《TensorFlow实战Google深度学习框架(第二版)》学习笔记及书评
《TensorFlow实战Google深度学习框架(第二版)》学习笔记
写在前面
-
封面

-
读后感
-
先说结论:不推荐
-
这本书我老老实实从头到尾看了一遍,所有的代码都是手敲了一遍。这本书对于想TensorFlow入门的小伙伴来说,可以看到 第8章 了解一下循环神经网络的原理,第8章最后的例子举的真的是很烂,用循环神经网络去预测sin函数曲线,我是真的佩服这种例子都能想得出来。循环神经网络,不应该找一个经典的,与时间有关的具有时间累积效应的例子之类的吗,比如说钢材随时间的损坏程度之类的(我瞎编的)。后面的第9章写的真的是,可能是我理解能力不够,一个完整的例子就完完整整把代码铺上可以吗?前面说过的代码也铺上可以吗,不会重复的。书里总是出现各种各样的函数,说前面介绍过了,这里与前面类似所以不写了。一个完整的处理框架这么重要的函数说不写就不写了吗?真的是对于我这种读者造成了非常大的困扰。洋洋洒洒那么多代码敲下来,最后因为被省略的代码,导致这个程序无法运行。也不能与书中给出的结果相比对,真的是气炸了。。。书里还有很多数据处理的部分,在前面处理了一部分数据,给出了处理数据的框架,到后面完整版代码的时候,处理数据部分就省略了。所以读者并不知道数据长啥样,然后就给出结果了,为了证明这个程序是能跑的,结果一粘贴,太不负责任了吧。(特别是第9章自然语言处理部分,明明不知道数据是啥样,还是硬着头皮把所有的代码敲了一遍,哎。。。)
-
下面是Page250关于Seq2Seq模型的代码实现数据部分的代码
# 假设输入数据已经用了9.2.1小节中的方法转换成了单词编号的格式。 SRC_TRAIN_DATA = "/path/to/data/train.en" 源语言输入文件。 TRG_TRAIN_DATA = "/path/to/data/train.zh" 目标语言输入文件。 -
我只想说假如你妹啊,这里把数据长啥样和数据处理部分加进来不行吗,我也没有train.en也没有train.zh。这个翻译模型我连样本都没有玩个锤子啊。。。

-
以上仅代表个人观点,本人表达能力理解能力都有限,如果感觉我言辞激烈,那肯定是你理解的问题。。。
-
1. TensorFlow图像处理函数学习总结
-
图像编码处理+图像大小调整+图像翻转+图像色彩调整+处理标注框
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: figure_deal_test1.py @time: 2019/1/21 10:06 @desc: 用TensorFlow对jpeg格式图像进行编码/解码 """ # matplotlib.pyplot是一个python的画图工具。在这一节中使用这个工具来可视化经过TensorFlow处理的图像。 import matplotlib.pyplot as plt import tensorflow as tf # 读取图像的原始数据。 image_raw_data = tf.gfile.FastGFile('F:/Python3Space/figuredata_deal/krystal.jpg', 'rb').read() with tf.Session() as sess: # 对图像进行jpeg的格式解码从而得到图相对应的三维矩阵。TensorFlow还提供了tf.image.decode_png函数对png格式的图像进行解码。 # 解码之后的结果为一个张量,在使用它的取值之前需要明确调用运行的过程。 img_data = tf.image.decode_jpeg(image_raw_data) imag_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32) # 调整图像调整大小 # 0:双线性插值法 resized_0 = tf.image.resize_images(imag_data, [300, 300], method=0) # 1:最近邻居法 resized_1 = tf.image.resize_images(imag_data, [300, 300], method=1) # 2:双三次插值法 resized_2 = tf.image.resize_images(imag_data, [300, 300], method=2) # 3:面积插值法 resized_3 = tf.image.resize_images(imag_data, [300, 300], method=3) # 对图像进行裁剪和填充 croped = tf.image.resize_image_with_crop_or_pad(imag_data, 1000, 1000) padded = tf.image.resize_image_with_crop_or_pad(imag_data, 3000, 3000) # 用过比例调整图像大小 central_cropped = tf.image.central_crop(imag_data, 0.5) # 将图像上下翻转 flipped_0 = tf.image.flip_up_down(imag_data) # 将图像左右翻转 flipped_1 = tf.image.flip_left_right(imag_data) # 将图像沿对角线翻转 transposed = tf.image.transpose_image(imag_data) # 随机图像翻转 flipped_2 = tf.image.random_flip_up_down(imag_data) flipped_3 = tf.image.random_flip_left_right(imag_data) # 图像亮度调整 adjusted = tf.image.adjust_brightness(imag_data, -0.5) # 色彩调整的API可能导致像素的实数值超出0.0-1.0的范围,因此在输出最终图像前需要将其值截断在0.0-1.0范围区内,否则 # 不仅图像无法正常可视化,以此为输入的神经网络的训练质量也可能收到影响。 adjusted_0 = tf.clip_by_value(adjusted, 0.0, 1.0) # 将图像的亮度+0.5 adjusted = tf.image.adjust_brightness(imag_data, 0.5) adjusted_1 = tf.clip_by_value(adjusted, 0.0, 1.0) # 在[-max_delta, max_delta)的范围随机调整图像的亮度。 adjusted_2 = tf.image.random_brightness(imag_data, max_delta=0.5) # 改变图像的对比度 adjusted_3 = tf.image.adjust_contrast(imag_data, 0.5) adjusted_4 = tf.image.adjust_contrast(imag_data, 5) adjusted_5 = tf.image.random_contrast(imag_data, 0.1, 10) # 调整图像色相 adjusted_6 = tf.image.adjust_hue(imag_data, 0.1) adjusted_7 = tf.image.adjust_hue(imag_data, 0.6) adjusted_8 = tf.image.random_hue(imag_data, 0.3) # 调整图像饱和度 adjusted_9 = tf.image.adjust_saturation(imag_data, -5) adjusted_10 = tf.image.adjust_saturation(imag_data, 5) adjusted_11 = tf.image.random_saturation(imag_data, 0, 5) # 图像标准化:将图像上的亮度均值变为0,方差变为1,。 adjusted_12 = tf.image.per_image_standardization(imag_data) # 处理标注框 # 将图像缩小一些,这样可视化能让标准框更加清楚。 # img_data_deal = tf.image.resize_images(imag_data, [180, 267], method=1) # 图像的输入是一个batch的数据,也就是多张图像组成四维矩阵,所以需要将解码之后的图像矩阵加一维 batched_1 = tf.expand_dims(tf.image.convert_image_dtype(img_data, tf.float32), 0) boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]]) result = tf.image.draw_bounding_boxes(batched_1, boxes) # 随机截取图像上有信息含量的部分 # 可以通过提供标注框的方式来告诉随机截取图像的算法哪些部分是“有信息量”的 begin, size, bbox_for_draw = tf.image.sample_distorted_bounding_box(tf.shape(img_data), bounding_boxes=boxes, min_object_covered=0.4) # 通过标注框可视化随机截取得到的图像 batched_2 = tf.expand_dims(tf.image.convert_image_dtype(img_data, tf.float32), 0) image_with_box = tf.image.draw_bounding_boxes(batched_2, bbox_for_draw) # 截取随机出来的图像。 distorted_image = tf.slice(img_data, begin, size) plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体) plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题) # ''' fig1 = plt.figure(1, (16, 16), dpi=250) ax = plt.subplot(331) ax.set_title('原图') plt.imshow(imag_data.eval()) ax = plt.subplot(332) ax.set_title('双线性插值法') plt.imshow(resized_0.eval()) ax = plt.subplot(333) ax.set_title('最近邻居法') plt.imshow(resized_1.eval()) ax = plt.subplot(334) ax.set_title('双三次插值法') plt.imshow(resized_2.eval()) ax = plt.subplot(335) ax.set_title('面积插值法') plt.imshow(resized_3.eval()) ax = plt.subplot(336) ax.set_title('对图像进行裁剪') plt.imshow(croped.eval()) ax = plt.subplot(337) ax.set_title('对图像进行填充') plt.imshow(padded.eval()) ax = plt.subplot(338) ax.set_title('比例调整图像大小') plt.imshow(central_cropped.eval()) fig2 = plt.figure(2, (16, 16), dpi=250) ax = plt.subplot(331) ax.set_title('图像上下反翻转') plt.imshow(flipped_0.eval()) ax = plt.subplot(332) ax.set_title('图像左右翻转') plt.imshow(flipped_1.eval()) ax = plt.subplot(333) ax.set_title('沿对角线翻转') plt.imshow(transposed.eval()) ax = plt.subplot(334) ax.set_title('随机上下翻转') plt.imshow(flipped_2.eval()) ax = plt.subplot(335) ax.set_title('随机左右翻转') plt.imshow(flipped_3.eval()) ax = plt.subplot(336) ax.set_title('亮度调整-0.5') plt.imshow(adjusted_0.eval()) ax = plt.subplot(337) ax.set_title('亮度调整+0.5') plt.imshow(adjusted_1.eval()) ax = plt.subplot(338) ax.set_title('亮度随机调整') plt.imshow(adjusted_2.eval()) fig3 = plt.figure(3, (16, 16), dpi=250) ax = plt.subplot(331) ax.set_title('对比度调整+0.5') plt.imshow(adjusted_3.eval()) ax = plt.subplot(332) ax.set_title('对比度调整+5') plt.imshow(adjusted_4.eval()) ax = plt.subplot(333) ax.set_title('对比度随机调整') plt.imshow(adjusted_5.eval()) ax = plt.subplot(334) ax.set_title('色相调整+0.1') plt.imshow(adjusted_6.eval()) ax = plt.subplot(335) ax.set_title('色相调整+0.6') plt.imshow(adjusted_7.eval()) ax = plt.subplot(336) ax.set_title('色相随机调整') plt.imshow(adjusted_8.eval()) ax = plt.subplot(337) ax.set_title('饱和度调整-5') plt.imshow(adjusted_9.eval()) ax = plt.subplot(338) ax.set_title('饱和度调整+5') plt.imshow(adjusted_10.eval()) ax = plt.subplot(339) ax.set_title('饱和度随机调整') plt.imshow(adjusted_11.eval()) # ''' fig4 = plt.figure(4, (16, 16), dpi=250) ax = plt.subplot(221) ax.set_title('图像标准化') plt.imshow(adjusted_12.eval()) ax = plt.subplot(222) ax.set_title('处理标注框') plt.imshow(result[0].eval()) ax = plt.subplot(223) ax.set_title('随机生成的包含一定信息量的边框') plt.imshow(image_with_box[0].eval()) ax = plt.subplot(224) ax.set_title('随机截取图像上信息含量的部分') plt.imshow(distorted_image.eval()) # 使用pyplot工具可视化得到的图像。 # plt.show() # ''' fig1.savefig('F:/Python3Space/figuredata_deal/figure1.jpg', bbox_inches='tight') fig2.savefig('F:/Python3Space/figuredata_deal/figure2.jpg', bbox_inches='tight') fig3.savefig('F:/Python3Space/figuredata_deal/figure3.jpg', bbox_inches='tight') # ''' fig4.savefig('F:/Python3Space/figuredata_deal/figure4.jpg', bbox_inches='tight') # 将表示一张图像的三维矩阵重新按照jpeg格式编码并存入文件中,打开这张图像,可以得到和原始图像一样的图像。 # encoded_image = tf.image.encode_jpeg(imag_data) # with tf.gfile.GFile('C:/Users/Administrator/Desktop/Python3Space/figuredata_deal/output.jpg', 'wb') as f: # f.write(encoded_image.eval()) -
运行结果:






2. TensorFlow图像预处理完整样例
-
以下TensorFlow程序完成了从图像片段截取,到图像大小调整再到图像翻转及色彩调整的整个图像预处理过程
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: figure_deal_test2.py @time: 2019/1/28 11:39 @desc: 图像预处理完整样例 """ import tensorflow as tf import numpy as np import matplotlib.pyplot as plt # 给定一张图像,随机调整图像的色彩。因为调整亮度,对比度,饱和度和色相的顺序会影响最后得到的结果。 # 所以可以定义多种不同的顺序。具体使用哪一种顺序可以在训练数据预处理时随机地选择一种。 # 这样可以进一步降低无关因素对模型的影响。 def distort_color(image, color_ordering=0): if color_ordering == 0: image = tf.image.random_brightness(image, max_delta=32. / 255.) image = tf.image.random_saturation(image, lower=0.5, upper=1.5) image = tf.image.random_hue(image, max_delta=0.2) image = tf.image.random_contrast(image, lower=0.5, upper=1.5) elif color_ordering == 1: image = tf.image.random_saturation(image, lower=0.5, upper=1.5) image = tf.image.random_brightness(image, max_delta=32. / 255.) image = tf.image.random_contrast(image, lower=0.5, upper=1.5) image = tf.image.random_hue(image, max_delta=0.2) elif color_ordering == 2: # 还可以定义其他的排列,但是在这里就不再一一列出了。 # ... pass return tf.clip_by_value(image, 0.0, 1.0) # 给定一张解码后的图像、目标图像的尺寸以及图像上的标注框,此函数可以对给出的图像进行预处理。 # 这个函数的输入图像是图像识别问题中原始的训练图像,而输出则是深井网络模型的输入层。注意这里 # 只是处理模型的训练数据,对于预测的数据,一般不需要使用随机变换的步骤。。 def preprocess_for_train(image, height, width, bbox): # 如果没有提供标注框,则认为整个图像就是需要关注的部分。 if bbox is None: bbox = tf.constant([0.0, 0.0, 1.0, 1.0], dtype=tf.float32, shape=[1, 1, 4]) # 转换图像张量的类型。 if image.dtype != tf.float32: image = tf.image.convert_image_dtype(image, dtype=tf.float32) # 随机截取图像,减小需要关注的物体大小对图像识别算法的影响。 bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box(tf.shape(image), bounding_boxes=bbox) distorted_image = tf.slice(image, bbox_begin, bbox_size) # 将随机截取的图像调整为神经网络层输入层的大小。大小调整的算法是随机选择的。 distorted_image = tf.image.resize_images(distorted_image, [height, width], method=np.random.randint(4)) # 随机左右翻转图像。 distorted_image = tf.image.random_flip_left_right(distorted_image) # 使用一种随机的顺序调整图像色彩。 distorted_image = distort_color(distorted_image, np.random.randint(2)) return distorted_image image_raw_data = tf.gfile.FastGFile('F:/Python3Space/figuredata_deal/krystal.jpg', "rb").read() with tf.Session() as sess: img_data = tf.image.decode_jpeg(image_raw_data) boxes = tf.constant([[[0.05, 0.05, 0.9, 0.7], [0.35, 0.47, 0.5, 0.56]]]) # 开始绘图 plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体) plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题) fig1 = plt.figure(1, (16, 9), dpi=100) # 运行6次获得6种不同的图像。 for i in range(6): # 将图像的尺寸调整为299*299. ax = plt.subplot(2, 3, i+1) ax.set_title('运行第' + str(i+1) + '次的图像') result = preprocess_for_train(img_data, 299, 299, boxes) plt.imshow(result.eval()) fig1.subplots_adjust(wspace=0.1) # plt.tight_layout() plt.savefig('F:/Python3Space/figuredata_deal/图像预处理完整样例.jpg', bbox_inches='tight') -
运行结果:

3. TensorFlow多线程输入数据处理框架
3.1 队列与多线程
-
对于队列,修改队列状态的操作主要有Enqueue、EnqueueMany和Dequeue。以下程序展示了如何使用这些函数来操作一个队列
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: queue_operate.py @time: 2019/1/31 21:32 @desc: 操作一个队列 """ import tensorflow as tf # 创建一个先进先出的队列,指定队列中最多可以保存两个元素,并指定类型为整数 q = tf.FIFOQueue(2, "int32") # 使用enqueue_many函数来初始化队列中的元素。和变量初始化类似,在使用队列之前需要明确的调用这个初始化过程。 init = q.enqueue_many(([0, 10],)) # 使用Dequeue函数将队列中的第一个元素出队列。这个元素的值将被存在变量x中 x = q.dequeue() # 将得到的值+1 y = x + 1 # 将+1后的值再重新加入队列。 q_inc = q.enqueue([y]) with tf.Session() as sess: # 运行初始化队列的操作 init.run() for _ in range(5): # 运行q_inc将执行数据出队列、出队的元素+1、重新加入队列的整个过程。 v, _ = sess.run([x, q_inc]) # 打印出队元素的取值 print(v) -
运行结果:

-
tf.Coordinator主要用于协同多个线程一起停止,以下程序展示了如何使用tf.Coordinator
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: coordinator_test1.py @time: 2019/2/2 21:35 @desc: tf.Coordinator主要用于协同多个线程一起停止,以下程序展示了如何使用tf.Coordinator """ import tensorflow as tf import numpy as np import threading import time # 线程中运行的程序,这个程序每隔1秒判断是否需要停止并打印自己的ID。 def MyLoop(coord, worker_id): # 使用tf.Coordinator类提供的协同工具判断当前线程是否需要停止 while not coord.should_stop(): # 随机停止所有的线程。 if np.random.rand() < 0.1: print("Stoping from id: %d\n" % worker_id) # 调用coord.request_stop()函数来通知其他线程停止。 coord.request_stop() else: # 打印当前线程的Id。 print("Working on id: %d\n" % worker_id) # 暂停1秒 time.sleep(1) # 声明一个tf.train.Coordinator类来协同多个线程。 coord = tf.train.Coordinator() # 声明创建5个线程。 threads = [threading.Thread(target=MyLoop, args=(coord, i, )) for i in range(5)] # 启动所有的线程 for t in threads: t.start() # 等待所有线程退出 coord.join(threads) -
运行结果:

-
如何使用tf.QueueRunner和tf.Coordinator来管理多线程队列操作
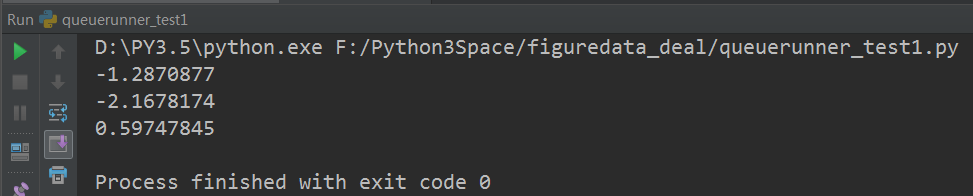
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: queuerunner_test1.py @time: 2019/2/3 12:31 @desc: 如何使用tf.QueueRunner和tf.Coordinator来管理多线程队列操作。 """ import tensorflow as tf # 声明一个先进先出的队列,队列中最多100个元素,类型为实数 queue = tf.FIFOQueue(100, "float") # 定义队列的入队操作 enqueue_op = queue.enqueue([tf.random_normal([1])]) # 使用tf.train.QueueRunner来创建多个线程运行队列的入队操作。 # tf.train.QueueRunner的第一个参数给出了被操作的队列,[enqueue_op] * 5 # 表示了需要启动5个线程,每个线程中运行的是enqueue_op操作 qr = tf.train.QueueRunner(queue, [enqueue_op] * 5) # 将定义过的QueueRunner加入Tensorflow计算图上指定的集合。 # tf.train.add_queue_runner函数没有指定集合 # 则加入默认集合tf.GraphKeys.QUEUE_RUNNERS。下面的函数就是将刚刚定义的 # qr加入默认的tf.GraphKeys.QUEUE_RUNNER集合。 tf.train.add_queue_runner(qr) # 定义出队操作 out_tensor = queue.dequeue() with tf.Session() as sess: # 使用tf.train.Coordinator来协同启动的线程。 coord = tf.train.Coordinator() # 使用tf.train.QueueRunner时,需要明确调用tf.train.start_queue_runners # 来启动所有线程。否则因为没有线程运行入队操作,当调用出队操作的时候,程序会一直 # 等待入队操作被运行。tf.train.start_queue_runners函数会默认启动 # tf.GraphKeys.QUEUE_RUNNERS集合中所有的QueueRunner。因为这个函数值支持启动 # 指定集合中的QueueRunner,所以一般来说tf.train.add_queue_runner函数和 # tf.trian.start_queue_runners函数会指定同一个集合。 threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 获取队列中的取值。 for _ in range(3): print(sess.run(out_tensor)[0]) # 使用tf.train.Coordinator来停止所有的线程 coord.request_stop() coord.join(threads) -
运行结果:
![img]()
3.2 输入文件队列
-
一个简单的程序来生成样例数据
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: sample_data_produce1.py @time: 2019/2/3 21:46 @desc: 一个简单的程序来生成样例数据 """ import tensorflow as tf # 创建TFRecord文件的帮助函数 def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 模拟海量数据情况下将数据写入不同的文件。num_shards定义了总共写入多少个文件 # instances_per_shard定义了每个文件中有多少个数据 num_shards = 2 instances_per_shard = 2 for i in range(num_shards): # 将数据分为多个文件时,可以将不同文件以类似0000n-of-0000m的后缀区分。其中m表示了 # 数据总共被存在了多少个文件,n表示当前文件的编号。式样的方式既方便了通过正则表达式 # 获取文件列表,又在文件名中加入了更多的信息。 filename = ('./data.tfrecords-%.5d-of-%0.5d' % (i, num_shards)) writer = tf.python_io.TFRecordWriter(filename) # 将数据封装成Example结构并写入TFRecord文件 for j in range(instances_per_shard): # Example结构仅包含当前样例属于第几个文件以及是当前文件的第几个样本 example = tf.train.Example(features=tf.train.Features(feature={ 'i': _int64_feature(i), 'j': _int64_feature(j) })) writer.write(example.SerializeToString()) writer.close() -
运行结果:
-
展示了tf.train.match_filenames_once函数和tf.train.string_input_producer函数的使用方法
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: sample_data_deal1.py @time: 2019/2/3 22:00 @desc: 展示了tf.train.match_filenames_once函数和tf.train.string_input_producer函数的使用方法 """ import tensorflow as tf # 使用tf.train.match_filenames_once函数获取文件列表 files = tf.train.match_filenames_once('./data.tfrecords-*') # 通过tf.train.string_input_producer函数创建输入队列,输入队列中的文件列表为 # tf.train.match_filenames_once函数获取的文件列表。这里将shuffle参数设为False # 来避免随机打乱读文件的顺序。但一般在解决真实问题时,会将shuffle参数设置为True filename_queue = tf.train.string_input_producer(files, shuffle=False) # 如前面所示读取并解析一个样本 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'i': tf.FixedLenFeature([], tf.int64), 'j': tf.FixedLenFeature([], tf.int64), } ) with tf.Session() as sess: # 虽然在本段程序中没有声明任何变量,但使用tf.train.match_filenames_once函数时 # 需要初始化一些变量。 tf.local_variables_initializer().run() print(sess.run(files)) # 声明tf.train.Coordinator类来协同不同线程,并启动线程。 coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 多次执行获取数据的操作 for i in range(6): print(sess.run([features['i'], features['j']])) # 请求处理的线程停止 coord.request_stop() # 等待,直到处理的线程已经停止 coord.join(threads) -
运行结果:

3.3 组合训练数据
-
通过TensorFlow提供的tf.train.batch和tf.train.shuffle_batch函数来将单个的样例组织成batch的形式输出
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: sample_data_deal2.py @time: 2019/2/4 11:15 @desc: 通过TensorFlow提供的tf.train.batch和tf.train.shuffle_batch函数来将单个的样例组织成batch的形式输出。 """ import tensorflow as tf # 使用tf.train.match_filenames_once函数获取文件列表 files = tf.train.match_filenames_once('./data.tfrecords-*') # 通过tf.train.string_input_producer函数创建输入队列,输入队列中的文件列表为 # tf.train.match_filenames_once函数获取的文件列表。这里将shuffle参数设为False # 来避免随机打乱读文件的顺序。但一般在解决真实问题时,会将shuffle参数设置为True filename_queue = tf.train.string_input_producer(files, shuffle=False) # 如前面所示读取并解析一个样本 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'i': tf.FixedLenFeature([], tf.int64), 'j': tf.FixedLenFeature([], tf.int64), } ) # 使用前面的方法读取并解析得到的样例。这里假设Example结构中i表示一个样例的特征向量 # 比如一张图像的像素矩阵。而j表示该样例对应的标签。 example, label = features['i'], features['j'] # 一个batch中样例的个数。 batch_size = 3 # 组合样例的队列中最多可以存储的样例个数。这个队列如果太大,那么需要占用很多内存资源; # 如果太小,那么出队操作可能会因为没有数据而被阻碍(block),从而导致训练效率降低。 # 一般来说这个队列的大小会和每一个batch的大小相关,下面一行代码给出了设置队列大小的一种方式。 capacity = 1000 + 3 * batch_size # 使用tf.train.batch函数来组合样例。[example, label]参数给出了需要组合的元素, # 一般example和label分别代表训练样本和这个样本对应的正确标签。batch_size参数给出了 # 每个batch中样例的个数。capacity给出了队列的最大容量。每当队列长度等于容量时, # TensorFlow将暂停入队操作,而只是等待元素出队。当元素个数小于容量时, # TensorFlow将自动重新启动入队操作。 # example_batch, label_batch = tf.train.batch([example, label], batch_size=batch_size, capacity=capacity) # 使用tf.train.shuffle_batch函数来组合样例。tf.train.shuffle_batch函数的参数 # 大部分都和tf.train.batch函数相似,但是min_after_dequeue参数是tf.train.shuffle_batch # 函数特有的。min_after_dequeue参数限制了出队时队列中元素的最少个数。当队列中元素太少时, # 随机打乱样例顺序的作用就不大了。所以tf.train.shuffle_batch函数提供了限制出队时最少元素的个数 # 来保证随机打乱顺序的作用。当出队函数被调用但是队列中元素不够时,出队操作将等待更多的元素入队 # 才会完成。如果min_after_dequeue参数被设定,capacity也应该相应调整来满足性能需求。 example_batch, label_batch = tf.train.shuffle_batch([example, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=30) with tf.Session() as sess: tf.local_variables_initializer().run() tf.global_variables_initializer().run() coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 获取并打印组合之后的样例。在真实问题中,这个输出一般会作为神经网络的输入。 for i in range(2): cur_example_batch, cur_label_batch = sess.run([example_batch, label_batch]) print(cur_example_batch, cur_label_batch) coord.request_stop() coord.join(threads) -
运行结果:
-
使用tf.train.batch函数来组合样例
![img]()
-
使用tf.train.shuffle_batch函数来组合样例
![img]()
-
两个函数的区别
tf.train.batch函数不会随机打乱顺序,而tf.train.shuffle_batch会随机打乱顺序
-


3.4 输入数据处理框架
-
输入数据处理的整个流程
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: sample_data_deal.py @time: 2019/2/8 20:30 @desc: 输入数据处理框架 """ from figuredata_deal.figure_deal_test2 import preprocess_for_train import tensorflow as tf # 创建文件列表,并通过文件列表创建输入文件队列。在调用输入数据处理流程前,需要统一所有原始数据的格式 # 并将它们存储到TFRecord文件中。下面给出的文件列表应该包含所有提供训练数据的TFRecord文件。 files = tf.train.match_filenames_once('file_pattern-*') filename_queue = tf.train.string_input_producer(files, shuffle=False) # 使用类似前面介绍的方法解析TFRecord文件里的数据。这里假设image中存储的是图像的原始数据,label为该 # 样例所对应的标签。height、width和channels给出了图片的维度。 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'image': tf.FixedLenFeature([], tf.string), 'label': tf.FixedLenFeature([], tf.int64), 'height': tf.FixedLenFeature([], tf.int64), 'width': tf.FixedLenFeature([], tf.int64), 'channels': tf.FixedLenFeature([], tf.int64), } ) image, label = features['image'], features['label'] height, width = features['height'], features['width'] channels = features['channels'] # 从原始图像数据解析出像素矩阵,并根据图像尺寸还原图像。 decoded_image = tf.decode_raw(image, tf.uint8) decoded_image.set_shape([height, width, channels]) # 定义神经网络输入层图片的大小 image_size = 299 # preprocess_for_train为前面提到的图像预处理程序 distorted_image = preprocess_for_train(decoded_image, image_size, image_size, None) # 将处理后的图像和标签数据通过tf.train.shuffle_batch整理成神经网络训练时需要的batch。 min_after_dequeue = 10000 batch_size = 100 capacity = min_after_dequeue + 3 * batch_size image_batch, label_batch = tf.train.shuffle_batch([distorted_image, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue) # 定义神经网络的结构以及优化过程, image_batch可以作为输入提供给神经网络的输入层。 # label_batch则提供了输入batch中样例的正确答案。 # 学习率 learning_rate = 0.01 # inference是神经网络的结构 logit = inference(image_batch) # loss是计算神经网络的损失函数 loss = cal_loss(logit, label_batch) # 训练过程 train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) # 声明会话并运行神经网络的优化过程 with tf.Session() as sess: # 神经网络训练准备工作。这些工作包括变量初始化、线程启动。 sess.run((tf.global_variables_initializer(), tf.local_variables_initializer())) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 神经网络训练过程。 TRAINING_ROUNDS = 5000 for i in range(TRAINING_ROUNDS): sess.run(train_step) # 停止所有线程 coord.request_stop() coord.join(threads)
4. TensorFlow数据集
4.1 数据集的基本使用方法
-
例子:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出 $y = x^2$ 的值
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test1.py @time: 2019/2/10 10:52 @desc: 例子:从一个张量创建一个数据集,遍历这个数据集,并对每个输入输出y = x^2 的值。 """ import tensorflow as tf # 从一个数组创建数据集。 input_data = [1, 2, 3, 5, 8] dataset = tf.data.Dataset.from_tensor_slices(input_data) # 定义一个迭代器用于遍历数据集。因为上面定义的数据集没有用placeholder作为输入参数 # 所以这里可以使用最简单的one_shot_iterator iterator = dataset.make_one_shot_iterator() # get_next() 返回代表一个输入数据的张量,类似于队列的dequeue()。 x = iterator.get_next() y = x * x with tf.Session() as sess: for i in range(len(input_data)): print(sess.run(y)) -
运行结果:

-
数据是文本文件:创建数据集
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test2.py @time: 2019/2/10 11:03 @desc: 数据是文本文件 """ import tensorflow as tf # 从文本文件创建数据集。假定每行文字是一个训练例子。注意这里可以提供多个文件。 input_files = ['./input_file11', './input_file22'] dataset = tf.data.TextLineDataset(input_files) # 定义迭代器用于遍历数据集 iterator = dataset.make_one_shot_iterator() # 这里get_next()返回一个字符串类型的张量,代表文件中的一行。 x = iterator.get_next() with tf.Session() as sess: for i in range(4): print(sess.run(x)) -
运行结果:

-
数据是TFRecord文件:创建TFRecord测试文件
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_createdata.py @time: 2019/2/10 13:59 @desc: 创建样例文件 """ import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import numpy as np import time # 生成整数型的属性。 def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 生成字符串型的属性。 def _bytes_feature(value): return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) a = [11, 21, 31, 41, 51] b = [22, 33, 44, 55, 66] # 输出TFRecord文件的地址 filename = './input_file2' # 创建一个writer来写TFRecord文件 writer = tf.python_io.TFRecordWriter(filename) for index in range(len(a)): aa = a[index] bb = b[index] # 将一个样例转化为Example Protocol Buffer,并将所有的信息写入这个数据结构。 example = tf.train.Example(features=tf.train.Features(feature={ 'feat1': _int64_feature(aa), 'feat2': _int64_feature(bb) })) # 将一个Example写入TFRecord文件中。 writer.write(example.SerializeToString()) writer.close() -
运行结果:
-
数据是TFRecord文件:创建数据集(使用最简单的one_hot_iterator来遍历数据集)
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test3.py @time: 2019/2/10 13:16 @desc: 数据是TFRecord文件 """ import tensorflow as tf # 解析一个TFRecord的方法。record是从文件中读取的一个样例。前面介绍了如何解析TFRecord样例。 def parser(record): # 解析读入的一个样例 features = tf.parse_single_example( record, features={ 'feat1': tf.FixedLenFeature([], tf.int64), 'feat2': tf.FixedLenFeature([], tf.int64), } ) return features['feat1'], features['feat2'] # 从TFRecord文件创建数据集。 input_files = ['./input_file1', './input_file2'] dataset = tf.data.TFRecordDataset(input_files) # map()函数表示对数据集中的每一条数据进行调用相应方法。使用TFRecordDataset读出的是二进制的数据。 # 这里需要通过map()函数来调用parser()对二进制数据进行解析。类似的,map()函数也可以用来完成其他的数据预处理工作。 dataset = dataset.map(parser) # 定义遍历数据集的迭代器 iterator = dataset.make_one_shot_iterator() # feat1, feat2是parser()返回的一维int64型张量,可以作为输入用于进一步的计算。 feat1, feat2 = iterator.get_next() with tf.Session() as sess: for i in range(10): f1, f2 = sess.run([feat1, feat2]) print(f1, f2) -
运行结果:

-
数据是TFRecord文件:创建数据集(使用placeholder和initializable_iterator来动态初始化数据集)
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test4.py @time: 2019/2/10 13:44 @desc: 用initializable_iterator来动态初始化数据集的例子 """ import tensorflow as tf from figuredata_deal.dataset_test3 import parser # 解析一个TFRecord的方法。与上面的例子相同不再重复。 # 从TFRecord文件创建数据集,具体文件路径是一个placeholder,稍后再提供具体路径。 input_files = tf.placeholder(tf.string) dataset = tf.data.TFRecordDataset(input_files) dataset = dataset.map(parser) # 定义遍历dataset的initializable_iterator iterator = dataset.make_initializable_iterator() feat1, feat2 = iterator.get_next() with tf.Session() as sess: # 首先初始化iterator,并给出input_files的值。 sess.run(iterator.initializer, feed_dict={input_files: ['./input_file1', './input_file2']}) # 遍历所有数据一个epoch,当遍历结束时,程序会抛出OutOfRangeError while True: try: sess.run([feat1, feat2]) except tf.errors.OutOfRangeError: break -
运行结果:

4.2 数据集的高层操作
-
一个使用数据集进行训练和测试的完整例子
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: dataset_test5.py @time: 2019/2/12 13:45 @desc: 使用数据集实现数据输入流程 """ import tensorflow as tf from figuredata_deal.figure_deal_test2 import preprocess_for_train # 列举输入文件。训练和测试使用不同的数据 train_files = tf.train.match_filenames_once('./train_file-*') test_files = tf.train.match_filenames_once('./test_files-*') # 定义parser方法从TFRecord中解析数据。这里假设image中存储的是图像的原始数据, # label为该样例所对应的标签。height、width和channels给出了图片的维度。 def parser(record): features = tf.parse_single_example( record, features={ 'image': tf.FixedLenFeature([], tf.string), 'label': tf.FixedLenFeature([], tf.int64), 'height': tf.FixedLenFeature([], tf.int64), 'width': tf.FixedLenFeature([], tf.int64), 'channels': tf.FixedLenFeature([], tf.int64), } ) # 从原始图像数据解析出像素矩阵,并根据图像尺寸还原图像。 decoded_image = tf.decode_raw(features['image'], tf.uint8) decoded_image.set_shape([features['height'], features['width'], features['channels']]) label = features['label'] return decoded_image, label # 定义神经网络输入层图片的大小 image_size = 299 # 定义组合数据batch的大小 batch_size = 100 # 定义随机打乱数据时buffer的大小 shuffle_buffer = 10000 # 定义读取训练数据的数据集 dataset = tf.data.TFRecordDataset(train_files) dataset = dataset.map(parser) # 对数据依次进行预处理、shuffle和batching操作。preprocess_for_train为前面介绍的 # 图像预处理程序。因为上一个map得到的数据集中提供了decoded_image和label两个结果,所以这个 # map需要提供一个有2个参数的函数来处理数据。在下面的代码中,lambda中的image代表的就是第一个map返回的 # decoded_image,label代表的就是第一个map返回的label。在这个lambda表达式中我们首先将decoded_image # 在传入preprocess_for_train来进一步对图像数据进行预处理。然后再将处理好的图像和label组成最终的输出。 dataset = dataset.map( lambda image, label: ( preprocess_for_train(image, image_size, image_size, None), label ) ) dataset = dataset.shuffle(shuffle_buffer).batch(batch_size) # 重复NUM_EPOCHS个epoch。在前面TRAINING_ROUNDS指定了训练的轮数, # 而这里指定了整个数据集重复的次数,它也间接地确定了训练的论述。 NUM_EPOCHS = 10 dataset = dataset.repeat(NUM_EPOCHS) # 定义数据集迭代器。虽然定义数据集的时候没直接使用placeholder来提供文件地址,但是 # tf.train.match_filenames_once方法得到的结果和与placeholder的机制类似,也需要初始化。 # 所以这里使用的是initializable_iterator iterator = dataset.make_initializable_iterator() image_batch, label_batch = iterator.get_next() # 定义神经网络的结果以及优化过程。这里与前面的相同。 learning_rate = 0.01 logit = inference(image_batch) loss = calc_loss(logit, label_batch) train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) # 定义测试用的Dataset。与训练时不同,测试数据的Dataset不需要经过随机翻转等预处理操作, # 也不需要打乱顺序和重复多个epoch。这里使用于训练数据相同的parser进行解析,调整分辨率 # 到网络输入层大小,然后直接进行batching操作。 test_dataset = tf.data.TFRecordDataset(test_files) test_dataset = test_dataset.map(parser).map( lambda image, label: ( tf.image.resize_images(image, [image_size, image_size]), label ) ) test_dataset = test_dataset.batch(batch_size) # 定义测试数据上的迭代器 test_iterator = test_dataset.make_initializable_iterator() test_image_batch, test_label_batch = test_iterator.get_next() # 定义预测结果为logit值最大的分类 test_logit = inference(test_image_batch) predictions = tf.argmax(test_logit, axis=-1, output_type=tf.int32) # 声明会话并运行神经网络的优化过程 with tf.Session() as sess: # 初始化变量 sess.run(( tf.global_variables_initializer(), tf.local_variables_initializer() )) # 初始化训练数据的迭代器。 sess.run(iterator.initializer) # 循环进行训练,知道数据集完成输入,抛出OutOfRangeError错误 while True: try: sess.run(train_step) except tf.errors.OutOfRangeError: break # 初始化测试数据的迭代器 sess.run(test_iterator.initializer) # 获取预测结果 test_results = [] test_labels = [] while True: try: pred, label = sess.run([predictions, test_label_batch]) test_results.extend(pred) test_labels.extend(label) except tf.errors.OutOfRangeError: break # 计算准确率 correct = [float(y == y_) for (y, y_) in zip(test_results, test_labels)] accuracy = sum(correct) / len(correct) print("Test accuracy is: ", accuracy)
5. 自然语言处理
5.1 语言模型评价方法
-
两个计算交叉熵函数的区别:
tf.nn.softmax_cross_entrypy_with_logits和tf.nn.sparse_softmax_cross_entrypy_with_logits#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: different_softmax.py @time: 2019/2/19 9:30 @desc: 两个计算交叉熵函数的区别:tf.nn.softmax_cross_entrypy_with_logits和tf.nn.sparse_softmax_cross_entrypy_with_logits """ import tensorflow as tf # 假设词汇表的大小为3,语料包含两个单词“2 0” word_labels = tf.constant([2, 0]) # 假设模型对两个单词预测时,产生的logit分别是[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5] # 注意这里的logit不是概率,因此它们不是0.0~1.0范围之间的数字。如果需要计算概率, # 则需要调用prob=tf.nn.softmax(logits)。但这里计算交叉熵的函数直接输入logits即可 predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]]) # 使用sparse_softmax_cross_entropy_with_logits计算交叉熵 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits) # 运行程序,计算loss的结果是[0.32656264, 0.46436879],这对应两个预测的perplexity损失。 sess = tf.Session() x = sess.run(loss) print(x) # softmax_cross_entropy_with_logits与上面的的函数相似,但是需要将预测目标以概率分布的形式给出。 word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]]) loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits) # 运行结果与上面相同 y = sess.run(loss) print(y) # 由于softmax_cross_entropy_with_logits允许提供一个概率分布,因此在使用时有更大的自由度。 # 举个例子,一种叫label smoothing的技巧是将正确数据的概率设为一个比1.0略小的值,将错误数据的概率 # 设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。 word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]]) loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits) z = sess.run(loss) print(z) -
运行结果:

5.2 PTB数据集的预处理
-
首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: word_deal1.py @time: 2019/2/20 10:42 @desc: 首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。 """ import codecs import collections from operator import itemgetter # 训练集数据文件 RAW_DATA = "./simple-examples/data/ptb.train.txt" # 输出的词汇表文件 VOCAB_OUTPUT = "ptb.vocab" # 统计单词出现的频率 counter = collections.Counter() with codecs.open(RAW_DATA, "r", "utf-8") as f: for line in f: for word in line.strip().split(): counter[word] += 1 # 按照词频顺序对单词进行排序 sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True) sorted_words = [x[0] for x in sorted_word_to_cnt] # 稍后我们需要在文本换行处加入句子结束符“<eos>”,这里预先将其加入词汇表。 sorted_words = ["<eos>"] + sorted_words # 在后面处理机器翻译数据时,出了"<eos>",还需要将"<unk>"和句子起始符"<sos>"加入 # 词汇表,并从词汇表中删除低频词汇。在PTB数据中,因为输入数据已经将低频词汇替换成了 # "<unk>",因此不需要这一步骤。 # sorted_words = ["<unk>", "<sos>", "<eos>"] + sorted_words # if len(sorted_words) > 10000: # sorted_words = sorted_words[:10000] with codecs.open(VOCAB_OUTPUT, 'w', 'utf-8') as file_output: for word in sorted_words: file_output.write(word + "\n") -
运行结果:
![img]()

-
在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: word_deal2.py @time: 2019/2/20 11:10 @desc: 在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。 """ import codecs import sys # 原始的训练集数据文件 RAW_DATA = "./simple-examples/data/ptb.train.txt" # 上面生成的词汇表文件 VOCAB = "ptb.vocab" # 将单词替换成为单词编号后的输出文件 OUTPUT_DATA = "ptb.train" # 读取词汇表,并建立词汇到单词编号的映射。 with codecs.open(VOCAB, "r", "utf-8") as f_vocab: vocab = [w.strip() for w in f_vocab.readlines()] word_to_id = {k: v for (k, v) in zip(vocab, range(len(vocab)))} # 如果出现了被删除的低频词,则替换为"<unk>"。 def get_id(word): return word_to_id[word] if word in word_to_id else word_to_id["<unk"] fin = codecs.open(RAW_DATA, "r", "utf-8") fout = codecs.open(OUTPUT_DATA, 'w', 'utf-8') for line in fin: # 读取单词并添加<eos>结束符 words = line.strip().split() + ["<eos>"] # 将每个单词替换为词汇表中的编号 out_line = ' '.join([str(get_id(w)) for w in words]) + '\n' fout.write(out_line) fin.close() fout.close() -
运行结果:

5.3 PTB数据的batching方法
-
从文本文件中读取数据,并按照下面介绍的方案将数据整理成batch。
方法是:先将整个文档切分成若干连续段落,再让batch中的每一个位置负责其中一段。
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: word_deal3.py @time: 2019/2/23 16:36 @desc: 从文本文件中读取数据,并按照下面介绍的方案将数据整理成batch。 方法是:先将整个文档切分成若干连续段落,再让batch中的每一个位置负责其中一段。 """ import numpy as np import tensorflow as tf # 使用单词编号表示的训练数据 TRAIN_DATA = './ptb.train' TRAIN_BATCH_SIZE = 20 TRAIN_NUM_STEP = 35 # 从文件中读取数据,并返回包含单词编号的数组 def read_data(file_path): with open(file_path, "r") as fin: # 将整个文档读进一个长字符串 id_string = ' '.join([line.strip() for line in fin.readlines()]) # 将读取的单词编号转为整数 id_list = [int(w) for w in id_string.split()] return id_list def make_batches(id_list, batch_size, num_step): # batch_size: 一个batch中样本的数量 # num_batches:batch的个数 # num_step: 一个样本的序列长度 # 计算总的batch数量。每个batch包含的单词数量是batch_size * num_step num_batches = (len(id_list) - 1) // (batch_size * num_step) # 将数据整理成一个维度为[batch_size, num_batches*num_step]的二维数组 data = np.array(id_list[: num_batches * batch_size * num_step]) data = np.reshape(data, [batch_size, num_batches * num_step]) # 沿着第二个维度将数据切分成num_batches个batch,存入一个数组。 data_batches = np.split(data, num_batches, axis=1) # 重复上述操作,但是每个位置向右移动一位,这里得到的是RNN每一步输出所需要预测的下一个单词 label = np.array(id_list[1: num_batches * batch_size * num_step + 1]) label = np.reshape(label, [batch_size, num_batches * num_step]) label_batches = np.split(label, num_batches, axis=1) # 返回一个长度为num_batches的数组,其中每一项包括一个data矩阵和一个label矩阵 print(len(id_list)) print(num_batches * batch_size * num_step) return list(zip(data_batches, label_batches)) def main(): train_batches = make_batches(read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP) # 在这里插入模型训练的代码。训练代码将在后面提到。 for i in train_batches: print(i) if __name__ == '__main__': main() -
运行结果:

5.4 一个完整的训练程序
-
一个完整的训练程序,它使用一个双层LSTM作为循环神经网络的主体,并共享Softmax层和词向量层的参数
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: word_deal4.py @time: 2019/2/25 9:38 @desc: 一个完整的训练程序,它使用一个双层LSTM作为循环神经网络的主体,并共享Softmax层和词向量层的参数。 """ import numpy as np import tensorflow as tf # 训练数据路径 TRAIN_DATA = "ptb.train" # 验证数据路径 EVAL_DATA = "ptb.valid" # 测试数据路径 TEST_DATA = "ptb.test" # 隐藏层规模 HIDDEN_SIZE = 300 # 深层循环神经网络中LSTM结构的层数 NUM_LAYERS = 2 # 词典规模 VOCAB_SIZE = 10000 # 训练数据batch的大小 TRAIN_BATCH_SIZE = 20 # 训练数据截断长度 TRAIN_NUM_STEP = 35 # 测试数据batch的大小 EVAL_BATCH_SIZE = 1 # 测试数据截断长度 EVAL_NUM_STEP = 1 # 使用训练数据的轮数 NUM_EPOCH = 5 # LSTM节点不被dropout的概率 LSTM_KEEP_PROB = 0.9 # 词向量不被dropout的概率 EMBEDDING_KEEP_PROB = 0.9 # 用于控制梯度膨胀的梯度大小上限 MAX_GRAD_NORM = 5 # 在Softmax层和词向量层之间共享参数 SHARE_EMB_AND_SOFTMAX = True # 通过一个PTBModel类来描述模型,这样方便维护循环神经网络中的状态。 class PTBModel(object): def __init__(self, is_training, batch_size, num_steps): # 记录使用的batch大小和截断长度 self.batch_size = batch_size self.num_steps = num_steps # 定义每一步的输入和预期输出。两者的维度都是[batch_size, num_steps] self.input_data = tf.placeholder(tf.int32, [batch_size, num_steps]) self.targets = tf.placeholder(tf.int32, [batch_size, num_steps]) # 定义使用LSTM结构为循环体结构且使用dropout的深层循环神经网络。 dropout_keep_prob = LSTM_KEEP_PROB if is_training else 1.0 lstm_cells = [ tf.nn.rnn_cell.DropoutWrapper(tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE), output_keep_prob=dropout_keep_prob) for _ in range(NUM_LAYERS) ] cell = tf.nn.rnn_cell.MultiRNNCell(lstm_cells) # 初始化最近的状态,即全零的向量。这个量只在每个epoch初始化第一个batch时使用。 self.initial_state = cell.zero_state(batch_size, tf.float32) # 定义单词的词向量矩阵 embedding = tf.get_variable("embedding", [VOCAB_SIZE, HIDDEN_SIZE]) # 将输入单词转化为词向量 inputs = tf.nn.embedding_lookup(embedding, self.input_data) # 只在训练时使用dropout if is_training: inputs = tf.nn.dropout(inputs, EMBEDDING_KEEP_PROB) # 定义输出列表。在这里先将不同时刻LSTM结构的输出收集起来,再一起提供给softmax层。 outputs = [] state = self.initial_state with tf.variable_scope("RNN"): for time_step in range(num_steps): if time_step > 0: tf.get_variable_scope().reuse_variables() cell_output, state = cell(inputs[:, time_step, :], state) outputs.append(cell_output) # 把输出队列展开成[batch, hidden_size * num_steps]的形状,然后再reshape成[batch*num_steps, hidden_size]的形状。 output = tf.reshape(tf.concat(outputs, 1), [-1, HIDDEN_SIZE]) # Softmax层:将RNN在每个位置上的输出转化为各个单词的logits if SHARE_EMB_AND_SOFTMAX: weight = tf.transpose(embedding) else: weight = tf.get_variable("weight", [HIDDEN_SIZE, VOCAB_SIZE]) bias = tf.get_variable("bias", [VOCAB_SIZE]) logits = tf.matmul(output, weight) + bias # 定义交叉熵损失函数和平均损失 loss = tf.nn.sparse_softmax_cross_entropy_with_logits( labels=tf.reshape(self.targets, [-1]), logits=logits ) self.cost = tf.reduce_sum(loss) / batch_size self.final_state = state # 只在训练模型时定义反向传播操作 if not is_training: return trainable_variables = tf.trainable_variables() # 控制梯度大小,定义优化方法和训练步骤 grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, trainable_variables), MAX_GRAD_NORM) optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0) self.train_op = optimizer.apply_gradients(zip(grads, trainable_variables)) # 使用给定的模型model在数据data上运行train_op并返回在全部数据上的perplexity值 def run_epoch(session, model, batches, train_op, output_log, step): # 计算平均perplexity的辅助变量 total_costs = 0.0 iters = 0 state = session.run(model.initial_state) # 训练一个epoch for x, y in batches: # 在当前batch上运行train_op并计算损失值。交叉熵损失函数计算的就是下一个单词为给定单词的概率 cost, state, _ = session.run( [model.cost, model.final_state, train_op], {model.input_data: x, model.targets: y, model.initial_state: state} ) total_costs += cost iters += model.num_steps # 只有在训练时输出日志 if output_log and step % 100 == 0: print("After %d steps, perplexity is %.3f" % (step, np.exp(total_costs / iters))) step += 1 # 返回给定模型在给定数据上的perplexity值 return step, np.exp(total_costs / iters) # 从文件中读取数据,并返回包含单词编号的数组 def read_data(file_path): with open(file_path, "r") as fin: # 将整个文档读进一个长字符串 id_string = ' '.join([line.strip() for line in fin.readlines()]) # 将读取的单词编号转为整数 id_list = [int(w) for w in id_string.split()] return id_list def make_batches(id_list, batch_size, num_step): # batch_size: 一个batch中样本的数量 # num_batches:batch的个数 # num_step: 一个样本的序列长度 # 计算总的batch数量。每个batch包含的单词数量是batch_size * num_step num_batches = (len(id_list) - 1) // (batch_size * num_step) # 将数据整理成一个维度为[batch_size, num_batches*num_step]的二维数组 data = np.array(id_list[: num_batches * batch_size * num_step]) data = np.reshape(data, [batch_size, num_batches * num_step]) # 沿着第二个维度将数据切分成num_batches个batch,存入一个数组。 data_batches = np.split(data, num_batches, axis=1) # 重复上述操作,但是每个位置向右移动一位,这里得到的是RNN每一步输出所需要预测的下一个单词 label = np.array(id_list[1: num_batches * batch_size * num_step + 1]) label = np.reshape(label, [batch_size, num_batches * num_step]) label_batches = np.split(label, num_batches, axis=1) # 返回一个长度为num_batches的数组,其中每一项包括一个data矩阵和一个label矩阵 # print(len(id_list)) # print(num_batches * batch_size * num_step) return list(zip(data_batches, label_batches)) def main(): # 定义初始化函数 initializer = tf.random_uniform_initializer(-0.05, 0.05) # 定义训练用的循环神经网络模型 with tf.variable_scope("language_model", reuse=None, initializer=initializer): train_model = PTBModel(True, TRAIN_BATCH_SIZE, TRAIN_NUM_STEP) # 定义测试用的循环神经网络模型。它与train_model共用参数,但是没有dropout with tf.variable_scope("language_model", reuse=True, initializer=initializer): eval_model = PTBModel(False, EVAL_BATCH_SIZE, EVAL_NUM_STEP) # 训练模型 with tf.Session() as session: tf.global_variables_initializer().run() train_batches = make_batches(read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP) eval_batches = make_batches(read_data(EVAL_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP) test_batches = make_batches(read_data(TEST_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP) step = 0 for i in range(NUM_EPOCH): print("In iteration: %d" % (i + 1)) step, train_pplx = run_epoch(session, train_model, train_batches, train_model.train_op, True, step) print("Epoch: %d Train Perplexity: %.3f" % (i + 1, train_pplx)) _, eval_pplx = run_epoch(session, eval_model, eval_batches, tf.no_op(), False, 0) print("Epoch: %d Eval Perplexity: %.3f" % (i + 1, eval_pplx)) _, test_pplx = run_epoch(session, eval_model, test_batches, tf.no_op(), False, 0) print("Test Perplexity: %.3f" % test_pplx) if __name__ == '__main__': main() -
运行结果:

5.5 实现机器翻译Seq2Seq完整经过
6. TensorFlow高层封装
6.1 TensorFlow高层封装总览
目前比较主流的TensorFlow高层封装有4个,分别是TensorFlow-Slim、TFLearn、Keras和Estimator。
首先,这里介绍先用TensorFlow-Slim在MNIST数据集上实现LeNet-5模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: slim_learn.py
@time: 2019/4/22 10:53
@desc: 使用TensorFlow-Slim在MNIST数据集上实现LeNet-5模型。
"""
import tensorflow as tf
import tensorflow.contrib.slim as slim
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
# 通过TensorFlow-Slim来定义LeNet-5的网络结构
def lenet5(inputs):
# 将输入数据转化为一个4维数组。其中第一维表示batch大小,另三维表示一张图片。
inputs = tf.reshape(inputs, [-1, 28, 28, 1])
# 定义第一层卷积层。从下面的代码可以看到通过TensorFlow-Slim定义的网络结构
# 并不需要用户去关心如何声明和初始化变量,而只需要定义网络结构即可。下一行代码中
# 定义了一个卷积层,该卷积层的深度为32,过滤器的大小为5x5,使用全0补充。
net = slim.conv2d(inputs, 32, [5, 5], padding='SAME', scope='layer1-conv')
# 定义一个最大池化层,其过滤器大小为2x2,步长为2.
net = slim.max_pool2d(net, 2, stride=2, scope='layer2-max-pool')
# 类似的定义其他网络层结构
net = slim.conv2d(net, 64, [5, 5], padding='SAME', scope='layer3-conv')
net = slim.max_pool2d(net, 2, stride=2, scope='layer4-max-pool')
# 直接使用TensorFlow-Slim封装好的flatten函数将4维矩阵转为2维,这样可以
# 方便后面的全连接层的计算。通过封装好的函数,用户不再需要自己计算通过卷积层之后矩阵的大小。
net = slim.flatten(net, scope='flatten')
# 通过TensorFlow-Slim定义全连接层,该全连接层有500个隐藏节点。
net = slim.fully_connected(net, 500, scope="layer5")
net = slim.fully_connected(net, 10, scope="output")
return net
# 通过TensorFlow-Slim定义网络结构,并使用之前章节中给出的方式训练定义好的模型。
def train(mnist):
# 定义输入
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 使用TensorFLow-Slim定义网络结构
y = lenet5(x)
# 定义损失函数和训练方法
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1)) # 1 means axis=1
loss = tf.reduce_mean(cross_entropy)
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(10000):
xs, ys = mnist.train.next_batch(100)
_, loss_value = sess.run([train_op, loss], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (i, loss_value))
def main(argv=None):
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
train(mnist)
if __name__ == '__main__':
main()
OK!运行吧皮卡丘!
第一个例子都报错。。。(ValueError: Rank mismatch: Rank of labels (received 1) should equal rank of logits minus 1 (received 4).)

我哭了!找了我半天错误,才发现少写了一句。
net = slim.flatten(net, scope='flatten')
可把我愁坏了,整了半天才弄好。。。
网上都是什么神仙回答,解释的有板有眼的,都说这本书是垃圾,害得我差点立刻在我对这本书评价的博客上再加上几句芬芳。
好歹是学到了知识了。对logits和labels加深了印象了。
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))logits:是计算得到的结果
labels:是原来的数据标签。
千万不要记混了!
labels=tf.argmax(y_, 1)labels输入的是[0, 0, 0, 1, 0, 0, 0, 0, 0, 0](以MNIST为例),
而在tf.nn.sparse_softmax_cross_entropy_with_logits函数中
labels的输入格式需要是[3],也就是说,是类别的编号。
诶!问题来了!
logits=ylogits的格式与labels一样吗?
不一样!
logits的格式与labels转换前的一样,也就是
[0.2, 0.3, 0.1, 0.9, 0.1, 0.1, 0.2, 0.2, 0.4, 0.6]
如果不转换labels的话,可以用tf.nn.softmax_cross_entropy_with_logits达到同样的效果。
诶?那为什么非要转换一下labels呢?
我也没看懂,非要骚一下吧。。。
好了正确的运行结果出来了:

如果我们把刚才说的那句代码改为:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_)
试试看?
哇哦~正常运行了有没有!!!

所以呢?所以为什么这里要非要用有sparse的这个函数呢?
反正我是没看懂(摊手┓( ´∀` )┏)。。。
与TensorFlow-Slim相比,TFLearn是一个更加简洁的高层封装。
因为TFLearn并没有集成在TensorFlow中,所以首先是用pip安装。
安装完后,下面是用TFLearn在MNIST数据集上实现LeNet-5模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tflearn_learn.py
@time: 2019/5/5 16:53
@desc: 使用TFLearn在MNIST数据集上实现LeNet-5模型。
"""
import tflearn
from tflearn.layers.core import input_data, fully_connected
from tflearn.layers.conv import conv_2d, max_pool_2d
from tflearn.layers.estimator import regression
import tflearn.datasets.mnist as mnist
# 读取mnist数据
trainX, trainY, testX, testY = mnist.load_data(data_dir="D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=True)
# 将图像数据reshape成卷积神经网络输入的格式
trainX = trainX.reshape([-1, 28, 28, 1])
testX = testX.reshape([-1, 28, 28, 1])
# 构建神经网络,这个过程和TensorFlow-Slim比较类似。input_data定义了一个placeholder来接入输入数据。
net = input_data(shape=[None, 28, 28, 1], name='input')
# 通过TFLearn封装好的API定义一个深度为5,过滤器为5x5,激活函数为ReLU的卷积层
net = conv_2d(net, 32, 5, activation='relu')
# 定义一个过滤器为2x2的最大池化层
net = max_pool_2d(net, 2)
# 类似地定义其他的网络结构。
net = conv_2d(net, 64, 5, activation='relu')
net = max_pool_2d(net, 2)
net = fully_connected(net, 500, activation='relu')
net = fully_connected(net, 10, activation='softmax')
# 使用TFLearn封装好的函数定义学习任务。指定优化器为sgd,学习率为0.01,损失函数为交叉熵。
net = regression(net, optimizer='sgd', learning_rate=0.01, loss='categorical_crossentropy')
# 通过定义的网络结构训练模型,并在指定的验证数据上验证模型的效果。
# TFLearn将模型的训练过程封装到了一个类中,这样可以减少非常多的冗余代码。
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(trainX, trainY, n_epoch=20, validation_set=([testX, testY]), show_metric=True)
个人感相较于Slim,TFLearn好用太多了吧。。。特别是model.fit真的是给我眼前一亮的感觉,这也太帅了吧,瞧这交叉熵小黄字,瞧这epoch,瞧这step。。。封装万岁!!!(对我这种菜鸡而言,不要跟我谈底层,我!不!够!格!)
运行结果:

6.2 Keras介绍
Keras基本用法
下面是用原生态的Keras在MNIST数据集上实现LeNet-5模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_learn.py
@time: 2019/5/5 17:42
@desc: 使用Keras在MNIST数据集上实现LeNet-5模型。
"""
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from keras import backend as K
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
# 因为不同的底层(TensorFlow或者MXNet)对输入的要求不一样,所以这里需要根据对图像
# 编码的格式要求来设置输入层的格式。
if K.image_data_format() == 'channels_first':
trainX = trainX.reshape(trainX.shape[0], 1, img_rows, img_cols)
testX = testX.reshape(trainX.shape[0], 1, img_rows, img_cols)
# 因为MNIST中的图片是黑白的,所以第一维的取值为1
input_shape = (1, img_rows, img_cols)
else:
trainX = trainX.reshape(trainX.shape[0], img_rows, img_cols, 1)
testX = testX.reshape(testX.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 使用Keras API定义模型
model = Sequential()
# 一层深度为32,过滤器大小为5x5的卷积层
model.add(Conv2D(32, kernel_size=(5, 5), activation='relu', input_shape=input_shape))
# 一层过滤器大小为2x2的最大池化层。
model.add(MaxPooling2D(pool_size=(2, 2)))
# 一层深度为64, 过滤器大小为5x5的卷积层。
model.add(Conv2D(64, (5, 5), activation='relu'))
# 一层过滤器大小为2x2的最大池化层。
model.add(MaxPooling2D(pool_size=(2, 2)))
# 将卷积层的输出拉直后作为下面全连接的输入。
model.add(Flatten())
# 全连接层,有500个节点。
model.add(Dense(500, activation='relu'))
# 全连接层,得到最后的输出。
model.add(Dense(num_calsses, activation='softmax'))
# 定义损失函数、优化函数和测评的方法。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy'])
# 类似TFLearn中的训练过程,给出训练数据,batch大小、训练轮数和验证数据,Keras可以自动完成模型的训练过程。
model.fit(trainX, trainY, batch_size=128, epochs=20, validation_data=(testX, testY))
# 在测评数据上计算准确率
score = model.evaluate(testX, testY)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
运行之后(跑了我一夜呀我滴妈。。。):

下面是用原生态的Keras实现循环神经网络。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_rnn.py
@time: 2019/5/6 12:30
@desc: 用原生态的Keras实现循环神经网络
"""
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM
from keras.datasets import imdb
# 最多使用的单词数
max_features = 20000
# 循环神经网络的截断长度。
maxlen = 80
batch_size = 32
# 加载数据并将单词转化为ID,max_features给出了最多使用的单词数。和自然语言模型类似,
# 会将出现频率较低的单词替换为统一的的ID。通过Keras封装的API会生成25000条训练数据和
# 25000条测试数据,每一条数据可以被看成一段话,并且每段话都有一个好评或者差评的标签。
(trainX, trianY), (testX, testY) = imdb.load_data(num_words=max_features)
print(len(trainX), 'train sequences')
print(len(testX), 'test sequences')
# 在自然语言中,每一段话的长度是不一样的,但循环神经网络的循环长度是固定的,所以这里需要先将
# 所有段落统一成固定长度。对于长度不够的段落,要使用默认值0来填充,对于超过长度的段落
# 则直接忽略掉超过的部分。
trainX = sequence.pad_sequences(trainX, maxlen=maxlen)
testX = sequence.pad_sequences(testX, maxlen=maxlen)
print('trainX shape', trainX.shape)
print('testX shape: ', testX.shape)
# 在完成数据预处理之后构建模型
model = Sequential()
# 构建embedding层。128代表了embedding层的向量维度。
model.add(Embedding(max_features, 128))
# 构建LSTM层
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
# 构建最后的全连接层。注意在上面构建LSTM层时只会得到最后一个节点的输出,
# 如果需要输出每个时间点的结果,呢么可以将return_sequence参数设为True。
model.add(Dense(1, activation='sigmoid'))
# 与MNIST样例类似的指定损失函数、优化函数和测评指标。
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 在测试数据上评测模型。
score = model.evaluate(testX, testY, batch_size=batch_size)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
睡了个午觉就跑完啦:


Keras高级用法
面对上面的例子,都是顺序搭建的神经网络模型,类似于Inception这样的模型结构,就需要更加灵活的模型定义方法了。
在这里我真的是忍不住要吐槽一下书上的内容,简直完全没有讲清楚在说什么鬼。。。没说清楚究竟是用的那一部分的数据,是MNIST还是rnn的数据。。。捣鼓了半天才知道是MNIST。然后这里的意思应该是用全连接的方式,即输入数据为(60000, -1),也就是说样本是60000个,然后把图片的维度拉伸为1维。(这里我也是摸索了好久才知道的),所以在代码中需要对数据进行reshape处理。不然会报错:
ValueError: Error when checking input: expected input_1 to have 2 dimensions, but got array with shape (60000, 28, 28)
参考链接:https://blog.csdn.net/u012193416/article/details/79399679
是真的坑爹,只能说。。。什么也没有说清楚,就特么瞎指挥。。。(然鹅,我是真的菜。。。摊手。。。)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_inception.py
@time: 2019/5/6 14:29
@desc: 用更加灵活的模型定义方法在MNIST数据集上实现全连接层模型。
"""
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
# 使用前面介绍的类似方法生成trainX、trainY、testX、testY,唯一的不同是这里只用了
# 全连接层,所以不需要将输入整理成三维矩阵。
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX.reshape(len(trainX), -1)
testX = testX.reshape(len(testX), -1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 定义输入,这里指定的维度不用考虑batch大小。
inputs = Input(shape=(784, ))
# 定义一层全连接层,该层有500隐藏节点,使用ReLU激活函数。这一层的输入为inputs
x = Dense(500, activation='relu')(inputs)
# 定义输出层。注意因为keras封装的categorical_crossentropy并没有将神经网络的输出
# 再经过一层softmax,所以这里需要指定softmax作为激活函数。
predictions = Dense(10, activation='softmax')(x)
# 通过Model类创建模型,和Sequential类不同的是Model类在初始化的时候需要指定模型的输入和输出
model = Model(inputs=inputs, outputs=predictions)
# 使用与前面类似的方法定义损失函数、优化函数和评测方法。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy'])
# 使用与前面类似的方法训练模型。
model.fit(trainX, trainY, batch_size=128, epochs=10, validation_data=(testX, testY))
修改之后运行可以得到:

通过这样的方式,Keras就可以实现类似Inception这样的模型结构了。
现在又要说坑爹的部分了,这本书在这里直接照抄的Keras的手册中的例子,来解释用Keras实现Inception-v3的模型结构,所以给出的代码是这样的
from keras.layers import Conv2D, MaxPooling2D, Input
# 定义输入图像尺寸
input_img = Input(shape=(256, 256, 3))
# 定义第一个分支。
tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
# 定义第二个分支。与顺序模型不同,第二个分支的输入使用的是input_img,而不是第一个分支的输出。
tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
# 定义第三个分支。类似地,第三个分支的输入也是input_img。
tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
# 将三个分支通过concatenate的方式拼凑在一起。
output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
你可能要问“这就完啦?”,我想告诉你的是,对的。关于Inception-v3的部分就这么点。然后我给你看一眼网上官方的代码:
参考链接:https://keras.io/zh/getting-started/functional-api-guide/

是不是有种似曾相识的感觉。。。
踏马的根本就没有想着去实现好吗?
我也是醉了的,我就问一句,不是一直在用MNIST数据集作为例子吗!那这个
input_img = Input(shape=(256, 256, 3))
图像尺寸怎么突然就编程(256, 256, 3)了呢?而不是(28, 28, 1)呢?
这本书一点都不走心好吗!
我也是佛了,那么我只能靠自己理解,并自己写例子了。这里面的艰辛我就不说了,不卖惨了,是真的恨,我只希望每一个例子都能够有始有终,都能够有输出有结果,能运行!
下面贴一下我自己想的改的代码吧:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_inception2.py
@time: 2019/5/6 15:43
@desc: 用原生态的Keras实现Inception
"""
from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flatten
import keras
from keras.models import Model
from keras.datasets import mnist
from keras import backend as K
# 使用前面介绍的类似方法生成trainX、trainY、testX、testY,唯一的不同是这里只用了
# 全连接层,所以不需要将输入整理成三维矩阵。
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
if K.image_data_format() == 'channels_first':
trainX = trainX.reshape(trainX.shape[0], 1, img_rows, img_cols)
testX = testX.reshape(trainX.shape[0], 1, img_rows, img_cols)
# 因为MNIST中的图片是黑白的,所以第一维的取值为1
input_shape = (1, img_rows, img_cols)
else:
trainX = trainX.reshape(trainX.shape[0], img_rows, img_cols, 1)
testX = testX.reshape(testX.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 定义输入图像尺寸
input_img = Input(shape=(28, 28, 1))
# 定义第一个分支。
tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
# 定义第二个分支。与顺序模型不同,第二个分支的输入使用的是input_img,而不是第一个分支的输出。
tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
# 定义第三个分支。类似地,第三个分支的输入也是input_img。
tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
# 将三个分支通过concatenate的方式拼凑在一起。
output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
# 将卷积层的输出拉直后作为下面全连接的输入。
tower_4 = Flatten()(output)
# 全连接层,有500个节点。
tower_5 = Dense(500, activation='relu')(tower_4)
# 全连接层,得到最后的输出。
predictions = Dense(num_calsses, activation='softmax')(tower_5)
# 通过Model类创建模型,和Sequential类不同的是Model类在初始化的时候需要指定模型的输入和输出
model = Model(inputs=input_img, outputs=predictions)
# 使用与前面类似的方法定义损失函数、优化函数和评测方法。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy'])
# 使用与前面类似的方法训练模型。
model.fit(trainX, trainY, batch_size=128, epochs=20, validation_data=(testX, testY))
# 在测试数据上评测模型。
score = model.evaluate(testX, testY, batch_size=128)
print('Test loss: ', score[0])
print('Test accuracy: ', score[1])
运行结果:

说明,我改了之后是能跑的。。。
对了,如果有杠精问我,人家只是抛砖引玉,让读者举一反三。。。那我没什么好说的。。。
又花了一晚上跑完。。。

用原生态的Keras实现非顺序模型,多输入和多输出模型。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_inception3.py
@time: 2019/5/7 14:54
@desc: 用原生态的Keras实现非顺序模型,多输入和多输出模型
"""
import keras
from tflearn.layers.core import fully_connected
from keras.datasets import mnist
from keras.layers import Input, Dense
from keras.models import Model
from keras import backend as K
# 类似前面的方式生成trainX、trainY、testX、testY
num_calsses = 10
img_rows, img_cols = 28, 28
# 通过Keras封装好的API加载MNIST数据。其中trainX就是一个60000x28x28的数组,
# trainY是每一张图片对应的数字。
(trainX, trainY), (testX, testY) = mnist.load_data()
trainX = trainX.reshape(len(trainX), -1)
testX = testX.reshape(len(testX), -1)
# 将图像像素转化为0到1之间的实数。
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
# 将标准答案转化为需要的格式(One-hot编码)。
trainY = keras.utils.to_categorical(trainY, num_calsses)
testY = keras.utils.to_categorical(testY, num_calsses)
# 定义两个输入,一个输入为原始的图片信息,另一个输入为正确答案。
input1 = Input(shape=(784, ), name='input1')
input2 = Input(shape=(10, ), name='input2')
# 定义一个只有一个隐藏节点的全连接网络。
x = Dense(1, activation='relu')(input1)
# 定义只使用了一个隐藏节点的网络结构的输出层。
output1 = Dense(10, activation='softmax', name='output1')(x)
# 将一个隐藏节点的输出和正确答案拼接在一起,这个将作为第二个输出层的输入。
y = keras.layers.concatenate([x, input2])
# 定义第二个输出层。
output2 = Dense(10, activation='softmax', name='output2')(y)
# 定义一个有多个输入和多个输出的模型,这里只需要将所有的输入和输出给出即可。
model = Model(inputs=[input1, input2], outputs=[output1, output2])
# 定义损失函数、优化函数和评测方法。若多个输出的损失函数相同,可以只指定一个损失函数。
# 如果多个输出的损失函数不同,则可以通过一个列表或一个字典来指定每一个输出的损失函数。
# 比如可以使用:loss = {'output1': 'binary_crossentropy', 'output2': 'binary_crossentropy'}
# 来为不同的输出指定不同的损失函数。类似的,Keras也支持为不同输出产生的损失指定权重,
# 这可以通过通过loss_weights参数来完成。在下面的定义中,输出output1的权重为1,output2
# 的权重为0.1。所以这个模型会更加偏向于优化第一个输出。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), loss_weights=[1, 0.1], metrics=['accuracy'])
# 模型训练过程。因为有两个输入和输出,所以这里提供的数据也需要有两个输入和两个期待的正确
# 答案输出。通过列表的方式提供数据时,Keras会假设数据给出的顺序和定义Model类时输入输出
# 给出的顺序是对应的。为了避免顺序不一致导致的问题,这里更推荐使用字典的形式给出。
model.fit(
[trainX, trainY], [trainY, trainY],
batch_size=128,
epochs=20,
validation_data=([testX, testY], [testY, testY])
)
运行结果:

我们可以看出,由于输出层1只使用了一个一维的隐藏节点,所以正确率很低,输出层2虽然使用了正确答案最为输入,但是损失函数中的权重较低,所以收敛速度较慢,准确率只有0.804。现在我们把权重设置相同,运行得到:

这样输出二经过了足够的训练,精度就提高了很多。
虽然通过返回值的方式已经可以实现大部分的神经网络模型,然而Keras API还存在两大问题。一是对训练数据的处理流程支持的不太好;二十无法支持分布式训练。为了解决这两个问题,Keras提供了一种与原生态TensorFlow结合得更加紧密的方式。下面的代码是:实现Keras与TensorFlow联合起来解决MNIST问题。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: keras_test4.py
@time: 2019/5/7 15:45
@desc: 实现Keras与TensorFlow联合起来解决MNIST问题。
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist_data = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
# 通过TensorFlow中的placeholder定义输入。类似的,Keras封装的网络层结构也可以支持使用
# 前面章节中介绍的输入队列。这样可以有效避免一次性加载所有数据的问题。
x = tf.placeholder(tf.float32, shape=(None, 784))
y_ = tf.placeholder(tf.float32, shape=(None, 10))
# 直接使用TensorFlow中提供的Keras API定义网络结构。
net = tf.keras.layers.Dense(500, activation='relu')(x)
y = tf.keras.layers.Dense(10, activation='softmax')(net)
# 定义损失函数和优化方法。注意这里可以混用Keras的API和原生态TensorFlow的API
loss = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_, y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
# 定义预测的正确率作为指标。
acc_value = tf.reduce_mean(tf.keras.metrics.categorical_accuracy(y_, y))
# 使用原生态TensorFlow的方式训练模型。这样可以有效地实现分布式。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(10000):
xs, ys = mnist_data.train.next_batch(100)
_, loss_value = sess.run([train_step, loss], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (i, loss_value))
print(acc_value.eval(feed_dict={x: mnist_data.test.images,
y_: mnist_data.test.labels}))
运行结果:

通过和原生态TensorFlow更紧密地结合,可以使建模的灵活性进一步提高,但是同时也会损失一部分封装带来的易用性。所以在实际问题中,需要根据需求合理的选择封装的程度。
6.3 Estimator介绍
Estimator基本用法
基于MNIST数据集,通过Estimator实现全连接神经网络。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: estimator_test1.py
@time: 2019/5/7 16:22
@desc: 基于MNIST数据集,通过Estimator实现全连接神经网络。
"""
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 将TensorFlow日志信息输出到屏幕
tf.logging.set_verbosity(tf.logging.INFO)
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
# 指定神经网络的输入层,所有这里指定的输入都会拼接在一起作为整个神经网络的输入。
feature_columns = [tf.feature_column.numeric_column("image", shape=[784])]
# 通过TensorFlow提供的封装好的Estimator定义神经网络模型。feature_columns参数
# 给出了神经网络输入层需要用到的数据,hidden_units列表中给出了每一层
# 隐藏层的节点数。n_classes给出了总共类目的数量,optimizer给出了使用的优化函数。
# Estimator会将模型训练过程中的loss变化以及一些其他指标保存到model_dir目录下,
# 通过TensorFlow可以可视化这些指标的变化过程。并通过TensorBoard可视化监控指标结果。
estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[500],
n_classes=10,
optimizer=tf.train.AdamOptimizer(),
model_dir="./log"
)
# 定义数据输入。这里x中需要给出所有的输入数据。因为上面feature_columns只定义了一组
# 输入,所以这里只需要制定一个就好。如果feature_columns中指定了多个,那么这里也需要
# 对每一个指定的输入提供数据。y中需要提供每一个x对应的正确答案,这里要求分类的结果
# 是一个正整数。num_epochs指定了数据循环使用的轮数。比如在测试时可以将这个参数指定为1.
# batch_size指定了一个batch的大小。shuffle指定了是否需要对数据进行随机打乱。
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.train.images},
y=mnist.train.labels.astype(np.int32),
num_epochs=None,
batch_size=128,
shuffle=True
)
# 训练模型。注意这里没有指定损失函数,通过DNNClassifier定义的模型会使用交叉熵作为损失函数。
estimator.train(input_fn=train_input_fn, steps=10000)
# 定义测试时的数据输入。指定的形式和训练时的数据输入基本一致。
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.test.images},
y=mnist.test.labels.astype(np.int32),
num_epochs=1,
batch_size=128,
shuffle=False
)
# 通过evaluate评测训练好的模型的效果。
accuracy_score = estimator.evaluate(input_fn=test_input_fn)["accuracy"]
print("\nTest accuracy: %g %%" % (accuracy_score*100))
运行可得:

使用下面的命令开启tensorboard之旅:(我又要喷了,书里根本没说怎么开启tensorboard,我完全靠自行百度摸索的。。。)
tensorboard --logdir=""
引号里面填自己的log所在的地址。然后运行:

复制最下面的那个地址,在浏览器(我是谷歌浏览器)粘贴并转到。
记住!是粘贴并转到,不是ctrl+v,是右键,粘贴并转到。
别问!问就是吃了好多亏。。。
反正我的电脑是粘贴并转到之后,卡了一会儿,就出现了这个界面:

虽然跟书上的图的布局不一样,下面折叠的指标,展开也有图就是了。。。
当然GRAPHS也是有的嘿嘿。。。

Estimator自定义模型
通过自定义的方式使用卷积神经网络解决MNIST问题:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: estimator_test2.py
@time: 2019/5/9 12:31
@desc: 通过自定义的方式使用卷积神经网络解决MNIST问题
"""
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
tf.logging.set_verbosity(tf.logging.INFO)
# 通过tf.layers来定义模型结构。这里可以使用原生态TensorFlow API或者任何
# TensorFlow的高层封装。X给出了输入层张量,is_training指明了是否为训练。
# 该函数返回前向传播的结果。
def lenet(x, is_training):
# 将输入转化为卷积层需要的形状
x = tf.reshape(x, shape=[-1, 28, 28, 1])
net = tf.layers.conv2d(x, 32, 5, activation=tf.nn.relu)
net = tf.layers.max_pooling2d(net, 2, 2)
net = tf.layers.conv2d(net, 64, 3, activation=tf.nn.relu)
net = tf.layers.max_pooling2d(net, 2, 2)
net = tf.contrib.layers.flatten(net)
net = tf.layers.dense(net, 1024)
net = tf.layers.dropout(net, rate=0.4, training=is_training)
return tf.layers.dense(net, 10)
# 自定义Estimator中使用的模型,定义的函数有4个输入,features给出了在输入函数中
# 会提供的输入层张量。注意这是一个字典,字典里的内容是通过tf.estimator.inputs.numpy_input_fn
# 中x参数的内容指定的。labels是正确答案,这个字段的内容是通过numpy_input_fn中y参数给出的。
# mode的取值有3中可能,分别对应Estimator类的train、evaluate和predict这3个函数。通过
# 这个参数可以判断当前会否是训练过程。最后params是一个字典,这个字典中可以给出模型相关的任何超参数
# (hyper-parameter)。比如这里将学习率放在params中。
def model_fn(features, labels, mode, params):
# 定义神经网络的结构并通过输入得到前向传播的结果。
predict = lenet(features["image"], mode == tf.estimator.ModeKeys.TRAIN)
# 如果在预测模式,那么只需要将结果返回即可。
if mode == tf.estimator.ModeKeys.PREDICT:
# 使用EstimatorSpec传递返回值,并通过predictions参数指定返回的结果。
return tf.estimator.EstimatorSpec(
mode=mode,
predictions={"result": tf.argmax(predict, 1)}
)
# 定义损失函数
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=predict, labels=labels))
# 定义优化函数。
optimizer = tf.train.GradientDescentOptimizer(learning_rate=params["learning_rate"])
# 定义训练过程。
train_op = optimizer.minimize(loss=loss, global_step=tf.train.get_global_step())
# 定义评测标准,在运行evaluate时会计算这里定义的所有评测标准。
eval_metric_ops = {
"my_metric": tf.metrics.accuracy(tf.argmax(predict, 1), labels)
}
# 返回模型训练过程需要使用的损失函数、训练过程和评测方法。
return tf.estimator.EstimatorSpec(
mode=mode,
loss=loss,
train_op=train_op,
eval_metric_ops=eval_metric_ops
)
mnist = input_data.read_data_sets("D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=False)
# 通过自定义的方式生成Estimator类。这里需要提供模型定义的函数并通过params参数指定模型定义时使用的超参数。
model_params = {"learning_rate": 0.01}
estimator = tf.estimator.Estimator(model_fn=model_fn, params=model_params)
# 和前面的类似,训练和评测模型。
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.train.images},
y=mnist.train.labels.astype(np.int32),
num_epochs=None,
batch_size=128,
shuffle=True
)
estimator.train(input_fn=train_input_fn, steps=30000)
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.test.images},
y=mnist.test.labels.astype(np.int32),
num_epochs=1,
batch_size=128,
shuffle=False
)
test_results = estimator.evaluate(input_fn=test_input_fn)
# 这里使用的my_metric中的内容就是model_fn中eval_metric_ops定义的评测指标。
accuracy_score = test_results["my_metric"]
print("\nTest accuracy: %g %%" % (accuracy_score*100))
# 使用训练好的模型在新数据上预测结果。
predict_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"image": mnist.test.images[:10]},
num_epochs=1,
shuffle=False
)
predictions = estimator.predict(input_fn=predict_input_fn)
for i, p in enumerate(predictions):
# 这里result就是tf.estimator.EstimatorSpec的参数predicitons中指定的内容。
# 因为这个内容是一个字典,所以Estimator可以很容易支持多输出。
print("Prediction %s : %s" % (i + 1, p["result"]))
运行之后得到:

预测结果:

使用数据集(Dataset)作为Estimator输入
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: estimator_test3.py
@time: 2019/5/9 14:13
@desc: 通过Estimator和数据集相结合的方式完成整个数据读取和模型训练的过程。
"""
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.INFO)
# Estimator的自定义输入函数需要每一次被调用时可以得到一个batch的数据(包括所有的
# 输入层数据和期待的正确答案标注),通过数据集可以很自然地实现这个过程。虽然Estimator
# 要求的自定义输入函数不能有参数,但是通过python提供的lambda表达式可以快速将下面的
# 函数转化为不带参数的函数。
def my_input_fn(file_path, perform_shuffle=False, repeat_count=1):
# 定义解析csv文件中一行的方法。
def decode_csv(line):
# 将一行中的数据解析出来。注意iris数据中最后一列为正确答案,前面4列为特征。
parsed_line = tf.decode_csv(line, [[0.], [0.], [0.], [0.], [0]])
# Estimator的输入函数要求特征是一个字典,所以这里返回的也需要是一个字典。
# 字典中key的定义需要和DNNclassifier中feature_columns的定义匹配。
return {"x": parsed_line[:-1]}, parsed_line[-1:]
# 使用数据集处理输入数据。数据集的具体使用方法可以参考前面。
dataset = (tf.data.TextLineDataset(file_path).skip(1).map(decode_csv))
if perform_shuffle:
dataset = dataset.shuffle(buffer_size=256)
dataset = dataset.repeat(repeat_count)
dataset = dataset.batch(12)
iterator = dataset.make_one_shot_iterator()
# 通过定义的数据集得到一个batch的输入数据。这就是整个自定义的输入过程的返回结果。
batch_features, batch_labels = iterator.get_next()
# 如果是为预测过程提供输入数据,那么batch_labels可以直接使用None。
return batch_features, batch_labels
# 与前面中类似地定义Estimator
feature_columns = [tf.feature_column.numeric_column("x", shape=[4])]
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 10],
n_classes=3
)
# 使用lambda表达式将训练相关的信息传入自定义输入数据处理函数并生成Estimator需要的输入函数
classifier.train(input_fn=lambda: my_input_fn("./iris_data/iris_training (1).csv", True, 10))
# 使用lambda表达式将测试相关的信息传入自定义输入数据处理函数并生成Estimator需要的输入函数。
# 通过lambda表达式的方式可以大大减少冗余代码。
test_results = classifier.evaluate(input_fn=lambda: my_input_fn("./iris_data/iris_test (1).csv", False, 1))
print("\nTest accuracy: %g %%" % (test_results["accuracy"]*100))
运行之后,玄学报错。。。

我佛了,查了一万种方法,也解决不了玄学报错。。。
然后,我换了个机器,macbook。。。就正常运行了。。。

头就很疼。。。
6.4 总结
要什么总结,不就是几种常见的TensorFlow高层封装嘛!包括TensorFlow-Slim、TFLearn、Keras和Estimator。反正就是结合起来,反正就是头疼。
7. TensorBoard可视化
7.1 TensorBoard简介
一个简单的TensorFlow程序,在这个程序中完成了TensorBoard日志输出的功能。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test1.py
@time: 2019/5/10 9:27
@desc: TensorBoard简介。一个简单的TensorFlow程序,在这个程序中完成了TensorBoard日志输出的功能。
"""
import tensorflow as tf
# 定义一个简单的计算图,实现向量加法的操作。
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
input2 = tf.Variable(tf.random_uniform([3], name="input2"))
output = tf.add_n([input1, input2], name="add")
# 生成一个写日志的writer,并将当前的TensorFlow计算图写入日志。TensorFlow提供了
# 多种写日志文件的API,在后面详细介绍。
writer = tf.summary.FileWriter('./log/', tf.get_default_graph())
writer.close()
运行之后输入:tensorboard --logdir=./log查看TensorBoard。

然后在浏览器中输入下面的网址。

7.2 TensorFlow计算图可视化
命名空间与TensorBoard图上节点
tf.variable_scope与tf.name_scope函数的区别
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test2.py
@time: 2019/5/10 10:26
@desc: tf.variable_scope与tf.name_scope函数的区别
"""
import tensorflow as tf
with tf.variable_scope("foo"):
# 在命名空间foo下获取变量"bar",于是得到的变量名称为“foo/bar”。
a = tf.get_variable("bar", [1])
# 输出:foo/bar: 0
print(a.name)
with tf.variable_scope("bar"):
# 在命名空间bar下获取变量“bar”,于是得到的变量名称为“bar/bar”。此时变量
# “bar/bar”和变量“foo/bar”并不冲突,于是可以正常运行。
b = tf.get_variable("bar", [1])
# 输出:bar/bar:0
with tf.name_scope("a"):
# 使用tf.Variable函数生成变量会受到tf.name_scope影响,于是这个变量的名称为“a/Variable”。
a = tf.Variable([1])
# 输出:a/Variable:0
print(a.name)
# tf.get_variable函数不受tf.name_scope函数的影响。
# 于是变量并不在a这个命名空间中。
a = tf.get_variable("b", [1])
# 输出:b:0
print(a.name)
with tf.name_scope("b"):
# 因为tf.get_variable不受tf.name_scope影响,所以这里试图获取名称为
# “a”的变量。然而这个变量已经被声明了,于是这里会报重复声明的错误
tf.get_variable("b", [1])
对不起,这一段代码,我知道作者想要表达什么意思。。。但我实在是觉得不知所云。

改进向量相加的样例代码
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test3.py
@time: 2019/5/10 10:41
@desc: 改进向量相加的样例代码
"""
import tensorflow as tf
# 将输入定义放入各自的命名空间中,从而使得TensorBoard可以根据命名空间来整理可视化效果图上的节点。
with tf.name_scope("input1"):
input1 = tf.constant([1.0, 2.0, 3.0], name="input1")
with tf.name_scope("input2"):
input2 = tf.Variable(tf.random_uniform([3]), name="input2")
output = tf.add_n([input1, input2], name="add")
writer = tf.summary.FileWriter("./log", tf.get_default_graph())
writer.close()
得到改进后的图:
\
展开input2节点的可视化效果图:

可视化一个真实的神经网络结构图
我是真的佛了。。。这里原谅我真的又要喷。。。首先是用之前的mnist_inference文件就已经炸了,然后下面还有一句跟前面一样的方式训练神经网络。。。我特么。。。。你你听,这说的是人话吗?我已经无力吐槽了。。。这本书用来作为我的TensorFlow启蒙书,真的是后悔死了。。。
下面的代码,依然是我自己凭借自己的理解,改后的,这本书是真的垃圾。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test4.py
@time: 2019/5/10 11:06
@desc: 可视化一个真实的神经网络结构图。
"""
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
# mnist_inference中定义的常量和前向传播的函数不需要改变,因为前向传播已经通过
# tf.variable_scope实现了计算节点按照网络结构的划分。
import BookStudy.book2.mnist_inference as mnist_inference
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径和文件名。
MODEL_SAVE_PATH = './model/'
MODEL_NAME = 'model.ckpt'
def train(mnist):
# 将处理输入数据的计算都放在名字为“input”的命名空间下。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name="y-input")
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 将处理滑动平均相关的计算都放在名为moving_average的命名空间下。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 将计算损失函数相关的计算都放在名为loss_function的命名空间下。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 将定义学习率、优化方法以及每一轮训练需要训练的操作都放在名字为“train_step”的命名空间下。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 初始化Tensorflow持久化类。
saver = tf.train.Saver()
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成。
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
# 每1000轮保存一次模型。
if i % 1000 == 0:
# 输出当前的训练情况。这里只输出了模型在当前训练batch上的损失函数大小。通过损失函数的大小可以大概了解到
# 训练的情况。在验证数据集上的正确率信息会有一个独立的程序来生成。
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
# 保存当前的模型。注意这里给出了global_step参数,这样可以让每个被保存的模型的文件名末尾加上训练的轮数,
# 比如“model.ckpt-1000” 表示训练1000轮之后得到的模型。
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
# 将当前的计算图输出到TensorBoard日志文件。
writer = tf.summary.FileWriter("./log", tf.get_default_graph())
writer.close()
def main(argv = None):
mnist = input_data.read_data_sets("D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
运行之后:

召唤tensorboard:

改进后的MNIST样例程序TensorFlow计算图可视化效果图:

节点信息
修改前面的代码,将不同迭代轮数的每个TensorFlow计算节点的运行时间和消耗的内存写入TensorBoard的日志文件中。
果然。。。这次又是只给出一部分代码。。。并且这个train_writer是什么啊,在哪里定义也没看到,拿来就用,真的是服了。。。(写的也太烂了,佛了,刷完这本书我就烧了。。。)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test5.py
@time: 2019/5/10 21:13
@desc: 修改前面的代码,将不同迭代轮数的每个TensorFlow计算节点的运行时间和消耗的内存写入TensorBoard的日志文件中。
"""
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
# mnist_inference中定义的常量和前向传播的函数不需要改变,因为前向传播已经通过
# tf.variable_scope实现了计算节点按照网络结构的划分。
import BookStudy.book2.mnist_inference as mnist_inference
INPUT_NODE = 784
OUTPUT_NODE = 10
LAYER1_NODE = 500
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 30000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径和文件名。
MODEL_SAVE_PATH = './model/'
MODEL_NAME = 'model.ckpt'
def train(mnist):
# 将处理输入数据的计算都放在名字为“input”的命名空间下。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name="y-input")
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 将处理滑动平均相关的计算都放在名为moving_average的命名空间下。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 将计算损失函数相关的计算都放在名为loss_function的命名空间下。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 将定义学习率、优化方法以及每一轮训练需要训练的操作都放在名字为“train_step”的命名空间下。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 初始化Tensorflow持久化类。
saver = tf.train.Saver()
# 将当前的计算图输出到TensorBoard日志文件。
train_writer = tf.summary.FileWriter("./log", tf.get_default_graph())
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独立的程序来完成。
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 每1000轮保存一次模型。
if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
# 将配置信息和记录运行信息的proto传入运行的过程,从而记录运行时每一个节点的时间、空间开销信息。
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys}, options=run_options, run_metadata=run_metadata)
# 将节点在运行时的信息写入日志文件。
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
# 输出当前的训练情况。这里只输出了模型在当前训练batch上的损失函数大小。通过损失函数的大小可以大概了解到
# 训练的情况。在验证数据集上的正确率信息会有一个独立的程序来生成。
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
# 保存当前的模型。注意这里给出了global_step参数,这样可以让每个被保存的模型的文件名末尾加上训练的轮数,
# 比如“model.ckpt-1000” 表示训练1000轮之后得到的模型。
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step)
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
train_writer.close()
def main(argv = None):
mnist = input_data.read_data_sets("D:/Python3Space/BookStudy/book2/MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
运行后:

启动TensorBoard,这样就可以可视化每个TensorFlow计算节点在某一次运行时所消耗的时间和空间。


TensorBoard左侧的Color栏中Compute和Memory这两个选项将可以被选择。


颜色越深的节点,时间和空间的消耗越大。

- 空心的小椭圆对应了TensorFlow计算图上的一个计算节点。
- 一个矩形对应了计算图上的一个命名空间。
7.3 监控指标可视化
将TensorFlow程序运行时的信息输出到TensorBoard日志文件中。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test6.py
@time: 2019/5/11 15:27
@desc: 将TensorFlow程序运行时的信息输出到TensorBoard日志文件中。
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
SUMMARY_DIR = './log'
BATCH_SIZE = 100
TRAIN_STEPS = 3000
# 生成变量监控信息并定义生成监控信息日志的操作。其中var给出了需要记录的张量,name给出了
# 在可视化结果中显示的图标名称,这个名称一般与变量名一致。
def variable_summaries(var, name):
# 将生成监控信息的操作放到同一个命名空间下。
with tf.name_scope('summaries'):
# 通过tf.summary.histogram函数记录张量中元素的取值分布。对于给出的图表
# 名称和张量,tf.summary.histogram函数会生成一个Summary protocol buffer。
# 将Summary写入TensorBoard日志文件后,在HISTOGRAMS栏和DISTRIBUTION栏
# 下都会出现对应名称的图标。和TensorFlow中其他操作类似。tf.summary.histogram
# 函数不会立刻被执行,只有当sess.run函数明确调用这个操作时,TensorFlow才会真正
# 生成并输出Summary protocol buffer。下文将更加详细地介绍如何理解HISTOGRAMS栏
# 和DISTRIBUTION栏下的信息。
tf.summary.histogram(name, var)
# 计算变量的平均值,并定义间生成平均值信息日志的操作。记录变量平均值信息的日志标签名
# 为'mean/' + name,其中mean为命名空间,/是命名空间的分隔符。从图中可以看出,在相同
# 命名空间中的监控指标会被整合到同一栏中。name则给出了当前监控指标属于哪一个变量。
mean = tf.reduce_mean(var)
tf.summary.scalar('mean/' + name, mean)
# 计算变量的标准差,并定义生成其日志的操作。
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar('stddev/' + name, stddev)
# 生成一层全连接层神经网络。
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
# 将同一层神经网络放在一个统一的命名空间下。
with tf.name_scope(layer_name):
# 声明神经网络边上的权重,并调用生成权重监控信息日志的函数。
with tf.name_scope('weights'):
weights = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
variable_summaries(weights, layer_name + '/weights')
# 声明神经网络的偏置项,并调用生成偏置项监控信息日志的函数。
with tf.name_scope('biases'):
biases = tf.Variable(tf.constant(0.0, shape=[output_dim]))
variable_summaries(biases, layer_name + '/biases')
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
# 记录神经网络输出节点在经过激活函数之前的分布。
tf.summary.histogram(layer_name + '/pre_activations', preactivate)
activations = act(preactivate, name='activation')
# 记录神经网络输出节点在经过激活函数之后的分布。在图中,对于layer1,因为
# 使用了ReLU函数作为激活函数,所以所有小于0的值都被设为了0。于是在激活后的
# layer1/activations图上所有的值都是大于0的。而对于layer2,因为没有使用
# 激活函数,所以layer2/activations和layer2/pre_activations一样。
tf.summary.histogram(layer_name + '/activations', activations)
return activations
def main(_):
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
# 定义输出
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# 将输入向量还原成图片的像素矩阵,并通过tf.summary.image函数定义将当前的图片信息写入日志的操作。
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
hidden1 = nn_layer(x, 784, 500, 'layer1')
y = nn_layer(hidden1, 500, 10, 'layer2', act=tf.identity)
# 计算交叉熵并定义生成交叉熵监控日志的操作。
with tf.name_scope('cross_entropy'):
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_))
tf.summary.scalar('cross entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 计算模型在当前给定数据上的正确率,并定义生成正确率监控日志的操作。如果在sess.run时
# 给定的数据是训练batch,那么得到的正确率就是在这个训练batch上的正确率;如果给定的
# 数据为验证或者测试数据,那么得到的正确率就是在当前模型在验证或者测试数据上的正确率。
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(y_, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 和其他TensorFlow中其他操作类似,tf.summary.scalar、tf.summary.histogram和
# tf.summary.image函数都不会立即执行,需要通过sess.run来明确调用这些函数。
# 因为程序中定义的写日志操作比较多,一一调用非常麻烦,所以TensorFlow提供了
# tf.summary.merge_all函数来整理所有的日志生成操作。在TensorFlow程序执行的
# 过程中只需要运行这个操作就可以将代码中定义的所有日志生成操作执行一次,从而将所有日志写入文件。
merged = tf.summary.merge_all()
with tf.Session() as sess:
# 初始化写日志的writer,并将当前TensorFlow计算图写入日志
summary_writer = tf.summary.FileWriter(SUMMARY_DIR, sess.graph)
tf.global_variables_initializer().run()
for i in range(TRAIN_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
# 运行训练步骤以及所有的日志生成操作,得到这次运行的日志。
summary, _ = sess.run([merged, train_step], feed_dict={x: xs, y_: ys})
# 将所有日志写入文件,TensorBoard程序就可以拿到这次运行所对应的运行信息。
summary_writer.add_summary(summary, i)
summary_writer.close()
if __name__ == '__main__':
tf.app.run()
运行之后打开tensorboard:

点击IMAGES栏可以可视化当前轮训练使用的图像信息。

TensorBoard的DISTRIBUTION一栏提供了对张量取值分布的可视化界面,通过这个界面可以直观地观察到不同层神经网络中参数的取值变化。

为了更加清晰地展示参数取值分布和训练迭代轮数之间的关系,TensorBoard提供了HISTOGRAMS视图。

颜色越深的平面代表迭代轮数越小的取值分布。
点击“OVERLAY”后,可以看到如下效果:

7.4 高维向量可视化
使用MNIST测试数据生成PROJECTOR所需要的两个文件。(一个sprite图像,一个tsv文件)
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test7.py
@time: 2019/5/12 20:45
@desc: 使用MNIST测试数据生成PROJECTOR所需要的两个文件。(一个sprite图像,一个tsv文件)
"""
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import os
from tensorflow.examples.tutorials.mnist import input_data
# PROJECTOR需要的日志文件名和地址相关参数。
LOG_DIR = './log2'
SPRITE_FILE = 'mnist_sprite.jpg'
META_FILE = "mnist_meta.tsv"
# 使用给出的MNIST图片列表生成sprite图像。
def create_sprite_image(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
# sprite图像可以理解成是所有小图片拼成的大正方形矩阵,大正方形矩阵中的每一个
# 元素就是原来的小图片。于是这个正方形的边长就是sqrt(n),其中n为小图片的数量。
# np.ceil向上取整。np.floor向下取整。
m = int(np.ceil(np.sqrt(images.shape[0])))
# 使用全1来初始化最终的大图片。
sprite_image = np.ones((img_h*m, img_w*m))
for i in range(m):
for j in range(m):
# 计算当前图片的编号
cur = i * m + j
if cur < images.shape[0]:
# 将当前小图片的内容复制到最终的sprite图像。
sprite_image[i*img_h: (i+1)*img_h, j*img_w: (j+1)*img_w] = images[cur]
return sprite_image
# 加载MNIST数据。这里指定了one_hot=False,于是得到的labels就是一个数字,表示当前图片所表示的数字。
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=False)
# 生成sprite图像
to_visualise = 1 - np.reshape(mnist.test.images, (-1, 28, 28))
sprite_image = create_sprite_image(to_visualise)
# 将生成的sprite图像放到相应的日志目录下。
path_for_mnist_sprites = os.path.join(LOG_DIR, SPRITE_FILE)
plt.imsave(path_for_mnist_sprites, sprite_image, cmap='gray')
plt.imshow(sprite_image, cmap='gray')
# 生成每张图片对应的标签文件并写到相应的日志目录下。
path_for_mnist_metadata = os.path.join(LOG_DIR, META_FILE)
with open(path_for_mnist_metadata, 'w') as f:
f.write('Index\tLabel\n')
for index, label in enumerate(mnist.test.labels):
f.write("%d\t%d\n" % (index, label))
这里写点小tips关于np.ceil、np.floor、enumerate:
np.ceil:向上取整。
np.floor:向下取整。
enumerate:该函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标。

回到正题,运行代码之后可以得到两个文件,一个是sprite图,一个是mnist_meta.csv文件。


在生成好辅助数据之后,以下代码展示了如何使用TensorFlow代码生成PROJECTOR所需要的日志文件来可视化MNIST测试数据在最后的输出层向量。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: tensorboard_test8.py
@time: 2019/5/13 9:34
@desc: 在生成好辅助数据之后,以下代码展示了如何使用TensorFlow代码生成PROJECTOR所需要的日志文件来可视化MNIST测试数据在最后的输出层向量。
"""
import tensorflow as tf
from BookStudy.book2 import mnist_inference
import os
# 加载用于生成PROJECTOR日志的帮助函数。
from tensorflow.contrib.tensorboard.plugins import projector
from tensorflow.examples.tutorials.mnist import input_data
# 和前面中类似地定义训练模型需要的参数。这里我们同样是复用mnist_inference过程。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
# 可以通过调整这个参数来控制训练迭代轮数。
TRAINING_STEPS = 10000
MOVING_AVERAGE_DECAY = 0.99
# 和日志文件相关的文件名及目录地址。
LOG_DIR = './log3'
SPRITE_FILE = 'D:/Python3Space/BookStudy/book2/tensorboard_test/log2/mnist_sprite.jpg'
META_FILE = 'D:/Python3Space/BookStudy/book2/tensorboard_test/log2/mnist_meta.tsv'
TENSOR_NAME = 'FINAL_LOGITS'
# 训练过程和前面给出的基本一致,唯一不同的是这里还需要返回最后测试数据经过整个
# 神经网络得到的输出矩阵(因为有很多张测试图片,每张图片对应了一个输出层向量,
# 所以返回的结果是这些向量组成的矩阵。
def train(mnist):
# 输入数据的命名空间。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 处理滑动平均的命名空间。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算损失函数的命名空间。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 定义学习率、优化方法及每一轮执行训练操作的命名空间。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase=True
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 训练模型
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (i, loss_value))
# 计算MNIST测试数据对应的输出层矩阵。
final_result = sess.run(y, feed_dict={x: mnist.test.images})
# 返回输出层矩阵的值。
return final_result
# 生成可视化最终输出层向量所需要的日志文件。
def visualisation(final_result):
# 使用一个新的变量来保存最终输出层向量的结果。因为embedding是通过TensorFlow中
# 变量完成的,所以PROJECTOR可视化的都是TensorFlow中的变量。于是这里需要新定义
# 一个变量来保存输出层向量的取值。
y = tf.Variable(final_result, name=TENSOR_NAME)
summary_writer = tf.summary.FileWriter(LOG_DIR)
# 通过projector.ProjectorConfig类来帮助生成日志文件。
config = projector.ProjectorConfig()
# 增加一个需要可视化的embedding结果。
embedding = config.embeddings.add()
# 指定这个embedding结果对应的TensorFlow变量名称。
embedding.tensor_name = y.name
# 指定embedding结果所对应的原始数据信息。比如这里指定的就是每一张MNIST测试图片
# 对应的真实类别。在单词向量中可以是单词ID对应的单词。这个文件是可选的,如果没有指定
# 那么向量就没有标签。
embedding.metadata_path = META_FILE
# 指定sprite图像。这个也是可选的,如果没有提供sprite图像,那么可视化的结果
# 每一个点就是一个小圆点,而不是具体的图片。
embedding.sprite.image_path = SPRITE_FILE
# 在提供sprite图像时,通过single_image_dim可以指定单张图片的大小。
# 这将用于从sprite图像中截取正确的原始图片。
embedding.sprite.single_image_dim.extend([28, 28])
# 将PROJECTOR所需要的内容写入日志文件。
projector.visualize_embeddings(summary_writer, config)
# 生成会话,初始化新声明的变量并将需要的日志信息写入文件。
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.save(sess, os.path.join(LOG_DIR, "model"), TRAINING_STEPS)
summary_writer.close()
# 主函数先调用模型训练的过程,再使用训练好的模型来处理MNIST测试数据,
# 最后将得到的输出层矩阵输出到PROJECTOR需要的日志文件中。
def main(argc=None):
mnist = input_data.read_data_sets('D:/Python3Space/BookStudy/book2/MNIST_data', one_hot=True)
final_result = train(mnist)
visualisation(final_result)
if __name__ == '__main__':
main()
运行结果:

然后打开tensorboard:

然后就GG了,网上百度了一万种方法。。。
参考链接:https://blog.csdn.net/weixin_42769131/article/details/84870558
tensorboard --logdir=./log3 --host=127.0.0.1
解决!然而!我可以打开前面的log,这次模型的生成的不知道是不是需要太大的内存,界面一致卡在Computing PCA…

就很头大。。。
然后我换了台电脑(MacBook),就能直接出来。。。

还是三围旋转的。。。旋转~ 跳跃~
然后我把tensorflow和numpy的包升级之后,终于不卡了。。。
可是:

这一片空白白是什么。。。你看我脸上是不是写满了快乐。。。
8. TensorBoard计算加速
8.1 TensorFlow使用GPU
1. 如何使用log_device_placement参数来打印运行每一个运算的设备。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test1.py
@time: 2019/5/14 19:40
@desc: 如何使用log_device_placement参数来打印运行每一个运算的设备
"""
import tensorflow as tf
a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
c = a + b
# 通过log_device_placement参数来输出运行每一个运算的设备。
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
运行结果:

2. 通过tf.device手工指定运行设备的样例。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test2.py
@time: 2019/5/14 19:54
@desc: 通过tf.device手工指定运行设备的样例。
"""
import tensorflow as tf
# 通过tf.device将运行指定到特定的设备上。
with tf.device('/cpu:0'):
a = tf.constant([1.0, 2.0, 3.0], shape=[3], name='a')
b = tf.constant([1.0, 2.0, 3.0], shape=[3], name='b')
with tf.device('/gpu:1'):
c = a + b
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
由于我并没有GPU,所以只是尬码代码。。。
3. 不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,那么程序将会报错。
4. 为了避免这个问题,TensorFlow在生成会话时,可以指定allow_soft_placement参数,当这个参数为True时,如果运算无法由GPU执行,那么TensorFlow会自动将它放到CPU上执行。
8.2 深度学习训练并行模式
- 常用的并行化深度学习模型训练方式有两种,同步模式和异步模式。
- 可以简单的认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。
- 在异步模式下,不同设备之间是完全独立的。
- 使用异步模式训练的深度学习模型有可能无法达到较优的训练结果。
- 在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。
- 总结来说就是,异步模式达到全局最优要难一些,但是速度快;同步模式更能达到全局最优,但墨迹。两者都有应用。
8.3 多GPU并行
在多GPU上训练深度学习模型解决MNIST问题。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test3.py
@time: 2019/5/15 10:35
@desc: 在多GPU上训练深度学习模型解决MNIST问题。
"""
from datetime import datetime
import os
import time
import tensorflow as tf
import BookStudy.book2.mnist_inference as mnist_inference
# 定义训练神经网络时需要用到的模型。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.001
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 1000
MOVING_AVERAGE_DECAY = 0.99
N_GPU = 2
# 定义日志和模型输出的路径
MODEL_SAVE_PATH = 'logs_and_models/'
MODEL_NAME = 'model.ckpt'
# 定义数据存储的路径。因为需要为不同的GPU提供不同的训练数据,所以通过placeholder的方式
# 就需要手动准备多份数据。为了方便训练数据的获取过程,可以采用前面介绍的Dataset的方式从
# TFRecord中读取数据。于是在这里提供的数据文件路径为将MNIST训练数据转化为TFRecord格式
# 之后的路径。如何将MNIST数据转化为TFRecord格式在前面有详细介绍,这里不再赘述。
DATA_PATH = 'output.tfrecords'
# 定义输入队列得到的训练数据,具体细节可以参考前面。
def get_input():
dataset = tf.data.TFRecordDataset([DATA_PATH])
# 定义数据解析格式。
def parser(record):
features = tf.parse_single_example(
record,
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'pixels': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
}
)
# 解析图片和标签信息。
decoded_image = tf.decode_raw(features['image_raw'], tf.uint8)
reshaped_image = tf.reshape(decoded_image, [784])
retyped_image = tf.cast(reshaped_image, tf.float32)
label = tf.cast(features['label', tf.int32])
return retyped_image, label
# 定义输入队列
dataset = dataset.map(parser)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.repeat(10)
dataset = dataset.batch(BATCH_SIZE)
iterator = dataset.make_one_shot_iterator()
features, labels = iterator.get_next()
return features, labels
# 定义损失函数。对于给定的训练数据、正则化损失计算规则和命名空间,计算在这个命名空间下的总损失。
# 之所以需要给定命名空间就是因为不同的GPU上计算得出的正则化损失都会加入名为loss的集合,如果不
# 通过命名空间就会将不同GPU上的正则化损失都加进来。
def get_loss(x, y_, regularizer, scope, reuse_variables=None):
# 沿用前面定义的函数来计算神经网络的前向传播结果。
with tf.variable_scope(tf.get_variable_scope(), reuse=reuse_variables):
y = mnist_inference.inference(x, regularizer)
# 计算交叉熵损失。
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=y_))
# 计算当前GPU上计算得到的正则化损失。
regularization_loss = tf.add_n(tf.get_collection('losses', scope))
# 计算最终的总损失。
loss = cross_entropy + regularization_loss
return loss
# 计算每一个变量梯度的平均值。
def average_gradients(tower_grads):
average_grads = []
# 枚举所有的变量和变量在不同GPU上计算得出的梯度。
for grad_and_vars in zip(*tower_grads):
# 计算所有GPU上的梯度平均值
grads = []
for g, _ in grad_and_vars:
expanded_g = tf.expand_dims(g, 0)
grads.append(expanded_g)
grad = tf.concat(grads, 0)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
# 将变量和它的平均梯度对应起来。
average_grads.append(grad_and_var)
# 返回所有变量的平均梯度,这个将被用于变量的更新。
return average_grads
# 主训练过程。
def main(argv=None):
# 将简单的运算放在CPU上,只有神经网络的训练过程在GPU上。
with tf.Graph().as_default(), tf.device('/cpu:0'):
# 定义基本的训练过程
x, y_ = get_input()
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
global_step = tf.get_variable('global_step', [], initializer=tf.constant_initializer(0), trainable=False)
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, 60000/BATCH_SIZE, LEARNING_RATE_DECAY)
opt = tf.train.GradientDescentOptimizer(learning_rate)
tower_grads = []
reuse_variables = False
# 将神经网络的优化过程跑在不同的GPU上。
for i in range(N_GPU):
# 将优化过程指定在一个GPU上
with tf.device('/gpu:%d' % i):
with tf.name_scope('GPU_%d' % i) as scope:
cur_loss = get_loss(x, y_, regularizer, scope, reuse_variables)
# 在第一次声明变量之后,将控制变量重用的参数设置为True。这样可以让不同的GPU更新同一组参数
reuse_variables = True
grads = opt.compute_gradients(cur_loss)
tower_grads.append(grads)
# 计算变量的平均梯度
grads = average_gradients(tower_grads)
for grad, var in grads:
if grad is not None:
tf.summary.histogram('gradients_on_average/%s' % var.op.name, grad)
# 使用平均梯度更新参数。
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
for var in tf.trainable_variables():
tf.summary.histogram(var.op.name, var)
# 计算变量的滑动平均值。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_to_average = (tf.trainable_variables() + tf.moving_average_variables())
variable_averages_op = variable_averages.apply(variable_to_average)
# 每一轮迭代需要更新变量的取值并更新变量的滑动平均值
train_op = tf.group(apply_gradient_op, variable_averages_op)
saver = tf.train.Saver()
summary_op = tf.summary.merge_all()
init = tf.global_variables_initializer()
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)) as sess:
# 初始化所有变量并启动队列。
init.run()
summary_writer = tf.summary.FileWriter(MODEL_SAVE_PATH, sess.graph)
for step in range(TRAINING_STEPS):
# 执行神经网络训练操作,并记录训练操作的运行时间。
start_time = time.time()
_, loss_value = sess.run([train_op, cur_loss])
duration = time.time() - start_time
# 每隔一段时间输出当前的训练进度,并统计训练速度
if step != 0 and step % 10 == 0:
# 计算使用过的训练数据个数。因为在每一次运行训练操作时,每一个GPU都会使用一个batch的训练数据,
# 所以总共用到的训练数据个数为batch大小 X GPU个数。
num_examples_per_step = BATCH_SIZE * N_GPU
# num_example_per_step为本次迭代使用到的训练数据个数,duration为运行当前训练过程使用的时间,
# 于是平均每秒可以处理的训练数据个数为num_examples_per_step / duration
examples_per_sec = num_examples_per_step / duration
# duration为运行当前训练过程使用的时间,因为在每一个训练过程中,每一个GPU都会使用一个batch的
# 训练数据,所以在单个batch上的训练所需要的时间为duration / GPU个数
sec_per_batch = duration / N_GPU
# 输出训练信息。
format_str = '%s: step %d, loss = %.2f (%.1f examples/sec; %.3f sec/batch)'
print(format_str % (datetime.now(), step, loss_value, examples_per_sec, sec_per_batch))
# 通过TensorBoard可视化训练过程。
summary = sess.run(summary_op)
summary_writer.add_summary(summary, step)
# 每隔一段时间保存当前的模型。
if step % 1000 == 0 or (step + 1) == TRAINING_STEPS:
checkpoint_path = os.path.join(MODEL_SAVE_PATH, MODEL_NAME)
saver.save(sess, checkpoint_path, global_step=step)
if __name__ == '__main__':
tf.app.run()
由于我依然没有GPU,所以只是尬码代码。。。
8.4 分布式TensorFlow
分布式TensorFlow原理
- 创建一个最简单的TensorFlow集群。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test4.py
@time: 2019/5/15 22:19
@desc: 创建一个最简单的TensorFlow集群
"""
import tensorflow as tf
c = tf.constant("Hello, distributed TensorFlow!")
# 创建一个本地的TensorFlow集群
server = tf.train.Server.create_local_server()
# 在集群上创建一个会话。
sess = tf.Session(server.target)
# 输出Hello,distributed TensorFlow!
print(sess.run(c))
输出得到:

- 在本地运行有两个任务的TensorFlow集群。
第一个任务代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test5.py
@time: 2019/5/15 22:27
@desc: 在本地运行有两个任务的TensorFlow集群。第一个任务的代码。
"""
import tensorflow as tf
c = tf.constant("Hello from server1!")
# 生成一个有两个任务的集群,一个任务跑在本地2222端口,另外一个跑在本地2223端口。
cluster = tf.train.ClusterSpec({"local": ["localhost: 2222", "localhost: 2223"]})
# 通过上面生成的集群配置生成Server,并通过job_name和task_index指定当前所启动的任务。
# 因为该任务是第一个任务,所以task_index为0.
server = tf.train.Server(cluster, job_name="local", task_index=0)
# 通过server.target生成会话来使用TensorFlow集群中的资源。通过设置
# log_device_placement可以看到执行每一个操作的任务。
sess = tf.Session(server.target, config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
server.join()
第二个任务代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test6.py
@time: 2019/5/16 10:14
@desc: 在本地运行有两个任务的TensorFlow集群。第二个任务的代码。
"""
import tensorflow as tf
c = tf.constant("Hello from server2!")
# 和第一个程序一样的集群配置。集群中的每一个任务需要采用相同的配置。
cluster = tf.train.ClusterSpec({"local": ["localhost: 2222", "localhost: 2223"]})
# 指定task_index为1,所以这个程序将在localhost: 2223启动服务。
server = tf.train.Server(cluster, job_name="local", task_index=1)
# 剩下的代码都和第一个任务的代码一致。
# 通过server.target生成会话来使用TensorFlow集群中的资源。通过设置
# log_device_placement可以看到执行每一个操作的任务。
sess = tf.Session(server.target, config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
server.join()
启动第一个任务后,可以得到类似下面的输出:

从第一个任务的输出中可以看到,当只启动第一个任务时,程序会停下来等待第二个任务启动。当第二个任务启动后,可以得到如下输出:


值得注意的是:第二个任务中定义的计算也被放在了同一个设备上,也就是说这个计算将由第一个任务来执行。
使用分布式TensorFlow训练深度学习模型一般有两种方式:
- 一种方式叫做计算图内分布式(in-graph replication)。优点:同步更新参数比较容易控制。缺点:当数据量太大时,中心节点容易造成性能瓶颈。
- 另外一种叫做计算图之间分布式(between-graph replication)。优点:并行程度更高。缺点:同步更新困难。
分布式TensorFlow模型训练
异步模式样例程序
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test7.py
@time: 2019/5/16 14:01
@desc: 实现异步模式的分布式神经网络训练过程。
"""
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.001
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 20000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径。
MODEL_SAVE_PATH = "./log1"
# MNIST数据路径。
DATA_PATH = "D:/Python3Space/BookStudy/book2/MNIST_data"
# 通过flags指定运行的参数。在前面对于不同的任务(task)给出了不同的程序。
# 但这不是一种可扩展的方式。在这一节中将使用运行程序时给出的参数来配置在
# 不同任务中运行的程序。
FLAGS = tf.app.flags.FLAGS
# 指定当前运行的是参数服务器还是计算服务器。参数服务器只负责TensorFlow中变量的维护
# 和管理,计算服务器负责每一轮迭代时运行反向传播过程。
tf.app.flags.DEFINE_string('job_name', 'worker', ' "ps" or "worker" ')
# 指定集群中的参数服务器地址。
tf.app.flags.DEFINE_string(
'ps_hosts', ' tf-ps0:2222,tf-ps1:1111',
'Comma-separated list of hostname:port for the parameter server jobs.'
' e.g. "tf-ps0:2222,tf-ps1:1111" '
)
# 指定集群中的计算服务器地址。
tf.app.flags.DEFINE_string(
'worker_hosts', ' tf-worker0:2222, tf-worker1:1111',
'Comma-separated list of hostname:port for the worker jobs. '
'e.g. "tf-worker0:2222,tf-worker1:1111" '
)
# 指定当前程序的任务ID。TensorFlow会自动根据参数服务器/计算服务器列表中的端口号来启动服务。
# 注意参数服务器和计算服务器的编号都是从0开始的。
tf.app.flags.DEFINE_integer(
'task_id', 0, 'Task ID of the worker/replica running the training.'
)
# 定义TensorFlow的计算图,并返回每一轮迭代时需要运行的操作。这个过程和前面的主函数基本一致,
# 但为了使处理分布式计算的部分更加突出,这里将此过程整理为一个函数。
def build_model(x, y_, is_chief):
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
# 通过前面给出的mnist_inference计算神经网络前向传播的结果。
y = mnist_inference.inference(x, regularizer)
global_step = tf.train.get_or_create_global_step()
# 计算损失函数并定义反向传播的过程。
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
60000 / BATCH_SIZE,
LEARNING_RATE_DECAY
)
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 定义每一轮迭代需要运行的操作。
if is_chief:
# 计算变量的滑动平均值。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([variable_averages_op, train_op]):
train_op = tf.no_op()
return global_step, loss, train_op
def main(argv=None):
# 解析flags并通过tf.train.ClusterSpe配置TensorFlow集群。
ps_hosts = FLAGS.ps_hosts.split(',')
worker_hosts = FLAGS.worker_hosts.split(',')
cluster = tf.train.ClusterSpec({'ps': ps_hosts, 'worker': worker_hosts})
# 通过tf.train.ClusterSpec以及当前任务创建tf.train.Server。
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_id)
# 参数服务器只需要管理TensorFlow中的变量,不需要执行训练的过程。server.join()会一直停在这条语句上。
if FLAGS.job_name == 'ps':
with tf.device("/cpu:0"):
server.join()
# 定义计算服务器需要运行的操作。
is_chief = (FLAGS.task_id == 0)
mnist = input_data.read_data_sets(DATA_PATH, one_hot=True)
# 通过tf.train.replica_device_setter函数来指定执行每一个运算的设备。
# tf.train.replica_device_setter函数会自动将所有的参数分配到参数服务器上,将
# 计算分配到当前的计算服务器上。
device_setter = tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_id,
cluster=cluster
)
with tf.device(device_setter):
# 定义输入并得到每一轮迭代需要运行的操作。
x = tf.placeholder(
tf.float32,
[None, mnist_inference.INPUT_NODE],
name='x-input'
)
y_ = tf.placeholder(
tf.float32,
[None, mnist_inference.OUTPUT_NODE],
name='y-input'
)
global_step, loss, train_op = build_model(x, y_, is_chief)
hooks = [tf.train.StopAtStepHook(last_step=TRAINING_STEPS)]
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
# 通过tf.train.MonitoredTrainingSession管理训练深度学习模型的通用功能。
with tf.train.MonitoredTrainingSession(
master=server.target,
is_chief=is_chief,
checkpoint_dir=MODEL_SAVE_PATH,
hooks=hooks,
save_checkpoint_secs=60,
config=sess_config
) as mon_sess:
print("session started.")
step = 0
start_time = time.time()
# 执行迭代过程。在迭代过程中tf.train.MonitoredTrainingSession会帮助完成初始化、
# 从checkpoint中加载训练过的模型、输出日志并保存模型,所以以下程序中不需要再调用
# 这些过程。tf.train.StopAtStepHook会帮忙判断是否需要退出。
while not mon_sess.should_stop():
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, global_step_value = mon_sess.run(
[train_op, loss, global_step],
feed_dict={x: xs, y_: ys}
)
# 每隔一段时间输出训练信息,不同的计算服务器都会更新全局的训练轮数,
# 所以这里使用global_step_value得到在训练中使用过的batch的总数。
if step > 0 and step % 100 == 0:
duration = time.time() - start_time
sec_per_batch = duration / global_step_value
format_str = "After %d training steps (%d global steps), loss on training batch is %g. (%.3f sec/batch)"
print(format_str % (step, global_step_value, loss_value, sec_per_batch))
step += 1
if __name__ == '__main__':
try:
tf.app.run()
except Exception as e:
print(e)
要启动一个拥有一个参数服务器、两个计算服务器的集群,需要现在运行参数服务器的机器上启动以下命令。
python gpu_test7.py --job_name=ps --task_id=0 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224
然后再运行第一个计算服务器的机器上启动以下命令:
python gpu_test7.py --job_name=worker --task_id=0 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224
最后再运行第二个计算服务器的机器上启动以下命令:
python gpu_test7.py --job_name=worker --task_id=1 --ps_hosts=localhost:2222 --worker_hosts=localhost:2223,localhost:2224
注意:如果你报错了:
1. UnknownError: Could not start gRPC server
一定是你的参数问题!检查你的task_id有没有写成taske_id等等,类似的,一定是这样!!!一定要跟程序中的参数名保持一致!!!
2. 跑的过程中python搞不清楚崩了,两个计算服务器都会崩,跟时间无关,随机的那种。。。直接弹出python已停止的那种
听我的换台电脑或者重装系统。
3. 报错‘ps’不存在的,没定义的注意了!
在cmd(windows系统)中启动上面三个命令的时候,参数的内容不要加引号!!!书上面加引号真的是坑死了好吗!
我就是解决了上述三个问题,换了台macbook,才总算功德圆满了跑出了结果。

左上:参数服务器
右上:计算服务器0
左下:计算服务器1
右下:运行tensorboard,结果如下:

同步模式样例程序
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: gpu_test8.py
@time: 2019/5/17 13:52
@desc: 实现同步模式的分布式神经网络训练过程。
"""
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
# 配置神经网络的参数。
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.001
LEARNING_RATE_DECAY = 0.99
REGULARAZTION_RATE = 0.0001
TRAINING_STEPS = 20000
MOVING_AVERAGE_DECAY = 0.99
# 模型保存的路径。
MODEL_SAVE_PATH = "./log2"
# MNIST数据路径。
DATA_PATH = "D:/Python3Space/BookStudy/book2/MNIST_data"
# 和异步模式类似的设置flags。
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('job_name', 'worker', ' "ps" or "worker" ')
tf.app.flags.DEFINE_string(
'ps_hosts', ' tf-ps0:2222, tf-ps1:1111',
'Comma-separated list of hostname:port for the parameter server jobs.'
' e.g. "tf-ps0:2222,tf-ps1:1111" '
)
tf.app.flags.DEFINE_string(
'worker_hosts', ' tf-worker0:2222, tf-worker1:1111',
'Comma-separated list of hostname:port for the worker jobs. '
'e.g. "tf-worker0:2222,tf-worker1:1111" '
)
tf.app.flags.DEFINE_integer(
'task_id', 0, 'Task ID of the worker/replica running the training.'
)
# 和异步模式类似的定义TensorFlow的计算图。唯一的区别在于使用。
# tf.train.SyncReplicasOptimizer函数处理同步更新。
def build_model(x, y_, n_workers, is_chief):
regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.train.get_or_create_global_step()
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
60000 / BATCH_SIZE,
LEARNING_RATE_DECAY
)
# 通过tf.train.SyncReplicasOptimizer函数实现同步更新。
opt = tf.train.SyncReplicasOptimizer(
tf.train.GradientDescentOptimizer(learning_rate),
replicas_to_aggregate=n_workers,
total_num_replicas=n_workers
)
sync_replicas_hook = opt.make_session_run_hook(is_chief)
train_op = opt.minimize(loss, global_step=global_step)
if is_chief:
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variable_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.control_dependencies([variable_averages_op, train_op]):
train_op = tf.no_op()
return global_step, loss, train_op, sync_replicas_hook
def main(argv=None):
# 和异步模式类似地创建TensorFlow集群。
ps_hosts = FLAGS.ps_hosts.split(',')
worker_hosts = FLAGS.worker_hosts.split(',')
n_workers = len(worker_hosts)
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_id)
if FLAGS.job_name == 'ps':
with tf.device("/cpu:0"):
server.join()
is_chief = (FLAGS.task_id == 0)
mnist = input_data.read_data_sets(DATA_PATH, one_hot=True)
device_setter = tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_id,
cluster=cluster
)
with tf.device(device_setter):
# 定义输入并得到每一轮迭代需要运行的操作。
x = tf.placeholder(
tf.float32,
[None, mnist_inference.INPUT_NODE],
name='x-input'
)
y_ = tf.placeholder(
tf.float32,
[None, mnist_inference.OUTPUT_NODE],
name='y-input'
)
global_step, loss, train_op, sync_replicas_hook = build_model(x, y_, n_workers, is_chief)
# 把处理同步更新的hook也加进来
hooks = [sync_replicas_hook, tf.train.StopAtStepHook(last_step=TRAINING_STEPS)]
sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
# 训练过程和异步一致。
with tf.train.MonitoredTrainingSession(
master=server.target,
is_chief=is_chief,
checkpoint_dir=MODEL_SAVE_PATH,
hooks=hooks,
save_checkpoint_secs=60,
config=sess_config
) as mon_sess:
print("session started.")
step = 0
start_time = time.time()
while not mon_sess.should_stop():
xs, ys = mnist.train.next_batch(BATCH_SIZE)
_, loss_value, global_step_value = mon_sess.run(
[train_op, loss, global_step],
feed_dict={x: xs, y_: ys}
)
if step > 0 and step % 100 == 0:
duration = time.time() - start_time
sec_per_batch = duration / global_step_value
format_str = "After %d training steps (%d global steps), loss on training batch is %g. (%.3f sec/batch)"
print(format_str % (step, global_step_value, loss_value, sec_per_batch))
step += 1
if __name__ == '__main__':
tf.app.run()
同上运行出来得到:


和异步模式不同,在同步模式下,global_step差不多是两个计算服务器local_step的平均值。比如在第二个计算服务器还没有开始之前,global_step是第一个服务器local_step的一般。这是因为同步模式要求收集replicas_to_average份梯度才会开始更新(注意这里TensorFlow不要求每一份梯度来自不同的计算服务器)。同步模式不仅仅是一次使用多份梯度,tf.train.SyncReplicasOptimizer的实现同时也保证了不会出现陈旧变量的问题,该函数会记录每一份梯度是不是由最新的变量值计算得到的,如果不是,那么这一份梯度将会被丢弃。
9. 写在最后
总算是把这本书一步一步的实现,一步一步的修改,从头认认真真的刷了一遍。取其精华,弃其糟粕。学习TensorFlow真的是一件不容易,也是一件很有成就感的过程。还有黑皮书《TensorFlow实战》和圣经花书《深度学习》要学,希望后面的书不会让我失望吧。
- ☁️ 我的CSDN:https://blog.csdn.net/qq_21579045
- ❄️ 我的博客园:https://www.cnblogs.com/lyjun/
- ☀️ 我的Github:https://github.com/TinyHandsome
- 🌈 我的bilibili:https://space.bilibili.com/8182822
- 🐧 粉丝交流群:1060163543,神秘暗号:为干饭而来
碌碌谋生,谋其所爱。🌊 @李英俊小朋友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号