解决“网页源代码编码形式为utf-8,但爬虫代码设置为decode('utf-8')仍出现汉字乱码”的问题
为了用爬虫获取百度首页的源代码,检查了百度的源代码,显示编码格式为utf-8

但这样写代码,却失败了…..
(这里提示:不要直接复制百度的URL,应该是http,不是https!!!)
# 获取百度首页的源码
import urllib.request
#(1)定义一个URL
url='http://www.baidu.com'
#(2)模拟浏览器向服务器发送请求 要在联网的前提下!
response=urllib.request.urlopen(url)
# (3)获取响应中的页面的源码
# 将二进制转化为字符串,也就是解码 decode('对应页面编码的格式')
content=response.read().decode('utf-8')
# (4)打印数据
print(content)
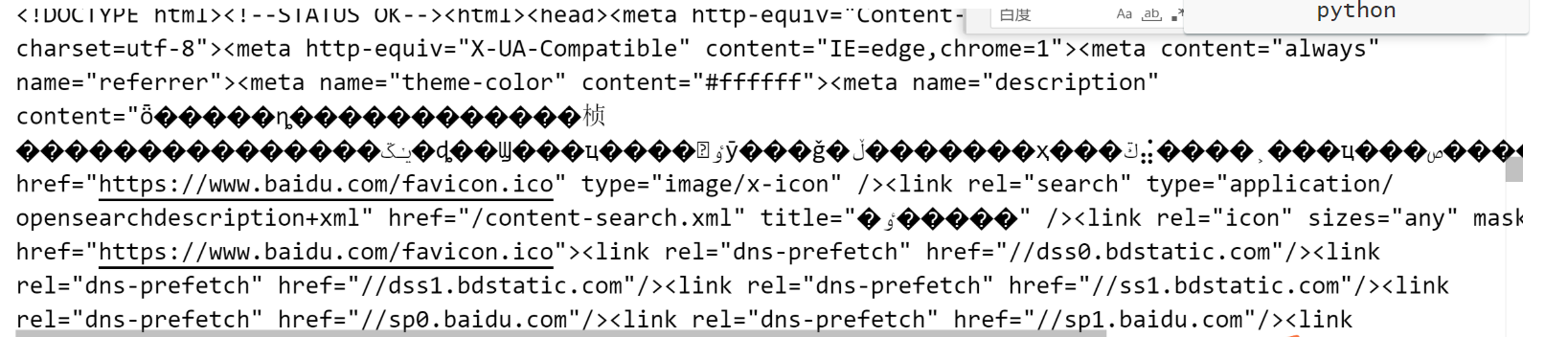
经过查阅资料,发现这样就可以了!成功的代码如下
import urllib.request
import chardet
# 定义一个URL
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 获取响应中的页面的源码
content = response.read()
# 检测编码
encoding = chardet.detect(content)['encoding']
# 将二进制转化为字符串,也就是解码
content = content.decode(encoding)
# 打印数据
print(content)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号