两句话讲清楚离线安装k8s
 终于搞到k8s了,老生常谈的原因,我要突破离线部署,这次成功了1.20.9版本的,1.31.3浅尝辄止了,不过后面如果我能突破新版本的k8s离线部署,我会回来更新的~
终于搞到k8s了,老生常谈的原因,我要突破离线部署,这次成功了1.20.9版本的,1.31.3浅尝辄止了,不过后面如果我能突破新版本的k8s离线部署,我会回来更新的~
两句话讲清楚离线安装k8s
我不会设置仅粉丝可见,不需要你关注我,仅仅希望我的踩坑经验能帮到你。如果有帮助,麻烦点个 👍 吧,这会让我创作动力+1 😁
写在前面
-
摘要
终于搞到k8s了,老生常谈的原因,我要突破离线部署,这次成功了1.20.9版本的,1.31.3浅尝辄止了,不过后面如果我能突破新版本的k8s离线部署,我会回来更新的~
-
环境
- 银河麒麟v10sp3,没网
- k8s版本:1.20.9,1.31.3(待完成)
- 三台机器,一个master,两个node
- 默认你每个机器弄好了docker嗷,没弄好快去学:两句话讲清楚离线安装docker
解决方案 [1.20.9]
-
所有机器执行以下操作,别问,问了也白问。当然了,优雅一点的话,提前给每台机器改个名字啥的:
hostnamectl set-hostname xxxx# 将 SELinux 设置为 permissive 模式(相当于将其禁用) sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config #关闭swap swapoff -a sed -ri 's/.*swap.*/#&/' /etc/fstab #允许 iptables 检查桥接流量 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sudo sysctl --system -
安装kubelet、kubeadm、kubectl
-
先搞清楚依赖的问题
Installing:
Installing for dependencies
-
当然是先处理依赖呀,ubtuntu、centos阿里镜像都有哈,搜就行了。由于我是银河麒麟,所以我选择:https://update.cs2c.com.cn/NS/V10
- cri-tools-1.31.1-150500.1.1.x86_64.rpm
- libnetfilter_queue-1.0.5-1.ky10.x86_64.rpm
- libnetfilter_cttimeout-1.0.0-13.ky10.x86_64.rpm
- libnetfilter_cthelper-1.0.0-15.ky10.x86_64.rpm
- conntrack-tools-1.4.6-2.ky10.x86_64.rpm
- socat-1.7.3.2-8.ky10.x86_64.rpm
-
1️⃣ 阿里!我的神: https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/Packages/ ,搞到四个文件:
- db7cb5cb0b3f6875f54d10f02e625573988e3e91fd4fc5eef0b1876bb18604ad-kubernetes-cni-0.8.7-0.x86_64.rpm
- c968b9ca8bd22f047f56a929184d2b0ec8eae9c0173146f2706cec9e24b5fefb-kubectl-1.20.9-0.x86_64.rpm
- 02431d76ab73878211a6052a2fded564a3a2ca96438974e4b0baffb0b3cb883a-kubelet-1.20.9-0.x86_64.rpm
- 8c6b5ba8f467558ee1418d44e30310b7a8d463fc2d2da510e8aeeaf0edbed044-kubeadm-1.20.9-0.x86_64.rpm
-
安装!上面的这么多rpm都要装啊,按依赖顺序来,错了会告诉你缺什么依赖,这个就不多说了,安装命令:
rpm -ivh xxx.rpm,这一步好说~
-
-
自建Registry
-
2️⃣ 离线,必然注定了镜像得自己整,首先你要能有个机器能把镜像搞到是不是
docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-proxy:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-scheduler:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-apiserver:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/kube-controller-manager:v1.20.9 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/etcd:3.4.13-0 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/coredns:1.7.0 docker pull registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/pause:3.2 -
💡 为了把这个机器的镜像导入你的自建registry的机器中,得导出和加载吧(当然了,如果你本机直接建registry,这一步可以跳过,毕竟你的服务端和客户端属于同一台机器了)
- 导出镜像:
docker save -o xxx.tar 镜像ID - 传入服务器并加载镜像:
docker load -i xxx.tar
- 导出镜像:
-
服务端:自建registry,基操勿六:
docker run -d -p 5000:5000 --name myregistry --restart=always -v /data/registry:/var/lib/registry registry:latest -
客户端:配置docker
/etc/docker/daemon.json:{"insecure-registries": ["服务端IP:5000"]}💡 由于后面也会要配置docker的配置文件,且会遇到各种问题(见 问题集合 所示)
👍 所以建议这里一波到位:
{ # 拉取地址要支持http的本地registry "insecure-registries" : ["10.4.32.48:5000"], # 本地registry的地址 "registry-mirrors": ["http://10.4.32.48:5000"], # 解决问题:detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". "exec-opts": ["native.cgroupdriver=systemd"] }重启docker
sudo systemctl daemon-reload sudo systemctl restart docker -
好了,刚才搞到客户端的镜像们可以开始 tag 和 push 了,举个栗子:
- 给镜像打自己的tag:
docker tag 镜像ID 服务端IP:5000/kube-proxy:v1.20.9 - push到服务端:
docker push 服务端IP:5000/kube-proxy:v1.20.9 - k8s主节点机器拉镜像:
docker pull 服务端IP:5000/kube-proxy:v1.20.9
ok,现在你的k8s主节点的机器上怎么滴应该吧刚才这么多镜像拉下来了吧。
- 给镜像打自己的tag:
-
-
使用kubeadm引导集群
-
初始化主节点,只在主节点运行,注意:这里的
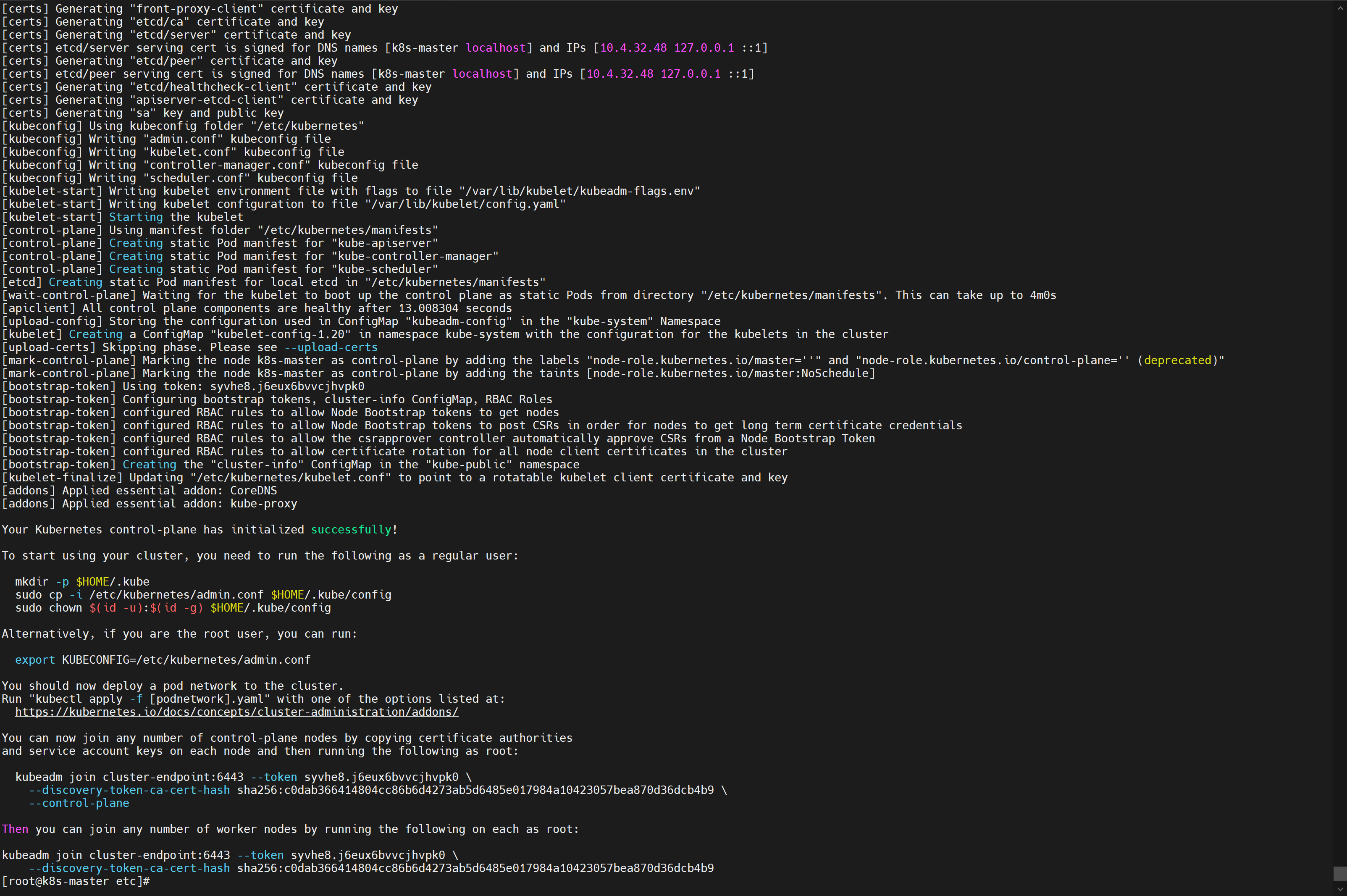
10.4.32.48是我自己的master节点# 所有机器添加master域名映射,以下需要修改为自己的 # 每一个节点都要添加这句话,让每个节点都知道主节点是谁 # 执行后的效果:ping cluster-endpoint 可以ping通 echo "10.4.32.48 cluster-endpoint" >> /etc/hosts # 主节点初始化 # --apiserver-advertise-address 管理节点ip # --image-repository containerd配置文件中的镜像仓库 # --control-plane-endpoint 管理节点ip # --pod-network-cidr=192.168.0.0/16 这么写是因为后面calico网络安装的yaml文件中默认的是这个 # --kubernetes-versio 这里是什么版本就是什么版本 v1.20.9 或者 v1.31.3 kubeadm init \ --apiserver-advertise-address=10.4.32.48 \ --control-plane-endpoint=cluster-endpoint \ --image-repository 10.4.32.48:5000 \ --kubernetes-version v1.20.9 \ --service-cidr=10.96.0.0/16 \ --pod-network-cidr=192.168.0.0/16我只能说两个字:成功!🎉
![在这里插入图片描述]()
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join cluster-endpoint:6443 --token syvhe8.j6eux6bvvcjhvpk0 \ --discovery-token-ca-cert-hash sha256:c0dab366414804cc86b6d4273ab5d6485e017984a10423057bea870d36dcb4b9 \ --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join cluster-endpoint:6443 --token syvhe8.j6eux6bvvcjhvpk0 \ --discovery-token-ca-cert-hash sha256:c0dab366414804cc86b6d4273ab5d6485e017984a10423057bea870d36dcb4b9 -
设置
.kube/config📍 主节点,使用!创建目录、复制配置文件、赋权~
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config成功啦!
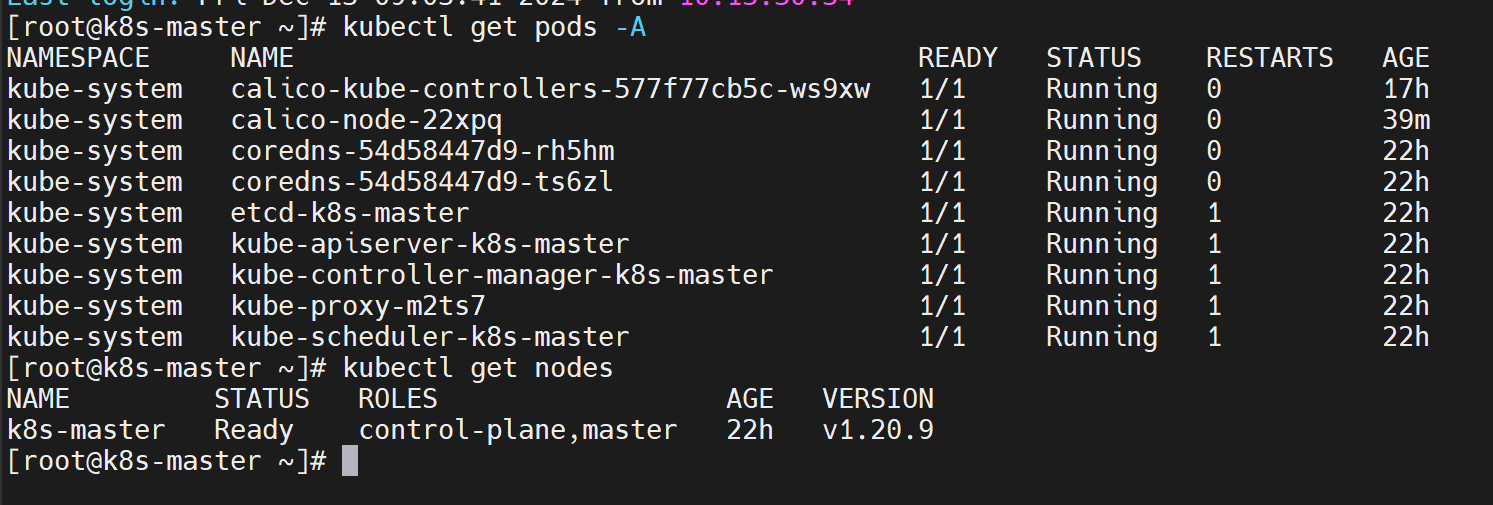
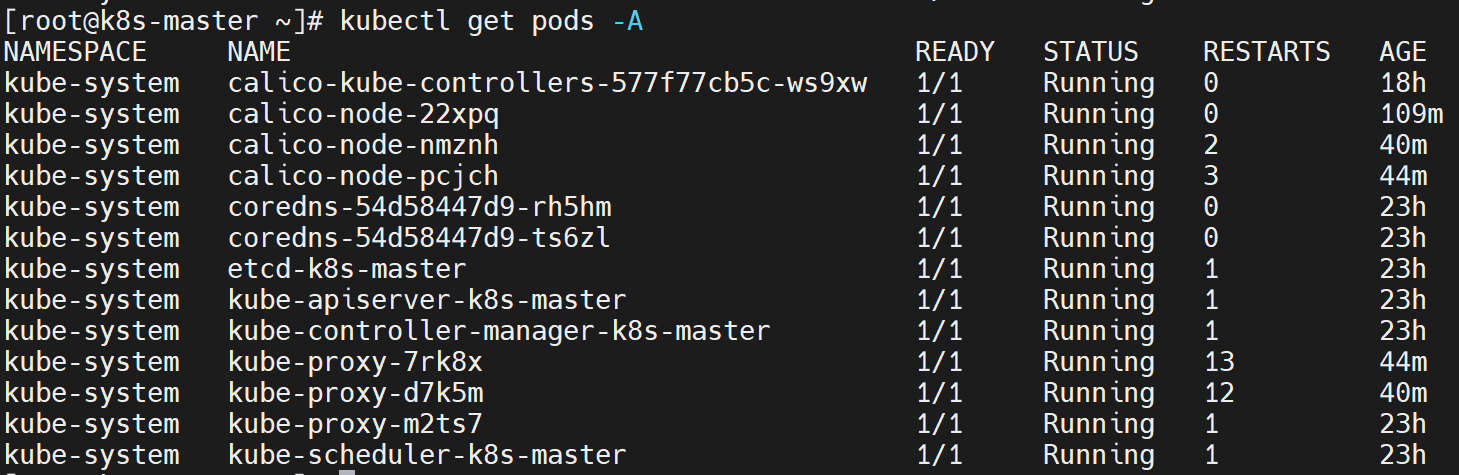
[root@k8s-master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master NotReady control-plane,master 3h50m v1.20.9 -
安装网络组件
现在主节点是 NotReady 是吧,原因是没有 deploy a pod network to the cluster,即缺少一个网络插件,把k8s的机器用网络插件串起来打通。
k8s支持很多网络插件,我们选择 calico
-
下载 calico v3.20 的配置文件:https://docs.projectcalico.org/v3.20/manifests/calico.yaml
-
准备 calico 需要的镜像,当然了都要push到自建的registry上:
⚠️ 注意嗷,这里是有calico前缀的,别掉了,因为这里的镜像跟之前的不一样,之前
kubeadm init的时候是从指定的镜像地址pull,所以都没有保留前缀docker.io/calico/cni:v3.20.6docker.io/calico/pod2daemon-flexvol:v3.20.6docker.io/calico/node:v3.20.6docker.io/calico/kube-controllers:v3.20.6
-
【前面配了就不用搞了】配置主节点
/etc/docker/daemon.json,这样从docker.io也会到自建的registry中搞镜像,当然了,记得重启docker服务:systemctl daemon-reload & systemctl restart docker"registry-mirrors": ["http://服务端IP:5000"] -
安装:
kubectl apply -f calico.yaml🎉 在所有镜像push之后,自动就 Ready 啦!pods们都 running 啦!
![在这里插入图片描述]()
-
-
加入Work节点
现在的主场从master到其他的work服务器啦,每个work服务器都这么搞哦!
-
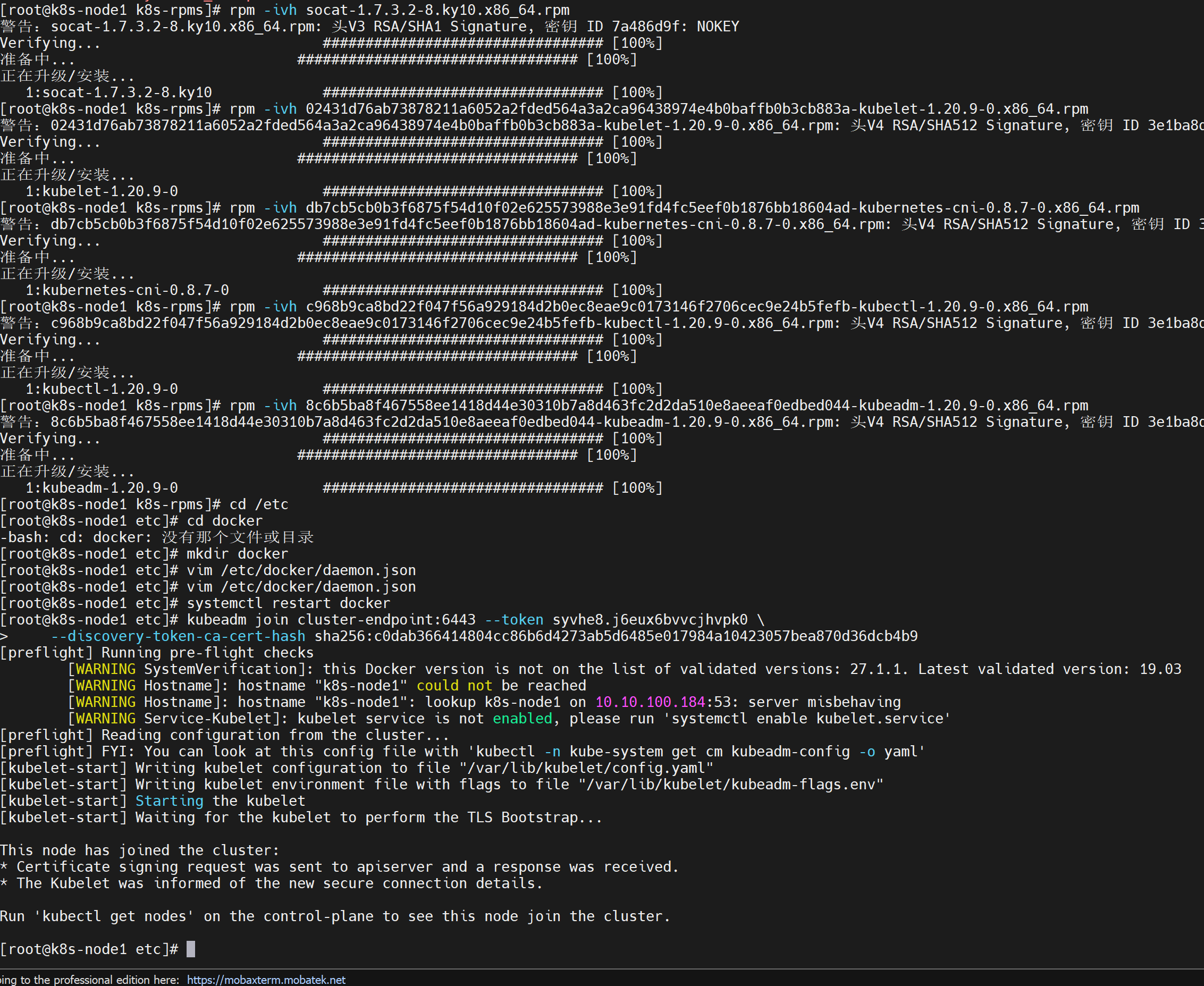
💡 首先Work服务器也要装 kubelet、kubeadm、kubectl 及其依赖,所以之前主节点怎么整的,现在也怎么整,还记得一堆rpm吗,回去看看吧
-
还是之前
kubeadm init成功显示里面的命令,在Work节点的服务器中运行:kubeadm join cluster-endpoint:6443 --token syvhe8.j6eux6bvvcjhvpk0 \ --discovery-token-ca-cert-hash sha256:c0dab366414804cc86b6d4273ab5d6485e017984a10423057bea870d36dcb4b9💡 但是这个令牌是24h有效的,如果过期了怎么办?
在master节点创建新令牌:
kubeadm token create --print-join-command -
🎉 成功啦!
![在这里插入图片描述]()
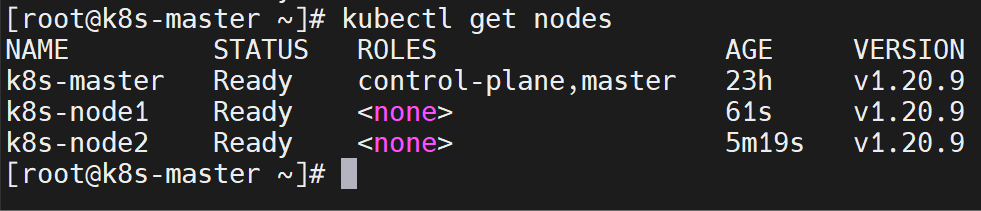
👌 回去主节点上可以看到加入的工作节点们~
![在这里插入图片描述]()
🎉 现在我们主节点、work节点都ready,且pods也都ready,这样就是集群全部起来啦,k8s搭建成功~ 集群是有自我修复能力的,如果把三个服务器都reboot,重启成功后,可以看到节点都在自动恢复。
![在这里插入图片描述]()
-
-
-
部署dashboard,虽然安装集群已经结束了,顺带的dashboard也整点吧~
-
kubernetes官方提供的可视化界面
- 官方地址:https://github.com/kubernetes/dashboard
- 我选择的是下载 v2.3.1 的yaml文件:https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
- 在自建的registry中备好相应的镜像
- kubernetesui/metrics-scraper:v1.0.6
- kubernetesui/dashboard:v2.3.1
- 安装:
kubectl apply -f recommended-v2.3.1.yaml
-
设置访问端口
-
修改配置文件中的
type: ClusterIP改为type: NodePortkubectl edit svc kubernetes-dashboard -n kubernetes-dashboard- 然后修改就行
-
找到端口,在安全组放行:
kubectl get svc -A | grep kubernetes-dashboard[root@k8s-master others]# kubectl get svc -A |grep kubernetes-dashboard kubernetes-dashboard dashboard-metrics-scraper ClusterIP 10.96.51.184 <none> 8000/TCP 33m kubernetes-dashboard kubernetes-dashboard NodePort 10.96.223.53 <none> 443:31345/TCP 33m需要在安全组中把 31345,也就是上面的最后一行那个
443:31345这个端口放开 -
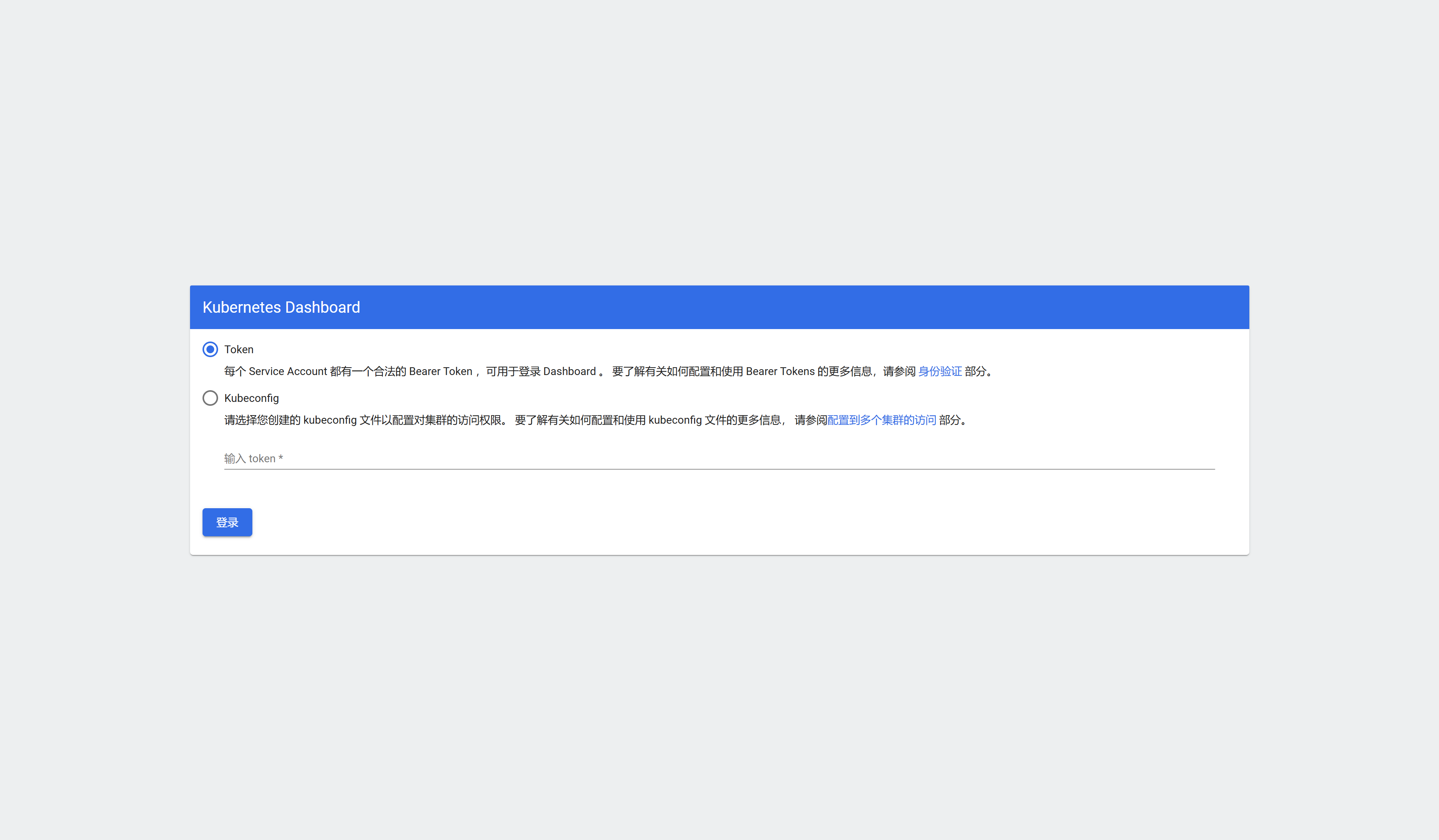
访问:
https://集群任意IP:端口(即31345),用 k8s-node1 为例:https://10.4.32.50:31345![在这里插入图片描述]()
-
-
创建访问账号
光看这个玩意儿,不知道登录的token是啥啊,需要自己弄,没错:
kubectl apply -f dash.yaml那么这个文件怎么写呢:
# 创建访问账号,准备一个yaml文件; vi dash.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard这样就创建了一个服务的账号:
admin-user -
令牌访问
-
获取访问令牌:
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"输出的还挺像jwt token的
eyJhbGciOiJSUzI1NiIsImtpZCI6IllLRDhuSGpndDhJOFRnUWtCNE5XQXZER1NfMDlwY25BR3VGMEl1dnN0Nm8ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWN6ZHo3Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJkY2MyOThhZS1iMzBlLTRiMzUtODMyNy00MDg3ZTkzYzk1NzIiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.S16hXdYbCu64pmEHw6U7hW28jPzxKB7V-tm-n-m3lupzgPIdaudKvSoUjPTy-O55h2_4CgMI0GuQTSNCopjj0Rnf5CxOzarpfSkHvo6C9HuJp1nQhOJJpzKPTNT3m_rYjwJwSgGnZasvGFfmvCndut6qLLYSsZr_sFdUL1rJOBs5peoCnmR7yptrrrog-e9Vtxkhr-Q04RqwJCYXjxPkmKevGTLYlLfbpC_c_JPlLsafjut3DgFrZWb0hwQzwdYOk1JDBcJbV0Jv5CG98jNT02mFoSq3m0aZ_T_aIWtTzdNi7f4siblzoffViIYcN42_5D_FdR4JctVqddR4Nu_O-Q -
然后一粘贴就登录了
![在这里插入图片描述]()
-
-
解决方案 [1.31.3] 这里只展示差异部分
总体来说,流程是一样的,就是包的区别
-
对于 1️⃣ 中,四个文件改为:https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.31/rpm/x86_64/
- kubernetes-cni-1.5.1-150500.1.1.x86_64.rpm
- kubelet-1.31.3-150500.1.1.x86_64.rpm
- kubectl-1.31.3-150500.1.1.x86_64.rpm
- kubeadm-1.31.3-150500.1.1.x86_64.rpm
-
docker不行啦,得用containerd。
containerd安装教程:参考链接:
-
"validate service connection: validate CRI v1 runtime API for endpoint \" unix:///var/run/containerd/:https://blog.csdn.net/qq_33371766/article/details/140361531 -
【kubeadm】离线部署k8s(使用containerd):https://blog.csdn.net/Nefertari___/article/details/135932563
-
轻量级容器管理工具Containerd的两种安装方式:https://www.cnblogs.com/liuzhonghua1/p/18010847
-
从 github 上下就完了: https://github.com/containerd/containerd/releases ,我下的是
containerd-1.7.24-linux-amd64.tar.gz -
创建containerd目录并解压
mkdir /root/containerd tar -zxvf containerd-1.7.24-linux-amd64.tar.gz -C /root/containerd -
追加环境变量并立即生效:
export PATH=$PATH:/usr/local/bin:/usr/local/sbin && source ~/.bashrc -
使containerd生效
cd /root/containerd/bin cp * /usr/bin cp ctr /usr/local/bin -
检查containerd的管理命令
ctictl是否好用:ctictl --version -
生成containerd配置文件
mkdir -p /etc/containerd/ containerd config default > /etc/containerd/config.toml -
修改containerd默认配置文件
-
修改
sandbox_image为自己registry的 pause 镜像 -
修改 仓库镜像,我是把所有各种镜像都指向自己的registry了
[plugins] ... [plugins."io.containerd.grpc.v1.cri"] ... # sandbox_image = "registry.k8s.io/pause:3.8" sandbox_image = "10.4.32.48:5000/pause:3.10" ... [plugins."io.containerd.grpc.v1.cri".registry] [plugins."io.containerd.grpc.v1.cri".registry.mirrors] [plugins."io.containerd.grpc.v1.cri".registry.mirrors."registry.k8s.io"] endpoint = ["http://10.4.32.48:5000"] [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] endpoint = ["http://10.4.32.48:5000"] [plugins."io.containerd.grpc.v1.cri".registry.mirrors."10.4.32.48:5000"] endpoint = ["http://10.4.32.48:5000"] ...
-
-
启动containerd,且设置自启:
systemctl start containerd && systemctl enable containerd
-
-
2️⃣ 中的镜像必然不一样啦。查看当前版本 kubeadm 安装对镜像的需求:
kubeadm config images list。现在知道下什么了吧,反正通过你的方式搞到这些镜像,然后push到你的registry中,为后续做准备falling back to the local client version: v1.31.3 registry.k8s.io/kube-apiserver:v1.31.3 registry.k8s.io/kube-controller-manager:v1.31.3 registry.k8s.io/kube-scheduler:v1.31.3 registry.k8s.io/kube-proxy:v1.31.3 registry.k8s.io/coredns/coredns:v1.11.3 registry.k8s.io/pause:3.10 registry.k8s.io/etcd:3.5.15-0 -
未完待续。。。
问题集合
-
为什么研究了1.20.9和1.31.3两个版本的k8s
因为我发现 kubeadm init 的时候报错了,应该是我安装的k8s版本太高了,导致docker里面的镜像版本太低报错:
this version of kubeadm only supports deploying clusters with the control plane version >= 1.30.0. Current version: v1.20.9 To see the stack trace of this error execute with --v=5 or higher我发现最新的版本是
v1.31.3,整吧,整吧整完之后报错:没有
containerd啥的,就是找不到这个服务,研究了一下发现Containerd与Docker有什么区别:https://zhuanlan.zhihu.com/p/718335600
-
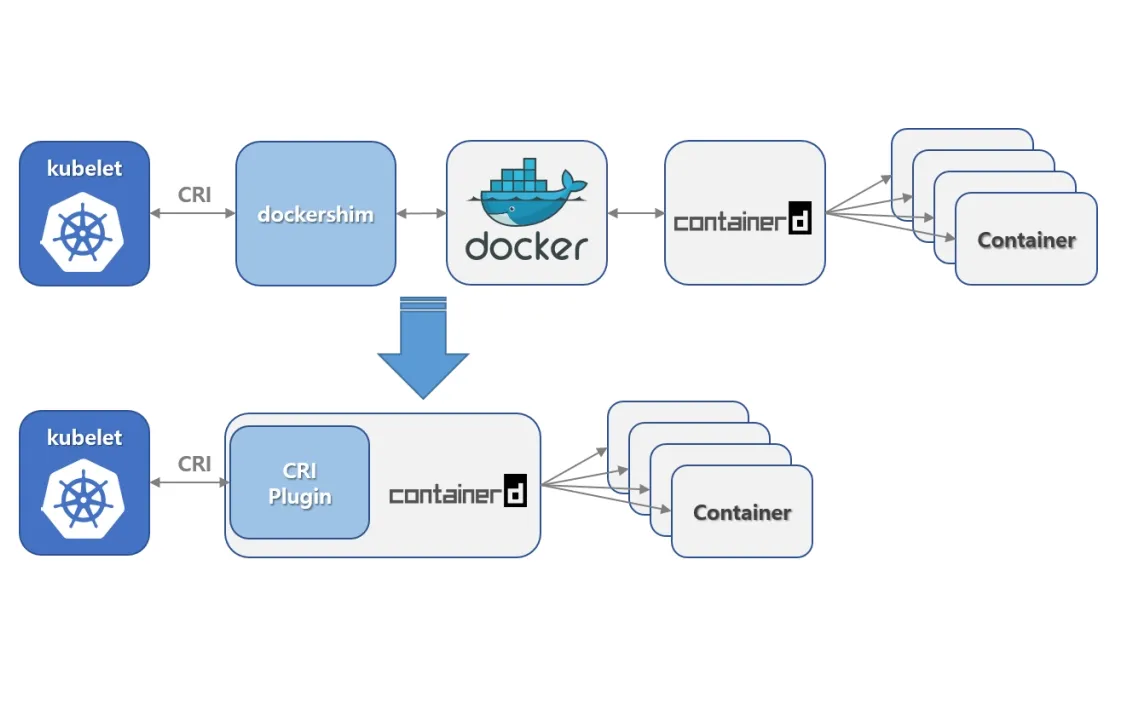
在1.20版本中将内置的dockershim进行分离,这个版本依旧还可以使用dockershim,但是在1.24中被删除。从1.24开始,大家需要使用其他受到支持的运
行时选项(例如containerd或CRI-O)![在这里插入图片描述]()
现在工作中k8s是使用containerd还是docker来管理容器:https://www.zhihu.com/question/3418508537/answer/31609642599
为什么这俩工具长得差不多?
-
咱先说个背景知识,这事儿的根子还在于,
Kubernetes这玩意儿,自己不生产容器,它就是个“调度员”,就是管你要什么容器,跑哪里,怎么跑,这些事儿。容器本身是由更底层的东西来管的。 -
Docker和containerd,就是两种帮你把容器跑起来的工具。最早Docker算是主流,后来containerd上位,成了 Kubernetes 里默认的容器管理方式。这两个工具呢,说白了,都能帮你把应用打包成容器,把代码、依赖、配置啥的都塞一块,想在哪儿跑都行。 -
只是,
Docker做了更多,它不仅仅管容器,还做镜像构建、注册、分发什么的。而containerd就精简得多,专注跑容器的核心功能。你可以理解为Docker是个大公司里的全能员工,啥都想干;而containerd就是个专注一件事的小专家,干活专心不出岔子。
Docker 落伍的根源在哪?
说白了,
Docker的锅有点儿多。一开始它啥都干,但Kubernetes真正搞起来后,发现有些事不需要它插手。比如容器的构建和分发,用不上
Kubernetes就能搞定;但是Docker自带的这些东西不仅多余,还拖慢系统。想想公司里的“全能”同事啥都管,有时候反倒不省心,是不是?- 性能负担:Docker 架构复杂、依赖多,在大规模场景下,额外的服务和功能就成了累赘,常常拖慢系统。就像你把一个公司所有职能都给一个人,这人反倒越干越慢,还常出小毛病。
- 兼容性不足:Docker 的架构不符合 Kubernetes CRI(Container Runtime Interface,容器运行时接口)的规范,需要一层转接,叫
dockershim。多一个环节就多一份不稳定的风险,出点问题谁都搞不清锅在哪儿。换个精简专注的containerd,直接上 CRI,少了中间商,省心多了。 - 复杂架构:Docker 的架构里带了很多没用的东西,举个例子,自己带了个 Docker Engine 和 Docker Daemon,就像一个人带个小助理,干活是方便了,但也有点拖沓。咱不如直接让 containerd 这个大力士上,直接扛活儿干。
- Kubernetes 直呼“去掉 dockershim”:2021 年 Kubernetes 就宣布正式抛弃 Docker 支持了,原因很简单,大家都嫌麻烦,尤其是多出来的 dockershim 维护成本高,风险大。既然有更好的选择,谁还拿着“扶不起的阿斗”?
那
containerd有啥独门绝技?好嘞,containerd 出场了。这个家伙清晰明了,就是个硬派选手。它干活就干“运行容器”这一件事,不掺和别的,省心省事儿。来看几个它独有的好处:
- 体积小,速度快:不多说了,containerd 不像 Docker 那么复杂,你也不用花额外心思去理解各种多余的东西。专注就是力量,咱玩 Kubernetes 就是要这个小、快、专注的工具,别整那些花里胡哨的。
- 架构简洁:containerd 和 Kubernetes 打交道的接口天然契合,没啥中间层,直接干活就完事儿。容器调度上,少一环,稳定性就上来。再说,简洁的东西维护起来也省心,不会今天冒泡明天掉线。
- 维护方便,社区活跃:虽然 containerd 看着小,但人家是 CNCF(云原生计算基金会)亲自罩的,不会没人管。Kubernetes 里一出啥问题,容器底层的社区老铁马上就给你支援,不怕没解决方案。咱们用它,也更省心。
现实工作中的利弊权衡
好了,咱说点实际工作中的情况吧。用 containerd 一开始可能不太习惯,尤其你要是以前 Docker 用得很熟。但公司里啥活不是从学不会到学会,containerd 这玩意儿上手成本其实也没那么高。
- 开发、测试的环境:Docker 环境用惯了,你本地开发、打包镜像还是得靠它。但是上了生产环境,部署到集群里,就用 containerd,两者配合着用,各司其职,这样效率最高。
- 从 Docker 转 containerd 的迁移成本:对,迁移成本有一些,但这就跟升级设备一样,忍一忍,等习惯了就好。这事儿吧,长痛不如短痛,公司总要向前走。切了 containerd,你会发现架构稳定性提升不止一点半点。
- 容器镜像管理:containerd 没有内置的镜像构建和分发功能,但这事儿也不难解决,反正公司内部用一些专门的镜像库(Registry),照样方便得很。大公司还会用 CI/CD 工具链串起来,哪里还用纠结这个。
总结
真要总结的话,就是这事儿早就没啥悬念了:
Docker好用在开发阶段,本地折腾项目谁都爱它;可真上生产,containerd必须安排。干活儿嘛,就要用对的工具,containerd精简稳定,省去 Docker 的各种麻烦和复杂性。咱就别纠结了,生产上用 Kubernetes 那就直接containerd,少走弯路。Containerd ctr、crictl、nerdctl 客户端命令介绍与实战操作
https://zhuanlan.zhihu.com/p/562014518Containerd 常见命令操作
更换 Containerd 后,以往我们常用的 docker 命令也不再使用,取而代之的分别是
crictl和ctr两个命令客户端。-
crictl是遵循 CRI 接口规范的一个命令行工具,通常用它来检查和管理kubelet节点上的容器运行时和镜像。 -
ctr是containerd的一个客户端工具。 -
ctr -v输出的是containerd的版本,crictl -v输出的是当前 k8s 的版本,从结果显而易见你可以认为crictl是用于k8s的。 -
一般来说你某个主机安装了 k8s 后,命令行才会有 crictl 命令。而 ctr 是跟 k8s 无关的,你主机安装了 containerd 服务后就可以操作 ctr 命令。
使用
crictl命令之前,需要先配置/etc/crictl.yaml如下:runtime-endpoint:unix:///run/containerd/containerd.sock image-endpoint:unix:///run/containerd/containerd.sock timeout:10 debug:false也可以通过命令进行设置:
crictl config runtime-endpointunix:///run/containerd/containerd.sock crictlconfigimage-endpointunix:///run/containerd/containerd.sock更多命令操作,可以直接在命令行输入命令查看帮助。
docker --help ctr --help crictl --help -
-
kubeadm init中的各种报错
-
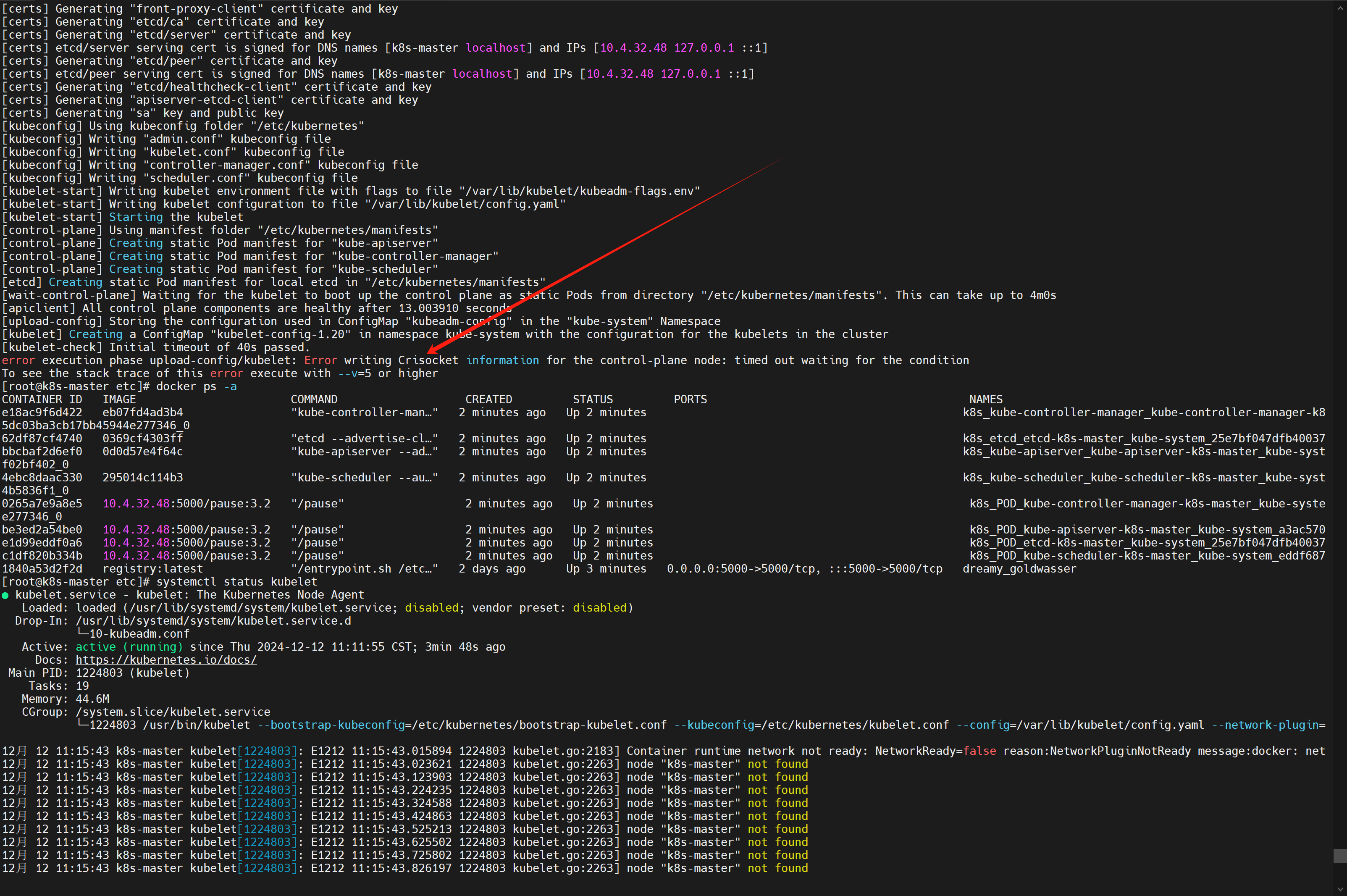
[1.20.9] 运行很顺利,但是突然报错了个蛇皮错误:
error execution phase upload-config/kubelet: Error writing Crisocket information for the control-plane node: timed out waiting for the condition![在这里插入图片描述]()
⚠️ 这个一搜就搜到了,都是同样的解决方案:
https://blog.51cto.com/u_16099200/10939353
https://blog.csdn.net/q_hsolucky/article/details/124273257
https://blog.csdn.net/weixin_41831919/article/details/118713869
swapoff -a kubeadm reset systemctl daemon-reload systemctl restart kubelet iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X其中:
-
swapoff -a:是一个用于禁用所有交换分区和交换文件的命令。在 Linux 系统中,交换空间(swap space)用于将不常用的内存页面从内存移出到磁盘上,以便释放更多的物理内存用于其他进程。使用 swapoff -a 可以将所有当前启用的交换空间禁用。在某些情况下,例如在配置 Kubernetes 集群时,可能需要禁用交换,因为 Kubernetes 对内存管理的要求不鼓励使用交换空间 -
iptables是一个用于配置 Linux 系统上的网络封包过滤规则的命令:-
iptables -F:清空所有默认表(filter表)中的规则链内的规则。也就是说,这将移除所有的输入(INPUT)、输出(OUTPUT)和转发(FORWARD)链中的规则。 -
iptables -t nat -F:清空nat表中的规则链,这将移除有关网络地址转换(NAT)的所有规则,如源地址伪装(MASQUERADE)和端口映射(DNAT, SNAT)等。 -
iptables -t mangle -F:清空mangle表中的规则链,它主要用于对数据包的服务类型(TOS)、TTL等进行修改。 -
iptables -X:删除用户自定义链。这个命令不会影响默认的规则链(如 INPUT、OUTPUT、FORWARD),但会删除所有用户自定义的链。
总结起来,这一系列命令的作用是清空
iptables中的所有规则和用户自定义的链,恢复到一个相对“干净”的状态。要注意的是,执行这些命令后,可能会导致你当前的防火墙策略失效,导致机器变得不安全,因此要慎重操作 -
⚠️ 其次是一个docker的问题,可能是我的docker版本太高了或者其他的原因:
detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”.参考:https://blog.csdn.net/zhyysj01/article/details/130965489
解决:在
/etc/docker/daemon.json中加一个配置,然后重启docker服务就行{ "exec-opts": ["native.cgroupdriver=systemd"] }然后查看一下:
docker info | grep Cgroup,现在是 systemd 了 -
-
[1.31.3] 问题就多了,这也是导致我最后弃坑1.31.3继续的原因,很难下去了,以后再研究吧
-
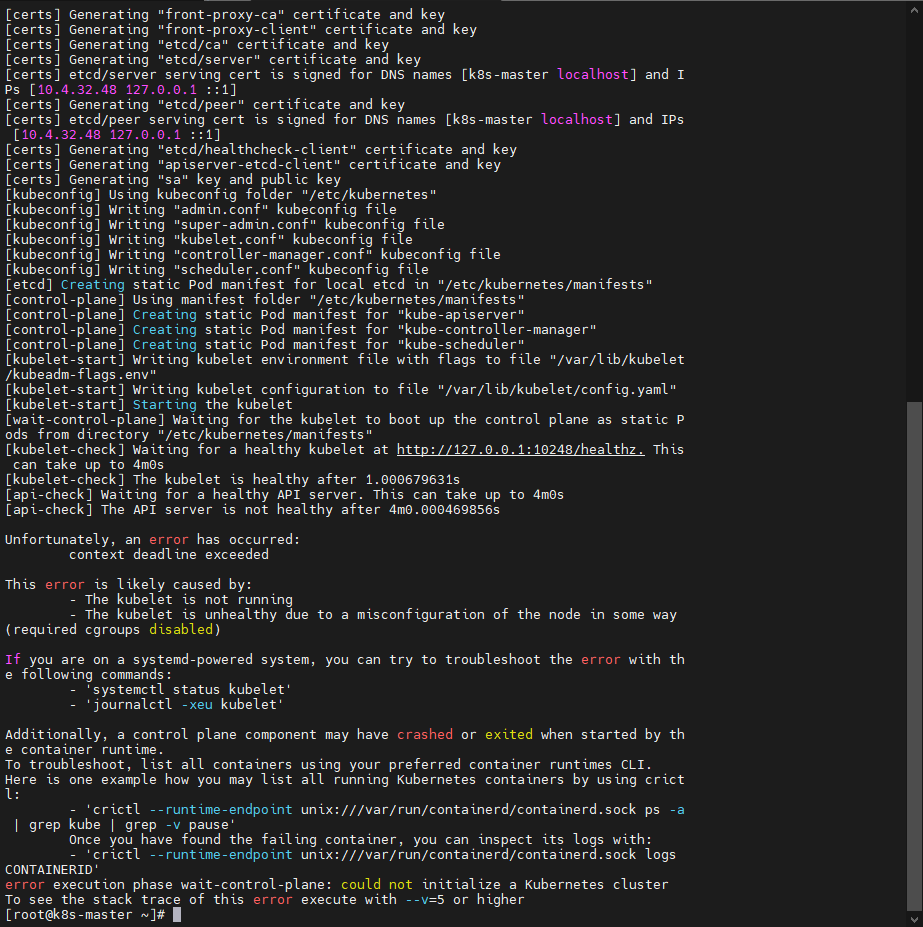
报错了,
crictl ps -a发现etcd和apiserver都没起来![在这里插入图片描述]()
![在这里插入图片描述]()
-
crictl logs etcd的容器ID发现,很多路径都没有权限:open /etc/kubernetes/pki/etcd/peer.key: permission denied"我直接
chmod 666整上了:chmod 666 /etc/kubernetes/pki/etcd/peer.keychmod 666 /etc/kubernetes/pki/etcd/server.key- 然后把挂了的 etcd 和 apiserver 删掉,一会儿就自动起来了
注意:不要
kubeadm reset一下,重新来过,还是会没权限,因为每次都是重来。![在这里插入图片描述]()
-
当我们
crictl ps -a的时候发现警告WARN[0000] runtime connect using default endpoints: [unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead. WARN[0000] image connect using default endpoints: [unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.参考:https://www.cnblogs.com/zmh520/p/18393109
-
修改
crictl的配置文件:vim /etc/crictl.yamlruntime-endpoint: "unix:///run/containerd/containerd.sock" timeout: 0 debug: false -
重启
containerd:systemctl restart containerd
-
❌ 到这里发现
kubectl get nodes还是不行,就暂时放弃了,安心搞1.20.9版本的k8s -
-
-
设置
.kube/config报错Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")略微一搜:https://download.csdn.net/blog/column/11866583/126112342
好家伙,难不成是之前1.31.4的残留导致的,我直接:
rm -rf $HOME/.kube,再重复 📍 中的三行命令即可。真有我的,解决!:happy: -
安装 calico 报错:
kubectl apply -f calico.yamlerror: unable to recognize "calico.yaml": no matches for kind "PodDisruptionBudget" in version "policy/v1"⚠️ 发现是当前k8s不支持calico的版本
https://blog.csdn.net/weixin_45379855/article/details/125175823
那是当然啊,我下的最新的calico,了解了一下,应该选v3.20
https://docs.projectcalico.org/v3.20/manifests/calico.yaml
再安装就成功啦 🎉
-
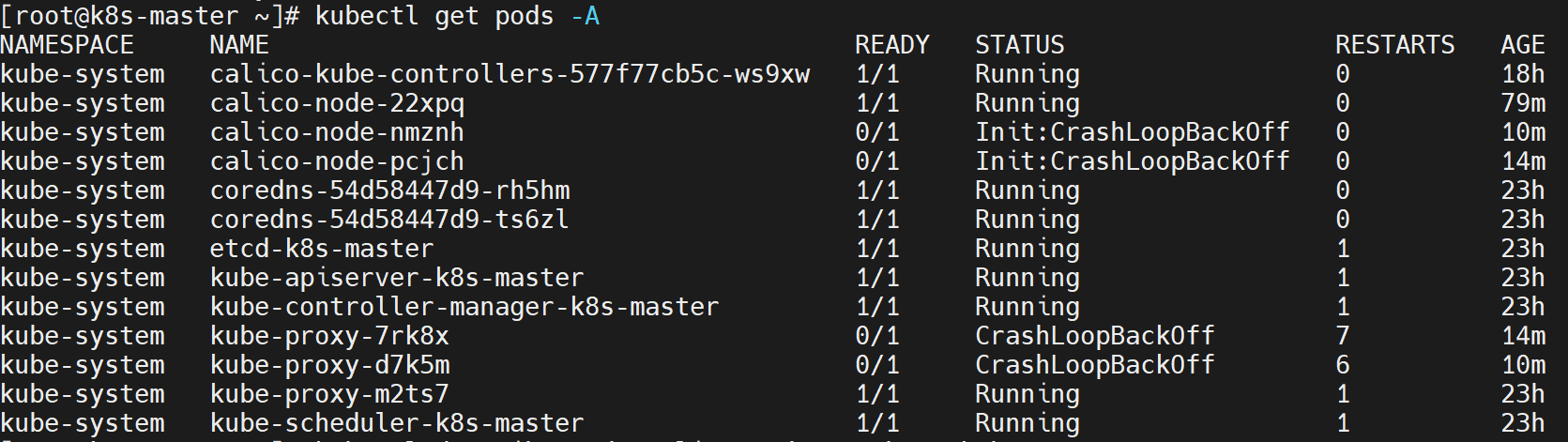
Work节点都Ready了,但是其实pod没有ready
⚠️ 从主节点上看到工作节点虽然都ready了,但是!
kubectl get pods -A会发现,有的pod没有启起来![在这里插入图片描述]()
-
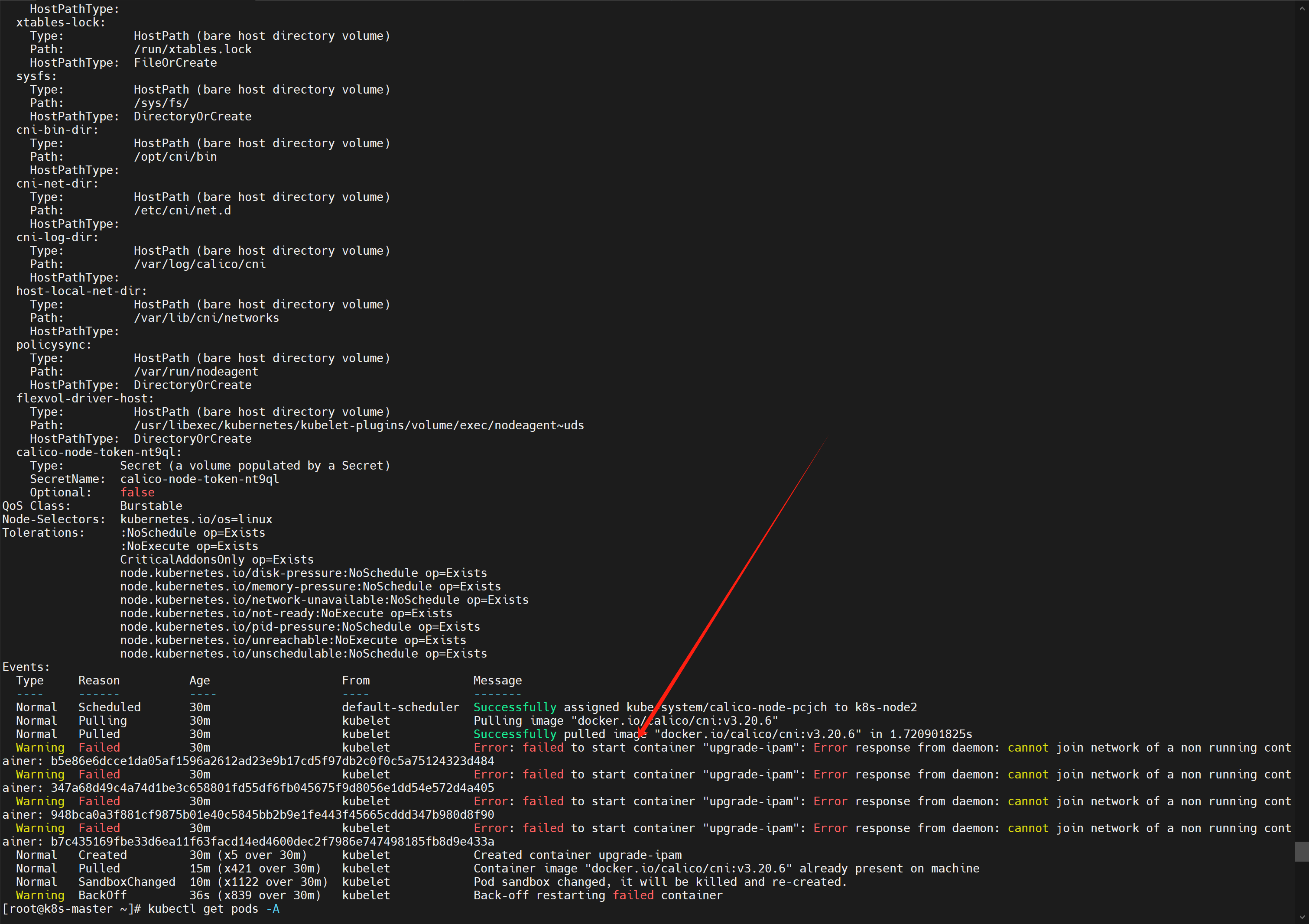
用
kubectl describe pod 【pod名】 -n 【命名空间】看可以发现,是子节点容器启不起来的问题![在这里插入图片描述]()
-
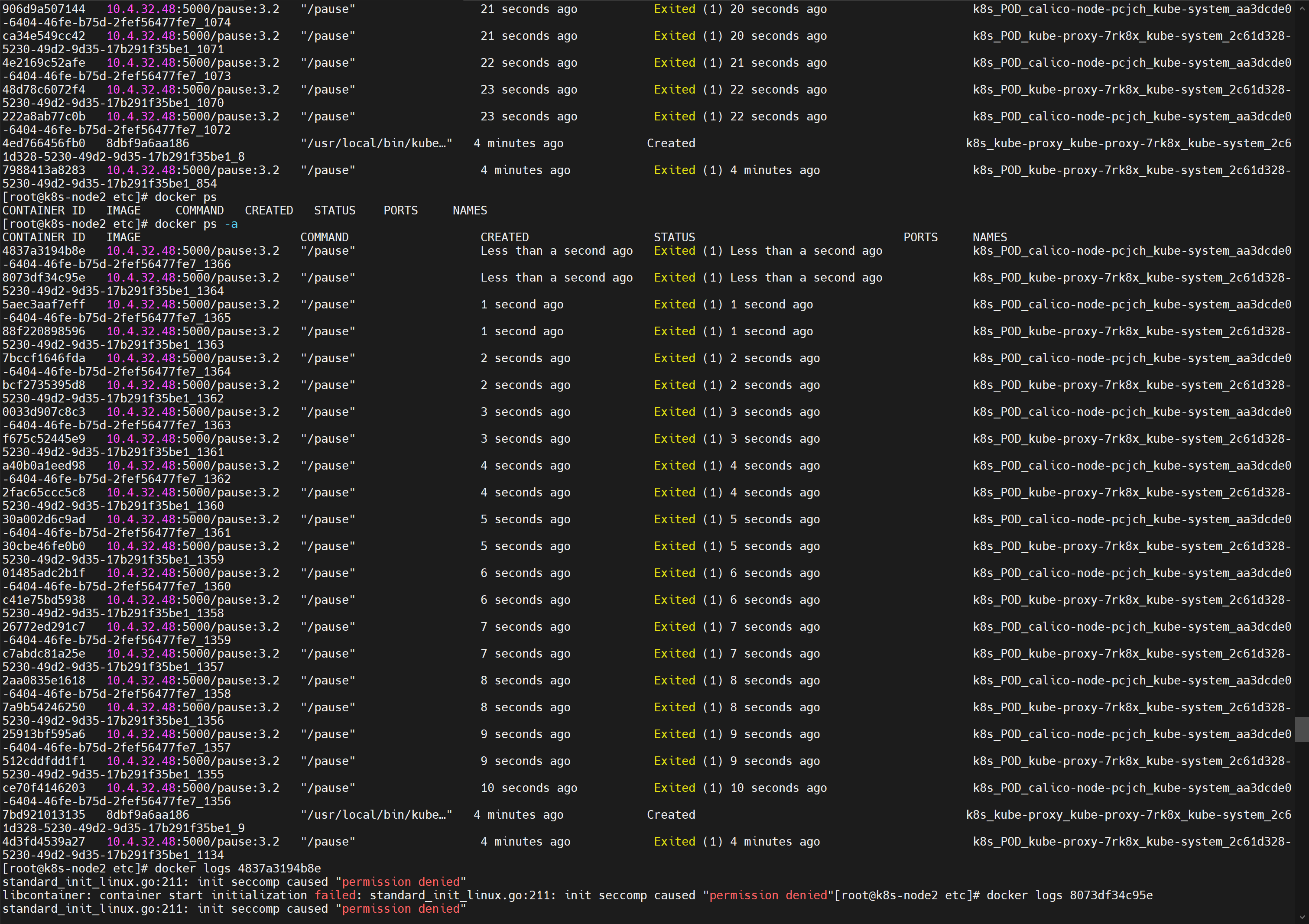
熟悉吗!我太熟悉了!我去work的节点一看
docker ps -a,好家伙一堆卡卡失败的啊,找一个失败的进去看看docker logs 【容器ID】,报错如下。我百度一查 seccomp,虽然看不懂啊,但我看到了一个关键词 podman,好家伙,这个我熟悉啊,银河麒麟docker的最大绊脚石!standard_init_linux.go:211: init seccomp caused "permission denied" libcontainer: container start initialization failed: standard_init_linux.go:211: init seccomp caused "permission denied"![在这里插入图片描述]()
解决:
yum remove podman,好家伙,我踏马怎么能忘记这个!全部就自己running了,醉醉的。![在这里插入图片描述]()
-
-
dashboard打不开,报错:
10.4.32.50 通常会使用加密技术来保护您的信息。Chrome 此次尝试连接到 10.4.32.50 时,该网站发回了异常的错误凭据。这可能是因为有攻击者在试图冒充 10.4.32.50,或者 Wi-Fi 登录屏幕中断了此次连接。请放心,您的信息仍然是安全的,因为 Chrome 尚未进行任何数据交换便停止了连接。 您目前无法访问10.4.32.50,因为此网站发送了Chrome无法处理的杂乱凭据。网络错误和攻击通常是暂时的,因此,此网页稍后可能会恢复正常。解决:只能说很神奇,你只需要在当前页面输入
thisisunsafe,就完事儿了,我擦真的很神奇,你看不到你的输入,就是盲打,打完就跳转了。并且后面都是直接跳转了


- ☁️ 我的CSDN:
https://blog.csdn.net/qq_21579045 - ❄️ 我的博客园:
https://www.cnblogs.com/lyjun/ - ☀️ 我的Github:
https://github.com/TinyHandsome - 🌈 我的bilibili:
https://space.bilibili.com/8182822 - 🍅 我的知乎:
https://www.zhihu.com/people/lyjun_ - 🐧 粉丝交流群:1060163543,神秘暗号:为干饭而来
碌碌谋生,谋其所爱。🌊 @李英俊小朋友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号