剑指offer5-优化时间和空间效率
题目-数组中出现次数超过一半的数字
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。如果不存在则输出0。
思路
1.数组中有一个数字出现的次数超过数组长度的一半==它出现的次数比其他所有数字出现次数的和还要多;
因此我们考虑一种思路,定义一个count。如果数字相同,则count++;如果数字不同,则count--;
这样的话,最后存储的序列元素m,就是这个序列中最多的元素。
2.上面这种思路其实就是Boyer-Moore Majority Vote Algorithm(摩尔投票算法),一种在线性时间O(n)和空间复杂度的情况下,在一个元素序列中查找包含最多的元素。属于流算法(streaming algorithm)
即从头到尾遍历数组,遇到两个不一样的数就把两个数同时去掉,去掉的数可能都不是m,也可能一个是m。但是因为m出现的次数大于总长度的一半,所以删完了最后剩下的数是m。
本题是摩尔投票算法最简单的形式。
3.本题需要注意的问题是:该序列中不一定存在长度大于数组一半的数,也就是之前存储的序列中最多元素m,长度不一定符合要求。由于之前已经找出了这个数字,那么就再次验证,判断该数字的出现次数是否>数组一半的长度。
解法
public class Solution { public int MoreThanHalfNum_Solution(int [] array) { int m = array[0]; int count=0;//初始化状态下计数器为0
//算法依次扫描序列中的元素 for(int i=0;i<array.length;i++){
//处理元素x时,如果计数器为0,将x赋值给m。
if(count==0){ m=array[i]; count++; } else if(array[i]==m){ count++; } else count--; } //如果不存在长度大于数组一半的数,则输出0 //第二次遍历 count = 0; for(int v:array){ if(v == m) count++; } if(count<=array.length/2){ return 0; } return m; } }
题目-最小的K个数
输入n个整数,找出其中最小的K个数。例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,。
思路
1.本题最简单的思路就是把输入的n个整数排序,排序后位于数列最前面的k个数就是所求。此时时间复杂度是O(nlogn)
2.借用快速排序。快排的partition()方法,会返回一个整数 j 使得 a[l .. j-1]小于等于 a[j],且a[j+1,.., h]大于等于a[j],此时 a[j] 就是数组的第 j 大元素。可以利用这个特性找到数组的第K个元素。
当且仅当允许修改数组元素时才可以使用。复杂度是O(N)+O(1)
3.快排的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
4.如果不允许修改数组元素&处理海量数据的场景。那么采用维护大小为K的最小堆来实现。复杂度:O(NlogK)+O(K)
具体:在添加一个元素之后,如果大顶堆的大小大于K,那么需要将大顶堆的堆顶元素去除。
解法
import java.util.ArrayList; public class Solution { public ArrayList<Integer> GetLeastNumbers_Solution(int [] input, int k) { ArrayList<Integer> ret = new ArrayList<>(); if(k > input.length || k <= 0) return ret; findKthSmallest(input, k-1);
//findKthSmallest会改变数组,使得前k个数都是最小的k个数 for(int i=0; i<k ;i++) ret.add(input[i]); return ret; } public void findKthSmallest(int[] input, int k){ int low=0, high=input.length-1; while(low < high){ //找寻基准数据的正确索引 int j=partition(input, low, high); if(j==k) break; //进行迭代对index之前和之后的数组进行相同的操作使整个数组有序 if(j>k) high=j-1; else low=j+1; } } //分区操作,结束该分区后,基准数就放在数列的中间位置 private int partition(int[] input, int low, int high){ //基准数据 int p = input[low]; int i=low, j=high+1; while(true){ //从后往前找,找到比p小的第一个数 while(i!=high && input[++i]<p); //从前往后找,找到比p大的第一个数 while(j!=low && input[--j]>p); //直到i>=j,第一回结束。此时p之前的数都小于p,p之后的数都大于p if(i >= j) break; swap(input, i, j); } swap(input, low, j); return j; } private void swap(int[] input, int i, int j){ int t = input[i]; input[i] = input[j]; input[j] = t; } }
题目-连续子数组的最大和
HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学。今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向量全为正数的时候,问题很好解决。但是,如果向量中包含负数,是否应该包含某个负数,并期望旁边的正数会弥补它呢?例如:{6,-3,-2,7,-15,1,2,2},连续子向量的最大和为8(从第0个开始,到第3个为止)。给一个数组,返回它的最大连续子序列的和,你会不会被他忽悠住?(子向量的长度至少是1)
思路
1.分析数组的规律。当从头到尾累加数组的数字,初始化和为0。如对于数组{6,-3,-2,7,-15,1,2,2},首先加上第一个数字6,此时和为6;再加上-3,-2,7和为8;再加上-15,此时和为-7,小于0,如果用小于0的数字去加后面的数,还不如抛弃前面这段,直接从1开始。再设置一个greatestSum用来记录当前最大子数组的和。
2.32位的int,正数的范围是(0,0x7FFFFFFF),负数(0x80000000,0xFFFFFFFF)。所以设置int最小值为0x80000000
解法
public class Solution { public int FindGreatestSumOfSubArray(int[] array) { boolean invalidInput = false; if((array.length<=0) || (array==null) ){ invalidInput = true; return 0; } int curSum=0; //32位的int,正数的范围是(0,0x7FFFFFFF),负数(0x80000000,0xFFFFFFFF) int greatestSum=0x80000000; for(int i=0; i<array.length; i++){ if(curSum<=0){ curSum=array[i]; } else curSum=curSum+array[i]; if(curSum>greatestSum) greatestSum=curSum; } return greatestSum; } }
题目-整数中1出现的次数(从1到n整数中1出现的次数)
求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1、10、11、12、13因此共出现6次,但是对于后面问题他就没辙了。ACMer希望你们帮帮他,并把问题更加普遍化,可以很快的求出任意非负整数区间中1出现的次数(从1 到 n 中1出现的次数)。
思路
1.最直观的方式是:累加,通过每次对10求余判断,整数的个位数字是否为1.如果这个数字大于10,那么再次除以10.
这种方式,如果输入n,n为O(logn)位,需要判断每一位是不是1,那么时间复杂度是O(n*logn)
解法
public class Solution { public int NumberOf1Between1AndN_Solution(int n) { if(n<0) return 0; int count=0; for(int i=1;i<=n;i++){ count+=numberOf1(i); } return count; } private static int numberOf1(int n){ int count=0; while(n>0){ if(n%10 == 1){ ++count; } n=n/10; } return count; } }
题目-把数组排成最小的数
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323。
思路
1.这个题目标就是找到一个排序规则,数组根据这个规则排序之后能排成一个最小的数字。
要确定排序规则,就是比较两个数字中,哪个应该排在前面。即哪个排在前面形成的数字会更小。
2.解决大数问题首要的方式就是:数字转化成字符串,nums[i]=numbers[i]+"";比较的时候按照字符串大小的比较规则就可以
3.数组的排序函数
解法
import java.util.Comparator; import java.util.Arrays; public class Solution { public String PrintMinNumber(int [] numbers) { int len=numbers.length; if(numbers == null || len == 0) return ""; //数字转成字符串 String[] nums = new String[len]; for(int i=0; i<len; i++){ nums[i]=numbers[i]+""; } //进行排序,来实现得到更小的数字 Arrays.sort(nums, new Comparator<String>(){ public int compare(String str1, String str2){ String c1 = str1+str2; String c2 = str2+str1; return c1.compareTo(c2); } }); String ret=""; for(int i=0;i<len;i++){ ret=ret+nums[i]; } return ret; } }
题目-丑数
把只包含质因子2、3和5的数称作丑数(Ugly Number)。例如6、8都是丑数,但14不是,因为它包含质因子7。 习惯上我们把1当做是第一个丑数。求按从小到大的顺序的第N个丑数。
思路
1.因子的概念:一个数 m 是另一个数 n 的因子,是指 n 能被 m 整除,也就是n%m==0。
2.最直观的方式就是:逐个判断每个整数是不是丑数。但是这种方式的时间效率很低
3.那么2中提到的方式,存在的问题是不管一个数是否为丑数,都要计算。那就为了优化这种方式,创建数组仅保存已经找到的丑数。以空间换时间。
由于丑数的定义是:另一个丑数乘以2、3或5的结果。
那么我们可以创建一个数组,用来保存数组里已有丑数,再将数组里的数乘以2、3或5。但是需要做的是把找到的丑数进行排序。
如果当前数组中最大的丑数是M,下一个要生成的丑数一定是数组中某一个丑数乘以2、3或5的结果。所以首先需要考虑的是把已有的每个丑数乘以2,我们只获取第一个大于M的结果。
但其实并不是需要把每个丑数都分别乘以2、3或5。由于现有数组是有序存放的,那么对乘以2而言,肯定存在一个丑数T2,排在它之前的每个丑数乘以2的结果 都会 小于 已有最大的丑数。而排在它之后的每个丑数乘以2的结果 都会 太大。那么我们只需要记下这个丑数的位置,每次生成新的丑数时,就去更新T2。对乘以3和5而言,也存在同样的T3和T5.
4.可以看成3个数组的合并,A:{1*2,2*2,3*2,4*2,5*2,6*2,8*2,10*2......};B:{1*3,2*3,3*3,4*3,5*3,6*3,8*3,10*3......};C:{1*5,2*5,3*5,4*5,5*5,6*5,8*5,10*5......}
如果下一个数,是某个数组中的,那么就把对应数组的指针往后移一位,
需要注意的是:如果这个数在多个数组中出现,那么这多个数组中每个数组的指针都需要往后移一位
可以用动态规划来理解这个问题,dp[i]表示第i个丑数,前面的每个状态都可以*2/*3/*5来形成一个新的状态,每次都选择最小的那个数来作为新的状态,也就是下一个丑数。
解法
public class Solution { public int GetUglyNumber_Solution(int index) { if(index <= 0) return 0; int[] uglyArray = new int[index]; uglyArray[0]=1;
//有资格同i相乘的最小丑数的位置 int multiply2 = 0; int multiply3 = 0; int multiply5 = 0; //按照大小生成丑数,这里的所有数都是丑数 for(int i=1;i<index;i++){ uglyArray[i] = min(uglyArray[multiply2]*2, uglyArray[multiply3]*3, uglyArray[multiply5]*5);
//如果一个丑数 dp[pi] 通过乘以 i 可以得到下一个丑数,那么这个丑数 dp[pi] 就永远失去了同 i 相乘的资格(没有必要再乘了),我们把 pi++ 让 dp[pi] 指向下一个丑数即可。 if(uglyArray[multiply2]*2 == uglyArray[i]) multiply2++; if(uglyArray[multiply3]*3 == uglyArray[i]) multiply3++; if(uglyArray[multiply5]*5 == uglyArray[i]) multiply5++; } return uglyArray[index-1]; } public int min(int num1, int num2, int num3){ int min = (num1<num2)?num1:num2; return min<num3?min:num3; } }
题目-第一个只出现一次的字符
在一个字符串(0<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置, 如果没有则返回 -1(需要区分大小写).
如输入“abaccdeff”,输出“b”
思路
1.最直观的方式就是使用HashMap对每个字符在字符串中出现的次数进行统计,但是要统计的字符范围有限,因此可以使用整型数组代替HashMap。
需要从头到尾扫描字符串两次,第一次扫描字符串时,每扫描到一个字符就在数组的对应项中把次数加1;
第二次扫描,每扫描到一个字符就能得到该字符的出现次数。那么第一个只出现一次的字符就是符合要求的输出。
2.优化的方式是:考虑到只需要找到只出现一次的字符,那么需要统计的次数信息只有0,1或更大,使用两个bit位就可以存储信息。
BitSet bs2 = new BitSet(256);
使用bs2.get(char )/bs2.set(char )来进行设置和提取操作
解法
public class Solution { public int FirstNotRepeatingChar(String str) { if(str == null){ return -1; } int[] cnts = new int[256]; for(int i=0;i<str.length();i++){ cnts[str.charAt(i)]++; } for(int i=0;i<str.length();i++){ if(cnts[str.charAt(i)]==1) return i; } return -1; } }
hashmap的使用方法:
建立hashmap:HashMap<Character,Integer> map=new HashMap<>();
增:map.put('c',4);
删:map.remove('c');
改:map.put('c',6);
查:map.containsKey('d'); & map.containsValue(4);
根据key找value:map.get(key);
遍历:1.使用keySet(),当只需要map中的键/值:Set<Character> keys=map.keySet();//返回key的集合 for(char key:keys){int value=map.get(key);//返回key对应的value值}
for(Integer value:map.values()){ int x=value;//得到所有的value值}
2.使用entryKey():Set<Entry<Character,Integer>> entrySet=map.entrySet();//返回所有键值对的集合
for(Entry<Character,Integer> entry:entrySet){char key=entry.getKey(); int value=entry.getValue;}
题目-数组中的逆序对
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数P。并将P对1000000007取模的结果输出。 即输出P%1000000007
思路
举例统计数组{7,5,6,4}中逆序对的过程:逆序对为(7,5),(7,6),(7,4),(5,4),(6,4)。
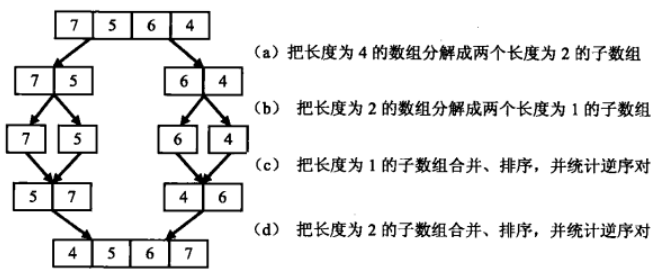
合并两个子数组并统计逆序对的过程:
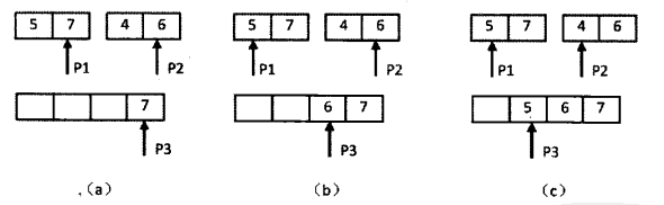
那么整体思路就是:
1.先把数组分割成两个子数组,统计出子数组内部的逆序对的数目,再统计出两个相邻子数组之间的逆序对的数目。
2.在统计逆序对的过程中,还需要对数组进行排序。(因为如果是排序后,那么如果左数组的第一个数大于右数组的第一个数,那么左数组中每个数与右数组的每个数肯定都能构成逆序对)
3.那么这个过程其实就是归并排序。
解法
public class Solution { private long reversePair = 0; public int InversePairs(int [] array) { int len = array.length; //数组为null/长度为0 if(array == null || len == 0){ return 0; } int[] p = new int[array.length]; //排序 mergeSort(array, 0, len-1, p); return (int)(reversePair%1000000007); } public void mergeSort(int [] array, int first, int last, int temp[]){ if(first<last){ int mid = (first+last)/2; //左边有序 mergeSort(array, first, mid, temp); //右边有序 mergeSort(array, mid+1, last, temp); //将左右两个有序数列合并 mergeArray(array, first, mid, last, temp); } } //将两个有序数列array[first,...,mid]和array[mid,...,last]合并 public void mergeArray(int[] array, int first, int mid, int last, int[] temp){ int first1 = first, end1 = mid; int first2 = mid+1, end2 = last; int p = 0; while(first1 <= end1 && first2 <= end2){ //左数组大于右数组 if(array[first1]>array[first2]){ temp[p++] = array[first2++]; //由于当前数组都是有序数组,如果当前左数组元素大于右数组元素array[first2] //那么就会有当前左数组后面的元素,都大于array[first2] reversePair+=mid-first1+1; } //如果左数组的数字 小于或等于 右数组的数字,不构成逆序对 //每一次比较时,都把较大的数字从后往前复制到一个辅助数组中,确保辅助数组中的数组增序 //把较大的数字复制到数组之后,把对应的指针向前移动一位,进行下一轮的比较 else{ temp[p++]=array[first1++]; } } //两个数组相互比较大小,其中一个数组比较完了。还剩左边数组还有一些数字,那么直接添加到temp后面 while(first1 <= end1){ temp[p++] = array[first1++]; } while(first2 <= end2){ temp[p++] = array[first2++]; } //此时的array是合并之后,有序的 for(int i=0; i<p; i++){ array[first+i]=temp[i]; } } }
题目-两个链表的第一个公共结点
输入两个链表,找出它们的第一个公共结点。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
思路
由链表结点的定义,看出两个链表是单向链表,如果单向链表有公共的结点,那么这两个链表从某一结点开始,它们的next都指向同一个结点。并且单向链表的每个结点都只有一个next,那么从第一个公共结点开始,它们的next都是指向同一结点,因此之后的所有结点都是重合的,不可能再出现分叉。
由于两个链表的长度可能不一致,因此为了让两个链表的指针同时到达交点,需要让长链表先走一段距离,再同时在两个链表上遍历。
如果访问链表A的指针访问到链表尾部,那么从链表B的头部开始重新访问链表B。//以此实现让长链表先走一个结点。
由于设第一个链表没交集的一段=a,第二个链表没交集的一段=b,交集一段=c。
那么a+c+b=b+c+a,因此两个链表会在交集处相遇。
解法
/* public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } }*/ public class Solution { public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) { ListNode l1 = pHead1, l2 = pHead2; //使得A和B两个链表的指针能同时访问到交点。即长的先走一段距离,当长度相等时一起向前走 while(l1 != l2){ //如果访问链表A的指针访问到链表尾部,那么从链表B的头部开始重新访问链表B l1 = (l1==null)?pHead2:l1.next; //如果访问链表B的指针访问到链表尾部,那么从链表A的头部开始重新访问链表A l2 = (l2==null)?pHead1:l2.next; } return l1; } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号