3.3 集合
3.1 类集
3.1.1 引入目的
- 对象数组有那些问题?普通的对象数组的最大问题在于数组中的元素个数是固定的,不能动态的扩充大小,所以最早的时候可以通过链表实现一个动态对象数组。但是这样做毕竟太复杂了,所以在 Java中为了方便用户操作各个数据结构, 所以引入了类集的概念,有时候就可以把类集称为 java 对数据结构的实现。
3.1.2 常用接口
- Collection、Map、Iterator,所有的类集操作的接口或类都在java.util包中。
3.1.2 类集结构图
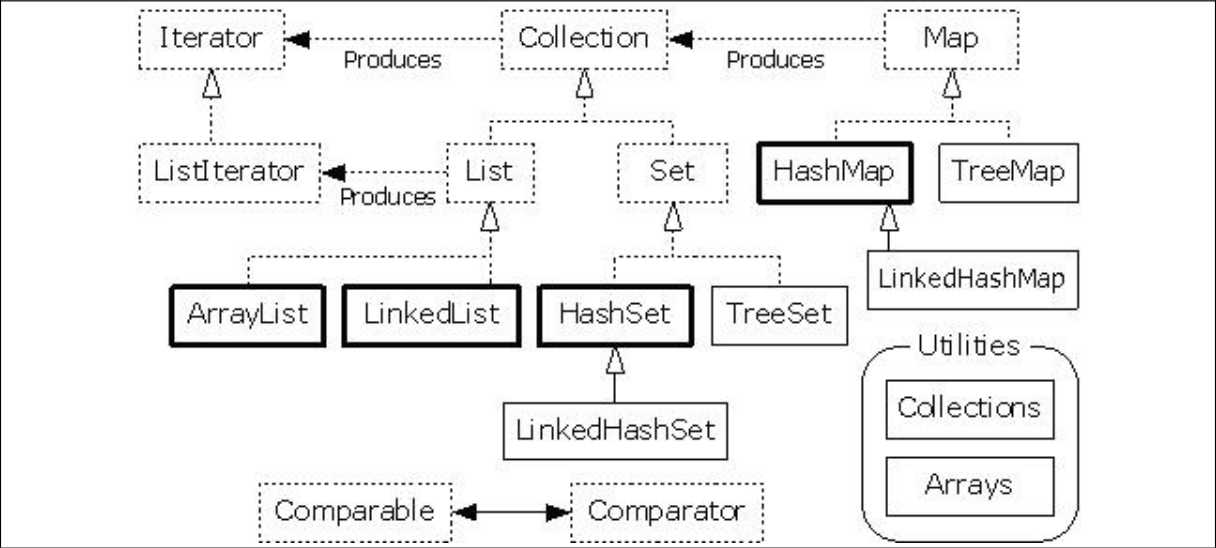
3.2 Collection接口
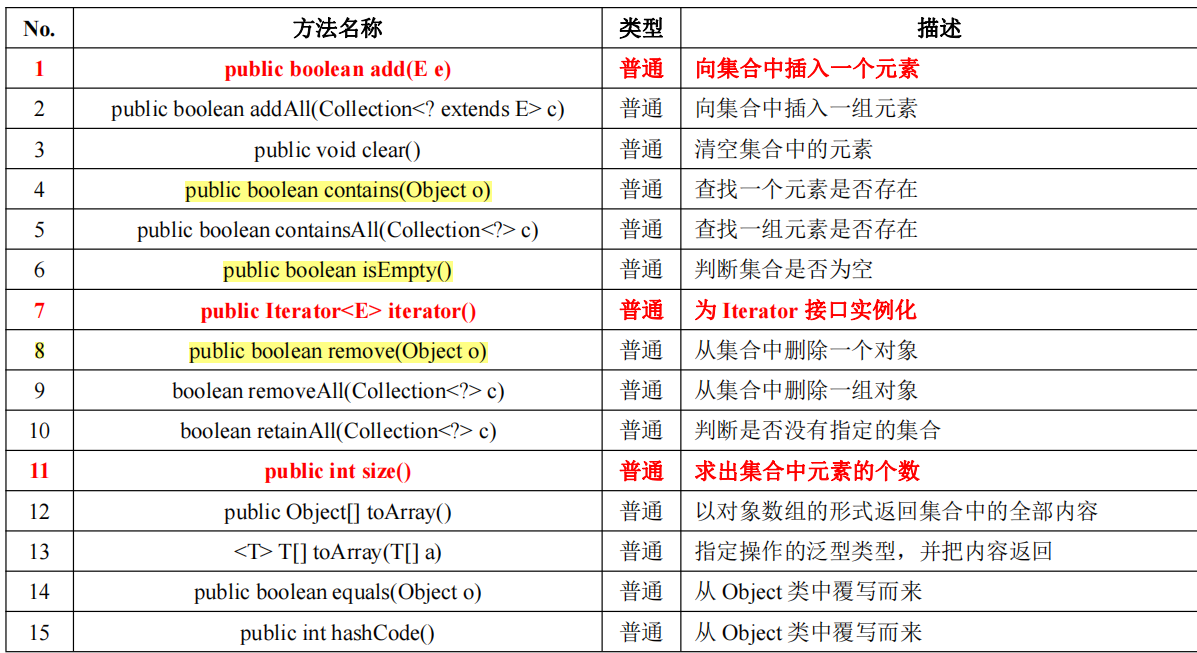
常用方法
3.3 List接口
3.3.1 实现类
- ArrayList(95%),Vector(4%),LinkedList(1%)
3.3.2 ArrayList
3.3.2.1 实现原理
- 数组自动扩容
3.3.2.2 常用方法
public static void main(String[] args) {
List<String> all = new ArrayList<String>(); // 实例化List对象,并指定泛型类型
all.add("hello "); // 增加内容,此方法从Collection接口继承而来
all.add(0, "LAMP ");// 增加内容,此方法是List接口单独定义的
all.add("world"); // 增加内容,此方法从Collection接口继承而来
all.remove(1); // 根据索引删除内容,此方法是List接口单独定义的
all.remove("world");// 删除指定的对象
System.out.print("集合中的内容是:");
for (int x = 0; x < all.size(); x++) { // size()方法从Collection接口继承而来
System.out.print(all.get(x) + "、"); // 此方法是List接口单独定义的
}
}
3.3.4 Vector
3.3.4.1 实现原理
- 数组自动扩容
3.3.4.2 概述
- Vector 属于Java元老级的操作类,是最早的提供了动态对象数组的操作类,在JDK 1.0 的时候就已经推出了此类的使用,只是后来在JDK1.2之后引入了Java类集合框架。但是为了照顾很多已经习惯于使用 Vector的用户,所以在JDK1.2之后将 Vector类进行了升级了,让其多实现了一个 List接口,这样才将这个类继续保留了下来。
3.3.4.3 Vector和ArrayList区别
- 时间:
- Vector:JDK1.0
- ArrayList:JDK1.2之后
- 性能;
- Vector:同步处理,性能低
- ArrayList:异步处理,性能高
- 输出:
- Vector:Iterator、ListIterator、Enumeration
- ArrayList:Iterator、ListIterator
3.3.5 LinkedList
3.3.5.1 概述
- 此类继承了AbstractList,所以是 List 的子类。但是此类也是 Queue 接口的子类
3.3.5.2 实现原理
- 双向链表
3.3.5.3 LinkedList常用方法
//模拟栈
LinkedList<Integer> list=new LinkedList<>();
//压栈
list.push(100);//在栈底
list.push(200);//在栈顶
//弹栈
list.pop();//弹出200
3.3.5.3 Queue常用方法
public static void main(String[] args) {
Queue<String> queue = new LinkedList<String>();
queue.add("A");
queue.add("B");
queue.add("C");
/*把queue的大小先取出来,否则每循环一次,移除一个元素,就少
一个元素,那么queue.size()在变小,就不能循环queue.size()次了。*/
int len=queue.size();
for (int x = 0; x <len; x++) {
System.out.println(queue.poll());
}
System.out.println(queue);
}
3.3.6 ArrayList与LinkedList区别
- LinkedList:增删改
- ArrayList:查询
3.4 Iterator和ListIterator
3.4.1 Iterable和Iterator区别
- collection接口实现Iterable接口,获取Iterator对象,可通过方法获取该对象
- Iterator接口获取Iterator对象的方法
3.4.2 Iterator和ListIteraor区别
- Iterator遍历Collection中的集合,由前向后单向输出
- ListIterator遍历List中的集合,双向输出
3.4.3 Iterator遍历原理
- 创建一个指针对象,指向当前数据结构的起始位置。(起始位置没有元素)
- hasNext():判断是否还有下一个元素
- next():返回当前对象,指向下一个对象
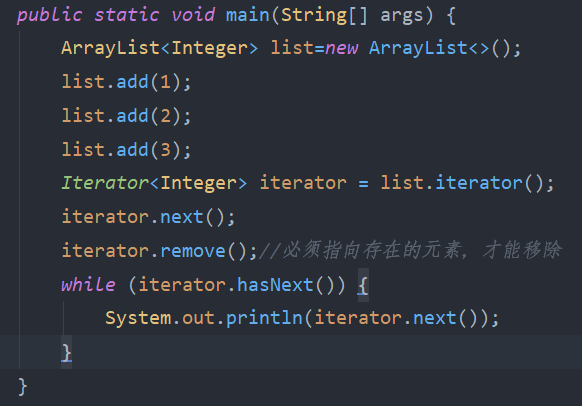
3.4.4 Iterator常用方法
public static void main(String[] args) {
ArrayList<Integer> list=new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> iterator = list.iterator();
iterator.next();
iterator.remove();//必须指向存在的元素,才能移除
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
3.4.5 ListIterator常用方法
public static void main(String[] args) {
ArrayList<Integer> list=new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
ListIterator<Integer> listIterator = list.listIterator();
//add方法在next()返回的元素之前插入(如果有),并且在previous()返回的元素之后插入 (如果有)
//光标所指位置有元素,在元素前插入,无元素,直接插入
listIterator.add(100);//在1前面插入,指针位置不变
//next方法返回列表中的下一个元素并前进光标位置
listIterator.next();
listIterator.next();//指针指向2
listIterator.set(200);//2-->200
//previous方法返回列表中的上一个元素并向后移动光标位置
listIterator.previous();//指向1
listIterator.add(300);//在1前面插入
listIterator.previous();
listIterator.previous();
listIterator.previous();//指针回到起点,未指向任何元素
while (listIterator.hasNext()) {
Integer next = listIterator.next();
System.out.println(next);
}
}
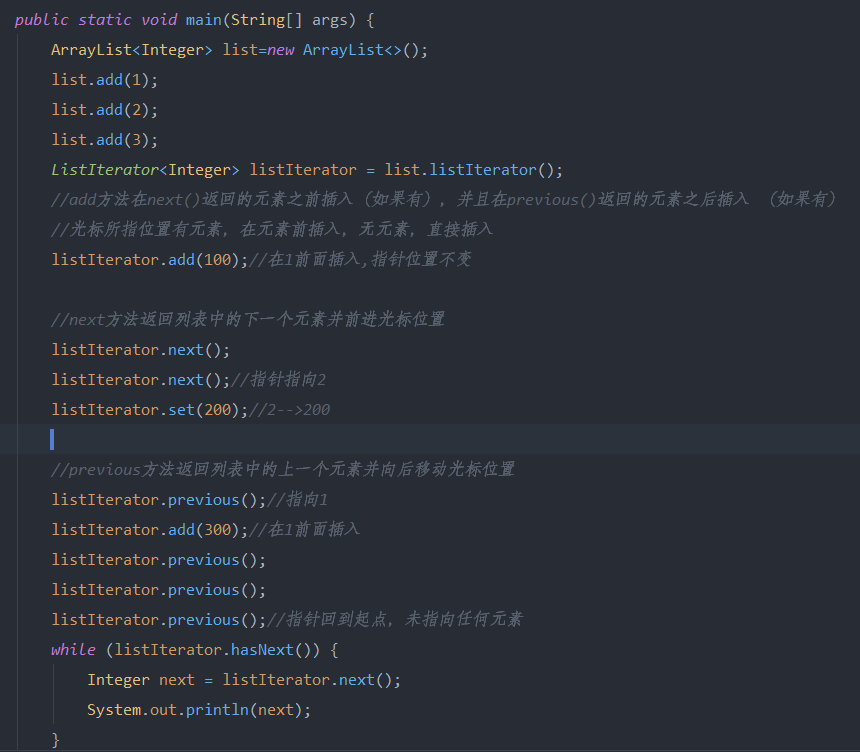
输出结果:
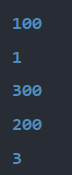
3.4.6 注意事项
- 在进行迭代输出的时候如果要想删除当前元素,则只能使用 Iterator接口中的 remove()方法,而不能使用集合中的remove()方法。否则将出现未知的错误。
- 但是,从实际的开发角度看,元素的删除操作出现的几率是很小的,基本上可以忽略
public static void main(String[] args) {
Collection<String> all = new ArrayList<String>();
all.add("A");
all.add("B");
all.add("C");
Iterator<String> iter = all.iterator();
while (iter.hasNext()) {// 判断是否有下一个元素
String str = iter.next(); // 取出当前元素
if (str.equals("C")) {
all.remove(str); // 错误,原本的要输出的集合的内容被破坏掉了
} else {
System.out.print(str + "、");
}
}
}
3.4.7 Enumeration(已废用接口)
3.4.7.1 概述
- Enumeration 是一个非常古老的输出接口,其也是一个元老级的输出接口,最早的动态数组使用 Vector 完成,那么只 要是使用了 Vector 则就必须使用 Enumeration 进行输出。
- 但是,与 Iterator 不同的是,如果要想使用 Enumeration 输出的话,则还必须使用 Vector 类完成
3.4.7.2 应用
public static void main(String[] args) {
Vector<String> v = new Vector<String>();
v.add("A");
v.add("B");
v.add("C");
Enumeration<String> enu = v.elements();
while (enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
}
3.5 Set
3.5.1 概述
- 内容不允许重复 ,重复则不存储
- 没有对 Collection接口进行扩充,因此没有get(int index)方法,所以无法使用循环进行输出。
- 可通过Iterator或转成数组toArray遍历元素
3.5.2 HashSet
3.5.2.1 特点
- 散列存放,输出顺序与存储顺序无关
3.5.3 TreeSet与Comparable
3.5.3.1 TreeSet特点
- 增加元素时属于无序的操作,增加之后可以进行排序功能的实现。
- 若向里面增加Person类,再进行排序,会报错:Person类不能向Comparable接口转型
- 因此要排序自定义的元素,必须在类中实现Comparble接口
3.5.3.2 Comparable
3.5.3.2.1 作用
- 对集合中对象是自定义的或者其他系统定义的类进行排序
3.5.3.2.2 应用(重写compareTo方法)
public class Person implements Comparable<Person> { //必须具体化泛型
private String name;
private int age;
public int compareTo(Person per) { //实现抽象方法
if (this.age > per.age) {
return 1;
} else if (this.age < per.age) {
return -1;
} else {
return 0;
}
}
}
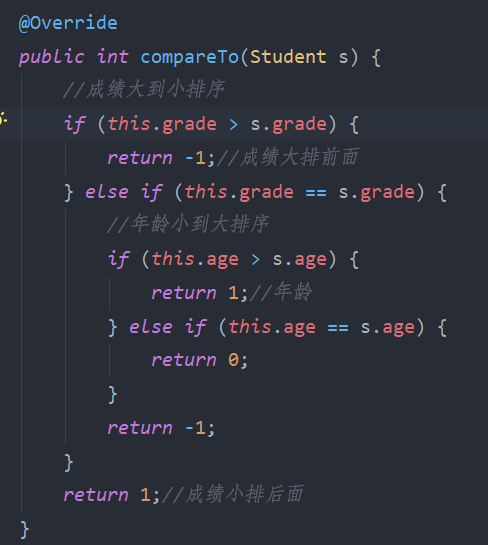
3.5.4 Comparable和Comparator
3.5.4.1 区别
- Comparalbe一般搭配TreeSet使用,进行自定义类的排序
- Comparator可搭配其他集合类使用,通过Collections类的sort方法重写compare方法
3.5.4.2 comparator应用
public static void main(String[] args) {
List<Student2> data = new ArrayList<>();
Student2 s1 = new Student2("贾宝玉", 14, 88.5);
Student2 s2 = new Student2("林黛玉", 13, 90.5);
Student2 s3 = new Student2("史湘云", 13, 85);
Student2 s4 = new Student2("薛宝钗", 15, 91);
data.add(s1);
data.add(s2);
data.add(s3);
data.add(s4);
//第二个参数也可传入实现Comparator接口的对象,可通过内部类形式
Collections.sort(data, new Comparator<Student2>() {
@Override
public int compare(Student2 s1, Student2 s2) {
//成绩降序
if (s1.getGrade() > s2.getGrade()) {
return -1;
} else if (s1.getGrade() == s2.getGrade()) {
//年龄升序
if (s1.getAge() > s2.getAge()) {
return 1;
} else if (s1.getAge() == s2.getAge()) {
return 0;
}
return -1;
}
return 1;
}
});
for (Student2 s : data) {
System.out.println(s);
}
}
(内部类链接: https://blog.csdn.net/scgyus/article/details/79454321 )
3.5.4.3 降序与升序
- 无论哪种顺序,都是用后一个元素和前一个元素进行比较,默认前一个参数数值较大
- 升序:后面的元素值较大
- 顺序:s2,s1,...,所以返回1,s1.getAge() > s2.getAge()
- 降序:前面的元素值较大
- 顺序:s1,s2,...所以返回-1,s1.getGrade() > s2.getGrade()
注意事项
- 若数值比较涉及小数点,需用关系运算符进行比较,不可按下列方式直接返回表达式的值
Collections.sort(stus,new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
int flag;
// 首选按年龄升序排序
flag = s1.getAge()-s2.getAge();
if(flag==0){
// 再按学号升序排序
flag = s1.getNum()-s2.getNum();
}
return flag;
}
});
3.5.5 判断并去除重复元素
- TreeSet:实现Comparable接口
- HashSet:重写Object的equals和hashCode方法
3.6 Map
3.6.1 概念:
- 存储键值对
3.6.2 HashMap
3.6.2.1 概念:
- 基于哈希表的Map接口的实现
3.6.2.2 实现方式
- 对象数组+链表
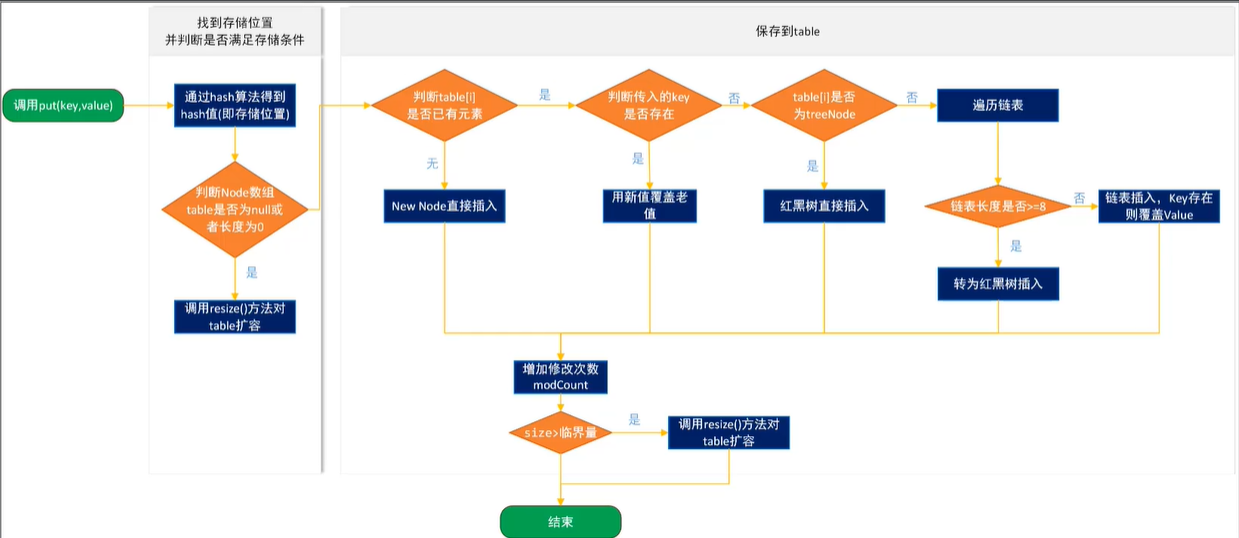
3.6.2.3 原理
- 哈希桶
- 初始数量为16
- 通过hash算法得到hash值(即存储位置)
- 存储位置计算方法:hashcode%length-->hashcode&(length-1)
- 改进算法约定数组长度必须为2的整数幂,保证最高位为1,减1后与运算可以保留余数
- K值若是重复则V值被覆盖
- 每个桶中数据量增加到8时,链表-->红黑树,当数据量减少到6时,红黑树-->链表
- 散列因子
- 默认值为0.75,即当使用的桶数量第一次达到16*0.75=12时,进行翻倍扩容,桶数量变为32
面试题:桶中数据量为7时,此时数据结构是链表还是红黑树
- 若未曾转化为红黑树,则为链表,反之则为红黑树
3.6.2.4 源码分析
3.6.3 输出方式
//法一:entryset+Iterator
public static void test2() {
Map<String,Integer> map=new HashMap<>();//获取map集合对象
map.put("1", 1);
map.put("2", 2);
Set<Map.Entry<String, Integer>> set = map.entrySet();//获取映射关系集合
for(Iterator<Map.Entry<String,Integer>> temp=set.iterator();temp.hasNext();){
Map.Entry<String, Integer> next = temp.next();
System.out.println(next.getKey()+"..."+next.getValue());
}
//法二:keyset+Iterator
Set<String> keyset = map.keySet();
for (Iterator<String> iterator = keyset.iterator(); iterator.hasNext(); ) {
String key = iterator.next();
System.out.println(key+"..."+map.get(key));
}
//法三:keyset+foreach
for(String key:keyset){
System.out.println(map.get(key));
}
3.6.3.1 Map.Entry
- Map.Entry 本身是一个接口。此接口是定义在 Map 接口内部的,是 Map 的内部接口。此内部接口使用 static 进行定义, 所以此接口将成为外部接口。 实际上来讲,对于每一个存放到 Map 集合中的 key 和 value 都是将其变为了 Map.Entry 并且将 Map.Entry 保存在了 Map 集合之中
3.6.4 HashMap和HashTable区别

3.6.5 各子类区别
- HashMap,HashTable,ConcurrentHashMap
- HashMap:线程不安全,效率高
- HashTable:线程安全,效率低
- ConcurrentHashMap:采用分段锁机制,保证线程安全且效率高
- TreeMap,LinkedHashMap
- TreeMap:无序存储,有序输出
- LinkedHashMap:有序存储和输出,数据存在HashMap和linkedList中
3.7 Collections
- Collections是集合的操作类与Colleciton接口无关
- 使用 Collections类返回的空的集合对象,本身是不支持任何的修改操作的,因为所有的方法都没实现
- 使用 Collections进行增加元素的操作,但是,从实际考虑,使用此类操作并不是很方便,最好的做法就是使用各个接口的直接操作的方法完成。此类只是 一个集合的操作类。
3.8 equals、hashcode与内存泄露
3.8.1 对hashcode的约定
- 在一个应用程序执行期间,如果一个对象的equals方法做比较所用到的信息没有被修改的话,则对该对象调用hashCode方法多次,它必须始终如一地返回同一个整数。
- 如果两个对象根据equals(Object o)方法是相等的,则调用这两个对象中任一对象的 hashCode 方法必须产生相同的整数结果。
- 如果两个对象根据equals(Objecto)方法是不相等的,则调用这两个对象中任一个对象的hashCode方法,不要求产生不同的整数结果。但如果能不同,则可能提高散列表的性能。
3.8.2 java集合中判断两个对象是否相等
- 判断两个对象的 hashCode是否相等
- 如果不相等,认为两个对象也不相等,完毕.
- 如果相等,转入 2 (这一点只是为了提高存储效率而要求的,其实理论上没有也可以,但如果没有,实际使用时效率会大大降低,所以我们 这里将其做为必需的。)
- 判断两个对象用 equals 运算是否相等
- 如果不相等,认为两个对象也不相等
- 如果相等,认为两个对象相等(equals()是判断两个对象是否相等的关键)
3.8.3 注意事项
- 当一个对象被存进HashSet集合后,就不能修改这个对象中的那些参与计算的哈希值的字段了,否则,对象被修改后的哈希值与最初存储进HashSet集合中时的哈希值就不同了,在这种情况下,即使在contains方法中使用该对象的当前引用作为参数去HashSet集合中检索对象,也将返回找不到对象的结果,这也会导致无法从HashSet集合中删除当前对象,从而造成内存泄露。
3.9 JDK1.9新特性
3.9.1 of方法存储元素,调用add方法会报错
public static void main(String[] args) {
List<String> list = List.of("1", "2");
for (String s : list) {
System.out.println(s+" " );
}
}
welcome~the interesting soul

 浙公网安备 33010602011771号
浙公网安备 33010602011771号