Disruptor系列(三)— 组件原理
前言
前两篇文章都是从github wiki中翻译而来,旨在能够快速了解和上手使用Disruptor。但是为了能够掌握该技术的核心思想,停留在使用层面还远远不够,需要了解其设计思想,实现原理,故这篇从源码层面分析其实现原理。
Disruptor中的术语非常多,这个在系列的第一篇已经介绍disruptor介绍。为了能够更加清晰而有条理的阅读源码,首先分析各个术语描述的组件的源码,下篇文章再将其串联起来分析:
- Sequence和RingBuffer数据结构和操作
- Sequener的协调
- SequenceBarrier的屏障作用以及原理
- EventProcessor循环消费和EventHandler的处理过程
- WaitStrategy如何让EventProcessor等待
- DSL如何对以上组件的装配
### Sequence和RingBuffer数据结构和操作
Disruptor作为高性能的线程间传递数据的数据库,必然需要存储数据(即数据或者事件)。Disruptor中使用叫做RingBuffer的数据结构来存储数据,并将其抽象为类RingBuffer,提供操作数据的行为。
RingBuffer内部的数据结构是一个环形缓冲区,如下图:
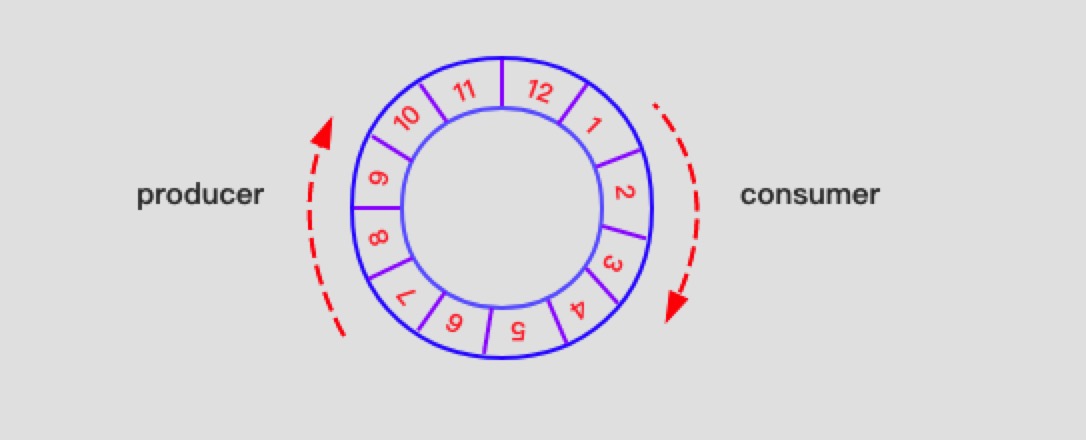
生产者将数据存入环形缓冲区,消费者随后从环形缓冲区取出数据处理。
对于该数据结构的表示,相信大家应该再熟悉不过,数组。RingBuffer内部包含了Object[]来表示环形缓冲区,存储Disruptor的数据:
private final long indexMask;
// 该数组表示环形缓冲
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
数组的天然优势就是顺序访问效率非常高,但是对于数组的读写访问需要维护其下标,表示读写的位置。
Disruptor将下标的表示抽象成Sequence类表示,用Sequence来记录读写位置。为什么单独抽象成Sequence来表示?原因有两点:
- 保证线程安全
- 保证缓存行共享
普通的Long类型无法保证线程安全,单独使用AtomicLong表示位置又存在伪共享问题(关于伪共享,这里不做详细介绍)。所以抽象Sequence类,并包含实际记录位置的value值。数据结构如下:
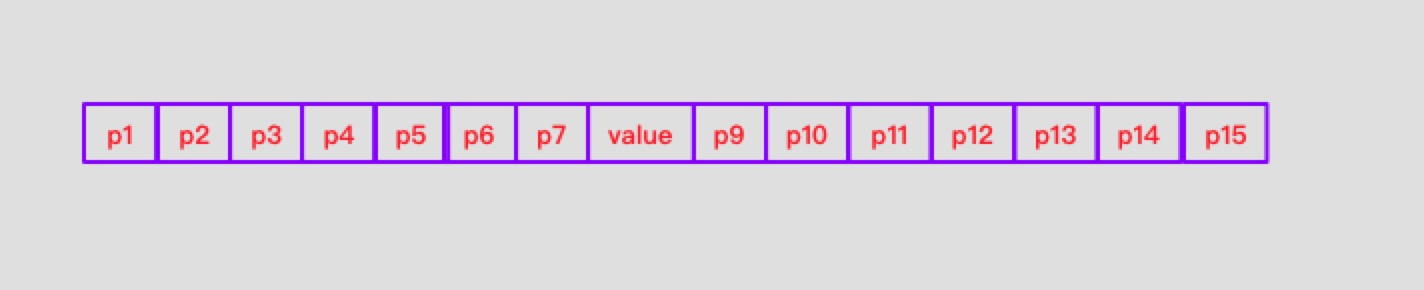
对于如何它是如何保证线程安全和解决伪共享问题可以看Javadocs中的描述:
Concurrent sequence class used for tracking the progress of the ring buffer and event processors. Support a number of concurrent operations including CAS and order writes.
Also attempts to be more efficient with regards to false sharing by adding padding around the volatile field.
Sequence用于并发场景下追踪RingBuffer和EventProcessor的进度。支持多种并发操作,如:CAS和顺序写。也尝试利用填充方式包围volatile value解决false sharing问题。
需要明白的是这里的填充是填充缓存行,保证value能独处一个缓存行中(即不和无依赖的变量同处一个缓存行中)。
再来看下它是如何进行填充的:
// 左边填充
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
// volatile value,保证可见性和有序性
class Value extends LhsPadding
{
protected volatile long value;
}
// 右边填充
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
// 继承RhsPadding,从而有缓存填充的volatile value
public class Sequence extends RhsPadding{
...
}
通过以上方式保证:在一个缓存行中,只有填充的数据和value。其中value用于记录RingBuffer的位置。关于其他的行为实现,基本完全和AtomicLong的实现一样,均使用Unsafe类提供的CAS操作实现去线程安全的操作,如:
public void set(final long value)
{
UNSAFE.putOrderedLong(this, VALUE_OFFSET, value);
}
通过UNSAFE提供的顺序写API设置,putOrderLong将会在写和之前的任何存储之间插入Store/Store barrier,保证这次write不会被重排。
如类似AtomicLong的CAS操作:
public boolean compareAndSet(final long expectedValue, final long newValue)
{
return UNSAFE.compareAndSwapLong(this, VALUE_OFFSET, expectedValue, newValue);
}
Sequence提供两种类型的构造函数:
// 使用默认值-1L初始化Sequence
public Sequence()
{
this(INITIAL_VALUE);
}
// 使用指定的参数构造Sequence
public Sequence(final long initialValue)
{
UNSAFE.putOrderedLong(this, VALUE_OFFSET, initialValue);
}
### Sequener的协调
RingBuffer用于存储数据,但是很多行为,如:控制写入数据至RingBuffer,控制读取等等行为,等待控制等都是在Sequencer中实现。Sequencer是Disruptor的核心。
其中控制图如下:
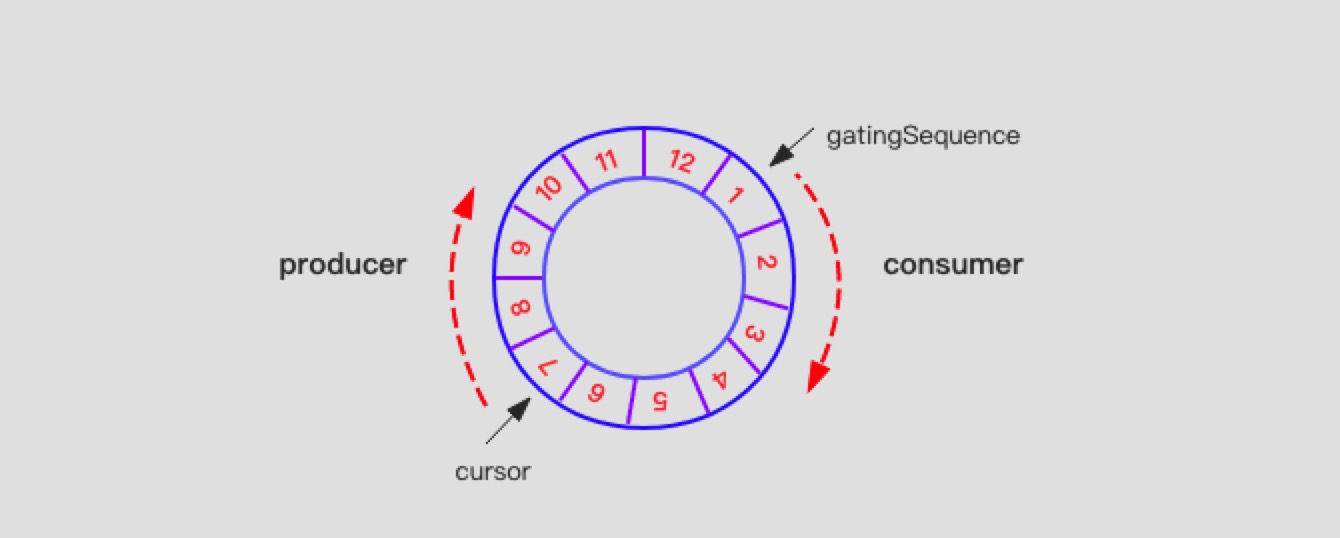
Sequencer中有两个非常重要的Sequence。一种是用来记录生产者的位置cursor,另一种用来记录消费者的位置gatingSequence。Sequencer需要控制生产者游标cursor沿着RingBuffer旋转方向不能超过覆盖消费者消费者的gatingSequence。
对于生产者而言,每次生产存入数据时,需要判断cursor + 1是否会覆盖gatingSequence。如果不覆盖,则可以写入数据。如果抵达消费者的Sequence边界,则需要使用相应的等待策略等待,等待有空的可用槽位写入。
对于消费者而言,每次消费时,需要检查是否有课消费的数据,只需要检查自身的Sequence和cursor的大小关系即可。
Sequencer的协调作用看下图描述:
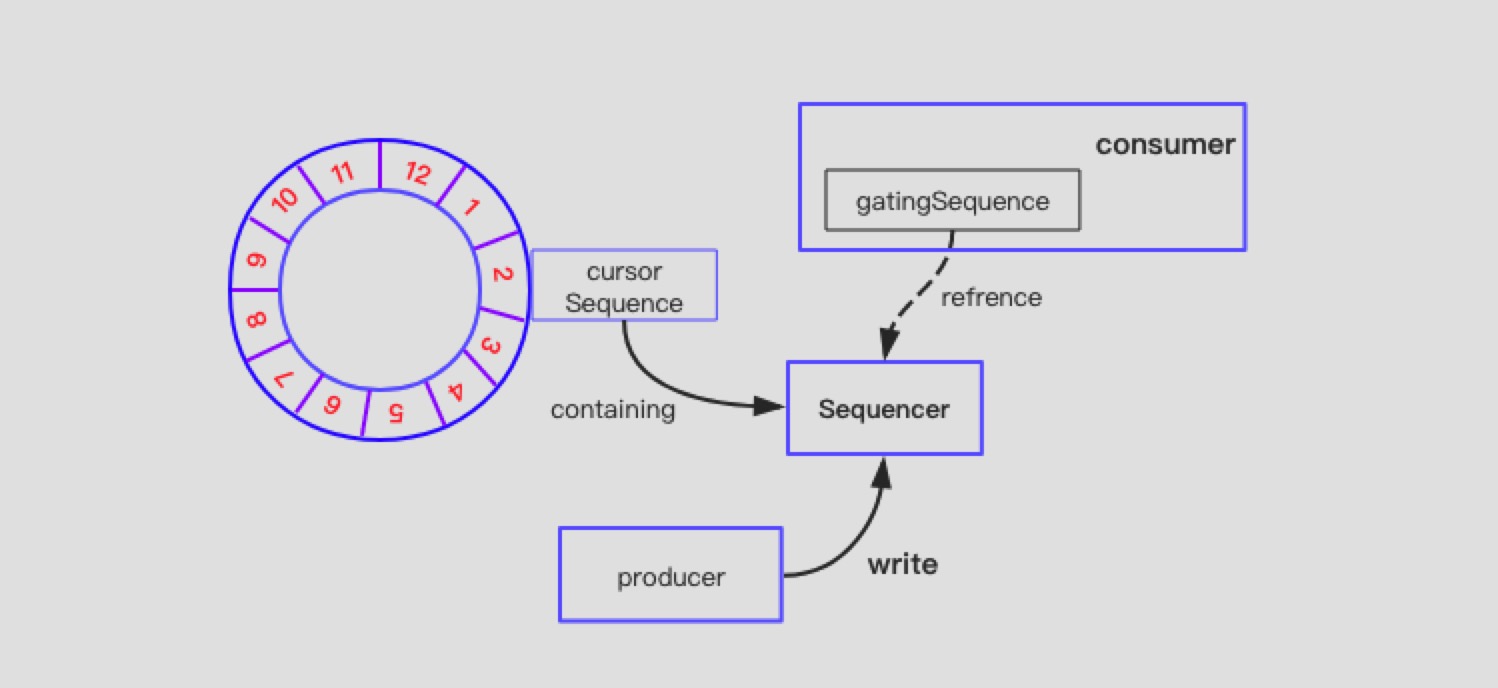
Disrutpor中根据场景不同分为两类Sequencer。单生产者使用SingleProducerSequencer,多生产者使用MultiProducerSequencer。Sequencer的UML类图如下:
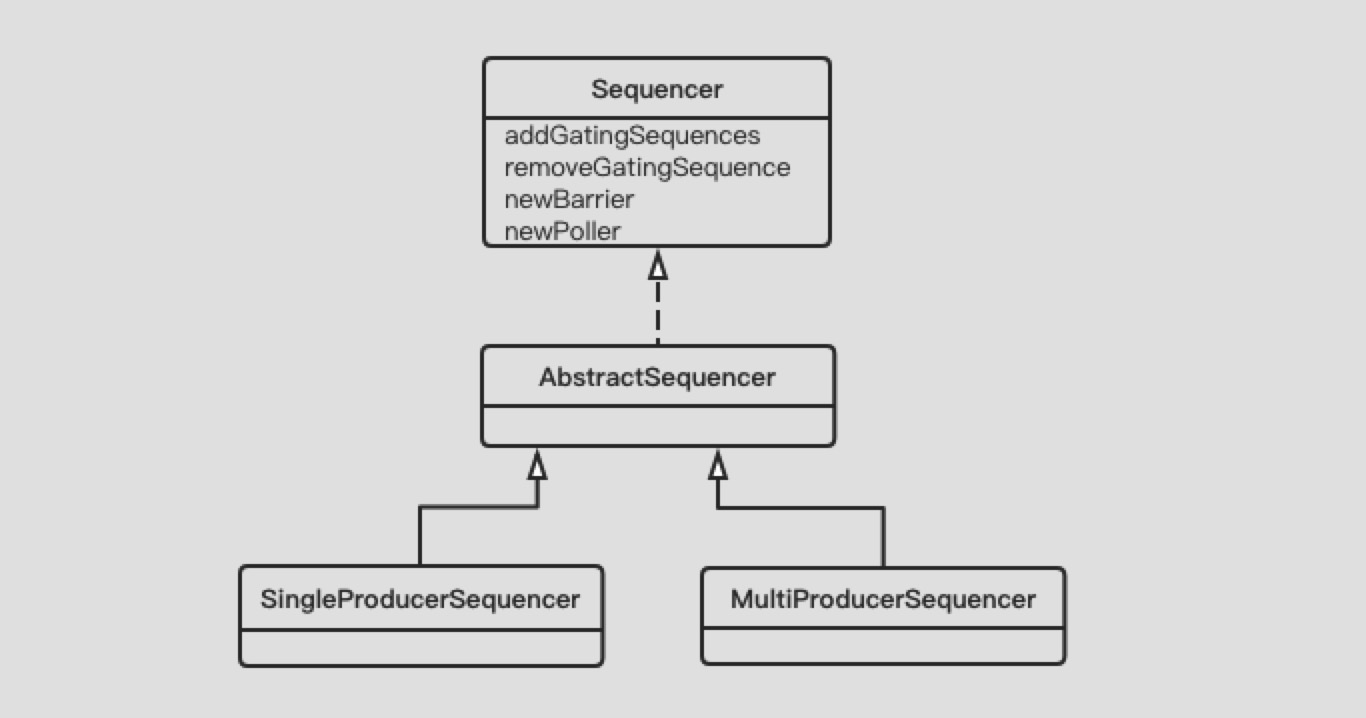
最顶层抽象了Sequencer接口,定义了Sequencer的基本行为:
- 增加门控Sequence
- 移除门控Sequence
- 创建新的SequenceBarrier
- 创建新的Event Poller
首先分析Sequencer的数据结构,其中成员域都在AbstractSequencer中定义:
// 原子引用更新器
private static final AtomicReferenceFieldUpdater<AbstractSequencer, Sequence[]> SEQUENCE_UPDATER =
AtomicReferenceFieldUpdater.newUpdater(AbstractSequencer.class, Sequence[].class, "gatingSequences");
// RingBuffer的大小
protected final int bufferSize;
// 等待策略
protected final WaitStrategy waitStrategy;
// RingBuffer游标,初始化值为-1L
protected final Sequence cursor = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
// 门控Sequence,即消费者Sequence,消费者可能会存在多个
protected volatile Sequence[] gatingSequences = new Sequence[0];
从包含的成员域也可以看出其实Disruptor的核心。cursor Sequence用于作为RingBuffer的游标,表示RingBuffer目前最大的可用的数据槽位。gatingSequences是消费者消费的位置Sequence,Sequencer依此进行控制生产者不能超过而覆盖未被消费的数据。waitStrategy主要用于创建SequenceBarrier,消费者需要依此策略进行wait。
Sequencer在Disruptor中起到的核心作用便是控制协调Sequence,并且做追踪使用。
### SequenceBarrier的屏障作用以及原理
SequenceBarrier的屏障主要作用于消费者的Sequence,控制消费者等待生产者生产可达的数据即cursor Sequence。
前一种模式是消费者依赖生产者最大可达数据。还有另一种模式是消费者依赖图(关于这个在第一篇Disruptor介绍中已经详细介绍),此时SequenceBarrier将控制消费者的Sequence不超过另外被依赖消费者的Sequence。
在Disruptor中关于SequenceBarrier有两个非常重要的行为:
// 等待指定sequence的slot可用
long waitFor(long sequence) throws AlertException, InterruptedException, TimeoutException;
// 获取RingBuffer的cursor
long getCursor();
Disruptor中关于SequenceBarrier的实现只有ProcessingSequenceBarrier其一个。其中结构如下:
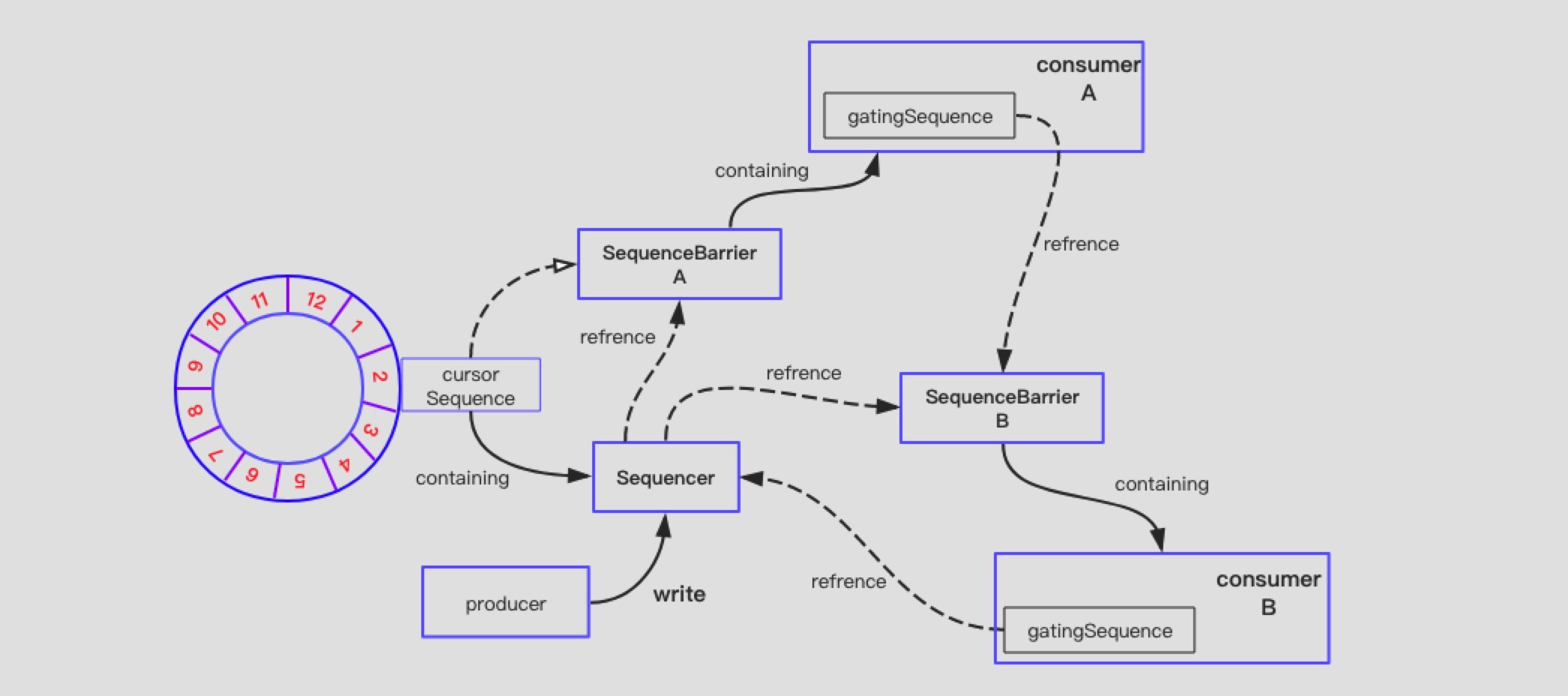
SequenceBarrier主要处在消费者和Sequencer之间,用于协调消费者与cursor Sequence,使用waitStraty策略协调。
再来看下其包含的成员域:
// SequneceBarrier使用的等待策略
private final WaitStrategy waitStrategy;
// SequenceBarrier依赖的Sequence,取决于消费者依赖图
// 要么是依赖cursor,要么依赖其他消费者Sequence
private final Sequence dependentSequence;
private volatile boolean alerted = false;
// cursor Sequence
private final Sequence cursorSequence;
private final Sequencer sequencer;
主要屏障的算法流程:消费者每次请求消费指定Sequence位置的数据时,SequenceBarrier发挥屏障作用,对其Sequence与依赖的Sequence比较。如果dependentSequence大于当前消费的Sequence,则返回不大于dependentSequence的最大可消费的位置。
上图中展示了上述所有的两种模型,消费者依赖生产者和消费者依赖消费者。Consumer A的SequenceBarrier A依赖cursor Sequence;Consumer B的SequenceBarrier B依赖Consumer A的gating Sequence。
### EventProcessor循环消费和EventHandler的处理过程
EventProcessor和EventHandler都是对消费端而言。其中EventProcessor由Disruptor内部使用,循环从RingBuffer中获取EventData。EventHandler由用户自实现的业务逻辑,处理消费的EventData。他们之间的关系是,EventHandler作为回调接口,EventProcessor将从RingBuffer消费者的Event传递给Handler处理。
在Disruptor中,EventProcessor的实现有三类:
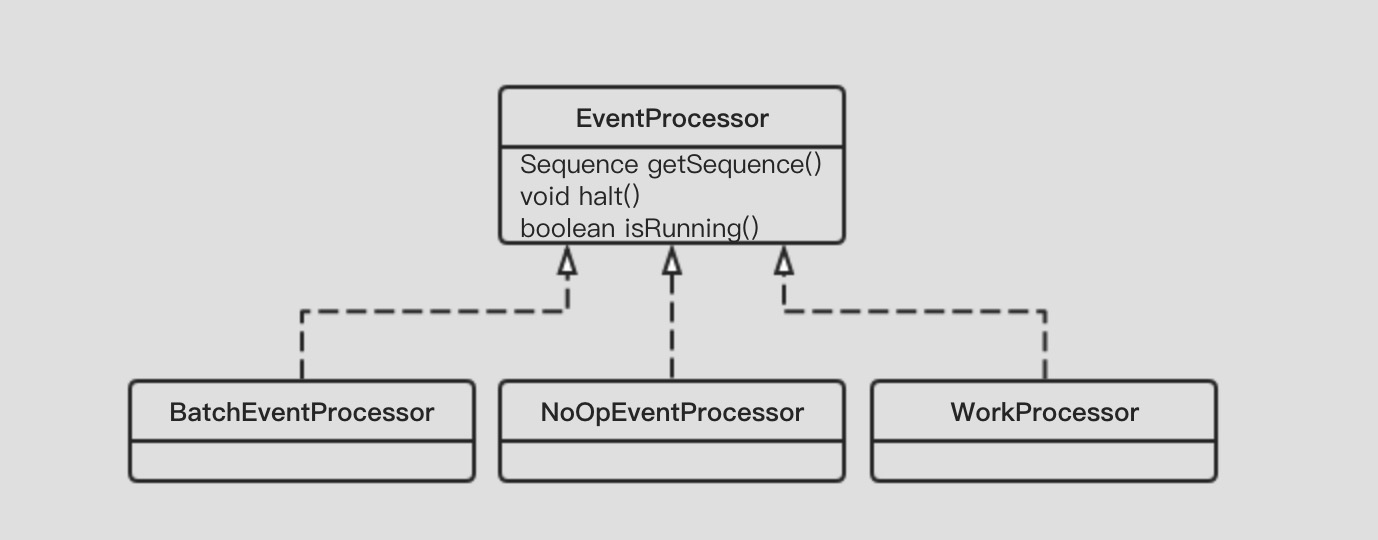
- BatchEventProcessor具有批量处理Event的能力,其中通过组合EventHandler,将从RingBuffer中获取的Event传递给Handler处理
- NoOpEventProcessor不具有任何操作,只是为了测试和预填充RingBuffer
- WorkProcessor通常结合WorkerPool使用
其中BatchEventProcessor是最频繁使用,这里具体看下它的数据结构:
// Sequence屏障,用于处理Sequene之间的依赖关系
private final SequenceBarrier sequenceBarrier;
// 用于定义的EventHandler
private final EventHandler<? super T> eventHandler;
// 消费者端的Sequence,用于标记消费者的位置
private final Sequence sequence = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
### WaitStrategy如何让EventProcessor等待
Disruptor中使用RingBuffer存储数据,实现消费者和生产者之间的数据交互。生产-消费模型中必然有等待,Disruptor也不例外。只不过Disrutor的优异之处在于提供了多种等待方式供用户针对各种应用场景进行选择。
Note:
目前Disruptor只针对消费者等待生产者时应用了等待策略,对于生产者等待消费者并未使用WaitStrategy。
当消费者消费到可达的最大Sequence位置时,即需要等待生产者生产数据,这时各种WaitStrategy便油然而生:
关于各种策略的语义和使用场景,上篇文章disruptor使用中已经详细介绍,这里不再赘述。这里着重分析每种策略的实现原理。
BlockingWaitStrategy
当无可达事件消费时,使用该策略,消费者将发生阻塞直到有事件时,消费者再继续运行:
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException
long availableSequence;
if (cursorSequence.get() < sequence)
{
lock.lock();
try
{
while (cursorSequence.get() < sequence)
{
barrier.checkAlert();
processorNotifyCondition.await();
}
}
finally
{
lock.unlock();
}
}
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
策略中使用Java的工具Lock和Condition实现循环等待。当有生产者发布事件时,将调用通知:
@Override
public void signalAllWhenBlocking()
{
lock.lock();
try
{
processorNotifyCondition.signalAll();
}
finally
{
lock.unlock();
}
}
BusySpinWaitStrategy
该策略是忙等策略,当无事件消费者,将一直处于循环运行,检测是否有事件:
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
SleepingWaitStrategy
使用该策略时,当无事件可消费,将睡眠指定的时间:
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException
{
long availableSequence;
int counter = retries;
while ((availableSequence = dependentSequence.get()) < sequence)
{
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
barrier.checkAlert();
if (counter > 100)
{
--counter;
}
else if (counter > 0)
{
--counter;
Thread.yield();
}
else
{
LockSupport.parkNanos(sleepTimeNs);
}
return counter;
}
其中使用LockSupport.parkNanos让消费者线程睡眠指定时间。如果一直无事件可消费,将循环睡眠,直到有事件可消费为止。
YieldingWaitStrategy
该策略使用Thread yield方式,置换出CPU给其他线程的方式达到等待:
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
int counter = SPIN_TRIES;
while ((availableSequence = dependentSequence.get()) < sequence)
{
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
barrier.checkAlert();
if (0 == counter)
{
Thread.yield();
}
else
{
--counter;
}
return counter;
}
其中使用Thread.yield()放弃CPU的使用,让其他线程能够使用。
Disruptor中的策略很多,但是大多数情况仍然使用Block策略,只有对严格要求低延时且CPU资源充足的情况才会使用忙等策略。
### DSL如何对以上组件的装配
以上介绍了很多围绕着RingBuffer的组件,如果将其装配组合,让其运行起来,估计要写很多样板代码且比较复杂。为了能够让其简单且易用,这里使用了DSL(Driven Specific Language)风格构建了Disruptor类帮助能够快速构建。
PS:
实际上,使用了构造者模式外观模式,能够借助Disruptor快速构建RingBuffer及其组件。通过组合装配这些组件,形成Disruptor。

Disruptor中持有RingBuffer和消费者信息,帮助完成快速构建高性能队列。
总结
Disruptor高性能队列中涉及到众多组件,本篇文章主要对其中的生产端和消费端以及处于中间的存储RingBuffer做了原理性分析。在这篇文章的基础上,下一篇将对其串联起来,从源码角度深入分析其实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号