分布式存储原理
三个节点简述:
namenode:

datanode:

secondary node

1、分布式文件管理系统:
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
容错。即使系统中有某些节点宕机,整体来说系统仍然可以持续运作而不会有数据损失【通过副本机制实现】。 副本文件:本机----->其他机器------->其他机架------------>其他公司/城市等等,之前我们定义副本为1,本机副本机制文件备份在其他节点,这样数据就安全了,数据丢失或者访问失败的概率就小了
分布式文件管理系统很多,hdfs只是其中一种,不合适小文件。
2、hdfs架构
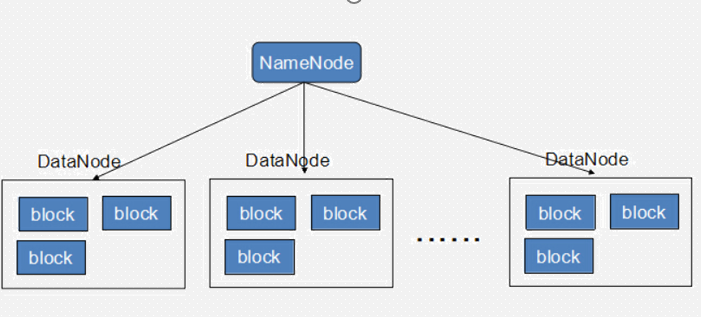
集群中不同的节点承担不同的职责。 负责命名空间职责的,存储元数据信息(针对hdfs的操作,比如切分信息就存放在master中)节点称为主节点(master node/namenode)
负责存储真实数据职责的节点称为从节点(slave node/datanode)。
主节点负责管理文件系统的文件结构,从节点负责存储真实的数据,称为主从式结构(master-slaves)。
在主节点上,为了加快用户访问的速度,会把整个命名空间信息都放在内存中,当存储的文件越多时,那么主节点就需要越多的内存空间。
在从节点存储数据时,有的原始数据文件可能很大,有的可能很小,大小不一的文件不容易管理,那么可以抽象出一个独立的存储文件单位,称为块(block)。
用户操作时,应该先和主节点打交道,查询数据在哪些从节点上存储(查询元数据),然后再到从节点读取。

3、查找数据
hdfs的元数据保存在namenode中,在namenode所在的节点的
/usr/local/soft/hadoop-2.7.6/tmp
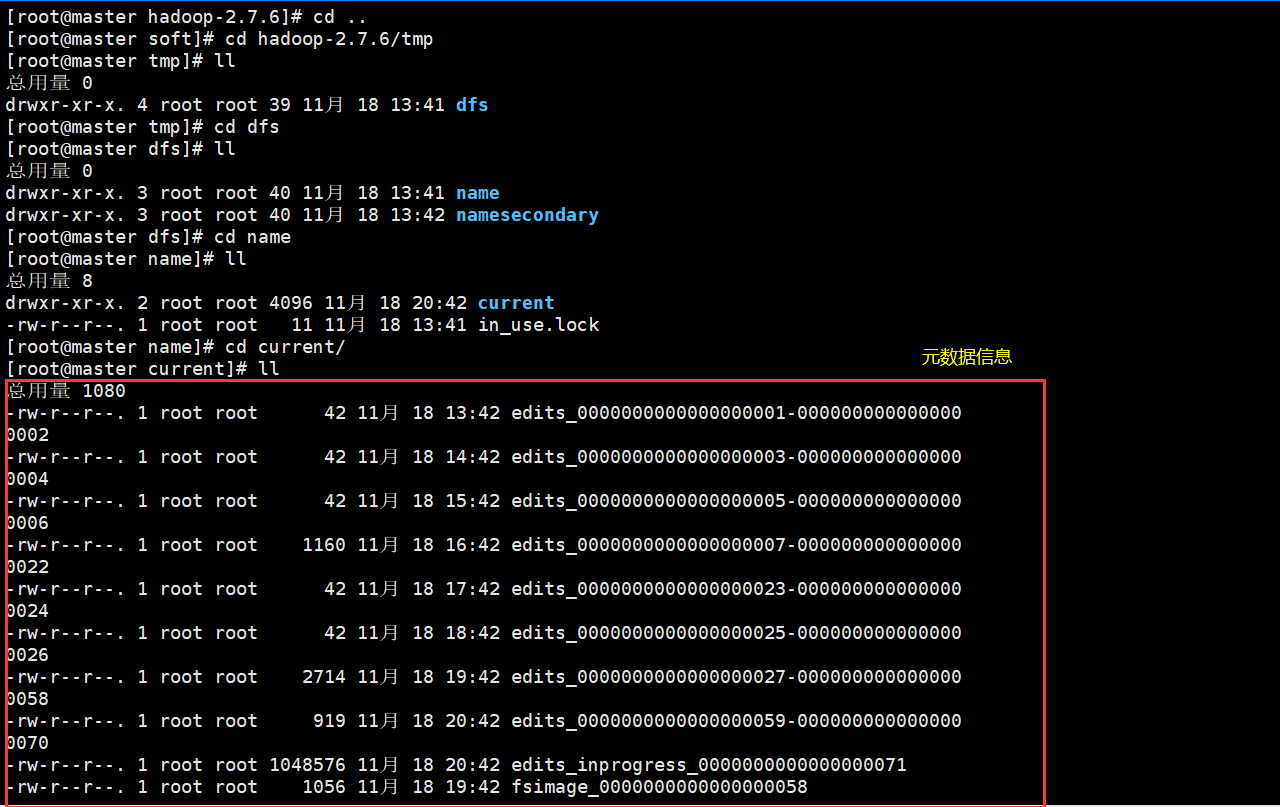
hdfs的数据保存在datanode中,在datanode的所在的节点的磁盘上
(/usr/local/soft/hadoop-2.7.6/tmp/dfs/data/current/BP-1968529002-192.168.129.101-1609771935660/current/finalized/subdir0/subdir0)
直接访问

自己一级一级目录找
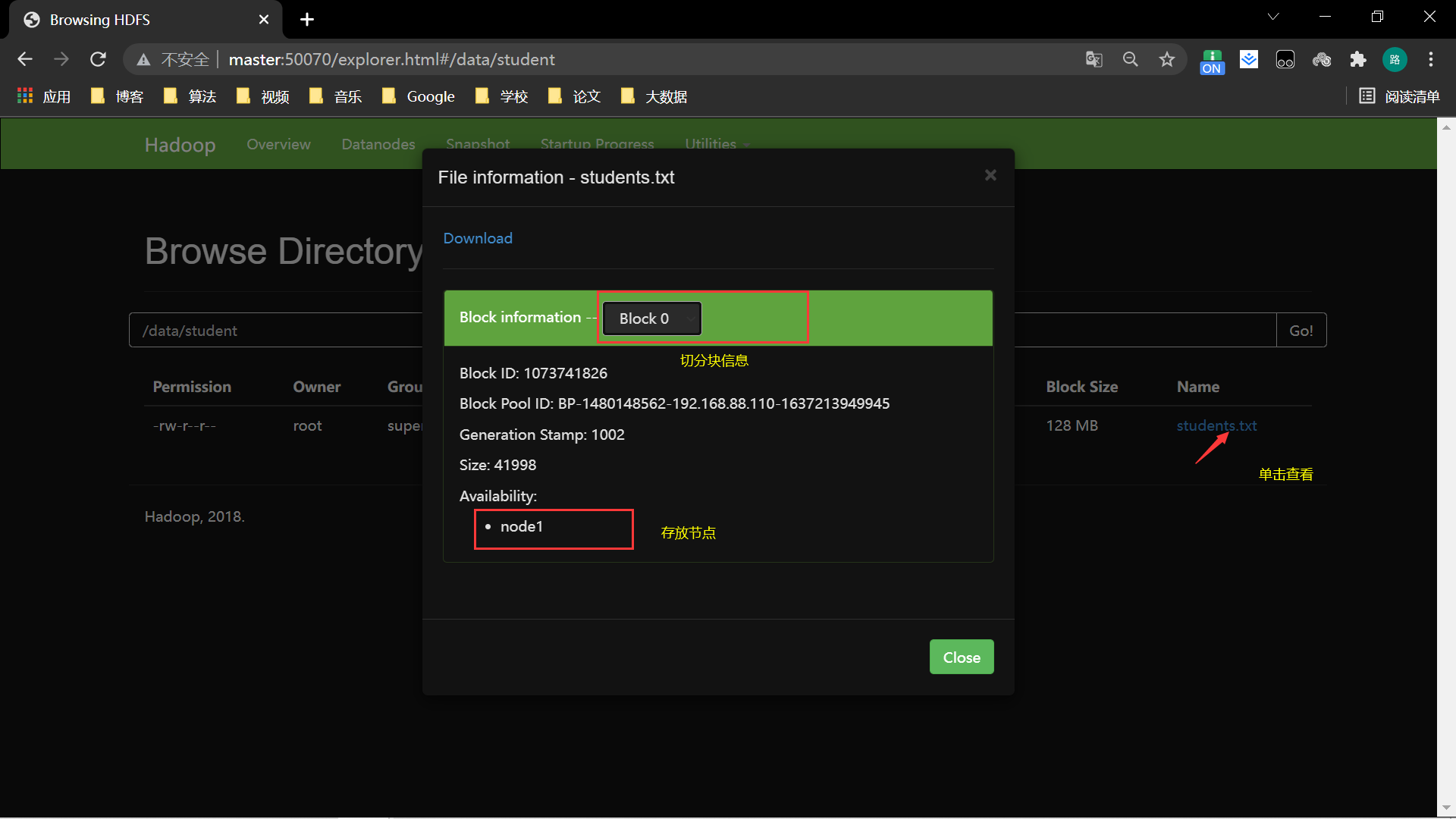
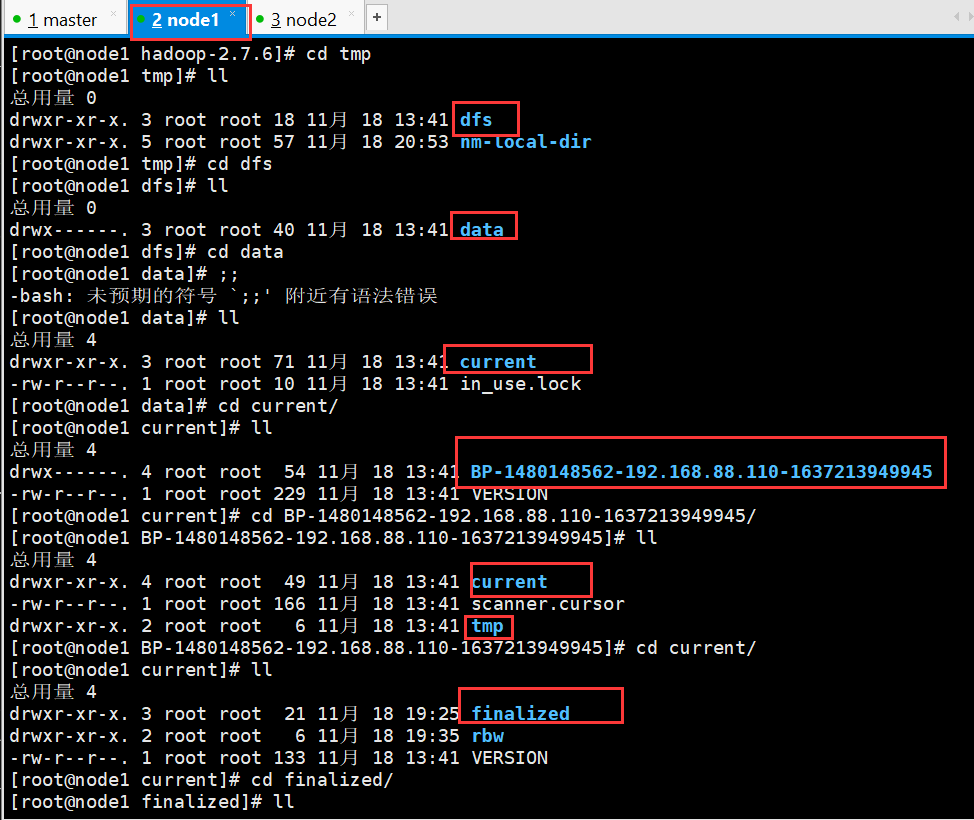
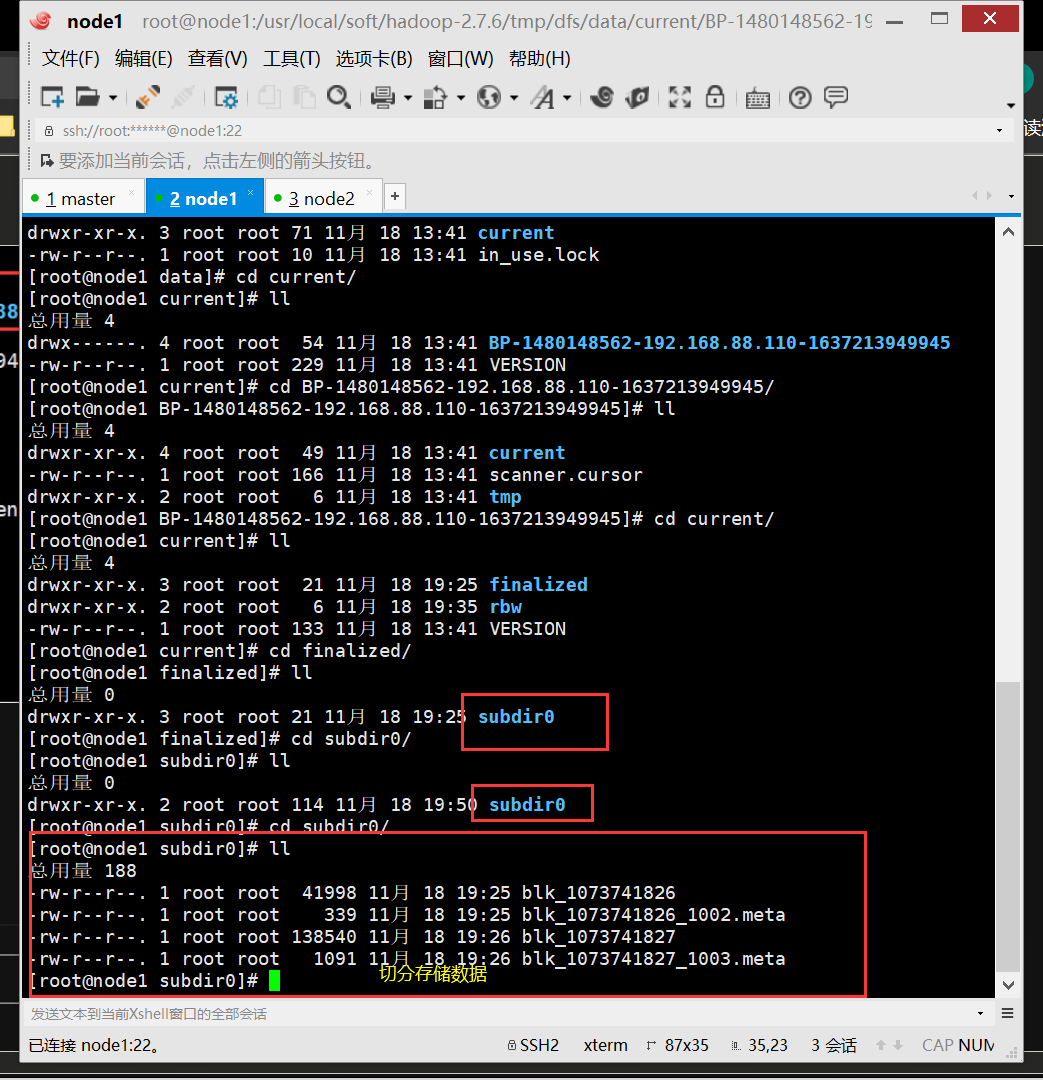
4、切分
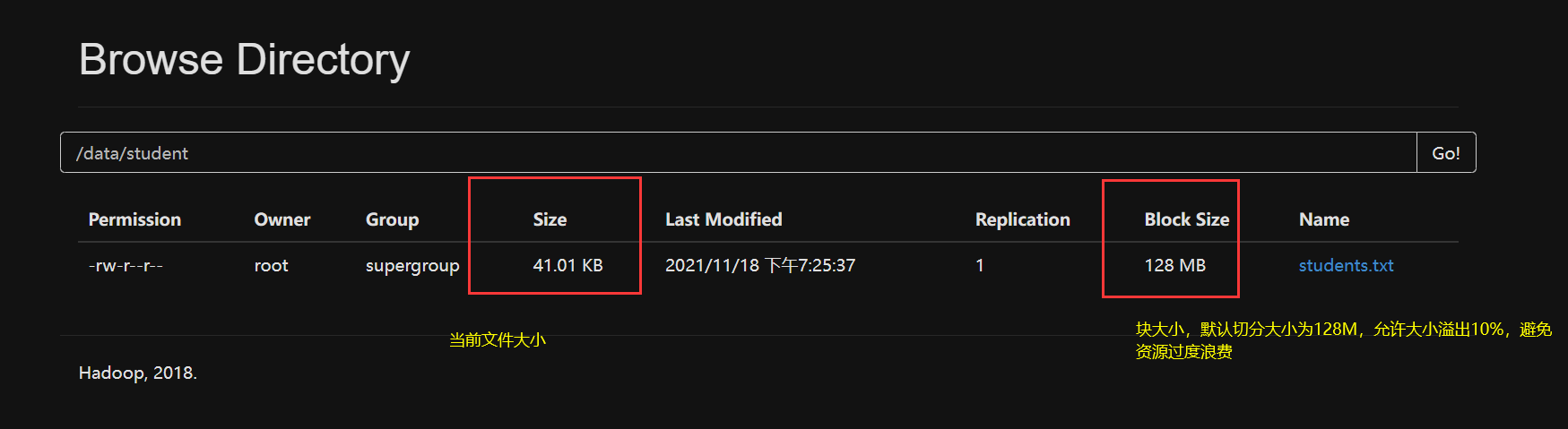
文件大小小于128MB不切分,允许文件溢出10%,避免切分后文件太少,浪费资源
超过溢出资源切分。并且切分过程会产生信息保存在master中,切分的block位置随机,前提是节点资源足够
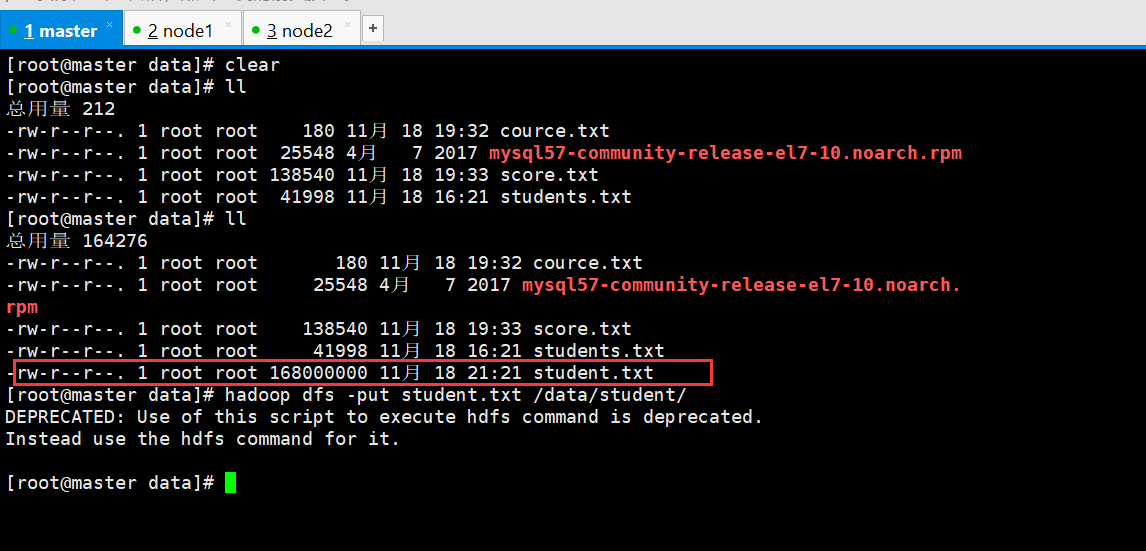
上传一个比较大的文件
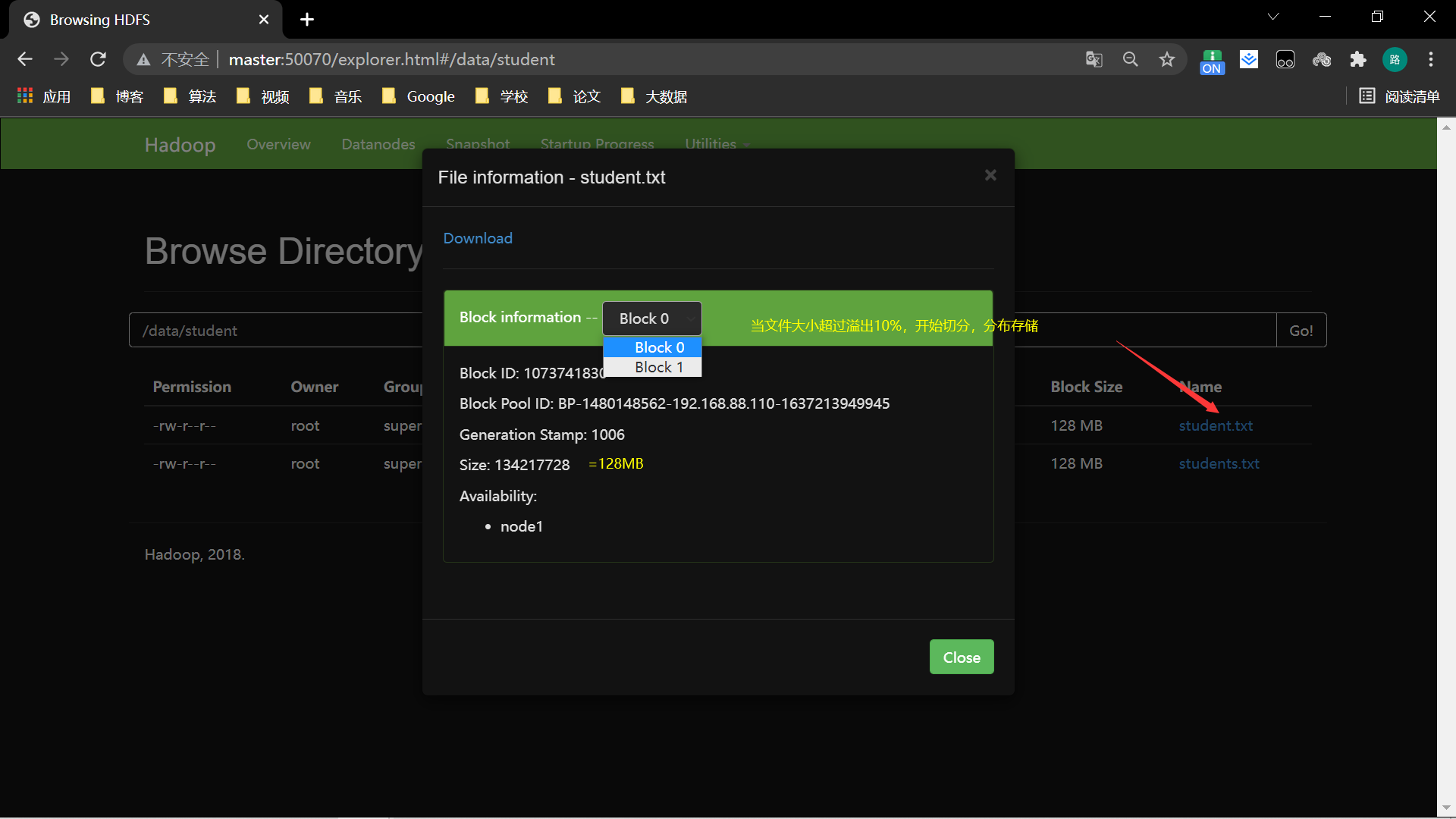
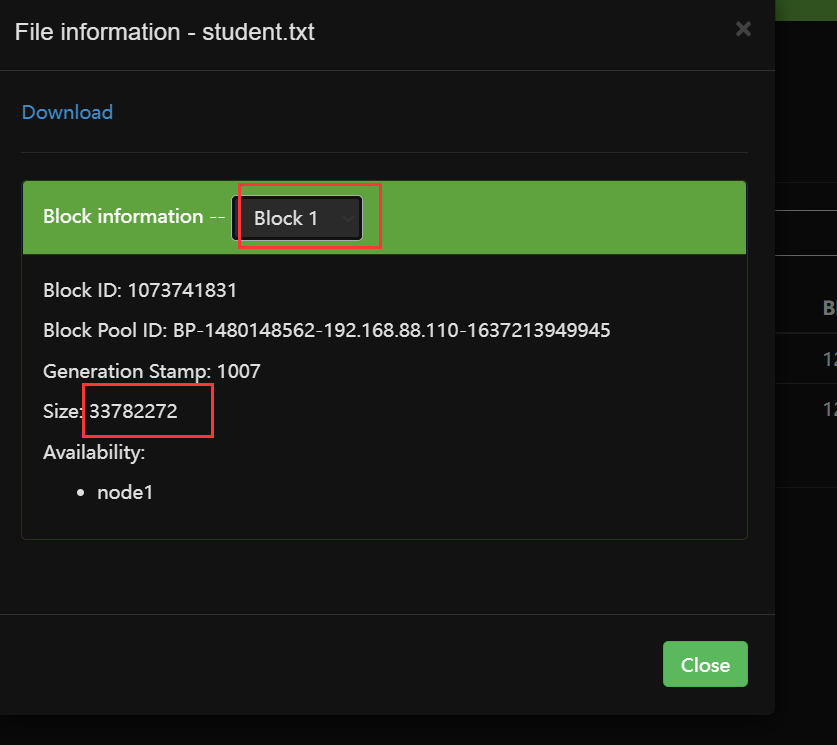
注意:Hadoop-2.7.6版本hdfs上不能直接修改
Hadoop-3版本可以hdfs上直接修改数据
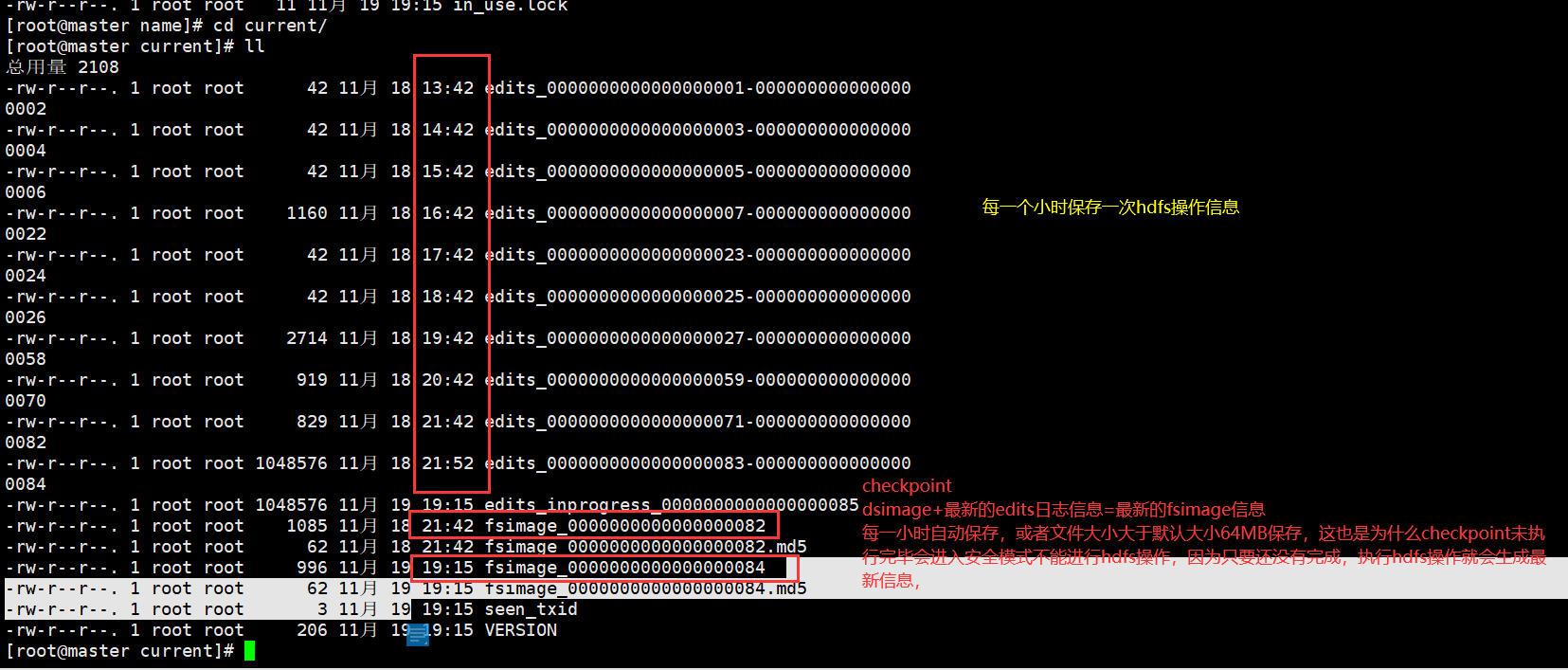
5、镜像文件和编辑日志介绍
fsimage文件:hadoop文件系统元数据的一个永久性的检查点,其中包含hadoop文件系统中的所有目录和文件idnode的序列化信息。
每个以MD5命名结尾的文件是对其前缀的校验,也就是说在看到的两个文件(fsimage_*)中,实际存储数据的是非MD5结尾的文件。
edits:操作日志文件,namenode启动后一些新增元信息日志。
fstime:保存最近一次checkpoint的时间
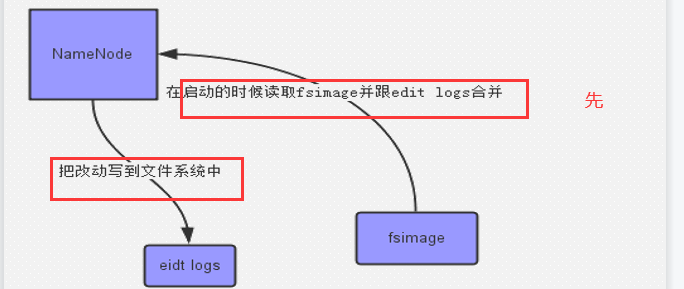
seconddary namenode工作流程:

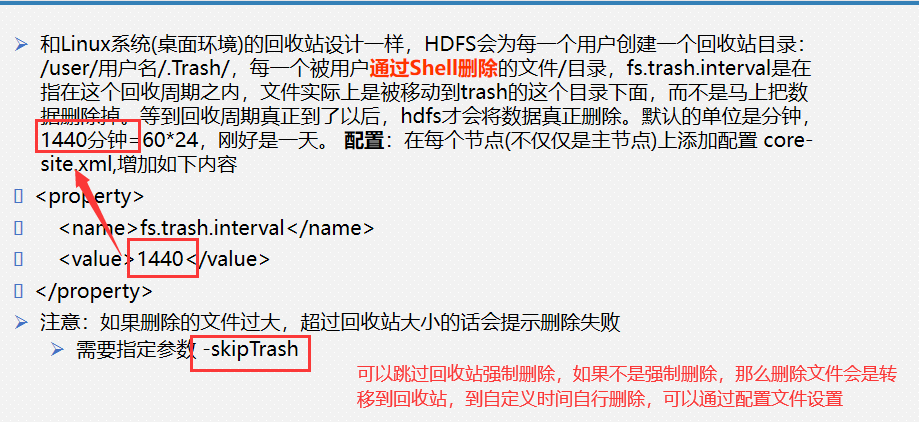
6、hdfs中的Trash回收站
7、FileSysterm

8、Remote Procedure Call

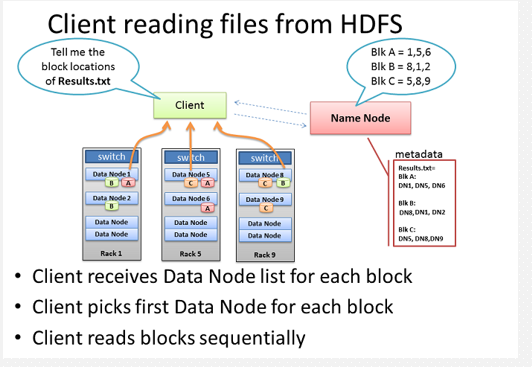
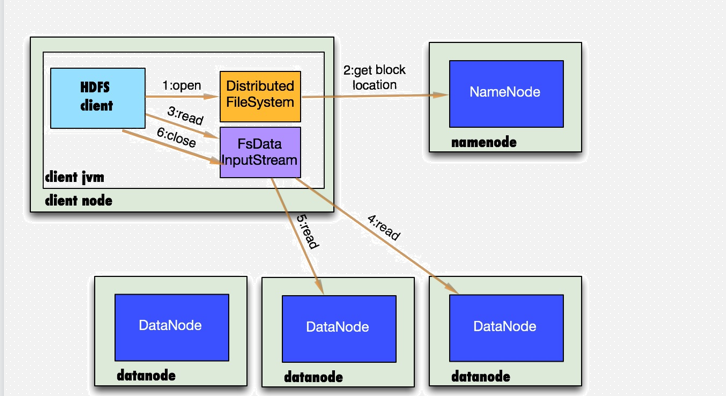
9、客户端读取多副本文件过程(就近原则)
10、数据存储--读数据
1.首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
2.DistributedFileSystem通过rpc获得文件的第一个block的locations,同一block按照副本数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.(就近原则)
3.前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
4.数据从datanode源源不断的流向客户端。
5.如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
6.如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继读,如果所有的块都读完,这时就会关闭掉所有的流。
7.如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像
该设计的方向就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.Before; import org.junit.Test; import java.io.*; import java.net.URI; /* 通过Java连接hadoop进行hdfs操作 */ public class HadoopAPI { FileSystem fs; @Before //初始化 public void init() throws Exception{ //自动获取hadoop配置文件 Configuration conf = new Configuration(); //设置副本 conf.set("dfs.replication","1"); //连接 URI uri = new URI("hdfs://master:9000"); //连接文件管理系统,生成一个对象,相当于一个客户端 fs = FileSystem.get(uri, conf); } @Test public void load() throws Exception{ //从hdfs上获取要读文件 FSDataInputStream path = fs.open(new Path("/data/student/students.txt")); //使用字符缓冲流读文件 BufferedReader br = new BufferedReader(new InputStreamReader(path)); String line; while ((line=br.readLine())!=null){ System.out.println(line); } br.close(); path.close(); } }
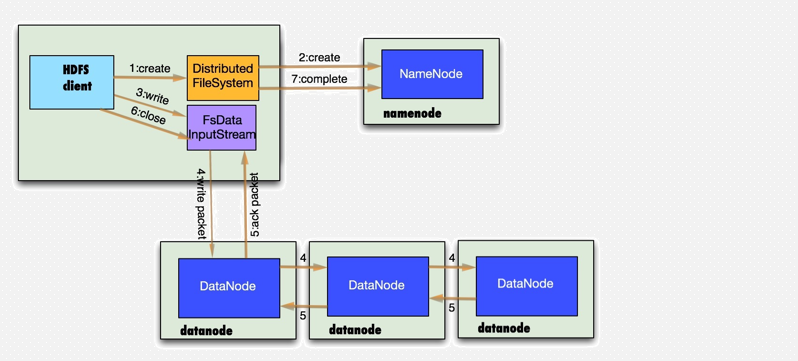
11、数据存储--写数据
1.客户端通过调用DistributedFileSystem的create方法创建新文件
2.DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常.
3.前两步结束后会返回FSDataOutputStream的对象,像读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream.DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。
4.DataStreamer会去处理接受data queue,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如副本数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
5.DFSOutputStream还有一个对列叫ack queue,也是有packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
如果在写的过程中某个datanode发生错误,会采取以下几步:
1) pipeline被关闭掉;
2)为了防止丢包ack queue里的packet会同步到data queue里;
3)把产生错误的datanode上当前在写但未完成的block删掉;
4)block剩下的部分被写到剩下的两个正常的datanode中;
5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
6.客户端完成写数据后调用close方法关闭写入流
7.DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知namenode把文件标示为已完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号