
MySQL第三章知识第一部分
SQL的特点:是一个综合的、功能极强并且简洁容易学的语言。
SQL的功能:数据查询、数据操纵、数据定义、数据控制。
数据库系统的主要功能是通过数据库支持的数据语言来实现。
菲关系模型(层次模型、网状模型)的数据语言分为:
- DDL:数据定义语言(用来维护存储数据的结构,例如:数据库、表等)。
- DML:数据操纵语言(对数据进行操作,也就是对数据表的内容进行操作)。
- DSDL:数据存储有关的描述语言。
SQL的特点:
- 综合统一:集数据定义语言、数据操纵语言、数据控制语言的功能与一体,语言风格统一,可以独立完成数据库生命周期中的全部活动;在关系模型中实体与实体之间的联系均用关系表示,这种数据结构的单一性带来了数据操作符的统一性。
- 高度非过程化:只要提出“做什么”,不用指明“怎么做”,因此无须了解存取路径,存取路径的选择以及SQL的操作过程由系统自动完成。
- 面向集合的操作方式:非关系数据模型采用的是面向记录的操作方式,操作对象是一条记录,但SQL采用集合操作方式,不仅操作对象、查找结果可以使元组的集合,而且一次插入、删除、更新操作的对象也可以是元组的集合。
- 以同一种语法结构提供多种使用方式:SQL既是独立的语言,又是嵌入式语言。作为独立语言,它能够独立的用于联机交互的使用方式,用户可以在终端键盘上直接敲入SQL命令对数据库进行操作;作为嵌入式语言,SQL语句可以嵌入到高级语言(C,C++,Java)程序中,供程序员设计程序时使用。
- 语言简洁、易学易用:SQL功能极强,语言十分简洁。核心功能只用了9个动词(数据查询:SELECT;数据定义:CREATE、DROP、ALTER;数据操纵:INSERT、UPDATE、DELETE;数据控制:GRANT、REVOKE)
补充:
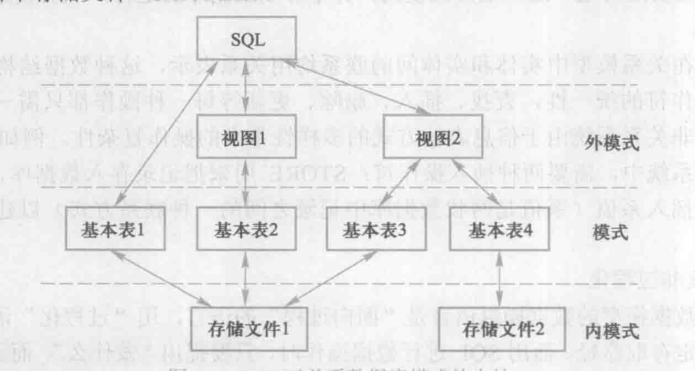
- 基本表和视图一样,都是关系。
- 基本表是本身独立存在的表,在关系数据库管理系统中一个关系对应一个基本表。
- 一个或多个基本表对应一个存储文件,一个表可以带若干索引,这些索引存放在存储文件中
- 存储文件的逻辑结构组成了关系数据库的内模式,存储文件的物理结构对最终用户是隐蔽的。
- 视图是从一个或多个基本表导出来的,它本身不独立存储的数据库中,所以视图是一个虚表。
数据定义:
关系数据库系统支持三级模式结构,其模式、外模式、内模式中的基本对象是模式、表、索引。因此SQL的数据定义包括模式定义、表定义、视图和索引的定义。
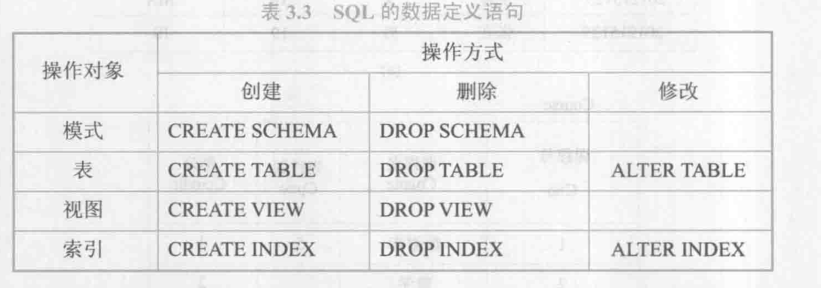
SQL标准不提供修改模式定义和修改视图定义的操作。如果想修改这些对象,只能先将它们删除然年再重建,SQL标准也没用提供索引相关的语句。
一个数据库管理系统的实例中可以建多个数据库,一个数据库中可以建立多个模式,一个模式下通常包括多个表、视图和索引等数据。
- 定义模式:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>;
如果没有指定<模式名>,那么<模式名>隐含为<用户名>。要创建模式,调用该命令的用户必须拥有数据库管理员权限,或者获得了数据库管理员授予的CREATE SCHEMA的权限。
定义模式实际上定义了一个命名空间,在这个空间中可以进一步定义该模式包含的数据库对象,例如基本表、视图、索引等。
- 删除模式:
DROP SCHEMA <模式名> <CASCADE|RESTRICT>;
其中CASCADE和RESTRICT必须二选一,选择了CASCADE(级联),表示在删除模式的同时把该模式中所有的数据库对象全部删除;选择了RESTRICT(限制),表示如果该模式中已经定义了下属的数据库对象,则拒绝删除语句的执行,只有当该模式中没有任何下属的对象时才能执行。
- 定义基本表
创建了一个模式就建立了一个数据库的命名空间,一个框架。
CREATE TABLE <表名> (<列名> <数据类型> [列级完整性约束条件]
,<列名> <数据类型> [列级完整性约束条件]
……
,[<表级完整性约束条件>]);
建表的同时可以定义与该表有关的完整性约束条件,这些完整性约束条件被存入系统的数据字典中,如果完整性约束条件涉及表中的多个属性列,则必须定义在表级上,否则可以定义在列级也可以定义在表级。有主码时要在主码那一列定义完后面加上“PRIMARY KEY”,标识为主码。如果有外码和被参照表以及被参照列,在完整性约束条件定义完后加上相应标识,外码“FOREIGN KEY”,被参照表“REFERENCES”,被参照列加上“()”就行。参照表和被参照表可以是同一个表。
数据类型:


- 修改基本表
ALTER TABLE<表名>
[ADD [COLUMN] <新列名> <数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT]]
[DROP CONSTRAINT<完整性约束> [CASCADE|RESTRICT]]
[ALTRE COLUMN <列名> <数据类型>];
其中<表名>是要修改的基本表,ADD字句用于增加新的列、新的列级完整性约束条件和新的表级完整性约束条件。DROP COLUMN字句用于删除表中的列。DROP CONSTRAINT字句用于删除指定的完整性约束条件。ALTER COLUMN 字句用于修改原有的列定义,包括修改列名和数据类型。
- 删除基本表
DROP TABLE <表名> [CASCADE|RESTRICT];
索引:
建立索引是加快查询素的有效手段。
数据库索引有多种类型,常见索引包括顺序文件上的索引、B+树索引、散列索引、位图索引等,索引虽然能加快数据库查询速度,但需要占用一定的存储空间,当基本表跟新时,索引要进行相应的维护,这些都会增加数据库的负担。
一般来说,建立与删除索引由数据库管理员或表的属主,即建立表的人,负责完成。关系数据库管理系统在执行查询时会自动选择合适的索引作为存取路径,用户不必也不能显示地选择索引。索引是关系数据库管理系统的内部实现技术,属于内模式的范畴。
- 建立索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>;
ON <表名>(<列名> [<次序>][,<列名>[<次序>]]……);
其中,<表名>是要建立索引的基本表的名字。索引可以建立在该表的一列或多列上,各列名之间用逗号隔开。每个<列名>后面还可以用<次序>指定索引值的排列次序,可选ASC(升序)或DESC(降序),默认值为ASC。
UNIQUE表明此索引的每一个索引值只对应唯一的数据记录。CLUSTER表示要建立的索引是聚簇索引。
- 修改索引
ALTER INDEX <旧索引名> RENAME TO <新索引名>;
- 删除索引
索引一经建立就由系统使用和维护,不需用户干预。建立索引是为了减少查询操作的时间,但如果数据增、删、改频繁,系统会花费许多时间来维护,从而降低了查询效率。这时可以删除一些不必要的索引。
DROP INDEX <索引名>;
删除索引时,系统会同时从数据字典中删去有关该索引的描述。
数据字典
数据字典是关系数据库管理系统内部的一组系统表,它记录了数据库中所有的定义信息,包括关系模式定义、视图定义、索引定义、完整性约束定义、各类用户对数据库的操作权限、统计信息等。关系数据库管理系统在执行SQL的数据定义语句时,实际上就是在更新数据字典表中的响应信息。在进行查询优化和查询处理时,数据字典中的纤细是其重要依据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号