高纬数据的降维方法
http://blog.socona.me/2013/03/29/dim-reduce-high-dim-clustering.html
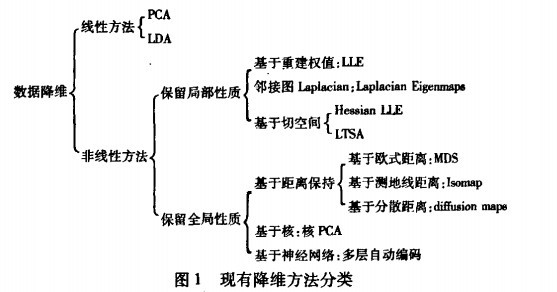
降维作为目前很多研究领域的重要研究分支之一,其方法本身就多种多样,根据降维方法的不同,产生了很多基于降维的聚类方法,如Kohonen自组织特征映射(self-organizing feature map,SOFM) 、主成分分析(Principle component analysis,PCA) 、多维缩放(Multi-dimensional scaling ,MDS) 等。此外还有一种特殊的降维聚类方法,即基于分形的降维 。
Kohonen 自组织特征映射是一种基于神经元网络的方法,它在保留数据的近似关系的前提下,寻求高维数据的低维特征映射,基于该方法对高维数据进行聚类处理,是一类典型的投影聚类方法。在Kohonen 自组织特征映射中,竞争层的每一个神经元都要相互竞争,胜出的神经元及其近邻神经元则更新它们的权值向量,以使其与输入数据尽可能相似。对神经网络进行训练之后,每个高维数据都将根据与神经元的权值向量的匹配情况投影到这些神经元上。
SOFM 的缺点在于它没有提供一个具体的准则来评价从高维到低维转换的优劣。而且对于很高维的数据而言,神经网络的训练过程收敛会很慢。主成分分析也是应用较为广泛的降维方法之一。对于一个包含n 个m 维数据的数据集,PCA 方法首先计算一个m ×m阶的协方差矩阵;然后计算该矩阵的k 个主导的特征向量,这k 个特征向量代表了原始数据的主要特征。在此基础上,即可把原始的高维数据沿着k 个特征向量代表的方向进行投影。由于投影之后的数据具有相对很低的维度,则可以利用传统的聚类算法进行聚类处理。
PCA 虽然提供了一些方法来确定上述k 值,但不同的方法所确定的k 值相差很大,因此还是很难找到正确合理的k 值。k 取值太小,会丢掉原始数据的重要特征;而k 取值过大,虽然能保留绝大部分原始信息,但投影之后的数据维度依然会很高,聚类处理仍然会很困难。PCA 的另一个缺陷在于,其空间复杂度是O(m2 ),时间复杂度是一个取决于特征值的数量并且大于O(m2)的值。为了将PCA 的成熟思想更好地应用于非线性降维领域,又有研究者对线性PCA 进行了扩展,从而产生了核PCA(Kernel PCA ) 。
多维缩放也是把高维数据映射到低维空间的一种方法,其映射过程保留了数据点之间的差异性(或相似性),即在原始数据集中相近的点仍然靠在一起,而远离的点仍然远离。该类算法的基本出发点是数据点之间的相似性(或差异性)描述。由于降维的目的就是寻求保持数据集感兴趣特性的低维数据集,通过低维数据的分析来获得相应的高维数据特性,从而达到简化分析、获取数据有效特征以及可视化数据的目标。因此,只要最大限度地保持数据间的差异性,便可获得有效的低维表示。MDS 的缺陷在于,首先它没有提供一个好的原则来确定究竟将数据降到多少维;此外,大多数该类方法的时间复杂度都是O(n2 )。其中n 为数据集的规模。
基于分形的降维是近年来才得到关注的一类方法。采用分形的思想,首先可以较为准确地估计出数据的本征维,从而为进一步降维提供指导性的参考。与其他方法对本征维的估计所不同的是,基于分形的方法能得到非整数值的本征维,即通常所说的分数维。关于分数维的定义,也有多种不同的描述,其中应用较广泛的是计盒维(box-counting dimension)和相关维(correlation dimension)。基于对这些相应维的估计,产生了一系列不同的方法,它们都为降维处理奠定了良好的基础。
我的添加:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号