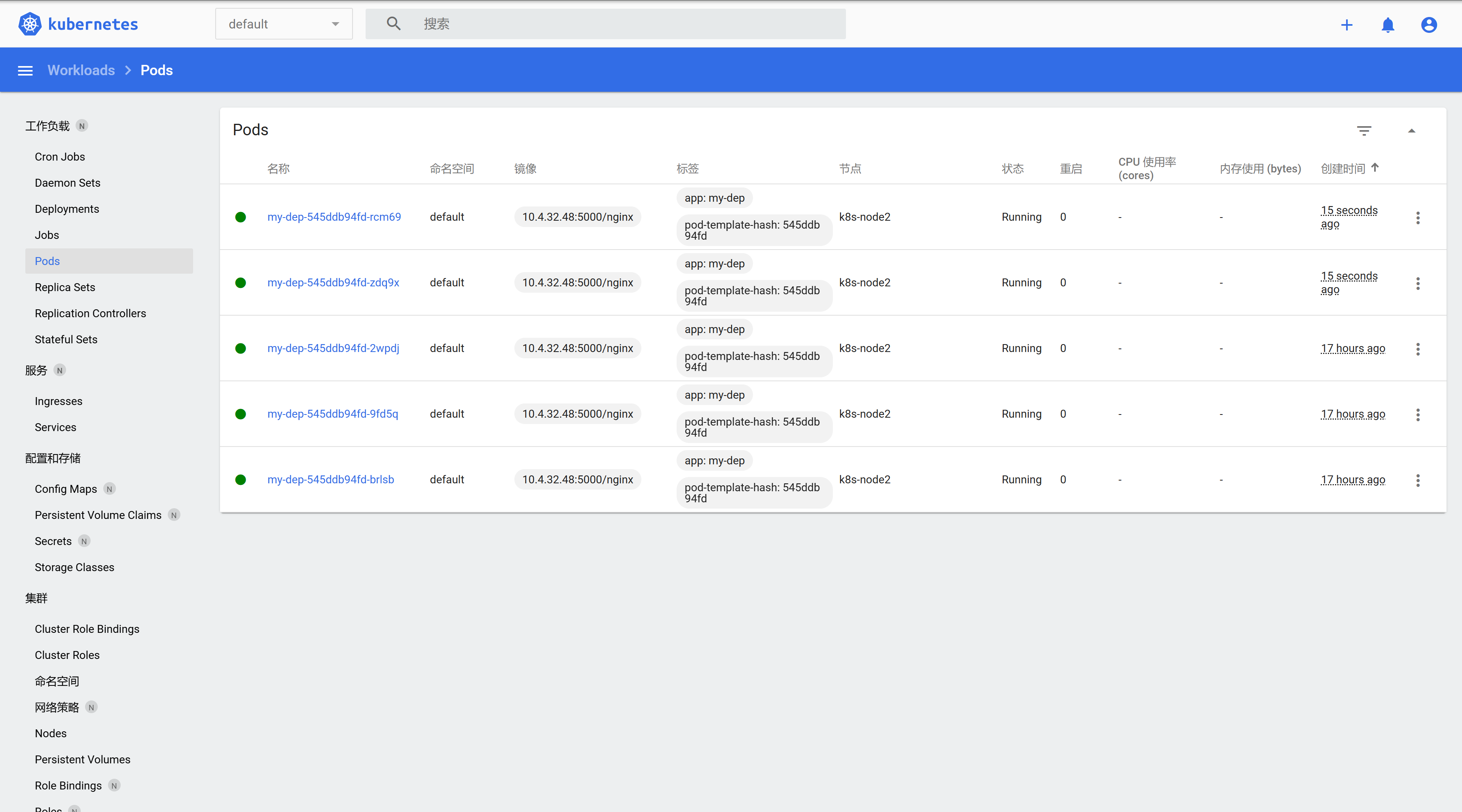
查看pod状态:
kubectl get pod [-n 命名空间] -
查看pod怎么了:
kubectl describe pod pod名称 [-n 名称空间] -
删除pod:
kubectl delete pod pod名称 [-n 名称空间] -
查看pod日志:
kubectl logs [-f] pod名称-f:一直跟踪
-
查看集群指标信息:
kubectl top nodes,其中cpu来说1000m就是用了一个核[root@k8s-master yamls]# kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% k8s-master 298m 3% 6654Mi 21% k8s-node1 177m 2% 2460Mi 16% k8s-node2 554m 6% 2323Mi 15%类似的查看每个pod的指标信息:
kubectl top pods -A -
每个pod,k8s都会分配一个ip:
kubectl get pod -owide,后面就能使用pod的IP+容器端口,就能访问到其中的应用❓ 为什么是192.168.xxx.xxx?
因为在
kubeadm init的时候,--pod-network-cidr写的是192.168.0.0/16。集群中的任意机器的任意应用都能通过 Pod 分配的IP来访问这个Pod
注意:只能在集群内访问,集群外不可以
-
进入容器:
kubectl exec -it mynginx -- /bin/bash
-
-
Deployment
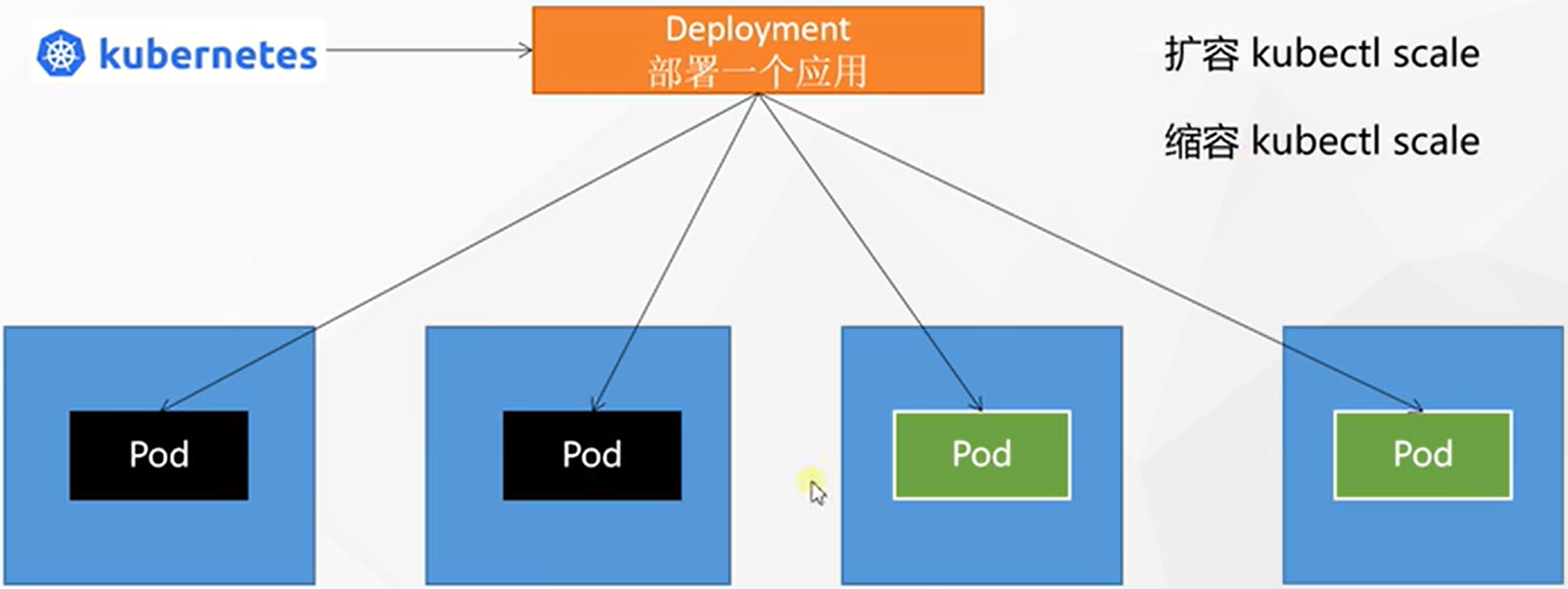
控制Pod,使Pod拥有多副本,自愈,扩缩容等能力
- 创建:
kubectl create deployment mytomcat --image=10.4.32.48:5000/tomcat:8.5.68 - 删除:
kubectl delete deploy mytomcat - 查看:
kubectl get deploy
特点:
-
自愈能力:用 deployment 部署的容器即使delete之后会自动重启一个新的
-
多副本:
kubectl create deploy my-dep --image=10.4.32.48:5000/nginx --replicas=3![在这里插入图片描述]()
通过yaml创建部署
apiVersion: apps/v1 kind: Deployment metadata: labels: app: my-dep name: my-dep spec: replicas: 3 selector: matchLabels: app: my-dep template: metadata: labels: app: my-dep spec: containers: - image: nginx name: nginx -
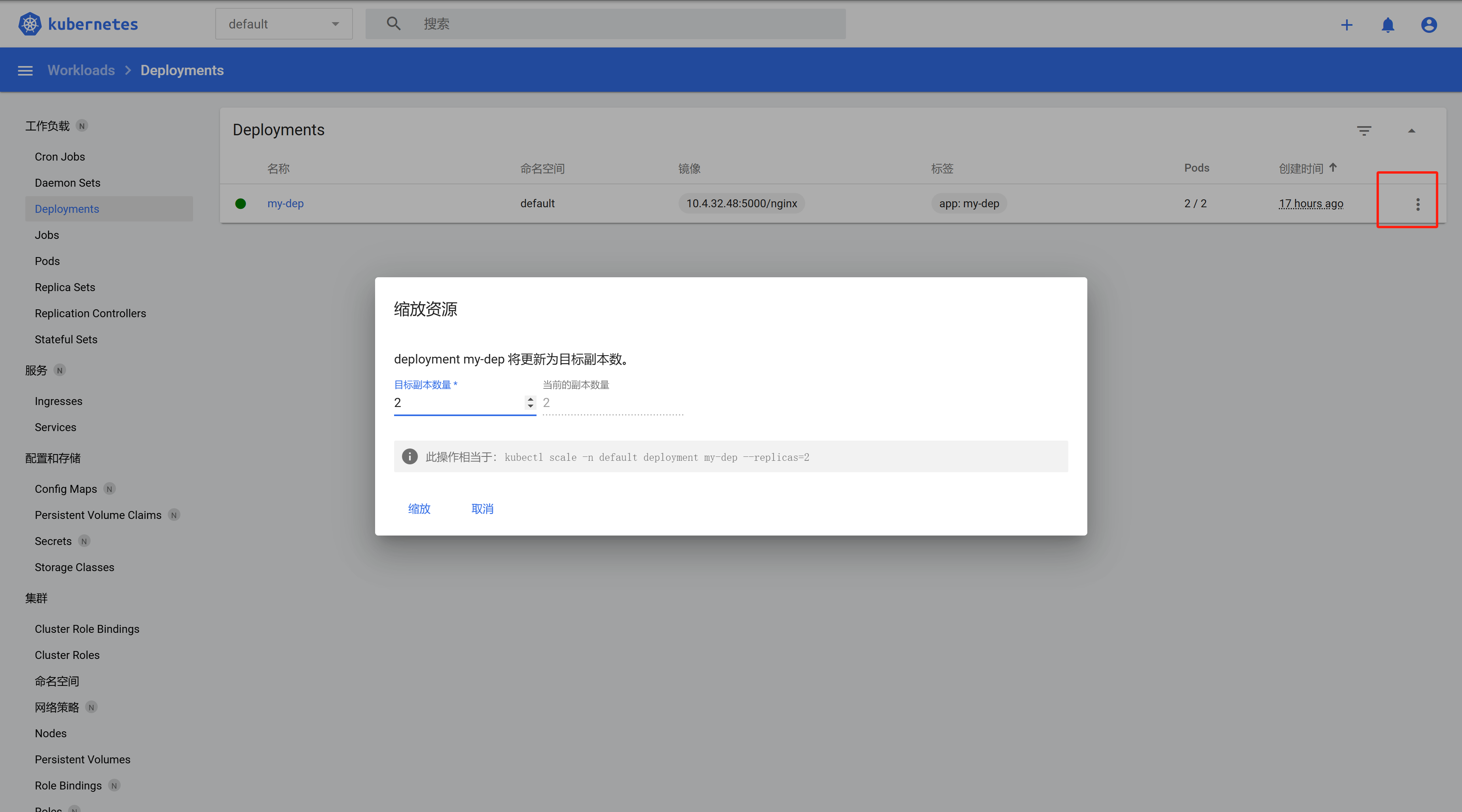
扩缩容
![在这里插入图片描述]()
-
命令行:
kubectl scale deploy/my-dep --replicas=5,类似的,缩容就是把replicas的数字降低![在这里插入图片描述]()
-
热编辑yaml:
kubectl edit deploy my-dep这时候会打开yaml文件,把里面的
replicas参数改为想要的数值,wq后即完成扩缩容 -
可视化界面扩缩容:
![在这里插入图片描述]()
-
-
自愈&故障转移
- pod炸了会自动重启
- node机器炸了就完蛋了,只能在别的机器启
⚠️ 没错,我自己测,直接把work节点reboot了,然后发现起不来啦
Error querying BIkD: unable to connect to Binov4 socket: dial wix /var/run/calico/bird.ctl: connect: connection refused calico/node is not ready: BIRD is not ready: BGP not established with![在这里插入图片描述]()
解决:https://www.cnblogs.com/exmyth/p/17259198.html
# [my new add content] - name: IP_AUTODETECTION_METHOD value: "interface=eth.*" # Cluster type to identify the deployment type - name: CLUSTER_TYPE value: "k8s,bgp" # Auto-detect the BGP IP address. - name: IP value: "autodetect" # Enable IPIP - name: CALICO_IPV4POOL_IPIP value: "Always"官方提供的yaml文件中,ip识别策略(IPDETECTMETHOD)没有配置,即默认为first-found,这会导致一个网络异常的ip作为nodeIP被注册,从而影响node-to-node mesh。我们可以修改成can-reach或者interface的策略,尝试连接某一个Ready的node的IP,以此选择出正确的IP。
- name: IP_AUTODETECTION_METHOD # 增加内容 value: "interface=eth.*" 或者 value: "interface=eth0" # 增加内容备注:记得
systemctl enable kubelet,没自启很难办啊,我排查了半天奶奶滴!😢 -
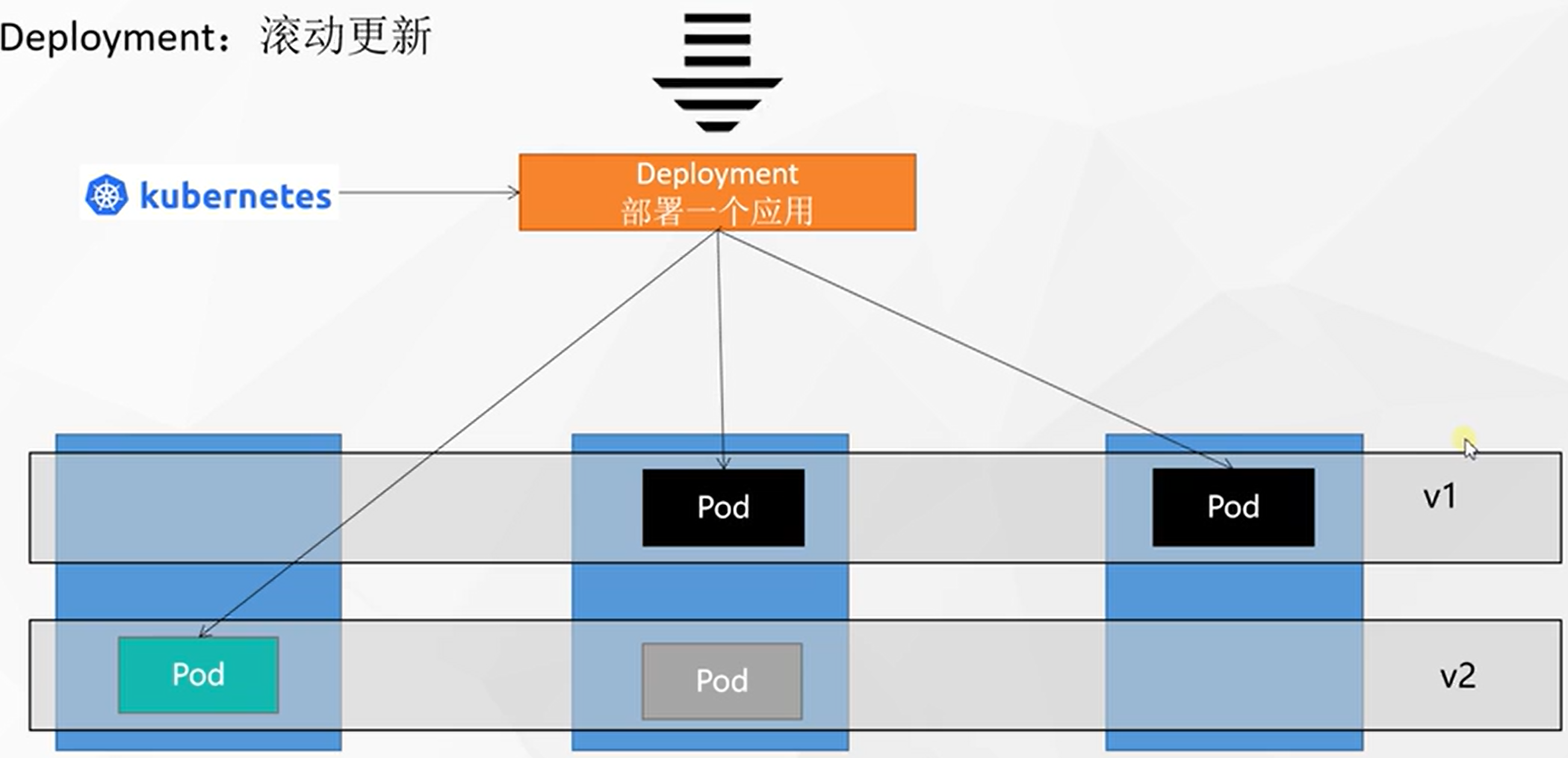
滚动更新
启一个新的杀一个老的,不断循环。
![在这里插入图片描述]()
-
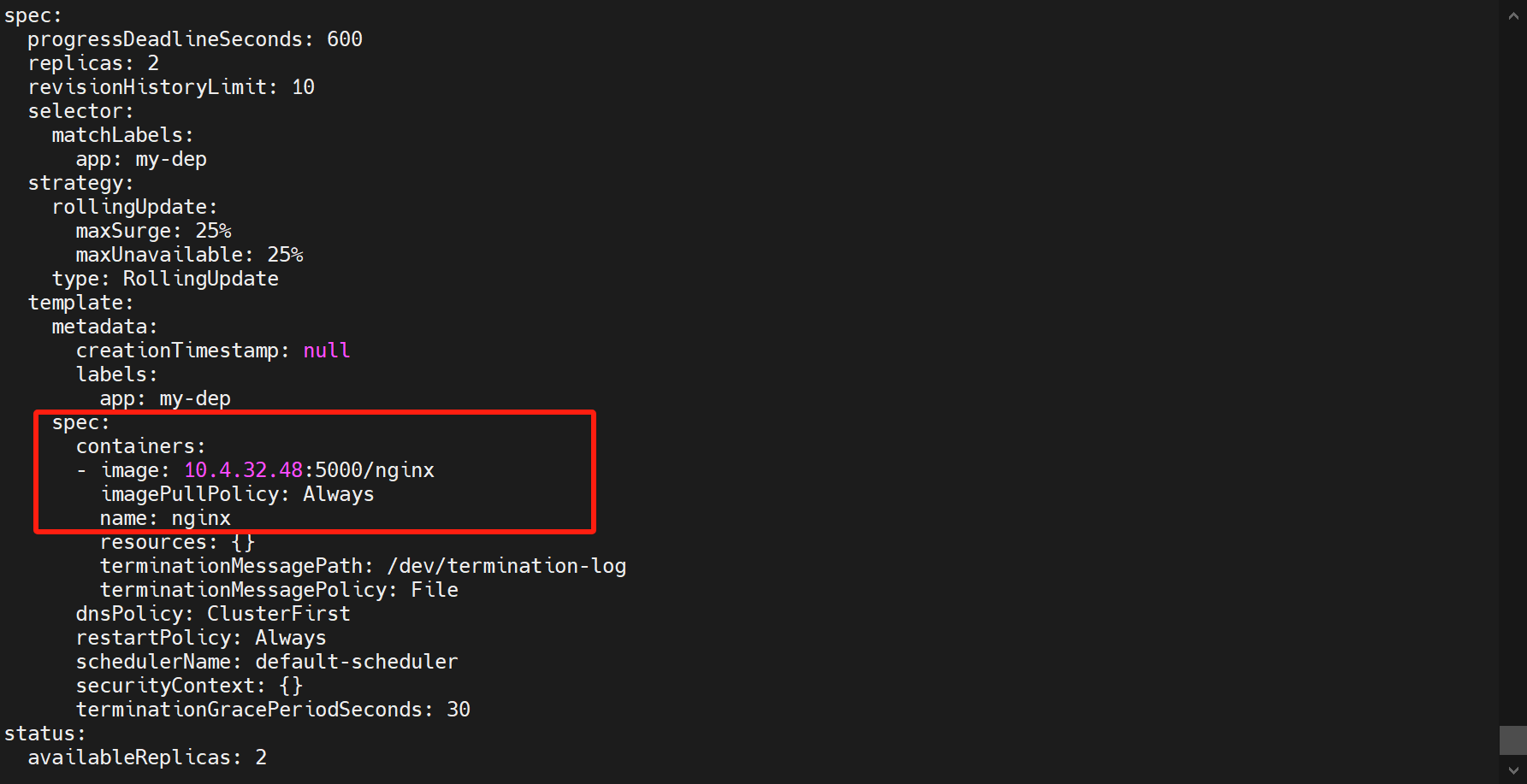
查看deploy的详情:
kubectl get deploy my-dep -oyaml![在这里插入图片描述]()
-
kubectl set image deploy/my-dep nginx=10.4.32.48:5000/nginx:1.16.1 --record:修改deploy的my-dep中nginx镜像为新的镜像,然后记录这次版本更新
-
-
版本回退
- 查看历史记录:
kubectl rollout history deployment/my-dep - 查看历史记录详情:
kubectl rollout history deployment/my-dep --revision=2 - 回滚上次:
kubectl rollout undo deployment/my-dep - 回滚指定版本:
kubectl rollout undo deployment/my-dep --to-revision=2
- 查看历史记录:
-
其他工作负载
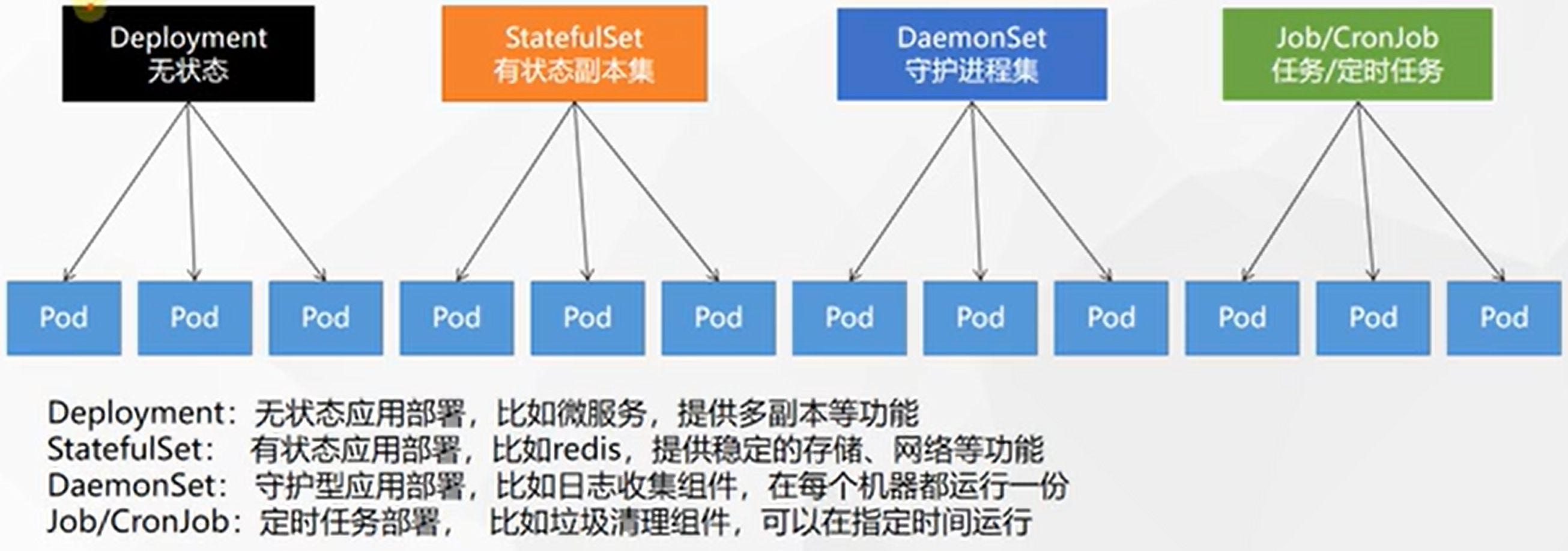
除了Deployment,k8s还有
StatefulSet、DaemonSet、Job等 类型资源。我们都称为工作负载。有状态应用使用StatefulSet部署,无状态应用使用Deployment部署:https://kubernetes.io/zh/docs/concepts/workloads/controllers/![在这里插入图片描述]()
Deployment:无状态应用,服务在哪儿拉起来都行StatefulSet:有状态应用,服务挂了在别的地方拉起来数据还要有DaemonSet:在每个机器上都有且一份,比如日志收集Job/CronJob:定时任务
- 创建:
-
Service
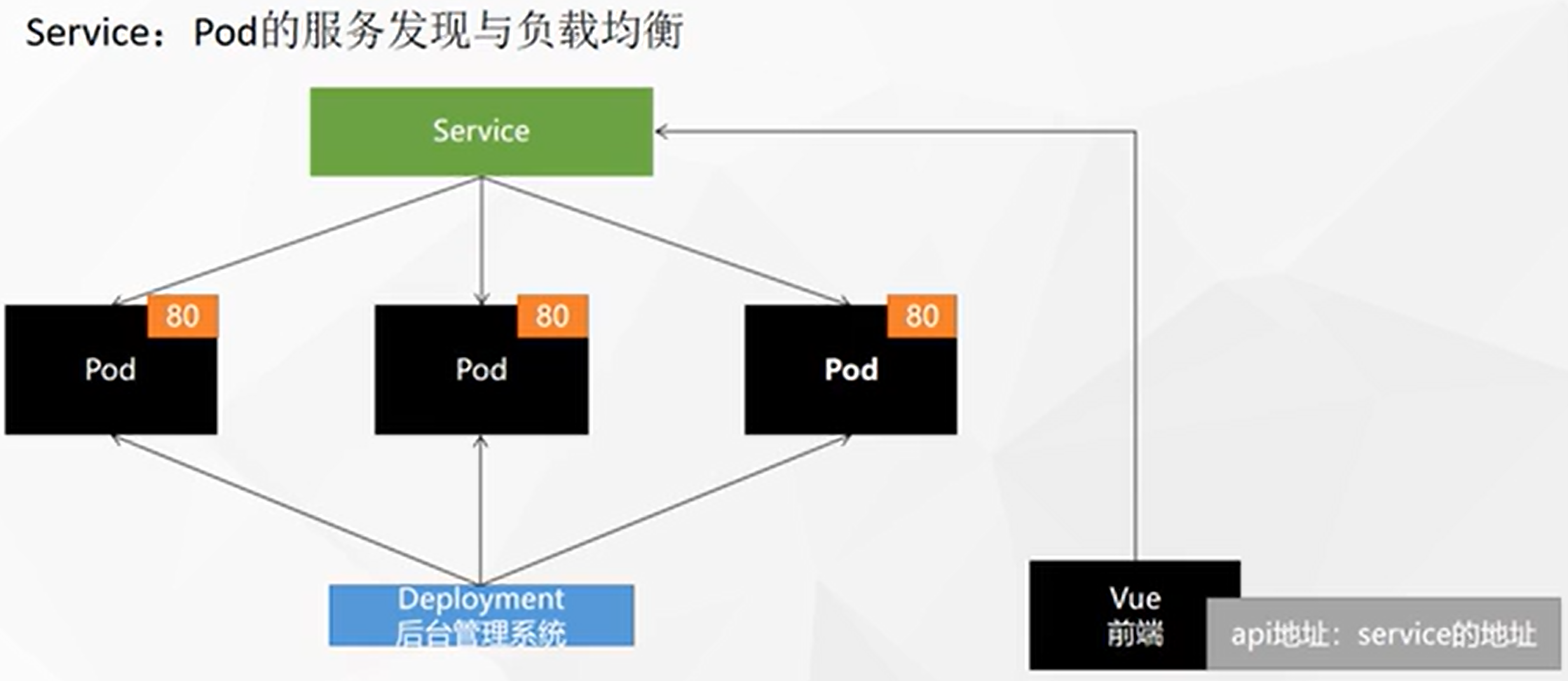
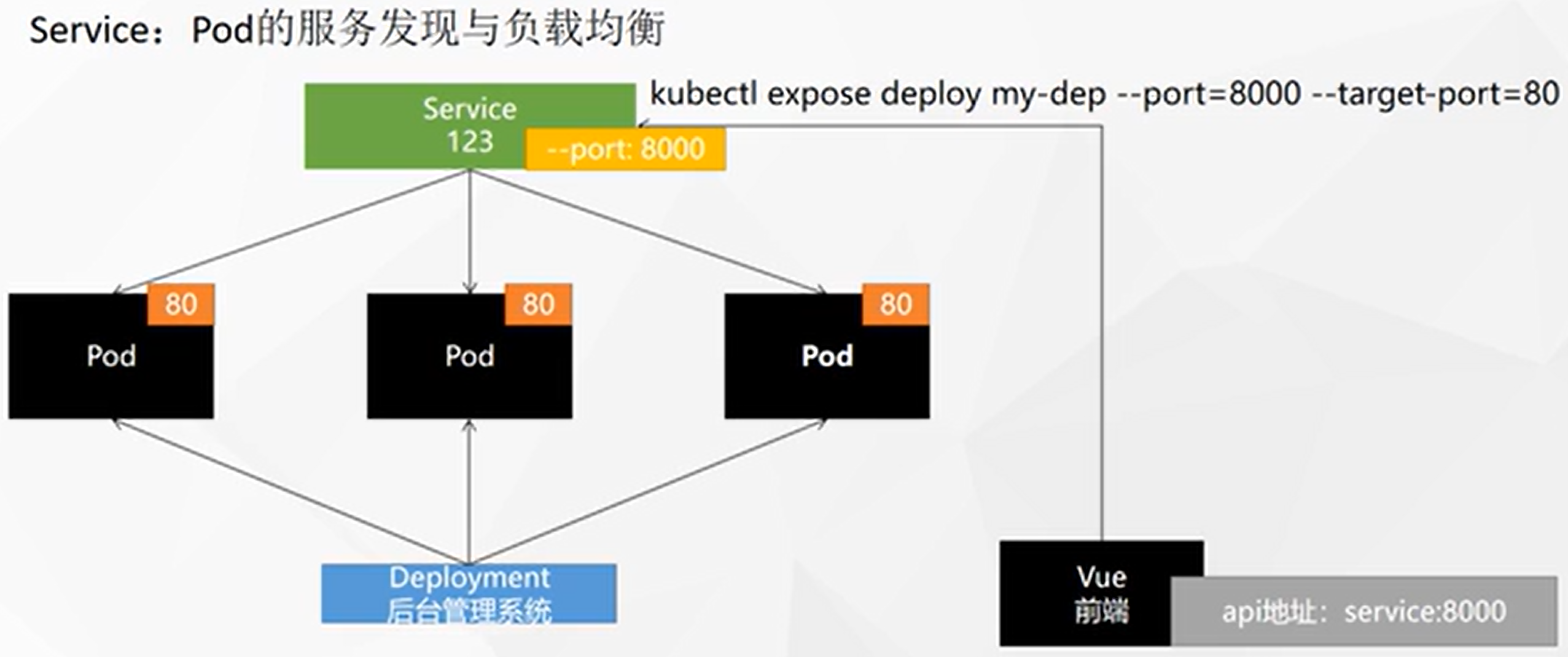
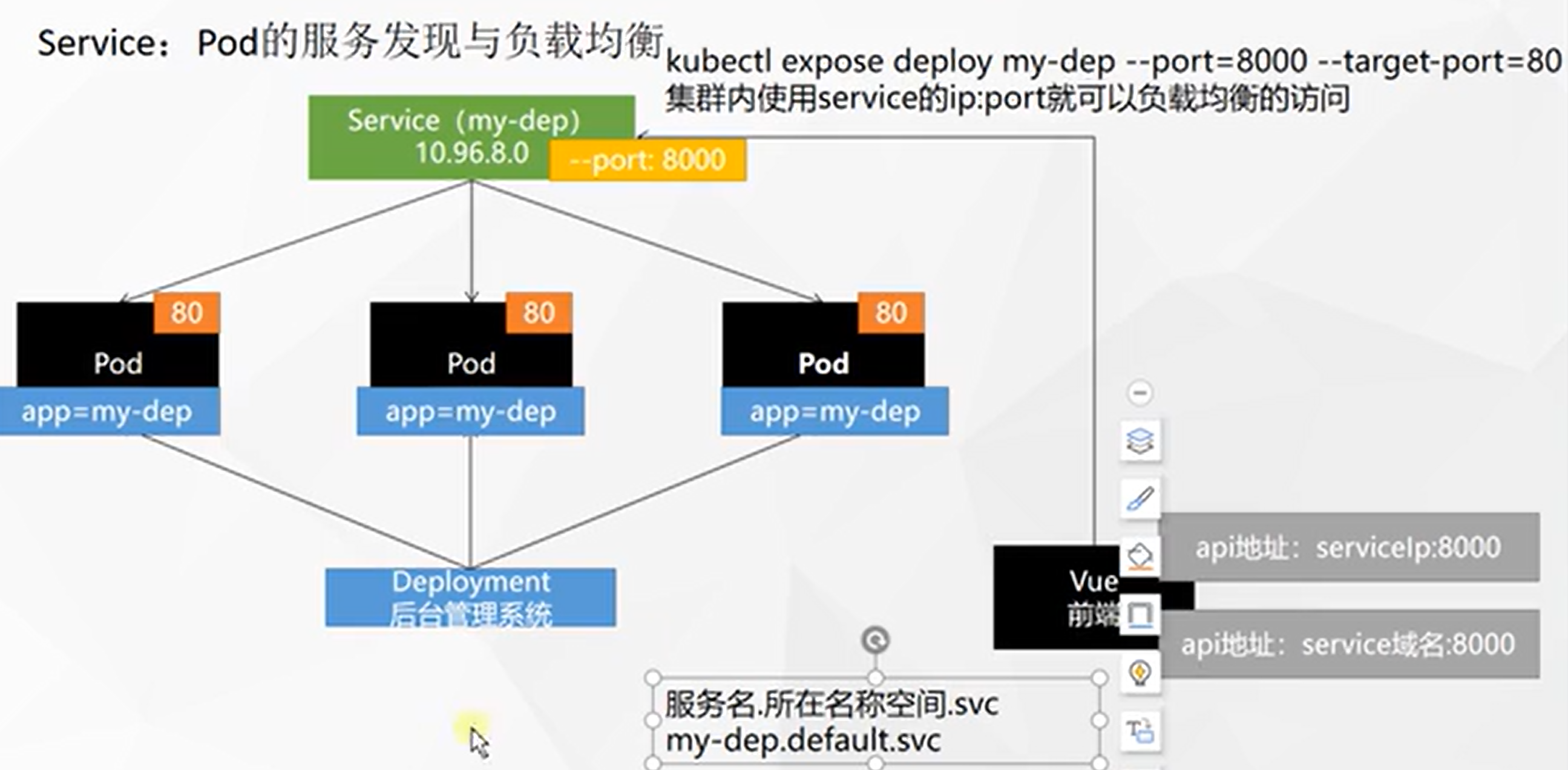
将一组 Pods 公开为网络服务的抽象方法。
![在这里插入图片描述]()
-
暴露Service资源的端口:
kubectl expose deploy my-dep --port=8000 --target-port=80 [--type=ClusterIP],默认的类型是集群IP -
查看当前Service的IP:
kubectl get service[root@k8s-master ~]# kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10d my-dep ClusterIP 10.96.26.98 <none> 8000/TCP 60s -
访问Service:
curl 10.96.26.98:8000,其实是负载均衡的访问[root@k8s-master ~]# curl 10.96.26.98:8000 3333 [root@k8s-master ~]# curl 10.96.26.98:8000 3333 [root@k8s-master ~]# curl 10.96.26.98:8000 2222 [root@k8s-master ~]# curl 10.96.26.98:8000 3333 [root@k8s-master ~]# curl 10.96.26.98:8000 1111 [root@k8s-master ~]# curl 10.96.26.98:8000 1111![在这里插入图片描述]()
-
使用标签检索Pod:
kubectl get pod -l app=my-dep -
查看Pod的标签:
kubectl get pod --show-labels -
使用yaml创建Service资源:
apiVersion: v1 kind: Service metadata: labels: app: my-dep name: my-dep spec: selector: app: my-dep ports: - port: 8000 protocol: TCP targetPort: 80 -
在pod内部可以通过
服务.default.svc:端口Service域名 访问接口:curl my-dep.default.svc:8000,⚠️ 在机器上是不行的![在这里插入图片描述]()
-
Service的服务发现机制可以让 Deploy 在缩放的时候自动同步 添加、删除 服务
-
⭐NodePort:
kubectl expose deploy my-dep --port=8000 --target-port=80 --type=NodePort,与ClusterIP只能在集群内部访问不同的是,NodePort可以在集群外部访问💡 NodePort默认范围在 30000-32767 之间
[root@k8s-master ~]# kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 10d my-dep NodePort 10.96.74.163 <none> 8000:31567/TCP 5s现在通过任意一台机器+上面PORT的方式,即可实现负载均衡的访问,比如不容浏览器尝试:
http://10.4.32.48:31567/- 查看service:
kubectl get svc - 删除service:
kubectl delete svc my-dep
- 查看service:
-
-
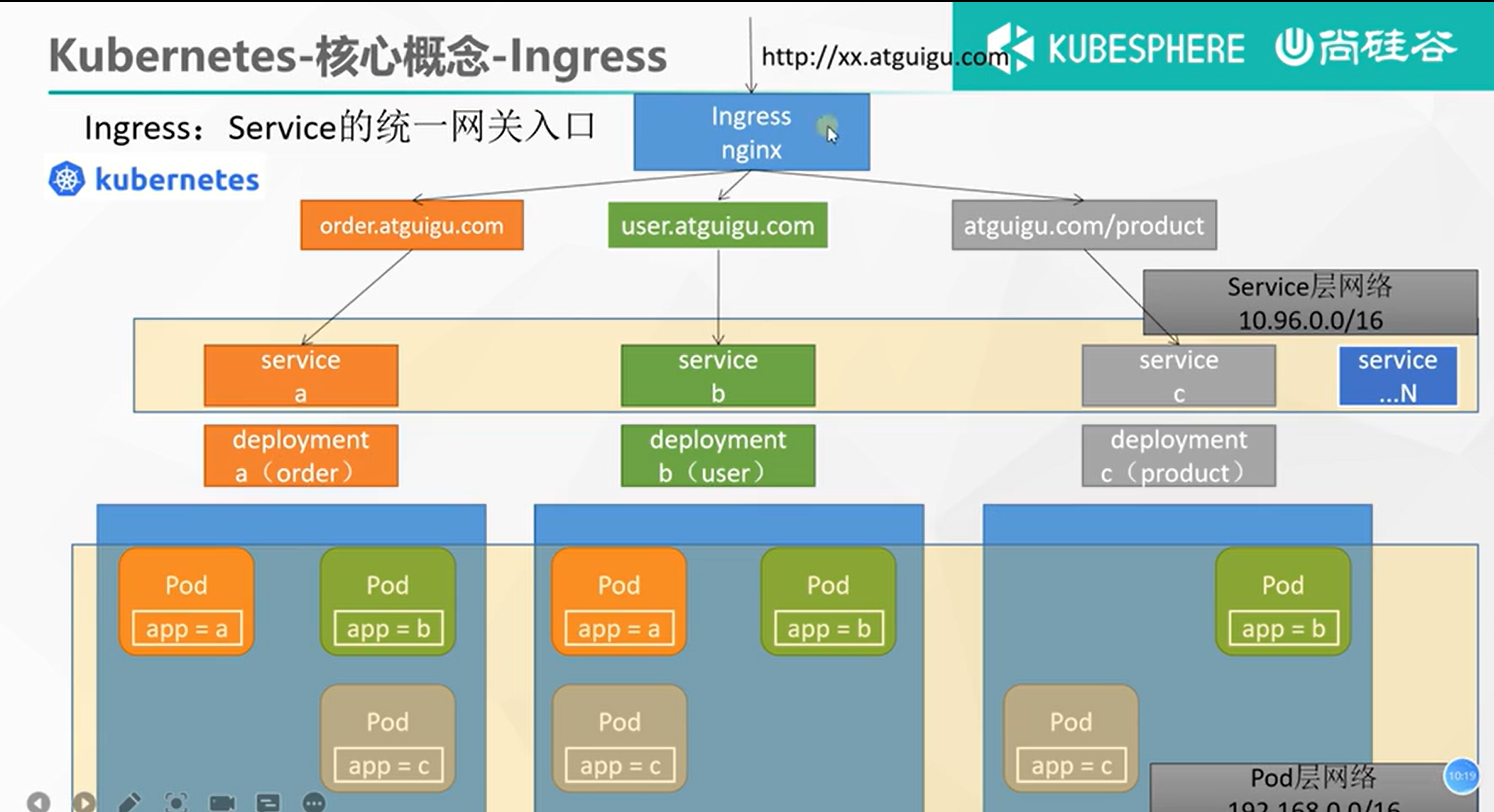
Ingress
Service的统一网关入口,PS:Service相当于是Pod的入口
官方文档:https://kubernetes.github.io/ingress-nginx/
![在这里插入图片描述]()
-
Ingress下载
-
获取指定版本的Ingress资源的yaml文件:https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml
-
从yaml中显示的内容可以看到需要以下镜像:
- k8s.gcr.io/ingress-nginx/controller:v0.46.0@sha256:52f0058bed0a17ab0fb35628ba97e8d52b5d32299fbc03cc0f6c7b9ff036b61a
- docker.io/jettech/kube-webhook-certgen:v1.5.1
-
修改yaml,因为我是用自己的registry,这镜像后面跟一堆不好整啊,我给删了,同样的yaml中的也要删哦,然后直接换成我的镜像 😁
# image: k8s.gcr.io/ingress-nginx/controller:v0.46.0@sha256:52f0058bed0a17ab0fb35628ba97e8d52b5d32299fbc03cc0f6c7b9ff036b61a 10.4.32.48:5000/ingress-nginx/controller:v0.46.0
-
-
Ingress部署:
kubectl apply -f xxx.yaml
[root@k8s-master ~]# kubectl get svc -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d default my-dep NodePort 10.96.74.163 <none> 8000:31567/TCP 3h38m ingress-nginx ingress-nginx-controller NodePort 10.96.249.10 <none> 80:32550/TCP,443:30767/TCP 25m ingress-nginx ingress-nginx-controller-admission ClusterIP 10.96.48.15 <none> 443/TCP 25m kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 11d kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.51.184 <none> 8000/TCP 9d kubernetes-dashboard kubernetes-dashboard NodePort 10.96.223.53 <none> 443:31345/TCP 9d可以看到,部署完了之后会产生2个Service,其中一个是以NodePort形式暴露,分别是
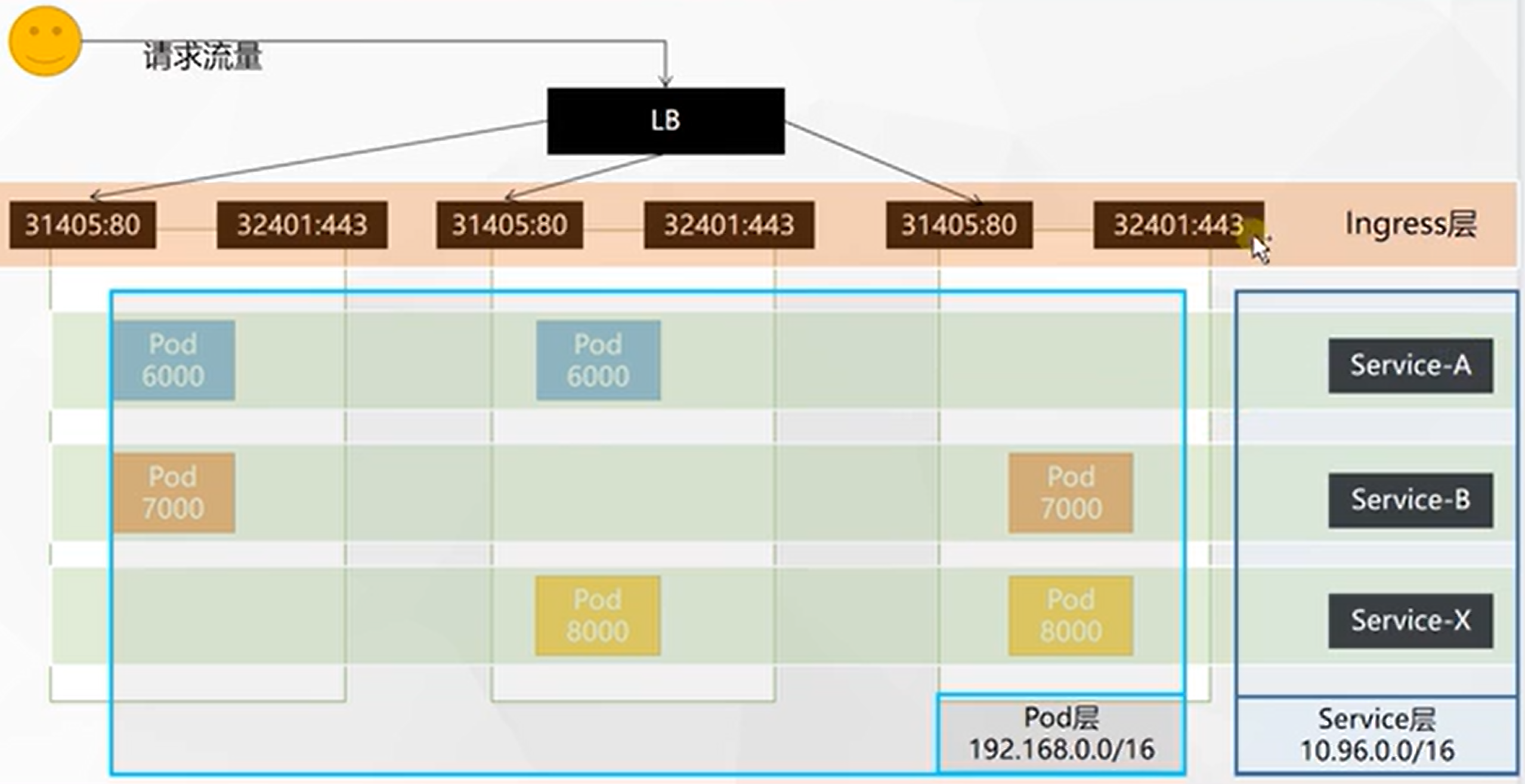
80:32550/TCP,443:30767/TCP我们访问看看,可以发现,其实也是nginx。未来的请求都会从这两个入口进。
![在这里插入图片描述]()
![在这里插入图片描述]()
- 测试
apiVersion: apps/v1 kind: Deployment metadata: name: hello-server spec: replicas: 2 selector: matchLabels: app: hello-server template: metadata: labels: app: hello-server spec: containers: - name: hello-server image: 10.4.32.48:5000/lfy_k8s_images/hello-server ports: - containerPort: 9000 --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-demo name: nginx-demo spec: replicas: 2 selector: matchLabels: app: nginx-demo template: metadata: labels: app: nginx-demo spec: containers: - image: 10.4.32.48:5000/nginx name: nginx --- apiVersion: v1 kind: Service metadata: labels: app: nginx-demo name: nginx-demo spec: selector: app: nginx-demo ports: - port: 8000 protocol: TCP targetPort: 80 --- apiVersion: v1 kind: Service metadata: labels: app: hello-server name: hello-server spec: selector: app: hello-server ports: - port: 8000 protocol: TCP targetPort: 9000-
域名访问
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-host-bar spec: ingressClassName: nginx rules: - host: "hello.atguigu.com" http: paths: - pathType: Prefix path: "/" backend: service: name: hello-server port: number: 8000 - host: "demo.atguigu.com" http: paths: - pathType: Prefix # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404 path: "/nginx" backend: service: # java,比如使用路径重写,去掉前缀nginx name: nginx-demo port: number: 8000[root@k8s-master yamls]# kubectl get ingress NAME CLASS HOSTS ADDRESS PORTS AGE ingress-host-bar nginx hello.atguigu.com,demo.atguigu.com 80 9s -
为了实现域名到IP的跳转,我们配置hosts
10.4.32.48 hello.atguigu.com 10.4.32.48 demo.atguigu.com -
然后测试:
-
http://hello.atguigu.com:32550/- 正常显示 hello world
-
http://demo.atguigu.com:32550/- 报错,且报错为 nginx 提示,说明是网关层 ingress 拦截
-
http://demo.atguigu.com:32550/nginx-
报错,且报错为 nginx/1.27.2 提示,说明是 pod 拦截
-
如果在
/usr/share/nginx/html中编辑一个文件nginx:echo 111 > nginx。则会发现,不断请求的时候,由于负载均衡,偶尔会下载一个内容为111的文件
-
-
-
在线修改 ingress:
kubectl edit ing ingress-host-bar
-
Ingress高级
-
路径重写:https://kubernetes.github.io/ingress-nginx/examples/rewrite/
$ echo ' apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: nginx.ingress.kubernetes.io/use-regex: "true" nginx.ingress.kubernetes.io/rewrite-target: /$2 name: rewrite namespace: default spec: ingressClassName: nginx rules: - host: rewrite.bar.com http: paths: - path: /something(/|$)(.*) pathType: ImplementationSpecific backend: service: name: http-svc port: number: 80 ' | kubectl create -f -apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: nginx.ingress.kubernetes.io/rewrite-target: /$2 name: ingress-host-bar spec: ingressClassName: nginx rules: - host: "hello.atguigu.com" http: paths: - pathType: Prefix path: "/" backend: service: name: hello-server port: number: 8000 - host: "demo.atguigu.com" http: paths: - pathType: Prefix path: "/nginx(/|$)(.*)" # 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404 backend: service: name: nginx-demo ## java,比如使用路径重写,去掉前缀nginx port: number: 8000 -
限流:https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/#rate-limiting
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-limit-rate annotations: nginx.ingress.kubernetes.io/limit-rps: "1" spec: ingressClassName: nginx rules: - host: "haha.atguigu.com" http: paths: - pathType: Exact path: "/" backend: service: name: nginx-demo port: number: 8000访问过快就会返回:503 服务不可用
-
-
小结
![在这里插入图片描述]()
-
-
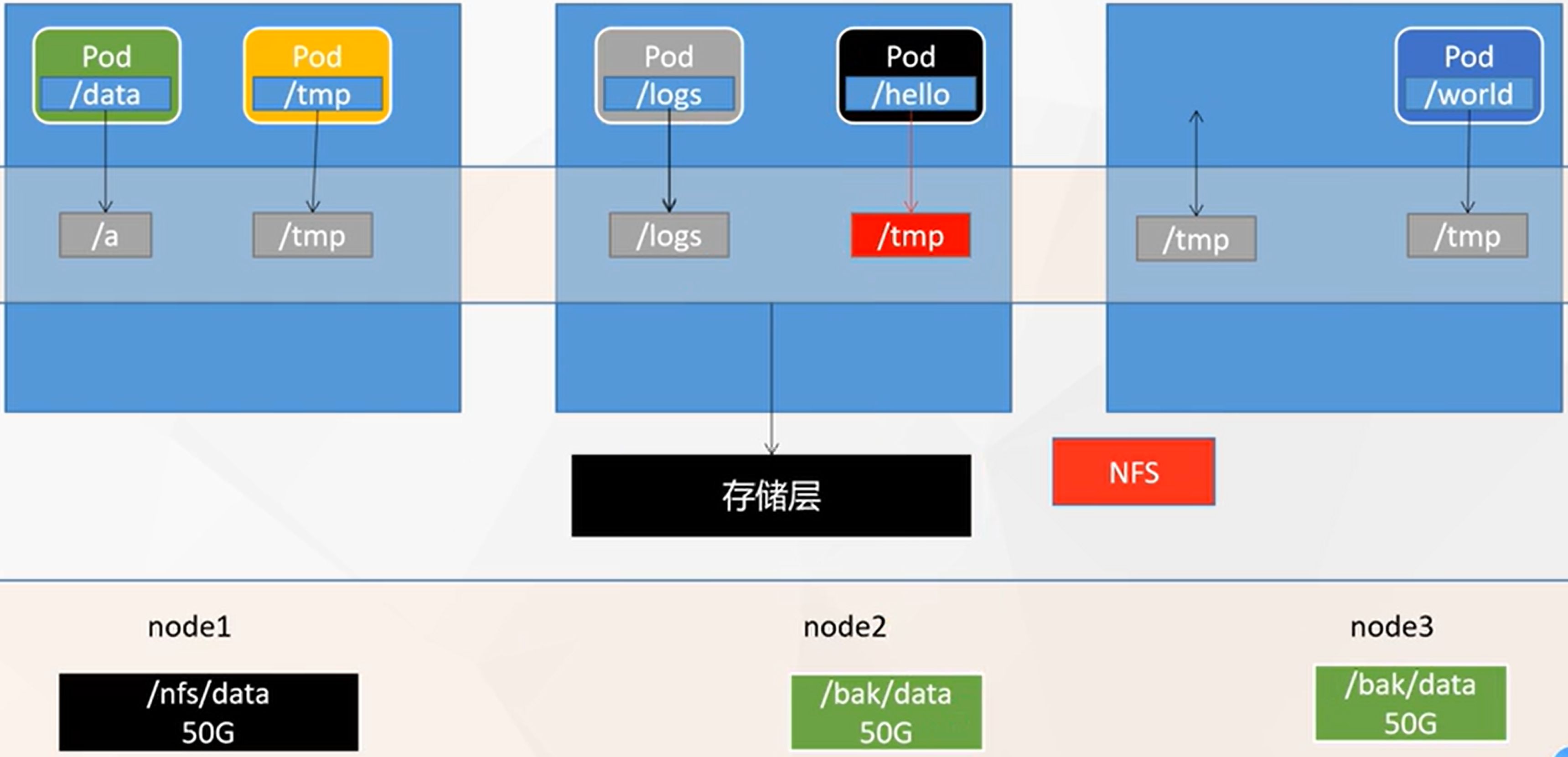
存储抽象
![在这里插入图片描述]()
-
环境准备
-
所有节点
# 所有机器安装 yum install -y nfs-utils💡 我要搞离线啊马飞,开冲
-
这次!我选择了一个新的方式:
yum install --downloadonly --downloaddir=/data nfs-utils -
当然了,前提是我做了一个 kylinv10sp3 的镜像哈哈,然后在有网的环境下搞的
![在这里插入图片描述]()
-
但是!需要注意的是,这些依赖很有可能你都有了,所以要从上到下的安装,缺什么补什么,比如这个,我验证之后复现,其实只需要两个rpm:
rpm -ivh nfs-utils-help-2.5.1-5.p03.ky10.x86_64.rpmrpm -ivh nfs-utils-2.5.1-5.p03.ky10.x86_64.rpm
-
-
主节点
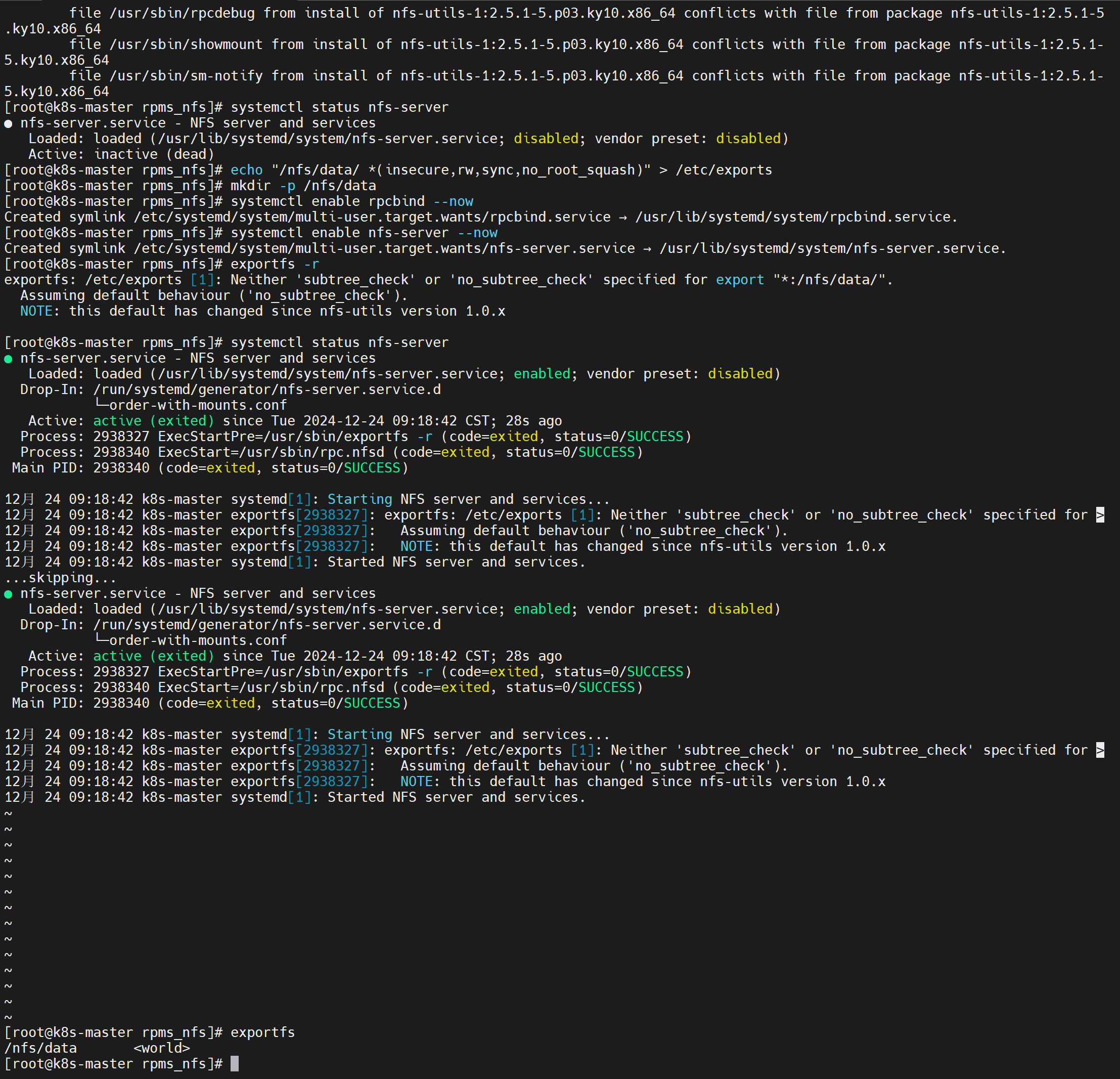
# nfs主节点 echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports mkdir -p /nfs/data systemctl enable rpcbind --now systemctl enable nfs-server --now # 配置生效 exportfs -r![在这里插入图片描述]()
完成了检查一下:
exportfs -
从节点
# 子节点看看远程服务器有哪些可以同步 showmount -e 10.4.32.48 # 执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /root/nfsmount mkdir -p /nfs/data mount -t nfs 10.4.32.48:/nfs/data /nfs/data # 写入一个测试文件,在服务器中写,看看子节点有没有同步更新 echo "hello nfs server" > /nfs/data/test.txt -
原生方式数据挂载:
kubectl apply -f deploy.yamlapiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-pv-demo name: nginx-pv-demo spec: replicas: 2 selector: matchLabels: app: nginx-pv-demo template: metadata: labels: app: nginx-pv-demo spec: containers: - image: 10.4.32.48:5000/nginx name: nginx volumeMounts: - name: html mountPath: /usr/share/nginx/html volumes: - name: html nfs: server: 10.4.32.48 path: /nfs/data/nginx-pv
-
-
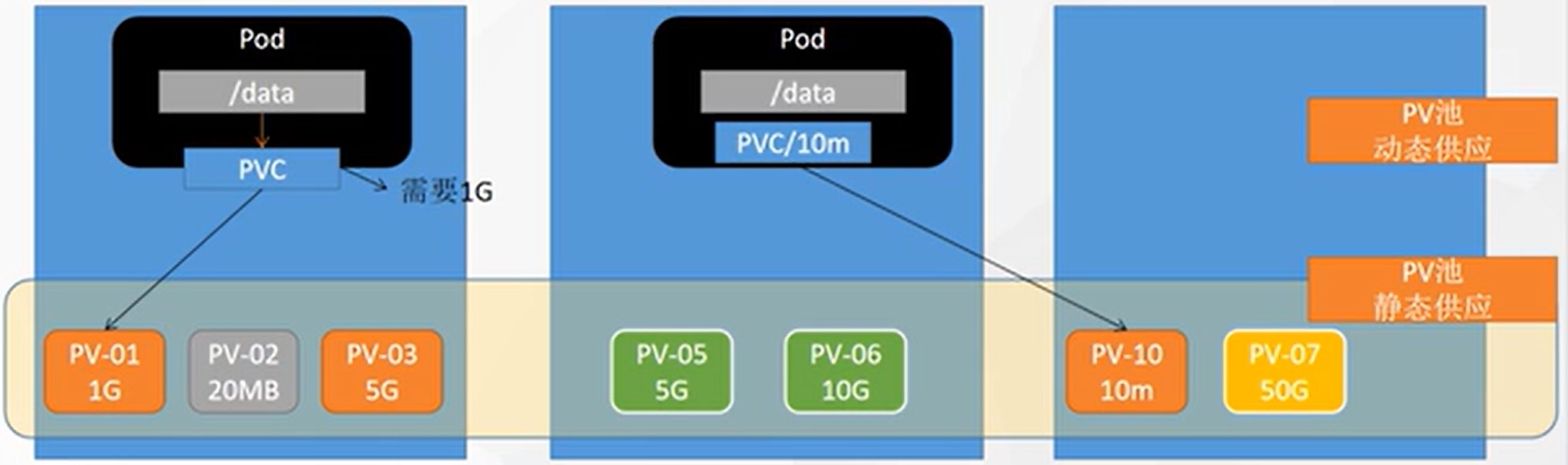
PV&PVC
😅 其实这是静态供应看看得了,后续要讲动态,才是实战的关键。
![在这里插入图片描述]()
❓ 上述直接挂载的问题:
- 当deploy删掉的时候,挂载的内容不会删除
- 每次创建deploy之前,需要新建目录
💡 解决:
- PV:持久卷(Persistent Volume),将应用需要持久化的数据保存到指定位置
- PVC:持久卷申明(Persistent Volume Claim),申明需要使用的持久卷规格
-
创建PV池
-
静态供应
# nfs主节点 mkdir -p /nfs/data/01 mkdir -p /nfs/data/02 mkdir -p /nfs/data/03 -
创建PV
apiVersion: v1 kind: PersistentVolume metadata: name: pv01-10m spec: capacity: storage: 10M accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/01 server: 10.4.32.48 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv02-1gi spec: capacity: storage: 1Gi accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/02 server: 10.4.32.48 --- apiVersion: v1 kind: PersistentVolume metadata: name: pv03-3gi spec: capacity: storage: 3Gi accessModes: - ReadWriteMany storageClassName: nfs nfs: path: /nfs/data/03 server: 10.4.32.48 -
查看资源:
kubectl get pv[root@k8s-master yamls]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv01-10m 10M RWX Retain Available nfs 10s pv02-1gi 1Gi RWX Retain Available nfs 10s pv03-3gi 3Gi RWX Retain Available nfs 10s
-
-
PVC创建与绑定
申请就apply,释放就是delete,基于yaml操作
查看:
kubectl get pvckind: PersistentVolumeClaim apiVersion: v1 metadata: name: nginx-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 200Mi storageClassName: nfs真正使用绑定pod:
apiVersion: apps/v1 kind: Deployment metadata: labels: app: nginx-deploy-pvc name: nginx-deploy-pvc spec: replicas: 2 selector: matchLabels: app: nginx-deploy-pvc template: metadata: labels: app: nginx-deploy-pvc spec: containers: - image: 10.4.32.48:5000/nginx name: nginx volumeMounts: - name: html mountPath: /usr/share/nginx/html volumes: - name: html persistentVolumeClaim: claimName: nginx-pvc查看情况:
kubectl get pv,pvc[root@k8s-master yamls]# kubectl get pvc,pv NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/nginx-pvc Bound pv03-3gi 3Gi RWX nfs 2m27s NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE persistentvolume/pv01-10m 10M RWX Retain Available nfs 11m persistentvolume/pv02-1gi 1Gi RWX Retain Released default/nginx-pvc nfs 11m persistentvolume/pv03-3gi 3Gi RWX Retain Bound default/nginx-pvc nfs 11m
-
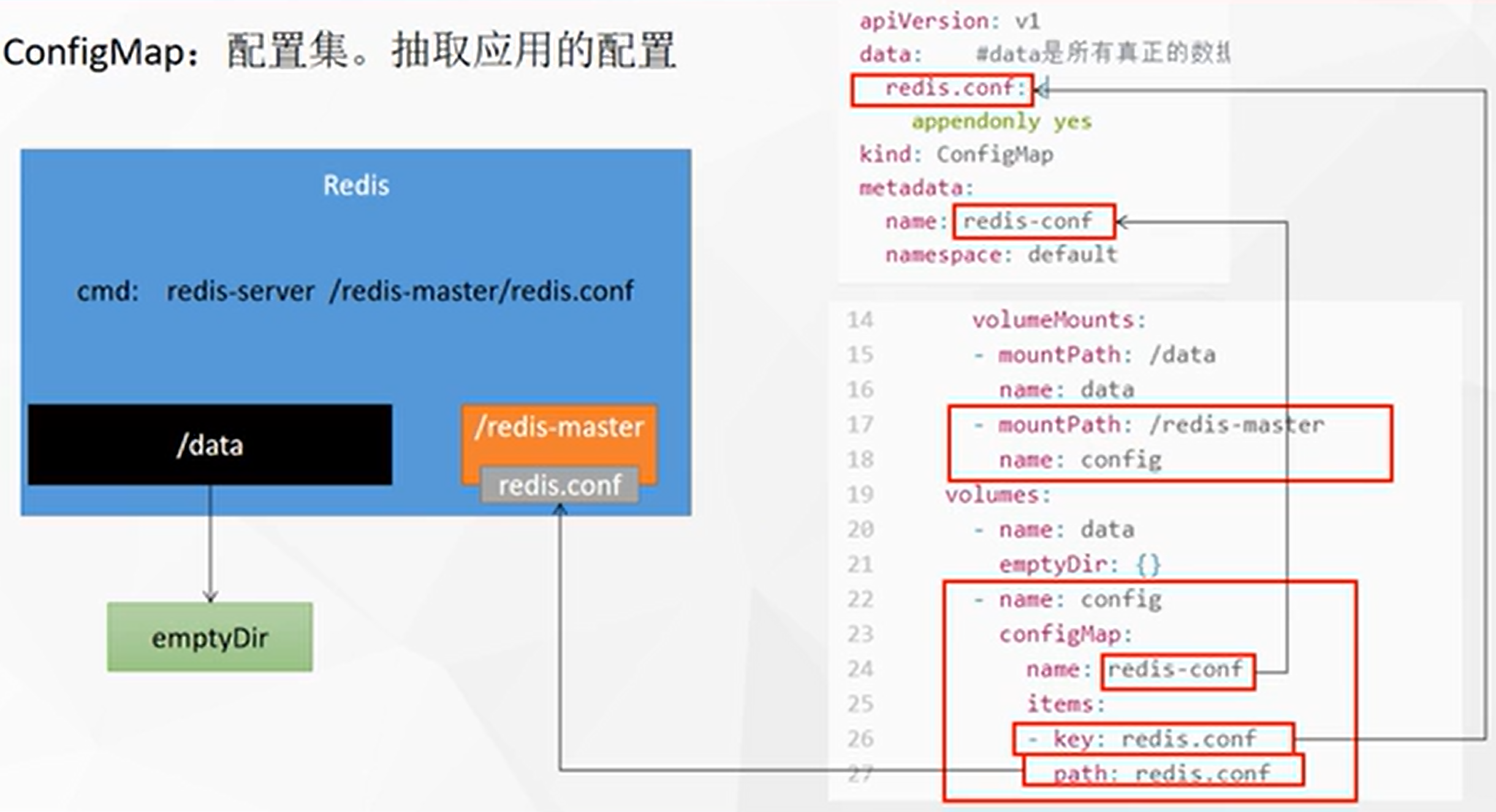
ConfigMap
配置集 抽取应用配置,并且可以自动更新,以Redis为例:
-
从本地文件建立配置集:
kubectl create cm redis-conf --from-file=redis.conf,创建完了这个文件就可以删了 -
查看配置集:
kubectl get cm -
查看配置集yaml:
kubectl get cm redis-conf -oyamlapiVersion: v1 # data里面是所有真正的数据,key:默认是文件名,value:配置文件的内容,|:表示接下来是大文本 data: redis.conf: | appendonly yes kind: ConfigMap metadata: name: redis-conf namespace: default -
创建Pod
apiVersion: v1 kind: Pod metadata: name: redis spec: containers: - name: redis image: 10.4.32.48:5000/redis:7.4 command: - redis-server - "/redis-master/redis.conf" # 指的是redis容器内部的位置 ports: - containerPort: 6379 volumeMounts: - mountPath: /data name: data - mountPath: /redis-master name: config volumes: - name: data emptyDir: {} - name: config configMap: name: redis-conf items: - key: redis.conf path: redis.conf![在这里插入图片描述]()
-
修改redis配置文件,会自动同步:
kubectl edit cm redis-conf,等一会儿大概一分钟,就同步了,redis容器中的配置文件就发生了改变 ⚠️但是不会自动重启redis的pod!我们的Pod部署的中间件自己本身没有热更新能力
-
检查redis配置
kubectl exec -it redis -- redis-cli 127.0.0.1:6379> CONFIG GET appendonly 127.0.0.1:6379> CONFIG GET requirepass
-
-
Secret
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
kubectl create secret docker-registry leifengyang-docker \ --docker-username=leifengyang \ --docker-password=Lfy123456 \ --docker-email=534096094@qq.com ##命令格式 kubectl create secret docker-registry regcred \ --docker-server=<你的镜像仓库服务器> \ --docker-username=<你的用户名> \ --docker-password=<你的密码> \ --docker-email=<你的邮箱地址>apiVersion: v1 kind: Pod metadata: name: private-nginx spec: containers: - name: private-nginx image: leifengyang/guignginx:v1.0 imagePullSecrets: - name: leifengyang-docker
-
4. KubeSphere平台安装
Kubernetes上安装KubeSphere
-
安装docker 😄复习一遍吧
sudo yum remove docker* sudo yum install -y yum-utils #配置docker的yum地址 sudo yum-config-manager \ --add-repo \ http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo #安装指定版本 sudo yum install -y docker-ce-20.10.7 docker-ce-cli-20.10.7 containerd.io-1.4.6 # 启动&开机启动docker systemctl enable docker --now # docker加速配置 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://82m9ar63.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } EOF sudo systemctl daemon-reload sudo systemctl restart docker -
安装k8s
-
基本环境
#设置每个机器自己的hostname hostnamectl set-hostname xxx # 将 SELinux 设置为 permissive 模式(相当于将其禁用) sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config #关闭swap swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab #允许 iptables 检查桥接流量 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sudo sysctl --system -
安装kubelet、kubeadm、kubectl
#配置k8s的yum源地址 cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF #安装 kubelet,kubeadm,kubectl sudo yum install -y kubelet-1.20.9 kubeadm-1.20.9 kubectl-1.20.9 #启动kubelet sudo systemctl enable --now kubelet #所有机器配置master域名 echo "172.31.0.4 k8s-master" >> /etc/hosts -
初始化master节点
初始化
kubeadm init \ --apiserver-advertise-address=172.31.0.4 \ --control-plane-endpoint=k8s-master \ --image-repository registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images \ --kubernetes-version v1.20.9 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=192.168.0.0/16记录关键信息
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join k8s-master:6443 --token 3vckmv.lvrl05xpyftbs177 \ --discovery-token-ca-cert-hash sha256:1dc274fed24778f5c284229d9fcba44a5df11efba018f9664cf5e8ff77907240 \ --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join k8s-master:6443 --token 3vckmv.lvrl05xpyftbs177 \ --discovery-token-ca-cert-hash sha256:1dc274fed24778f5c284229d9fcba44a5df11efba018f9664cf5e8ff77907240安装Calico网络插件
curl https://docs.projectcalico.org/manifests/calico.yaml -O kubectl apply -f calico.yaml -
加入worker节点
kubeadm join k8s-master:6443 --token 3vckmv.lvrl05xpyftbs177 \ --discovery-token-ca-cert-hash sha256:1dc274fed24778f5c284229d9fcba44a5df11efba018f9664cf5e8ff77907240
-
-
安装KubeSphere前置环境
-
nfs文件系统
安装nfs-server
# 在每个机器。 yum install -y nfs-utils # 在master 执行以下命令 echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports # 执行以下命令,启动 nfs 服务;创建共享目录 mkdir -p /nfs/data # 在master执行 systemctl enable rpcbind systemctl enable nfs-server systemctl start rpcbind systemctl start nfs-server # 使配置生效 exportfs -r #检查配置是否生效 exportfs配置nfs-client(选做)
showmount -e 172.31.0.4 mkdir -p /nfs/data mount -t nfs 172.31.0.4:/nfs/data /nfs/data⭐ 配置默认存储 kubesphere要求k8s集群中有默认存储类型
相较于静态供应的pc和pvc,默认存储提供动态供应能力
- 注意修改两处ip地址为自己的master地址
- 其中涉及到镜像
nfs-subdir-external-provisioner:v4.0.2需要处理
## 创建了一个存储类 apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs-storage annotations: storageclass.kubernetes.io/is-default-class: "true" provisioner: k8s-sigs.io/nfs-subdir-external-provisioner parameters: archiveOnDelete: "true" ## 删除pv的时候,pv的内容是否要备份 --- apiVersion: apps/v1 kind: Deployment metadata: name: nfs-client-provisioner labels: app: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default spec: replicas: 1 strategy: type: Recreate selector: matchLabels: app: nfs-client-provisioner template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner # 修改成自己的镜像 image: 10.4.32.48:5000/nfs-subdir-external-provisioner:v4.0.2 # resources: # limits: # cpu: 10m # requests: # cpu: 10m volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: k8s-sigs.io/nfs-subdir-external-provisioner - name: NFS_SERVER value: 10.4.32.48 ## 指定自己nfs服务器地址 - name: NFS_PATH value: /nfs/data ## nfs服务器共享的目录 volumes: - name: nfs-client-root nfs: server: 10.4.32.48 path: /nfs/data --- apiVersion: v1 kind: ServiceAccount metadata: name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nfs-client-provisioner-runner rules: - apiGroups: [""] resources: ["nodes"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: run-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default roleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default subjects: - kind: ServiceAccount name: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: default roleRef: kind: Role name: leader-locking-nfs-client-provisioner apiGroup: rbac.authorization.k8s.io确认配置是否生效:
kubectl get sc,Storage Class[root@k8s-master yamls]# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE nfs-storage (default) k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 17s测试效果:
-
先写一个PVC的yaml,在这里没有指定storageClassName,所以使用默认的存储类
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubesphere-test-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 200Mi -
看看pv有没有动态生成:
kubectl get pv
-
metrics-server
集群指标监控组件
- 注意镜像的问题:
metrics-server:v0.4.3
apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server rbac.authorization.k8s.io/aggregate-to-admin: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-view: "true" name: system:aggregated-metrics-reader rules: - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server name: system:metrics-server rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats - namespaces - configmaps verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: ports: - name: https port: 443 protocol: TCP targetPort: https selector: k8s-app: metrics-server --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --kubelet-insecure-tls - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port image: 10.4.32.48:5000/metrics-server:v0.4.3 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 4443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS periodSeconds: 10 securityContext: readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100 - 注意镜像的问题:
-
-
⭐安装KubeSphere
只能搜到3.3版本的文档了,学习的时候还是3.1.1:https://kubesphere.io/zh/docs/v3.3/quick-start/minimal-kubesphere-on-k8s/
-
下载核心文件
❓ 这个时候你要问了,有哪些镜像要搞啊,很多!超级多!
我统计了一下,48个,没错,都是我一个一个手敲下载的:
- alpine:3.14
- csiplugin/snapshot-controller:v3.0.3
- docker:19.03
- istio/pilot:1.6.10
- istio/proxyv2:1.6.10
- jaegertracing/jaeger-agent:1.17
- jaegertracing/jaeger-collector:1.17
- jaegertracing/jaeger-operator:1.17.1
- jaegertracing/jaeger-query:1.17
- jimmidyson/configmap-reload:v0.3.0
- kubeedge/cloudcore:v1.6.2
- kubespheredev/openpitrix-jobs:v3.1.1
- kubesphere/edge-watcher-agent:v0.1.0
- kubesphere/edge-watcher:v0.1.0
- kubesphere/elasticsearch-curator:v5.7.6
- kubesphere/elasticsearch-oss-6.7.0:1
- kubesphere/fluent-bit:v1.6.9
- kubesphere/fluentbit-operator:v0.5.0
- kubesphere/kiali-operator:v1.26.1
- kubesphere/kiali:v1.26.1
- kubesphere/ks-apiserver:v3.1.1
- kubesphere/ks-console:v3.1.1
- kubesphere/ks-controller-manager:v3.1.1
- kubesphere/ks-installer:v3.1.1
- kubesphere/ks-jenkins:2.249.1
- kubesphere/kube-auditing-operator:v0.1.2
- kubesphere/kube-auditing-webhook:v0.1.2
- kubesphere/kube-events-exporter:v0.1.0
- kubesphere/kube-events-operator:v0.1.0
- kubesphere/kube-events-ruler:v0.2.0
- kubesphere/kube-rbac-proxy:v0.8.0
- kubesphere/kube-state-metrics:v1.9.7
- kubesphere/kubectl:v1.20.0
- kubesphere/log-sidecar-injector:1.1
- kubesphere/notification-manager-operator:v1.0.0
- kubesphere/notification-manager:v1.0.0
- kubesphere/prometheus-config-reloader:v0.42.1
- kubesphere/prometheus-operator:v0.42.1
- kubesphere/s2ioperator:v3.1.0
- minio/mc-RELEASE.2019-08-07T23-14:43Z
- minio/minio-RELEASE.2019-08-07T01-59:21Z
- mirrorgooglecontainers/defaultbackend-amd64:1.4
- osixia/openldap:1.3.0
- prom/alertmanager:v0.21.0
- prom/node-exporter:v0.18.1
- prom/prometheus:v2.26.0
- redis-5.0.12:alpine
- thanosio/thanos:v0.18.0
-
安装器:
https://github.com/kubesphere/ks-installer/releases/download/v3.1.1/kubesphere-installer.yaml- 需要注意的是镜像:
kubesphere/ks-installer:v3.1.1 - 完事儿了
kubectl apply -f kubesphere-installer.yaml
--- apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: clusterconfigurations.installer.kubesphere.io spec: group: installer.kubesphere.io versions: - name: v1alpha1 served: true storage: true scope: Namespaced names: plural: clusterconfigurations singular: clusterconfiguration kind: ClusterConfiguration shortNames: - cc --- apiVersion: v1 kind: Namespace metadata: name: kubesphere-system --- apiVersion: v1 kind: ServiceAccount metadata: name: ks-installer namespace: kubesphere-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: ks-installer rules: - apiGroups: - "" resources: - '*' verbs: - '*' - apiGroups: - apps resources: - '*' verbs: - '*' - apiGroups: - extensions resources: - '*' verbs: - '*' - apiGroups: - batch resources: - '*' verbs: - '*' - apiGroups: - rbac.authorization.k8s.io resources: - '*' verbs: - '*' - apiGroups: - apiregistration.k8s.io resources: - '*' verbs: - '*' - apiGroups: - apiextensions.k8s.io resources: - '*' verbs: - '*' - apiGroups: - tenant.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - certificates.k8s.io resources: - '*' verbs: - '*' - apiGroups: - devops.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - monitoring.coreos.com resources: - '*' verbs: - '*' - apiGroups: - logging.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - jaegertracing.io resources: - '*' verbs: - '*' - apiGroups: - storage.k8s.io resources: - '*' verbs: - '*' - apiGroups: - admissionregistration.k8s.io resources: - '*' verbs: - '*' - apiGroups: - policy resources: - '*' verbs: - '*' - apiGroups: - autoscaling resources: - '*' verbs: - '*' - apiGroups: - networking.istio.io resources: - '*' verbs: - '*' - apiGroups: - config.istio.io resources: - '*' verbs: - '*' - apiGroups: - iam.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - notification.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - auditing.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - events.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - core.kubefed.io resources: - '*' verbs: - '*' - apiGroups: - installer.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - storage.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - security.istio.io resources: - '*' verbs: - '*' - apiGroups: - monitoring.kiali.io resources: - '*' verbs: - '*' - apiGroups: - kiali.io resources: - '*' verbs: - '*' - apiGroups: - networking.k8s.io resources: - '*' verbs: - '*' - apiGroups: - kubeedge.kubesphere.io resources: - '*' verbs: - '*' - apiGroups: - types.kubefed.io resources: - '*' verbs: - '*' --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: ks-installer subjects: - kind: ServiceAccount name: ks-installer namespace: kubesphere-system roleRef: kind: ClusterRole name: ks-installer apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: Deployment metadata: name: ks-installer namespace: kubesphere-system labels: app: ks-install spec: replicas: 1 selector: matchLabels: app: ks-install template: metadata: labels: app: ks-install spec: serviceAccountName: ks-installer containers: - name: installer image: 10.4.32.48:5000/kubesphere/ks-installer:v3.1.1 imagePullPolicy: "Always" resources: limits: cpu: "1" memory: 1Gi requests: cpu: 20m memory: 100Mi volumeMounts: - mountPath: /etc/localtime name: host-time volumes: - hostPath: path: /etc/localtime type: "" name: host-time - 需要注意的是镜像:
-
集群配置:
https://github.com/kubesphere/ks-installer/releases/download/v3.1.1/cluster-configuration.yaml-
修改集群配置,见下面【中的内容】
-
注意修改下面的 local_registry 为自己的
⚠️ 出现了redis:5.0.12-alpine这个镜像非要前面加个library
✔️ 根据pod的报错信息直接搞就行:
docker tag redis:5.0.12-alpine 10.4.32.48:5000/library/redis:5.0.12-alpine -
完事儿了
kubectl apply -f cluster-configuration.yaml
--- apiVersion: installer.kubesphere.io/v1alpha1 kind: ClusterConfiguration metadata: name: ks-installer namespace: kubesphere-system labels: version: v3.1.1 # 【我们需要修改的内容】 spec: persistence: storageClass: "" # If there is no default StorageClass in your cluster, you need to specify an existing StorageClass here. authentication: jwtSecret: "" # Keep the jwtSecret consistent with the Host Cluster. Retrieve the jwtSecret by executing "kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret" on the Host Cluster. # 【配置本地镜像地址】 local_registry: "10.4.32.48:5000" # Add your private registry address if it is needed. etcd: # 【开启】 monitoring: true # Enable or disable etcd monitoring dashboard installation. You have to create a Secret for etcd before you enable it. # 【写master节点的IP】 endpointIps: 10.4.32.48 # etcd cluster EndpointIps. It can be a bunch of IPs here. port: 2379 # etcd port. tlsEnable: true common: redis: # 【开启】 enabled: true openldap: # 【开启】 enabled: true minioVolumeSize: 20Gi # Minio PVC size. openldapVolumeSize: 2Gi # openldap PVC size. redisVolumSize: 2Gi # Redis PVC size. monitoring: # type: external # Whether to specify the external prometheus stack, and need to modify the endpoint at the next line. endpoint: http://prometheus-operated.kubesphere-monitoring-system.svc:9090 # Prometheus endpoint to get metrics data. es: # Storage backend for logging, events and auditing. # elasticsearchMasterReplicas: 1 # The total number of master nodes. Even numbers are not allowed. # elasticsearchDataReplicas: 1 # The total number of data nodes. elasticsearchMasterVolumeSize: 4Gi # The volume size of Elasticsearch master nodes. elasticsearchDataVolumeSize: 20Gi # The volume size of Elasticsearch data nodes. logMaxAge: 7 # Log retention time in built-in Elasticsearch. It is 7 days by default. elkPrefix: logstash # The string making up index names. The index name will be formatted as ks-<elk_prefix>-log. basicAuth: enabled: false username: "" password: "" externalElasticsearchUrl: "" externalElasticsearchPort: "" console: enableMultiLogin: true # Enable or disable simultaneous logins. It allows different users to log in with the same account at the same time. port: 30880 alerting: # (CPU: 0.1 Core, Memory: 100 MiB) It enables users to customize alerting policies to send messages to receivers in time with different time intervals and alerting levels to choose from. # 【打开告警功能】 enabled: true # Enable or disable the KubeSphere Alerting System. # thanosruler: # replicas: 1 # resources: {} auditing: # Provide a security-relevant chronological set of records,recording the sequence of activities happening on the platform, initiated by different tenants. # 【打开审计功能】 enabled: true # Enable or disable the KubeSphere Auditing Log System. devops: # (CPU: 0.47 Core, Memory: 8.6 G) Provide an out-of-the-box CI/CD system based on Jenkins, and automated workflow tools including Source-to-Image & Binary-to-Image. # 【重点体验devops,打开】 enabled: true # Enable or disable the KubeSphere DevOps System. jenkinsMemoryLim: 2Gi # Jenkins memory limit. jenkinsMemoryReq: 1500Mi # Jenkins memory request. jenkinsVolumeSize: 8Gi # Jenkins volume size. jenkinsJavaOpts_Xms: 512m # The following three fields are JVM parameters. jenkinsJavaOpts_Xmx: 512m jenkinsJavaOpts_MaxRAM: 2g events: # Provide a graphical web console for Kubernetes Events exporting, filtering and alerting in multi-tenant Kubernetes clusters. # 【打开事件功能】 enabled: true # Enable or disable the KubeSphere Events System. ruler: enabled: true replicas: 2 logging: # (CPU: 57 m, Memory: 2.76 G) Flexible logging functions are provided for log query, collection and management in a unified console. Additional log collectors can be added, such as Elasticsearch, Kafka and Fluentd. # 【打开日志功能】 enabled: true # Enable or disable the KubeSphere Logging System. logsidecar: enabled: true replicas: 2 metrics_server: # (CPU: 56 m, Memory: 44.35 MiB) It enables HPA (Horizontal Pod Autoscaler). # 【不用打开,因为我们前置已经装好镜像了】 enabled: false # Enable or disable metrics-server. monitoring: storageClass: "" # If there is an independent StorageClass you need for Prometheus, you can specify it here. The default StorageClass is used by default. # prometheusReplicas: 1 # Prometheus replicas are responsible for monitoring different segments of data source and providing high availability. prometheusMemoryRequest: 400Mi # Prometheus request memory. prometheusVolumeSize: 20Gi # Prometheus PVC size. # alertmanagerReplicas: 1 # AlertManager Replicas. multicluster: clusterRole: none # host | member | none # You can install a solo cluster, or specify it as the Host or Member Cluster. network: networkpolicy: # Network policies allow network isolation within the same cluster, which means firewalls can be set up between certain instances (Pods). # Make sure that the CNI network plugin used by the cluster supports NetworkPolicy. There are a number of CNI network plugins that support NetworkPolicy, including Calico, Cilium, Kube-router, Romana and Weave Net. # 【打开网络策略】 enabled: true # Enable or disable network policies. ippool: # Use Pod IP Pools to manage the Pod network address space. Pods to be created can be assigned IP addresses from a Pod IP Pool. # 【指定 calico】 type: calico # Specify "calico" for this field if Calico is used as your CNI plugin. "none" means that Pod IP Pools are disabled. topology: # Use Service Topology to view Service-to-Service communication based on Weave Scope. type: none # Specify "weave-scope" for this field to enable Service Topology. "none" means that Service Topology is disabled. openpitrix: # An App Store that is accessible to all platform tenants. You can use it to manage apps across their entire lifecycle. store: # 【打开应用商店】 enabled: true # Enable or disable the KubeSphere App Store. servicemesh: # (0.3 Core, 300 MiB) Provide fine-grained traffic management, observability and tracing, and visualized traffic topology. # 【打开微服务治理功能】 enabled: true # Base component (pilot). Enable or disable KubeSphere Service Mesh (Istio-based). kubeedge: # Add edge nodes to your cluster and deploy workloads on edge nodes. # 【打开边缘计算】 enabled: true # Enable or disable KubeEdge. cloudCore: nodeSelector: {"node-role.kubernetes.io/worker": ""} tolerations: [] cloudhubPort: "10000" cloudhubQuicPort: "10001" cloudhubHttpsPort: "10002" cloudstreamPort: "10003" tunnelPort: "10004" cloudHub: advertiseAddress: # At least a public IP address or an IP address which can be accessed by edge nodes must be provided. - "" # Note that once KubeEdge is enabled, CloudCore will malfunction if the address is not provided. nodeLimit: "100" service: cloudhubNodePort: "30000" cloudhubQuicNodePort: "30001" cloudhubHttpsNodePort: "30002" cloudstreamNodePort: "30003" tunnelNodePort: "30004" edgeWatcher: nodeSelector: {"node-role.kubernetes.io/worker": ""} tolerations: [] edgeWatcherAgent: nodeSelector: {"node-role.kubernetes.io/worker": ""} tolerations: [] -
-
查看安装进度:
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f⚠️ 报错找不到 kube-etcd-client-certs 的secret
MountVolume.SetUp failed for volume "secret-kube-etcd-client-certs" : secret "kube-etcd-client-certs" not found💡 解决:其实在 ks-install 的官网就能看到解决方案:
![在这里插入图片描述]()
告诉你,根据etcd的配置情况选择不同的解决方案,那我们就去
/etc/kubernetes/pki/etcd/目录下看上一看,确实有如上文件,所以我们选择第一种:kubectl -n kubesphere-monitoring-system create secret generic kube-etcd-client-certs \ --from-file=etcd-client-ca.crt=/etc/kubernetes/pki/etcd/ca.crt \ --from-file=etcd-client.crt=/etc/kubernetes/pki/etcd/healthcheck-client.crt \ --from-file=etcd-client.key=/etc/kubernetes/pki/etcd/healthcheck-client.key⚠️ 三个deploy报错 ks-apiserver、ks-console、ks-controller-manager,进去一看,报错内容是:
... is forbidden: error looking up service account kubesphere-system/kubesphere: serviceaccount "kubesphere" not found简单来说,就是叫kubesphere的serviceaccount资源没找到,就很离谱,可能是因为之前安装的时候各种镜像没搞下来,然后卸载也没卸载干净导致的,全网也没看到解决方案,除了一个issue,也根本没人回复,我一时间觉得kubesphere社区这么逊吗?
- 为了解决这个问题,首先要解决的是怎么删干净kubeshpere:
- 获取3.1版本的卸载脚本:https://github.com/kubesphere/ks-installer/blob/release-3.1/scripts/kubesphere-delete.sh
chmod +x kubesphere-delete.sh,卸载的。。。很慢很慢 😓
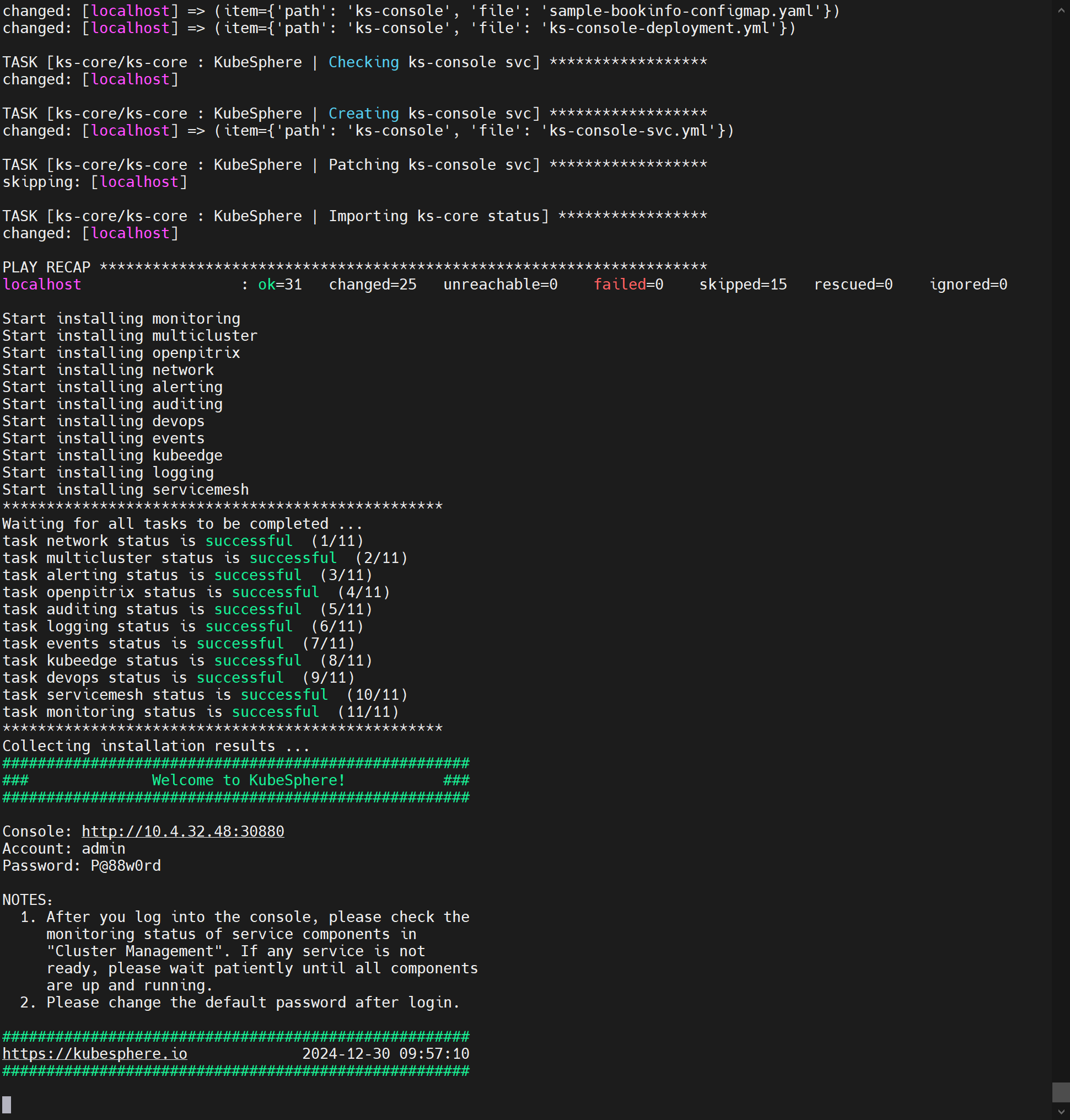
- 太慢了,我特么受不了直接重装了k8s,反正离线的,东西是现成的,反正好使了,就很奇怪,真的就好使了,之前都是11个task确认完了之后,
collecting installation results后面就跟着失败了,我严重怀疑是中间各种没有镜像,可能导致了一些问题,等我把所有镜像都搞到registry之后,重来一波就好使了!所有pod都running了!😅
成功:🎉
![在这里插入图片描述]()
:happy: 所有pod running真的太开心啦!
![在这里插入图片描述]()
- 为了解决这个问题,首先要解决的是怎么删干净kubeshpere:
-
Linux单节点部署KubeSphere
-
开通服务器:4c8g;centos7.9;防火墙放行 30000~32767;指定hostname
hostnamectl set-hostname node1 -
安装
-
准备KubeKey
export KKZONE=cn curl -sfL https://get-kk.kubesphere.io | VERSION=v1.1.1 sh - chmod +x kk -
使用KubeKey引导安装集群
#可能需要下面命令 yum install -y conntrack ./kk create cluster --with-kubernetes v1.20.4 --with-kubesphere v3.1.1
-
-
安装后开启功能:平台管理-自定义资源CRD-ClusterConfiguration 中修改配置(仅适用于单节点集群),fasle改true就行,然后更新,等会儿就会自动开始安装,启动pod等等
Linux多节点部署KubeSphere
-
准备多太服务器:4c8g (master)、8c16g * 2(worker)、centos7.9、内网互通、每个机器有自己域名、防火墙开放30000~32767端口
-
使用KubeKey创建集群
-
下载KubeKey
export KKZONE=cn curl -sfL https://get-kk.kubesphere.io | VERSION=v1.1.1 sh - chmod +x kk -
创建集群配置文件
./kk create config --with-kubernetes v1.20.4 --with-kubesphere v3.1.1修改配置文件:
- 修改hosts,name-机器域名,address-内网ip,inernalAddress-内网ip,user-机器账号,password-机器密码
- 配置etcd装到哪儿(master),master装哪儿(master),worker装哪儿(node1,node2)
-
使用指定的配置文件创建集群
./kk create cluster -f config-sample.yaml -
查看进度
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
-
5. KubeSphere实战
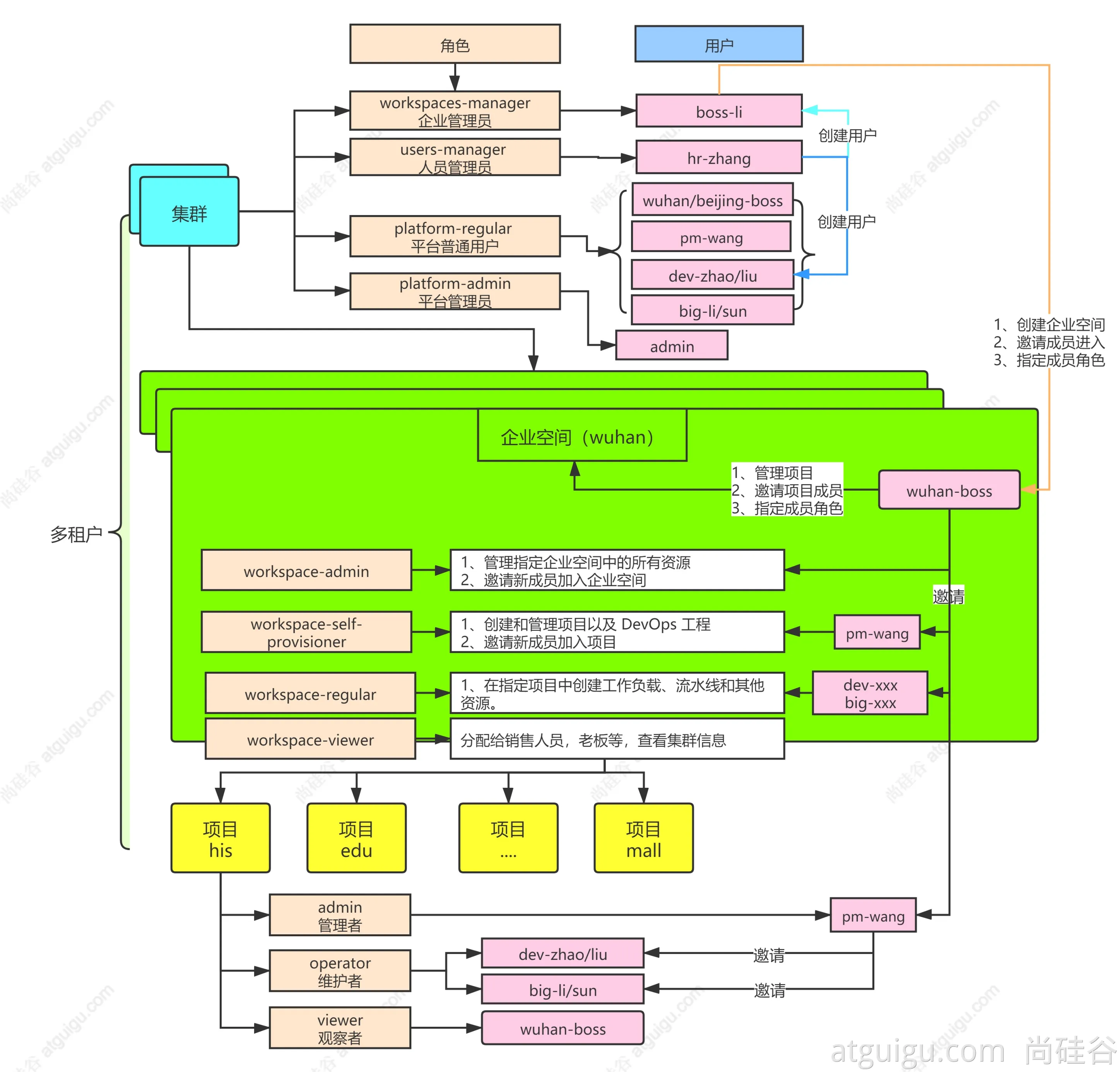
多租户系统实战
中间件部署实战
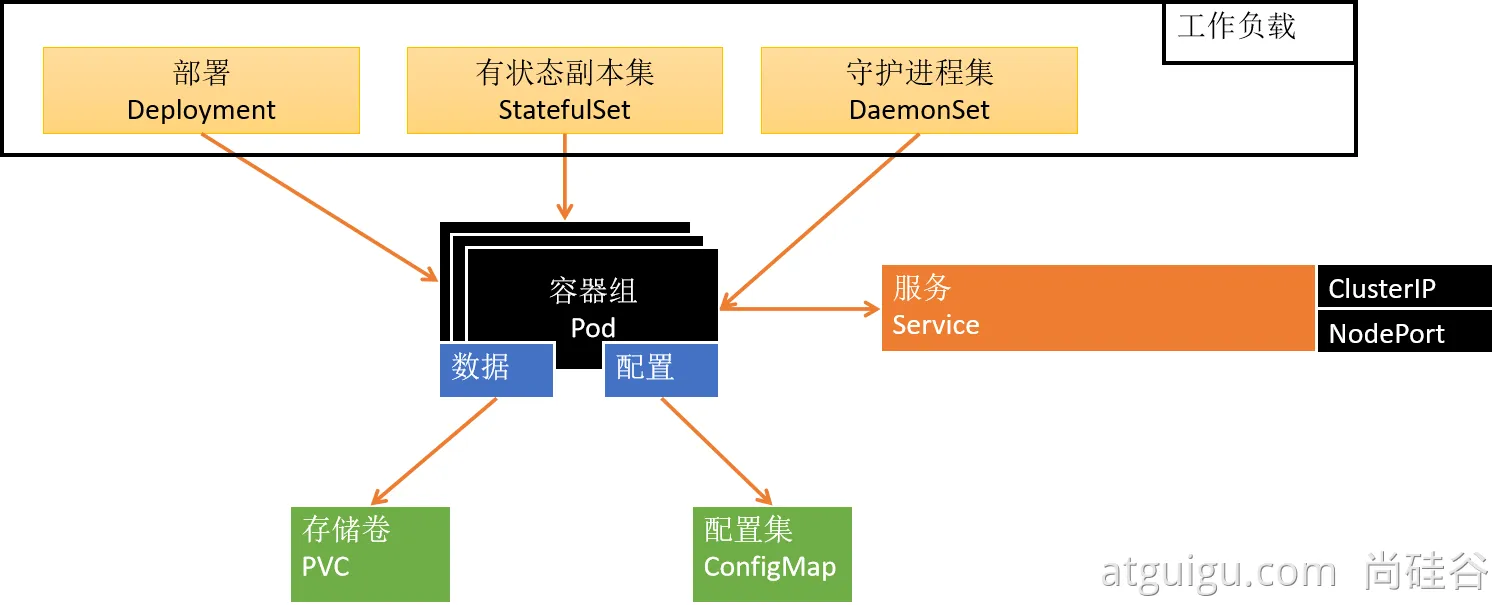
应用部署需要关注的信息【应用部署三要素】
- 应用的部署方式(有状态、无状态、守护进程集)
- 应用的数据挂载(数据,配置文件)
- 应用的可访问性
-
部署MySQL
-
MySQL容器启动
docker run -p 3306:3306 --name mysql-01 \ -v /mydata/mysql/log:/var/log/mysql \ -v /mydata/mysql/data:/var/lib/mysql \ -v /mydata/mysql/conf:/etc/mysql/conf.d \ -e MYSQL_ROOT_PASSWORD=密码就不给你看了~ \ --restart=always \ -d mysql:5.7 -
MySQL配置示例
[client] default-character-set=utf8mb4 [mysql] default-character-set=utf8mb4 [mysqld] lower_case_table_names=1 init_connect='SET collation_connection = utf8mb4_unicode_ci' init_connect='SET NAMES utf8mb4' character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci skip-character-set-client-handshake skip-name-resolve -
MySQL部署分析
![在这里插入图片描述]()
💡 kubesphere配置注意
- 访问模式:
- 有状态应用:单节点读写
- 无状态应用:多节点读写
❓ MySQL配置文件修改后会直接同步到pod中,但是mysql容器没有热更新能力,不能感知配置文件改变自动重启pod。只能点一下重新部署。
![在这里插入图片描述]()
-
集群内部,直接通过应用的 【服务名.项目名】 直接访问 ,比如:
mysql -uroot -hhis-mysql-3zw7.his -p这里的
-h是 host 的意思,集群内部那个node都可以访问 -
删掉创建有状态副本集 自带的服务,自己建 自定义工作负载
注意删除的时候不要删除有状态副本集(StatefulSet),而是只删当前的服务(这个服务是自动创建的,只能集群内访问,不喜欢后缀名可以删掉重新自己搞)
两个服务分别是对内和对外,对外测试的时候用,正式上线的时候,直接一删,就能保护数据库无法被外部访问
![在这里插入图片描述]()
- 访问模式:
-
-
部署Redis
-
redis容器启动
#创建配置文件 ## 1、准备redis配置文件内容 mkdir -p /mydata/redis/conf && vim /mydata/redis/conf/redis.conf ##配置示例 appendonly yes port 6379 bind 0.0.0.0 #docker启动redis docker run -d -p 6379:6379 --restart=always \ -v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf \ -v /mydata/redis-01/data:/data \ --name redis-01 redis:7.4 \ redis-server /etc/redis/redis.conf -
redis部署分析,注意,这里的redis.conf在 配置中心-配置 里面做了键值对,key就是文件名,value就是配置本身
![在这里插入图片描述]()
即使调整副本数量,删了再新建,数据依然还在
-
可以不用指定卷,只是创建的时候建的。
有状态应用在创建的时候都应自动挂载,而不是提前创建pv
![在这里插入图片描述]()
![在这里插入图片描述]()
-
-
部署ElasticSearch
-
es容器启动
# 创建数据目录 mkdir -p /mydata/es-01 && chmod 777 -R /mydata/es-01 && chomd 777 -R /mydata/es-01/data # 容器启动 docker run --restart=always -d -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms512m -Xmx512m" \ -v es-config:/usr/share/elasticsearch/config \ -v /mydata/es-01/data:/usr/share/elasticsearch/data \ --name es-01 \ 10.4.32.48:5000/elasticsearch:7.13.4💡 注意:这里的
-v es-config:/usr/share/elasticsearch/config具名卷挂载跟之前的文件夹挂载不同,如果直接挂载空文件夹,会导致容器内部config文件夹中也没有内容。如果用具名卷挂载,会先把config中的内容复制一份到卷中,再进行挂载。
-
es部署分析
![在这里插入图片描述]()
这里我们关注两个文件,且以子路径的形式挂载:
![在这里插入图片描述]()
-
elasticsearch.ymlcluster.name: "docker-cluster" network.host: 0.0.0.0 -
jvm.options################################################################ ## ## JVM configuration ## ################################################################ ## ## WARNING: DO NOT EDIT THIS FILE. If you want to override the ## JVM options in this file, or set any additional options, you ## should create one or more files in the jvm.options.d ## directory containing your adjustments. ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/current/jvm-options.html ## for more information. ## ################################################################ ################################################################ ## IMPORTANT: JVM heap size ################################################################ ## ## The heap size is automatically configured by Elasticsearch ## based on the available memory in your system and the roles ## each node is configured to fulfill. If specifying heap is ## required, it should be done through a file in jvm.options.d, ## and the min and max should be set to the same value. For ## example, to set the heap to 4 GB, create a new file in the ## jvm.options.d directory containing these lines: ## ## -Xms4g ## -Xmx4g ## ## See https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html ## for more information ## ################################################################ ################################################################ ## Expert settings ################################################################ ## ## All settings below here are considered expert settings. Do ## not adjust them unless you understand what you are doing. Do ## not edit them in this file; instead, create a new file in the ## jvm.options.d directory containing your adjustments. ## ################################################################ ## GC configuration 8-13:-XX:+UseConcMarkSweepGC 8-13:-XX:CMSInitiatingOccupancyFraction=75 8-13:-XX:+UseCMSInitiatingOccupancyOnly ## G1GC Configuration # NOTE: G1 GC is only supported on JDK version 10 or later # to use G1GC, uncomment the next two lines and update the version on the # following three lines to your version of the JDK # 10-13:-XX:-UseConcMarkSweepGC # 10-13:-XX:-UseCMSInitiatingOccupancyOnly 14-:-XX:+UseG1GC ## JVM temporary directory -Djava.io.tmpdir=${ES_TMPDIR} ## heap dumps # generate a heap dump when an allocation from the Java heap fails; heap dumps # are created in the working directory of the JVM unless an alternative path is # specified -XX:+HeapDumpOnOutOfMemoryError # specify an alternative path for heap dumps; ensure the directory exists and # has sufficient space -XX:HeapDumpPath=data # specify an alternative path for JVM fatal error logs -XX:ErrorFile=logs/hs_err_pid%p.log ## JDK 8 GC logging 8:-XX:+PrintGCDetails 8:-XX:+PrintGCDateStamps 8:-XX:+PrintTenuringDistribution 8:-XX:+PrintGCApplicationStoppedTime 8:-Xloggc:logs/gc.log 8:-XX:+UseGCLogFileRotation 8:-XX:NumberOfGCLogFiles=32 8:-XX:GCLogFileSize=64m # JDK 9+ GC logging 9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
-
-
在es的pod中查看es是否启动成功
![在这里插入图片描述]()
类似的创建在集群外访问的NodePort服务,同样可以通过IP访问:
![在这里插入图片描述]()
-
-
应用商店
怎么把上述部署流程固化,实现一键部署呢。点了就能直接部署了,不过这里果然还是有镜像的问题,得改资源配置为自己的registry
-
应用仓库
-
helm:https://helm.sh/
-
helm的仓库叫charts:https://artifacthub.io/
跟
hub.docker中搜索镜像下载很像,不过这里的是k8s的核心配置yaml -
charts(artifacthub)中发布比较多charts的公司叫 bitnami
![在这里插入图片描述]()
-
算了同步,就不弄了,我服务器网都没有,我同步个毛啊
![在这里插入图片描述]()
-
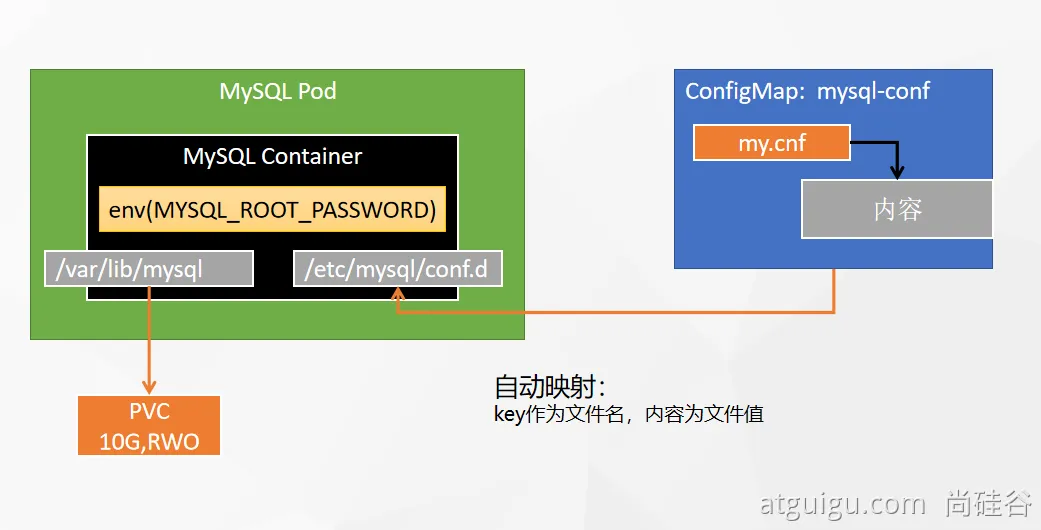
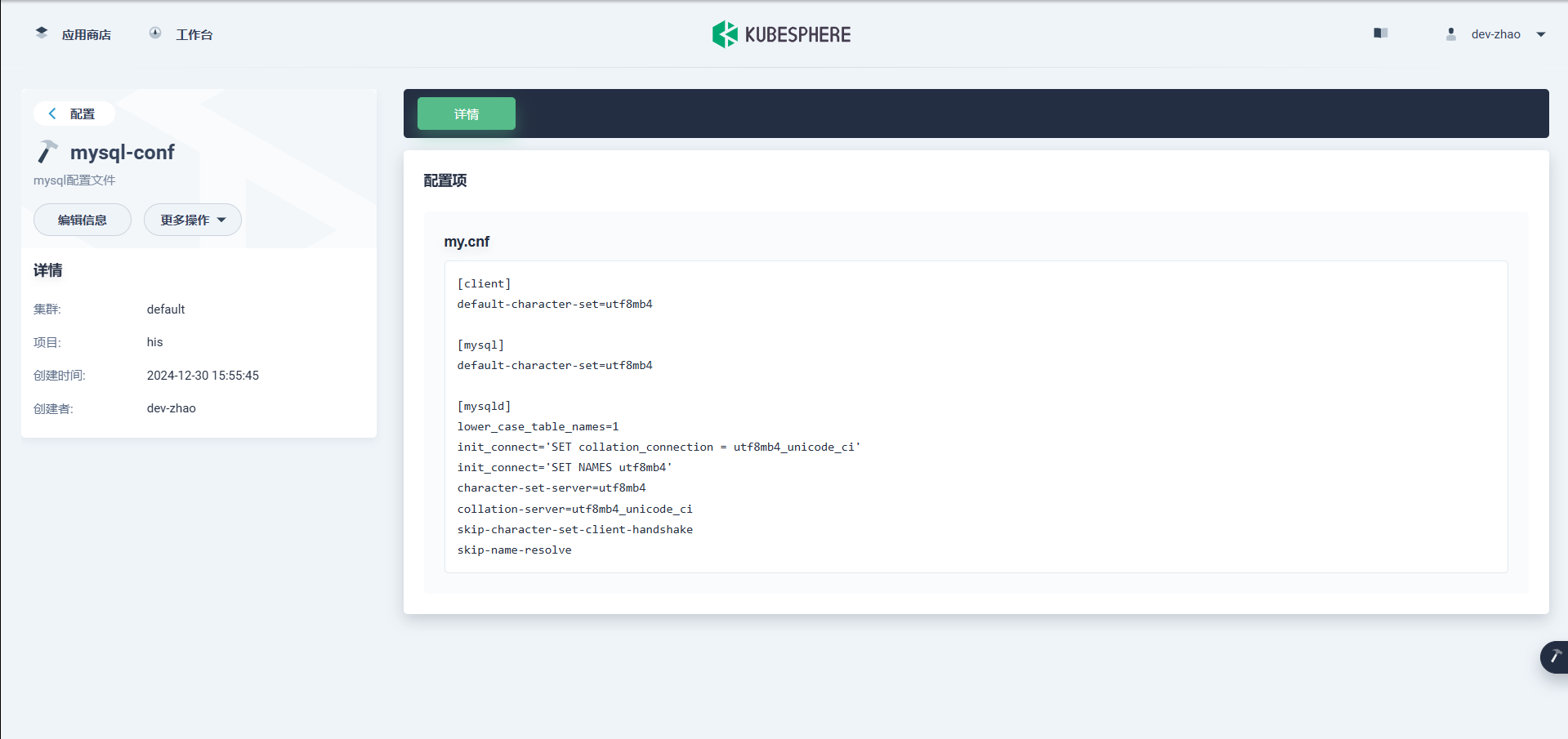
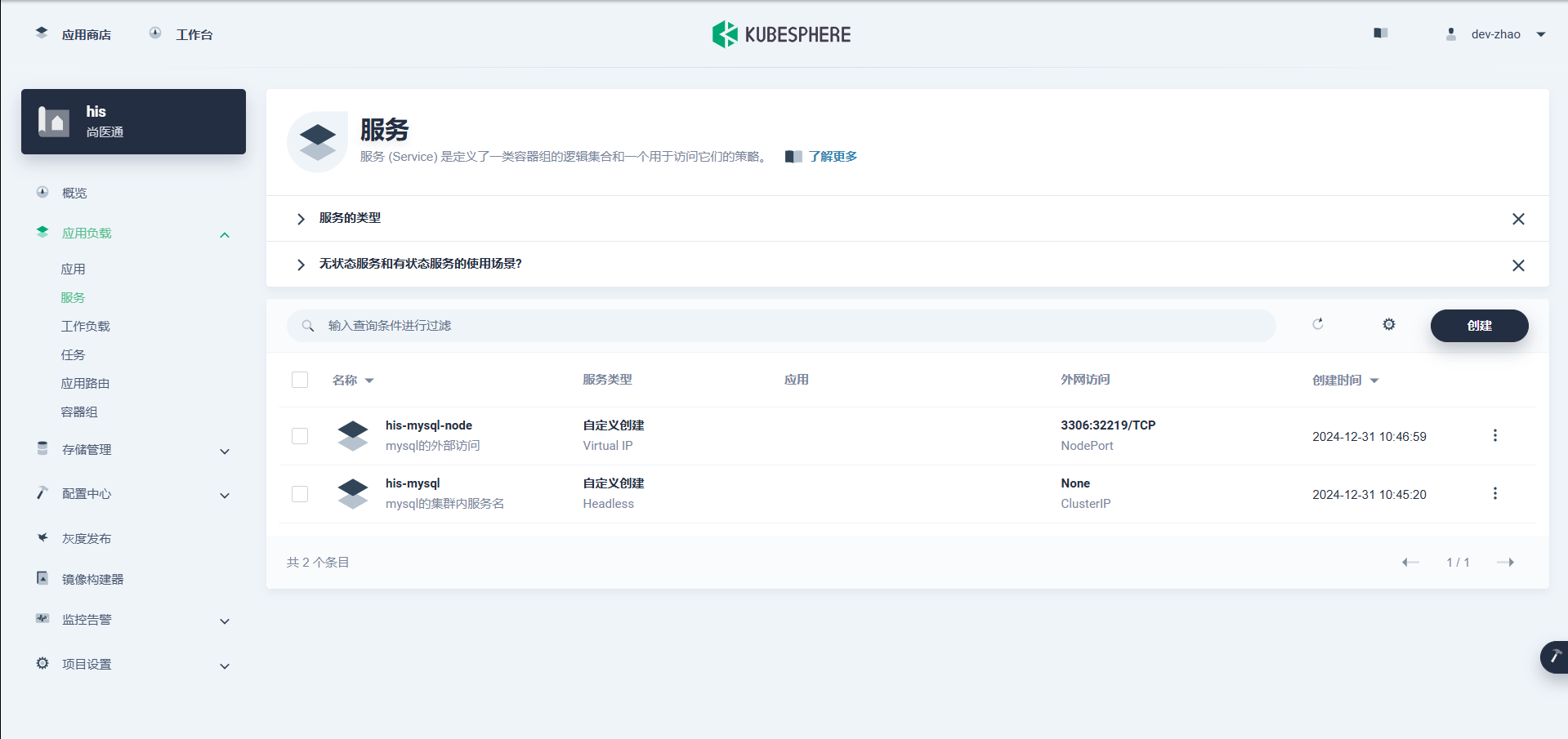
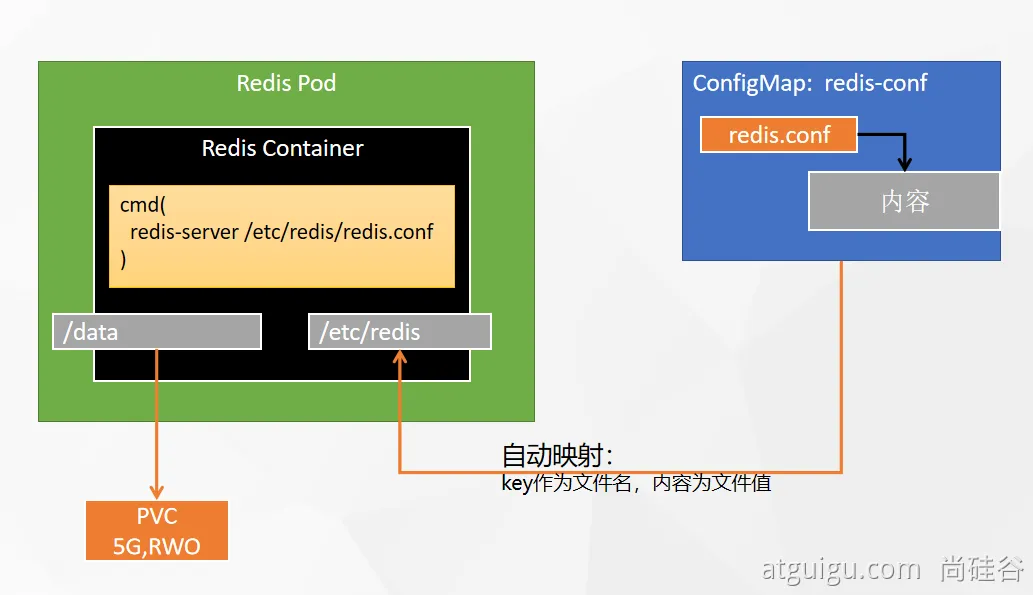
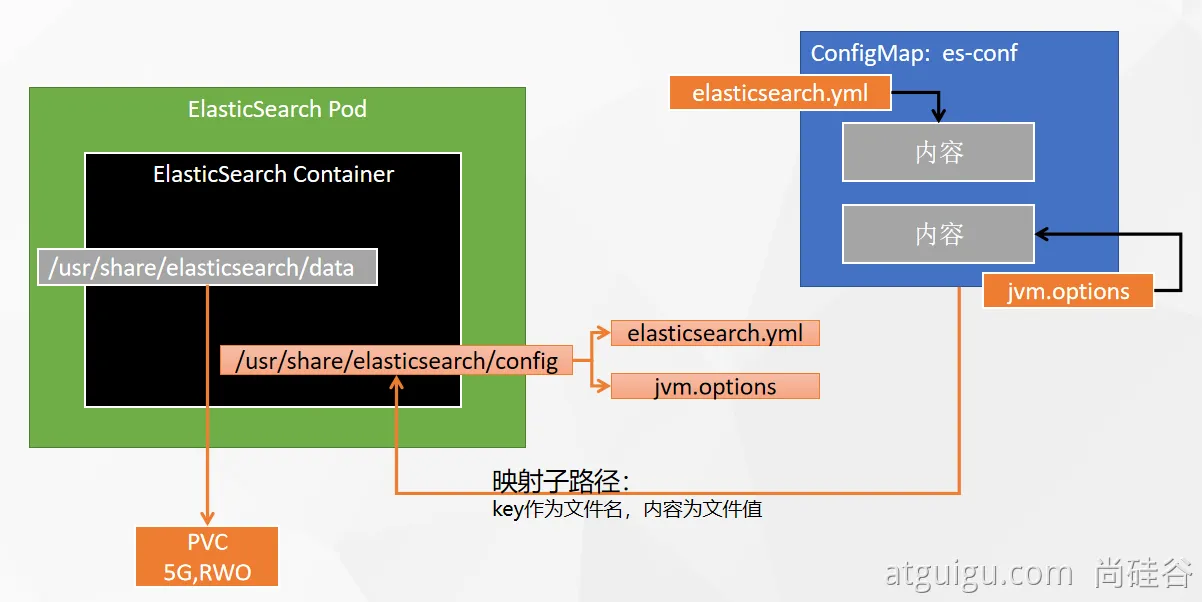
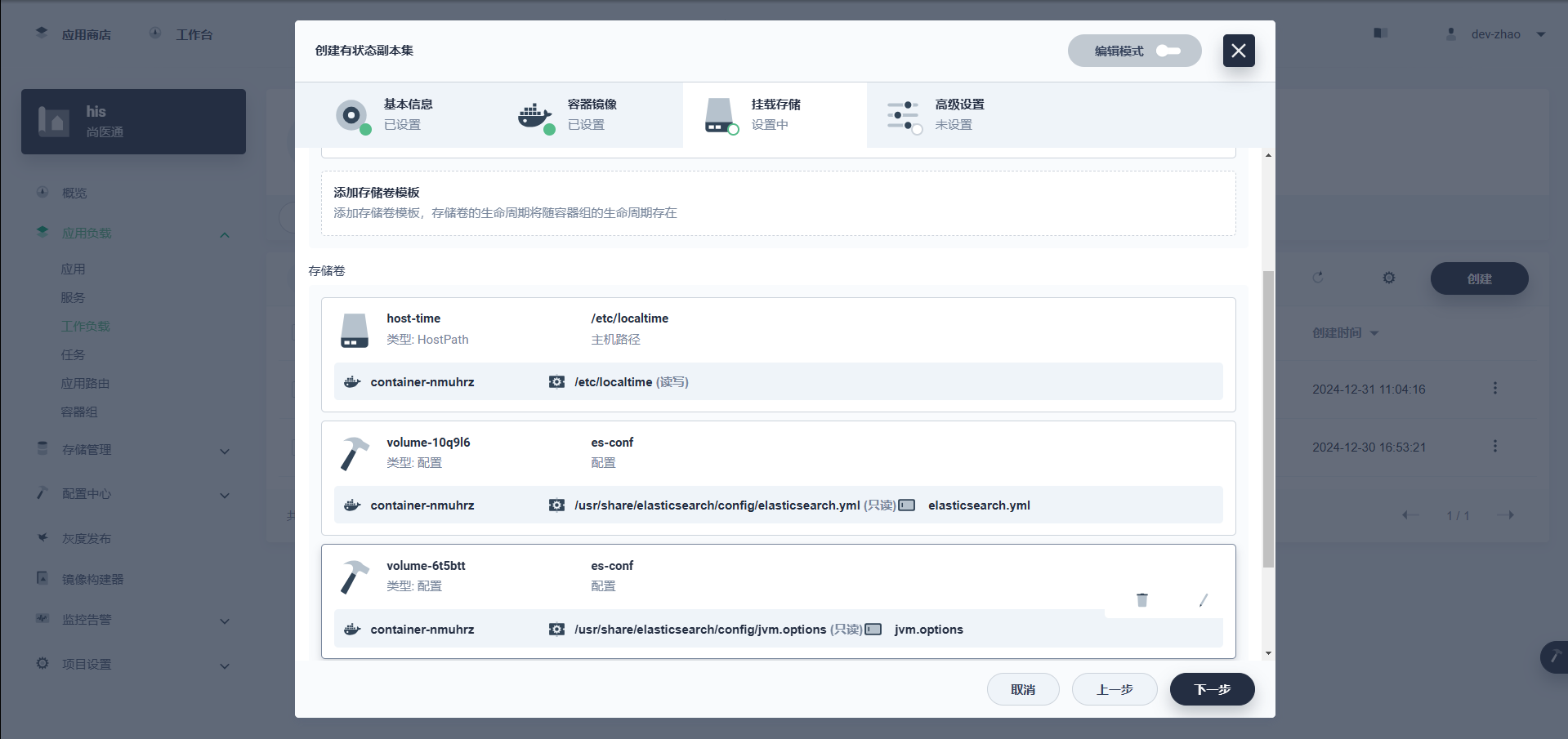
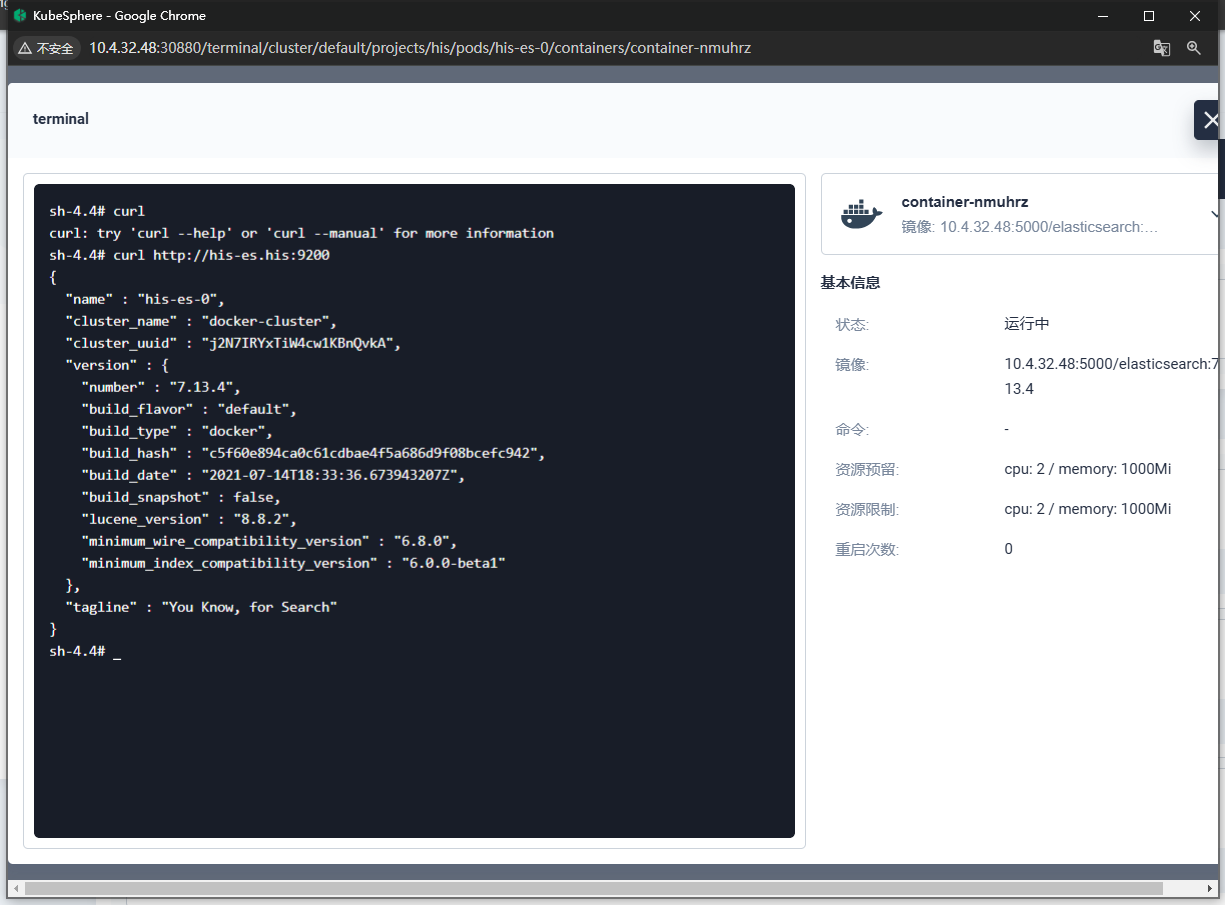
RuoYi-Cloud部署实战
本地环境-nacos启动
-
架构:https://gitee.com/zhangmrit/ruoyi-cloud/blob/nacos/doc/ruoyi-cloud.png
![在这里插入图片描述]()
-
nacos下载位置:https://github.com/alibaba/nacos/releases
不过这里我们选择跟老师一样的版本2.0.3:https://github.com/alibaba/nacos/releases/tag/2.0.3
-
部署:我们选择 单机模式支持mysql 的方式进行部署
⚠️ 注意哦:nacos路径中不能有中文,切记!
-
修改
nacos/conf/application.properties中的内容,需要设置spring使用mysql的数据库,以及开启并修改对应的配置#*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=Qiangmima@666 ### Connection pool configuration: hikariCP ... -
在 mysql 中新建一个
nacos数据库,执行nacos\conf\nacos-mysql.sql中的sql,创建需要的表。 -
单机启动nacos
-
得先有java,兄弟:java下载、安装、环境配置
-
在
nacos/bin目录cmd中运行:startup.cmd -m standalone -
访问本机的:
http://localhost:8848/nacos/![在这里插入图片描述]()
-
nacos的默认登录账号密码都是:
nacos![在这里插入图片描述]()
-
-
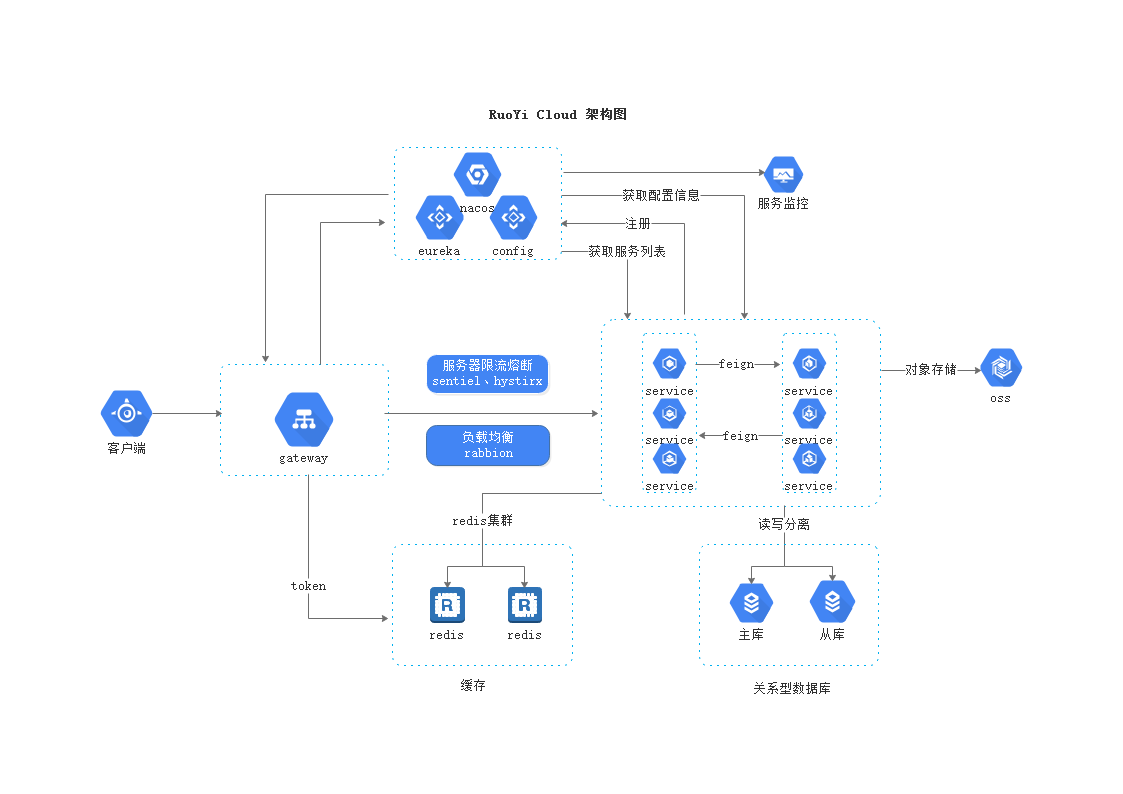
本地环境-导入数据库
-
执行
RuoYi-Cloud/sql/ry_config_20240902.sql项目中的配置sql -
修改 nacos 的配置文件中,把数据库改为项目的数据库,然后 重启nacos
db.url.0=jdbc:mysql://127.0.0.1:3306/ry-config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC重启之后,就发现界面上多了很多yaml文件了
![在这里插入图片描述]()
-
创建项目需要的数据库:ry-cloud:
CREATE DATABASE `ry-cloud` DEFAULT CHARACTER SET = 'utf8mb4';可恶啊,不让我创建中间有-的库
-
在 ry-cloud 库中执行
RuoYi-Cloud/sql/ry_20240629.sql、RuoYi-Cloud/sql/quartz.sql -
执行
RuoYi-Cloud/sql/ry_seata_20210128.sql,这个会自己创库创表 -
修改nacos中关于MySQL的配置信息,把用户名和密码改对:
ruoyi-job-dev.ymlruoyi-system-dev.yml
本地环境-启动完成
-
进入项目的前端工程:
RouYi-Cloud/ruoyi-ui,下载依赖包:(这里加不加registry其实都还好,我没加也挺快的)
npm install --registry=https://registry.npm.taobao.org -
因为我在本机直接用容器部署了redis,所以没有改redis配置的需求(localhost:6379)
[!warning] Idea的服务里面看不到spring
如题,真的痛苦,所以我直接去配置里面找到spring,然后下载了一堆东西之后,然后就能再spring的栏中搜到老师启动的服务,双击打开时java文件,在java文件中点击了服务启动的,很痛苦~ 😢
![在这里插入图片描述]()
-
监控平台也可以正常登录了:
![在这里插入图片描述]()
上云部署
-
注意事项:
- 中间件:有状态、数据导入
- 微服务:无状态、制作镜像
- 网络:各种访问地址
- 配置:生产配置分离、URL
-
迁移数据库:
😢 由于没有老师那样的工具,只能自己想办法啦~
😄 我的办法就是:下载MySQL Workbench,DBeaver现在难用太多。。。
👍 整完啦~这个工具还不错呐~
![在这里插入图片描述]()
💡 注意:schemas搁这儿呢,别到处找了~
![在这里插入图片描述]()
-
nacos上云,集群部署
![在这里插入图片描述]()
[!tip] tip
首先,我们创建了nacos服务,当然了会启动一个nacos的pod,然后我们把pod扩一个。在其中pod的bash中访问
his-nacos.his,即nacos总服务。我们会发现,其实是访问了地址:his-nacos-v1-1.his-nacos.his.svc.cluster.local类似的,我们要访问pod,只需要访问
his-nacos-v1-[x].his-nacos.his.svc.cluster.local,修改[x]为对应的pod即可![在这里插入图片描述]()
-
创建配置文件
-
application.properties,记住,数据库地址要改成内部地址+端口号,比如his-mysql.his:3306,账号密码也是一样# # Copyright 1999-2021 Alibaba Group Holding Ltd. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # #*************** Spring Boot Related Configurations ***************# ### Default web context path: server.servlet.contextPath=/nacos ### Default web server port: server.port=8848 #*************** Network Related Configurations ***************# ### If prefer hostname over ip for Nacos server addresses in cluster.conf: # nacos.inetutils.prefer-hostname-over-ip=false ### Specify local server's IP: # nacos.inetutils.ip-address= #*************** Config Module Related Configurations ***************# ### If use MySQL as datasource: spring.datasource.platform=mysql ### Count of DB: db.num=1 ### Connect URL of DB: db.url.0=jdbc:mysql://his-mysql.his:3306/ry-config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC db.user.0=root db.password.0=*** ### Connection pool configuration: hikariCP db.pool.config.connectionTimeout=30000 db.pool.config.validationTimeout=10000 db.pool.config.maximumPoolSize=20 db.pool.config.minimumIdle=2 #*************** Naming Module Related Configurations ***************# ### Data dispatch task execution period in milliseconds: Will removed on v2.1.X, replace with nacos.core.protocol.distro.data.sync.delayMs # nacos.naming.distro.taskDispatchPeriod=200 ### Data count of batch sync task: Will removed on v2.1.X. Deprecated # nacos.naming.distro.batchSyncKeyCount=1000 ### Retry delay in milliseconds if sync task failed: Will removed on v2.1.X, replace with nacos.core.protocol.distro.data.sync.retryDelayMs # nacos.naming.distro.syncRetryDelay=5000 ### If enable data warmup. If set to false, the server would accept request without local data preparation: # nacos.naming.data.warmup=true ### If enable the instance auto expiration, kind like of health check of instance: # nacos.naming.expireInstance=true ### will be removed and replaced by `nacos.naming.clean` properties nacos.naming.empty-service.auto-clean=true nacos.naming.empty-service.clean.initial-delay-ms=50000 nacos.naming.empty-service.clean.period-time-ms=30000 ### Add in 2.0.0 ### The interval to clean empty service, unit: milliseconds. # nacos.naming.clean.empty-service.interval=60000 ### The expired time to clean empty service, unit: milliseconds. # nacos.naming.clean.empty-service.expired-time=60000 ### The interval to clean expired metadata, unit: milliseconds. # nacos.naming.clean.expired-metadata.interval=5000 ### The expired time to clean metadata, unit: milliseconds. # nacos.naming.clean.expired-metadata.expired-time=60000 ### The delay time before push task to execute from service changed, unit: milliseconds. # nacos.naming.push.pushTaskDelay=500 ### The timeout for push task execute, unit: milliseconds. # nacos.naming.push.pushTaskTimeout=5000 ### The delay time for retrying failed push task, unit: milliseconds. # nacos.naming.push.pushTaskRetryDelay=1000 ### Since 2.0.3 ### The expired time for inactive client, unit: milliseconds. # nacos.naming.client.expired.time=180000 #*************** CMDB Module Related Configurations ***************# ### The interval to dump external CMDB in seconds: # nacos.cmdb.dumpTaskInterval=3600 ### The interval of polling data change event in seconds: # nacos.cmdb.eventTaskInterval=10 ### The interval of loading labels in seconds: # nacos.cmdb.labelTaskInterval=300 ### If turn on data loading task: # nacos.cmdb.loadDataAtStart=false #*************** Metrics Related Configurations ***************# ### Metrics for prometheus #management.endpoints.web.exposure.include=* ### Metrics for elastic search management.metrics.export.elastic.enabled=false #management.metrics.export.elastic.host=http://localhost:9200 ### Metrics for influx management.metrics.export.influx.enabled=false #management.metrics.export.influx.db=springboot #management.metrics.export.influx.uri=http://localhost:8086 #management.metrics.export.influx.auto-create-db=true #management.metrics.export.influx.consistency=one #management.metrics.export.influx.compressed=true #*************** Access Log Related Configurations ***************# ### If turn on the access log: server.tomcat.accesslog.enabled=true ### The access log pattern: server.tomcat.accesslog.pattern=%h %l %u %t "%r" %s %b %D %{User-Agent}i %{Request-Source}i ### The directory of access log: server.tomcat.basedir= #*************** Access Control Related Configurations ***************# ### If enable spring security, this option is deprecated in 1.2.0: #spring.security.enabled=false ### The ignore urls of auth, is deprecated in 1.2.0: nacos.security.ignore.urls=/,/error,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-ui/public/**,/v1/auth/**,/v1/console/health/**,/actuator/**,/v1/console/server/** ### The auth system to use, currently only 'nacos' and 'ldap' is supported: nacos.core.auth.system.type=nacos ### If turn on auth system: nacos.core.auth.enabled=false ### worked when nacos.core.auth.system.type=ldap,{0} is Placeholder,replace login username # nacos.core.auth.ldap.url=ldap://localhost:389 # nacos.core.auth.ldap.userdn=cn={0},ou=user,dc=company,dc=com ### The token expiration in seconds: nacos.core.auth.default.token.expire.seconds=18000 ### The default token: nacos.core.auth.default.token.secret.key=SecretKey012345678901234567890123456789012345678901234567890123456789 ### Turn on/off caching of auth information. By turning on this switch, the update of auth information would have a 15 seconds delay. nacos.core.auth.caching.enabled=true ### Since 1.4.1, Turn on/off white auth for user-agent: nacos-server, only for upgrade from old version. nacos.core.auth.enable.userAgentAuthWhite=false ### Since 1.4.1, worked when nacos.core.auth.enabled=true and nacos.core.auth.enable.userAgentAuthWhite=false. ### The two properties is the white list for auth and used by identity the request from other server. nacos.core.auth.server.identity.key=serverIdentity nacos.core.auth.server.identity.value=security #*************** Istio Related Configurations ***************# ### If turn on the MCP server: nacos.istio.mcp.server.enabled=false #*************** Core Related Configurations ***************# ### set the WorkerID manually # nacos.core.snowflake.worker-id= ### Member-MetaData # nacos.core.member.meta.site= # nacos.core.member.meta.adweight= # nacos.core.member.meta.weight= ### MemberLookup ### Addressing pattern category, If set, the priority is highest # nacos.core.member.lookup.type=[file,address-server] ## Set the cluster list with a configuration file or command-line argument # nacos.member.list=192.168.16.101:8847?raft_port=8807,192.168.16.101?raft_port=8808,192.168.16.101:8849?raft_port=8809 ## for AddressServerMemberLookup # Maximum number of retries to query the address server upon initialization # nacos.core.address-server.retry=5 ## Server domain name address of [address-server] mode # address.server.domain=jmenv.tbsite.net ## Server port of [address-server] mode # address.server.port=8080 ## Request address of [address-server] mode # address.server.url=/nacos/serverlist #*************** JRaft Related Configurations ***************# ### Sets the Raft cluster election timeout, default value is 5 second # nacos.core.protocol.raft.data.election_timeout_ms=5000 ### Sets the amount of time the Raft snapshot will execute periodically, default is 30 minute # nacos.core.protocol.raft.data.snapshot_interval_secs=30 ### raft internal worker threads # nacos.core.protocol.raft.data.core_thread_num=8 ### Number of threads required for raft business request processing # nacos.core.protocol.raft.data.cli_service_thread_num=4 ### raft linear read strategy. Safe linear reads are used by default, that is, the Leader tenure is confirmed by heartbeat # nacos.core.protocol.raft.data.read_index_type=ReadOnlySafe ### rpc request timeout, default 5 seconds # nacos.core.protocol.raft.data.rpc_request_timeout_ms=5000 #*************** Distro Related Configurations ***************# ### Distro data sync delay time, when sync task delayed, task will be merged for same data key. Default 1 second. # nacos.core.protocol.distro.data.sync.delayMs=1000 ### Distro data sync timeout for one sync data, default 3 seconds. # nacos.core.protocol.distro.data.sync.timeoutMs=3000 ### Distro data sync retry delay time when sync data failed or timeout, same behavior with delayMs, default 3 seconds. # nacos.core.protocol.distro.data.sync.retryDelayMs=3000 ### Distro data verify interval time, verify synced data whether expired for a interval. Default 5 seconds. # nacos.core.protocol.distro.data.verify.intervalMs=5000 ### Distro data verify timeout for one verify, default 3 seconds. # nacos.core.protocol.distro.data.verify.timeoutMs=3000 ### Distro data load retry delay when load snapshot data failed, default 30 seconds. # nacos.core.protocol.distro.data.load.retryDelayMs=30000 -
cluster.conf,记住这里的ip也要改内部地址哦,有几个集群改成几个地址# # Copyright 1999-2018 Alibaba Group Holding Ltd. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # #it is ip #example his-nacos-v1-0.his-nacos.his.svc.cluster.local:8848 his-nacos-v1-1.his-nacos.his.svc.cluster.local:8848 his-nacos-v1-2.his-nacos.his.svc.cluster.local:8848
-
-
创建有状态服务
[!warning] nacos注意用standalone部署
- 从后面回来的,用集群部署好了没问题,但是部署其他的报错了,
Nacos cluster is running with 1.X mode, can't accept gRPC request temporarily. Please check the server status or close Double write to force open 2.0 mode. - 我尝试了修改nacos版本,改成了v2.4.3,但是会出现其他的错,导致nacos集群启不起来,所以还是放弃。参考
-
镜像:
10.4.32.48:5000/nacos/nacos-server:v2.0.3 -
nacos只需要挂载配置文件,不需要挂载存储
⚠️ 要以子路径的形式挂载哦,这样其他的配置文件才会同时存在(即使没有暴露出来)要一个一个路径配哦。
路径是:
/home/nacos/conf![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
[!warning] warning
⚠️ 不要直接配置好了,就挂载,因为这样会导致其他的配置文件消失(因为没有暴露出来,则会直接覆盖消失)
![在这里插入图片描述]()
- 从后面回来的,用集群部署好了没问题,但是部署其他的报错了,
-
修改配置文件要记得重启StatefulSet:降低副本数量到0,然后再重新新增到目标数量。
-
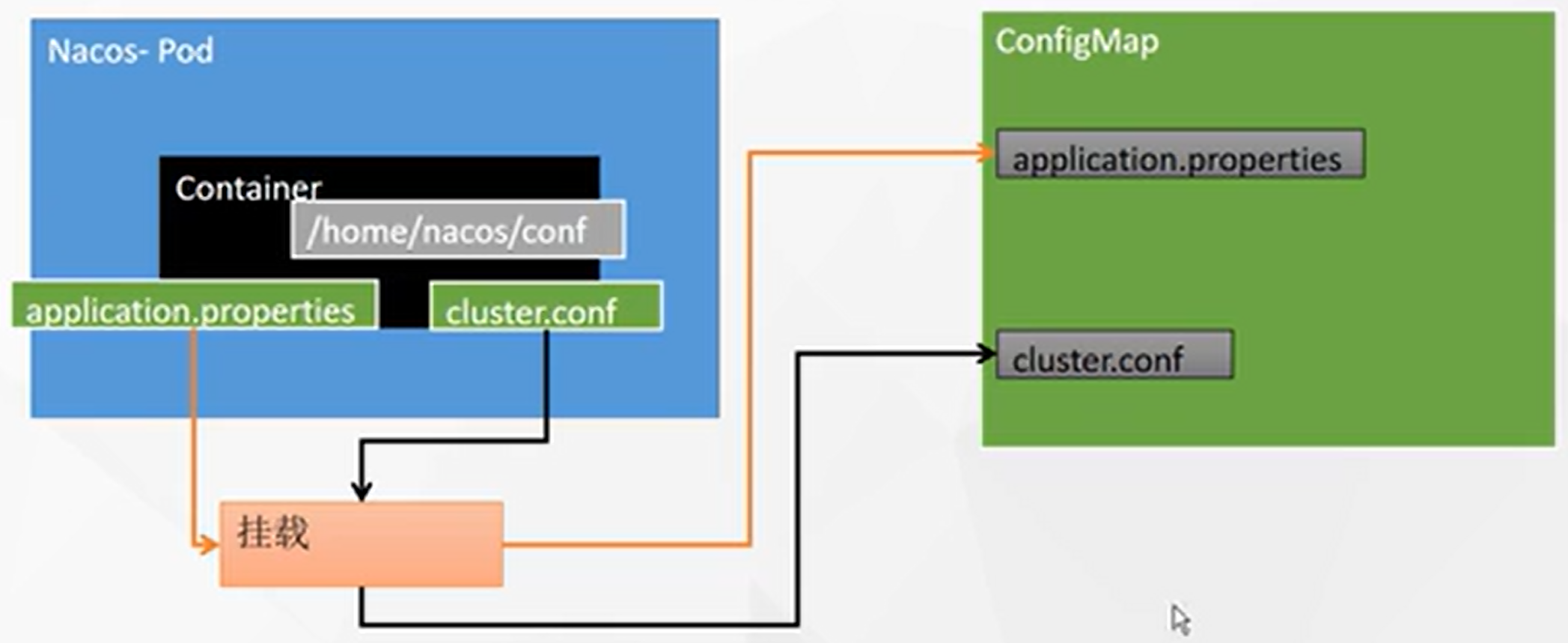
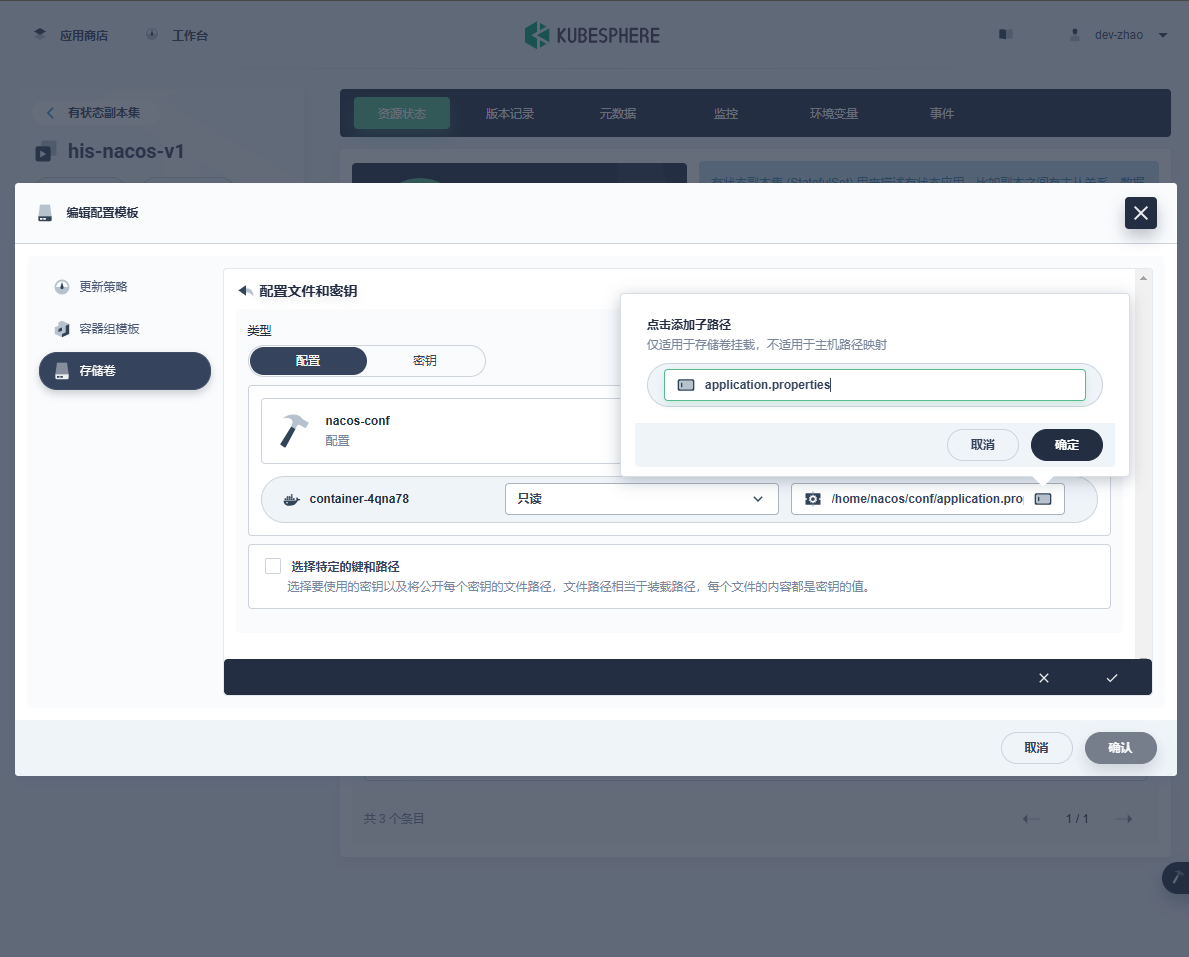
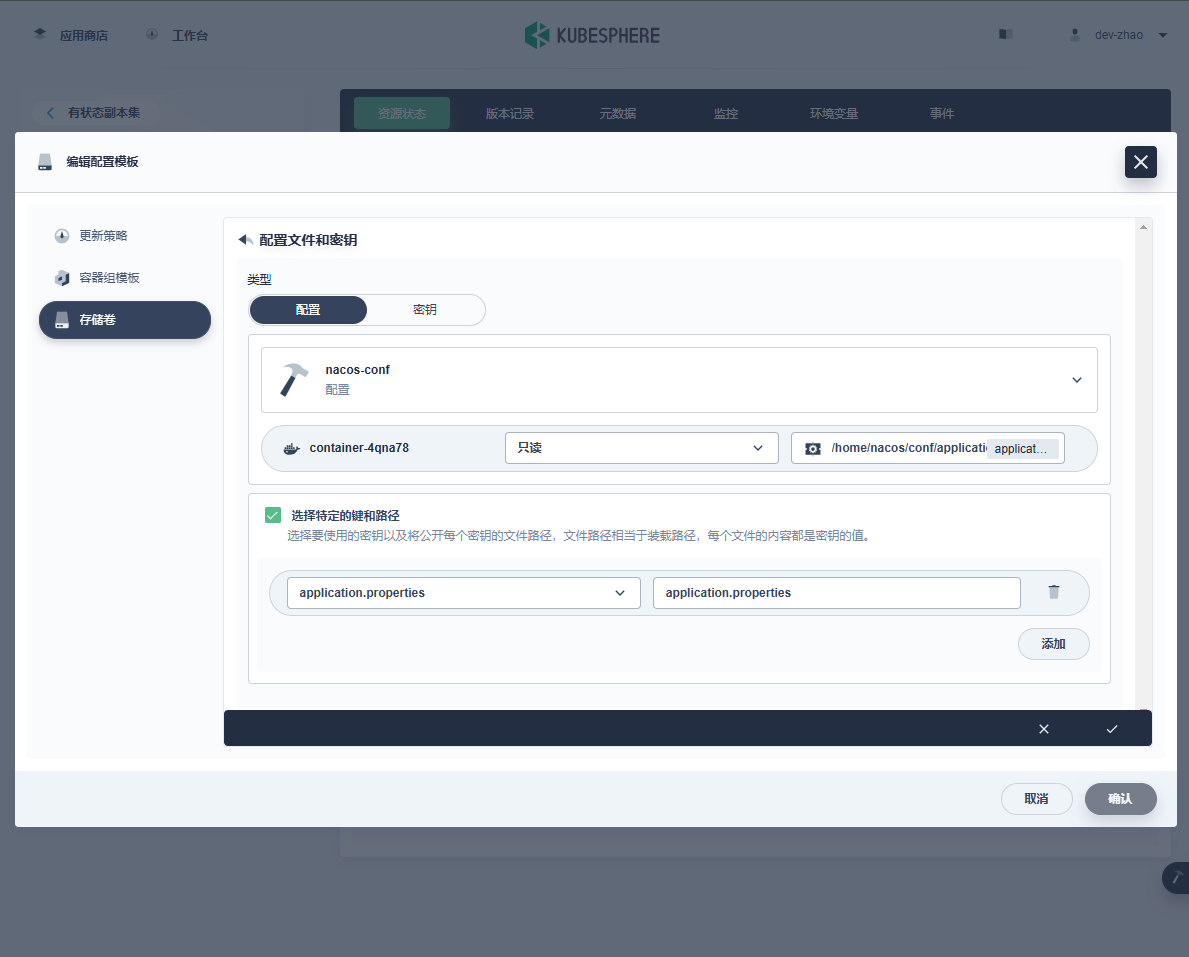
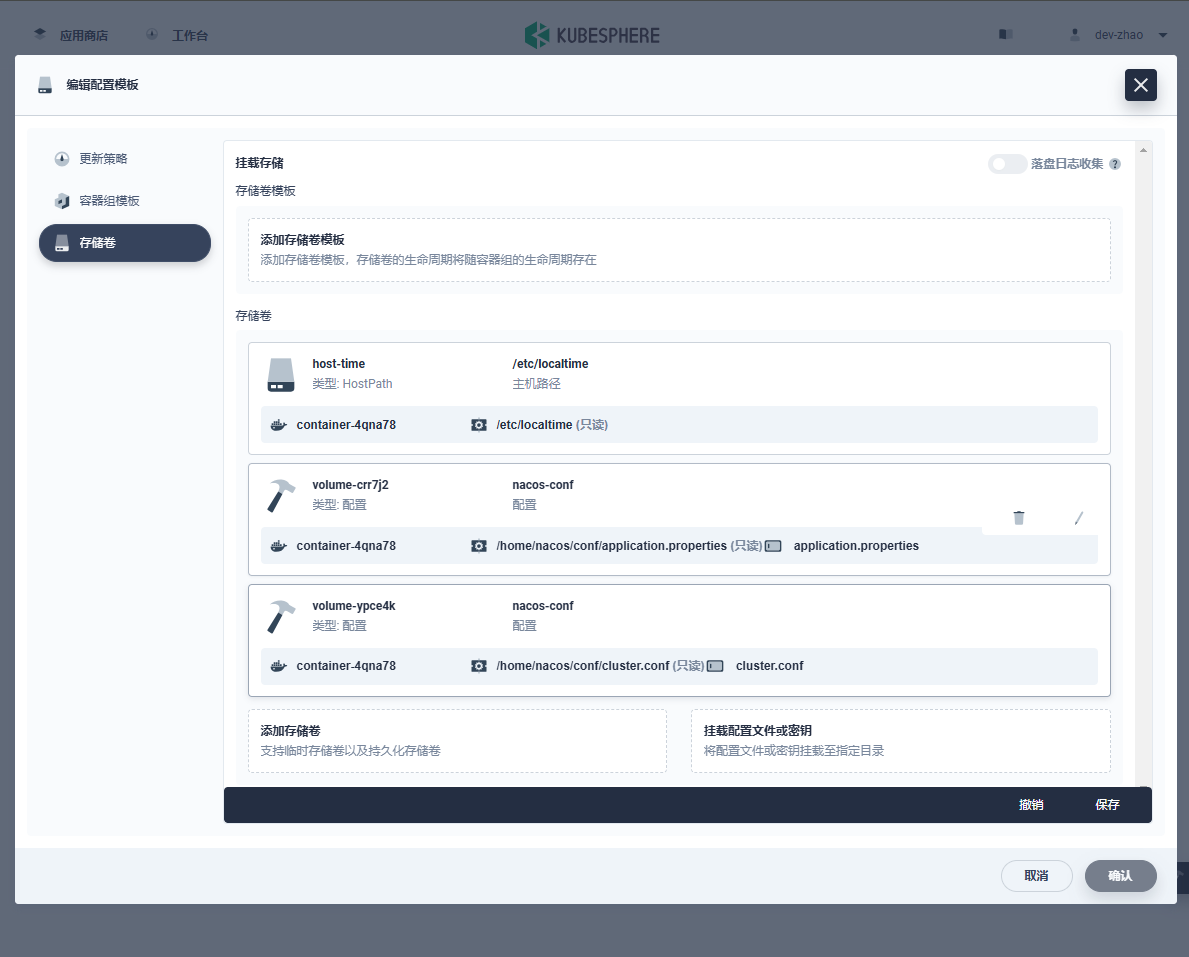
Java微服务上云
微服务 自底向上 的部署方式
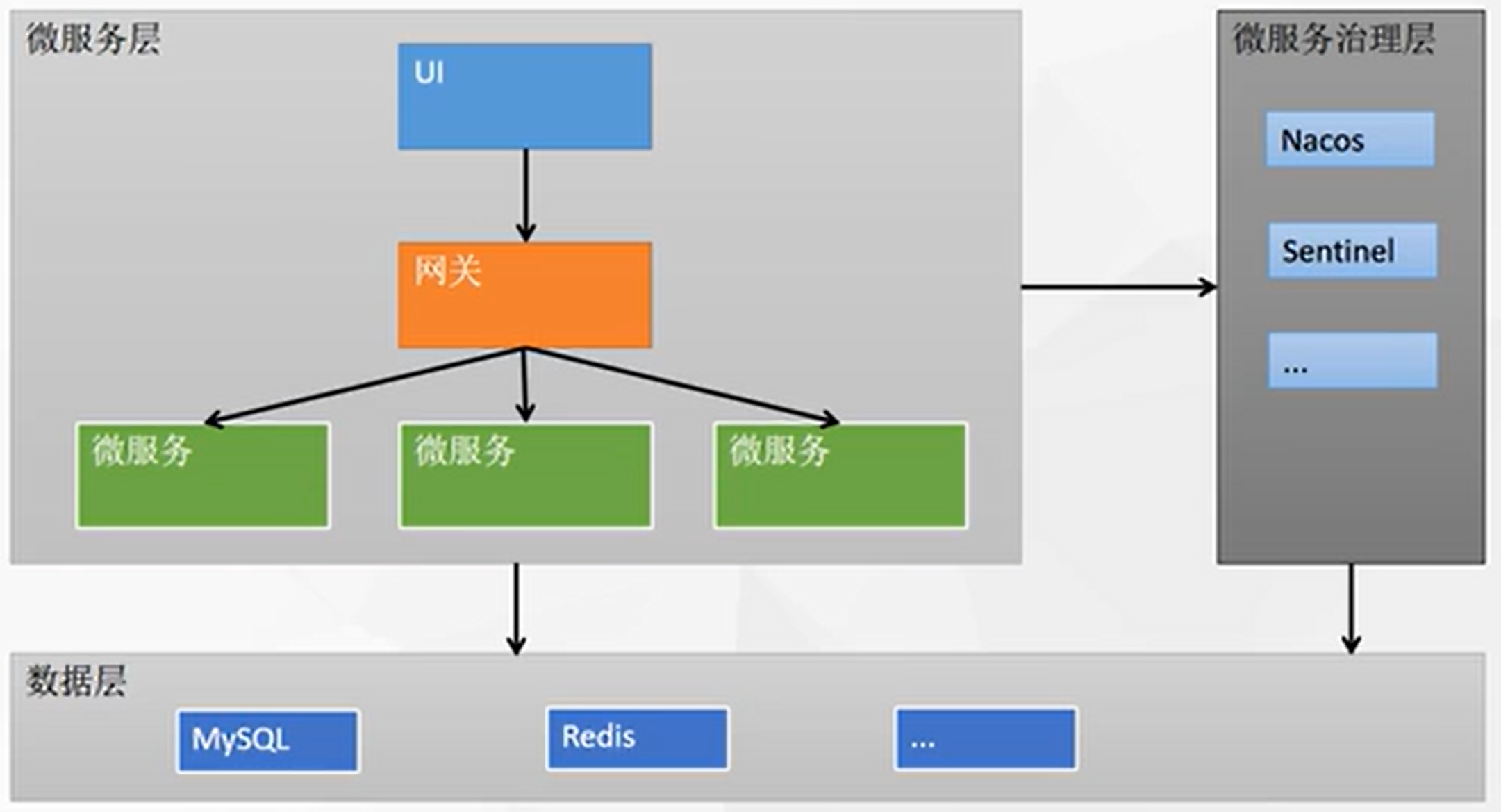
-
云上环境Dockerfile配置
FROM openjdk:8-jdk LABEL maintainer=liyingjun #docker run -e PARAMS="--server.port 9090" ENV PARAMS="--server.port=8080 --spring.profiles.active=prod --spring.cloud.nacos.discovery.server-addr=his-nacos.his:8848 --spring.cloud.nacos.config.server-addr=his-nacos.his:8848 --spring.cloud.nacos.config.namespace=prod --spring.cloud.nacos.config.file-extension=yml" RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone COPY target/*.jar /app.jar EXPOSE 8080 # ENTRYPOINT ["/bin/sh","-c","java -Dfile.encoding=utf8 -Djava.security.egd=file:/dev/./urandom -jar app.jar ${PARAMS}"]规则:
- 容器默认以8080端口启动
- 时间为CST
- 环境变量 PARAMS 可以动态指定配置文件中任意的值
- nacos集群内地址为
his-nacos.his:8848 - 微服务默认启动加载 nacos中
服务名-激活的环境.yml文件,所以线上的配置可以全部写在nacos中。
![在这里插入图片描述]()
-
微服务上云
-
先用maven打包成 .jar
-
测试 .jar 是否能用,并指定启动编码为utf8 :
java -Dfile.encoding=utf8 -jar ruoyi-auth.jar -
构建每个微服务的jar包和Dockerfile的文件结构
├─ruoyi-auth │ │ Dockerfile │ │ │ └─target │ ruoyi-auth.jar │ ├─ruoyi-gateway │ │ Dockerfile │ │ │ └─target │ ruoyi-gateway.jar │ ├─ruoyi-modules-file │ │ Dockerfile │ │ │ └─target │ ruoyi-modules-file.jar │ ├─ruoyi-modules-job │ │ Dockerfile │ │ │ └─target │ ruoyi-modules-job.jar │ ├─ruoyi-modules-system │ │ Dockerfile │ │ │ └─target │ ruoyi-modules-system.jar │ └─ruoyi-visual-monitor │ Dockerfile │ └─target ruoyi-visual-monitor.jar -
构建镜像:
docker build -t ruoyi-auth:v1.0 -f Dockerfile .[!tag]
这里由于众所周知的原因修改了镜像的路径为某个路径,方便镜像的下载
![在这里插入图片描述]()
-
推送镜像 给阿里云
- 开通阿里云 “容器镜像服务(个人版)”
- 创建一个名称空间(lfy_ruoyi)。(存储镜像)
- 推送镜像到阿里云镜像仓库
[!tip]
这里我直接推送到自己的Registry中~
- tag + push
💡 问题来了,太麻烦了家人们,这样~ 有没有自动化制作镜像流程,自动化打包推送镜像流程
-
部署规则
- 应用一启动会获取到 "应用名-激活的环境标识.yml"
- 每次部署应用的时候,需要提前修改nacos线上配置,确认好每个中间件的连接地址是否正确
开始部署:直接从服务开始创建 无状态服务 即可! 记得确认和修改nacos的生产yml配置信息:
- redis:
his-redis.his:6379 - mysql:
his-mysql.his:3306 - 以及以上的用户名和密码
看到nacos的服务列表中出现服务,就是启动成功啦!
[!warning]
数据库表名大小写的问题
其实跟着下来已经在数据库配置中弄好了,这里提醒一下,如果job服务报错,可能是这个问题。
网关服务 修改yaml配置文件,新增setinel问题
spring: redis: host: his-redis.his port: 6379 password: cloud: # 【新增内容】start sentinel: # 取消控制台懒加载 eager: true transport: # 控制台地址 dashbord:127.0.0.1:8718 # nacos配置持久化 datasource: ds1: nacos: server-addr: his-nacos.his:8848 dataId: sentinel-ruoyi-gateway groupId: DEFAULT_GROUP data-type: json rule-type: gw-flow # 【新增内容】end gateway:6个微服务就部署好了:
![在这里插入图片描述]()
-
-
前端上云
-
先把
vue.config.js中的网关从localhost改为服务的:ruoyi-gateway.his -
打包:
npm run build:prod -
准备如下路径
│ dockerfile ├─conf │ nginx.conf └─html └─dist -
修改
nginx.conf如下两处,server_name _;,proxy_pass http://ruoyi-gateway.his:8080/;worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; server { listen 80; # 1. 浏览器无论收到什么地址,都会到nginx来处理,因为k8s分配ip是随机分配的,所以要改为 _。nginx就可以处理来自任何地址的请求了。 server_name _; location / { root /home/ruoyi/projects/ruoyi-ui; try_files $uri $uri/ /index.html; index index.html index.htm; } location /prod-api/{ proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header REMOTE-HOST $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 2. 网关地址要改为对应的 proxy_pass http://ruoyi-gateway.his:8080/; } # 避免actuator暴露 if ($request_uri ~ "/actuator") { return 403; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } } -
打包好的dist文件夹所有内容复制到html下
-
准备好Dockerfile,当然了,镜像得改
# 基础镜像 FROM 10.4.32.48:5000/nginx # author MAINTAINER liyingjun # 挂载目录 VOLUME /home/ruoyi/projects/ruoyi-ui # 创建目录 RUN mkdir -p /home/ruoyi/projects/ruoyi-ui # 指定路径 WORKDIR /home/ruoyi/projects/ruoyi-ui # 复制conf文件到路径 COPY ./conf/nginx.conf /etc/nginx/nginx.conf # 复制html文件到路径 COPY ./html/dist /home/ruoyi/projects/ruoyi-ui -
构建镜像:
docker build -t 10.4.32.48:5000/ruoyi-ui:v1.0 -f dockerfile .,直接为我的Registry路径,后面就可以直接docker push啦 -
直接跟之前一样启无状态服务即可,注意,这里要开外网 NodePort
![在这里插入图片描述]()
-
-
探针
问题:考虑到nacos在启动的时候与mysql数据库的pod健康状态有强相关,如果nacos在启动时候mysql pod还没有正常运行,nacos的pod就会一直处于不正常的状态,无法使用。
解决:引入存活探针,定时访问nacos的本机地址
/nacos,如果没有响应则不断删掉pod并重启,直到mysql正常即nacos正常为止。![在这里插入图片描述]()
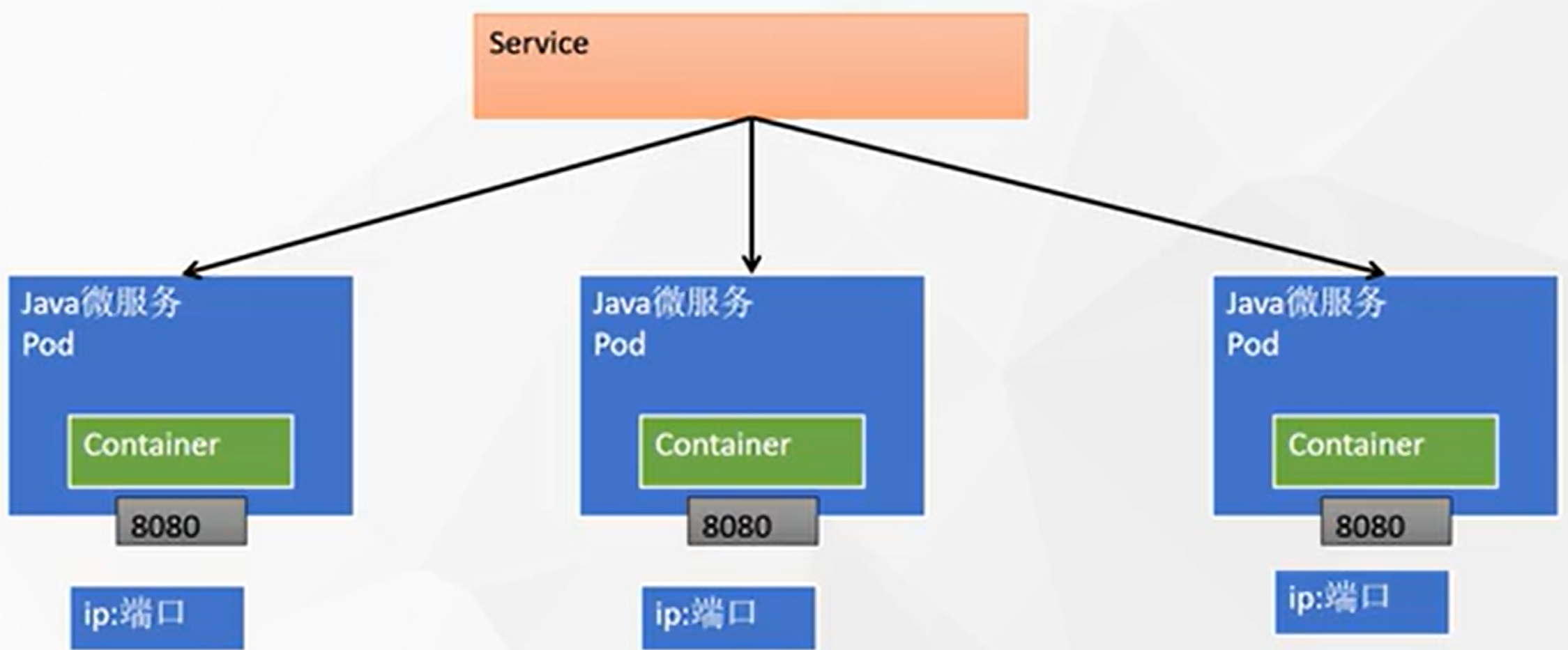
6. 云原生DevOps基础与实战
DevOps简介
DevOps 是一系列做法和工具,可以使 IT 和软件开发团队之间的流程实现自动化。其中,随着敏捷软件开发日趋流行,持续集成 (CI,Continuous Integration) 、 持续交付 (CD,Continuous Delivery) 和 持续部署 (CD,Continuous Deployment) 已经成为该领域一个理想的解决方案。在 CI/CD 工作流中,每次集成都通过自动化构建来验证,包括编码、发布和测试,从而帮助开发者提前发现集成错误,团队也可以快速、安全、可靠地将内部软件交付到生产环境。
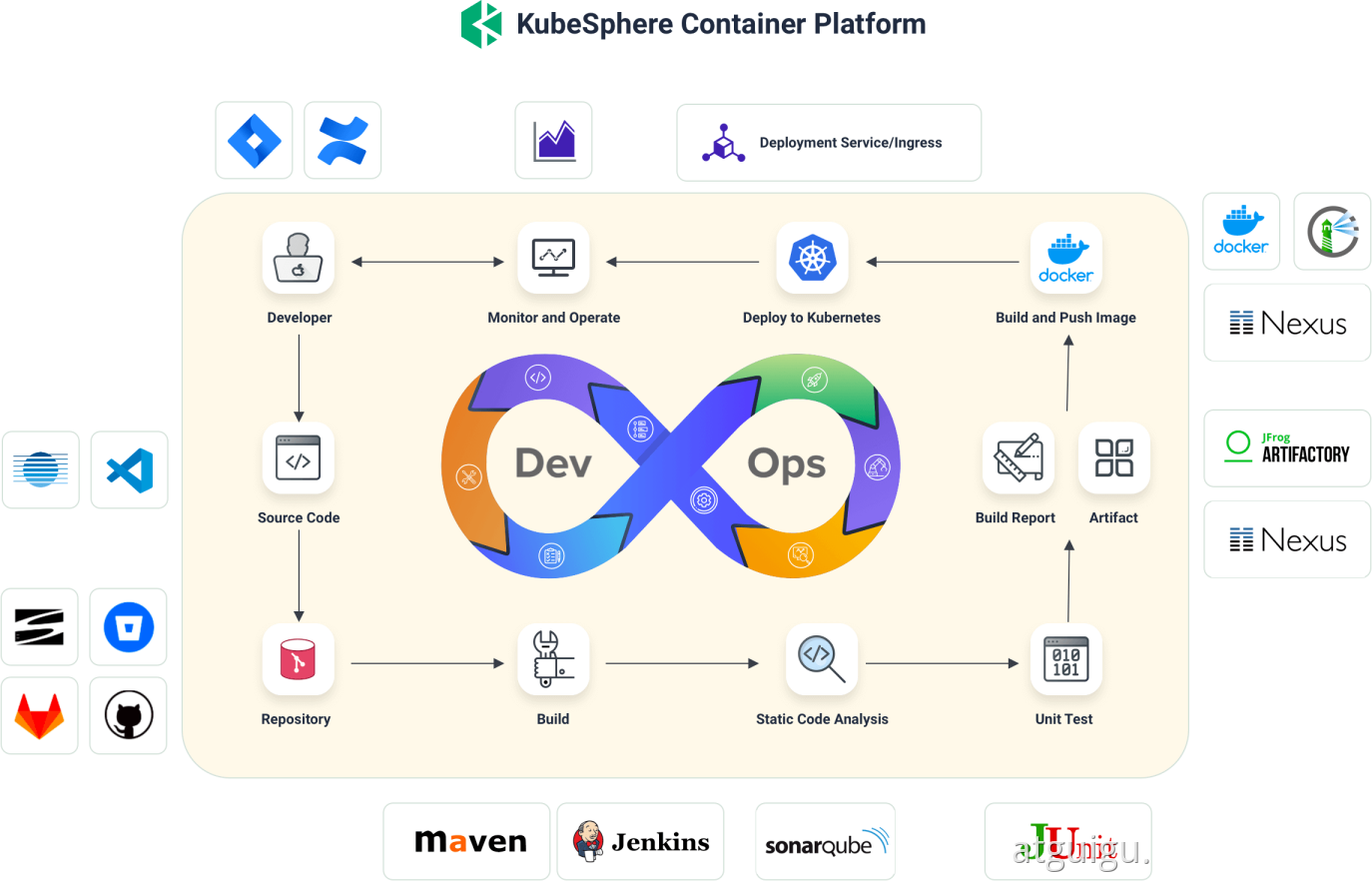
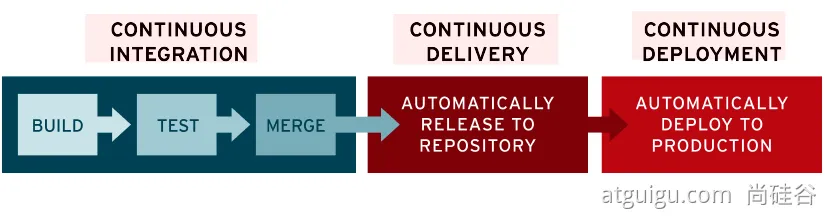
尚医通项目上云
-
项目架构
![在这里插入图片描述]()
-
中间件
中间件 集群内地址 外部访问地址 Sentinel his-sentinel.his:8080 10.4.32.48:31723 MongoDB his-mongo.his:27017 10.4.32.48:32713 MySQL his-mysql.his:3306 10.4.32.48:32219 Nacos his-nacos.his:8848 10.4.32.48:31329 Redis his-redis.his:6379 10.4.32.48:31636 RabbitMQ rabbitm-j3dy7r-rabbitmq.his:5672 10.4.32.48:31397 -
sentinel
[!warning] sentinel官方没有镜像
去下载老师的镜像吧。。。
部署完之后,根据外网开放端口可以访问sentinel:sentinel/sentinel
![在这里插入图片描述]()
-
mongo:好说,整就完了,我不是用app部署的,我是自己写的 his-mongo 和 his-mongo-node,同样的,我不得不下了个 MongoDB Compass
![在这里插入图片描述]()
-
-
流水线
-
项目地址:
https://gitee.com/leifengyang/yygh-parent https://gitee.com/leifengyang/yygh-admin https://gitee.com/leifengyang/yygh-site -
导入数据
- mysql:
yygh-parent-master/data/sql - mongodb:
yygh-parent-master/data/json
- mysql:
-
项目默认规则
- 每个微服务项目,在生产环境时,会自动获取
微服务名-prod.yml作为自己的核心配置文件 - 每个微服务项目,在生产环境时,默认都是使用
8080端口
- 每个微服务项目,在生产环境时,会自动获取
-
生产与开发配置隔离,在nacos上配置,给每一个微服务:
-
service-cmn-prod.ymlserver: port: 8080 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl mapper-locations: classpath:mapper/*.xml global-config: db-config: logic-delete-value: 1 logic-not-delete-value: 0 spring: cloud: sentinel: transport: dashboard: http://his-sentinel.his:8080 redis: host: his-redis.his port: 6379 database: 0 timeout: 1800000 password: lettuce: pool: max-active: 20 #最大连接数 max-wait: -1 #最大阻塞等待时间(负数表示没限制) max-idle: 5 #最大空闲 min-idle: 0 #最小空闲 datasource: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://his-mysql.his:3306/yygh_cmn?characterEncoding=utf-8&useSSL=false username: root password: 密码就不给你看了~ hikari: connection-test-query: SELECT 1 connection-timeout: 60000 idle-timeout: 500000 max-lifetime: 540000 maximum-pool-size: 12 minimum-idle: 10 pool-name: GuliHikariPool jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 -
service-hosp-prod.ymlserver: port: 8201 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl mapper-locations: classpath:mapper/*.xml feign: sentinel: enabled: true client: config: default: #配置全局的feign的调用超时时间 如果 有指定的服务配置 默认的配置不会生效 connectTimeout: 30000 # 指定的是 消费者 连接服务提供者的连接超时时间 是否能连接 单位是毫秒 readTimeout: 50000 # 指定的是调用服务提供者的 服务 的超时时间() 单位是毫秒 spring: main: allow-bean-definition-overriding: true #当遇到同样名字的时候,是否允许覆盖注册 cloud: sentinel: transport: dashboard: his-sentinel.his:8080 data: mongodb: host: his-mongo.his port: 27017 database: yygh_hosps #指定操作的数据库 rabbitmq: host: rabbitm-j3dy7r-rabbitmq.his port: 5672 username: root password: rabbitmq_Qiangmima@666 datasource: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://his-mysql.his:3306/yygh_hosp?characterEncoding=utf-8&useSSL=false username: root password: 密码就不给你看了~ hikari: connection-test-query: SELECT 1 connection-timeout: 60000 idle-timeout: 500000 max-lifetime: 540000 maximum-pool-size: 12 minimum-idle: 10 pool-name: GuliHikariPool jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 redis: host: his-redis.his -
service-order-prod.ymlserver: port: 8206 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl mapper-locations: classpath:mapper/*.xml feign: sentinel: enabled: true client: config: default: #配置全局的feign的调用超时时间 如果 有指定的服务配置 默认的配置不会生效 connectTimeout: 30000 # 指定的是 消费者 连接服务提供者的连接超时时间 是否能连接 单位是毫秒 readTimeout: 50000 # 指定的是调用服务提供者的 服务 的超时时间() 单位是毫秒 spring: main: allow-bean-definition-overriding: true #当遇到同样名字的时候,是否允许覆盖注册 cloud: sentinel: transport: dashboard: his-sentinel.his:8080 rabbitmq: host: rabbitm-j3dy7r-rabbitmq.his port: 5672 username: root password: rabbitmq_Qiangmima datasource: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://his-mysql.his:3306/yygh_order?characterEncoding=utf-8&useSSL=false username: root password: mysql_Qiangmima hikari: connection-test-query: SELECT 1 connection-timeout: 60000 idle-timeout: 500000 max-lifetime: 540000 maximum-pool-size: 12 minimum-idle: 10 pool-name: GuliHikariPool jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 redis: host: his-redis.his # 微信 #weixin: # appid: wx8397f8696b538317 # partner: 1473426802 # partnerkey: T6m9iK73b0kn9g5v426MKfHQH7X8rKwb # notifyurl: http://a31ef7db.ngrok.io/WeChatPay/WeChatPayNotify weixin: appid: wx74862e0dfcf69954 partner: 1558950191 partnerkey: T6m9iK73b0kn9g5v426MKfHQH7X8rKwb notifyurl: http://qyben.free.idcfengye.com/api/order/weixin/notify cert: C:\Users\lfy\Desktop\yygh-parent\service\service-order\src\main\resources\apiclient_cert.p12 -
service-oss-prod.ymlserver: port: 8080 spring: cloud: sentinel: transport: dashboard: his-sentinel.his:8080 #阿里云 OSS aliyun: oss: file: endpoint: oss-cn-beijing.aliyuncs.com keyid: LTAI4FhtGRtRGtPvmLBv8vxk keysecret: sq8e8WLYoKwJoCNLbjRdlSTaOaFumD #bucket可以在控制台创建,也可以使用java代码创建 bucketname: online-teach-file -
service-sms-prod.ymlserver: port: 8204 spring: cloud: sentinel: transport: dashboard: his-sentinel.his:8080 rabbitmq: host: rabbitm-j3dy7r-rabbitmq.his port: 5672 username: root password: rabbitmq_Qiangmima@666 redis: host: his-redis.his #阿里云 短信 aliyun: sms: regionId: default accessKeyId: LTAI0YbQf3pX8WqC secret: jX8D04DmDI3gGKjW5kaFYSzugfqmmT -
service-statistics-prod.ymlserver: port: 8208 feign: sentinel: enabled: true client: config: default: #配置全局的feign的调用超时时间 如果 有指定的服务配置 默认的配置不会生效 connectTimeout: 30000 # 指定的是 消费者 连接服务提供者的连接超时时间 是否能连接 单位是毫秒 readTimeout: 50000 # 指定的是调用服务提供者的 服务 的超时时间() 单位是毫秒 spring: main: allow-bean-definition-overriding: true #当遇到同样名字的时候,是否允许覆盖注册 cloud: sentinel: transport: dashboard: his-sentinel.his:8080 -
service-task-prod.ymlserver: port: 8207 spring: cloud: sentinel: transport: dashboard: his-sentinel.his:8080 rabbitmq: host: rabbitm-j3dy7r-rabbitmq.his port: 5672 username: rabbitm-j3dy7r-rabbitmq.his password: rabbitmq_Qiangmima@666 -
service-user-prod.ymlserver: port: 8203 mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl mapper-locations: classpath:mapper/*.xml feign: sentinel: enabled: true client: config: default: #配置全局的feign的调用超时时间 如果 有指定的服务配置 默认的配置不会生效 connectTimeout: 30000 # 指定的是 消费者 连接服务提供者的连接超时时间 是否能连接 单位是毫秒 readTimeout: 50000 # 指定的是调用服务提供者的 服务 的超时时间() 单位是毫秒 spring: main: allow-bean-definition-overriding: true #当遇到同样名字的时候,是否允许覆盖注册 cloud: sentinel: transport: dashboard: his-sentinel.his:8080 datasource: type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://his-mysql.his:3306/yygh_user?characterEncoding=utf-8&useSSL=false username: root password: 密码就不给你看了~ hikari: connection-test-query: SELECT 1 connection-timeout: 60000 idle-timeout: 500000 max-lifetime: 540000 maximum-pool-size: 12 minimum-idle: 10 pool-name: GuliHikariPool jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 wx: open: # 微信开放平台 appid app_id: wxc606fb748aedee7c # 微信开放平台 appsecret app_secret: 073e8e1117c1054b14586c8aa922bc9c # 微信开放平台 重定向url(需要在微信开放平台配置) redirect_url: http://qyben.free.idcfengye.com/api/user/weixin/callback #redirect_url: http://qyben.free.idcfengye.com/api/user/weixin/callback #wx: # open: # # 微信开放平台 appid # app_id: wxed9954c01bb89b47 # # 微信开放平台 appsecret # app_secret: 2cf9a4a81b6151d560e9bbc625c3297b # # 微信开放平台 重定向url(需要在微信开放平台配置) # redirect_url: http://guli.shop/api/ucenter/wx/callback yygh: #预约挂号平台baserul baseUrl: http://localhost:3000 -
server-gateway-prod.ymlserver: port: 80 spring: application: name: server-gateway cloud: gateway: discovery: #是否与服务发现组件进行结合,通过 serviceId(必须设置成大写) 转发到具体的服务实例。默认为false,设为true便开启通过服务中心的自动根据 serviceId 创建路由的功能。 locator: #路由访问方式:http://Gateway_HOST:Gateway_PORT/大写的serviceId/**,其中微服务应用名默认大写访问。 enabled: true routes: - id: service-user uri: lb://service-user predicates: - Path=/*/user/** - id: service-cmn uri: lb://service-cmn predicates: - Path=/*/cmn/** - id: service-sms uri: lb://service-sms predicates: - Path=/*/sms/** - id: service-hosp uri: lb://service-hosp predicates: - Path=/*/hosp/** - id: service-order uri: lb://service-order predicates: - Path=/*/order/** - id: service-statistics uri: lb://service-statistics predicates: - Path=/*/statistics/** - id: service-cms uri: lb://service-cms predicates: - Path=/*/cms/** - id: service-oss uri: lb://service-oss predicates: - Path=/*/oss/**
-
-
Jenkinsfile
// 流水线文件 pipeline { agent any stages { stage('Build'){ ... } stage('Test') stage('Deploy') } } -
使用kubesphere的流水线模板创造流水线
-
修改maven让他从阿里云下载镜像
- 使用admin登陆ks
- 进入集群管理
- 进入配置中心
- 找到配置
- ks-devops-agent
- 修改这个配置。加入maven阿里云镜像加速地址
-
缓存机制:已经下载过的jar包,下一次流水线的启动,不会重复下载
-
在
environment中定义的所有变量,可以在流水线的任意位置使用$变量名 -
部署到k8s集群:
-
给每一个微服务准备一个
deploy.yaml(k8s的部署配置文件) -
执行以下步骤:kubernetesDeploy(kubesphere已经集成好的工具)
-
传入
deploy.yaml的位置就能部署kubectl apply -f deploy.yaml- 这里需要注意的是,运行上述命令需要 kubectl 的权限,因此需要配置 Kubeconfig 中的相关内容,比如配置路径
-
一定在项目里面(his,不是流水线项目),找到配置-秘钥,配置一个阿里云的访问账号密码
-
[!warning] devops任务一直队列中
看到这个问题肯定是知道出错了,我们用的是maven的label,那么我们有对应的镜像吗,没有印象?必然啊,我们啥也没用。
- 去服务器上看一下
kubectl get pods -A,哦豁,看到devops那有几个pod拉镜像失败了吧,失败?失败就对了 - 好了,总结一下要拉哪些镜像
- jenkins/jnlp-slave:3.27-1
- kubesphere/builder-maven:v3.1.0
PS:注意老师演示的需要联网的,用maven打包需要去下载依赖,由于我是无网环境,所以这个没办法了,maven命令会卡在下载依赖的部分
http://maven.aliyun.com/nexus/content/groups/public/org/springframework/boot/spring-boot-starter-parent/2.2.1.RELEASE/spring-boot-starter-parent-2.2.1.RELEASE.pom -
-
https://www.processon.com/view/link/6143043af346fb45e3e2fe38#map
7. KubeKey
-
KubeKey介绍
-
k8s的部署方式:
-
官方推荐的方式:kubeadm、kops、Kubespray
-
第三方:KubeKey
-
-
KubeKey
- 由 go 语言开发,是一种全新的安装工具。提供灵活的安装选择,例如集群大小上可以选择:
- all-in-one 集群
- 高可用集群
- 安装结果上可以选择
- 仅安装 k8s/k3s
- 同时安装 k8s/k3s 和 kubesphere
- 由 go 语言开发,是一种全新的安装工具。提供灵活的安装选择,例如集群大小上可以选择:
-
为什么选择 KubeKey
- Go 语言开发,运行速度快,不用提前准备和配置安装工具的环境
- 支持多种安装选项
- 自动化多节点并行安装,提高安装效率
- 使用方式简单
- 代码可扩展性强,方便二次开发
-
使用方式:参考对应的文档就行,使用
./kk进行管理
-
-
部署高可用 Kubernetes 集群
-
集群部署概览
![在这里插入图片描述]()
-
External loadbalancer
![在这里插入图片描述]()
-
Internal loadbalancer
![在这里插入图片描述]()
-
使用 KubeKey 部署高可用集群
![在这里插入图片描述]()
-
-
KubeKey 集群配置文件详解
-
hosts:节点 node 相关的配置-
name:给机器命名 -
address:外部访问的地址 -
internalAddress:局域网机器互相连接的地址 -
user:需要sudo权限的用户 -
password:对应的密码
-
-
network 基本用默认的就行,calico好使的很
-
./kk create config --with-kubesphere v3.2.0 -f config.yaml
-
-
Kubernetes 增删集群节点
- 增
- 修改
config.yaml文件 - 执行
./kk add nodes -f config.yaml
- 修改
- 删:
./kk delete node node3 -f config.yaml
- 增
-
Kubernetes 集群证书管理
- 查看命令:
./kk certs -h - 查看证书:
./kk certs check-expiration -f config.yaml - 更新集群证书
- 集群证书位置:
/etc/kubernetes/pki/ - 更新证书:
./kk certs renew -f config.yaml
- 集群证书位置:
- 查看命令:
-
KubeSphere 启动可插拔组件
参考:https://kubesphere.io/zh/docs/v3.3/pluggable-components/app-store/
在界面上修改配置文件
ClusterConfiguration-ks-installer,将需要使用的组件打开,更新之后会自动开始下载。然后执行以下命令查看安装进展:kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f -
⭐ Kubernetes 节点管理
参考:https://kubesphere.io/zh/docs/v3.3/cluster-administration/nodes/
-
通过节点管理-更多操作-编辑标签,可以增加标签,比如
kubernetes.io/gpu-node设置为 1,在将来创建工作负载的时候添加对应的标签,可以实现需要gpu环境运行的pod会自动调度到该标签的机器上![在这里插入图片描述]()
-
增加污点
指定某些服务器做 复杂逻辑,这些服务器设置污点,打上 不允许调度 等污点,因此该服务器就 不会/尽量不 被调度
-

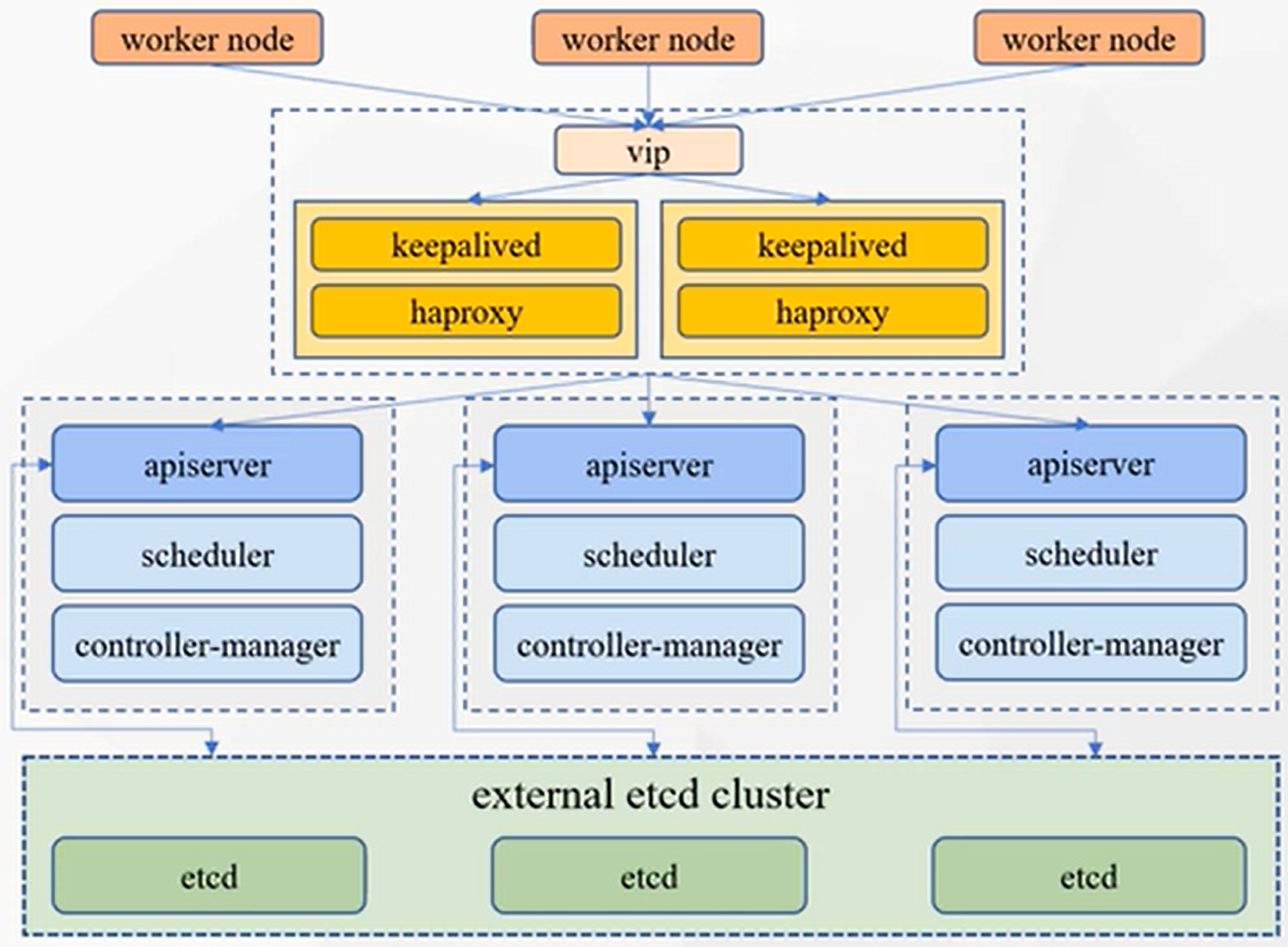
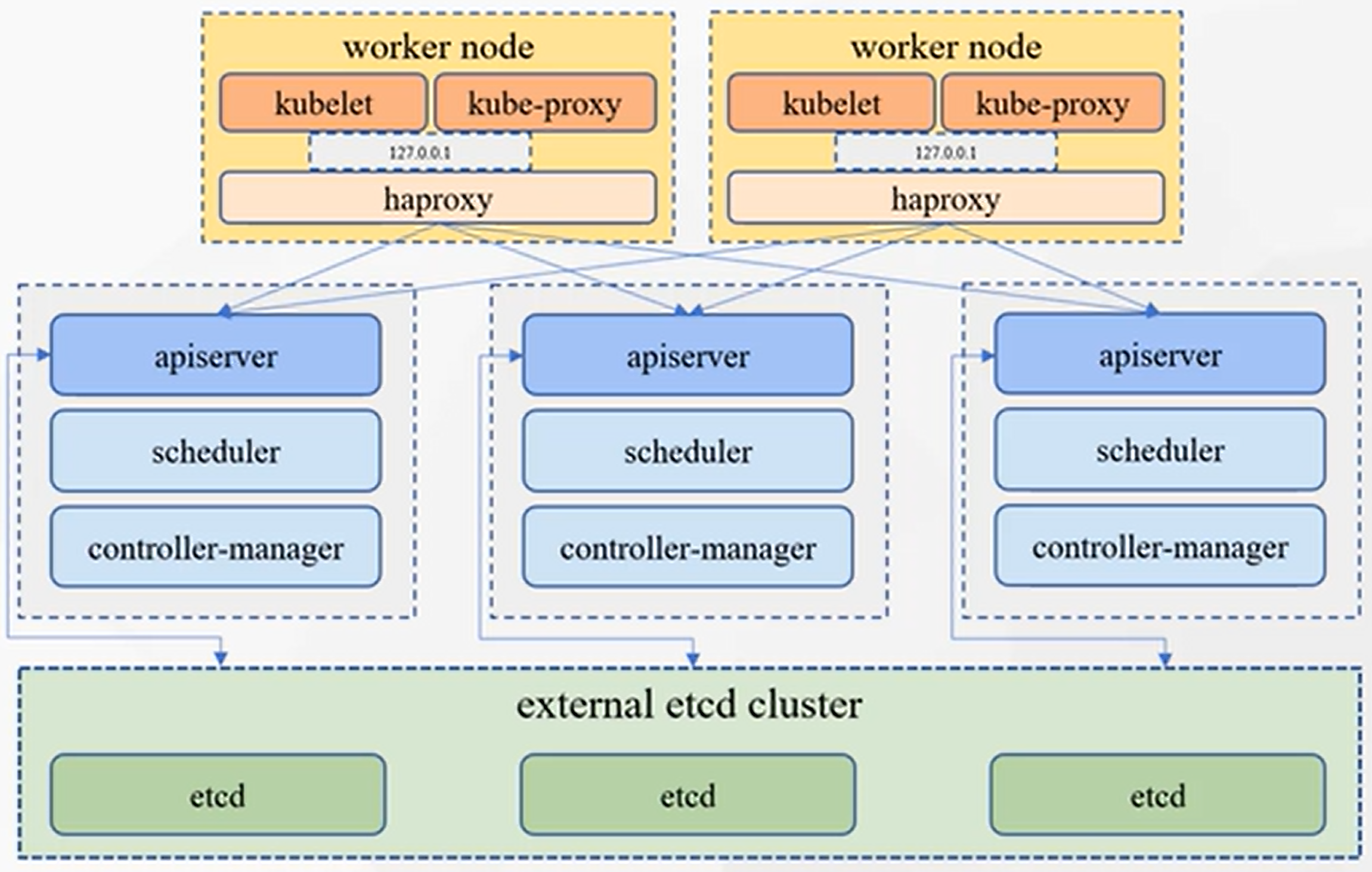
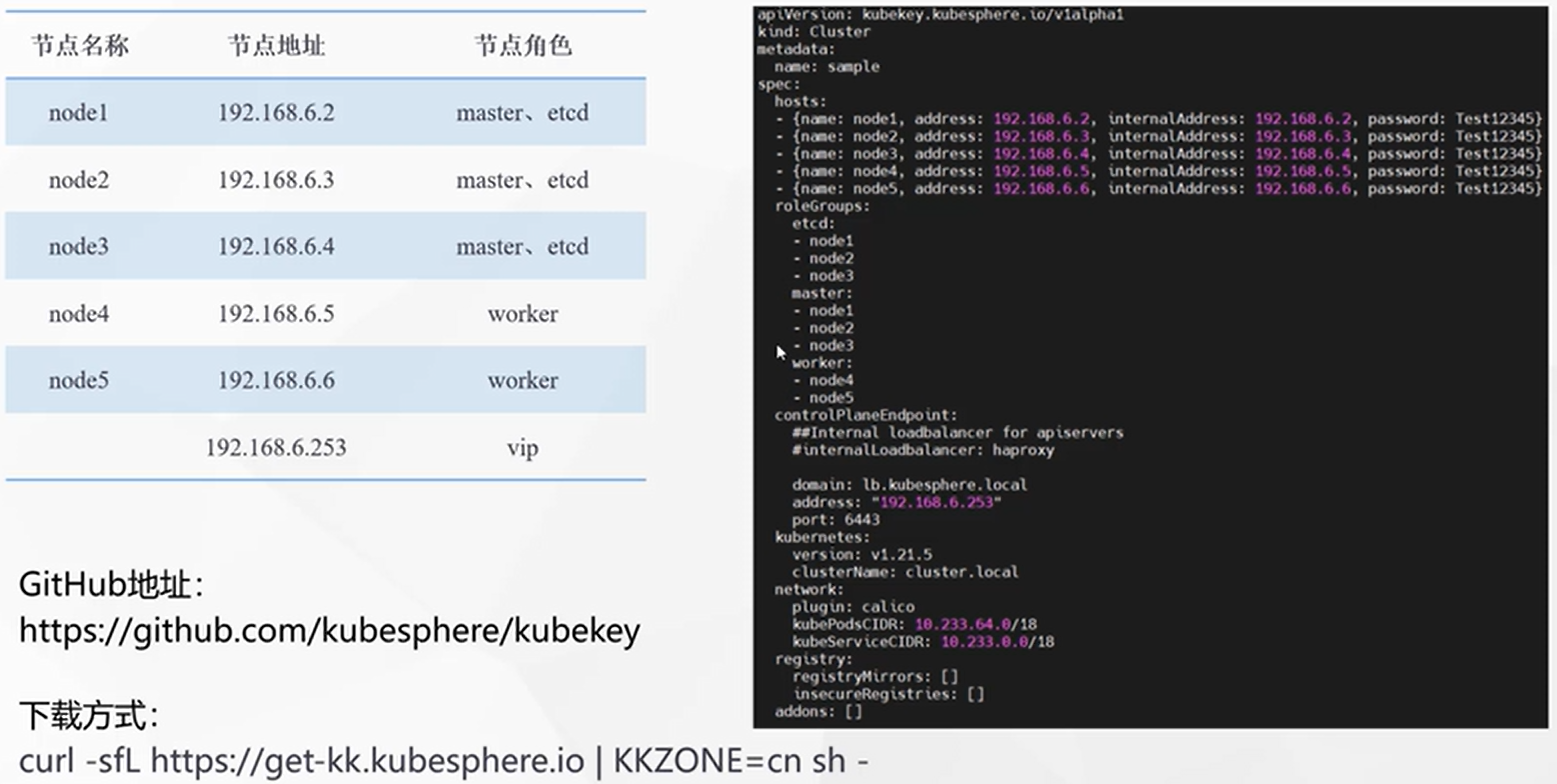
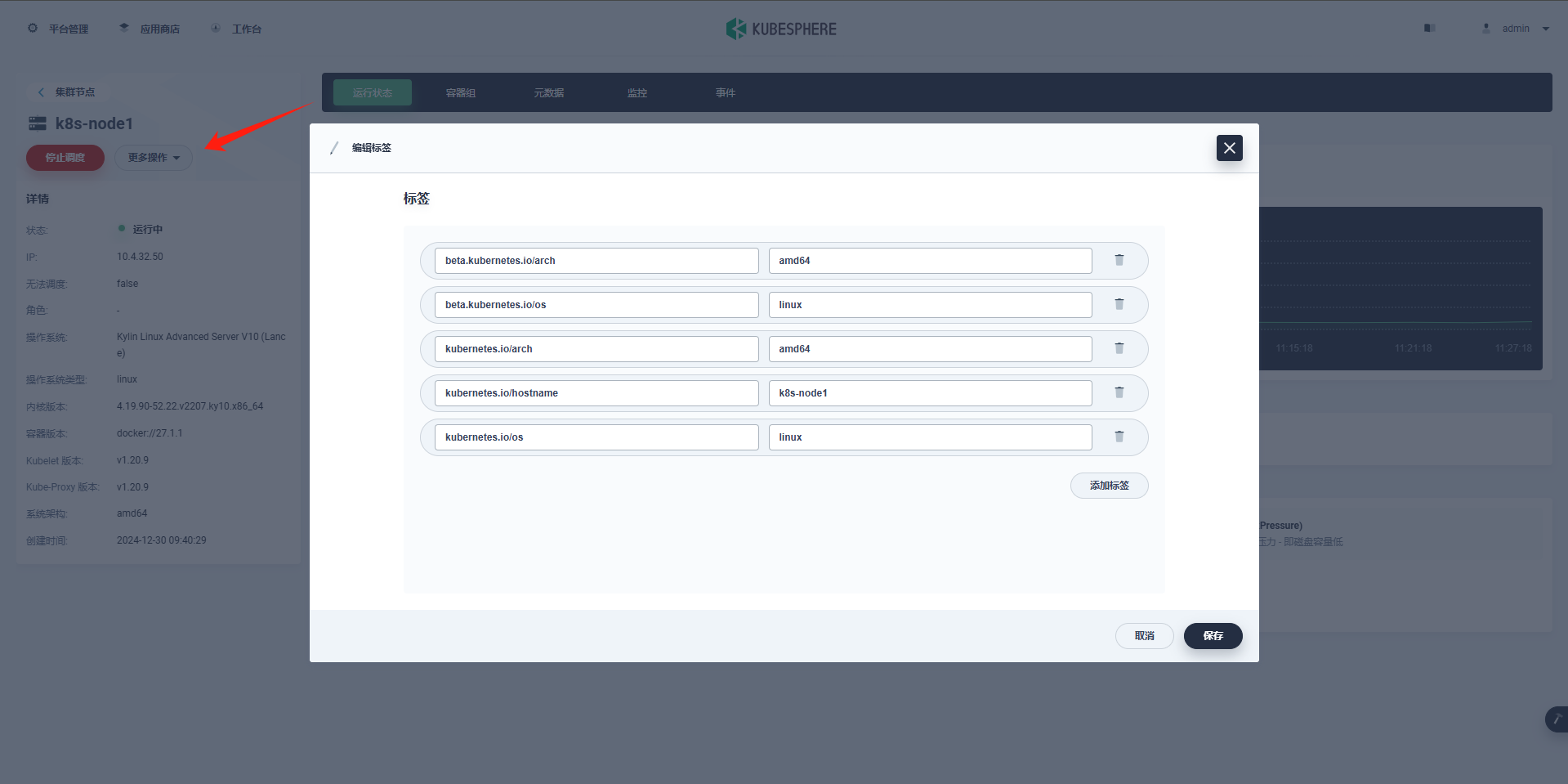
8. DevOps
-
git基础
- git特性:几乎所有操作都是本地执行;直接记录快照,而非差异比较;时刻保持数据完整性
- 默认会记录已修改的状态,状态为:已修改 modified
git add:把文件提交到暂存区,状态为 已暂存 stagedgit commit:把保存在暂存区的文件快照永久转储到 git 目录中,状态为:已提交 committed
-
![在这里插入图片描述]()
-
![在这里插入图片描述]()
-
DevOps 自动测试构建
-
DevOps 自动部署
-
Source-to-Image (S2I) 是一个工具箱和工作流,用于从源代码构建可再现容器镜像。S2I 通过将源代码注入容器镜像,自动将编译后的代码打包成镜像。KubeSphere 集成 S2I 来自动构建镜像,并且无需任何 Dockerfile 即可发布到 Kubernetes。
![构建流程]()
-
Binary-to-Image (B2I) 是一个工具箱和工作流,用于从二进制可执行文件(例如 Jar、War 和二进制包)构建可再现容器镜像。更确切地说,您可以上传一个制品并指定一个目标仓库,例如 Docker Hub 或者 Harbor,用于推送镜像。如果一切运行成功,会推送您的镜像至目标仓库,并且如果您在工作流中创建服务 (Service),也会自动部署应用程序至 Kubernetes。
-
![流水线概览]()
[!info] 备注
- 阶段 1:Checkout SCM:从 GitHub 仓库检出源代码。
- 阶段 2:单元测试:待该测试通过后才会进行下一阶段。
- 阶段 3:SonarQube 分析:SonarQube 代码质量分析。
- 阶段 4:构建并推送快照镜像:根据策略设置中选定的分支来构建镜像,并将
SNAPSHOT-$BRANCH_NAME-$BUILD_NUMBER标签推送至 Docker Hub,其中$BUILD_NUMBER为流水线活动列表中的运行序号。 - 阶段 5:推送最新镜像:将 SonarQube 分支标记为
latest,并推送至 Docker Hub。 - 阶段 6:部署至开发环境:将 SonarQube 分支部署到开发环境,此阶段需要审核。
- 阶段 7:带标签推送:生成标签并发布到 GitHub,该标签会推送到 Docker Hub。
- 阶段 8:部署至生产环境:将已发布的标签部署到生产环境。
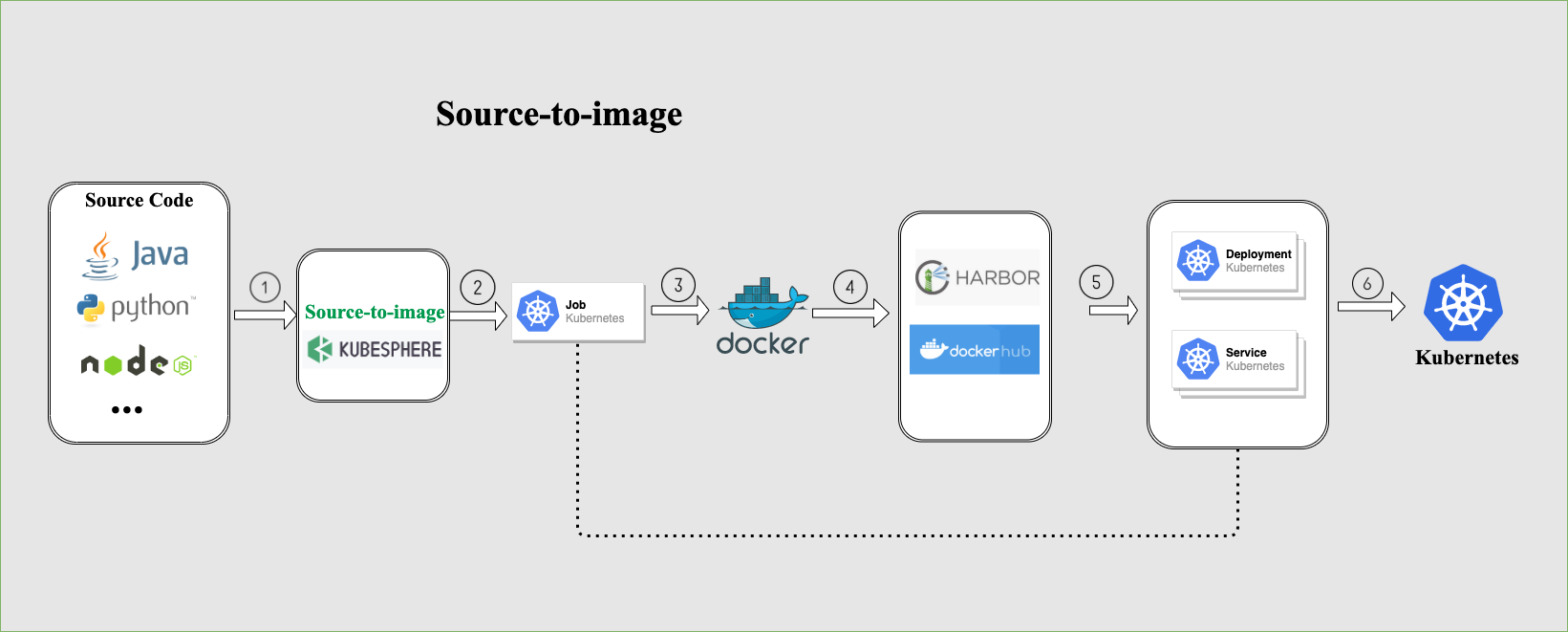
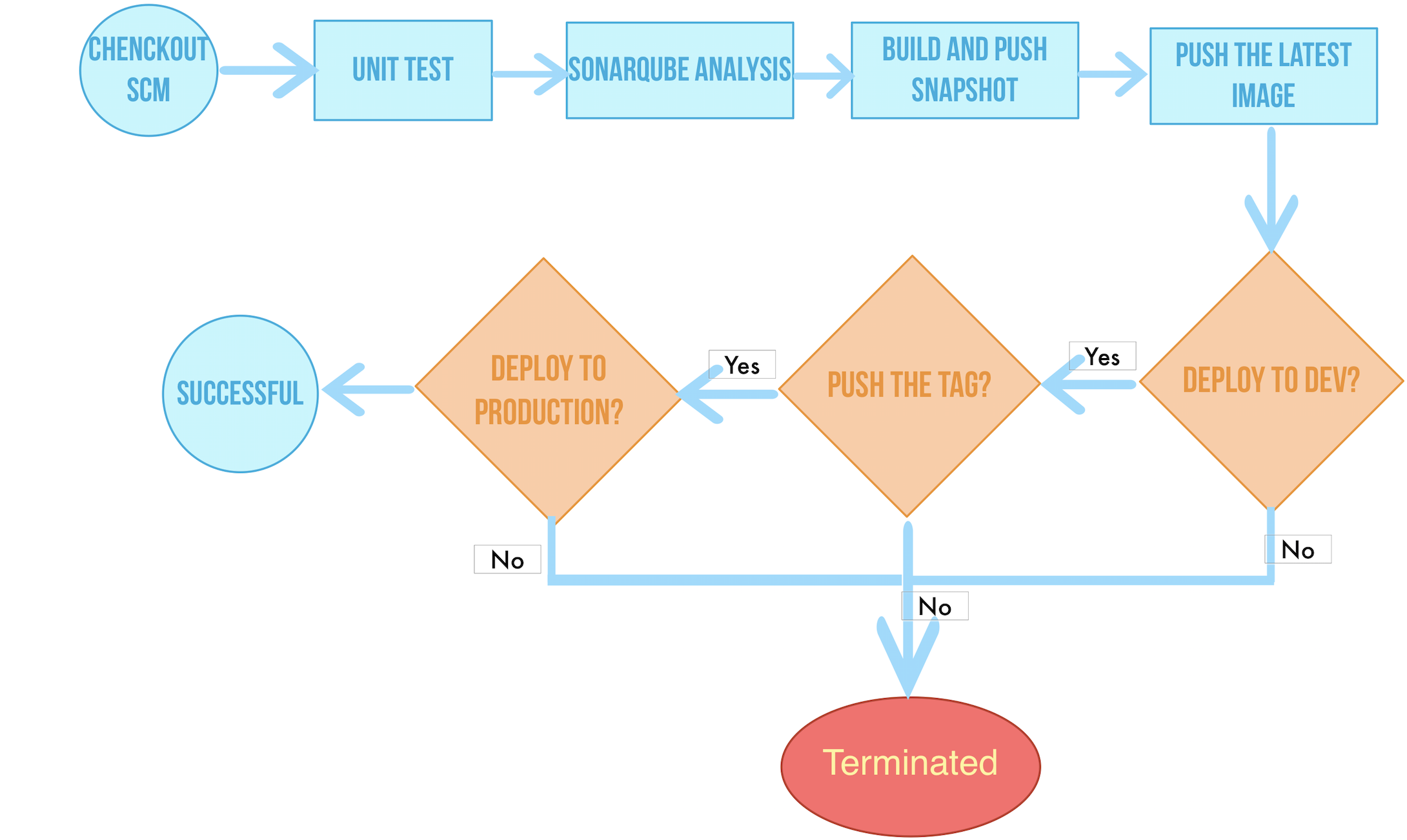
9. KubeSphere的备份与恢复
目的:备份源环境的多节点ks集群A,在目标环境上恢复
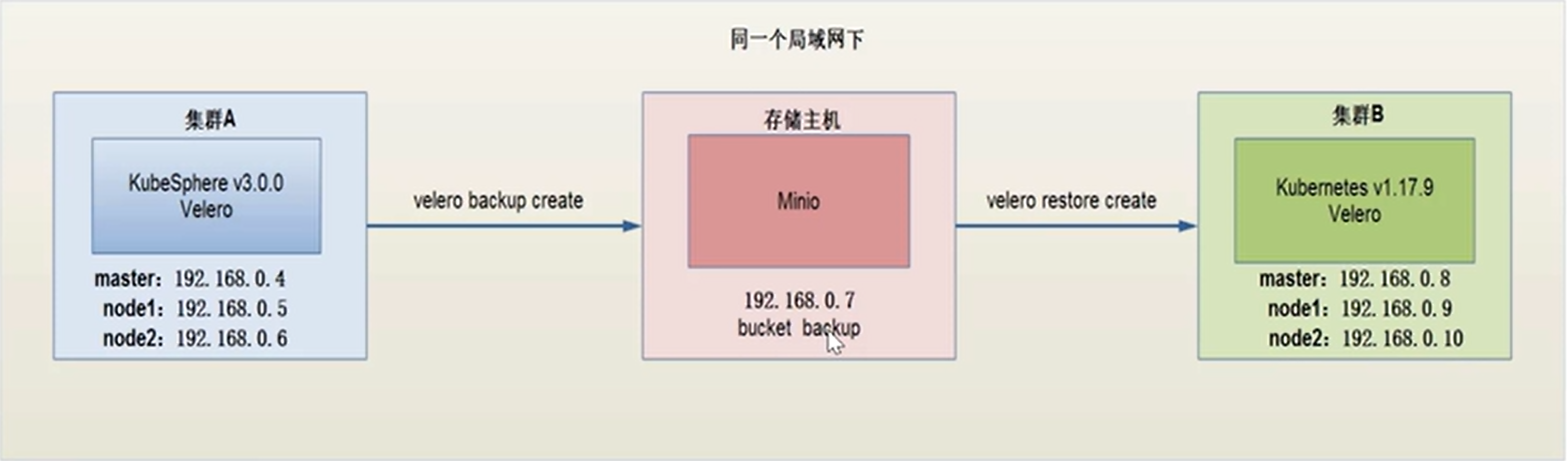
Velero备份原理图
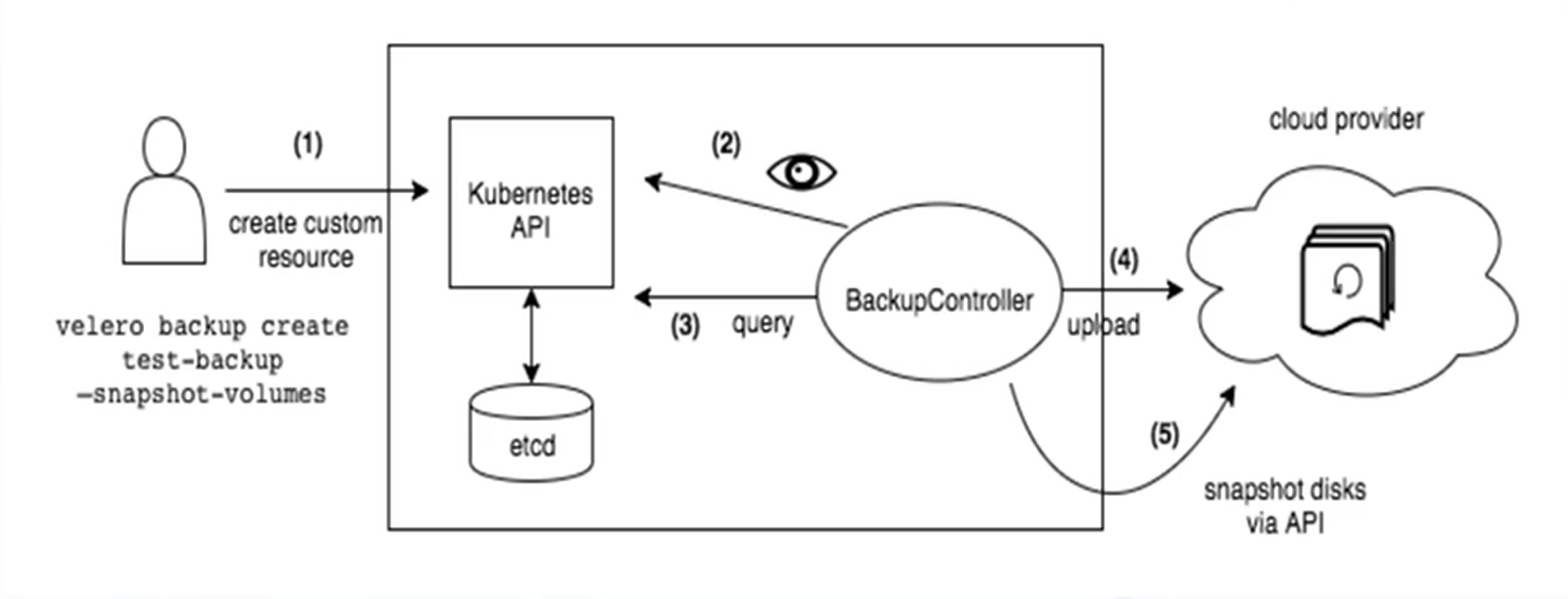
- Velero 提供了备份和恢复 Kubernetes 集群资源和持久卷的工具,可以在云上或本地运行。Velero 可对集群进行备份与恢复,以防数据丢失;也可将集群资源迁移到其他集群,如将生产集群复制到备份集群。
- Restic 是 Velero 的开源备份组件,用于备份和恢复 Kubernetes 卷,备份前,卷必须被注释。备份 pv 数据时,不支持卷类型为 hostpath。
velero-plugin-for-aws:v1.1.0是阿里云插件,后端主要支持兼容 S3 的存储。- Velero 支持两种关于后端存储的 CRD,分别是 BackupStorageLocation 和 VolumeSnapshotLocation。
- BackupStorageLocation 主要用来定义 Kubernetes 集群资源的数据存放位置,即集群对象数据,不是 PVC 的数据。后端存储主要支持兼容 S3 的存储,比如 Minio 等。
- VolumeSnapshotLocation 主要用来给 PV 做快照,需要云厂商提供插件,还需要使用 CSI 等存储机制。这里我们使用专门的备份工具 Restic,把 PV 数据备份到 minio。
10. Kubernetes集群重启与恢复
-
Master节点启停
为了确保重启 Master 节点期间 Kubernetes 集群能够使用,集群中 Master 节点数量要大于等于 3。包含要停的master
- 登录 KubeSphere
- 备份数据
- 停止 Master 节点调度
- 驱逐 Master 节点上的工作负载
- 停止 Master 节点
- 恢复 Master 节点
- 允许 Master 节点调度
-
Work节点启停
在实际工作中,可能某个 Worker 节点需要维护、迁移,我们需要平滑的停止、启动该节点,尽量减少启停中对集群、业务造成的影响。摘除 Worker 节点操作中,该 Worker 节点上的工作负载将被驱逐到其他节点上,请确保集群资源充足。
- 登录 KubeSphere
- 停止 Worker 节点调度
- 驱逐 Worker 节点上的工作负载
- 停止 Docker、Kubelet 等服务
- 恢复 Worker 节点
- 允许 Worker 节点调度
-
集群启停
在实际工作中,计划内的机房断电、断网等特殊情况可能发生,在此之前我们需要平滑地停止Kubernetes 集群,在环境恢复正常后再平滑地启动集群,从而避免集群出现异常。
- 登录 Kubernetes 控制节点
- 备份数据
- 停止所有节点
- 恢复所有节点
- 检查集群状态
- 常见问题排查
- etcd 集群启动失败
- 部分节点加入集群失败
- 部分 pod 不断重启
-
在 ks 上调试应用
在实际工作中,您部署的应用会发生一些问题,我们可以通过工具查看日志,分析事件来进行排查。
- 登录Kubesphere 容器平台
- 创建一个部署,并增加健康检查
- 创建一个服务并绑定容器,nodeport 外网访问方式
- 模拟故障
- 使用工具箱查看日志、调度情况和事件
-
ks 应用调度
在实际环境中,不同的服务会对资源有不同的要求,根据实际需求,我们需要将这些应用部署到特定的服务器,从而提升服务性能和服务器资源使用率。
-
nodeSelector定向调度
nodeSelector是节点选择约束的最简单推荐形式。nodeSelector是PodSpec的一个字段。通过设置label相关策略将pod关联到对应label的节点上。
-
nodeName定向调度
nodeName是节点选择约束的最简单方法,但是由于其自身限制,通常不使用它。nodeName 是 PodSpec 的一个字段。如果指定nodeName,调度器将优先在指定的 node 上运行 pod。
-
nodeAffinity定向调度
nodeAffinity 类似于 nodeSelector,使用 nodeAffinity 可以根据节点的 labels 限制 Pod 能够调度到哪些节点,当前 nodeAffinity 有软亲和性和硬亲和性两种类型,节点亲和性与 nodeSelector 相比,亲和/反亲和功能极大地扩展了可以表达约束的类型。增强了如下能力:
- 语言更具表现力
- 在调度器无法满足要求时,仍然调度该 pod
软亲和性:设置权重,当没有节点满足要求时,会部署到其他节点上。
-
11. Helm
-
Helm及应用仓库简介
-
Helm是Kuberetes的包管理器
- 类似于Ubuntu的apt-get、Centos的yum,用于管理Charts
- Helm Chart是用来封装Kubernetes应用程序的一系列YAML文件
-
安装Helm:https://github.com/helm/helm
直接在release中下载对应操作系统的文件
- 进入解压后的文件夹:
cd linux-amd64 - 复制到
mv helm /usr/local/bin - 查看一下是否成功:
helm、helm list
- 进入解压后的文件夹:
-
应用仓库:管理和分发Helm Charts
-
安装Harbor
-
helm repo add harbor https://helm.goharbor.io -
helm fetch harbor/harbor,然后在当前路径可以看到一个压缩文件,比如harbor-1.17.0.tgz -
解压文件:
tar xf harbor-1.17.0.tgz -
进入harbor文件夹,编辑
values.yaml- 将expose的暴露方式从
ingress改为nodePort - 将 tls 的 enable 改为
false - 修改暴露的端口 nodePort 从
30002改为30882 - 将 externalURL 从
https://core.harbor.domain改为http://你的IP:30882
- 将expose的暴露方式从
-
运行
helm template .渲染模板 -
安装harbor:
cd ..、helm install my-harbor harbor -n harbor💡 这里需要有k8s集群,不然就会报错
-
helm list -n harbor:查看安装情况 -
登录harbor,默认账户密码:
admin/Harbor12345
-
-
-
如何开发一个Helm应用
helm create hello-chart:创建Chart目录chart.yaml:声明了当前 Chart 的名称、版本等基本信息values.yaml:提供应用安装时的默认参数templates/:包含应用部署所需要使用的YAML文件,比如 Deployment和Service等charts/:当前 Chart 依赖的其他 Chart
helm template hello-chart:渲染chart并输出helm install hello hello-chart/ -n default:安装 hello-charthelm package hello-chart:打包Chart- 将Chart推送到应用仓库
-
KubeSphere 应用全生命周期实践
- 开发中:开发中的
- 待发布:已开发完成,等待应用商店管理员审核通过
- 已审核通过:应用商店管理员审核通过
- 审核未通过:应用商店管理员审核未通过
- 已上架:已经上架到应用商店
- 已下架:从应用商店下架
-
KubeSphere 应用仓库管理
- 添加应用仓库
- 删除应用仓库
- 手动更新应用仓库
- 应用仓库自动同步远程仓库
-
KubeSphere 应用管理场景
- 部署hello-chart应用
- 升级hello-chart应用
- 删除hello-chart应用
12. Kubernetes多集群管理与使用
-
Kubernetes Federation 介绍
-
最早的多集群项目,由K8s社区提出和维护。Federation v1在K8s v1.3左右就已经着手设计(Design Proposal),并在后面几个版本中发布了相关的组件与命令行工具(kubefed),用于帮助使用者快速建立联邦集群,并在1.6时,进入了 Beta 阶段;但 Federation v1 在进入Beta后,就没有更进一步的发展,由于灵活性和API成熟度的问题,在K8s v1.11 左右正式被弃用。
-
在 v1 版本中我们要创建一个联邦资源的大致步骤如下:把联邦的所有配置信息都写到资源对象 annotations 里,整个创建流程与K8s类似,将资源创建到 Federation API Server,之后 Federation Controller Manager 会根据 annotations 里面的配置将该资源创建到各子集群。
-
有了 v1 版本的经验和教训之后,社区提出了新的集群联邦架构:Federation v2。
v2 版本利用 CRD 实现了整体功能,通过定义多种自定义资源(CR),从而省掉了 v1 中的 API Server;
v2 版本由两个组件构成:
- admission-webhook 提供了准入控制
- controller-manager 处理自定义资源以及协调不同集群间的状态
-
在逻辑上,Federation v2 分为两个大部分:confguration(配置)和propagation(分发)
-
configuration 主要包含两个配置:Cluster Confguration 和 Type Configuration。
-
如果想新增一种要被联邦托管的资源的话,就需要建立一个新的FederatedXX的CRD,用来描述对应资源的结构和分发策路(需要被分发到哪些集群上);Federated Resource CRD主要包括三部分:
- Templates 用于描述被联邦的资源
- Placement 用来描述将被部署的集群,若没有配置,则不会分发到任何集群中
- Overrides 允许对部分集群的部分资源进行覆写
-
-
KubeSphere 多集群介绍
-
Kubernetes 从 1.8 版本起就声称单集群最多可支持 5000 个节点和 15 万个 Pod,实际上应该很少有公司会部署如此庞大的一个单集群,很多情况下因为各种各样的原因我们可能会部署多个集群,但是又想将它们统一起来管理,这时候就需要用到集群联邦(Federation)。
-
集群联邦的一些典型应用场景:
- 高可用:在多个集群上部署应用,可以最大限度地减少集群故障带来的影响
- 避免厂商锁定:可以将应用负载分布在多个厂商的集群上并在有需要时直接迁移到其它厂商
- 故障隔离:拥有多个小集群可能比单个大集群更利于故障隔离
-
图片里面定义了两个概念,Host 集群指的是装了 kubefed 的集群,属于 ControlPlane,Member 集群指的是被管控集群,Host集群与 Member 集群之间属于联邦关系
![在这里插入图片描述]()
-
在导入集群的时候 KubeSphere 提供了两种方式:
- 第一种是直接连接。这种情况要求 Host 到 Member 集群网络可达,只需要提供一个 kubeconfg 文件可直接把集群加入进来。
- 第二种是代理连接。对于 Host 集群到 Member 集群网络不可达的情况,目前 kubefed 还没有办法做到联邦。因此 KubeSphere 开源了Tower 组件,实现了私有云场景下集群联邦管理,用户只需要在私有集群创建一个 agent 就可以实现集群联邦。
-
Tower 的工作流程:在 Member 集群内部起了一个 agent 以后,Member 集群会去连接 Host 集群的 Tower Server,Server收到这个连接请求后会直接监听一个 Controller 预先分配好的端口建立一个隧道,这样就可以通过这个隧道从 Host 往 Member 集群分发资源。
-
-
Kubernetes 跨多集群的应用发布
- 在 KubeSphere 中企业空间是最小的租户单元,企业空间提供了跨集群、跨项目(即 Kubernetes 中的命名空间)共享资源的能力。企业空间中的成员可以在授权集群中创建项目,并通过邀请授权的方式参与项目协同。
- 用户是 KubeSphere 的帐户实例,可以被设置为平台层面的管理员参与集群的管理,也可以被添加到企业空间中参与项目协同。
- 多级的权限控制和资源配额限制是 KubeSphere 中资源隔离的基础,奠定了多租户最基本的形态
-
微服务
-
spring-cloud-kubernetes 基础概念
spring-cloud-kubernetes 是 Spring Cloud 社区为 K8s 环境,提供的开箱即用的服务发现、配置分发的方案。该项目实现了的 Spring Cloud 中几个核心的接口,允许开发者在 Kubernetes 上构建和运行 SpringCloud 应用。
-
在 KubeSphere 上部署 Spring Cloud 全家桶
spring-cloud-kubernetes 简化了 K8s 环境下 spring-cloud 应用的组件依赖,提供了开箱即用的服务发现和配置管理能力,为 java 微服务应用提供了良好的基础。在 spring-cloud-bookinfo 这个示例中,我们充分的利用了 spring cloud 和 K8s 的能力,SpringCloud 和 K8s 并不是处在对立面,我们需要各取所长。
-
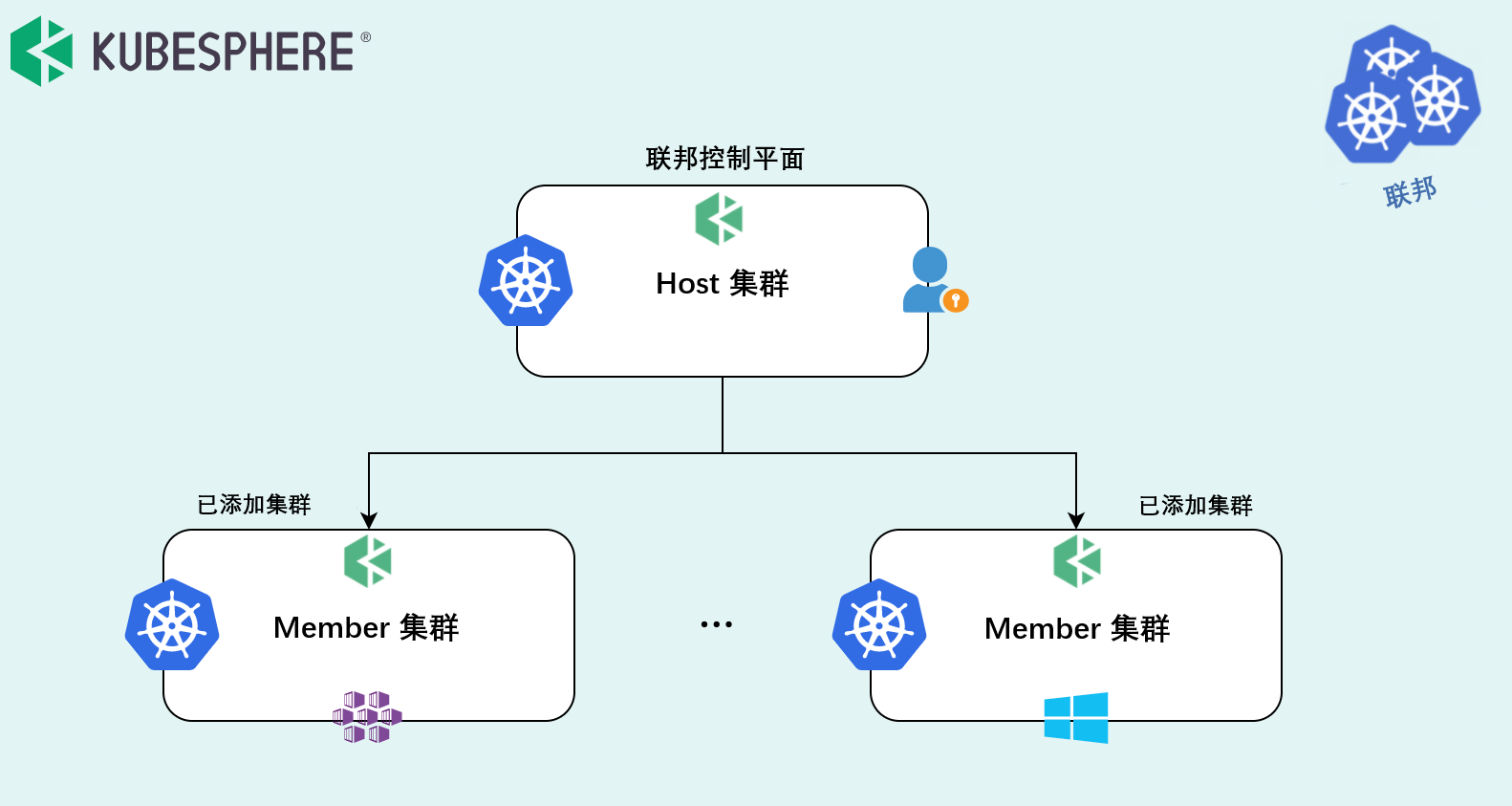
13. Service Mesh
-
微服务概念回顾
-
微服务,又叫微服务架构,是一种软件架构方式。它将应用构建成一系列按业务领域划分模块的、小的自治服务。
![在这里插入图片描述]()
-
微服务的特点:
- 高度可维护和可测试性
- 松耦合
- 独立部署
- 围绕业务能力进行组织
-
-
传统微服务框架的挑战
-
传统微服务框架:SpringCloud、Dubbo、Tars、其他
![在这里插入图片描述]()
-
不足
- 过于绑定特定技术栈
- 多语言支持受限
- 代码侵入度过高
- 老旧系统维护难
-
-
Service Mesh 概念与架构
- sideCar从本质上讲就是网络代理,把业务的流入流出的网络请求进行拦截处理再转发,实现了对业务逻辑的零入侵,并且实现了开发语言和技术栈的解耦,实现了完全的隔离,实现了基础设施和业务逻辑的解耦。
- 服务网格是用于处理服务间通信的专用基础设施层,它负责通过包含现代云原生应用程序的复杂服务拓扑来传递请求。实际上,服务网格通常通过一组轻量级网络代理来实现,这些代理与应用程序代码一起部署,而不需要感知应用程序本身。
![在这里插入图片描述]()
-
Istio 简介
![在这里插入图片描述]()
-
特性
- 流量管理
- 可观测性
- 安全性能
-
Istio 安装
-
Bookinfo 演示
-
Istio 核心概念解读
- 虚拟服务
- 目标规则
- 网关
- 服务入口
- Sidecar
-
虚拟服务和目标规则使用 + 启用服务治理
-
通过编辑 kubeshpere-system下的 cluster config 来启动service mesh 功能:
kubectl -n kubesphere-system edit cc ks-installer,设置 istio 为 enable 就行,然后保存::wq。(不过我安装ks的时候,已经安装了嘿嘿)![在这里插入图片描述]()
-
在一个项目中设置网关(我这里在高级设置里面,而不是网关设置)
![在这里插入图片描述]()
-
后面创建应用布拉布拉,救命,很难懂诶~ 😢
总之这样创建的应用,容器被自动注入了探针 istio-proxy
![在这里插入图片描述]()
-
😢 一顿操作之后,还是没法在自制应用中访问,哎。。。给服务开了NodePort就能通过ip+端口访问,不太理解。。。
💡 这个问题,我解决了,人麻了。。。
出现问题的第一时间还是去看看有没出问题的pod,不光光看该项目的namespace下的pod,比如
kubesphere-controls-system里面就有一个报错了,一看发现是拉不到镜像:kubesphere/nginx-ingress-controller:v0.35.0 -
弄好咯 🎉
![在这里插入图片描述]()
-
-
-
灰度发布
策略有三种:蓝绿部署、金丝雀发布、流量镜像
金丝雀确实帅 😮
14. Kubernetes集群与应用日志
-
生产部署最佳实践
-
日志系统介绍
KubeSphere 为口志收集、査询和管理提供了一个强大的、全面的、易于使用的日志系统。它涵盖了不同层级的日志,包括租户、基础设施资源和应用。用户可以从项目、工作负载、容器组和关键字等不同维度对日志进行搜索。与 Kibana 相比,KubeSphere基于租户的日志系统中,每个租户只能查看自己的日志,从而可以在租户之间提供更好的隔离性和安全性。除了 KubeSphere 自身的日志系统,该容器平台还允许用户添加第三方日志收集器,如Elasticsearch、Kafka 和Fluentd。日志收集路径如下:
![在这里插入图片描述]()
-
日志安装
在
自定义资源 CRD-ClusterConfiguration配置中找到logging,启用设置为true即可启用日志组件-
单节点启用日志组件
-
单节点containerd环境启用日志组件
需要增加额外的配置,在
enabled同级增加一个字段containerruntime: containerd![在这里插入图片描述]()
-
多节点启用日志组件
-
-
Fluent Bit 是一个开源的日志处理器和转发器,它允许您从不同的来源收集任何数据,如指标和日志,用于过滤器过滤它们,并将他们发送到多个目的地。
- 轻量
- 高性能
- 插件丰富
-
-
日志检索与日志落盘
![在这里插入图片描述]()
落盘日志的收集:
-
以 project-admin 的身份登录 kubesphere 的 web 控制台,进入项目。
-
在左侧导航栏中,选择项目设置的日志收集,点击 已启用 以启用该功能。
![在这里插入图片描述]()
-
在左侧导航栏中,选择应用负载中的工作负载。在部署选项卡下,点击创建。
-
在出现的对话框中,设置部署的名称,再点击下一步。
-
在容器组设置下,点击添加容器。
-
在搜索栏中输入alpine,以该镜像为示例。
-
向下滚动并勾选启动命令。在运行命令和参数中分别输入以下值,点击√,然后点击下一步。
运行命令: /bin/bash 参数: -c,if [! -d/data/log];then mkdir -p /data/log;fi; while true; do data >> /data/log/app-test.log; sleep 30; done -
在存储卷设置选项下,切换启用收集存储卷上的日志,点击挂载存储卷。
![在这里插入图片描述]()
-
在临时存储卷选项卡下,输入存储卷名称,并设置访问模式和路径,点击√,然后点击下一步继续。
![在这里插入图片描述]()
-
点击高级设置中的创建以完成创建。
💡 这样可以直接让k8s接管日志,太好用啦
![在这里插入图片描述]()
[!warning] 注意镜像
没错,果然我没有镜像,elastic/filebeat:6.7.0,手动操作一下就OK了
-
-
- 如何将日志存储改为外部 Elasticsearch 并关闭内部 Elasticsearch
- 如何在启用 X-Pack Security 的情况下将日志存储改为 Elasticsearch
- 如何修改日志数据保留期限
- 无法使用工具箱找到某些节点上工作负载的日志
- 工具箱中的日志查询页面在加载时卡住
- 工具箱显示今天没有日志记录
- 在工具箱中查看日志时,报告内部服务器错误
- 如何让 KubeSphere 只收集指定工作负载的日志
- 在查看容器实时日志的时候,控制台上看到的实时日志要比 kubectl log -f xxx 看到的少

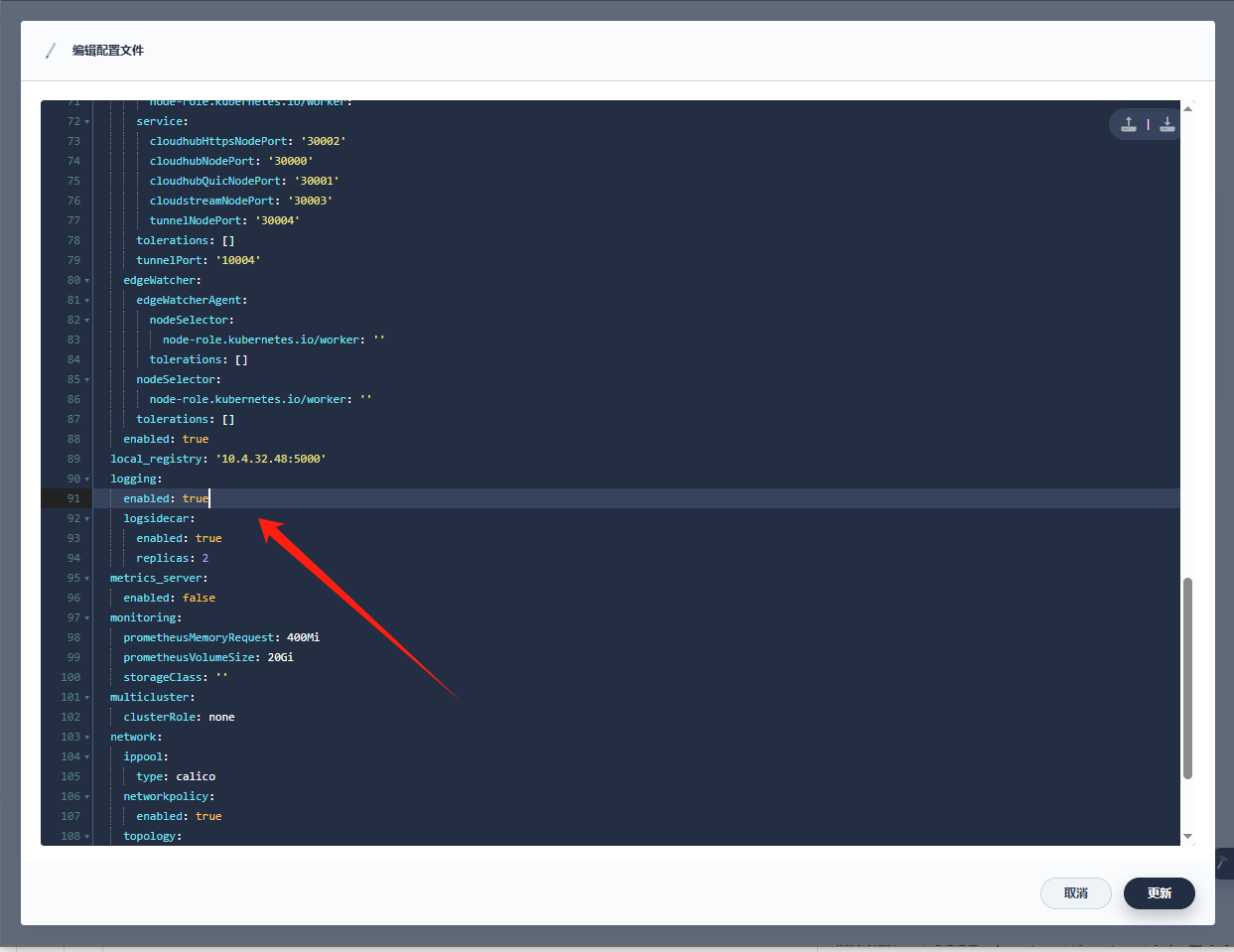
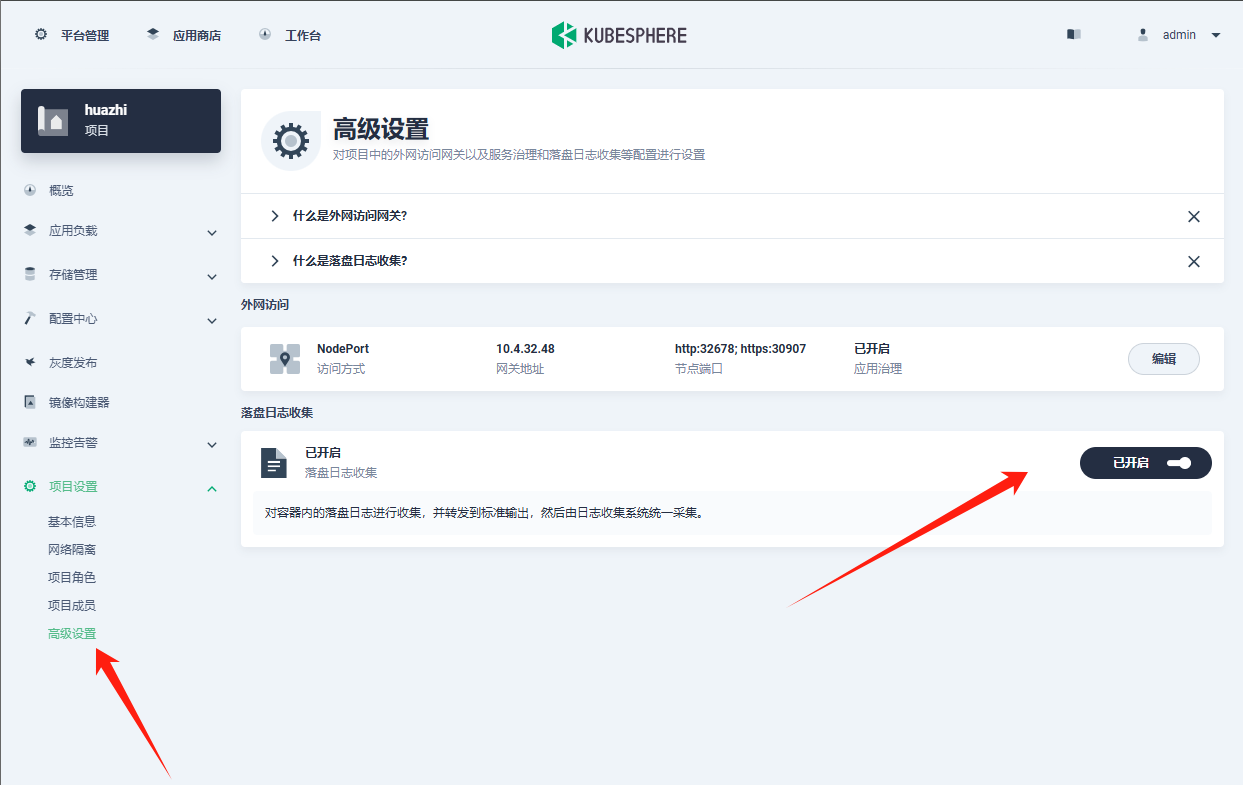
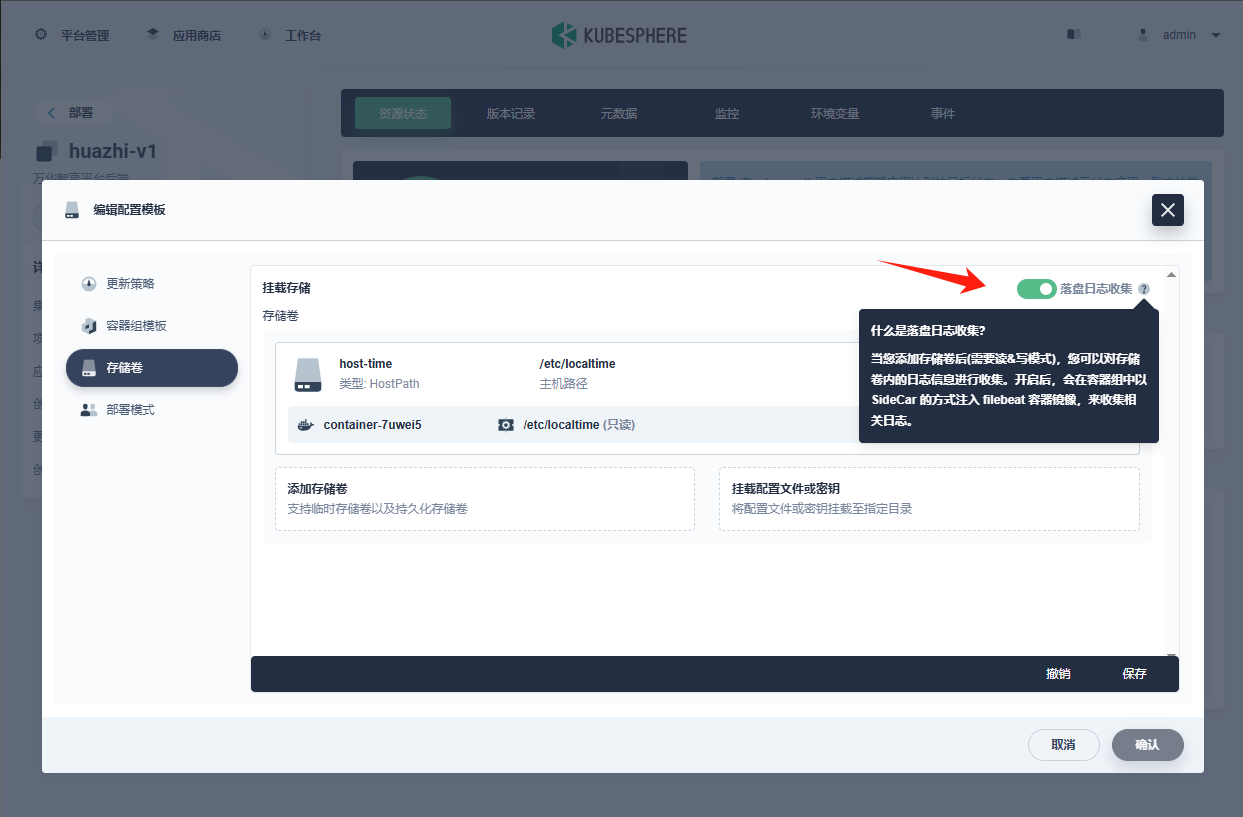
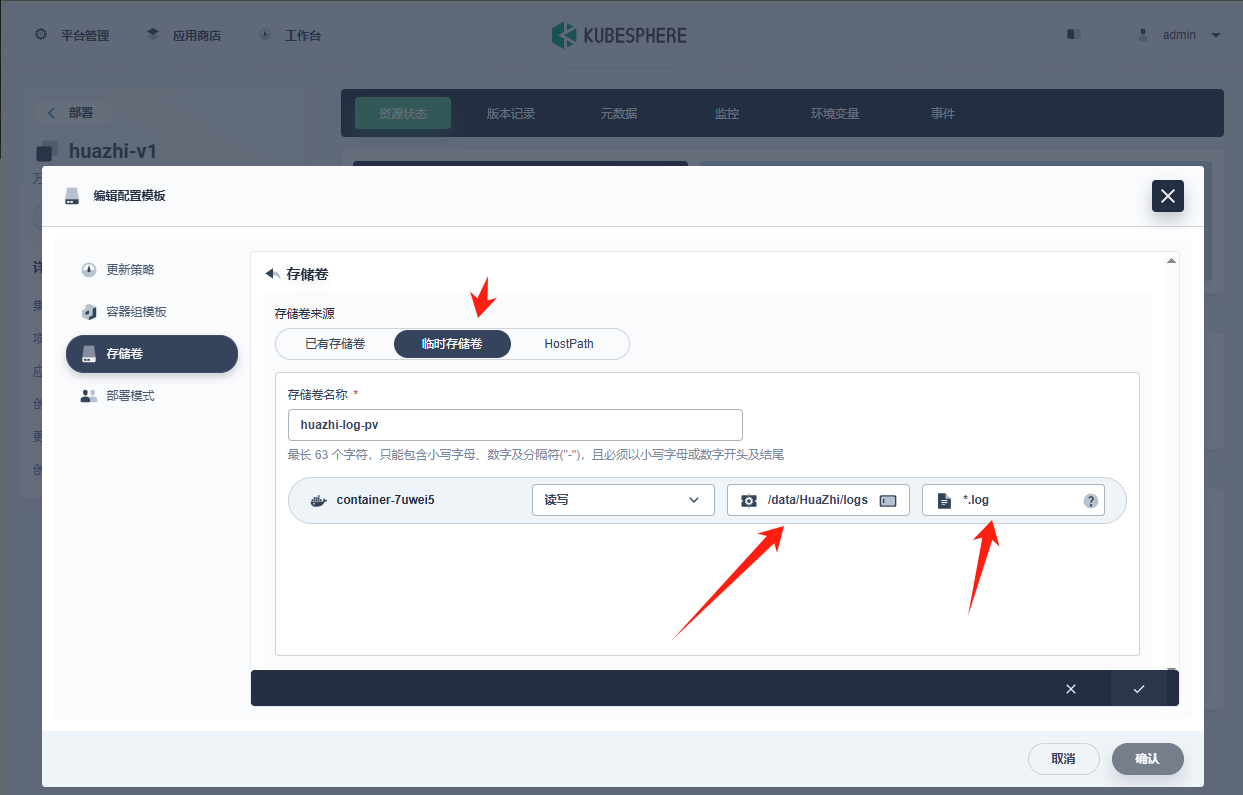
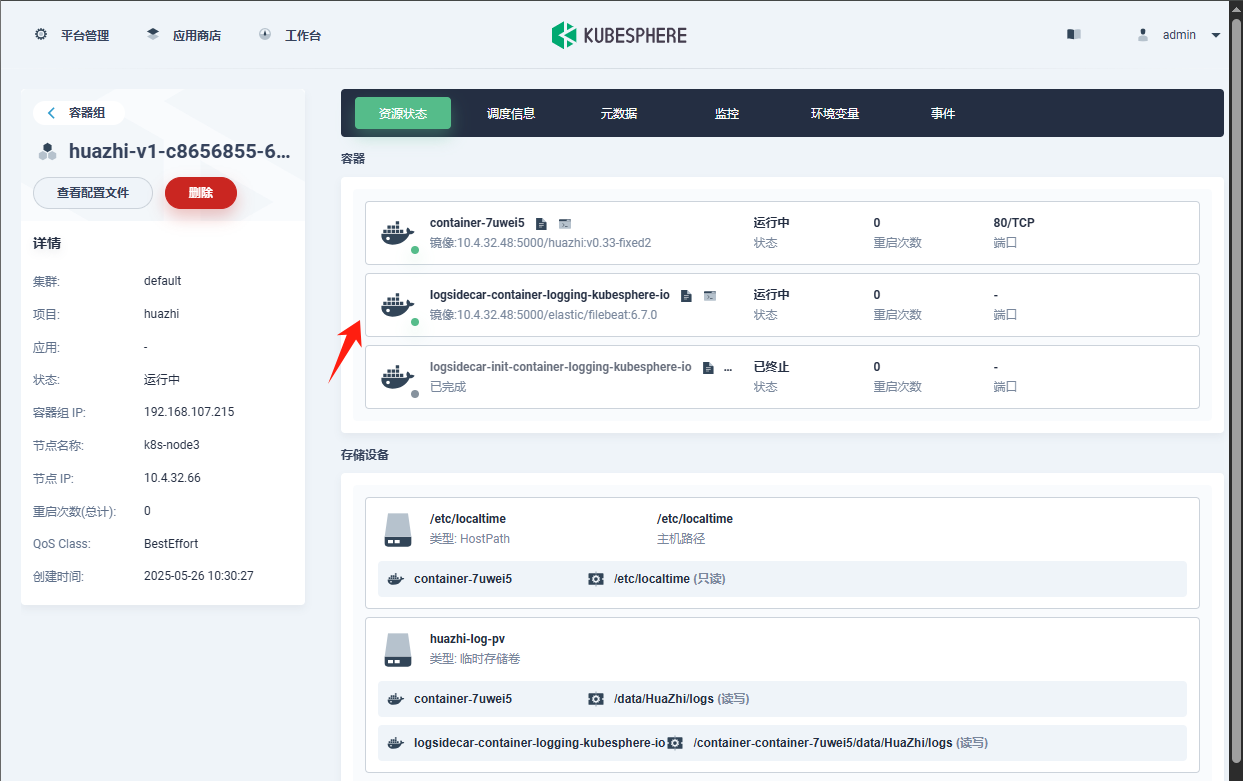
15. 监控与告警
-
Prometheus 安装使用
![在这里插入图片描述]()
-
配置包含:全局配置、规则、监控目标
prometheus.yml,启动容器:docker run -d --name prometheus-test --privileged=true --net=host -v E:/11-container/prometheus-test:/etc/prometheus prom/prometheus# 全局配置 global: scrape_interval: 15s evaluation_interval: 15s external_labels: monitor: 'my-monitor' # 告警规则 # rule-files: # - 'rules/*.yml' # 监控目标 scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] -
Exporter
-
从其他软件或者系统重获取状态信息,并转换为 Prometheus metrics
-
软件本身通过 url 暴露 Prometheus 格式的 metrics
-
Node Exporter 就是一个可以干这个活的东西
-
直接从release中下载:
node_exporter-1.9.1.linux-amd64.tar.gz -
解压:
tar zxf node_exporter-1.9.1.linux-amd64.tar.gz -
进入文件夹:
cd node_exporter-1.9.1.linux-amd64 -
运行:
./node_exporter![在这里插入图片描述]()
-
-
修改 prometheus 的配置
# 全局配置 global: scrape_interval: 15s evaluation_interval: 15s external_labels: monitor: 'my-monitor' # 告警规则 # rule-files: # - 'rules/*.yml' # 监控目标 scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] - job_name: 'node' static_configs: - targets: ["10.5.32.171:9100"] -
重启容器:
docker restart prometheus-test -
查看容器是否正常重启:
docker logs -f prometheus-test -
可以成功监控到啦
![在这里插入图片描述]()
-
-
-
PromQL 介绍
-
瞬时向量(Instant vector):一组时间序列,每个时间序列包含单个样本,它们共享相同的时间戳,也就是说,表达式的返回值中只会包含该时间序列中的最新的一个样本值。
http_requests_total {__name__="http_requests_total"}- 包含所有时间序列
- 只增不减,Counter
http_requests_total{job="prometheus", code="200"} http_requests_totla{status_code=~"2.*"}=:选择与提供的字符串完全相同的标签!=:选择与提供的字符串不相同的标签=~:选择正则表达式与提供的字符串(或子字符串)相匹配的标签!~:选择正则表达式与提供的字符串(或子字符串)不匹配的标签
-
区间向量(Range vector):一组时间序列,每个时间序列包含一段时间范围内的样本数据。
http_requests_total{job="prometheus"}[5m][]定义时间选择的范围- 单位:s, m, h, d, w, y
rate(http_requests_total[5m])- 区间范围内的平均增长速率
irate(http_requests_total[5m])- 通过区间向量中最后两个样本数据来计算区间向量的增长速率
简单指标类型
Counter(计数器):只增不减。服务的请求数、已完成的任务数、错误发生的次数Guage(仪表盘):可随意变化。进程数量、内存使用率、温度、并发请求的数量
复杂指标类型
Histogram:样本的值分布在 bucket 中的数量,命名为<basename>_bucket{le="<上边界>"}Summary:服务器端直接算好了分位数,不能聚合
-
标量(Scalar):浮点型的数据值
-
字符串(String)
-
-
Prometheus 告警处理
![在这里插入图片描述]()
-
安装并运行 AlertManager,其实跟前面 node_exporter 的流程是一样的,下载,解压,进目录,运行:
alertmanager-0.28.1.linux-arm64.tar.gz -
运行:
./alertmanager --config.file=./alertmanager.yml![在这里插入图片描述]()
-
查看 alertmanager:
http://10.5.32.171:9093/默认的服务器9093端口就能看到界面啦
![在这里插入图片描述]()
-
prometheus对接alertmanager:修改prometheus的配置、添加alertmanager的配置和告警规则,然后重启
# 全局配置 global: scrape_interval: 15s evaluation_interval: 15s external_labels: monitor: "my-monitor" # 告警规则 rule_files: - "/etc/prometheus/rules/*_rules.yml" - "/etc/prometheus/rules/*_alerts.yml" # 监控目标 scrape_configs: - job_name: "prometheus" static_configs: - targets: ["localhost:9090"] - job_name: "node" static_configs: - targets: ["10.5.32.171:9100"] # 告警 alerting: alertmanagers: - static_configs: - targets: ["10.5.32.171:9093"] -
编写 prometheus 的告警规则
/etc/prometheus/rules/node_alerts.yml,根据映射的路径,需要新建rules文件夹后编写yaml:groups: - name: node_alerts rules: - alert: HostOutOfMemory expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 > 10 for: 2m labels: severity: warnnig annotations: summary: Most out of memory (instance {{ $labels.instance }}) description: "Node memory is filling up (> 10% left)\n VALUE * {{ $value }}\n LABELS * {{ $labels }}"- 节点的内存可用率不断变化,每隔一段时间由
scrape_interval定义的时间被 prometheus 抓取一次,默认是 15 秒。 - 根据每个
evaluation_interval的指标来评估告警规则,默认是 15 秒。 - 当告警表达式为 true 时,会创建一个告警并转换到 Pending 状态,执行 for 语句。
- 在下一个评估周期中,如果告警表达式仍然为 true,则检查 for 的持续时间,如果超过了持续时间,则告警将转换为 Firing,生成通知并将其推送到 Alertmanager。
- 如果告警表达式不再为 true,则 Prometheus 会将告警规则的状态从 Pending 更改为 Inactive。
[!tag] 状态转换关系
状态 含义 是否通知 pending 条件首次触发,等待确认 否 firing 条件持续满足,已确认告警 是 inactive 未触发或已恢复 否 inactive→pending当指标首次满足告警条件时。pending→firing当指标持续满足条件达到for时间。pending→inactive当指标在for时间内恢复。firing→inactive当指标恢复到阈值以下。firing→firing如果repeat_interval设置,会周期性重复通知。
- 节点的内存可用率不断变化,每隔一段时间由
-
写好之后还要重启 Prometheus 的容器,重启后,就能看到告警啦:
![在这里插入图片描述]()
-
Alertmanager 也能看到推送的报警啦
![在这里插入图片描述]()
-
-
Operator 安装使用与高级配置
-
架构
![在这里插入图片描述]()
- Prometheus:声明 Prometheus deployment 期望的状态。
- Prometheus Server:Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群。
- Alertmanager:声明了 Alertmanager Deployment。
- ServiceMonitor:声明式指定应如何监控 Kubernetes Service,自动生成相关 Prometheus 抓取配置。
- Operator:根据自定义资源(CRD)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
-
项目:
- Prometheus-operator
- Kube-prometheus:其实包含了上者
- Prometheus Operator:创建CRD自定义的资源对象
- Hightly available Prometheus:创建高可用的Prometheus
- Highly available Alertmanager:创建高可用的告警组件
- Prometheus node-exporter:创建主机的监控组件
- Prometheus Adapter for Kubernetes Metrics APIs:创建自定义监控的指标工具(例如可以通过 Nginx 的 request 来进行应用的自动伸缩)
- kube-state-metrics:监控 k8s 相关资源对象的状态指标
- Grafana:监控面板
-
-
KubeSphere 监控功能与使用
-
监控系统介绍
- 基于 Prometheus 生态
- 多租户隔离
- 多维度监控
- 全面丰富的指标
- 灵活多样的展现方式
-
集群状态监控
-
物理资源监控
- 集群资源
- 节点资源
-
Kubernetes核心组件监控
- API Server
- ETCD
- Scheduler
-
Kubesphere核心组件监控
![在这里插入图片描述]()
-
-
应用资源监控
-
管理员视角
-
集群层级
-
项目与应用资源统计
![在这里插入图片描述]()
-
用量排行
![在这里插入图片描述]()
-
-
-
普通用户视角
- 企业空间层级
- 项目层级
- 工作负载层级
- 容器组层级
- 容器层级
-
-
-
KubeSphere 应用状态监控
-
Kubernetes 集群状态监控
-
KubeSphere 基于租户的告警与通知
-
告警功能介绍
-
兼容 Prometheus 规则(3.1开始)
-
多租户支持
-
内置平台告警才策略
-
规则配置方式
-
-
集群告警
-
内置告警策略
-
物理资源(cpu/内存/存储)
![在这里插入图片描述]()
-
核心组件(k8s/etcd等)
-
-
规则模板配置策略
-
节点(cpu/内存/磁盘/网络/容器组利用率)
![在这里插入图片描述]()
![在这里插入图片描述]()
告警状态已经是触发中,如果配置了通知管理,则可以收到相应的告警信息
![在这里插入图片描述]()
-
-
自定义规则配置策略(其实就是PromQL)
![在这里插入图片描述]()
![在这里插入图片描述]()
要记得在平台管理中配置通知设置哦
![在这里插入图片描述]()
-
-
应用告警
-
规则模板配置策略(cpu/内存/网络/副本不可用)
- 部署
- 有状态副本集
- 守护进程集
-
自定义规则配置策略
-
在项目中创建告警(而不是平台,不用管理员登录,用项目开发者登录)
![在这里插入图片描述]()
![在这里插入图片描述]()
-
类似的,也可以自定义规则 就是点点和写PromQL的区别
![在这里插入图片描述]()
-
-
-
-
KubeSphere 自定义监控
-
KubeSphere 自定义监控
![在这里插入图片描述]()
![在这里插入图片描述]()
-
KubeSphere 导入 Grafana 监控模板
-
使用自定义监控面板监控 GPU
-

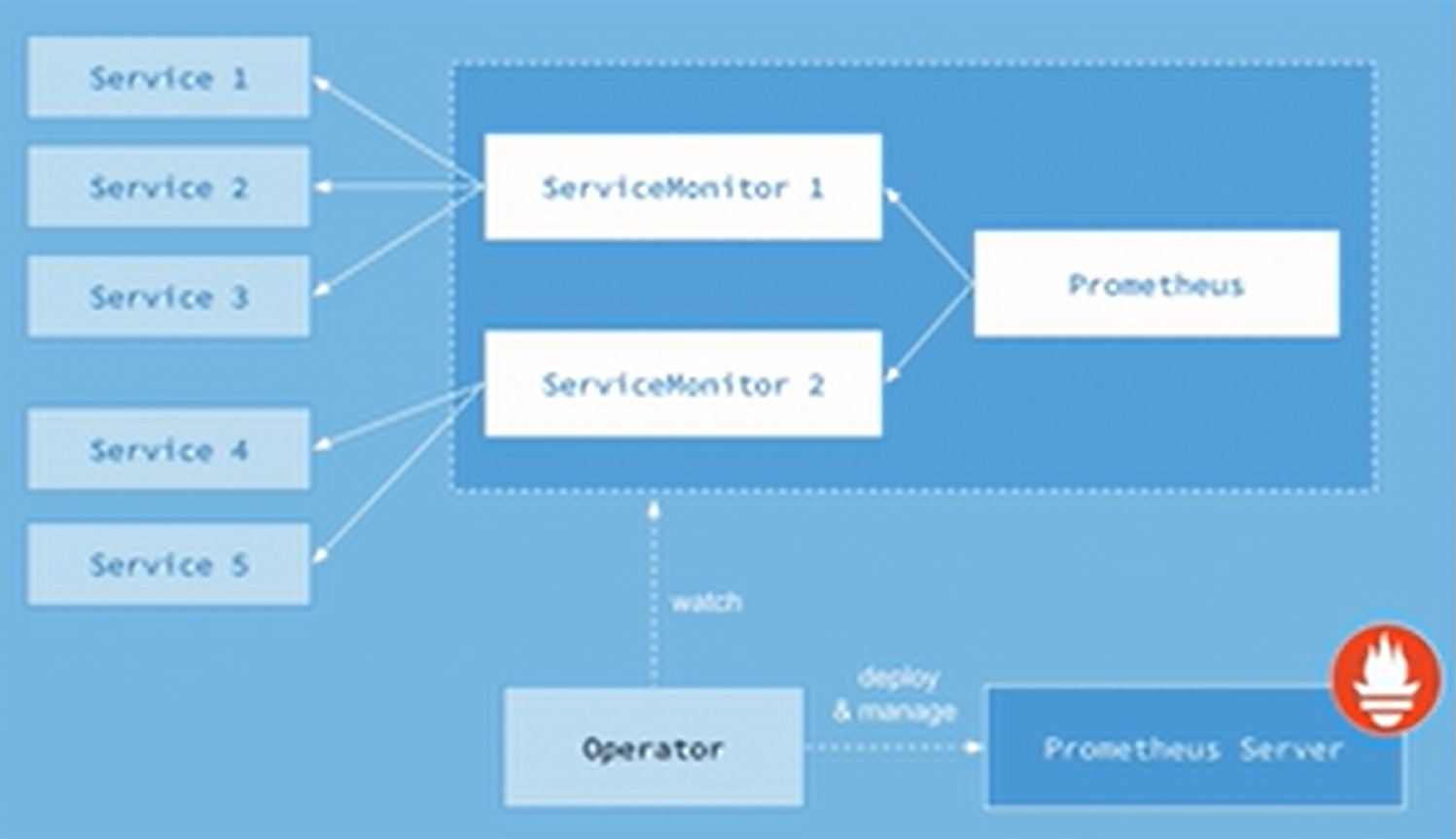
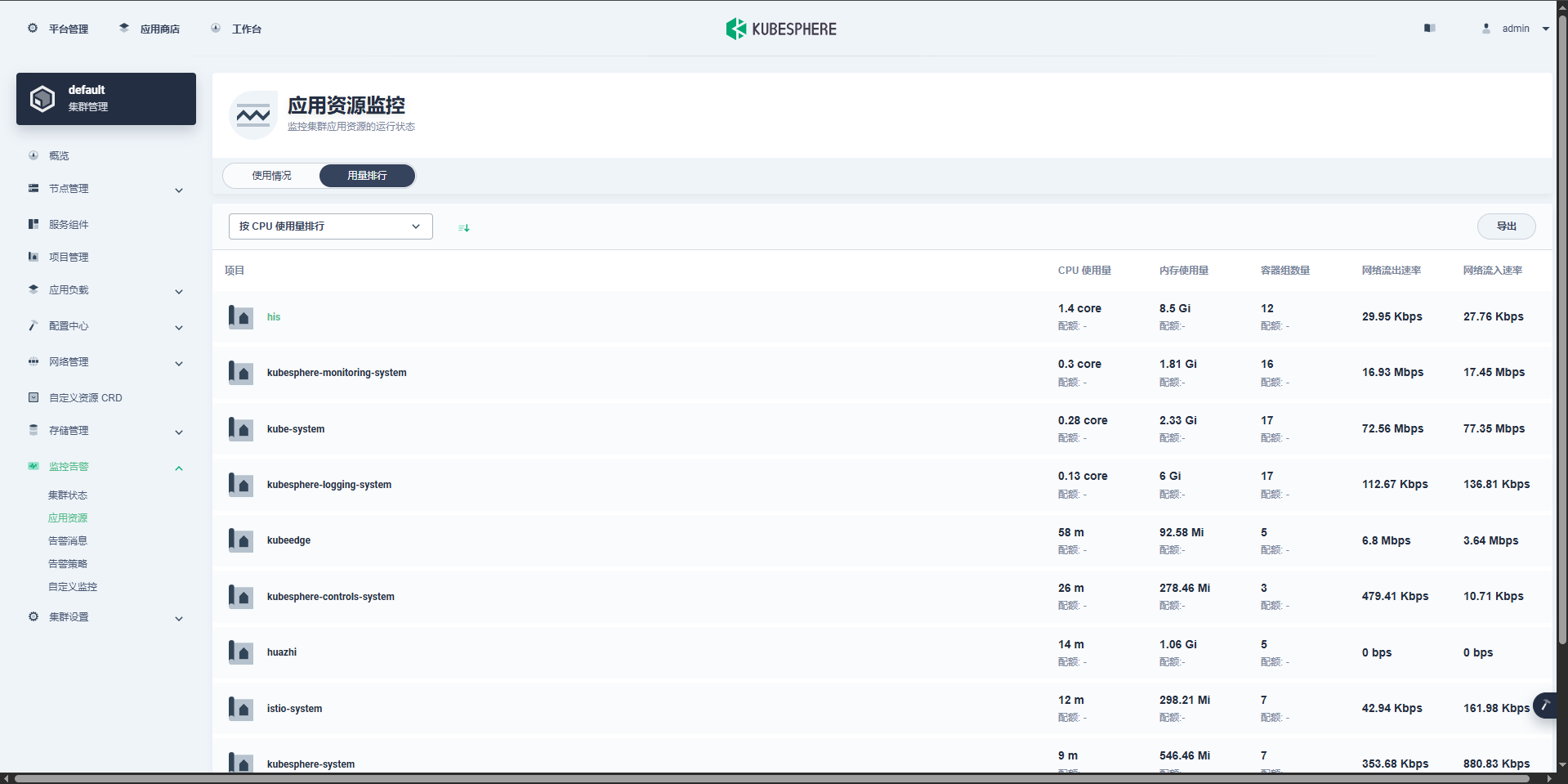
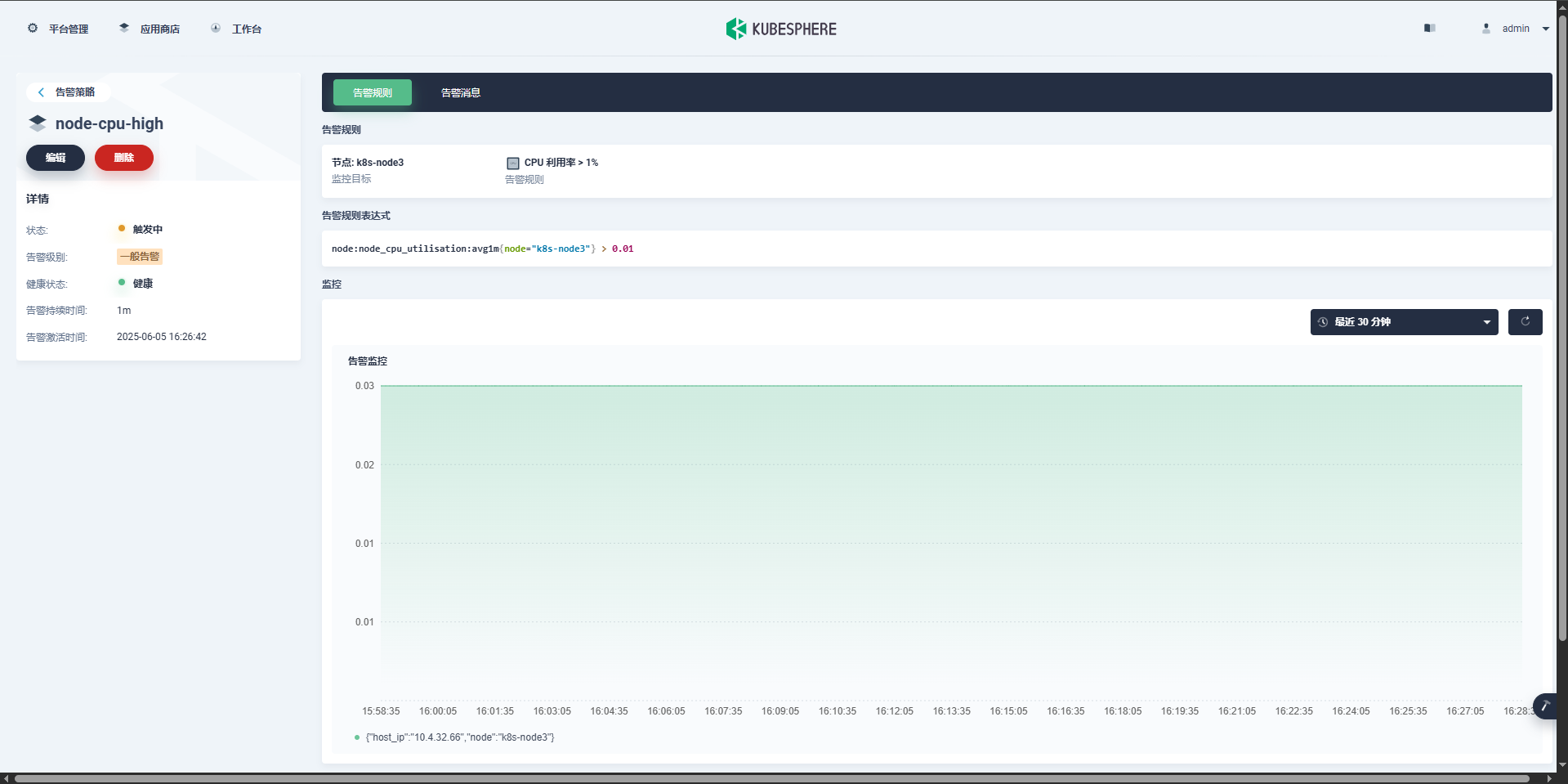
16. 可观测性
-
Kubernetes 审计与事件
![在这里插入图片描述]()
-
Kubernetes 计量计费
![在这里插入图片描述]()
![在这里插入图片描述]()
17. KubeVirt虚拟机负载管理
-
虚拟化技术介绍
-
Cloud Computing 云计算
在云计算发展过程中,有两类虚拟化平台技术:
- OpenStack(IaaS):关注虚拟机的计算、网络和存储资源管理
- Kubernetes(PaaS):关注容器的自动化部署、编排调度和发布管理
![在这里插入图片描述]()
-
Virtualization 虚拟化
![在这里插入图片描述]()
-
Libvirt
![在这里插入图片描述]()
-
-
KubeVirt 介绍
-
KubeVirt
其实就是说,Kubernetes可以管理虚拟机和容器
![在这里插入图片描述]()
-
KubeVirt Components
![在这里插入图片描述]()
-
VM starting flow
![在这里插入图片描述]()
-
-
KubeVirt 虚拟机
- VirtualMachines(VM):为集群内的 VirtualMachineInstance 提供管理功能,例如 开机/关机/重启虚拟机,确保虚拟机实例的启动状态。
- VirtualMachineInstaces(VMI):类似于 Kubernetes Pod,是管理虚拟机的最小资源。一个 VirtualMachineInstance 对象即表示一台正在运行的虚拟机实例,包含一个虚拟机所需要的各种配置。
- VirtualMachineInstanceReplicaSet:类似 Kubernetes 的 ReplicaSet,可以启动指定数量的 VirtualMachineInstance,并且保证指定数量的 VirtualMachineInstance 运行,可以配置 HPA。
- VirtualMachineInstanceMigrations:提供虚拟机迁移的能力。
-
KubeVirt 虚拟机镜像
![在这里插入图片描述]()
-
KubeVirt 磁盘和卷
![在这里插入图片描述]()
-
KubeVirt 网络
![在这里插入图片描述]()
-
Multus插件可以在pod中生成多张网卡
![在这里插入图片描述]()
-
网络配置
![在这里插入图片描述]()
-
-
使用 KubeVirt 管理虚拟机负载 (😓 不搞了不搞了,俺用不上呐)
- KubeVirt的部署
- 使用KubeVirt创建虚拟机
- 虚拟机的启动和停止
- 创建虚拟机快照与恢复快照
- 虚拟机的迁移
-
KubeSphere 虚拟化云平台及功能介绍
-
KSV 平台的背景及简介
![在这里插入图片描述]()
![在这里插入图片描述]()
-
KSV 平台功能介绍
KubeSphere Virtualization(KSV)是一款 容器虚拟化云平台管理软件,轻量级、松耦合是产品的初衷;简洁的界面和易懂的操作是产品的特点。用户无需拥有任何与容器相关的知识就可以非常轻松的进行部署和简单的操作功能。
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
-
-
KubeSphere 虚拟化云平台安装&功能演示
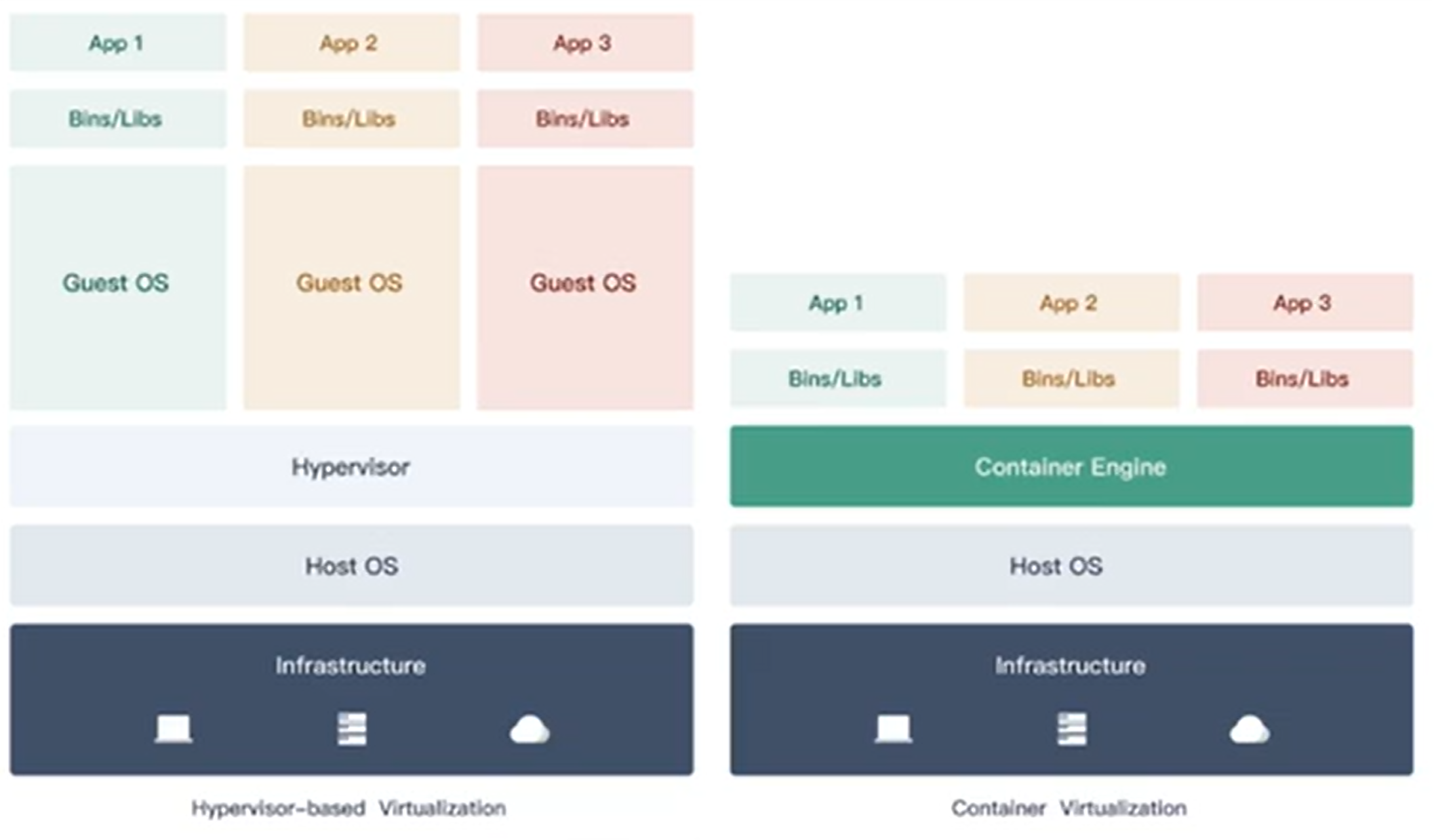
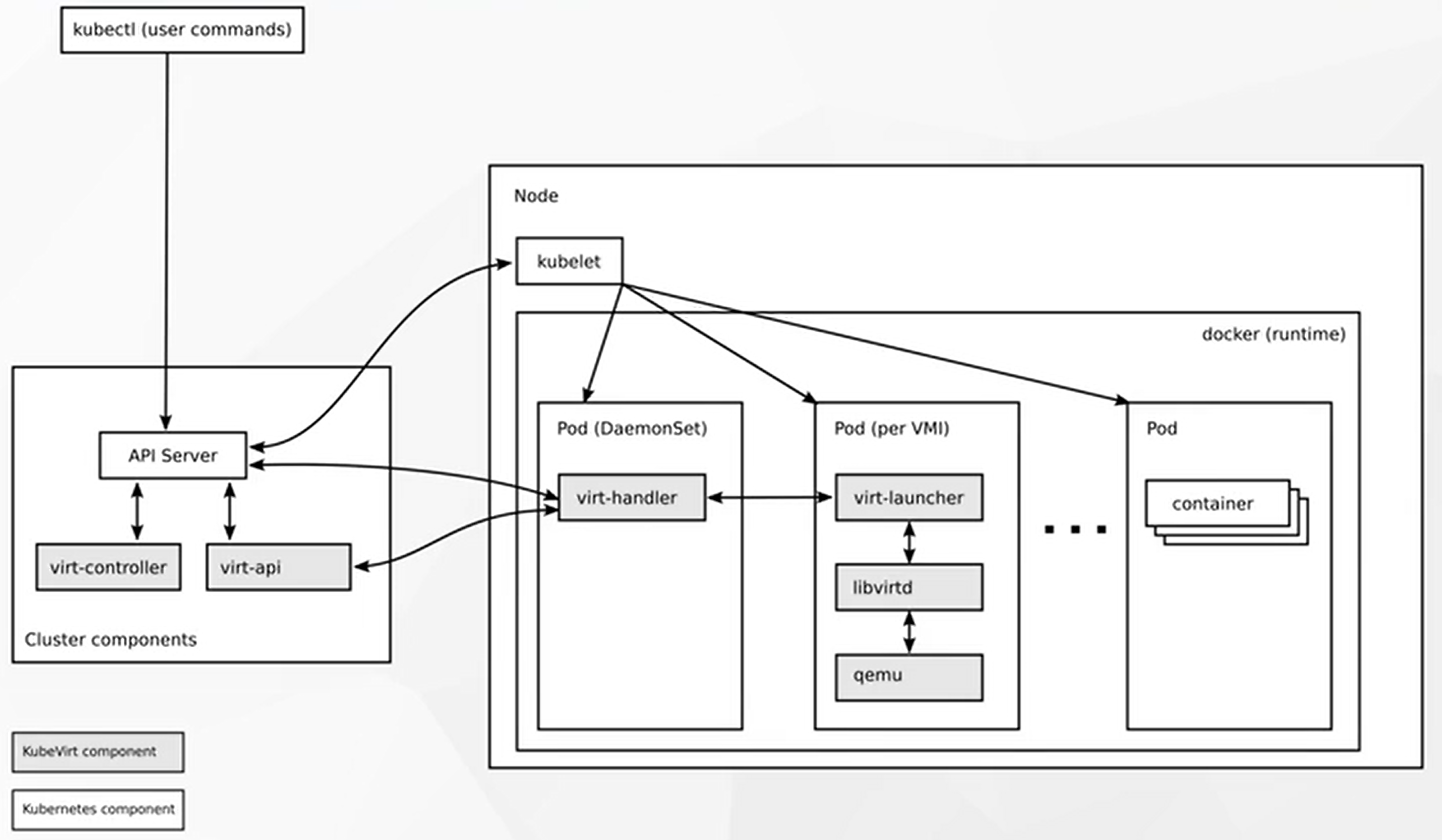

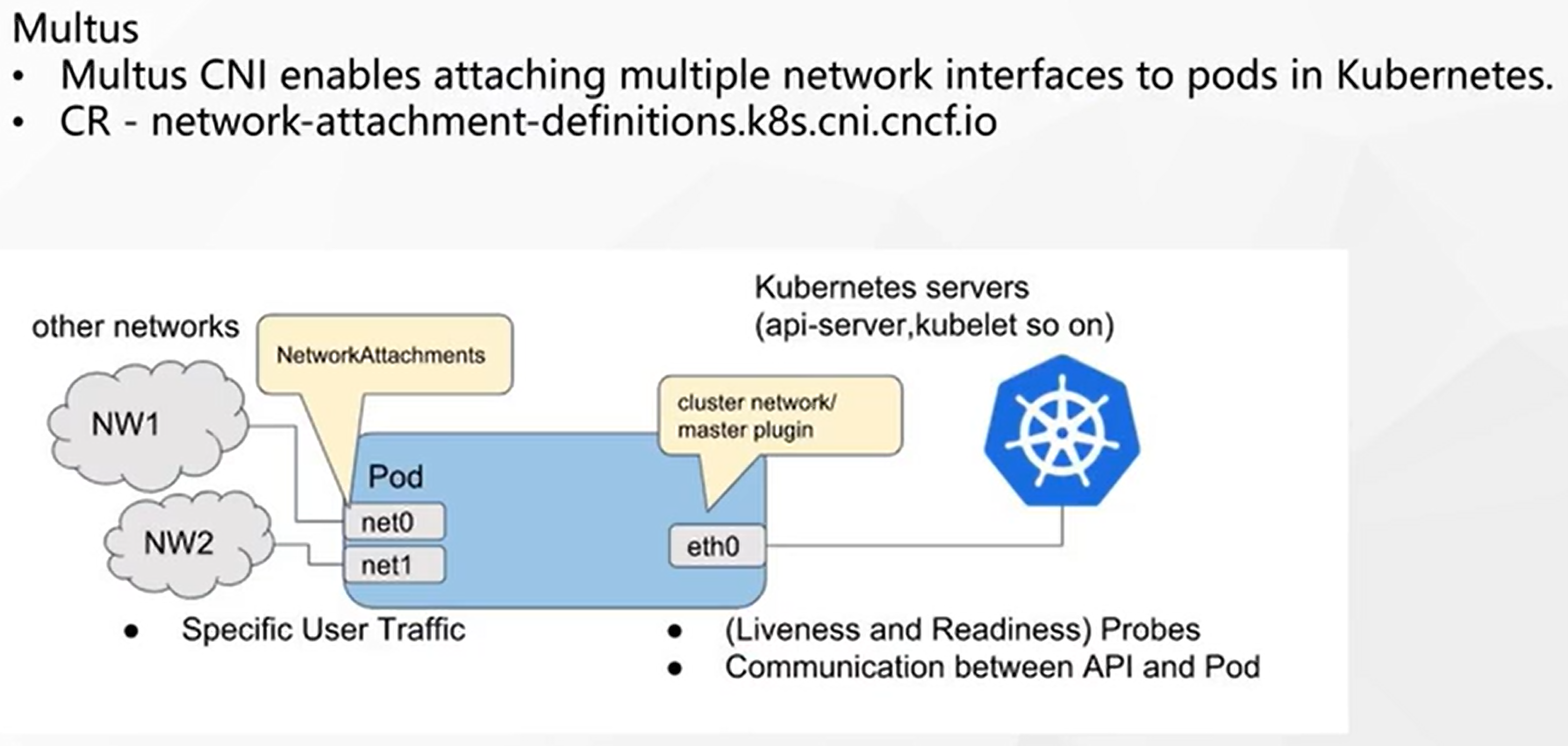

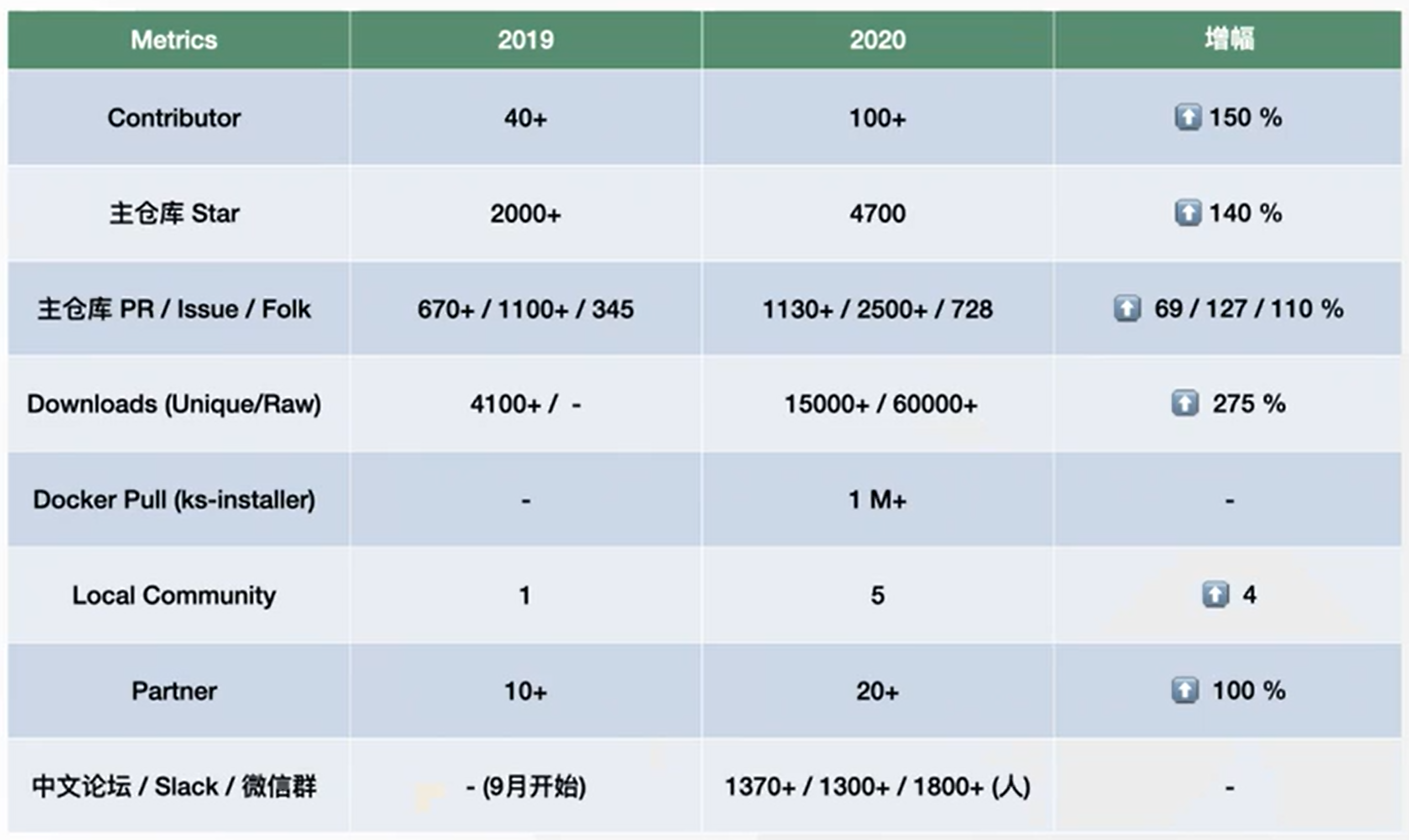
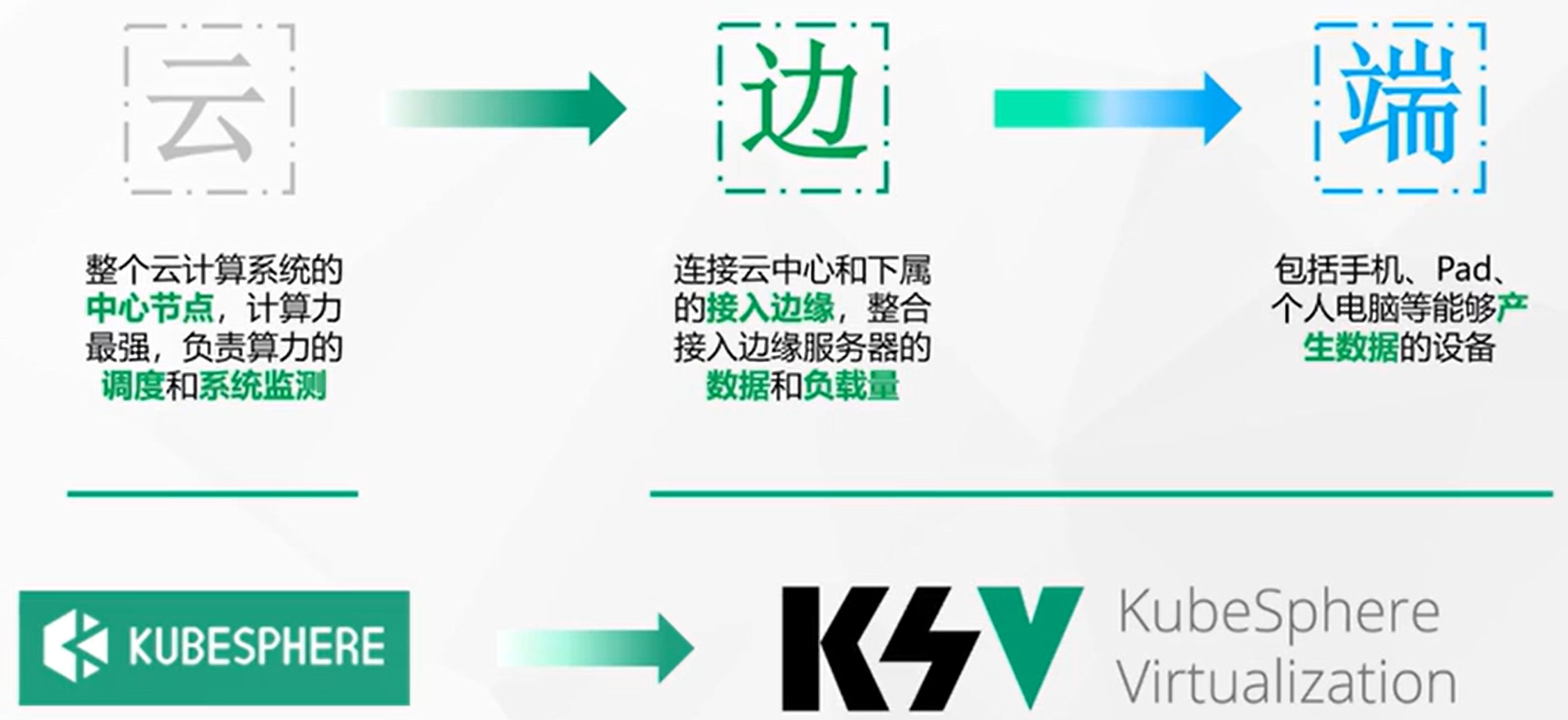





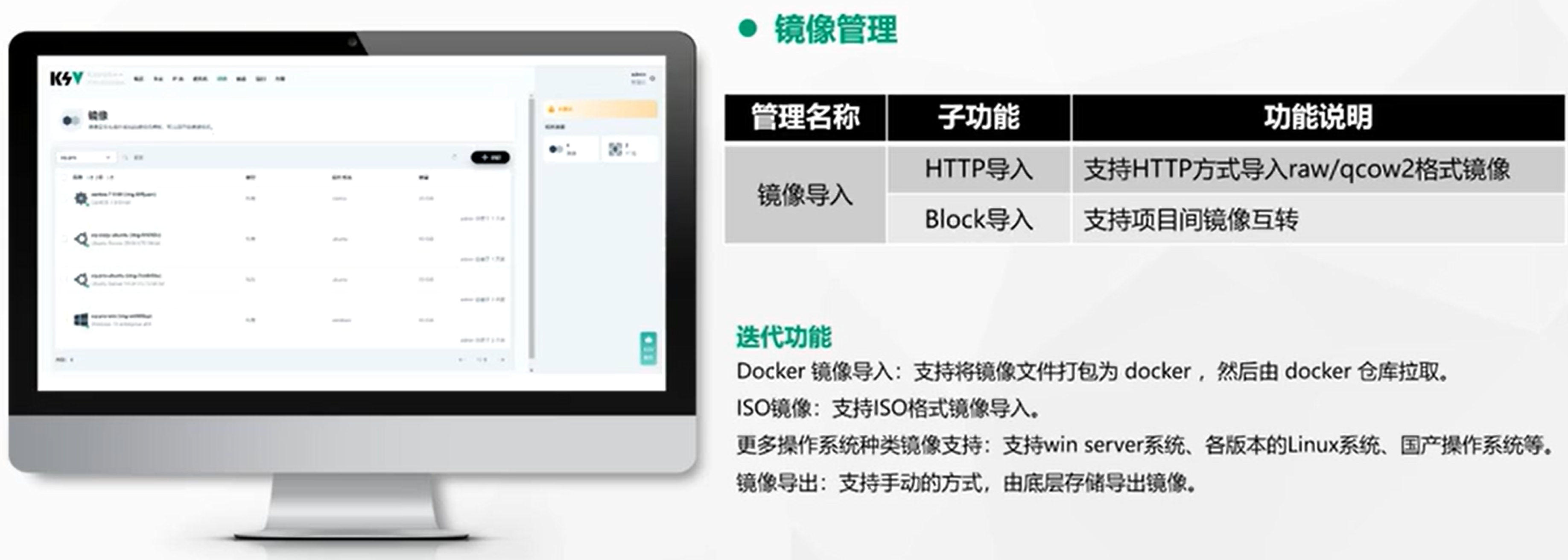

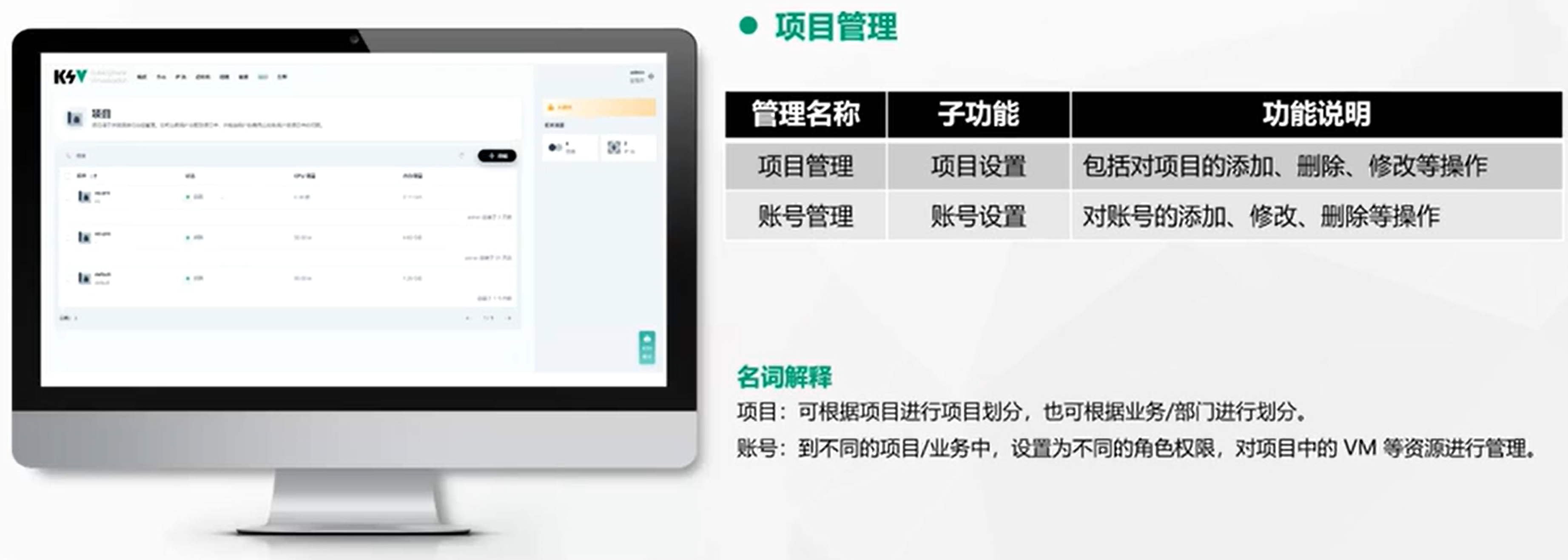


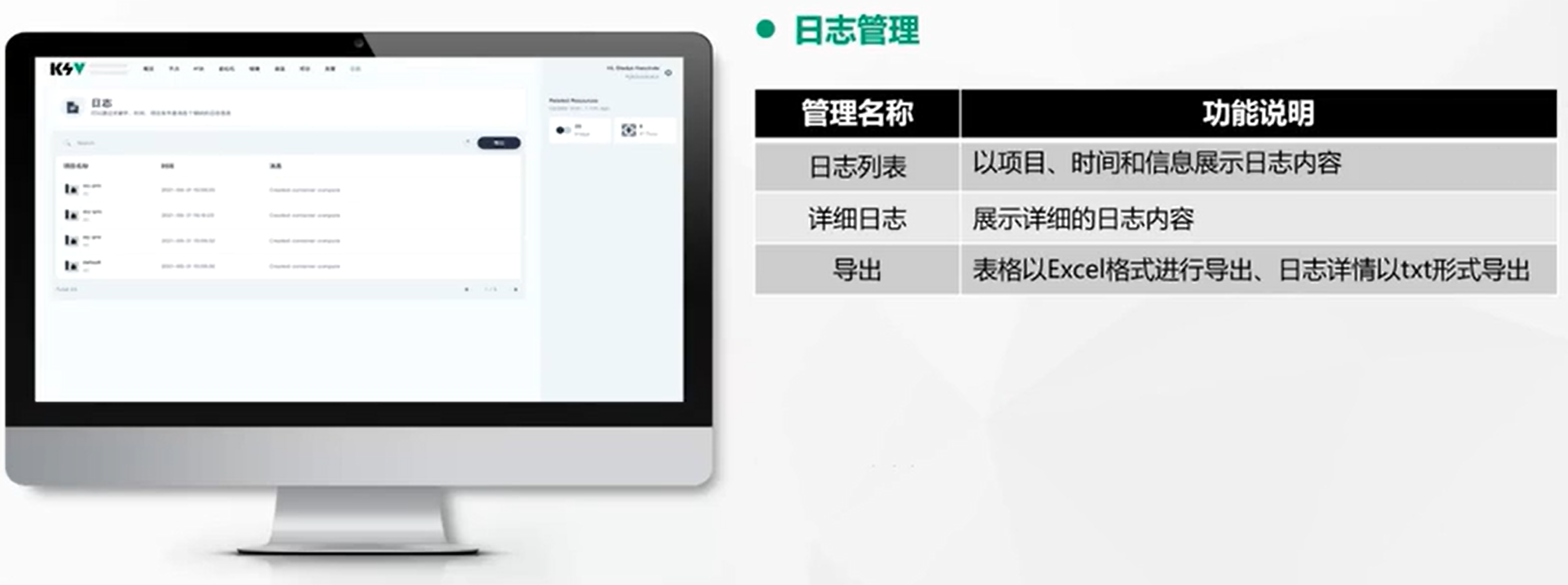
18. CKA/CKS备考攻略
-
CKA / CKS 简介(开卷考试?😸 )
![在这里插入图片描述]()
![在这里插入图片描述]()
-
学习途径推荐
![在这里插入图片描述]()
![在这里插入图片描述]()
知识点梳理——CKA
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
知识点梳理——CKS
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
![在这里插入图片描述]()
-
技巧方法总结
![在这里插入图片描述]()
-
考试心得分享












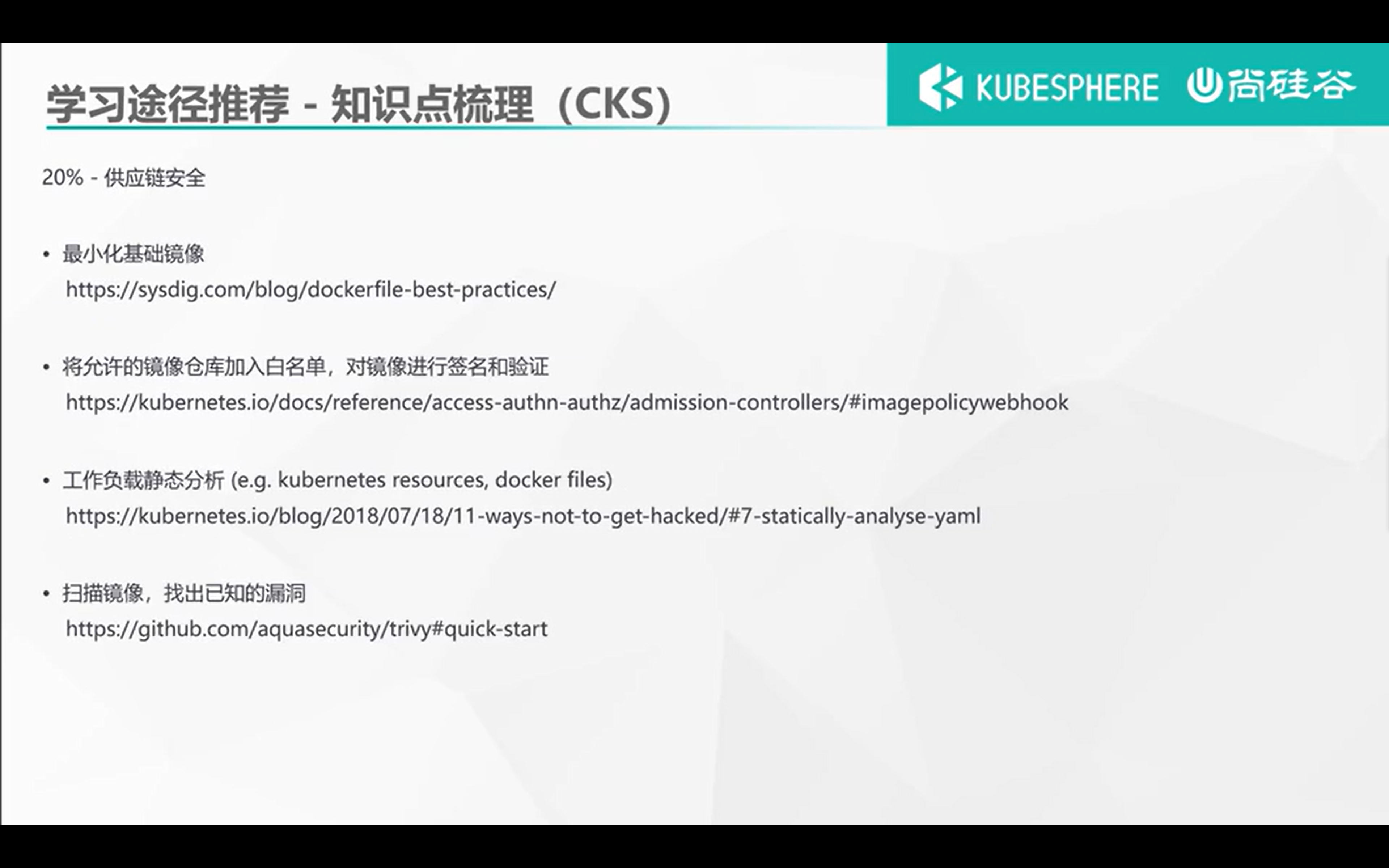


- ☁️ 我的CSDN:
https://blog.csdn.net/qq_21579045/ - ❄️ 我的博客园:
https://www.cnblogs.com/lyjun/ - ☀️ 我的Github:
https://github.com/TinyHandsome/ - 🌈 我的bilibili:
https://space.bilibili.com/8182822/ - 🍅 我的知乎:
https://www.zhihu.com/people/lyjun_/ - 🐧 粉丝交流群:1060163543,神秘暗号:为干饭而来
碌碌谋生,谋其所爱。🌊 @李英俊小朋友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号